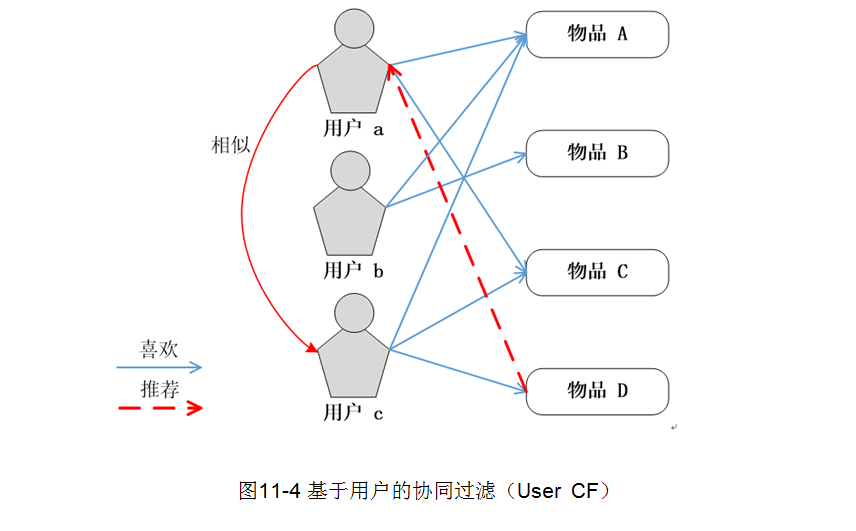
推荐算法--CF 一、ItemCF 基于物品的协同过滤就是根据用户历史选择物品的行为,通过物品间的相似度,给用户推荐其他物品。 1.1 原理 计算物品之间的相似度 根据物品的相似度和用户的历史行为给用户生成推荐列表 1.2 物品相似度计算 喜欢物品的⽤户记作集合 喜欢物品的⽤户记作集合 定义交集 两个物品的相似度(余弦相似度): 预估⽤户对候选物品的兴趣: 1.3 ItemCF召回的完整流程 1. 2025-03-10 推荐算法 #推荐算法
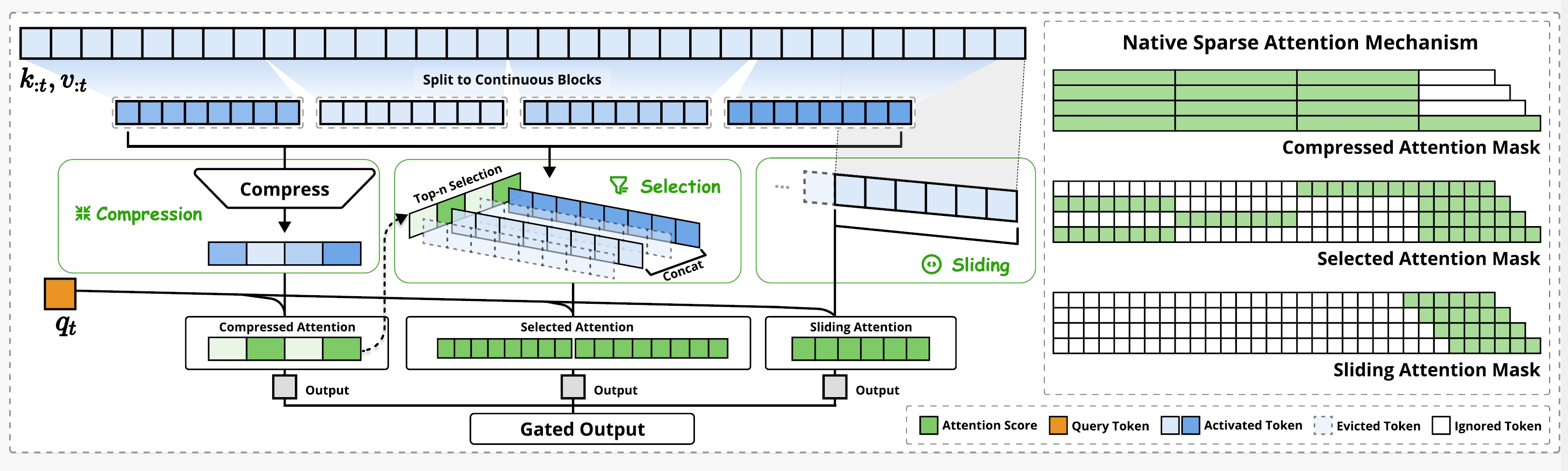
Native Sparse Attention——DeepSeek 提出硬件级的稀疏注意力机制 论文:[2502.11089] Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention 一、简介 DeepSeek 团队最近(2025 年 2 月)提出的一种稀疏注意力机制,核心的创新在于: 智能信息分层:将文本压缩为粗粒度语义块、动态筛选关键片段,并结合局部滑动窗口,既保留全局理解又减少 2025-03-01 LLM #LLM #DeepSeek
神经网络(七)——优化算法 优化算法在神经网络训练中至关重要,它们决定了如何调整模型参数以最小化损失函数。以下是对神经网络中常用优化算法的详细总结,包括梯度下降及其变种。 一、梯度下降(Gradient Descent) 梯度下降是最基础的优化算法,通过沿着损失函数梯度的反方向更新参数,逐步减少损失。 算法步骤 初始化参数:随机初始化参数 。 计算梯度:计算损失函数 对参数 的梯度 。 更新参数:沿梯度反方向更新参数: 2025-02-16 DL #DL #神经网络 #优化算法
