Claude Code(四):测试驱动开发(TDD)与并行Agent
要点
- 思维范式转变:从“让 AI 修复 Bug”到“让 AI 编写测试来定位并修复 Bug”,我们将实践真正的 测试驱动调试 (Test-Driven Debugging)。
- 高级指令工程:学习如何通过 think a lot 和 plan mode 等指令,引导 AI 进行更深层次的、结构化的思考与规划。
- 并行智能体:见证 Claude Code 最强大的功能之一——通过一条指令 派生出两个并行的子智能体 (Subagents),对同一个重构任务进行“头脑风暴”,并提出不同方案供我们选择。
- 构建健壮性:理解为什么先写测试、再做重构是保证系统稳定性的基石,以及如何让 AI 在整个过程中贯彻这一思想。
一、Bug场景复现
我们的 RAG 聊天机器人项目已经迭代了一段时间。现在,我们回到应用中,尝试提出一个之前能够正常工作的问题:“课程 5 涵盖了哪些内容?”
然而,前端返回了一个错误。
面对这个报错,大多数人的第一反应可能是复制错误信息,或者截张图,直接扔给 Claude让它帮忙修复。
这当然是一种方法,但它治标不治本,并且充满了不确定性。我们不知道 AI 会如何修改代码,也无法保证这次修复不会引入新的问题。这是一种“黑盒式”的修复,对于追求卓越工程质量的开发者来说,是不可接受的。
所以,我决定采取一种更 methodical(系统化)的方法。
二、测试驱动调试
我的核心思路是:我们不仅要修复眼前的 Bug,更要为整个系统建立一个“免疫系统”——一套完善的自动化测试。 这样,未来任何的修改导致了问题,我们都能在第一时间发现。
这个 Bug 可能源于多个文件:
- AIGenerator:处理与 Anthropic API 交互的地方,可能是 Prompt 出了问题。
- rag_system.py:作为 RAG 系统的“指挥官”,负责整个流程的编排。
- search_tools:定义了具体的搜索工具,这里也可能存在缺陷。
因此,我给 Claude Code 下达的指令,不是去“修复 Bug”,而是 首先为这几个核心文件编写测试用例。然后,通过运行这些测试,来定位并最终修复问题。
2.1 Prompt 的艺术:引导 AI 深度思考
为了完成这个复杂的任务,我的 Prompt 经过了精心的设计。
