Claude Code(十):Claude Code Skills
一、Skills简介
Agent Skills 是扩展 Claude 功能的模块化能力。每个 Skill 包含指令、元数据和可选资源(脚本、模板),Claude 在相关时会自动使用这些资源。简单说,就是通过文件和文件夹的方式,让 Claude 变得更专业、更懂行。
Claude 的 Agent Skills
系统代表了一种复杂的基于提示词的元工具架构,通过专门的指令注入来扩展 LLM
的能力。与传统的函数调用或代码执行不同,skills 通过 提示词扩展 和
上下文修改 来改变 Claude 处理后续请求的方式,而无需编写可执行代码。
1.1 为什么使用 Skills
提升 Claude 使用效率的方法很多,网上可以找到各种提示词优化、上下文管理等技巧,也有不少开源项目和商业工具。
但这些都存在一个共同问题:每次都要重新设置。每次启动新对话,都需要重复配置一遍,既浪费时间又有学习成本。
Claude Skills 的出现正是为了解决这个问题。它能将你的专业知识、工作流程和领域知识打包成可复用模块,并在遇到相关任务时自动激活。
Skills 是可重用的、基于文件系统的资源,为 Claude 提供特定领域的专业知识:工作流、上下文和最佳实践,将通用代理转变为专家。与提示不同(提示是对话级别的一次性任务指令),Skills 按需加载,无需在多个对话中重复提供相同的指导。
主要优势:
- 专业化 Claude:为特定领域的任务定制功能
- 减少重复:创建一次,自动使用
- 组合功能:结合 Skills 构建复杂工作流
二、Skills 如何工作
Skills 利用 Claude 的虚拟机环境提供超越仅使用提示可能实现的功能。Claude 在具有文件系统访问权限的虚拟机中运行,允许 Skills 作为包含指令、可执行代码和参考资料的目录存在,组织方式就像您为新团队成员创建的入职指南。
这种基于文件系统的架构支持渐进式披露:Claude 按需分阶段加载信息,而不是预先消耗上下文。
2.1 Skills 架构
Skills 在代码执行环境中运行,Claude 具有文件系统访问、bash 命令和代码执行功能。可以这样想:Skills 作为虚拟机上的目录存在,Claude 使用与您在计算机上导航文件相同的 bash 命令与它们交互。
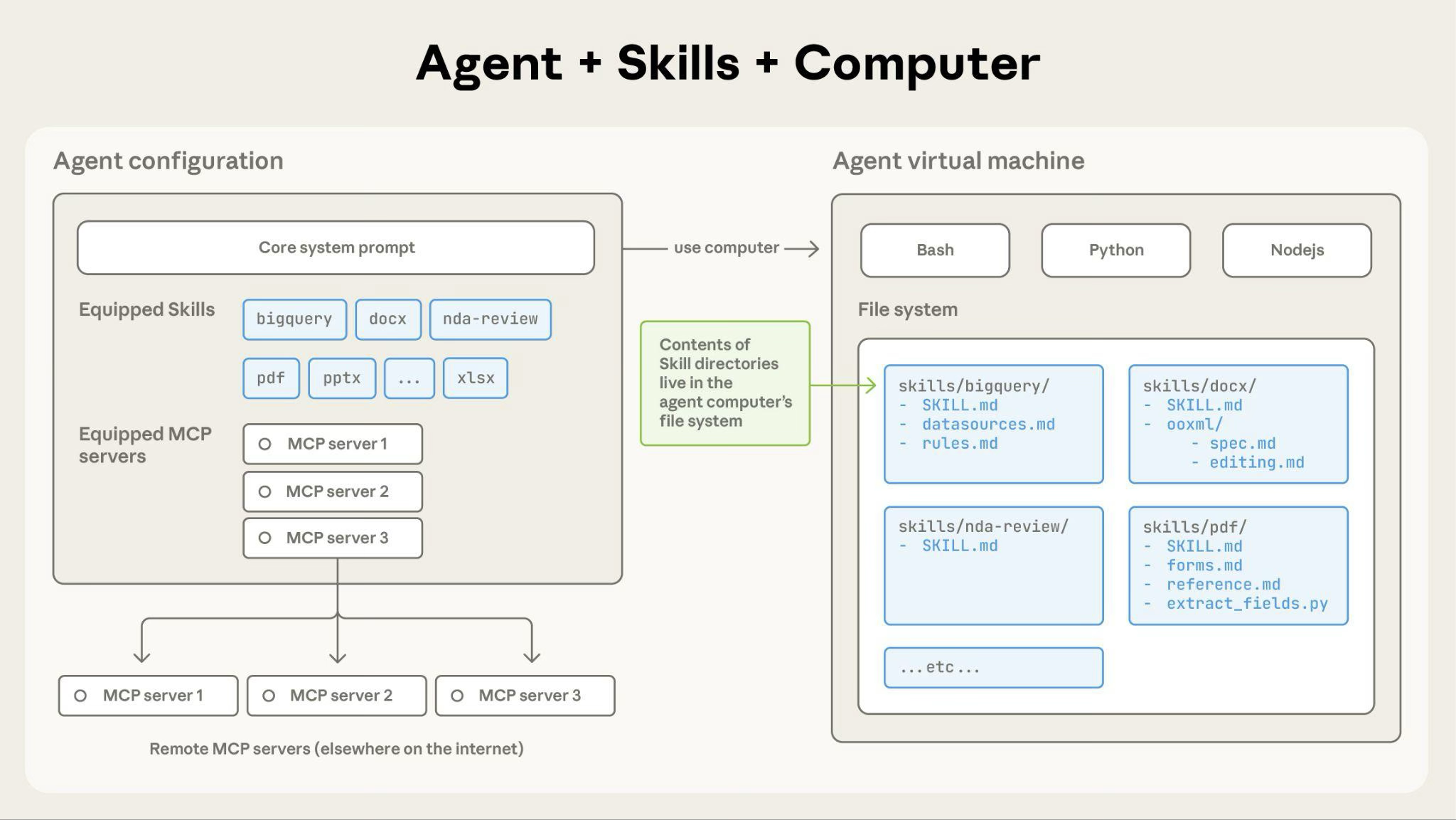
Claude 如何访问 Skill 内容:
触发 Skill 时,Claude 使用 bash 从文件系统读取 SKILL.md,将其指令带入上下文窗口。如果这些指令引用其他文件(如 FORMS.md 或数据库架构),Claude 也会使用其他 bash 命令读取这些文件。当指令提及可执行脚本时,Claude 通过 bash 运行它们并仅接收输出(脚本代码本身永远不会进入上下文)。
此架构支持的功能:
按需文件访问:Claude 仅读取每个特定任务所需的文件。Skill 可以包含数十个参考文件,但如果您的任务只需要销售架构,Claude 仅加载该文件。其余文件保留在文件系统上,消耗零令牌。