神经网络(六)——更多RNN 一、门控循环单元(GRU) 门控循环单元与普通的循环神经网络之间的关键区别在于:前者支持隐状态的门控。这意味着模型有专门的机制来确定应该何时更新隐状态,以及应该何时重置隐状态。这些机制是可学习的,并且能够解决了上面列出的问题。例如,如果第一个词元非常重要,模型将学会在第一次观测之后不更新隐状态。同样,模型也可以学会跳过不相关的临时观测。最后,模型还将学会在需要的时候重置隐状态。 1.1 重置门和更 2025-01-27 DL #DL #神经网络 #RNN
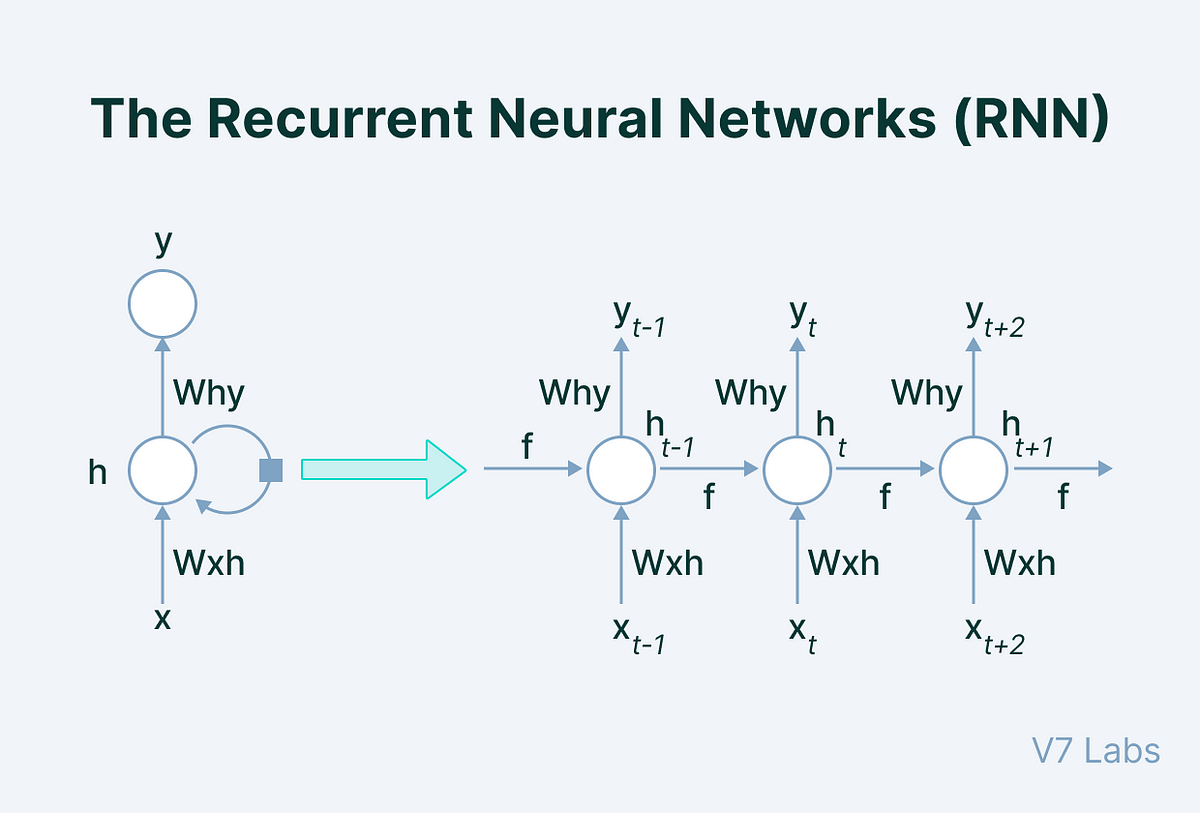
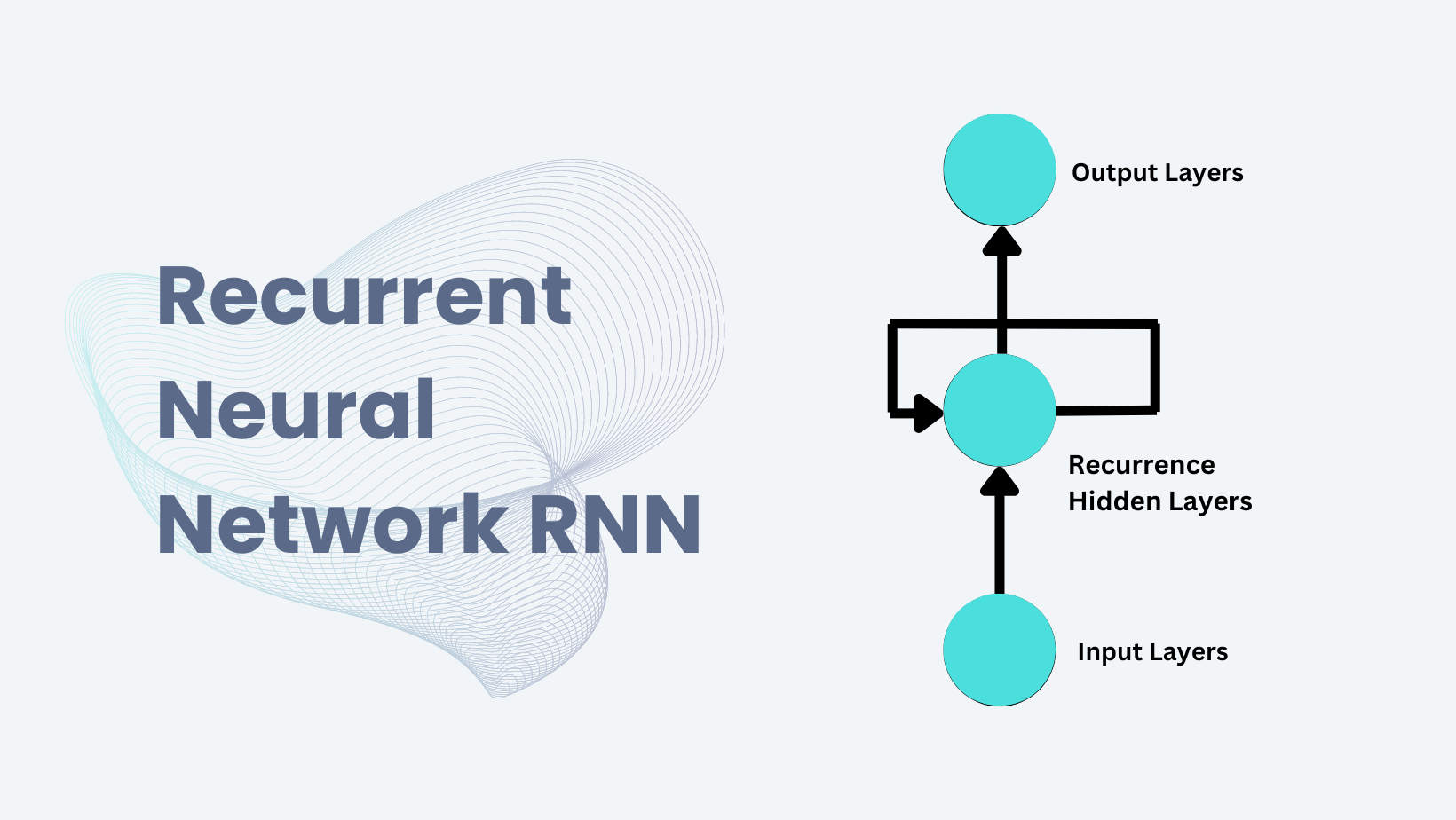
神经网络(五)——循环神经网络(Recurrent Neural Network,RNN) 循环神经网络(Recurrent Neural Network,RNN)是一类用于处理序列数据的神经网络,它在时间步上有循环连接,能够捕捉序列中的时间依赖关系。RNN广泛应用于自然语言处理(NLP)、时间序列预测、语音识别等领域。 一、序列模型 1.1 自回归模型 对于股票,用表示价格,即在时间步(time step)时,观察到的价格。对于本文中的序列通常是离散的,并在整数或其子集上变化。在日的股 2025-01-20 DL #DL #神经网络 #RNN
神经网络(四)——更多CNN 一、深度卷积神经网络(AlexNet) AlexNet和LeNet的架构非常相似,这里是一个稍微精简版本的AlexNet。 从LeNet(左)到AlexNet(右) AlexNet和LeNet的设计理念非常相似,但也存在显著差异。 AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。 AlexNet使用ReLU而不是si 2025-01-15 DL #DL #神经网络 #CNN
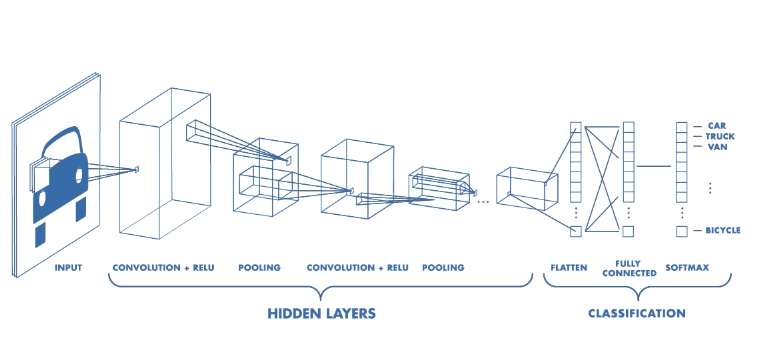
