Jet-Nemotron:高效语言模型与后神经网络架构搜索
一、简介
英伟达发布了一个全新的混合架构语言模型系列,Jet-Nemotron。Jet-Nemotron系列有Jet-Nemotron-2B和Jet-Nemotron-4B大小。英伟达表示Jet-Nemotron系列「小模型」性能超越了Qwen3、Qwen2.5、Gemma3和 Llama3.2等当前最先进的开源全注意力语言模型。
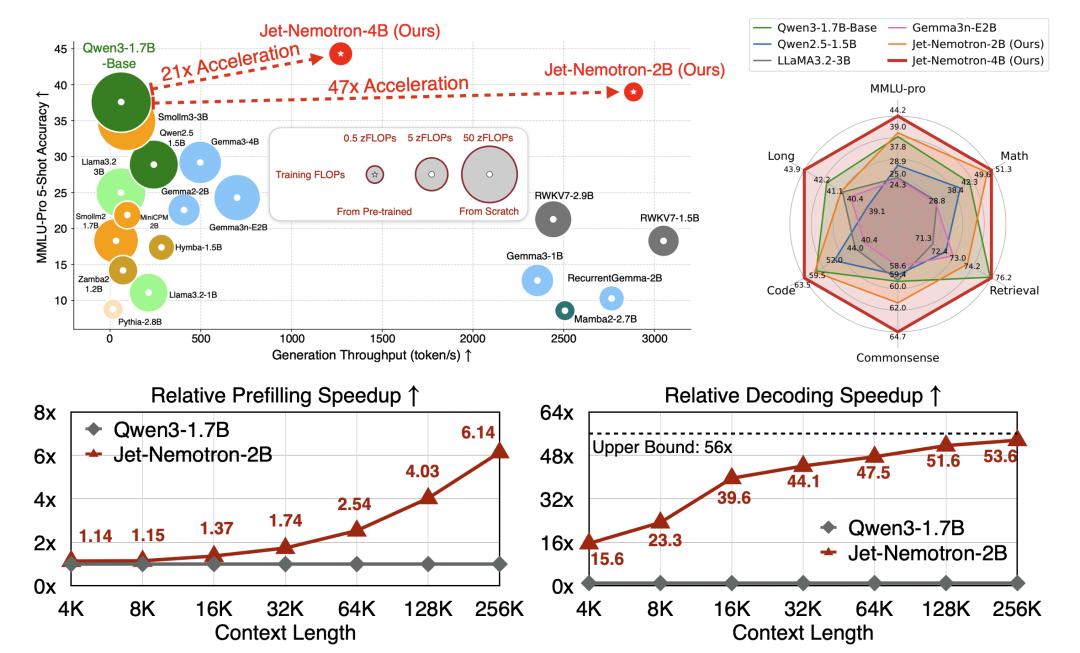
同时实现了显著的效率提升,在H100 GPU上生成吞吐量最高可提升53.6倍。在右上角的雷达图中,可以看到Jet-Nemotron简直就是六边形战士。Jet-Nemotron-4B模型在六个维度MMLU-pro、Math、Retrieval、Commonsense、Code、Long几乎都拉满。
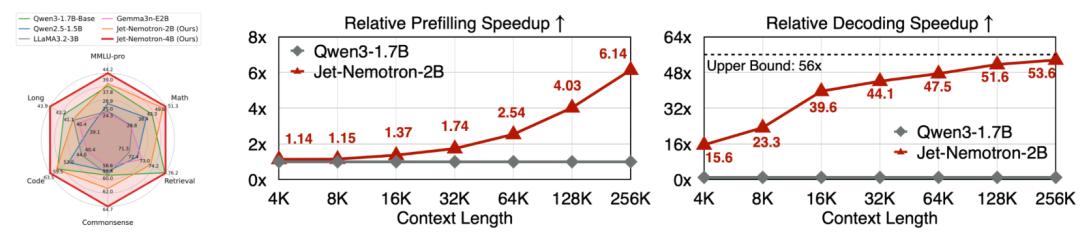
在预填充和解码阶段,Jet-Nemotron-2B在上下文越增加的情况下,相对Qwen 3-1.7B优势越夸张。
- 同等硬件与评测设置下,Jet-Nemotron在长上下文的场景里,把吞吐做到了数量级提升(解码可达50倍提升)。
- 同时在常识/数学/代码/检索/长上下文等维度的准确率不降反升。
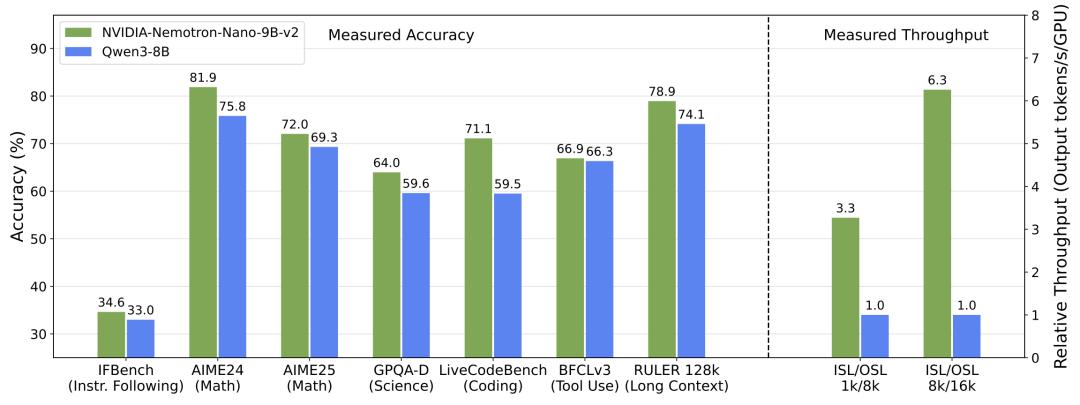
相较传统全注意力小模型又快又准。9B大小的NVIDIA Nemotron Nano 2模型。在复杂推理基准测试中实现了和Qwen3-8B相当或更优的准确率,并且吞吐量最高可达其6倍。
Jet-Nemotron有两项核心创新。
- 后神经网络架构搜索(Post Neural Architecture Search,PostNAS),这是一个高效的训练后架构探索与适应流程,适用于任意预训练的Transformer模型;
- JetBlock,一种新型线性注意力模块,其性能显著优于先前的设计,如Mamba2。
二、Neural Architecture Search(NAS)
NAS是自动化设计神经网络拓扑结构的过程,旨在实现特定任务的最佳性能。其目标是利用有限的资源和最少的人工干预来设计架构。