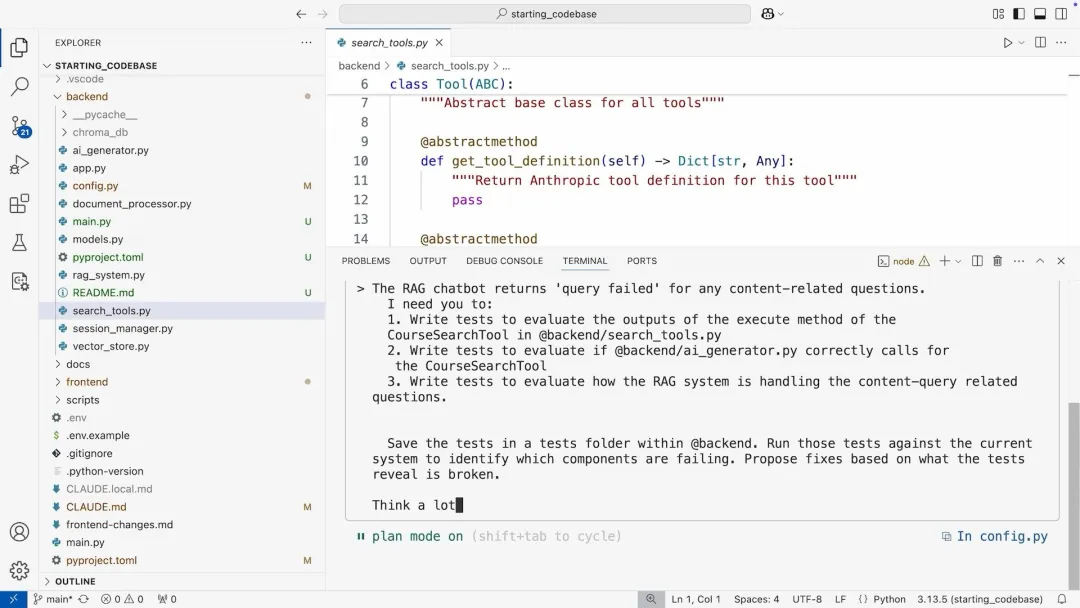
我在这里使用了两个关键的“元指令”:
- think a lot:这个指令会告诉 Claude Code,接下来的任务比较复杂,需要它分配更多的资源(token)来进行内部的“思考”过程。这使得它在制定计划时会更加周全和深入。
- plan mode:开启计划模式。这意味着 Claude Code 在真正开始修改文件之前,会先给出一个详细的行动计划。只有在我审查并批准这个计划之后,它才会开始执行。这给了我绝对的控制权,避免 AI “自由发挥”导致意外情况。
这个“先思考,再出计划,后执行”的流程,完美复刻了人类专家的工作模式,也是我们与 Agentic AI 高效协作的关键。
2.2 AI 的执行过程:从诊断到修复
Claude Code 启动后,它的“思考”过程是完全透明的。我能看到它正在阅读哪些文件,以及它对问题的初步诊断:
- 初步诊断:它推测可能是配置问题、复杂的工具调用链中存在故障点,或是组件间的错误传递受限。
- 计划制定:
- 创建一个 tests/ 目录。
- 使用 pytest 框架编写针对 ai_generator.py, rag_system.py 和 search_tools.py 的单元测试和集成测试。
- 为了隔离测试环境,它计划使用 mock 来模拟 ChromaDB 等外部依赖。
- 安装必要的测试依赖(如 pytest)。
- 运行测试。
- 根据测试结果分析并修复 Bug。
批准这个计划后。接下来,Claude Code 开始了它的工作。

它首先创建了测试目录和文件,然后提示我安装 pytest。
- Pytest:一个成熟且功能强大的 Python 测试框架。它使得编写小型、可读的测试变得简单,并且可以扩展以支持复杂的函数式测试。
- Mocking:测试中的一个核心概念。当我们的测试对象依赖于其他复杂的组件(如数据库、网络API)时,我们不希望在测试中真实地去调用它们,因为这会让测试变慢、不稳定且难以设置。Mocking 允许我们用一个“假的”对象(Mock Object)来替代这些真实依赖。这个假对象完全在我们的控制之下,我们可以指定它在被调用时返回什么值,从而精确地测试我们的代码逻辑,而不用关心其依赖项的内部工作。