神经网络(三)——卷积神经网络(Convolutional Neural Network) 卷积神经网络(Convolutional Neural Network, CNN)是一种专门用于处理具有网格状拓扑数据(如图像)的深度学习模型。CNN在计算机视觉领域表现卓越,广泛应用于图像分类、对象检测、图像分割等任务。 输入层:接收原始图像数据,通常为三维数组(宽度、高度、通道数)。 卷积层:对输入图像进行卷积操作,生成特征图。 激活函数:对卷积结果应用激活函数,如ReLU。 池化层:对特征 2025-01-10 DL #DL #神经网络 #CNN
神经网络(一)——线性神经网络 神经网络(Neural Network)是一种模仿人脑神经系统的计算模型,广泛应用于人工智能(AI)和机器学习领域。它的核心思想是通过多个简单的计算单元(神经元)之间的连接和权重调整,来处理和学习复杂的任务。 一、线性神经网络 尽管神经网络涵盖了更多更为丰富的模型,但是依然可以用描述神经网络的方式来描述线性模型, 从而把线性模型看作一个神经网络。线性回归是一个单层神经网络。 如图所示的神经网络中 2024-12-30 DL #DL #神经网络
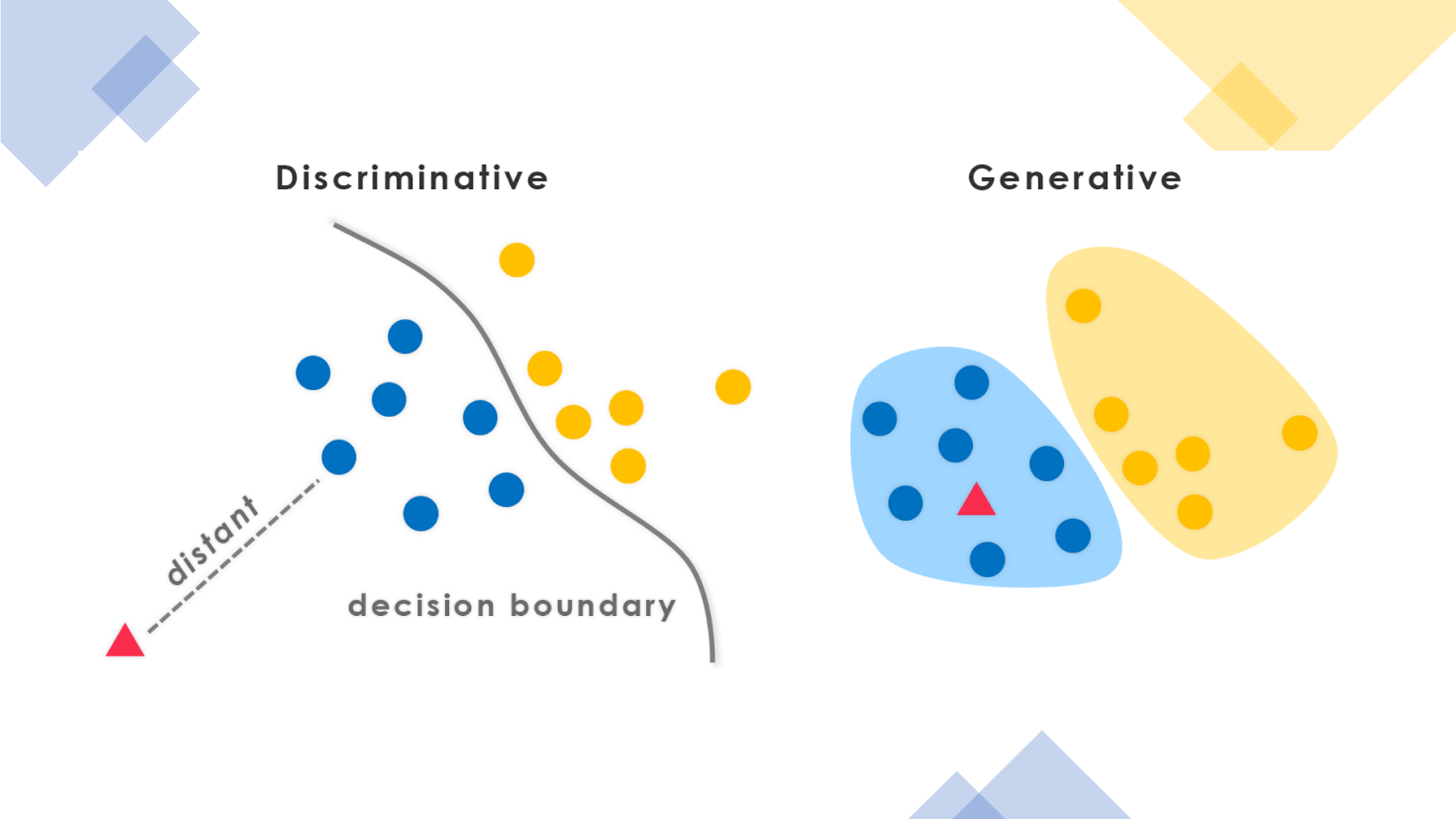
Generative Model 一、简介 生成式模型是指无监督和半监督的机器学习算法,使计算机能够使用文本、音频和视频文件、图像甚至代码等现有内容来创建新的可能内容。生成式模型主要功能是理解并捕获给定数据集中的潜在模式或分布。一旦学习了这些模式,模型就可以生成与原始数据集具有相似特征的新数据。 1.1 判别式模型 vs. 生成式模型 判别式模型 学习策略函数Y=f(X)或者条件概率P(Y|X) 不能反映训练数据本身的特性 学 2024-12-23 Generative Model #LLM #Generative Model
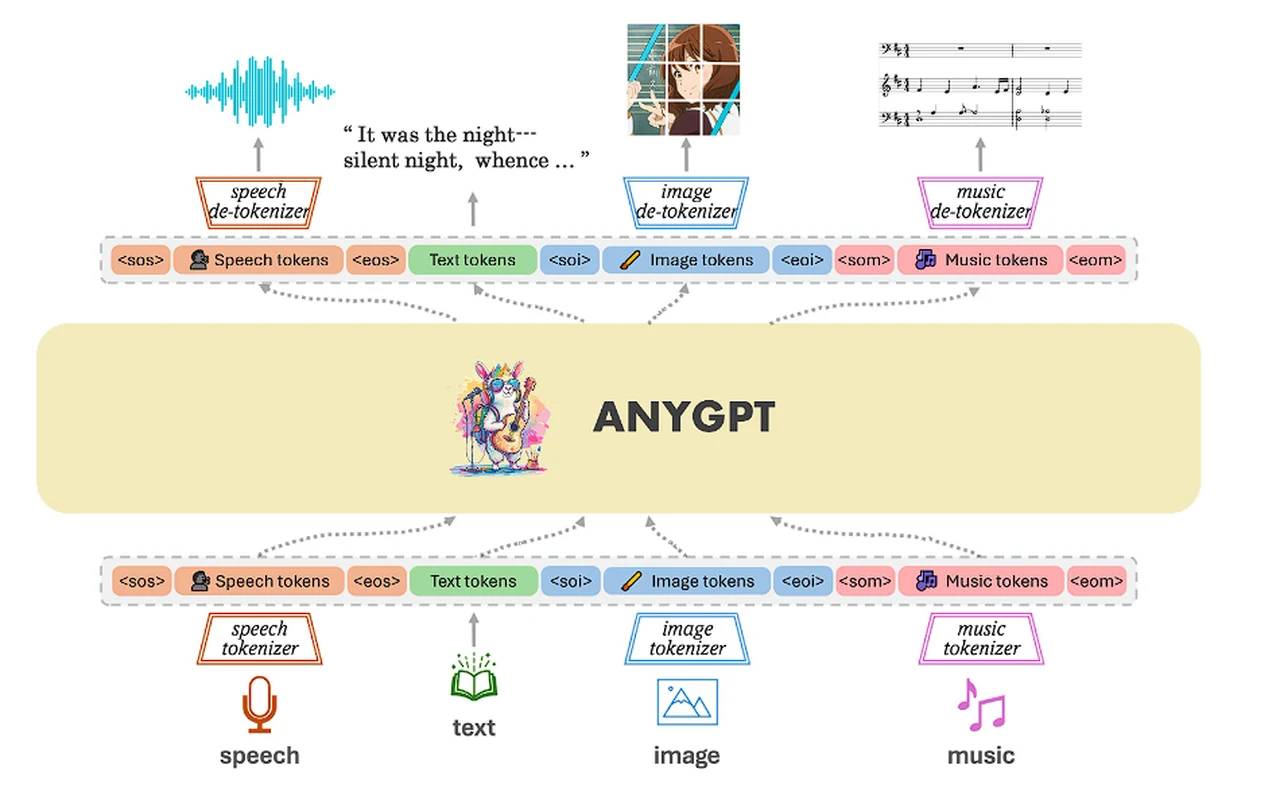
