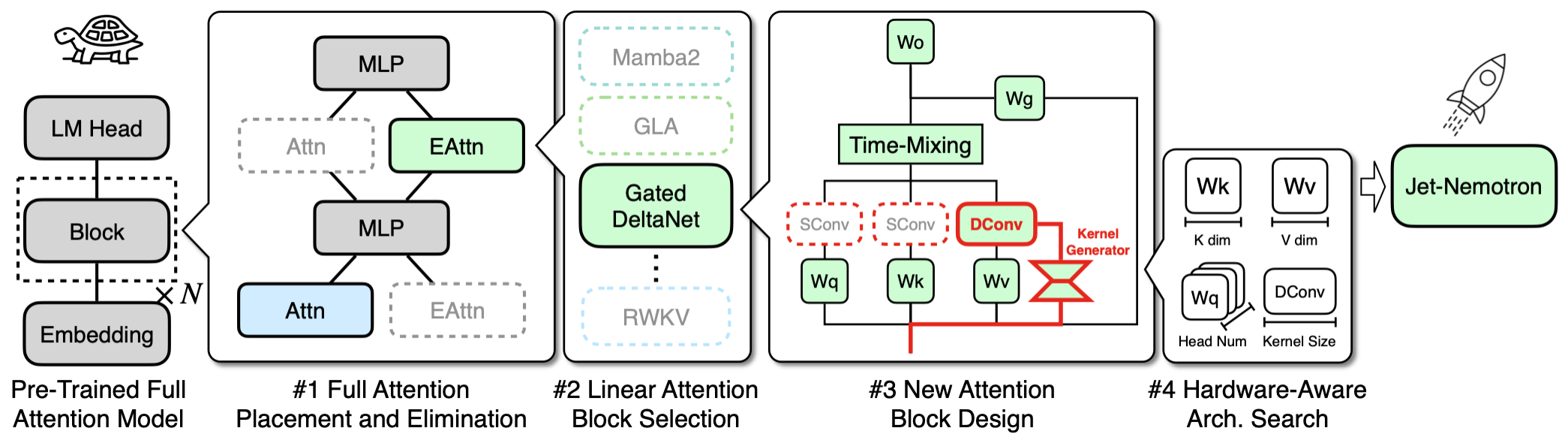
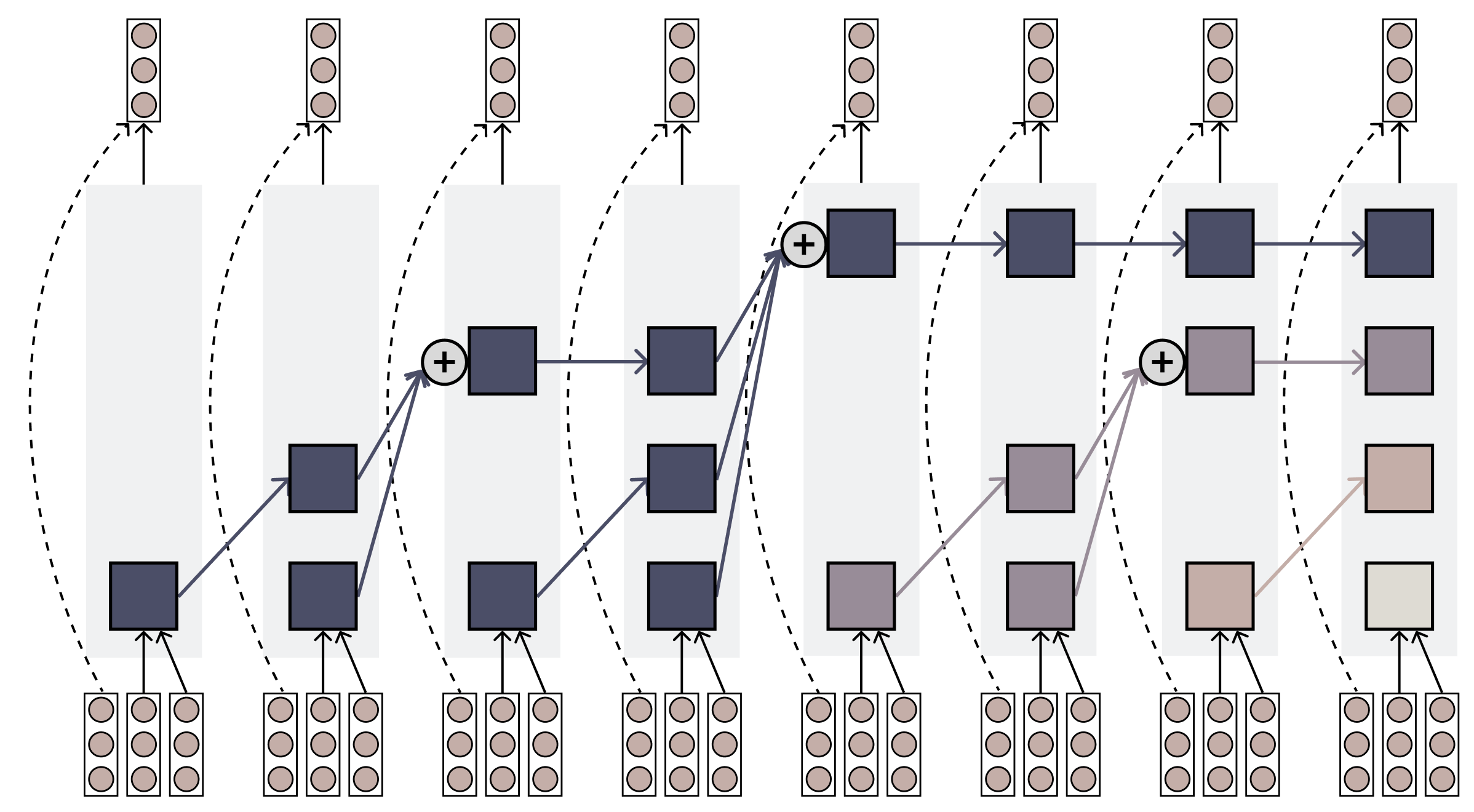
Jet-Nemotron:高效语言模型与后神经网络架构搜索 一、简介 英伟达发布了一个全新的混合架构语言模型系列,Jet-Nemotron。Jet-Nemotron系列有Jet-Nemotron-2B和Jet-Nemotron-4B大小。英伟达表示Jet-Nemotron系列「小模型」性能超越了Qwen3、Qwen2.5、Gemma3和 Llama3.2等当前最先进的开源全注意力语言模型。 同时实现了显著的效率提升,在H100 GPU上生成吞吐量最高可提 2025-09-30 LLM > PostNAS > JetBlock #LLM #PostNAS #JetBlock
AlphaEvolve:超级编码智能体 一、简介 AlphaEvolve,它是一种进化编码 Agent ,可大幅提升最先进的 LLM 在高难度任务(如解决开放科学问题或优化计算基础设施的关键部分)上的能力。AlphaEvolve 负责协调 LLM 的自主流水线,其任务是通过直接修改代码来改进算法。AlphaEvolve 采用进化方法,不断接收来自一个或多个评估者的反馈,迭代改进算法,从而可能带来新的科学和实践发现。我们将这种方法应用于一 2025-09-21 LLM > Agent #LLM #Agent
Matrix-Game 2.0:交互世界模型 一、简介 世界模型(World Model)是AI领域的一个宏大目标,旨在创建能够模拟人们世界运行规律的计算模型。近年来,基于扩散模型的视频生成技术展示了其作为世界模型的巨大潜力,它们能够捕捉复杂的物理动态和交互行为。 最近DeepMind 发布的 Genie 3,Dynamics也推出了Mirage 2世界模型: Genie 3 Genie 3 是由 Google DeepMind 开发的先进 2025-09-12 World Models > Matrix-Game #World Models #Matrix-Game