NAS 的核心是一种搜索算法。简单来说,NAS 的目的就是希望可以有一套演算法或是一个框架能够自动的根据我们的需求找到最好的 neural architecture ,而我们的搜索目标有可能会是根据 performance,或是根据硬体资源限制(hardware constraints) 来进行搜索。
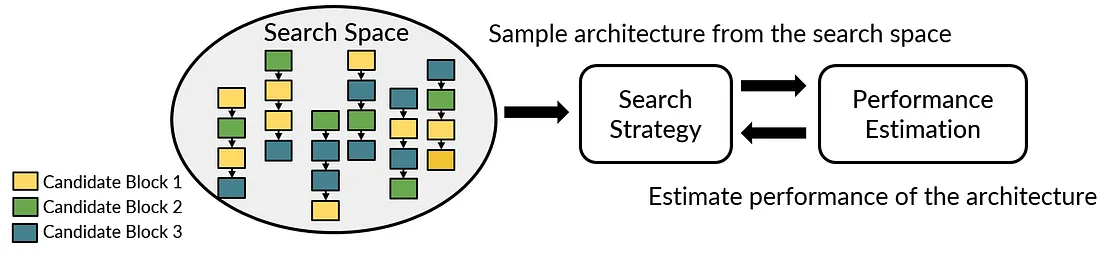
而 NAS 可以分成三个大部分,也就是 search space, search strategy 和 performance estimation strategy。
- 搜索空间(search space):也就是我们在选择 neural architecture 时,我们所可以调整的所有选择。举例来说,kerne size, channel size, convolution type 以及 layer number 等等。
- 搜索策略(Search Strategy):在给定的 search space 当中,我们要透过什么方式来搜索出最好的 neural architecture。举例来说,在搜索 hyperparameter 时最为大家熟悉的 grid search 以及 random search,或是 evolution algorithm (进化算法) 等等。
- 评估策略(Performance Estimation Strategy):我们从 search space 当中挑选出了一个 neural architecture,我们如何评估这个 neural architecture 是好还是坏的方式。举例来说,我们可以实际的训练每个 neural architecture 来获得实际的 top-1 accuracy,我们也可以训练少量的 neural architecture,并且将实际训练好的数据,用来训练一个额外的 accuracy predictor。
2.1 Random search
最简单的方法显然是随机搜索,它通常被用作基准。在这里,一个有效的架构是随机选择的,不涉及任何学习。
2.2 Reinforcement Learning NAS
对于 NAS 这个 task 来说,其实最直觉的方法就是我不断的从 search space 当中取出不同的 neural architecture ,并且实际的训练之后来获得真正的 performance,借着不断的重复这个动作,当我穷尽整个 search space 时,我理所当然的就可以得到这个 search space 当中最好的那个 neural architecture。