多模态大型语言模型(MLLM) 一、简介 模态的定义:模态(modal)是事情经历和发生的方式,我们生活在一个由多种模态(Multimodal)信息构成的世界,包括视觉信息、听觉信息、文本信息、嗅觉信息等等。 MLLMs 的定义:由LLM扩展而来的具有接收与推理多模态信息能力的模型。 多种模型概念: 单模态大模型 跨模态模型 多模态模型 多模态语言大模型 1.1 单模态大模型 单模态大模型是指模型输入和输出是同一种模态, 2024-12-17 LLM #LLM #MLLM
DeepSpeed DeepSpeed是一个深度学习优化软件套件,使分布式训练和推理变得简单、高效和有效。它可以做训练/推理具有数十亿或数万亿参数的密集或稀疏模型;实现出色的系统吞吐量并有效扩展到数千个GPU;在资源受限的GPU系统上进行训练/推理;实现前所未有的低延迟和高吞吐量的推理;以低成本实现极限压缩,实现无与伦比的推理延迟和模型尺寸减小。 一、DeepSpeed简介 DeepSpeed四大创新支柱 D 2024-12-10 LLM #LLM #DeepSpeed
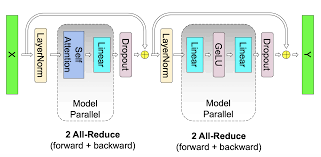
Megatron-LM 一、 通讯原语操作 NCCL 英伟达集合通信库,是一个专用于多个 GPU 乃至多个节点间通信的实现。它专为英伟达的计算卡和网络优化,能带来更低的延迟和更高的带宽。 Broadcast Broadcast代表广播行为,执行Broadcast时,数据从主节点0广播至其他各个指定的节点(0~3) 广播操作:所有rank都从“root”rank接收数据 Scatter Scatter与Broadca 2024-12-03 LLM #LLM #Megatron-LM
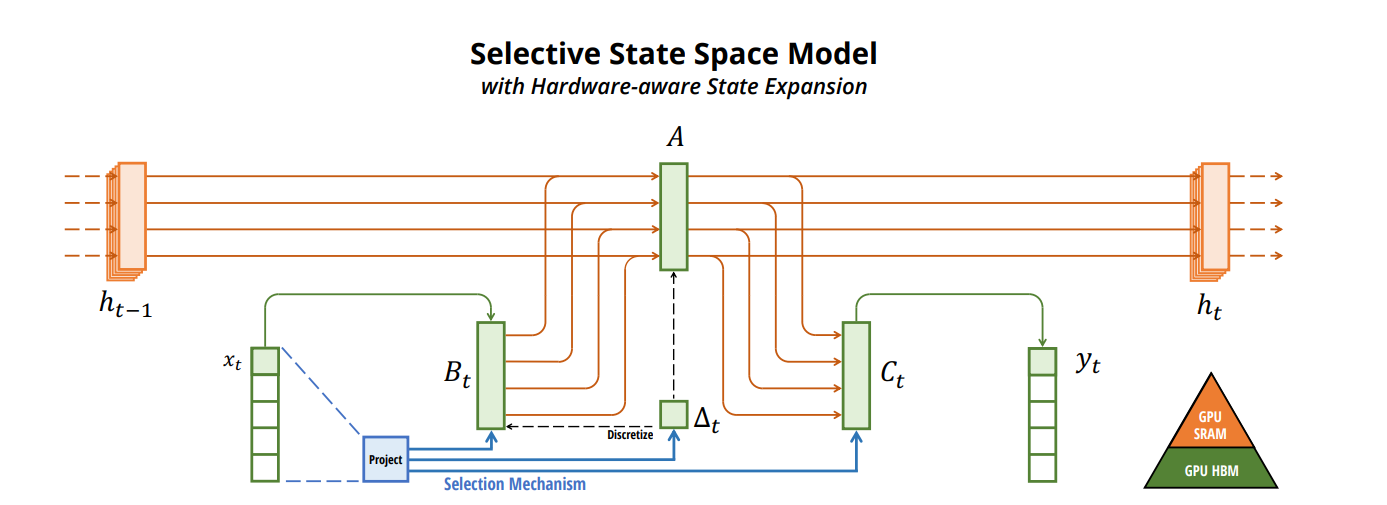
LLM(十一)——Mamba 一、SSM(State Space Model) 1.1 State Space 下图中每个小框代表迷宫中的一个位置,并有某些隐式的信息,例如你距离出口有多远: 而上述迷宫可以简化建模为一个“状态空间表示state space representation”,每一个小框显示: 当前所在位置(当前状态Current State) 下一步可以前往哪里(未来可能的状态Possible Future 2024-11-28 LLM #LLM #Mamba