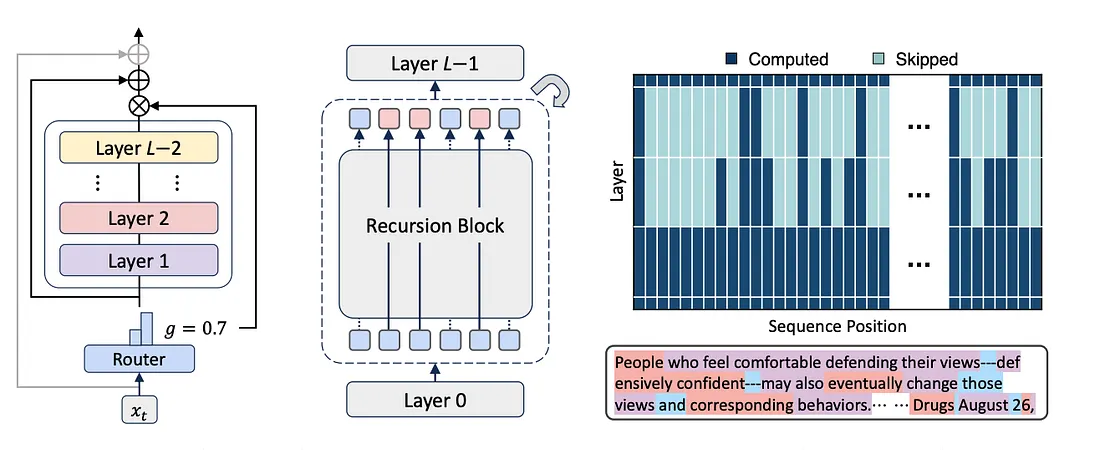
Mixture-of-Recursions:混合递归模型,通过学习动态递归深度,以实现对自适应Token级计算的有效适配 一、背景 Transformer 架构的问题: 对所有token进行统一计算(Uniform compute for all tokens):每个token,无论多么简单或复杂,都要经过整个堆栈层 - 导致简单token的计算浪费,而较难token的利用率不足。 参数数量过多(Excessive parameter count):Transformer 为每一层分配单独的权重,导致模型规模过大 2025-09-02 LLM > MoR #LLM #MoR
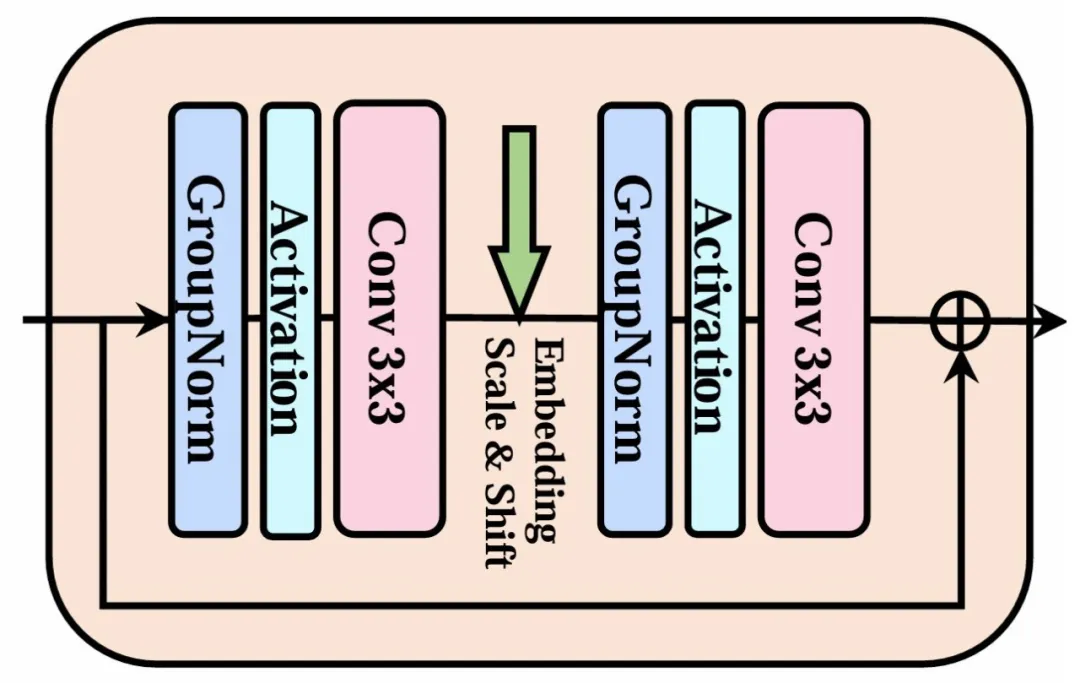
DiC:重新思考扩散模型中的 3×3 卷积 一、背景 扩散模型现状: 主流架构从CNN-注意力混合(如U-Net)转向纯Transformer(如DiT、U-ViT),生成质量优异但推理速度慢(自注意力计算开销大)。 加速尝试(如高效注意力、SSM架构)效果有限,难以满足实时需求。 卷积的潜力: Conv3x3是硬件友好的极速操作(支持Winograd加速),但传统设计在扩散模型中性能不足(感受野有限,扩展性差)。 构建 3x3 2025-08-24 Diffusion Model > CNN #Diffusion Model #DiC
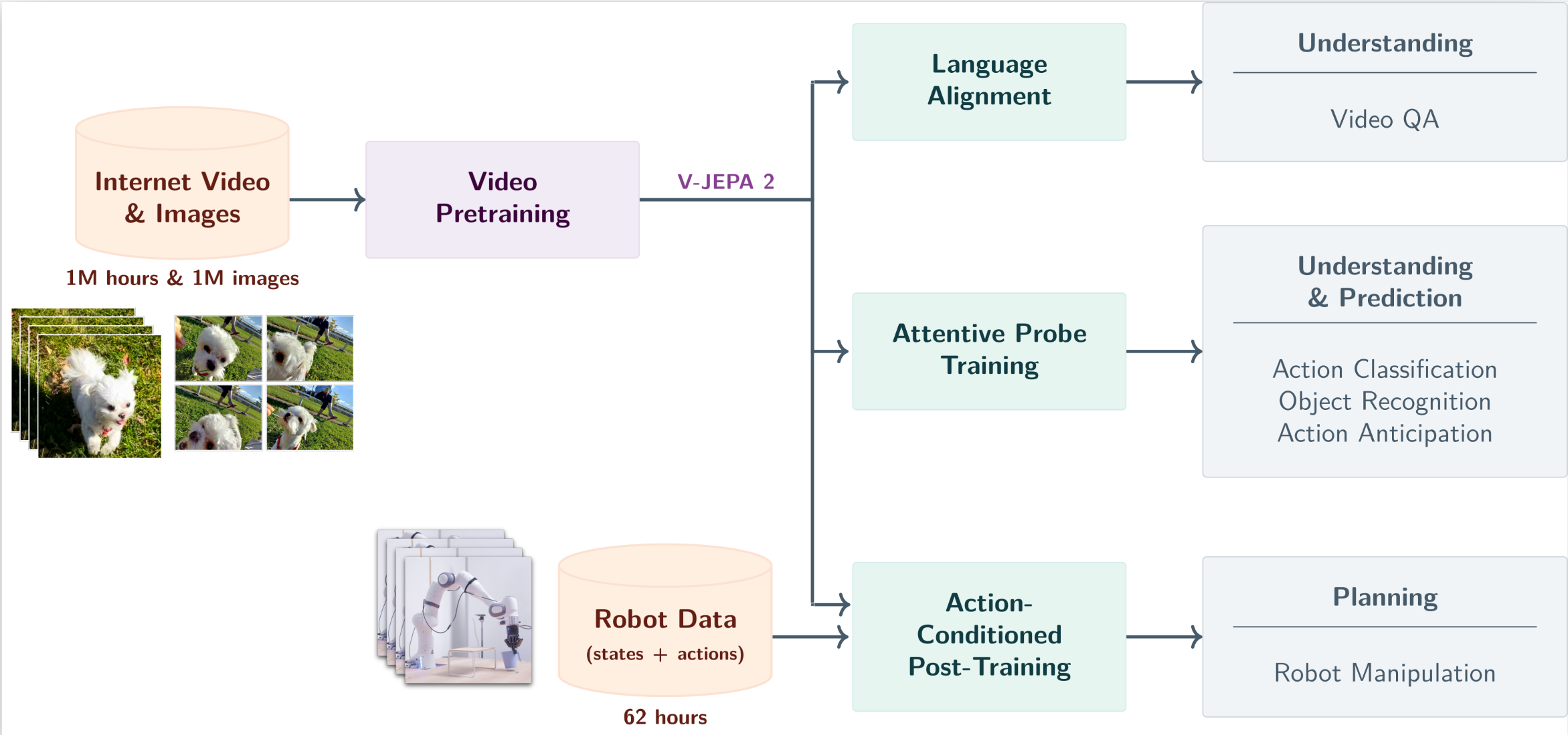
Meta世界模型 V-JEPA 2 一、简介 Meta开源发布V-JEPA 2世界模型:一个能像人类一样理解物理世界的AI模型。世界模型简单说,就是能够对真实物理世界做出反应的AI模型。它应该具备以下几种能力: 理解:世界模型应该能够理解世界的观察,包括识别视频中物体、动作和运动等事物。 预测:一个世界模型应该能够预测世界将如何演变,以及如果智能体采取行动,世界将如何变化。 规划:基于预测能力,世界模型应能用于规划实现给定目标的行 2025-08-16 World Model #World Model
