DeepSeek OCR 2:Visual Causal Flow
一、简介
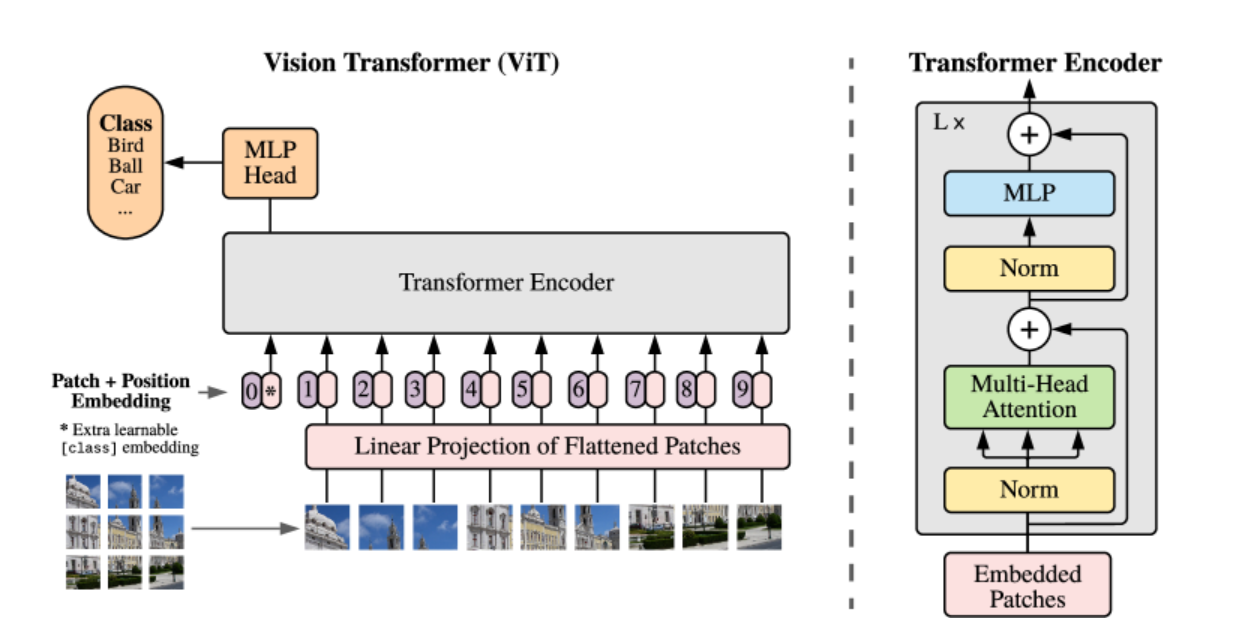
DeepSeek-OCR 2 对上一代的优化主要是编码器上的改进,如下图:用 LLM 式架构替换了 DeepEncoder 中的 CLIP 模块。通过定制化注意力掩码,视觉 token 采用双向注意力机制,而可学习查询则采用因果注意力机制。因此,每个查询 token 既能关注所有视觉 token,也能关注之前的查询,从而实现对视觉信息的渐进式因果重排序,初步验证了LLM-style 架构作为 VLM 编码器的可行性。
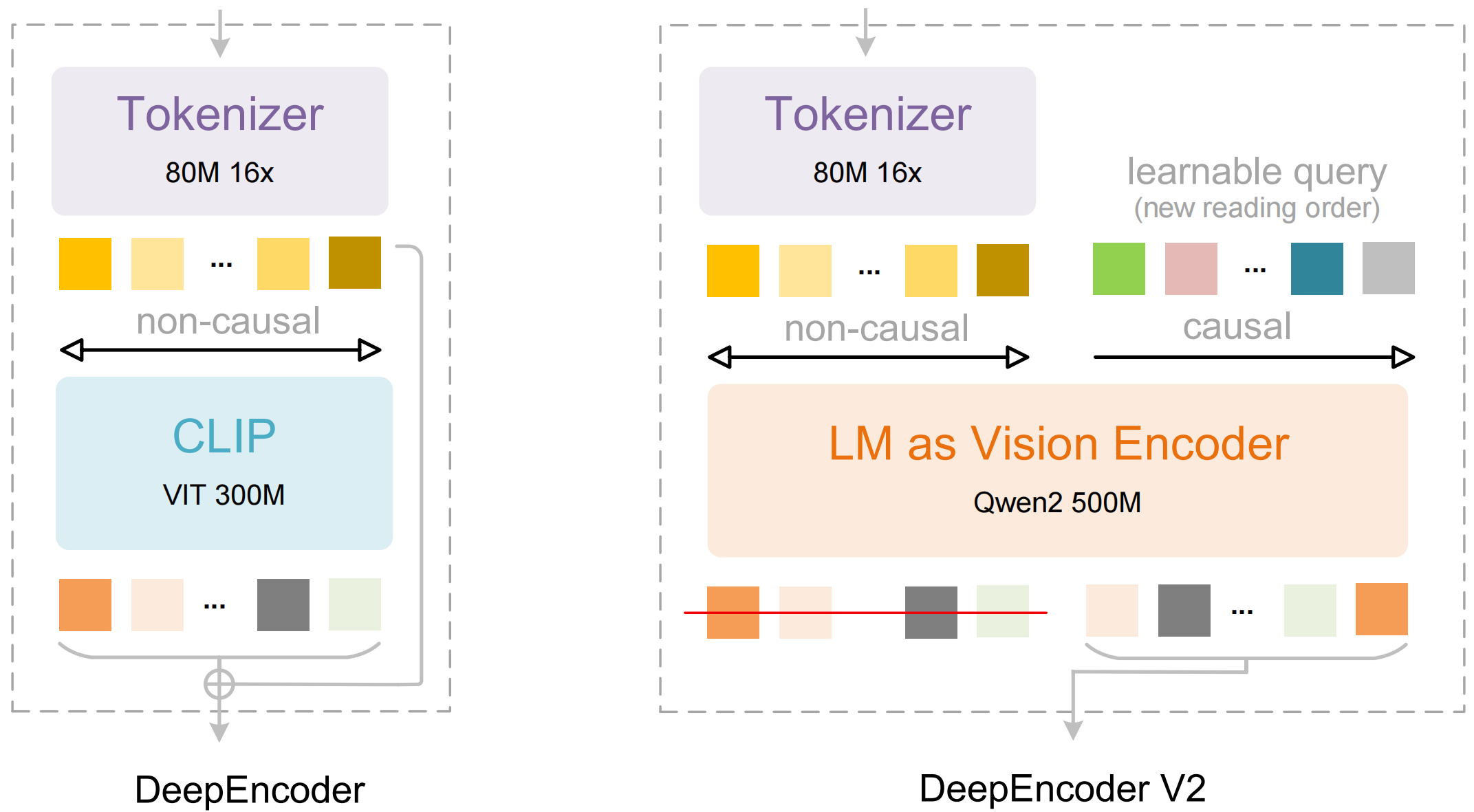
视觉因果流
DeepSeek在论文中指出,传统的视觉语言模型(VLM)通常采用光栅扫描(Raster-Scan)顺序处理图像,即固定地从左到右、从上到下。
这种方式强行将2D图像拍扁成1D序列,忽略了图像内部的语义结构。
这显然与人类的视觉习惯背道而驰。
人类在看图或阅读文档时,目光是随着逻辑流动的:先看标题,再看正文,遇到表格会按列或按行扫视,遇到分栏会自动跳跃。
为了解决这个问题,DeepSeek-OCR2引入了DeepEncoder V2。
它最大的特点是用一个轻量级的大语言模型(Qwen2-0.5B)替换了原本的CLIP编码器,并设计了一种独特的「因果流查询」(Causal Flow Query)机制。
模型架构
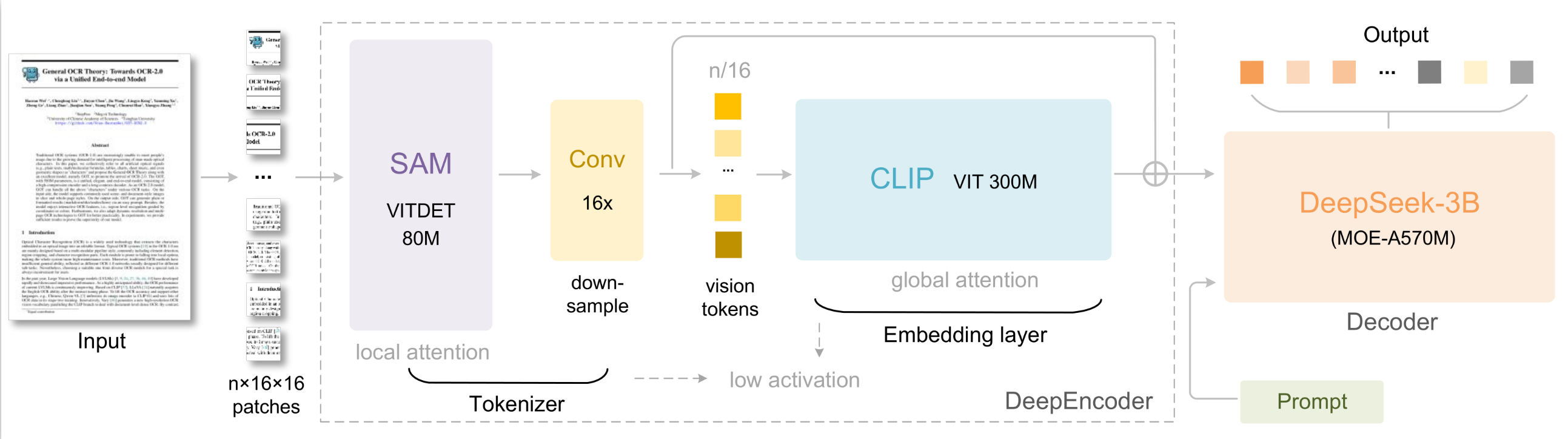
DeepSeek-OCR 2 继承了 DeepSeek-OCR 的【编码器-解码器】架构,但对核心的编码器进行了升级(DeepEncoder → DeepEncoder V2),解码器不变:
- 编码器(DeepEncoder V2):在DeepEncoder V1中,DeepEncoder专门解决现有VLMs视觉编码器(如Vary、InternVL2.0)的痛点:高分辨率输入时token过多、激活内存大、不支持多分辨率。DeepEncoder V2在功能上仍然继承了DeepEncoder V1,但引入了【图像离散化+语义重排序】——将输入图像转化为视觉token,并通过因果推理机制按图像语义重新排列token顺序,而非固定的“左上到右下”栅格顺序。
- 解码器(DeepSeek-MoE Decoder):基于重新排序后的视觉token和文本提示(Prompt),生成最终的OCR输出(文本、公式、表格等内容)。
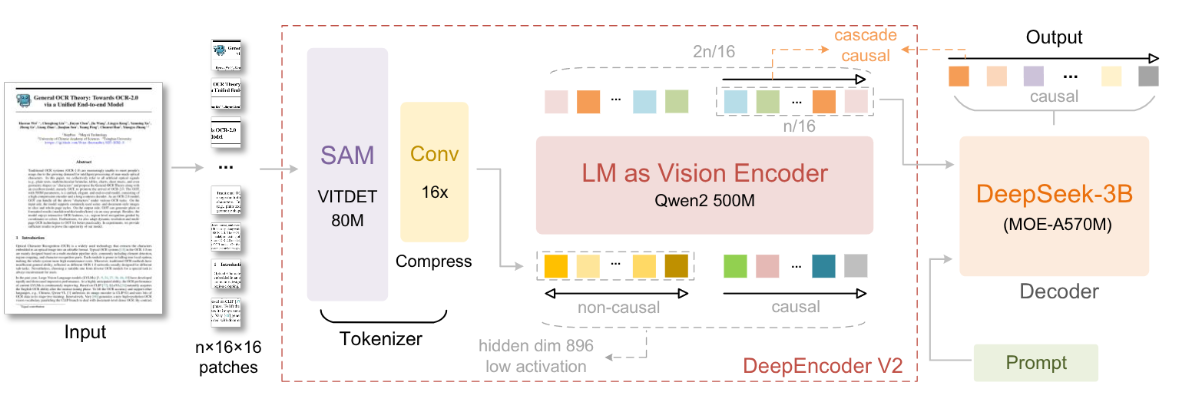
二、DeepEncoder V2
普通的编码器是一个重要组件,它通过注意力机制提取和压缩图像特征,其中每个token都关注所有其他token,实现类似于人类视锥和周边视觉的全图像感受野。然而,将 2D 图像块展平为 1D 序列通过文本导向的位置编码施加了严格的顺序偏差。这与自然的视觉阅读模式相矛盾,尤其是在光学文本、表格和表格中的非线性布局。
2.1 视觉分词器(Vision Tokenizer)
沿用了SAM-base(80M参数)加卷积层的设计,将图像转换为视觉Token。
- 输出维度调整:最终卷积层的输出维度从 DeepEncoder 的 1024 降至 896,适配LLM-style 编码器输入维度。