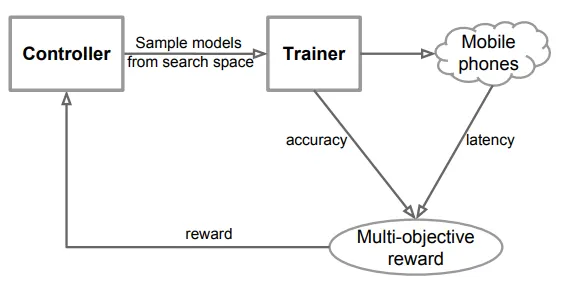
所以最早的 NAS 是基于 reinforcement learning 的方式来进行搜索,也就是透过一个 controller (agent) 不断的挑出 neural architecture,并且透过 trainer (environment) 实际的进行训练,而所得到的 performance (eg, top-1 accuracy, FLOPs or latency) 会作为 reward 进而更新 controller,使得 controller 可以学习要如何才可以 sample 出可以让 reward 最好的 neural architecture。
NAS早期(NAS-RL,NASNet)使用循环神经网络 ( RNN ) 作为策略网络(控制器)。RNN 负责生成候选架构。然后在验证集上训练和评估该架构。为了最大化预期的验证准确率,RNN 控制器的参数进行了优化。如何实现?使用策略梯度技术,例如强化学习 (REINFORCE) 和近端策略优化 (PPO) 。
ENAS使用了一个通过策略梯度训练的 RNN 控制器。值得注意的是,它是首批在架构之间有效共享参数的研究之一。其直观感受是,架构可以被视为一个大型图的一部分,这种方法已被广泛使用。ENAS 训练分为两个交替步骤:
- 使用 REINFORCE 训练 RNN 控制器
- 使用典型的梯度下降形式训练共享参数
另一项成功的尝试是MetaQNN。
2.3 Global search space
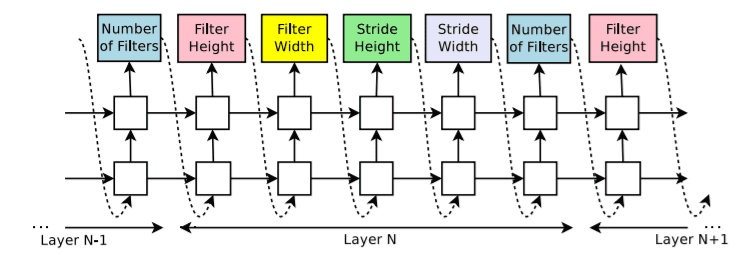
NAS-RL会寻找所有可能的操作组合,从而产生巨大且非常昂贵的搜索空间。它尝试将各种操作组合起来,以形成链式结构 (又称顺序结构)的网络。搜索空间的参数化方式包括:
- 层数
- 每个操作的类型
- 每个操作的超参数(例如,kernel size,filters数量)
后来, 跳跃连接(skip connections)也被添加到组合中,从而允许多分支架构,例如 ResNet 或 DenseNet 等拓扑。
2.4 Modular search space