高效的脚本执行:当 Claude 运行 validate_form.py 时,脚本的代码永远不会加载到上下文窗口中。仅脚本的输出(如”验证通过”或特定错误消息)消耗令牌。这使脚本比让 Claude 即时生成等效代码要高效得多。
捆绑内容没有实际限制:因为文件在访问前不消耗上下文,Skills 可以包含全面的 API 文档、大型数据集、广泛的示例或任何您需要的参考资料。对于未使用的捆绑内容没有上下文成本。
这种基于文件系统的模型是使渐进式披露工作的原因。Claude 导航您的 Skill 就像您参考入职指南的特定部分一样,访问每个任务所需的确切内容。
2.2 三种 Skill 内容类型,三个加载级别
Skills 可以包含三种类型的内容,每种在不同时间加载。
2.2.1 第 1 级:元数据(始终加载)
内容类型:指令。Skill 的 YAML 前置数据提供发现信息:
1 | |
Claude 在启动时加载此元数据并将其包含在系统提示中。这种轻量级方法意味着您可以安装许多 Skills 而不会产生上下文成本;Claude 只知道每个 Skill 的存在以及何时使用它。
2.2.2 第 2 级:指令(触发时加载)
内容类型:指令。SKILL.md 的主体包含程序知识:工作流、最佳实践和指导:
1 | |
当您请求与 Skill 描述匹配的内容时,Claude 通过 bash 从文件系统读取 SKILL.md。只有这样,此内容才会进入上下文窗口。
2.2.3 第 3 级:资源和代码(按需加载)
内容类型:指令、代码和资源。Skills 可以捆绑其他材料:
1 | |
指令:包含专业指导和工作流的其他 markdown 文件(FORMS.md、REFERENCE.md)
代码:Claude 通过 bash 运行的可执行脚本(fill_form.py、validate.py);脚本提供确定性操作而不消耗上下文
资源:参考资料,如数据库架构、API 文档、模板或示例
Claude 仅在引用时访问这些文件。文件系统模型意味着每种内容类型都有不同的优势:指令用于灵活指导,代码用于可靠性,资源用于事实查询。
| 级别 | 加载时间 | 令牌成本 | 内容 |
|---|---|---|---|
| 第 1 级:元数据 | 始终(启动时) | 每个 Skill 约 100 个令牌 | YAML 前置数据中的 name 和 description |
| 第 2 级:指令 | 触发 Skill 时 | 不到 5k 个令牌 | 包含指令和指导的 SKILL.md 主体 |
| 第 3 级+:资源 | 按需 | 实际上无限制 | 通过 bash 执行的捆绑文件,不将内容加载到上下文中 |
渐进式披露确保任何给定时间只有相关内容占据上下文窗口。
2.3 示例:加载 PDF 处理 skill
以下是 Claude 如何加载和使用 PDF 处理 skill 的方式:
- 启动:系统提示包括:
PDF 处理 - 从 PDF 文件中提取文本和表格、填充表单、合并文档 - 用户请求:「从此 PDF 中提取文本并总结」
- Claude
调用:
bash: read pdf-skill/SKILL.md→ 指令加载到上下文中 - Claude 确定:不需要表单填充,因此不读取 FORMS.md