测试代码很快生成完毕。当我看到生成的测试文件时,我确信这套流程是正确的。代码结构清晰,使用了 pytest 的 fixtures(测试固件)来准备测试数据和 Mock 对象,这完全是专业级的测试代码。
接下来,Claude Code 运行了它自己编写的测试。果不其然,测试失败了。
根据失败的测试日志,它迅速定位到了问题的根源:在执行向量搜索时,返回结果的最大数量 MAX_RESULTS 被错误地设置为了 0。这是一个非常隐蔽的配置错误,如果靠人工去排查,可能需要花费不少时间。
它立即修改了配置,然后再次运行了所有测试。这一次,全部通过。
最后,它给出了一个全面的总结,报告了它发现的问题、进行的修复,以及它为项目新增的测试基础设施。
我回到浏览器,刷新页面,重新提出了那个问题。
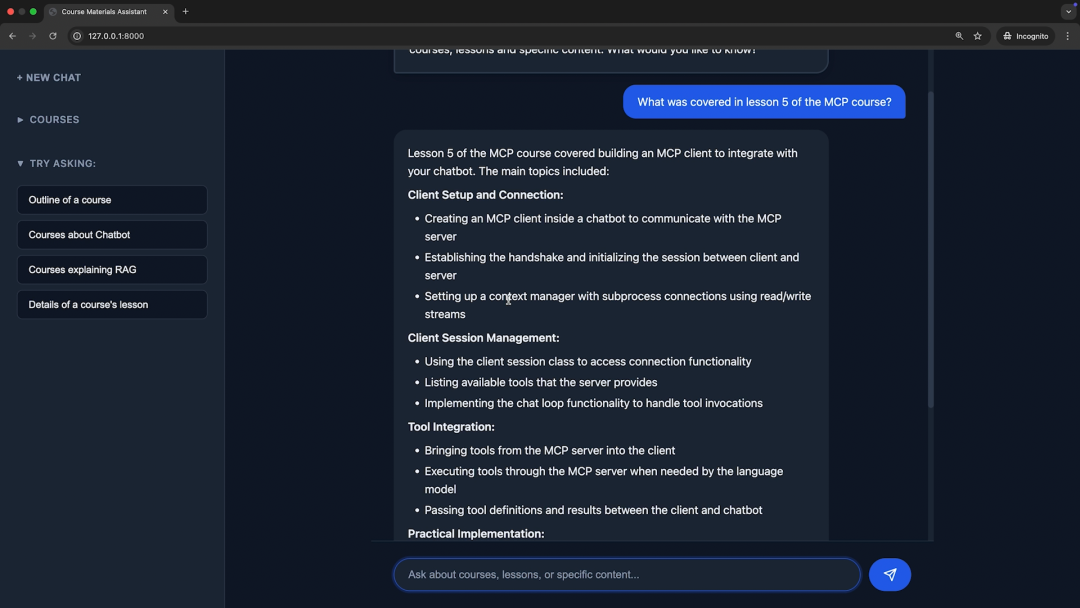
这一次,我们得到了正确、详细的回答。Bug 被修复了。但更重要的是,我们的代码库现在拥有了一套自动化测试,成为了一个更健壮、更可靠的系统。
三、终极挑战:当 AI 成为并行思考的架构师
解决了 Bug,我准备迎接一个更大的挑战:代码重构。
3.1 问题背景:单次工具调用的局限
我发现 ai_generator.py 中的一个设计缺陷:系统被硬编码为 每次用户查询最多只能进行一次工具调用(Tool Call)。
这意味着,对于简单问题,比如“课程 X 的大纲是什么?”,系统可以正常工作。但对于复杂问题,比如“对比课程 X 的第 4 课和课程 Y 的第 2 课,找出它们共同讨论的主题”,系统就无能为力了。因为要回答这个问题,至少需要两次工具调用:
- 获取课程 X 的大纲
- 获取课程 Y 的大纲
当前的架构无法支持这种多轮、连续的工具调用。我需要重构它。
3.2 方案设计:让 AI“头脑风暴”
这次的重构比修复 Bug 要复杂得多。它涉及到修改核心的业务逻辑,可能会有多种实现方案,每种方案都有其优缺点。我该选择哪一种?
此时,我决定使用 Claude Code 的一个堪称“杀手级”的功能。我没有直接告诉它“用方案 A”或“用方案 B”,因为连我自己也不是 100% 确定哪个方案最好。