为了解决全局空间问题,提出了基于单元的方法,以“模块化”搜索空间。也就是说,混合不同的层块(称为模块)。NASNet 是该类别中最流行的算法。NASNet 仅学习两种模块或“单元”:执行特征提取的常规单元和对输入进行下采样的缩减单元。 最终架构是通过以预定义的方式堆叠这些单元来构建的。
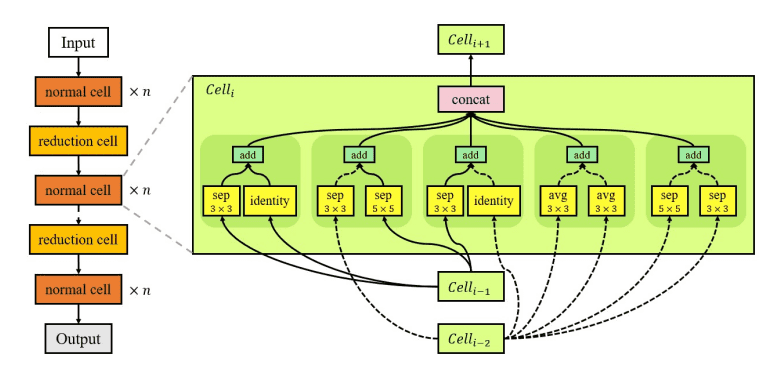
基于单元的方法在其他文献(例如ENAS) 中得到了广泛的应用。但通过单元进行模块化并非唯一的选择。FPNAS通过交替优化某些块并保持其他块不变来强调块的多样性。FBNet采用逐层搜索空间。网络中每个可搜索层都可以从逐层搜索空间中选择不同的块。
2.5 Evolutionary algorithms
遗传算法 (GA) 是优化网络架构的另一种方法。进化算法从模型种群开始。在每个步骤中,一些模型会被采样并通过应用突变进行“复制”,从而生成后代。突变可以是局部操作,例如添加网络层、修改超参数等。训练完成后,这些模型会进行评估并重新加入种群。该过程不断重复,直到满足特定条件。
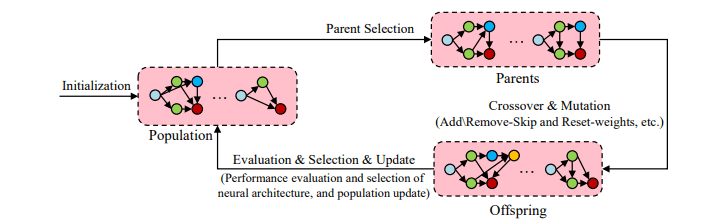
GeNet提出了一种编码方法,将每个架构表示为固定长度的二进制字符串,该方法将从标准遗传算法中使用。
AmoebaNet使用锦标赛选择进化算法 ,或者更确切地说是其一种修改版本,称为正则化进化。不同之处在于,它还会考虑每个模型的“年龄”(即 GA 的步长),并优先考虑较新的模型。请注意,这里也使用了 NASNet 的搜索空间。
2.6 Sequential model-based optimization
在基于模型的顺序优化中,我们可以将 NAS 视为一个顺序过程,该过程会迭代构建越来越复杂的网络。代理模型会评估所有候选模块(或单元),并选择一些有潜力的候选模块。然后,它会在验证集上评估生成的网络的性能,并根据该性能进行自我更新。通过迭代,模型逐渐扩展并达到所需的性能。
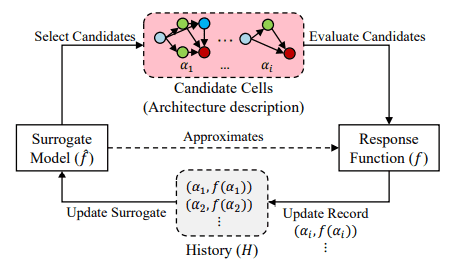
2.6.1 Progressive NAS
Progressive NAS 最主要的概念便是一层一层渐进式的方式决定在每一层要用什么样的选择。
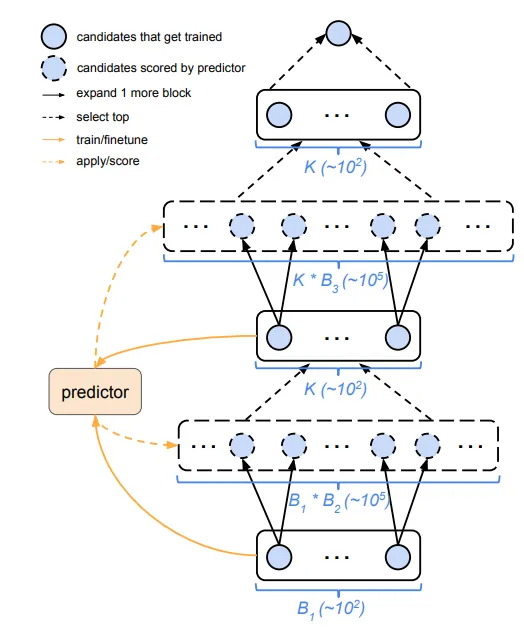
而由于要决定每一层要用什么样的架构,我们首先需要知道所有选择的好坏,而实际的将所有种可能的架构 training,并根据结果来决定好坏会花费许多时间,因此会额外的训练一个 controller,而 controller 的目的就是预测当前这样的组合的准确率会是多少。