- Claude 执行:使用 SKILL.md 中的指令完成任务
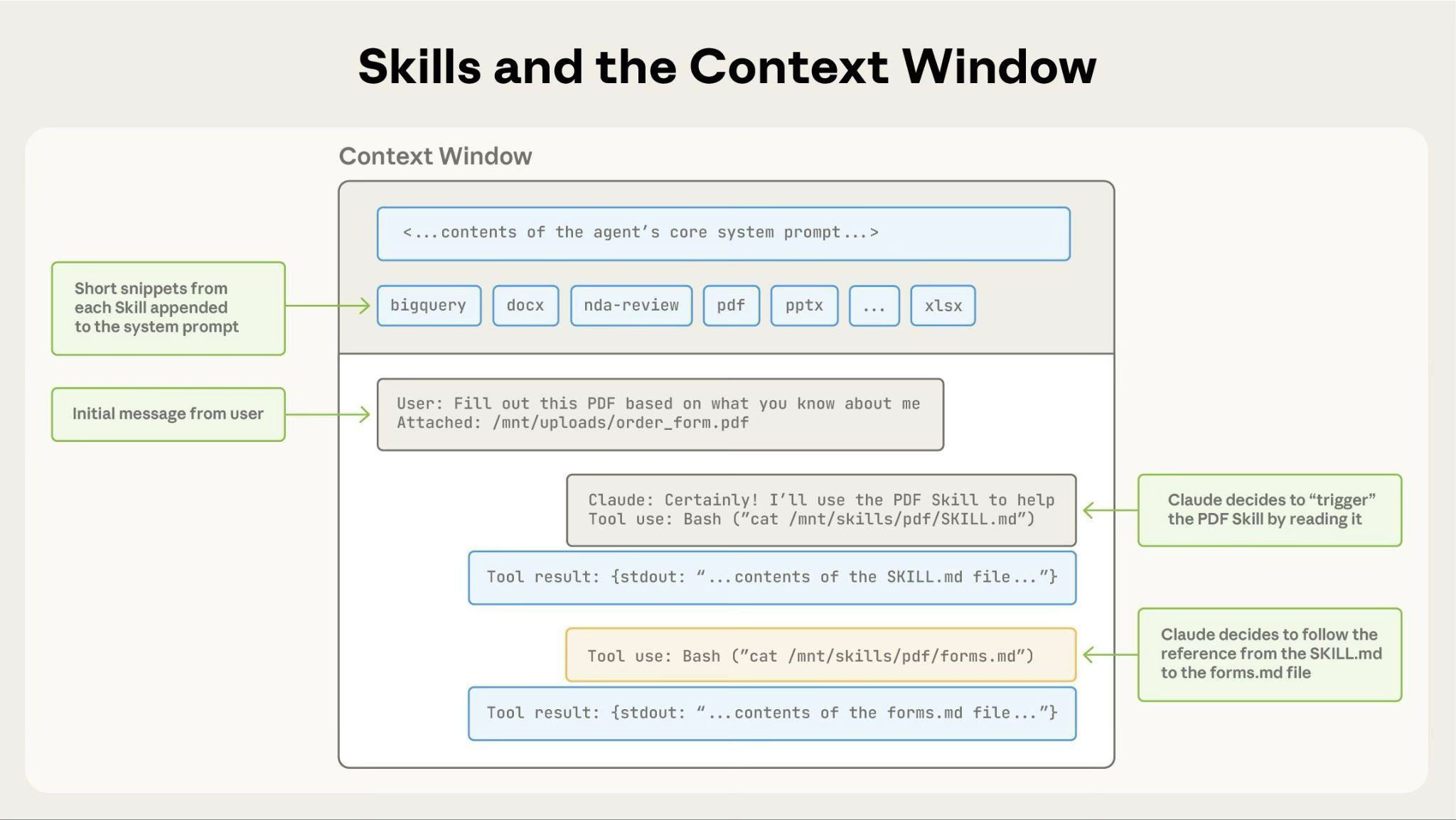
该图表显示:
- 预加载系统提示和 skill 元数据的默认状态
- Claude 通过 bash 读取 SKILL.md 触发 skill
- Claude 根据需要可选地读取其他捆绑文件,如 FORMS.md
- Claude 继续执行任务
这种动态加载确保只有相关的 skill 内容占据上下文窗口。
2.4 Skills使用
2.4.1 Skills 存放在哪里
你存储 Skill 的位置决定了谁可以使用它:
| 位置 | 路径 | 适用于 |
|---|---|---|
| 个人 | ~/.claude/skills/ |
你,跨所有项目 |
| 项目 | .claude/skills/ |
在此存储库中工作的任何人 |
| 插件 | 与插件捆绑 | 安装了该插件的任何人 |
如果两个 Skills 有相同的名称,较高的行获胜:托管覆盖个人,个人覆盖项目,项目覆盖插件。
2.4.2 何时使用 Skills 与其他选项
Claude Code 提供了多种自定义行为的方式。关键区别:Skills 由
Claude 根据你的请求自动触发,而斜杠命令要求你显式输入
/command。
| 使用这个 | 当你想要… | 何时运行 |
|---|---|---|
| Skills | 给 Claude 专业知识(例如,“使用我们的标准审查 PR”) | Claude 在相关时选择 |
| 斜杠命令 | 创建可重用的提示(例如,/deploy staging) |
你输入 /command 来运行它 |
| CLAUDE.md | 设置项目范围的说明(例如,“使用 TypeScript 严格模式”) | 加载到每个对话中 |
| Sub-Agents | 将任务委托给具有自己工具的单独上下文 | Claude 委托,或你显式调用 |
| Hooks | 在事件上运行脚本(例如,在文件保存时 lint) | 在特定工具事件上触发 |
| MCP 服务器 | 将 Claude 连接到外部工具和数据源 | Claude 根据需要调用 MCP 工具 |
Skills 与Sub-Agents:Skills 向当前对话添加知识。Sub-Agents在具有自己工具的单独上下文中运行。使用 Skills 获得指导和标准;当你需要隔离或不同的工具访问时使用Sub-Agents。 Skills 与 MCP:Skills 告诉 Claude _如何_使用工具;MCP _提供_工具。例如,MCP 服务器将 Claude 连接到你的数据库,而 Skill 教 Claude 你的数据模型和查询模式。
2.4.3 Skills vs Sub-Agents vs MCP
| 特性 | Skills | Sub-Agents | MCP (Model Context Protocol) |
|---|---|---|---|
| 目的 | 用专业知识、工作流程、资源扩展 Claude | 生成自主代理处理复杂子任务 | 连接外部工具和数据源 |