神经网络(二)——多层感知机(Multilayer Perceptron) 在现实世界中有很多数据无法通过线性变换来表示,可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型。最简单的方法是将许多全连接层堆叠在一起,每一层都输出到上面的层,直到生成最后的输出。可以把前层看作表示,把最后一层看作线性预测器。这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。一个单隐藏层的多层感知机,具有5个隐藏单 2024-11-24 DL #DL #神经网络 #MLP
LLM(十)——Infini Transformer Infini-attention不同于过去的Attention机制,每次在处理一个新的输入时都会重新计算整个序列的 Attention 权重,也就代表会将过去的 K, V 都丢弃。 而 infini-attention 则是将 K, V 都保存在压缩记忆体里面,这样可以有两个优点: 处理较长(甚至无限)的文本、上下文比较有帮助 可以减少复杂度。因为不需要一直重复计算,可以提升效率、减少计算资源 2024-11-22 LLM #LLM #Infini_Transformer
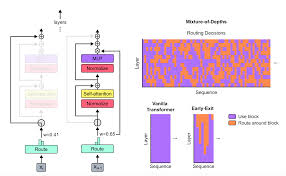
LLM(九)——Mixture-of-Depths Transformers 一、Mixture-of-Depths Transformers MoD(Mixture-of-Depths)采用的技术类似于混合专家(Mixture of Experts,MoE) transformer,其中动态token级路由决策是在整个网络深度上做出的。然而,与 MoE 的想法不同,MoD要么将计算应用于像标准transformer那样的token,要么通过残差连接(Residual Co 2024-11-15 LLM #LLM #MoD