于是,我编写了一个非常详细的 Prompt,保存在一个 backend-tool-refactor.md 文件中。这个 Prompt 的核心思想是:我不给你最终方案,我只给你目标和约束,然后你派生出两个并行的子智能体,去分别探索不同的实现路径,然后把方案拿给我来决策。
让我们来仔细剖析这个 Prompt 的精华部分:
1 | |
1 | |
最后一句 “Use two parallel subagents to brainstorm possible plans. Do not implement any code.” 是整个任务的灵魂。我命令它扮演一个“技术经理”的角色,分派任务给两个“下属”(子智能体),让它们去进行方案调研。
3.3 见证奇迹:两个 AI 的并行思考
当我执行这个 Prompt 后:
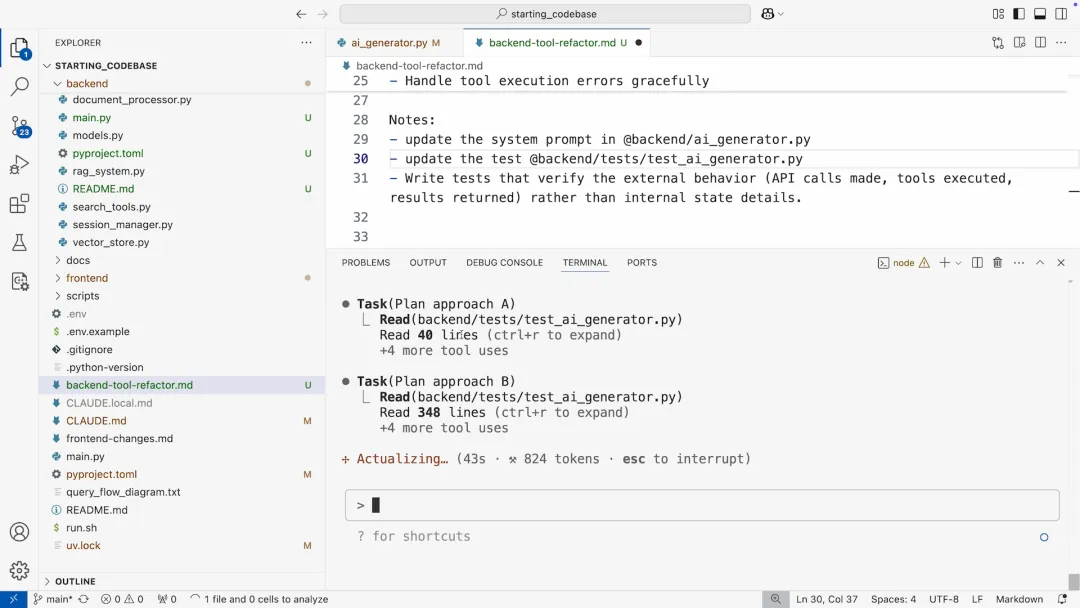
Claude Code 调用了一个名为 task 的内置工具,瞬间派生出两个并行的子进程。这两个子智能体开始同时工作,它们各自阅读代码库,分析需求,并独立地构思解决方案。
- Agentic AI:智能体 AI系统,不仅仅是一个被动的问答或代码生成工具。它是一个具备自主性、能够设定目标、制定计划、使用工具并执行任务的系统。
- Subagents:子智能体的概念则将这一能力推向了新的高度。主智能体可以根据任务的需要,动态地创建和分派一个或多个专门的子智能体来处理子任务。这就像一个项目经理将一个大项目分解成多个小任务,然后分配给不同的团队成员去并行完成。这种“分而治之”的策略,极大地提升了 AI 解决复杂问题的能力和效率。
几分钟后,两个子智能体完成了它们的“头脑风暴”,并向我提交了各自的方案。
- 方案 A (Iterative Approach):一个迭代式的方法。它建议在现有 generate_response 方法中加入一个循环,来处理多轮工具调用。这个方案改动较小,实现起来更安全,风险更低。
- 方案 B (Comprehensive Redesign):一个更全面的重构方案。它建议引入新的辅助方法来专门管理工具调用循环和状态,将多轮逻辑与核心生成逻辑解耦。这个方案从长远来看,代码结构更清晰,可维护性更好,但改动也更大。
现在,选择权回到了我的手上。Claude Code 完美地扮演了技术顾问的角色,它分析了两种路径,列出了利弊,等待我的决策。这种人机协作的模式,我认为是未来软件开发的终极形态。
