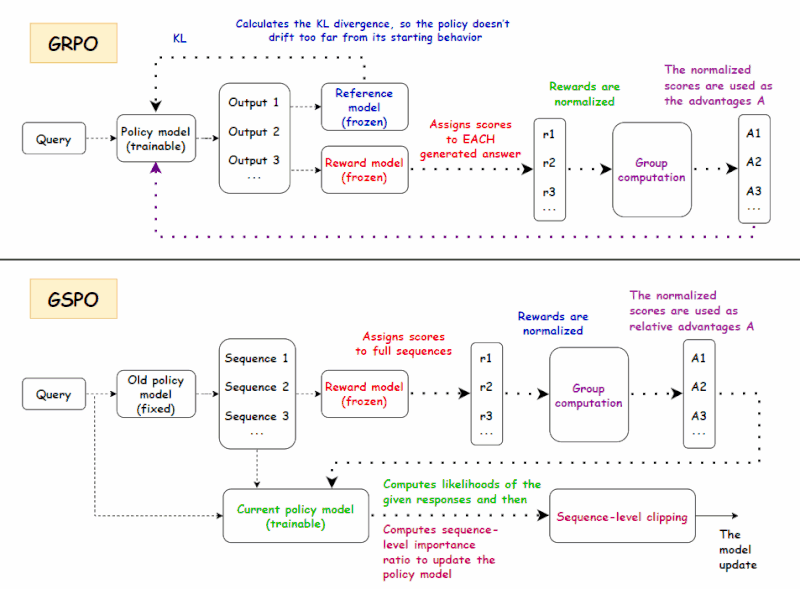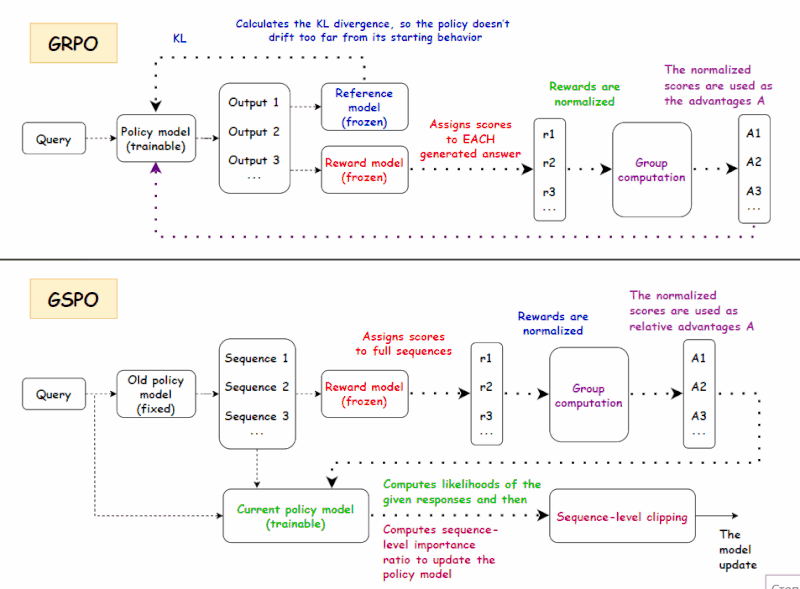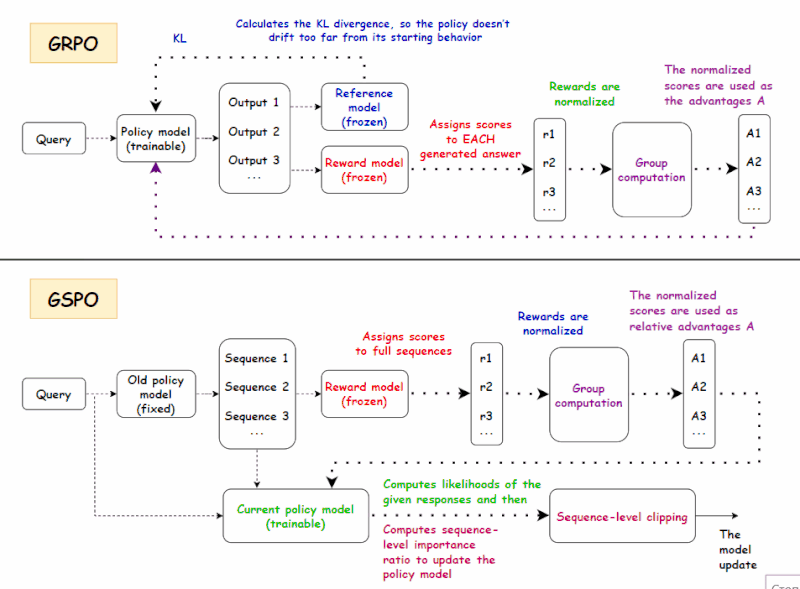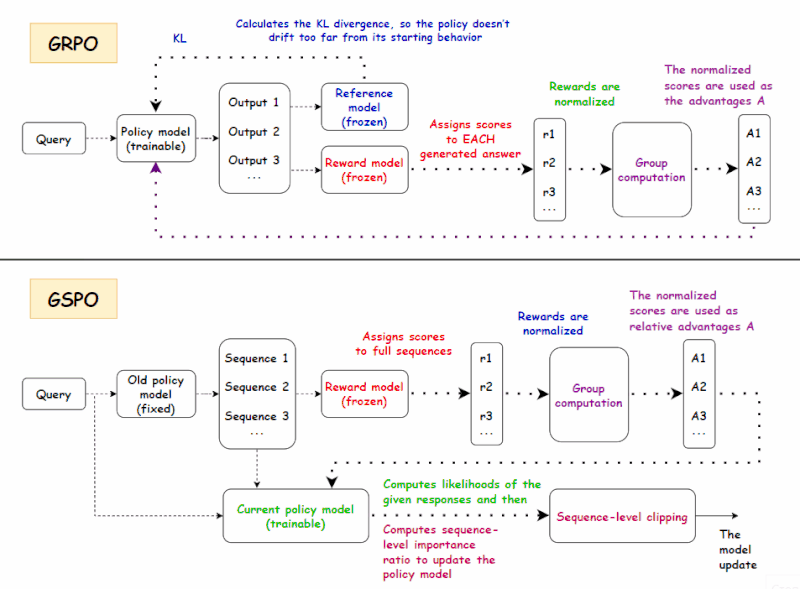