Claude Code(七):Jupyter 数据分析与 Streamlit 可视化
要点
- Notebook 专属工具:了解 Claude Code 针对 Jupyter Notebook 的特有工具,如 read_notebook,使其能够理解和操作 .ipynb 文件的单元格结构。
- AI 驱动的重构:学习如何通过一个详尽的 Prompt,指导 AI 进行“关注点分离”,将数据加载、业务指标计算等逻辑从 Notebook 中剥离,形成独立的 Python 模块。
- 交互式应用生成:掌握如何向 Claude Code 清晰地描述一个仪表盘的布局和组件,让它利用 Streamlit 库,将重构后的代码逻辑快速转化为一个 Web 应用。
- 迭代式开发与调试:观察在整个重构和生成过程中,如何与 AI 进行多轮对话,修复代码错误、调整应用布局,完成一个真实场景下的迭代开发闭环。
一、一份典型的Notebook
课程从一个常见的数据分析场景开始:我们拿到了一份分析电商数据的 Jupyter Notebook。
这份 Notebook 具备了所有“能用但不好用”的典型特征:
- 逻辑混杂:数据读取、数据清洗、指标计算、图表绘制的代码全部线性地堆叠在一起。
- 代码重复:为了计算不同的指标,同样的数据处理逻辑可能被复制粘贴了多次。
- 可读性差:代码块之间缺乏清晰的说明,充斥着临时的变量名和被注释掉的代码。
- 难以复用:如果想在另一个项目中使用其中的某个计算逻辑,唯一的办法就是“复制粘贴”,这极易引入错误。
- 输出混乱:虽然最终得出了结论,但过程中伴随着各种警告信息和格式不佳的中间输出。
我们的目标,不是去质疑这份 Notebook 的分析结论,而是要对它的 工程质量 进行一次彻底的重构。
二、从 Notebook 到模块化代码的重构
我们启动 Claude Code,并准备了一个详尽的 Prompt。值得一提的是,为了处理复杂的指令,一个很好的实践是先将 Prompt 写在一个 Markdown 文件中,这样便于组织思路和反复修改。
这个 Prompt 的核心是向 Claude Code 传达了 “关注点分离” (Separation of Concerns) 的思想。
- 关注点分离 (SoC):关注点分离是软件工程中的一个核心设计原则。它主张将一个复杂的计算机程序分解成多个不同的部分,每个部分只处理一个独立的“关注点”或“职责”。
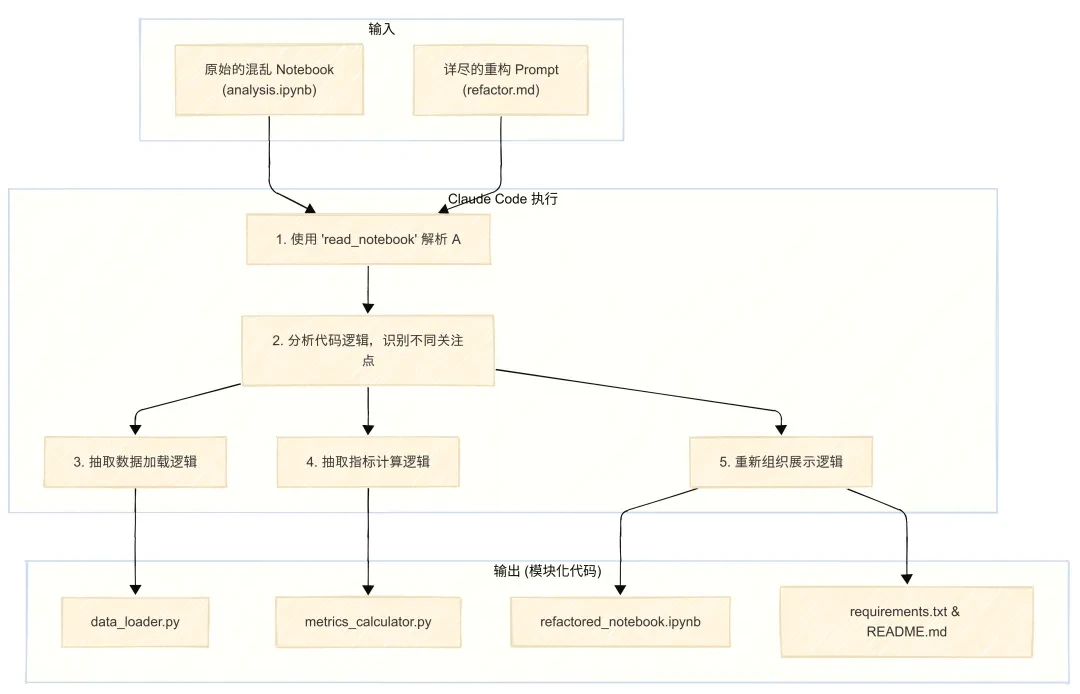
在本次案例中,我们将原始 Notebook 中混杂的逻辑分离为三个独立的关注点:
- 数据加载/处理 (data_loader.py)
- 业务指标计算 (metrics_calculator.py)
- 数据展示/可视化 (重构后的 Notebook)
这样做的好处是显而易见的:每个模块职责单一,易于理解、测试和复用。
我们的 Prompt 明确要求 Claude Code:
- 创建 data_loader.py:用于封装所有从 CSV 文件读取和预处理数据的逻辑。
- 创建 metrics_calculator.py:用于封装所有业务指标(如年同比增长率、平均订单价值)的计算逻辑。
- 重构 Notebook:创建一个新的、整洁的 Notebook,它不再包含具体的实现逻辑,而是通过导入和调用上述两个模块来完成分析和可视化。
- 提升代码质量:要求为新生成的函数添加文档字符串(docstrings),并改进可视化的美观度。
- 生成辅助文件:创建 requirements.txt 和 README.md,完善项目的工程化。