| 调用方式 | 模型自动发现(基于上下文) | 父代理显式生成 | MCP 服务器工具调用 |
| 持久性 | 触发时加载到上下文 | 独立运行,返回结果 | 无状态工具执行 |
| 最适合 | 领域专业知识、工作流程、模板 | 并行任务、研究、探索 | 外部 API、数据库、第三方服务 |
| 上下文使用 | 渐进式披露(元数据→指令→资源) | 每个子代理有独立上下文 | 最小上下文(仅工具定义) |
| 复杂度 | 低(只需 SKILL.md + 可选文件) | 中等(需要编排) | 中-高(需要服务器设置) |
| 示例 | 代码审查指南、部署工作流程 | 「研究这个主题」、「探索代码库」 | GitHub API、数据库查询、Slack 集成 |
使用建议:
- Skills:当你需要 Claude 遵循特定程序、使用领域知识或重复执行脚本时
- Sub-Agents:当你需要并行工作、委托复杂研究或隔离任务时
- MCP:当你需要与外部系统、API 交互时
三、Skills结构
现在让我们通过检查 Anthropic skill 仓库中的 skill-creator Skill 作为案例研究,深入了解如何构建 Skills。作为提醒,agent skills 是由指令、脚本和资源组成的有组织的文件夹,agents 可以动态发现和加载以更好地执行特定任务。Skills 通过将您的专业知识打包成 Claude 的可组合资源来扩展 Claude 的能力,将通用 agents 转变为符合您需求的专门 agents。
3.1 基础结构
1 | |
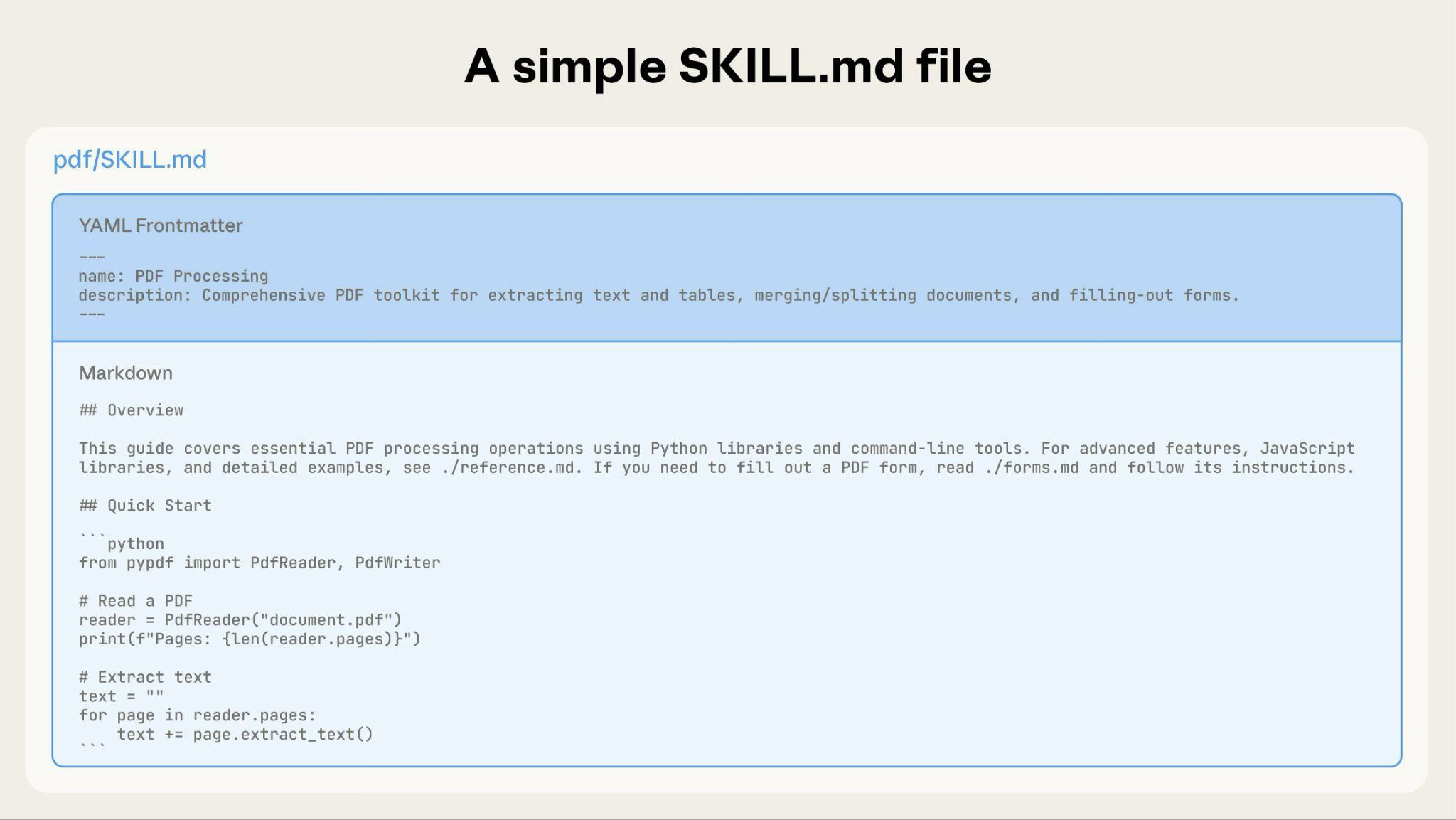
3.2 SKILL.md 格式
每个 Skill 都需要一个带有 YAML 前置数据的 SKILL.md
文件:
1 | |
字段要求:
name:
- 最多 64 个字符
- 只能包含小写字母、数字和连字符
- 不能包含 XML 标签
- 不能包含保留字:「anthropic」、「claude」
description:
- 必须非空
- 最多 1024 个字符
- 不能包含 XML 标签
description 应包括 Skill 的功能以及 Claude
何时应使用它。
四、最佳实践
4.1 核心原则

上下文窗口是一种公共资源。您的技能与 Claude 需要了解的所有其他内容共享上下文窗口,包括:
- 系统提示
- 对话历史
- 其他技能的元数据
- 您的实际请求
技能中的每个令牌都没有直接成本。启动时,只有所有技能的元数据(名称和描述)被预加载。Claude 仅在技能变得相关时才读取 SKILL.md,并根据需要读取其他文件。但是,在 SKILL.md 中保持简洁仍然很重要:一旦 Claude 加载它,每个令牌都会与对话历史和其他上下文竞争。
4.1.1 默认假设:Claude 已经非常聪明
只添加 Claude 没有的上下文。质疑每一条信息:
- “Claude 真的需要这个解释吗?”
- “我能假设 Claude 知道这个吗?”
- “这段落值得它的令牌成本吗?”