因此 Progressive NAS 主要可以分成几个大步骤:
- 从 l-layers 的
个可能的网路架构中,透过 controller 预测结果,并挑选出最好的 个网路架构。 - 将
个网路架构实际的训练并得到他们间的好坏,并利用这 个结果更新 controller ,使其可以预测的更加准确,将最好的网路架构接上下一层的所有可能选择,建构出 l+1 layers 的 个架构,并回到步骤 1。
DPP-Net采用与 PNAS 非常类似的方法,但它也考虑了执行搜索的设备。给定执行搜索的设备,并根据其内存大小和类似的硬件特性设置约束。不满足约束的模型要么从候选列表中移除,要么使用Paretto optimality。
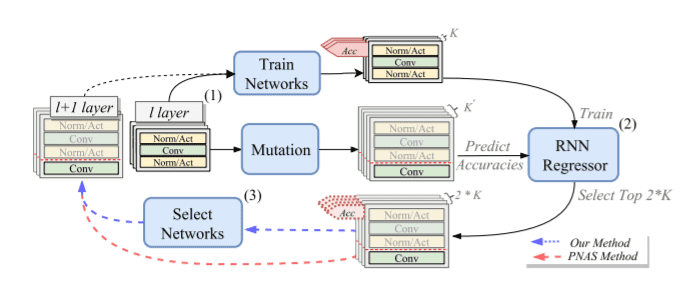
DPP-Net 搜索策略说明:(1)训练和变异,(2)更新和推理,以及(3)模型选择
2.7 One-shot NAS
为了减少过去 NAS 所耗费的大量时间(eg, 实际训练每个 neural architecture 的时间),One-shot NAS 透过将 search space 当中的所有 neural architectures 结合成为一个 over-parameterized 的 neural network,而这个巨大且错综复杂的网路又被称作为 supernet。下图为建构 Supernet 的范例,假如在每层当中,我们总共有三种 candidate blocks 可以选择,则在 supernet 当中每层里面便会同时有三个不同 candidate blocks。
而这样建构的好处在于当 supernet 训练完毕之后,透过 activate supernet 当中不同的 candidate blocks,我们可以进而 approximate 在 search space 当中的任何一个 neural architecture (如下图最右边的部分)。因此 one-shot NAS 之所以称为“one-shot” 的原因在于,我们只需要训练一个 neural network (supernet) ,便可以借此评估整个 search space 当中的任一个 neural architecture。
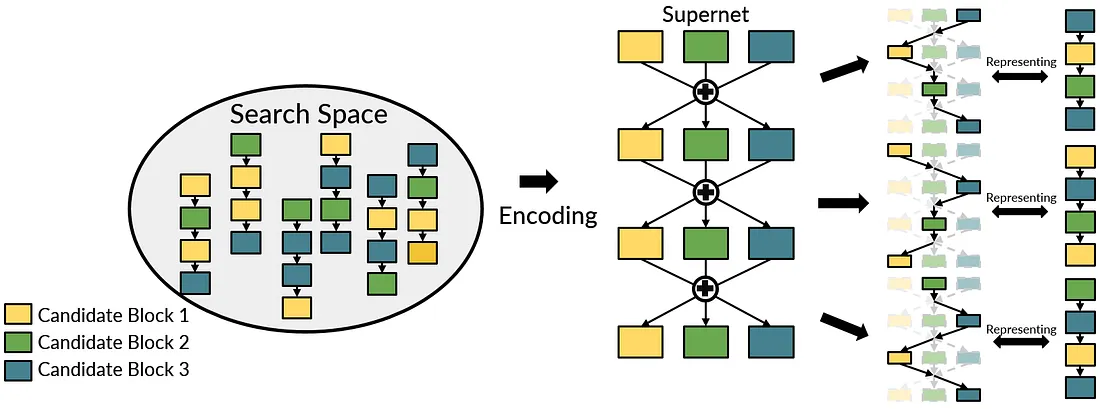