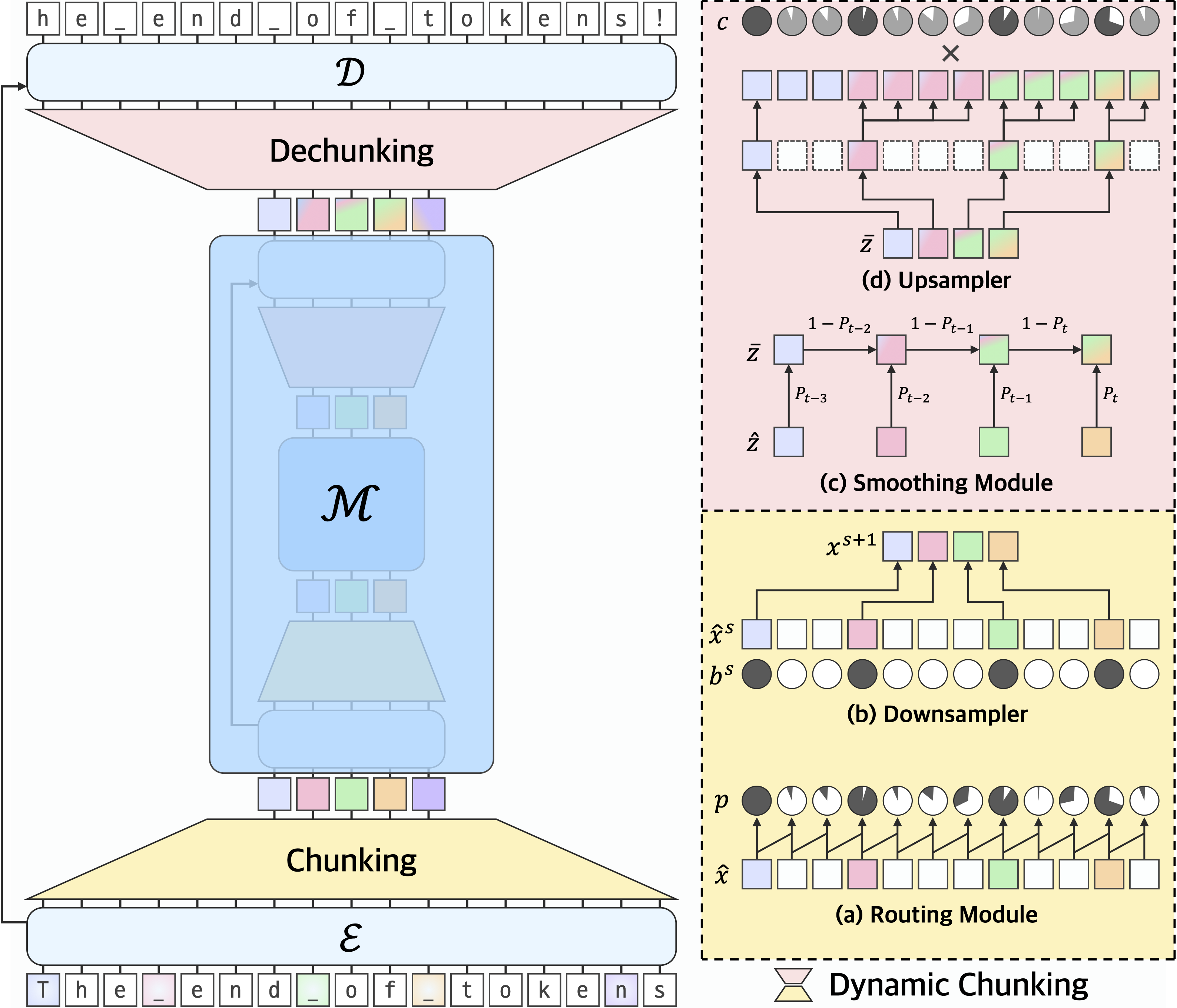
H-Net与动态分块技术 一、简介 当我们阅读文本时,大脑会毫不费力地将字母组合成单词,再将单词组合成有意义的短语。我们不会刻意去思考一个单词在哪里结束,另一个单词在哪里开始,一切自然而然地发生了。然而,事实证明,在人工智能中复制这种自然能力是自然语言处理领域最持久的挑战之一。 几十年来,AI 系统一直依赖于一种名为tokenization的预处理步骤,将文本分解成易于管理的块。目前主流的方法是Byte-Pair Enco 2025-08-07 LLM > H-Net #LLM #H-Net
Muon An optimizer for hidden layers in neural networks 一、引言 在深度学习领域,优化算法对模型训练效率和性能起着关键作用。从经典的随机梯度下降 (SGD) 及其动量法,到自适应优化方法 Adam/AdamW 等,一系列优化器大大加速了神经网络的收敛。 Muon (Momentum Orthogonalized by Newton-Schulz):一种新的神经网络优化器。Muon 因其出色的实用性能而备受关注:它曾创下 NanoGPT 的速度纪录。Mu 2025-07-25 LLM > Optimizer #LLM #Optimizer
Log Linear Attention 一、简介 《对数线性注意力》(Log-Linear Attention)尝试在传统注意力和线性注意力机制的复杂度和表达力间取得一个平衡,作者中的 Tri Dao 也是 Mamba 和 FlashAttention 的作者之一。 1.1 引言与动机 现有方法的困境: 标准Softmax注意力:虽然表达能力强,但其计算复杂度为 (T为序列长度),内存复杂度为 ,这使其在处理长序列时成本高昂,成为一 2025-07-16 LLM > Attention #LLM #Attention