好的例子:简洁(大约 50 个令牌):
1 | |
不好的例子:过于冗长(大约 150 个令牌):
1 | |
简洁版本假设 Claude 知道什么是 PDF 以及库如何工作。
4.1.2 高自由度(基于文本的说明):
使用场景:
- 多种方法都有效
- 决策取决于上下文
- 启发式方法指导方法
示例:
1 | |
4.1.3 中等自由度(伪代码或带参数的脚本):
使用场景:
- 存在首选模式
- 某些变化是可以接受的
- 配置影响行为
示例:
1 | |
4.1.4 低自由度(特定脚本,很少或没有参数):
使用场景:
- 操作脆弱且容易出错
- 一致性至关重要
- 必须遵循特定的序列
示例:
1 | |
类比:将 Claude 视为探索路径的机器人:
- 两侧都是悬崖的狭窄桥:只有一种安全的前进方式。提供具体的护栏和精确的说明(低自由度)。示例:必须按精确顺序运行的数据库迁移。
- 没有危险的开放田野:许多路径都能成功。给出一般方向并相信 Claude 会找到最佳路线(高自由度)。示例:上下文决定最佳方法的代码审查。
按模型的测试考虑:
- Claude Haiku(快速、经济):技能是否提供了足够的指导?
- Claude Sonnet(平衡):技能是否清晰高效?
- Claude Opus(强大的推理):技能是否避免过度解释?
对 Opus 完美有效的东西可能需要为 Haiku 提供更多细节。如果您计划在多个模型中使用您的技能,请针对所有模型都能很好地工作的说明。
4.2 Skills结构
4.2.1 命名约定
使用一致的命名模式使技能更容易引用和讨论。我们建议对技能名称使用动名词形式(动词 + -ing),因为这清楚地描述了技能提供的活动或能力。
请记住,name 字段必须仅使用小写字母、数字和连字符。
好的命名示例(动名词形式):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentation
可接受的替代方案:
- 名词短语:
pdf-processing、spreadsheet-analysis - 面向行动:
process-pdfs、analyze-spreadsheets
避免:
- 模糊的名称:
helper、utils、tools - 过于通用:
documents、data、files - 保留字:
anthropic-helper、claude-tools - 技能集合中的不一致模式
一致的命名使以下操作更容易:
- 在文档和对话中引用技能
- 一目了然地理解技能的功能
- 组织和搜索多个技能
- 维护专业、统一的技能库
description
字段启用技能发现,应包括技能的功能和使用时机。
始终用第三人称编写。描述被注入到系统提示中,不一致的视角可能会导致发现问题。
- 好的:“处理 Excel 文件并生成报告”
- 避免:“我可以帮助您处理 Excel 文件”
- 避免:“您可以使用此功能处理 Excel 文件”
具体并包含关键术语。包括技能的功能和使用它的具体触发器/上下文。
每个技能恰好有一个描述字段。描述对于技能选择至关重要:Claude 使用它从可能的 100+ 个可用技能中选择正确的技能。您的描述必须提供足够的细节,以便 Claude 知道何时选择此技能,而 SKILL.md 的其余部分提供实现细节。
4.2.2 示例
PDF 处理技能:
1 | |
Excel 分析技能: 1
description: 分析 Excel 电子表格、创建数据透视表、生成图表。在分析 Excel 文件、电子表格、表格数据或 .xlsx 文件时使用。
Git 提交助手技能: 1
description: 通过分析 git 差异生成描述性提交消息。当用户要求帮助编写提交消息或审查暂存更改时使用。
避免模糊的描述,如: 1
description: 帮助处理文档
1 | |
1 | |
4.3 渐进式披露模式
SKILL.md 作为概述,指向 Claude 根据需要查看的详细材料,就像入职指南中的目录一样。
实用指导:
- 保持 SKILL.md 正文在 500 行以下以获得最佳性能
- 接近此限制时将内容拆分为单独的文件
- 使用下面的模式有效地组织说明、代码和资源
基本技能仅包含一个 SKILL.md 文件,其中包含元数据和说明:
随着您的技能增长,您可以捆绑 Claude 仅在需要时加载的其他内容:

完整的技能目录结构可能如下所示:
1 | |
4.3.1 模式 1:高级指南与参考
1 | |
Claude 仅在需要时加载 FORMS.md、REFERENCE.md 或 EXAMPLES.md。
4.3.2 模式 2:特定领域组织
对于具有多个领域的技能,按领域组织内容以避免加载无关的上下文。当用户询问销售指标时,Claude 只需要读取与销售相关的架构,而不是财务或营销数据。这保持令牌使用低且上下文集中。
1 | |
SKILL.md 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# BigQuery 数据分析
## 可用数据集
**财务**:收入、ARR、计费 → 参阅 [reference/finance.md](reference/finance.md)
**销售**:机会、管道、账户 → 参阅 [reference/sales.md](reference/sales.md)
**产品**:API 使用、功能、采用 → 参阅 [reference/product.md](reference/product.md)
**营销**:活动、归因、电子邮件 → 参阅 [reference/marketing.md](reference/marketing.md)
## 快速搜索
使用 grep 查找特定指标:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```
4.3.3 模式 3:条件详情
显示基本内容,链接到高级内容:
1 | |
Claude 仅在用户需要这些功能时读取 REDLINING.md 或 OOXML.md。
4.3.4 避免深层嵌套引用
当从其他引用文件引用文件时,Claude
可能会部分读取文件。遇到嵌套引用时,Claude 可能会使用
head -100
等命令预览内容,而不是读取整个文件,导致信息不完整。
保持引用距离 SKILL.md 一级。所有参考文件应直接从 SKILL.md 链接,以确保 Claude 在需要时读取完整文件。
不好的例子:太深:
1 | |
好的例子:一级深:
1 | |
4.3.5 使用目录结构化较长的参考文件
对于超过 100 行的参考文件,在顶部包含目录。这确保 Claude 即使在部分读取时也能看到可用信息的完整范围。
示例:
1 | |
Claude 可以根据需要读取完整文件或跳转到特定部分。
4.4 工作流和反馈循环
4.4.1 对复杂任务使用工作流