- 16倍token压缩比:通过窗口注意力(window attention)实现,在仅用80M参数的情况下,将图像patch压缩16倍,大幅降低后续全局注意力模块的计算成本和激活内存。
2.2 LLM作为视觉编码器(Language model as vision encoder)
用紧凑LLM架构替换初代 DeepEncoder 中的 CLIP ViT 模块,实现“视觉因果建模”。 采用 Qwen2-0.5B(500M参数)作为视觉编码器,参数规模与 CLIP ViT(300M)接近,无额外计算开销。
将原始的ViT改成了LM格式,你可以这么理解,ViT就是纯Encoder结构,会让每个视觉Token都彼此看见。
那么就存在了一个问题,就是视觉token其实是2维的,直接Patch会出现信息错乱,因此加入位置编码,但是这样就相当于看图像,就是必须从左上一直看到右下,按照顺序来阅读,而人在看图片的时候,会考虑每个模块的语义关联性,会有一定的阅读顺序,当然跟排版页有关。比如双栏的,如果直接横行阅读,那么就会出现视觉和语义的Gap,或者是竖版文字识别等。
那么怎么做呢,直觉的做法,就是对视觉Token进行排序就可以了嘛,事实上DeepSeek-OCR-V2也是这么做的。而对视觉Token排序,可以是encoder-decoder框架也可以是纯decoder框架,encoder-decoder类似于mBART式交叉注意力结构,但是经过实验发现若采用,视觉 token 隔离在独立编码器内,难以收敛。
而纯decoder,让视觉token前面内容看不到后面内容,也是不合理的,所以采用prefix LM结构,同时引入可学习query交互,有效压缩视觉信息。就是双流(双向+因果)注意力架构,这不是是首创,不过确实是在编码器里首次使用。