Boltzmann Machines 一、Boltzmann Machines发展历程 1.1 霍普菲尔德网络(Hopfield Network) 从一个简单的二进制神经元网络入手,介绍了「霍普菲尔德网络」的核心思想。每个神经元只有1或0两种状态,最重要的是,神经元之间通过对称加权连接。 整个神经网络的全局状态,被称为一个「配置」(configuration),并有一个「优度」(goodness)。其「优度」是由所有活跃神经元之间权 2025-07-08 NN > Boltzmann Machines #NN #Boltzmann Machines
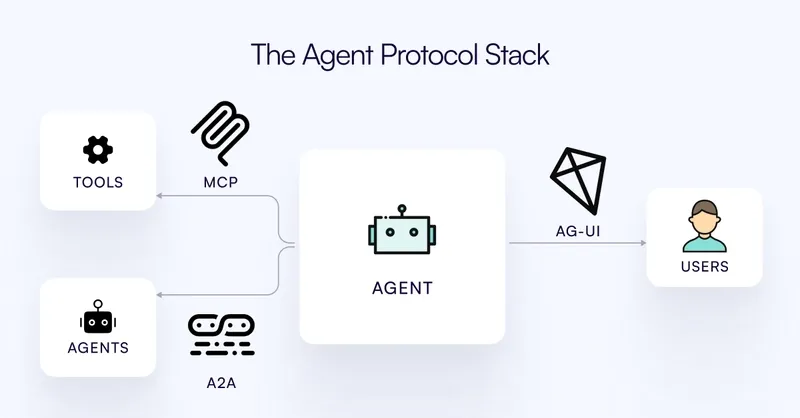
Function Calling vs. MCP vs. A2A vs. AG-UI 一、Function Calling 传统的函数调用方式,通过预定义接口传递参数并获取返回值,适用于结构化、明确的输入输出场景。例如:调用数学计算函数 sum(a, b),返回 a + b 的结果。 应用场景 计算服务:calculate_distance(lat1, lon1, lat2, lon2)。 数据库查询:get_user_profile(user_id)。 第三方API集成:调用支 2025-06-30 LLM > MCP #MCP #A2A #AG-UI
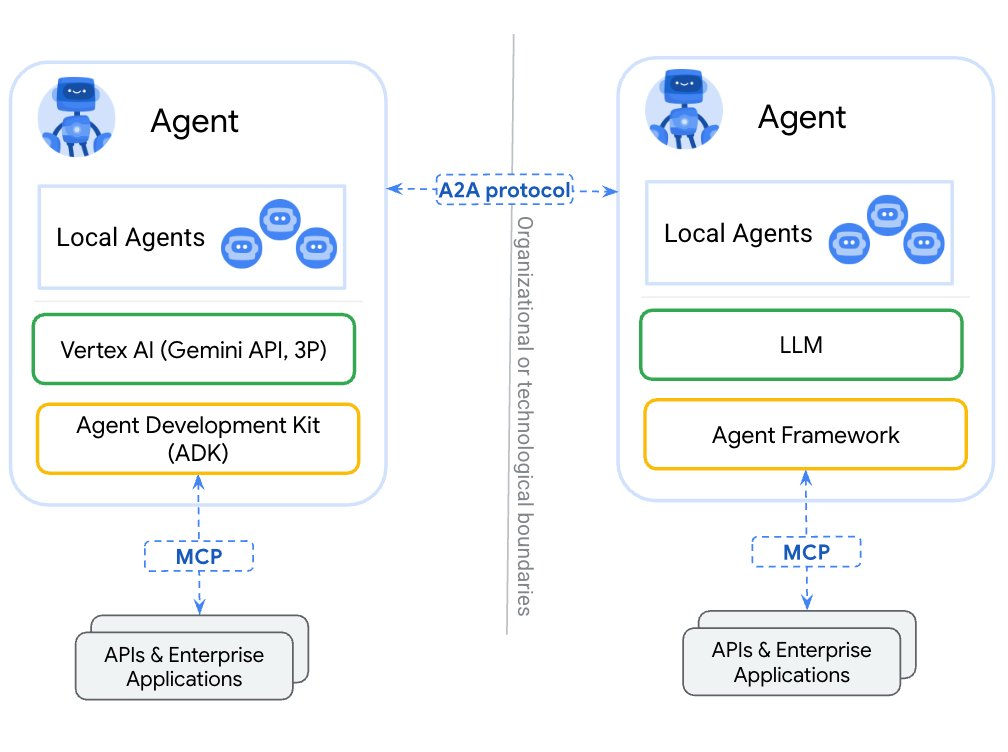
A2A 谷歌在25年4月初发布了A2A协议,作为MCP协议的补充。Agent2Agent协议致力于促进独立agent间的通信,帮助不同生态系统的agent沟通和协作。 一、核心概念 Agent Card:一个公共元数据文件(通常位于 /.well-known/agent.json),用于描述Agent的能力、技能、端点 URL 以及认证要求。客户端通过它来发现Agent。 Agent Card通常包括 2025-06-23 LLM > A2A #A2A