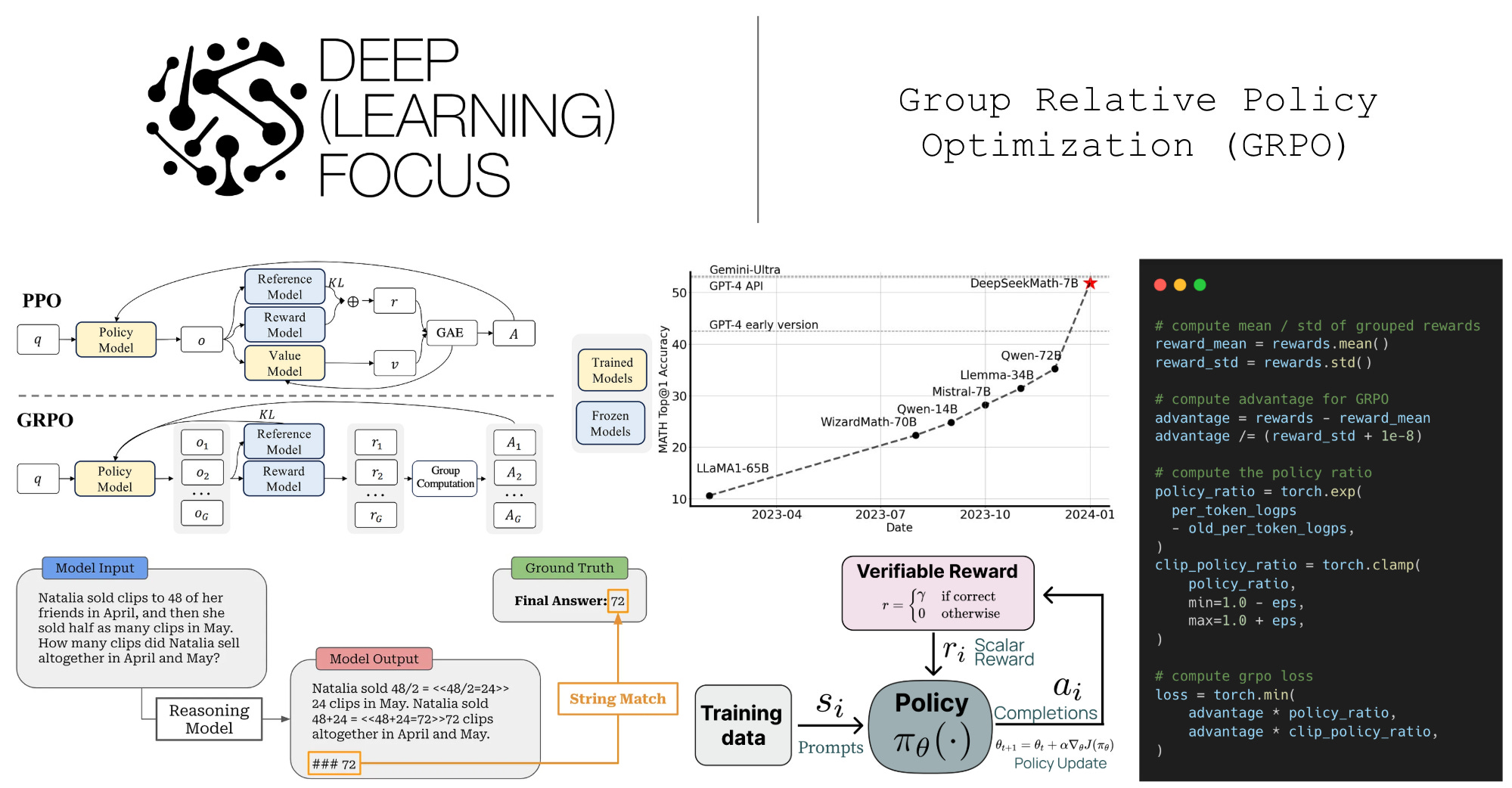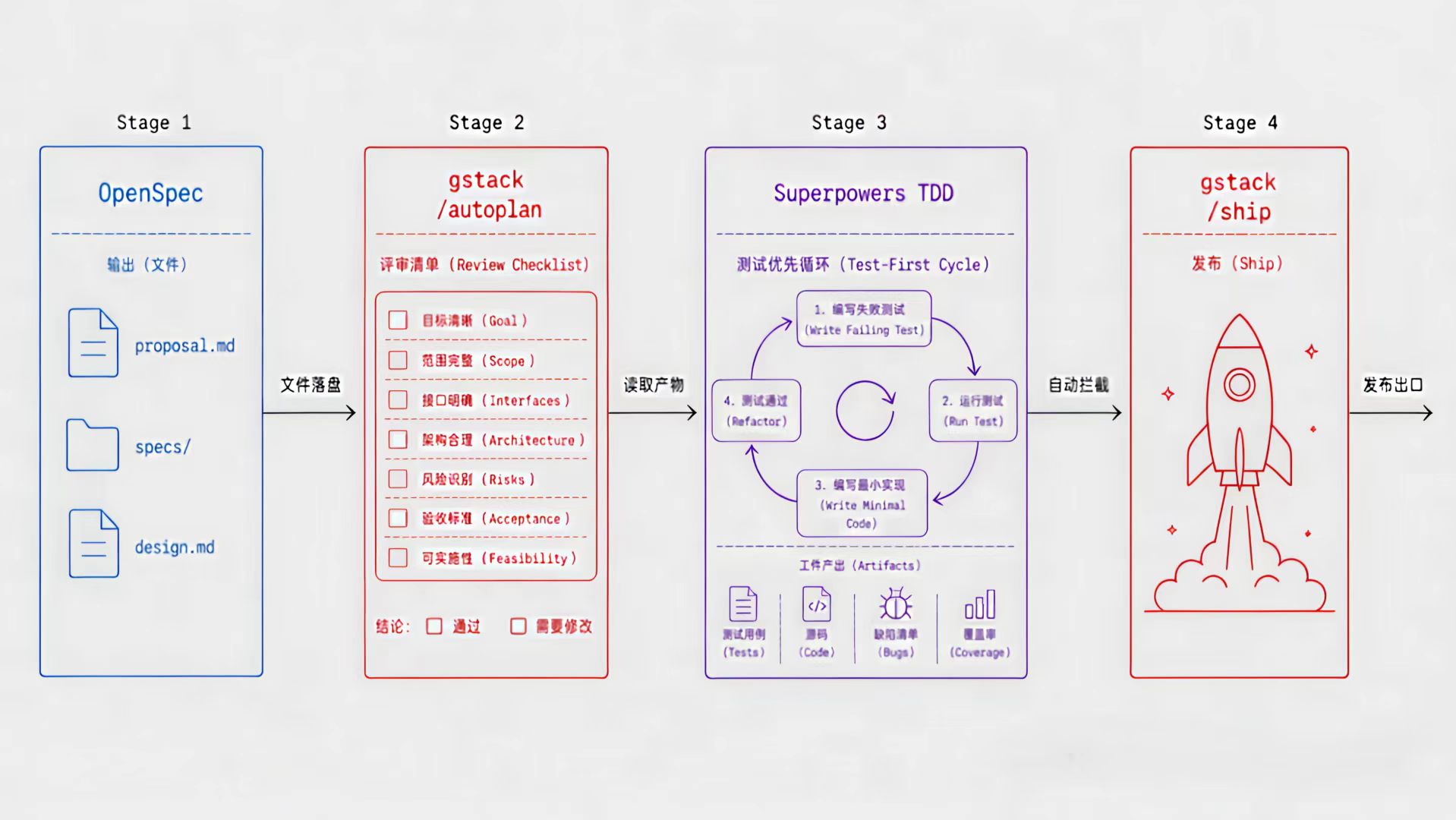
gstack + Superpowers + OpenSpec 三器合一:AI 编程工程化共存方案
引言:AI 编程的三个断层 AI 辅助编程进入 2026 年,社区已经形成共识:单靠一个 AI 模型裸写代码远远不够。实际工程中面临三个核心断层: 需求断层:AI 在聊天记录里”记住”需求,三轮回合后就开始 drift。没有结构化的规范文档,需求就是一阵风。 质量断层:AI 写代码快,但写测试慢、写文档懒、做边界检查敷衍。没有硬性约束,代码量上去了,技术债也上去了。 流程断层:从想法到上线,中间