DeepEncoder V2 将这个组件重新设计为一个具有双流注意力机制的 LLM 风格架构。视觉token使用双向注意力来保留 CLIP 的全局建模能力,而新引入的因果流查询则采用因果注意力。这些可学习的查询作为视觉token的后缀添加,其中每个查询都关注所有视觉token和先前的查询。通过保持查询和视觉token之间相同的基数,这种设计在不对token数量进行修改的情况下,对视觉特征施加了语义排序和蒸馏。最后,只有因果查询的输出被输入到 LLM 解码器。
论文使用 Qwen2-0.5B实例化该架构,其 500M 参数与 CLIP ViT(300M)相当,且不会带来过高的计算开销。带有视觉token前缀连接的解码器架构至关重要,前缀设计使视觉token在所有层中保持活跃,促进与因果查询的有效视觉信息交换。
该架构实际上建立了两阶段级联因果推理:编码器通过可学习的查询语义重排视觉token,而 LLM 解码器对有序序列执行自回归推理。与通过位置编码强加严格空间排序的普通编码器不同,论文的因果排序查询适应平滑视觉语义,同时自然地与 LLM 的单向注意力模式对齐。这种设计可能弥合二维空间结构与一维因果语言建模之间的差距。
2.3 因果流查询(Causal flow query)
因果查询token的数量等于视觉token的数量,计算为
- 全局视图使用
的分辨率,对应于 256 个查询嵌入,表示为 query。 - 局部裁剪采用
的分辨率,裁剪数量 范围从 0 到 6(当图像两个维度都小于 768 时,不应用裁剪)。
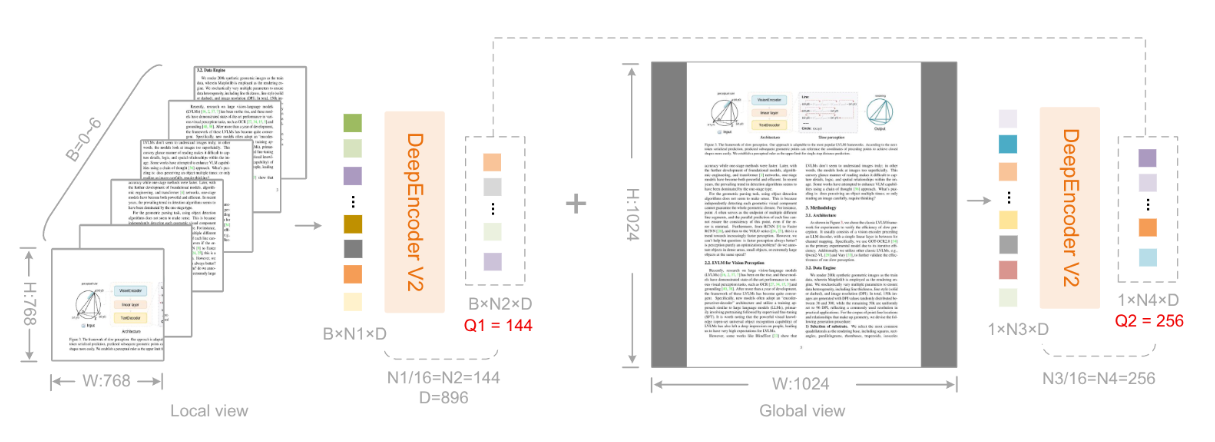
所有局部视图共享一套 144 个查询嵌入,记为 query。因此,输入到 LLM