MCP 2024年11月份,claude推出了模型上下文协议( MCP),作为一种潜在的解决方案,解决大模型和其他工具交互。作为大模型与其他工具交互的协议,MCP这几个月也在在开发人员和 AI 社区中获得了巨大的关注。 一、MCP 原理 提出背景:随着基座大模型变得更加智能,agent与外部工具、数据和 API 交互的能力变得越来越分散:开发人员需要为agent运行和集成的每个系统实现具有特殊业务逻辑 2025-06-16 LLM > MCP #MCP
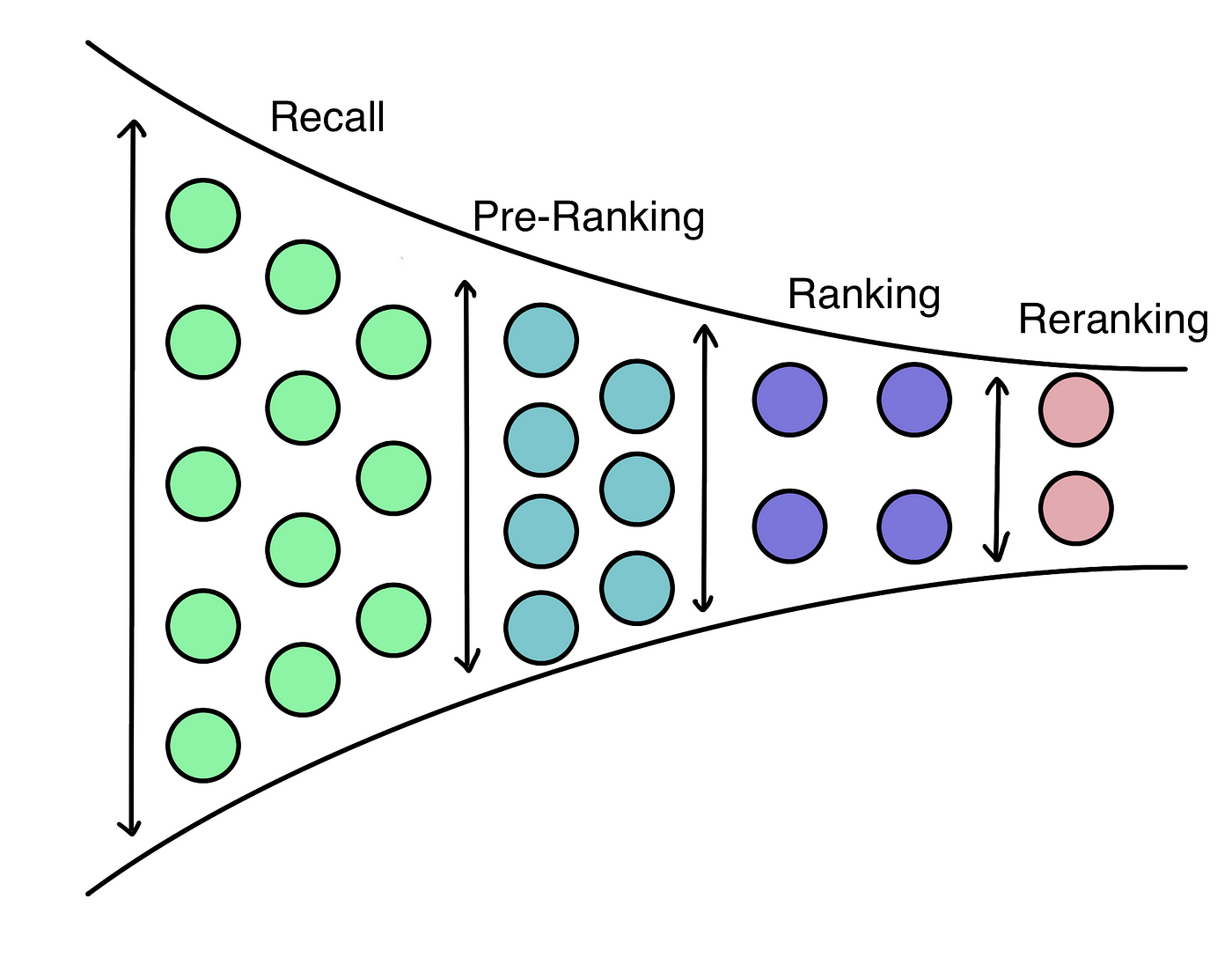
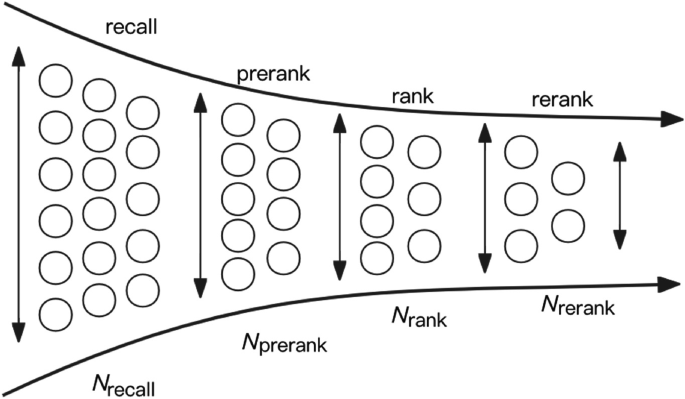
重排:多样性算法 一、推荐系统中的多样性 如果多样性做得好,可以显著提升推荐系统的核心业务指标。 1.1 物品相似性的度量 基于物品属性标签。 类⽬、品牌、关键词…… 基于物品向量表征。 ⽤召回的双塔模型学到的物品向量(不好)。 基于内容的向量表征(好)。 基于物品属性标签 物品属性标签:类⽬、品牌、关键词…… 根据⼀级类⽬、⼆级类⽬、品牌计算相似度。 物品:美妆、彩妆、⾹奈⼉。 物品:美妆、⾹⽔、 2025-06-10 推荐算法 > ReRank #推荐算法 #ReRank #MMR #DPP
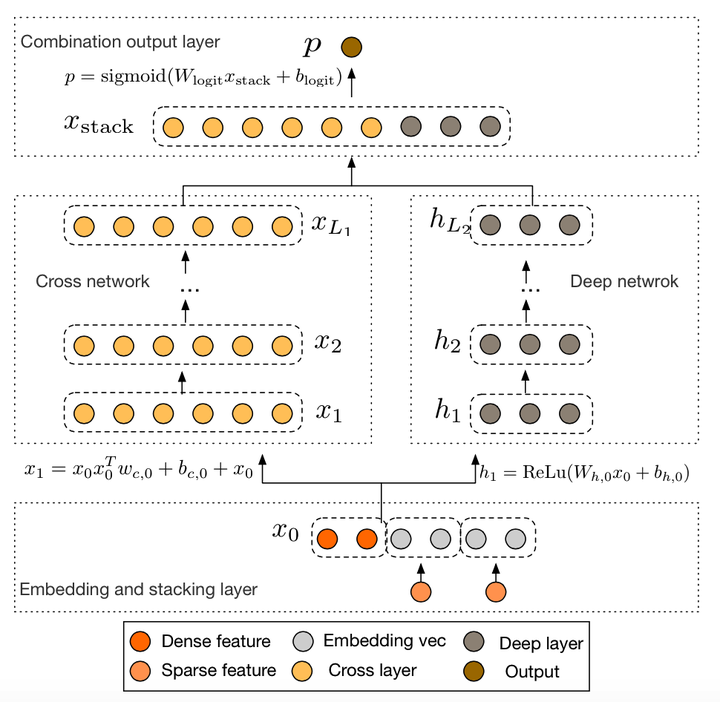
特征交叉 一、Factorized Machine (FM) 1.1 线性模型 有个特征,记作 线性模型: 模型有 个参数: 和 预测是特征的加权和。(只有加,没有乘。) 1.2 二阶交叉特征 线性模型+⼆阶交叉特征: 如果很大参数量就会很大,可以用以下方式减少参数数量 Factorized Machine (FM): FM模型有个参数。 Factorized Machi 2025-06-04 推荐算法 > 特征交叉 #推荐算法 #特征交叉
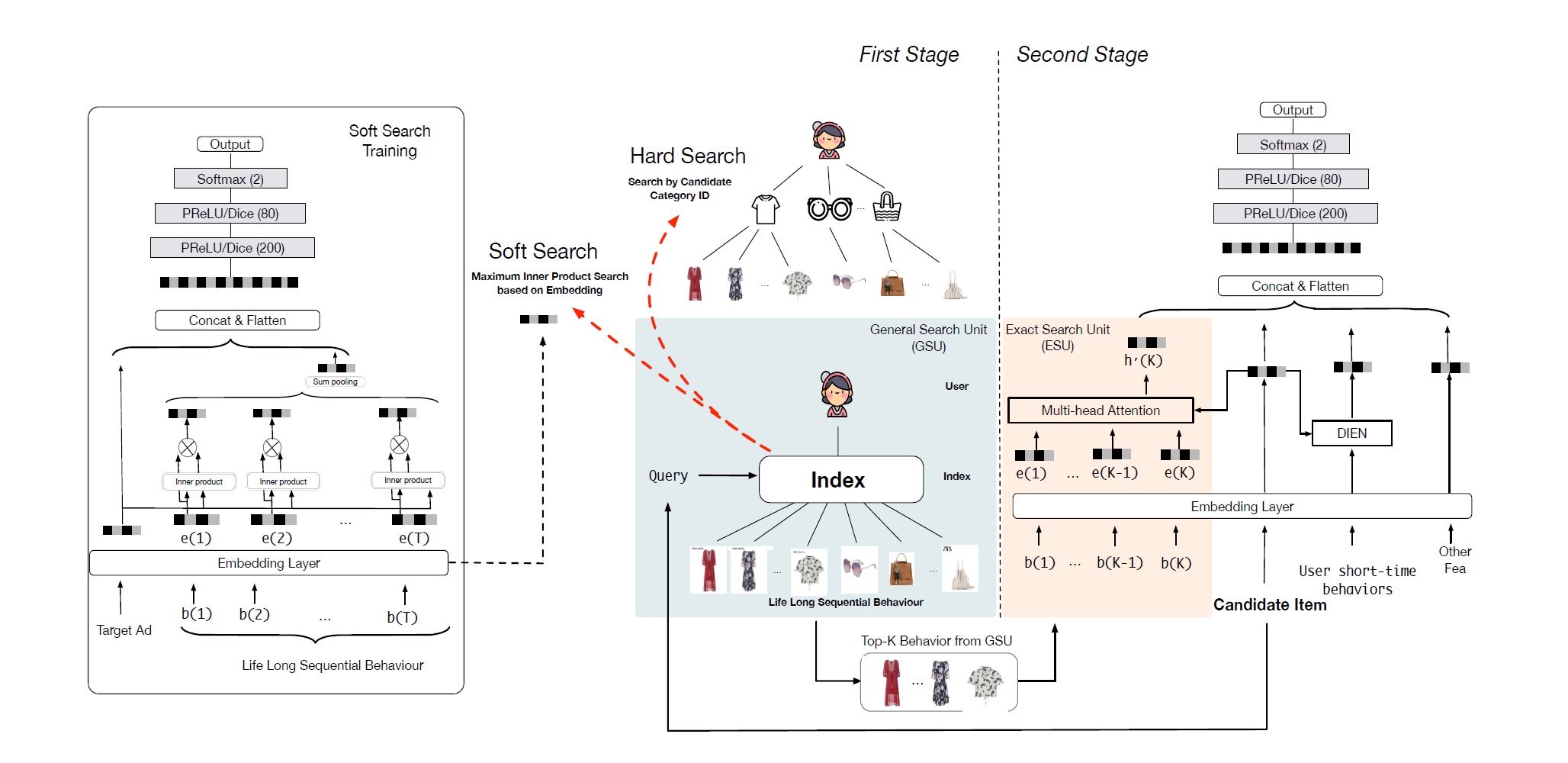