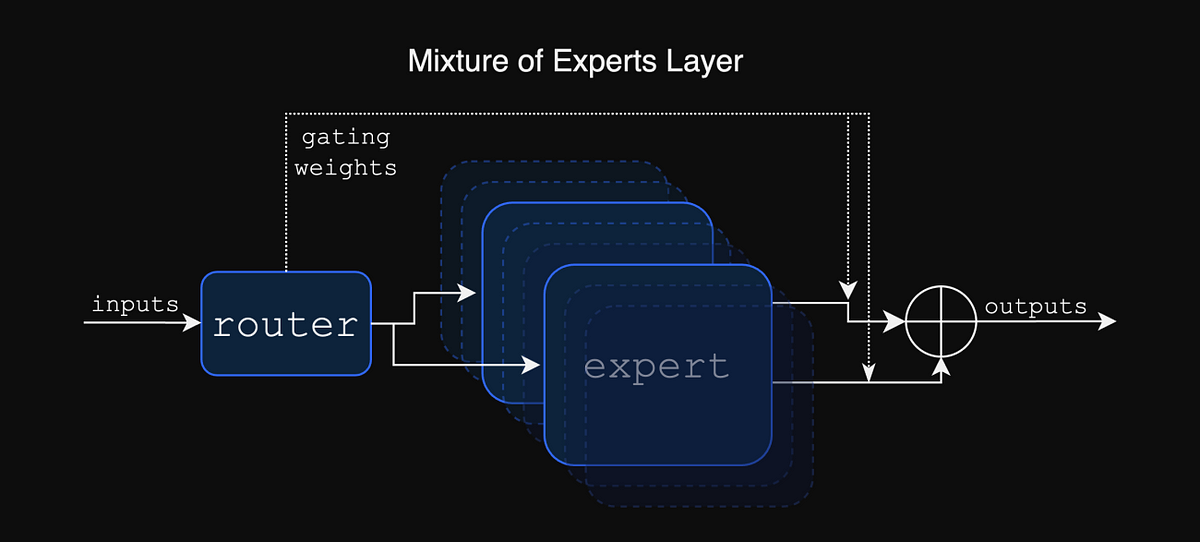
LLM(八)——MoE 一、混合专家模型(Mixtral of Experts) 在 Transformer 模型的背景下,MoE 主要由两个部分组成: 稀疏 MoE 层 代替了传统的密集前馈网络 (FFN) 层。MoE 层包含若干“专家”(如 8 个),每个专家都是一个独立的神经网络。实际上,这些专家通常是 FFN,但它们也可以是更复杂的网络,甚至可以是 MoE 本身,形成一个层级结构的 MoE。 一个门控网络或路由 2024-11-07 LLM #LLM #MoE
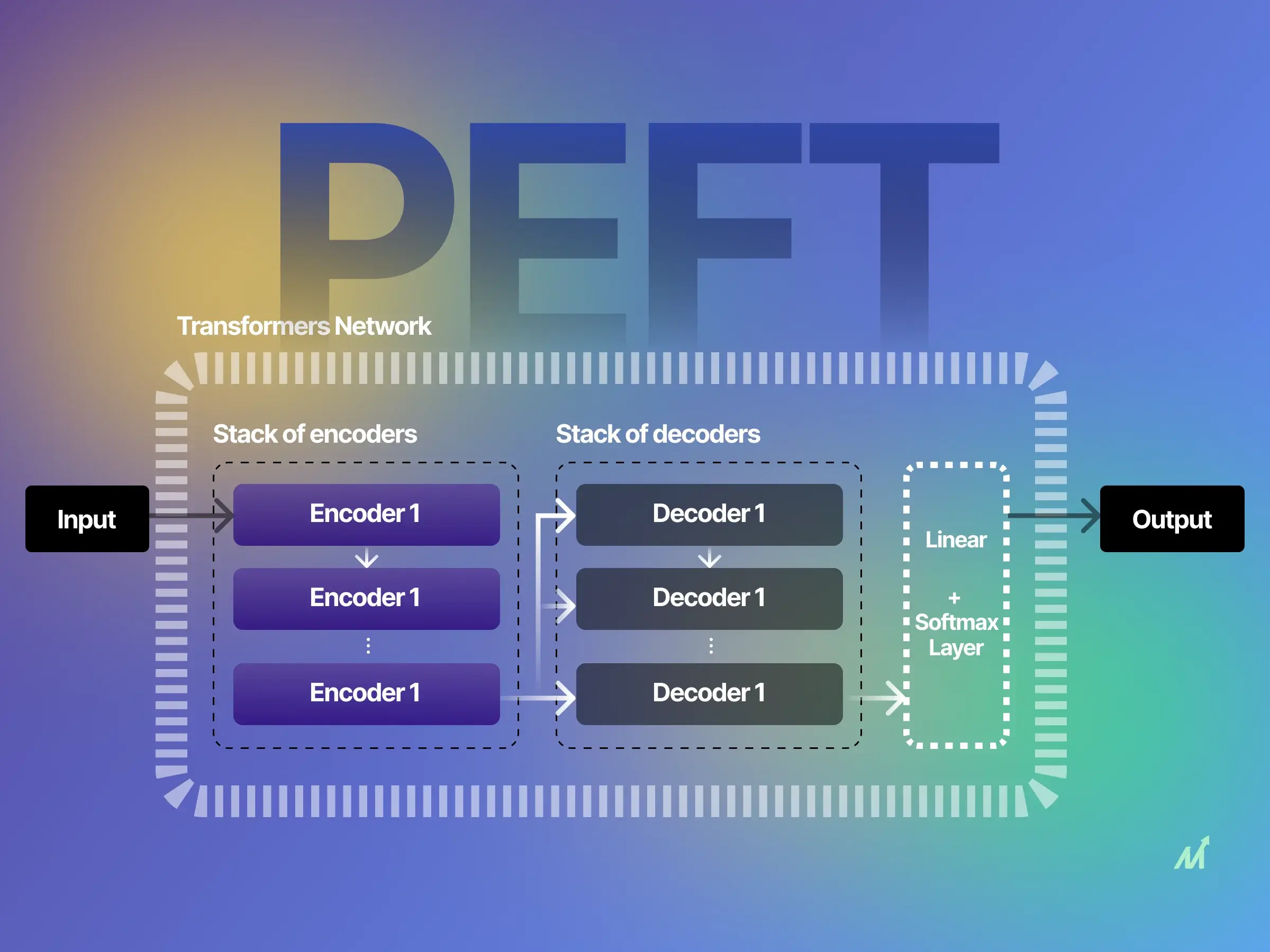
LLM(七)——参数高效微调(Parameter-efficient fine-tuning,PEFT) 随着模型变得越来越大,在消费级硬件上对模型进行全部参数的微调变得不可行。此外,为每个下游任务独立存储和部署微调模型变得非常昂贵,因为微调模型与原始预训练模型的大小相同。参数高效微调(PEFT) 方法旨在解决这两个问题!PEFT 方法使您能够获得与全参数微调相当的性能,同时只有少量可训练参数。 一、PEFT类型 Additive methods Additive methods的主要思想是通过添加 2024-11-02 LLM #LLM #PEFT #Fine-tuning
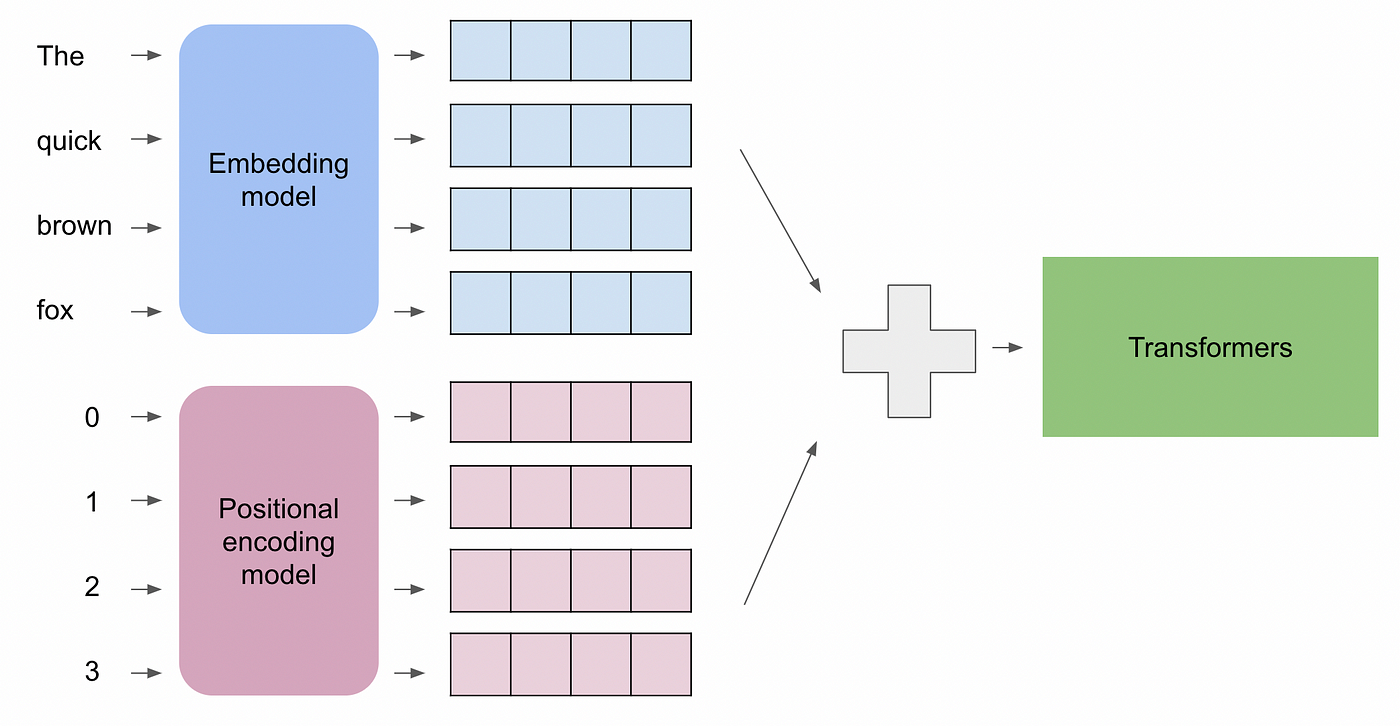
LLM(六)——Position Encoding RNN的结构包含了序列的时序信息,而Transformer却完全把时序信息给丢掉了,比如“狗咬我”,和“我咬狗”,两者的意思千差万别,故为了解决时序的问题,Transformer的作者用了一个绝妙的办法:位置编码(Positional Encoding) 一、绝对位置编码(Absolute Positional Encoding) 1.1 简介 将每个位置编号,从而每个编号对应一个向量,最终通过结 2024-10-27 LLM #LLM #Position Encoding