的重新排序视觉token的总数是
2.4 Attention mask
通过掩码设计实现双流注意力机制的隔离与协同,确保视觉token的全局建模和因果查询的有序推理。
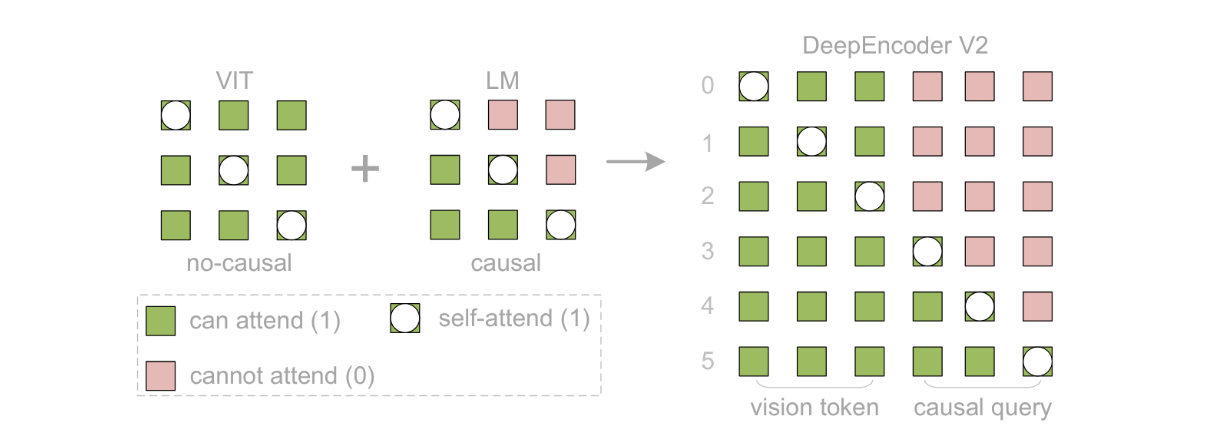
注意力掩码由两个不同的区域组成。左侧区域对原始视觉token应用双向注意力(类似于 ViT),允许完全的token到token的可视性。右侧区域采用因果注意力(三角形掩码,与仅解码器 LLM 相同)用于因果流token,其中每个token只关注之前的token。这两个组件沿序列维度连接起来构建 DeepEncoder V2 的注意力掩码(M),如下所示:
表示因果查询 token 的数量, 代表视觉 token 的数量,LowerTri 表示下三角矩阵(对角线及其下方为 1,上方为 0)。 左上块 :视觉token的双向注意力掩码(1表示可关注,0表示不可关注),允许所有视觉token互相关注。
右上块 :视觉token无法关注因果流查询,避免视觉token被查询的排序逻辑干扰。
左下块 :因果流查询可关注所有视觉token,确保查询能捕捉全局图像信息。
右下块 :因果流查询的因果注意力掩码(下三角矩阵),每个查询仅能关注之前的查询,实现有序的因果推理。
三、训练
3.1 数据
DeepSeek-OCR 2 采用与 DeepSeek-OCR 相同的数据源,包括 OCR 1.0、OCR 2.0 和通用视觉数据,其中 OCR 数据占训练混合的 80%。论文还引入了两个改进:(1) 更均衡的 OCR 1.0 数据采样策略,按内容类型(文本、公式、表格)以 3:1:1 的比例划分页面,以及(2)通过合并语义相似的类别来优化布局检测的标签细化(例如,将”图表说明”和”图表标题”统一)。鉴于这些细微差异,论文认为 DeepSeek-OCR 是一个有效的比较基线。