行为序列 一、用户行为序列建模 用户最近 n 次点击、点赞、收藏、转发等行为都是推荐系统中重要的特征,可以帮助召回和排序变得更精准。这节课介绍最简单的方法——对用户行为取简单的平均,作为特征输入召回、排序模型。 用户的LastN行为序列可以反映出用户对什么样的物品感兴趣,召回的双塔模型、粗排的三塔模型、还有精排模型都可以用LastN特征。LastN特征很有效,把它用到召回和排序模型中,所有指标都会大涨。 简 2025-05-28 推荐算法 > DIN > SIM #推荐算法 #DIN #SIM
排序模型 排序的目标是根据业务目标来不断变化的,最早期,业务目标简单,需要聚焦的时候,往往会选取⼀个指标来重点优化,当做到中期的时候,就会发现单⼀指标对整体的提升已经非常有限了,或者说会出现很多问题,这个时候,往往就会引入多目标排序来解决这些问题。 排序的依据 排序模型预估点击率、点赞率、收藏率、转发率等多种分数。 融合这些预估分数。(⽐如加权和。) 根据融合的分数做排序、截断。 一、多目标模型 1.1 2025-05-20 推荐算法 > Rank #推荐算法 #Rank
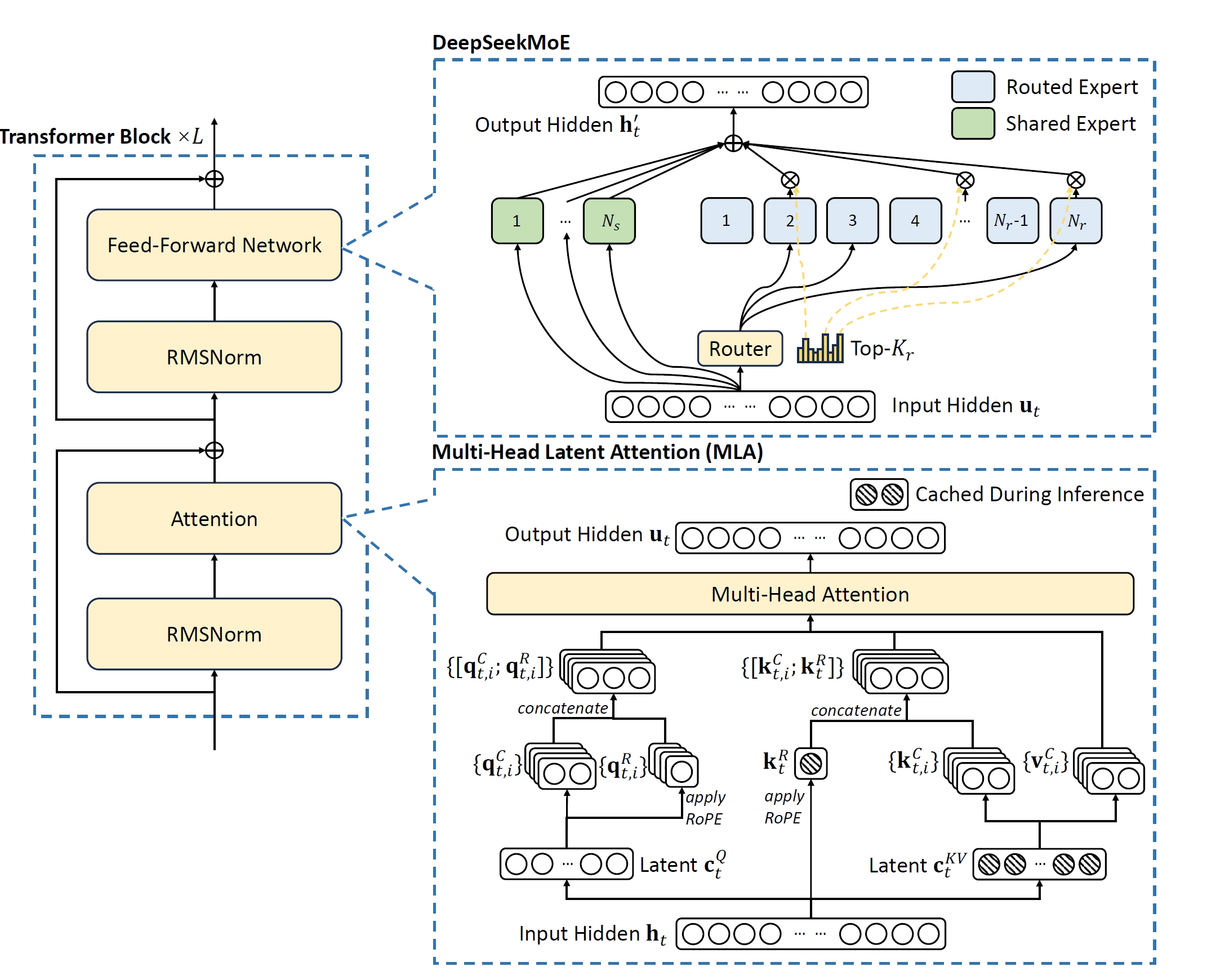
DeepSeek V3 DeepSeek-V3 是一款性能卓越的混合专家(MoE)语言模型,整体参数规模达到 671B,其中每个 token 激活的参数量为 37B。 基于提升性能和降低成本的双重目标,在架构设计方面,DeepSeek-V3 采用了MLA来确保推理效率,并使用 DeepSeekMoE来实现经济高效的训练。这两种架构在 DeepSeek-V2 中已经得到验证,证实了它们能够在保持模型性能的同时实现高效的训练 2025-05-13 LLM #LLM #DeepSeek
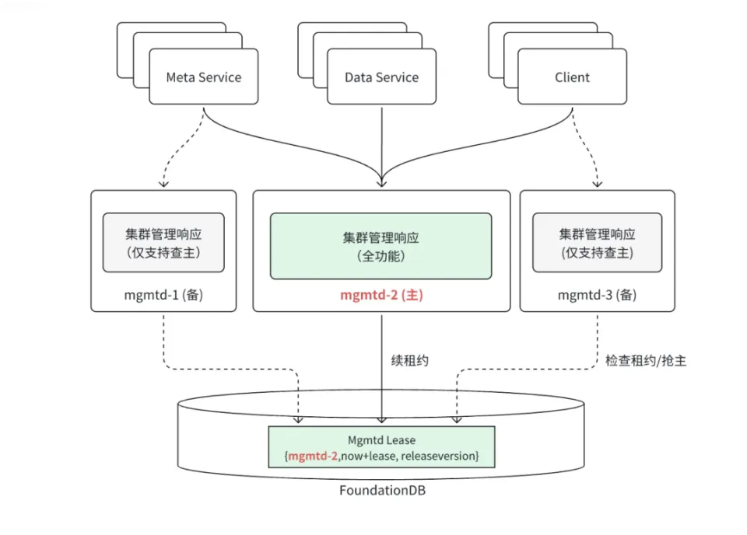
DeepSeek 3FS & Smallpond 一、3FS & Smallpond 概述 Fire-Flyer File System(3FS) 是一个高性能分布式文件系统,旨在解决人工智能训练和推理工作负载的挑战。