将复杂操作分解为清晰的顺序步骤。对于特别复杂的工作流,提供一个清单,Claude 可以将其复制到其响应中并在进行时检查。
示例 1:研究综合工作流(适用于没有代码的技能):
1 | |
此示例展示了工作流如何应用于不需要代码的分析任务。清单模式适用于任何复杂的多步骤流程。
示例 2:PDF 表单填充工作流(适用于有代码的技能):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38## PDF 表单填充工作流
复制此清单并在完成项目时检查:
```
任务进度:
- [ ] 步骤 1:分析表单(运行 analyze_form.py)
- [ ] 步骤 2:创建字段映射(编辑 fields.json)
- [ ] 步骤 3:验证映射(运行 validate_fields.py)
- [ ] 步骤 4:填充表单(运行 fill_form.py)
- [ ] 步骤 5:验证输出(运行 verify_output.py)
```
**步骤 1:分析表单**
运行:`python scripts/analyze_form.py input.pdf`
这提取表单字段及其位置,保存到 `fields.json`。
**步骤 2:创建字段映射**
编辑 `fields.json` 为每个字段添加值。
**步骤 3:验证映射**
运行:`python scripts/validate_fields.py fields.json`
在继续之前修复任何验证错误。
**步骤 4:填充表单**
运行:`python scripts/fill_form.py input.pdf fields.json output.pdf`
**步骤 5:验证输出**
运行:`python scripts/verify_output.py output.pdf`
如果验证失败,返回步骤 2。
清晰的步骤防止 Claude 跳过关键验证。清单帮助 Claude 和您跟踪多步骤工作流的进度。
4.4.2 实现反馈循环
常见模式:运行验证器 → 修复错误 → 重复
此模式大大提高输出质量。
示例 1:风格指南合规性(适用于没有代码的技能):
1 | |
这展示了使用参考文档而不是脚本的验证循环模式。“验证器”是 STYLE_GUIDE.md,Claude 通过读取和比较来执行检查。
示例 2:文档编辑流程(适用于有代码的技能):
1 | |
验证循环可以及早捕获错误。
4.5 内容指南
4.5.1 避免时间敏感信息
不要包含会过时的信息:
不好的例子:时间敏感(会变成错误):
1 | |
好的例子(使用”旧模式”部分): 1
2
3
4
5
6
7
8
9
10
11
12
13## 当前方法
使用 v2 API 端点:`api.example.com/v2/messages`
## 旧模式
<details>
<summary>旧版 v1 API(已弃用 2025-08)</summary>
v1 API 使用:`api.example.com/v1/messages`
此端点不再受支持。
</details>
旧模式部分提供历史背景,而不会使主要内容混乱。
4.5.2 使用一致的术语
选择一个术语并在整个技能中使用它:
好的 - 一致:
- 始终”API 端点”
- 始终”字段”
- 始终”提取”
不好的 - 不一致:
- 混合”API 端点”、“URL”、“API 路由”、“路径”
- 混合”字段”、“框”、“元素”、“控件”
- 混合”提取”、“拉取”、“获取”、“检索”
一致性帮助 Claude 理解和遵循说明。
4.6 常见模式
4.6.1 模板模式
为输出格式提供模板。将严格程度与您的需求相匹配。
对于严格要求(如 API 响应或数据格式):
1 | |
对于灵活指导(当适应有用时):
1 | |
4.6.2 示例模式
对于输出质量取决于看到示例的技能,提供输入/输出对,就像在常规提示中一样:
1 | |
示例帮助 Claude 比单独的描述更清楚地理解所需的风格和细节程度。
4.6.3 条件工作流模式
通过决策点指导 Claude:
1 | |
如果工作流变得很大或复杂,有许多步骤,考虑将它们推送到单独的文件中,并告诉 Claude 根据任务读取适当的文件。
4.7 评估和迭代
4.7.1 首先构建评估
在编写大量文档之前创建评估。 这确保您的技能解决真实问题,而不是记录想象的问题。
评估驱动的开发:
- 识别差距:在没有技能的情况下对代表性任务运行 Claude。记录具体的失败或缺失的上下文
- 创建评估:构建三个场景来测试这些差距
- 建立基线:测量没有技能的 Claude 的性能
- 编写最少说明:创建足够的内容来解决差距并通过评估
- 迭代:执行评估、与基线比较并改进
此方法确保您解决实际问题,而不是预期可能永远不会出现的要求。
评估结构:
1 | |
此示例演示了具有简单测试标准的数据驱动评估。我们目前不提供运行这些评估的内置方式。用户可以创建自己的评估系统。评估是衡量技能有效性的真实来源。
4.7.2 与 Claude 一起迭代开发技能
最有效的技能开发流程涉及 Claude 本身。与一个 Claude 实例(“Claude A”)合作创建将由其他实例(“Claude B”)使用的技能。Claude A 帮助您设计和改进说明,而 Claude B 在真实任务中测试它们。这之所以有效,是因为 Claude 模型既理解如何编写有效的代理说明,也理解代理需要什么信息。
创建新技能:
在没有技能的情况下完成任务:与 Claude A 一起使用常规提示来解决问题。在您工作时,您自然会提供上下文、解释偏好并分享程序知识。注意您重复提供的信息。
识别可重用模式:完成任务后,识别您提供的对类似未来任务有用的上下文。
示例:如果您完成了 BigQuery 分析,您可能提供了表名、字段定义、过滤规则(如”始终排除测试账户”)和常见查询模式。
要求 Claude A 创建技能:“创建一个技能来捕获我们刚刚使用的 BigQuery 分析模式。包括表架构、命名约定和关于过滤测试账户的规则。”
Claude 模型本身理解技能格式和结构。您不需要特殊的系统提示或”编写技能”技能来让 Claude 帮助创建技能。只需要求 Claude 创建技能,它就会生成具有适当前置事项和正文内容的正确结构化 SKILL.md。
审查简洁性:检查 Claude A 是否没有添加不必要的解释。问:“删除关于赢率意义的解释 - Claude 已经知道这个。”
改进信息架构:要求 Claude A 更有效地组织内容。例如:“组织这个,使表架构在单独的参考文件中。我们稍后可能会添加更多表。”
在类似任务上测试:使用技能与 Claude B(一个加载了技能的新实例)进行相关用例。观察 Claude B 是否找到正确的信息、正确应用规则并成功处理任务。
根据观察迭代:如果 Claude B 遇到困难或遗漏了什么,返回 Claude A 并提供具体信息:“当 Claude 使用此技能时,它忘记了为 Q4 按日期过滤。我们应该添加关于日期过滤模式的部分吗?”