3.4 执行与验证
我评估后,认为方案 A 作为当前阶段的实现更为稳妥。于是我回复:“Implement approach A”。
同时,我再次开启了 plan mode,确保在它动手之前,我能审查它的具体实施计划。
Claude Code 迅速给出了基于方案 A 的详细计划:
- 修改 generate_response 方法签名,增加一个 max_rounds 参数。
- 更新系统 Prompt,告知模型它可以进行多轮工具调用。
- 在 handle_tool_execution 中实现核心的循环逻辑。
- 最关键的一步:更新 test_ai_generator.py 中的现有测试,并** 增加一个新的测试用例**,专门验证 sequential tool calling(顺序工具调用)的行为是否符合预期。
看到它主动提出要更新和增加测试,我感到非常欣慰。这表明它完全理解了软件工程的健壮性原则:任何重构都必须有测试来保驾护航。
我批准了计划。Claude Code 开始修改代码,并运行了新的测试。所有测试都顺利通过。
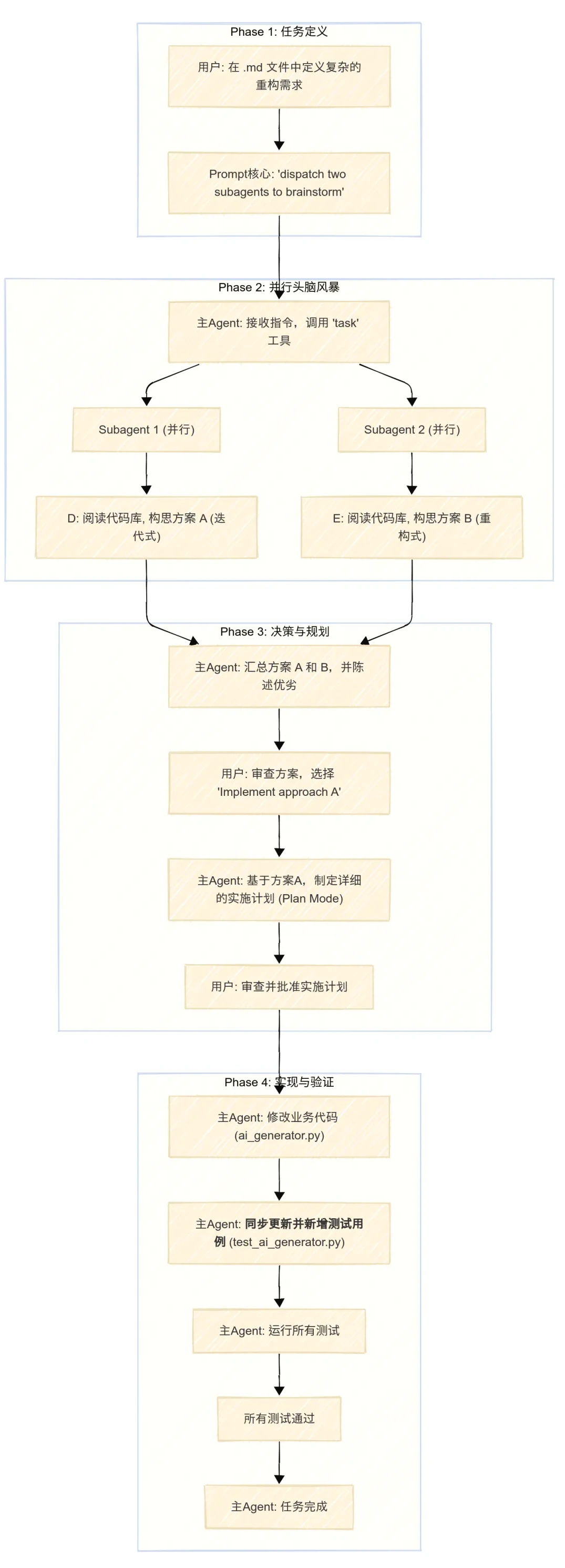
最后,我在前端进行了实际验证。我提出了一个真正需要多轮工具调用的问题:“有没有其他课程涵盖与 MCP 课程第 5 课相同的主题?”
为了回答这个问题,系统需要:
- 第一次工具调用:获取 MCP 课程的大纲,找到第 5 课的主题(例如,“构建 MCP 客户端”)。
- 第二次工具调用:用“构建 MCP 客户端”作为关键词,去搜索其他所有课程。
系统成功地执行了这个流程,并给出了答案:“看起来没有其他课程涵盖构建 MCP 客户端的主题。” 这个答案是准确的,更重要的是,它证明了我们的重构是成功的。
我们实践了两种软件工程领域至关重要的思想范式:
- 测试驱动的开发与调试:我们不再把测试看作是事后的负担,而是将其作为驱动开发、保证质量的“指挥棒”。通过让 AI 先写测试,我们确保了每一次修复和重构都是建立在坚实的基础之上的。
- 架构方案的探索与决策:通过开创性的“并行子智能体”功能,我们让 AI 参与到了软件设计中最具创造性的“头脑风暴”环节。AI 不再只是一个执行者,它成为了一个能够提供多种架构选项、分析利弊的“技术顾问”。