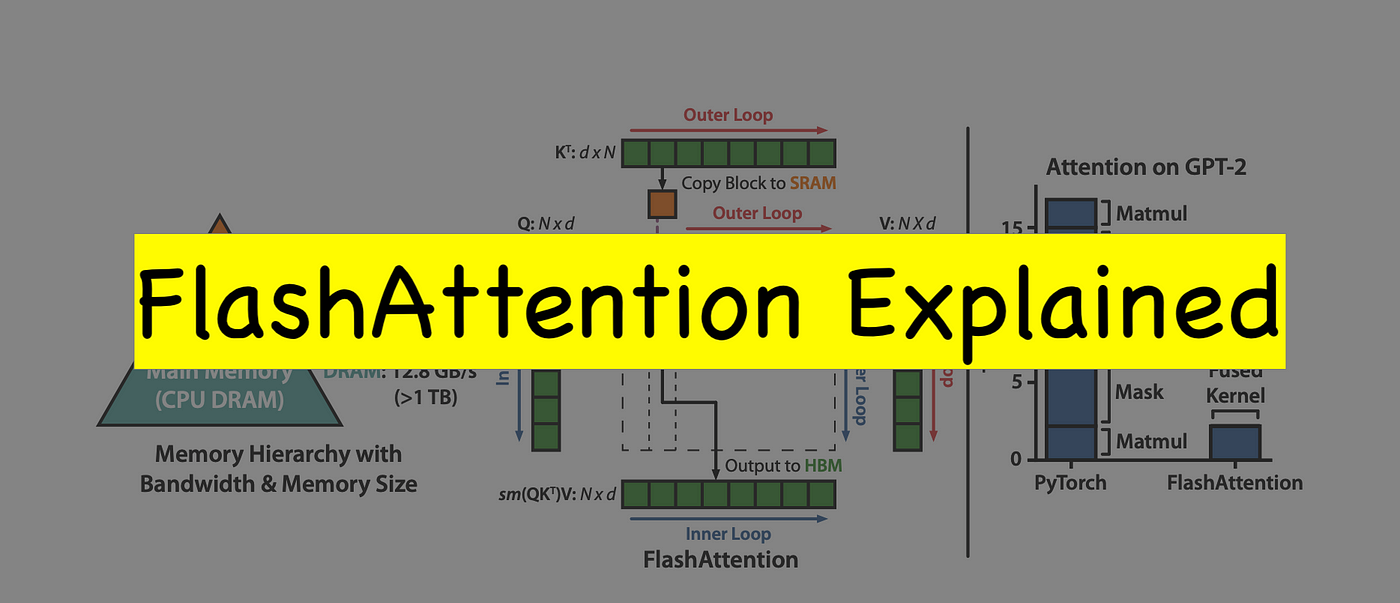
LLM(五)——Hardware Optimization Attention 一、PagedAttention vLLM发现LLM 服务的性能受到内存瓶颈的影响。在自回归 decoder 中,所有输入到 LLM 的 token 会产生注意力 key 和 value 的张量,这些张量保存在 GPU 显存中以生成下一个 token。这些缓存 key 和 value 的张量通常被称为 KV cache,其具有以下特点: 显存占用大:在 LLaMA-13B 中,缓存单个序列最多需 2024-10-20 LLM #LLM #Attention #PagedAttention #FlashAttention
LLM(四)——Attention变种 一、Multi-Query Attention(MQA) 多查询注意力(MQA)是多头注意力(MHA)算法的改进版本,它可以在不牺牲模型精度的情况下提高计算效率。在标准 MHA 中,单独的线性变换应用于每个注意力头的查询 (Q)、键 (K) 和值 (V)。 MQA 与此不同,它在所有头中使用一组共享的键 (K) 和值 (V),同时允许对每个查询 (Q) 进行单独的转换。 Multi-Query 2024-10-16 LLM #LLM #Attention
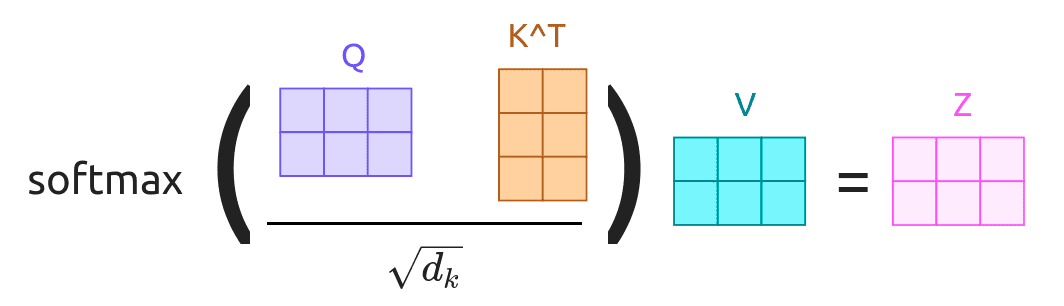
LLM(三)——Self-Attention、Multi-Head Attention和Transformer Self Attention就是Q、K、V均为同一个输入向量映射而来的Encoder-Decoder Attention,它可以无视词之间的距离直接计算依赖关系,能够学习一个句子的内部结构,实现也较为简单并且可以并行计算。 Multi-Head Attention同时计算多个Attention,并最终得到合并结果,通过计算多次来捕获不同子空间上的相关信息。 一、Self-Attention 首先, 2024-10-10 LLM #LLM #DL #Attention #Transformer