它利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络,提供一个共享存储层,从而简化分布式应用程序的开发。 Smallpond 基于 3FS 和 DuckDB 构建,专注于 PB 级数据的快速处理。Smallpond 2025-05-06 LLM #LLM #DeepSeek
DeepSeek DualPipe & EPLB LLM的训练中,高效利用计算资源、降低通信开销以及维持负载均衡是亟待解决的关键问题。尤其在面对超大规模模型和海量数据时,传统训练方法往往难以应对。DeepSeek 团队在这一领域取得了突破性进展,其中 DualPipe 和 EPLB 作为两项核心技术,为优化大规模模型训练提供了创新解决方案。 DualPipe 是一种创新的双向流水线并行算法。 它通过在流水线的两端同时注入微批次,实现了前向和反向传 2025-04-30 LLM #LLM #DeepSeek
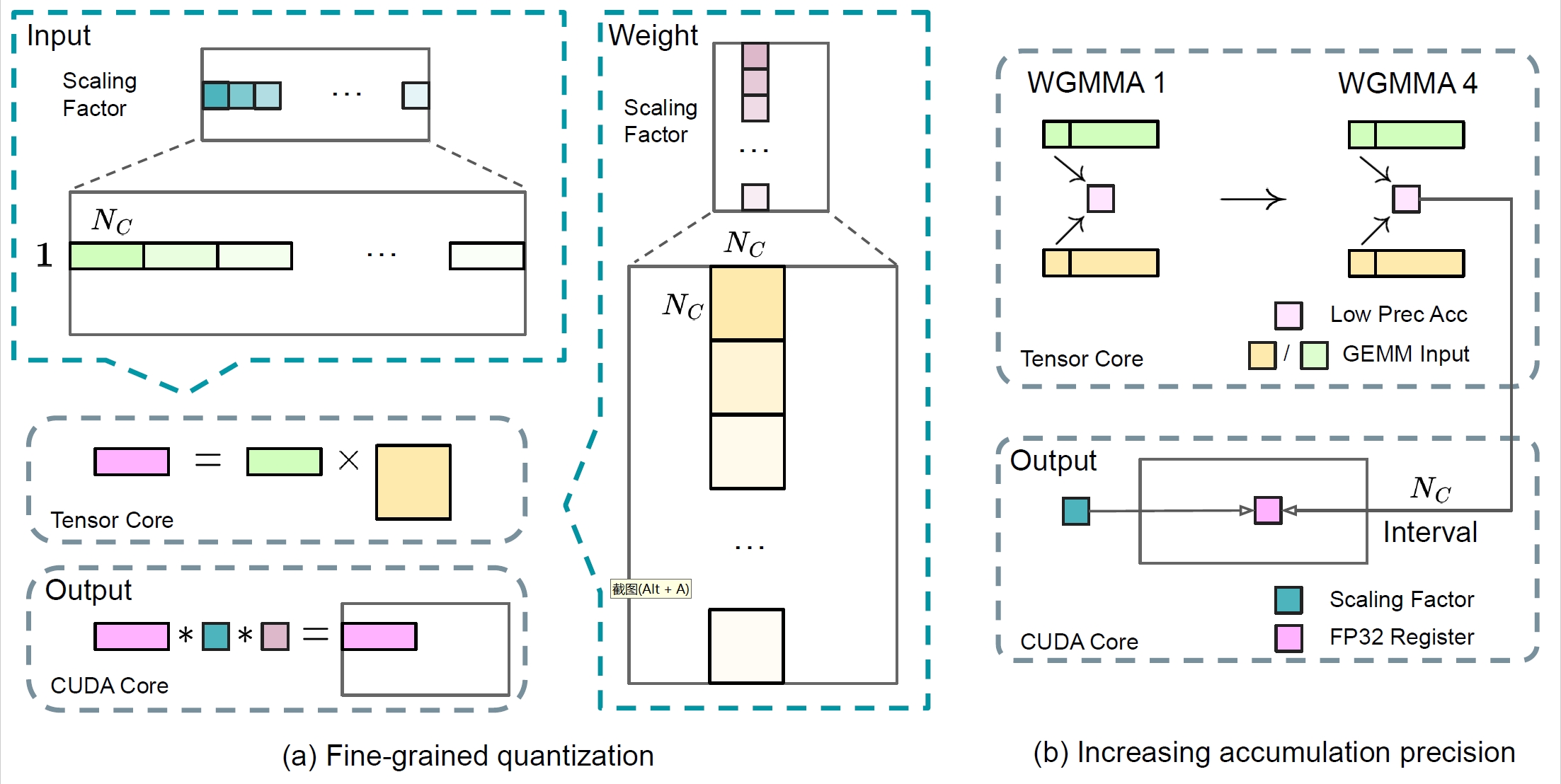
DeepSeek DeepGEMM 大多数AI技术的核心,背后其实都离不开一种计算——矩阵乘法(GEMM)。别把这个当做数学教科书的一种公式计算,实际上 GEMM 就像是深度学习的“心脏”,几乎每个AI模型训练、每次预测,都少不了它的身影。 DeepGEMM 是一个专为 NVIDIA Hopper 架构设计的高效 FP8 矩阵乘法库,支持普通和混合专家模型(MoE)分组矩阵乘法,通过简洁的实现和即时编译技术,实现了高性能和易用性。 2025-04-23 LLM #LLM #DeepSeek
DeepSeek DeepEP DeepEP 是一款专为混合专家(MoE)和专家并行(EP)设计的高性能通信库。它具有高效的全连接 GPU 内核(通常称为 MoE 分发和合并),能够实现出色的吞吐量和极低的延迟。此外,DeepEP 支持包括 FP8 在内的低精度计算,确保了深度学习工作负载的灵活性。 DeepEP的核心亮点 全场景覆盖的通信内核:提供高吞吐量内核(支持NVLink/RDMA混合转发)和超低延迟内核(纯RDMA通 2025-04-07 LLM #LLM #DeepSeek