3.2 训练流程
三个阶段中训练 DeepSeek-OCR 2: (1) 编码器预训练,(2) 查询增强,和 (3) 解码器专业化。第一阶段使视觉分词器和 LLM 风格的编码器获得特征提取、分词压缩和分词重排序的基本能力。第二阶段进一步增强编码器的分词重排序能力,同时提升视觉知识压缩。第三阶段冻结编码器参数,仅优化解码器,在相同的 FLOPs 下实现更高的数据吞吐量。
3.2.1 训练 DeepEncoder V2
让视觉tokenizer和LLM-style编码器掌握三大基础能力——特征提取、token压缩、视觉token基础重排序。
- 训练目标:采用语言建模任务(next token prediction),编码器与轻量级解码器联合优化。
- 数据配置:双分辨率数据加载(768×768、1024×1024),约100M图像-文本对样本(序列长度8K)。
- 初始化:视觉tokenizer继承自DeepEncoder,LLM编码器初始化自Qwen2-0.5B-base。
输出仅保留训练后的编码器参数,用于后续阶段。
3.2.2 查询增强
强化因果流查询的语义重排序能力,同时提升编码器与解码器的协同性。冻结视觉tokenizer(SAM-conv结构),仅联合优化LLM编码器与DeepSeek-MoE解码器。
3.2.3 查询增强 Continue-training LLM(LLM续训)
冻结DeepEncoder V2所有参数,仅更新DeepSeek-LLM解码器参数。