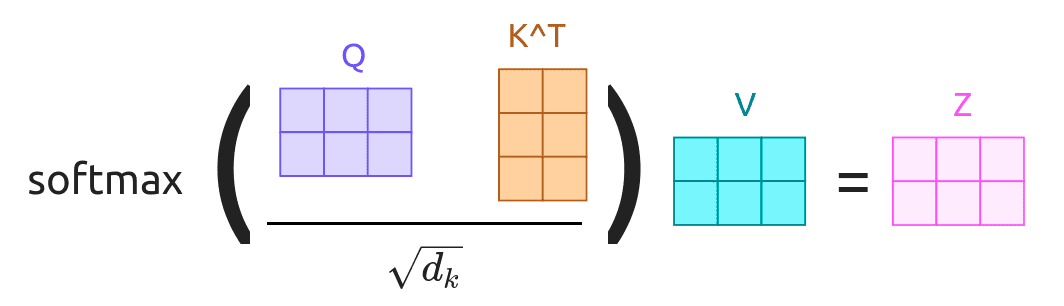
LLM(五)——Hardware Optimization Attention
一、PagedAttention vLLM发现LLM 服务的性能受到内存瓶颈的影响。在自回归 decoder 中,所有输入到 LLM 的 token 会产生注意力 key 和 value 的张量,这些张量保存在 GPU 显存中以生成下一个 token。这些缓存 key 和 value 的张量通常被称为 KV cache,其具有以下特点: 显存占用大:在 LLaMA-13B 中,缓存单个序列最多需