Claude Code 接收指令后,开始执行。它使用了 read_notebook 工具来解析原始 .ipynb 文件,然后按计划创建了新的 Python 文件和重构后的 Notebook。
在重构过程中,我们遇到了一个 KeyError。这提供了一个很好的机会来展示人机协作调试的流程:我们将错误信息和相关的代码单元格反馈给 Claude Code,它迅速定位问题并进行了修复。
最终,我们得到了一套结构清晰的代码。新的 Notebook 变得非常整洁,主要由导入语句、高层函数调用和精美的图表组成,可读性和可维护性得到了质的飞跃。
三、从 Notebook 到 Streamlit 仪表盘的跃迁
重构后的代码为我们进行下一步的“产品化”打下了坚实的基础。我们的新目标是:将这些分析结果从一个静态的 Notebook,转变为一个可交互的 Web 仪表盘。我们选择了 Streamlit 这个强大的工具。
- Streamlit:一个开源的 Python 库,它能让你用纯 Python 脚本,以极快的速度为你的数据科学和机器学习项目创建美观、可交互的 Web 应用。你无需任何前端知识(HTML/CSS/JS),只需调用 Streamlit 提供的 API,就能生成滑块、按钮、图表等各种 UI 组件,非常适合快速原型设计和数据产品交付。
我们再次采用编写 Markdown Prompt 的方式,向 Claude Code 描述了我们想要的仪表盘的具体 布局:
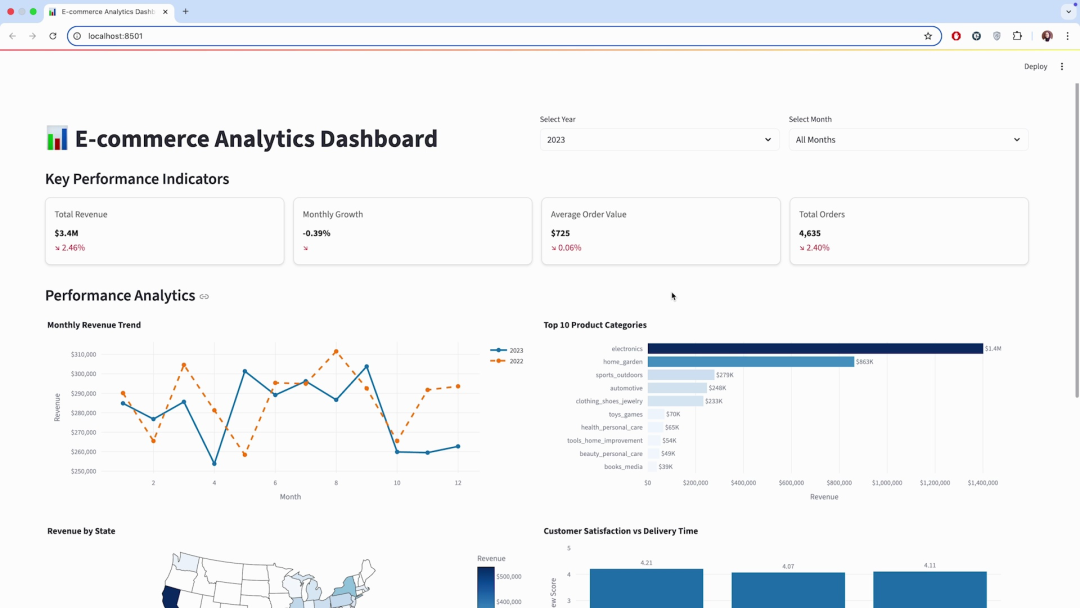
- Header:包含标题和年份过滤器。
- KPIs:用卡片形式展示四个关键指标(总收入、增长率、平均订单价值、总订单数)。
- Charts:分行展示四个核心图表(收入趋势、品类表现、各州收入地图、客户满意度)。
这种 “布局即 Prompt” 的方法非常高效。我们不是让 AI 自由发挥,而是给了它一个清晰的“线框图”,这大大减少了后续反复调整的成本。
Claude Code 接收到这个新的 Prompt 后,开始编写
dashboard.py 文件。它导入了 streamlit
库,并调用了我们之前重构好的data_loader 和
metrics_calculator 模块。
在本地运行 streamlit run dashboard.py
后,我们的仪表盘原型诞生了。初版虽然大体可用,但存在一些瑕疵:一些卡片是空的,且默认年份不是我们期望的
2023 年。
我们再次通过一个简短的 Prompt
迭代:make the default year 2023, add filters for months, remove the empty cards。Claude
Code 迅速更新了 dashboard.py 代码。
刷新浏览器后,我们得到了一个功能完善、布局合理的交互式仪表盘。在很短的时间内,我们完成了一次从原始数据分析脚本到专业数据产品的端到端转换。
四、总结
本期的案例,完美地展示了 Claude Code 在数据科学工作流中的应用潜力。它所扮演的角色,远不止一个简单的代码片段生成器。
- 作为“代码架构师”,它帮助我们将混乱的探索性代码,重构为遵循软件工程原则的、模块化的、可维护的代码库。
- 作为“应用开发者”,它根据我们用自然语言描述的布局,快速地将数据分析逻辑封装成一个可交互的 Streamlit Web 应用。
- 作为“敏捷的队友”,它在整个过程中能与我们进行高效的迭代和调试,快速响应我们的调整需求。
这个工作流的转变,让数据科学家和分析师可以将更多的精力投入到更高价值的工作中:定义业务问题、设计分析逻辑、构思产品的最终形态,而将繁琐的代码组织、UI 布局实现等工作,放心地交给 AI 去完成。