LLM(二)——Attention机制 Attention 机制很像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。我们的视觉系统就是一种 Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。 seq2seq 在seq2seq中,有一个Encoder和一个Decoder,Encoder和Decoder都是RNN。seq2seq的缺点在 2024-10-03 LLM #LLM #DL #Attention
LLM(一)——LLM简介 一、语言模型的发展历程 语言模型的发展历程从最初的简单统计模型到如今的复杂神经网络模型,经历了多个重要阶段。 1. 统计语言模型(Statistical Language Model, SLM) 统计语言模型使用马尔可夫假设(Markov Assumption)来建立语言序列的预测模型,通常是根据词序列中若干个连续的上下文单词来预测下一个词的出现概率,即根据一个固定长度的前缀来预测目标单词。具有 2024-09-27 LLM #LLM
LangGraph(七)——Code Generation 一、 LangGraph for Code Generation 1.1 动机 代码生成和分析是大型语言模型(LLMs)最重要的应用之一,这一点从GitHub Copilot这样的产品的普遍性以和GPT-engineer这样的项目的受欢迎程度就可见一斑。最近AlphaCodium的研究工作表明,通过使用流程范式而不是简单的prompt:answer,可以改进代码生成,答案可以通过迭代没(1)测试答 2024-09-21 LangGraph #LLM #LLM学习笔记 #Agent #LangGraph