迭代现有技能:
当改进技能时,相同的分层模式继续。您在以下之间交替:
- 与 Claude A 合作(帮助改进技能的专家)
- 与 Claude B 测试(使用技能执行真实工作的代理)
- 观察 Claude B 的行为并将见解带回 Claude A
在真实工作流中使用技能:给 Claude B(加载了技能)实际任务,而不是测试场景
观察 Claude B 的行为:注意它在哪里遇到困难、成功或做出意外选择
示例观察:“当我要求 Claude B 生成区域销售报告时,它编写了查询但忘记了过滤测试账户,即使技能提到了此规则。”
返回 Claude A 进行改进:分享当前的 SKILL.md 并描述您观察到的内容。问:“我注意到 Claude B 在要求区域报告时忘记了过滤测试账户。技能提到了过滤,但也许还不够突出?”
审查 Claude A 的建议:Claude A 可能建议重新组织以使规则更突出、使用更强的语言如”必须过滤”而不是”始终过滤”,或重构工作流部分。
应用并测试更改:使用 Claude A 的改进更新技能,然后在类似请求上再次与 Claude B 测试
根据使用情况重复:当您遇到新场景时继续观察-改进-测试循环。每次迭代都根据真实代理行为而不是假设改进技能。
收集团队反馈:
- 与队友分享技能并观察他们的使用
- 问:“技能在预期时激活吗?说明清楚吗?缺少什么?”
- 合并反馈以解决您自己使用模式中的盲点
为什么此方法有效:Claude A 理解代理需求,您提供领域专业知识,Claude B 通过真实使用揭示差距,迭代改进根据观察到的行为而不是假设改进技能。
4.7.3 观察 Claude 如何导航技能
当您迭代技能时,注意 Claude 实际上如何在实践中使用它们。观察:
- 意外的探索路径:Claude 是否以您没有预期的顺序读取文件?这可能表明您的结构不如您认为的那样直观
- 错过的连接:Claude 是否未能遵循对重要文件的引用?您的链接可能需要更明确或突出
- 对某些部分的过度依赖:如果 Claude 反复读取同一文件,考虑该内容是否应该在主 SKILL.md 中
- 忽略的内容:如果 Claude 从不访问捆绑文件,它可能是不必要的或在主说明中信号不良
根据这些观察而不是假设进行迭代。您的技能元数据中的”name”和”description”特别关键。Claude 在决定是否响应当前任务触发技能时使用这些。确保它们清楚地描述技能的功能和使用时机。
4.8 要避免的反模式
4.8.1 避免 Windows 风格的路径
始终使用正斜杠在文件路径中,即使在 Windows 上:
- ✓
好的:
scripts/helper.py、reference/guide.md - ✗
避免:
scripts\helper.py、reference\guide.md
Unix 风格的路径在所有平台上都有效,而 Windows 风格的路径在 Unix 系统上会导致错误。
4.8.2 避免提供太多选项
除非必要,否则不要呈现多种方法:
1 | |
4.9 高级:带有可执行代码的技能
下面的部分重点关注包含可执行脚本的技能。
4.9.1 解决,不要推卸
编写技能脚本时,处理错误条件而不是推卸给 Claude。
好的例子:明确处理错误:
1 | |
不好的例子:推卸给 Claude: 1
2
3def process_file(path):
# 只是失败并让 Claude 弄清楚
return open(path).read()
配置参数也应该被证明和记录,以避免”巫毒常数”(Ousterhout 定律)。如果您不知道正确的值,Claude 如何确定它?
好的例子:自文档化:
1 | |
不好的例子:魔法数字:
1 | |
4.9.2 提供实用脚本
即使 Claude 可以编写脚本,预制脚本也提供优势:
实用脚本的优势:
- 比生成的代码更可靠
- 节省令牌(无需在上下文中包含代码)
- 节省时间(无需代码生成)
- 确保跨使用的一致性

上面的图表显示了可执行脚本如何与说明文件一起工作。说明文件(forms.md)引用脚本,Claude 可以执行它而无需将其内容加载到上下文中。
重要区别:在您的说明中明确说明 Claude 是否应该:
- 执行脚本(最常见):“运行
analyze_form.py来提取字段” - 作为参考读取(对于复杂逻辑):“参阅
analyze_form.py了解字段提取算法”
对于大多数实用脚本,执行是首选,因为它更可靠和高效。
示例:
1 | |
4.9.3 使用视觉分析
当输入可以呈现为图像时,让 Claude 分析它们:
1 | |
在此示例中,您需要编写 pdf_to_images.py 脚本。
Claude 的视觉能力帮助理解布局和结构。
4.9.4 创建可验证的中间输出
当 Claude 执行复杂的开放式任务时,它可能会犯错误。“计划-验证-执行”模式通过让 Claude 首先以结构化格式创建计划,然后在执行前使用脚本验证该计划来及早捕获错误。
示例:想象要求 Claude 根据电子表格更新 PDF 中的 50 个表单字段。没有验证,Claude 可能会引用不存在的字段、创建冲突的值、遗漏必需字段或错误地应用更新。
解决方案:使用上面显示的工作流模式(PDF
表单填充),但添加一个中间 changes.json
文件,在应用更改前进行验证。工作流变成:分析 →
创建计划文件 → 验证计划 → 执行 →
验证。
为什么此模式有效:
- 及早捕获错误:验证在更改应用前发现问题
- 机器可验证:脚本提供客观验证
- 可逆计划:Claude 可以迭代计划而不接触原件
- 清晰调试:错误消息指向特定问题
何时使用:批量操作、破坏性更改、复杂验证规则、高风险操作。
实现提示:使用详细的验证脚本和特定的错误消息,如”字段 ‘signature_date’ 未找到。可用字段:customer_name、order_total、signature_date_signed”来帮助 Claude 修复问题。
4.9.5 打包依赖项
技能在代码执行环境中运行,具有特定于平台的限制:
- claude.ai:可以从 npm 和 PyPI 安装包并从 GitHub 存储库拉取
- Anthropic API:没有网络访问权限,没有运行时包安装