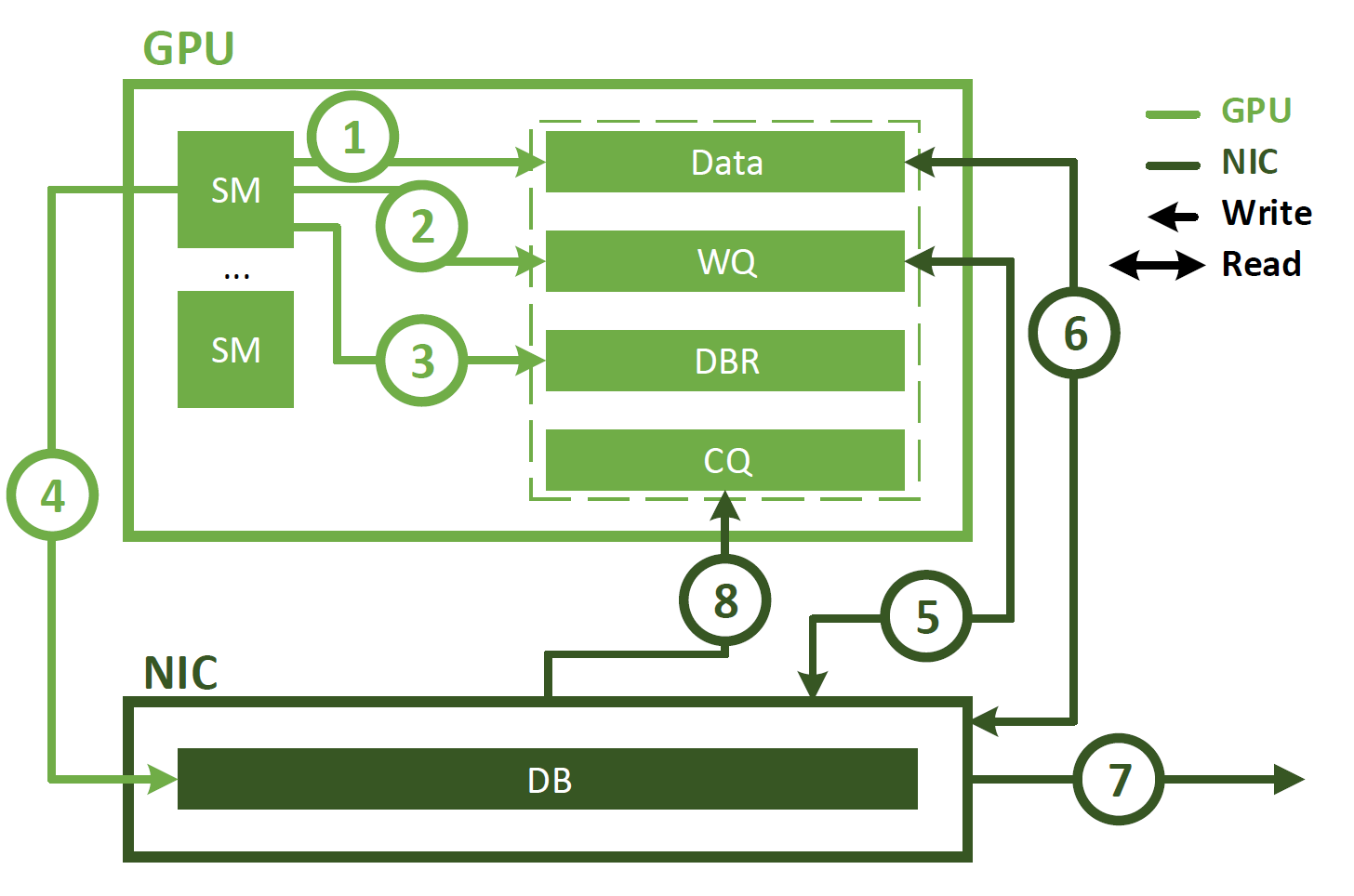
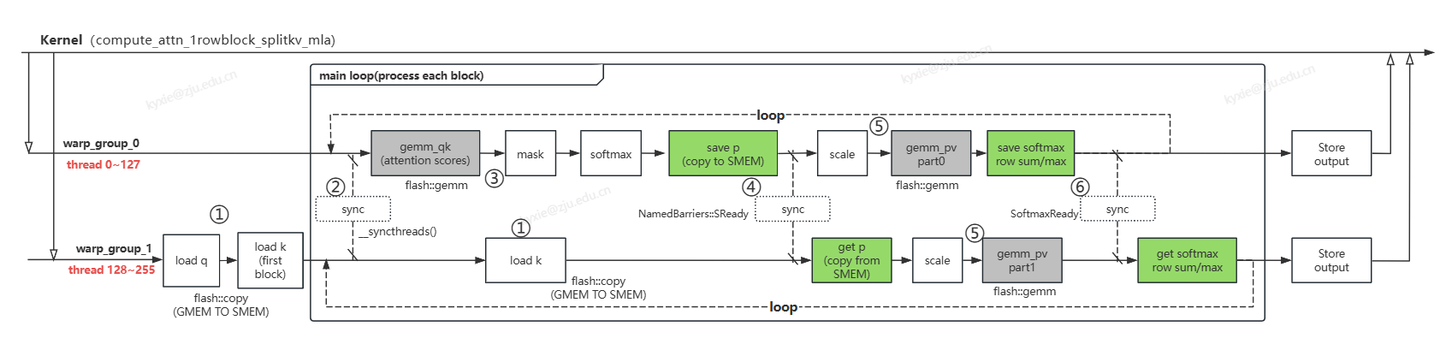
DeepSeek Flash MLA FlashMLA是一种在变长序列场景下的加速版MLA(Multi-Head Linear Attention),针对decoding阶段优化。目前deepseek已将其开源:FlashMLA。 特点: 存算优化:双warp group计算流设计与应用(存算重叠、数据双缓存); 分页缓存:KV page block管理提升显存利用率,更好适应变长序列; SM负载均衡:动态调整block数据,充分利 2025-03-31 LLM #LLM #DeepSeek
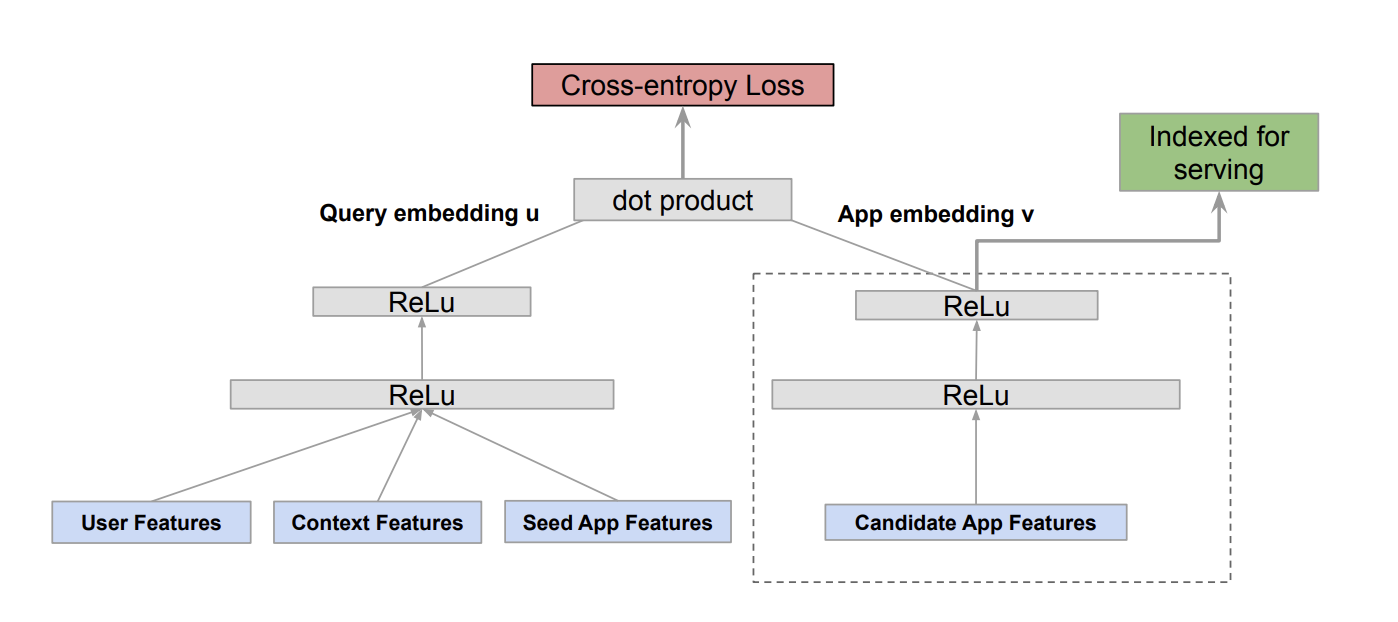
推荐算法--双塔模型 一、双塔模型 双塔模型(two-tower)也叫 DSSM,是推荐系统中最重要的召回通道,没有之一。这节课的内容是双塔模型的结构、训练方式。 双塔模型有两个塔:用户塔、物品塔。两个塔各输出一个向量,作为用户、物品的表征。两个向量的內积或余弦相似度作为对兴趣的预估。 用户塔: 物品塔: 双塔模型: 二、双塔模型的训练 双塔模型训练方式有以下几种: Pointwise:独⽴看待每个正样本、负样 2025-03-24 推荐算法 #推荐算法
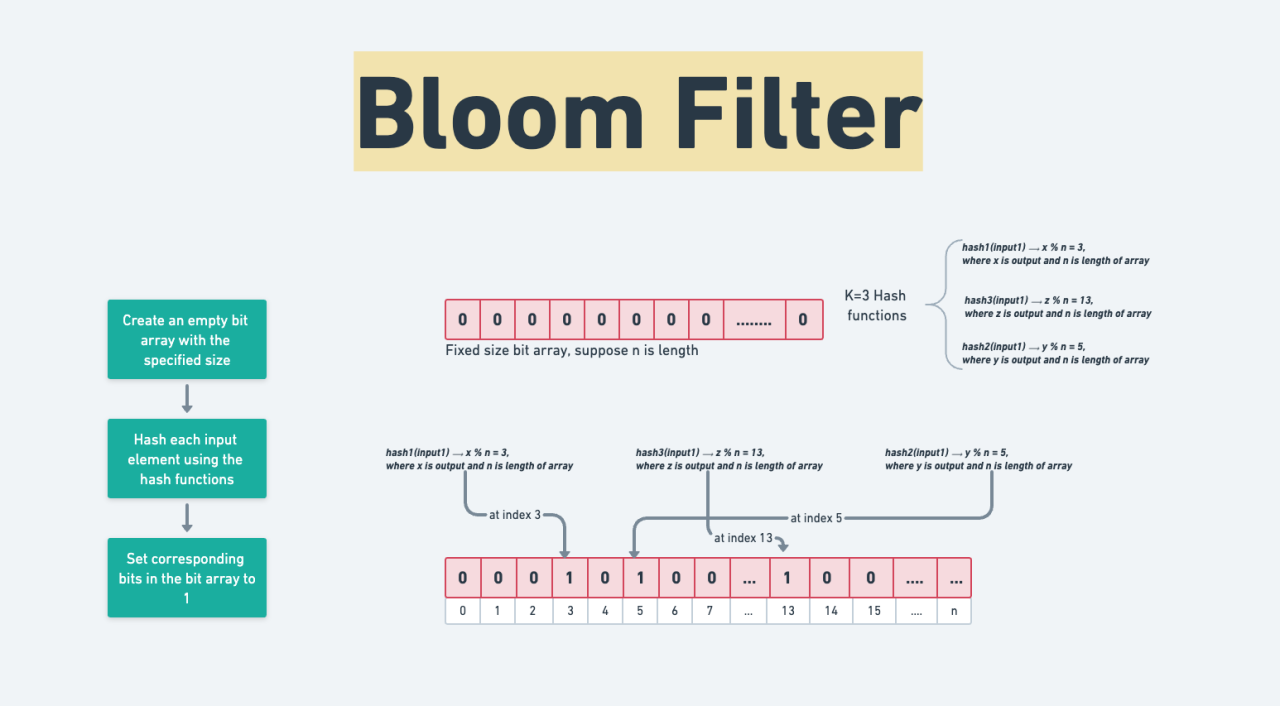
曝光过滤 如果⽤户看过某个物品,则不再把该物品曝光给该⽤户。对于每个⽤户,记录已经曝光给他的物品。对于每个召回的物品,判断它是否已经给该⽤户曝光过,排除掉曾经曝光过的物品。⼀位⽤户看过个物品,本次召回个物品,如果暴⼒对⽐,需要的时间。 布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是 2025-03-17 推荐算法 > BloomFilter #推荐算法 #BloomFilter