在您的 SKILL.md 中列出所需的包,并验证它们在代码执行工具文档中可用。
4.9.6 运行时环境
技能在具有文件系统访问、bash 命令和代码执行能力的代码执行环境中运行。
这如何影响您的创作:
Claude 如何访问技能:
- 元数据预加载:启动时,所有技能 YAML 前置事项中的名称和描述被加载到系统提示中
- 按需读取文件:Claude 在需要时使用 bash 读取工具从文件系统访问 SKILL.md 和其他文件
- 高效执行脚本:实用脚本可以通过 bash 执行,而无需将其完整内容加载到上下文中。只有脚本的输出消耗令牌
- 大文件无上下文惩罚:参考文件、数据或文档在实际读取前不消耗上下文令牌
文件路径很重要:Claude 像文件系统一样导航您的技能目录。使用正斜杠(
reference/guide.md),而不是反斜杠描述性地命名文件:使用指示内容的名称:
form_validation_rules.md,而不是doc2.md为发现组织:按域或功能组织目录
- 好的:
reference/finance.md、reference/sales.md - 不好的:
docs/file1.md、docs/file2.md
- 好的:
捆绑综合资源:包括完整的 API 文档、广泛的示例、大型数据集;在访问前没有上下文惩罚
对确定性操作优先使用脚本:编写
validate_form.py而不是要求 Claude 生成验证代码明确执行意图:
- “运行
analyze_form.py来提取字段”(执行) - “参阅
analyze_form.py了解提取算法”(作为参考读取)
- “运行
测试文件访问模式:通过使用真实请求测试来验证 Claude 可以导航您的目录结构
示例:
1 | |
当用户询问收入时,Claude 读取 SKILL.md,看到对
reference/finance.md 的参考,并调用 bash
来仅读取该文件。sales.md 和 product.md
文件保留在文件系统上,在需要前消耗零上下文令牌。这个基于文件系统的模型是启用渐进式披露的原因。Claude
可以导航并有选择地加载每个任务所需的内容。
4.10 MCP 工具参考
如果您的技能使用 MCP(模型上下文协议)工具,始终使用完全限定的工具名称以避免”找不到工具”错误。
格式:ServerName:tool_name
示例: 1
2使用 BigQuery:bigquery_schema 工具检索表架构。
使用 GitHub:create_issue 工具创建问题。
其中:
BigQuery和GitHub是 MCP 服务器名称bigquery_schema和create_issue是这些服务器中的工具名称
没有服务器前缀,Claude 可能无法定位工具,特别是当有多个 MCP 服务器可用时。
4.10.1 避免假设工具已安装
不要假设包可用:
1 | |
4.11 技术说明
4.11.1 YAML 前置事项要求
SKILL.md 前置事项需要 name 和 description
字段,具有特定的验证规则:
name:最多 64 个字符,仅小写字母/数字/连字符,无 XML 标签,无保留字description:最多 1024 个字符,非空,无 XML 标签
4.11.2 令牌预算
保持 SKILL.md 正文在 500 行以下以获得最佳性能。如果您的内容超过此限制,使用前面描述的渐进式披露模式将其拆分为单独的文件。
4.12.3 有效技能清单
在分享技能之前,验证:
核心质量
- 描述具体并包含关键术语
- 描述包括技能的功能和使用时机
- SKILL.md 正文在 500 行以下
- 其他详情在单独的文件中(如果需要)
- 没有时间敏感信息(或在”旧模式”部分中)
- 整个技能中术语一致
- 示例具体,不抽象
- 文件引用一级深
- 适当使用渐进式披露
- 工作流有清晰的步骤
代码和脚本
- 脚本解决问题而不是推卸给 Claude
- 错误处理明确且有帮助
- 没有”巫毒常数”(所有值都有理由)
- 所需的包在说明中列出并验证为可用
- 脚本有清晰的文档
- 没有 Windows 风格的路径(所有正斜杠)
- 关键操作的验证/验证步骤
- 包含质量关键任务的反馈循环
测试
- 至少创建了三个评估
- 使用 Haiku、Sonnet 和 Opus 进行了测试
- 使用真实使用场景进行了测试
- 合并了团队反馈(如果适用)
五、Skills仓库
官方仓库:https://github.com/anthropics/skills 1. Awesome-Claude-Skills 1: https://github.com/ComposioHQ/awesome-claude-skills 2. Awesome-Claude-Skills 2: https://github.com/VoltAgent/awesome-claude-skills 3. Awesome-Claude-Skills 3: https://github.com/BehiSecc/awesome-claude-skills 4. SkillsMP: https://skillsmp.com 5. AiTMPL Skills: https://aitmpl.com/skills 6. Claude Marketplaces: https://claudemarketplaces.com
Reference
- Agent Skills Docs
- Equipping agents for the real world with Agent Skills
- Agent Skills 开发指南
- Agent Skills 最佳实践
- 告别繁琐!ZCF+Claude一键配置终极方案,1分钟搞定所有设置!
- Claude 新功能深度解析:Agent Skills 让 AI 智能体变得更专业
- Claude Agent Skills:第一性原理深度解析
- Claude Skill 从原理到实战——一句话实现公众号自动撰写、排版、配图、发布
- Claude Code 与 Codex 协作开发 3.0:从 MCP 到 Skills 的技术演进
- Claude 新王牌 “Skills” 深度解析:让你的 AI 秒变行业专家,告别重复劳动