而在 One-shot NAS 当中,根据训练 supernet 以及搜索的不同,又可以分为两种,分别为 Differentiable NAS 以及 Single-path NAS 。
one-shot NAS
2.7.1 Differentiable NAS
Differentiable NAS (DNAS) 希望可以透过 gradient descent 的方式来进行搜索。然而,由于 neural architectures 本身是离散的,因此我们没有办法直接对 neural architectures 微分并且计算梯度。因此 DNAS 使用了一个额外的可微分参数,我们称作为 architecture parameters,目的是希望透过这个可以微分的参数来学习在 search space 当中好的 neural architecture 的分布。
下图为 supernet 当中的某一层 layer,而 DNAS 首先对于每个 candidate block 皆会给予一个 architecture parameter,而这个值通常会是随机初始的(如图中的 0.2, 0.7, 和 0.1),因此对于这层 layer output 的计算方式,便会是每个 candidate block 本身的 output 和 architecture parameters 进行 weighted sum (如左图中的数学式),透过这样的方式,我们便计算出 architecture parameters 的梯度,并且更新,而当 architecture parameters 更新完毕之后,便可以将之作为 “candidate blocks 之间重要程度的依据” ,进而直接对其做 argmax 并 sample 出搜索到的 architecture (如下图的右边)。
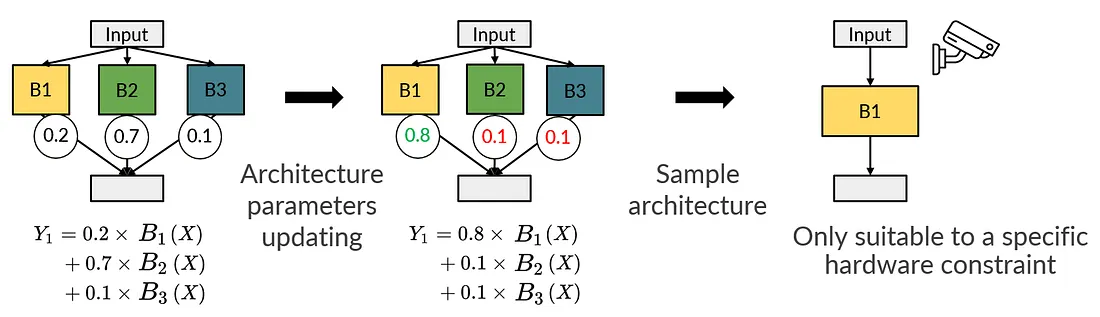
然而,以上的方式对于 DNAS
来说有一个缺点,便是搜索时间不弹性,透过上面的图,我们可以发现,当今天我们更新完整个
architecture parameters 之后,我们仅仅只能从 architecture parameters 中
sample 出一组在特定硬体资源限制之下的 neural
architecture,因此当今天我们需要搜索在
2.7.2 Single-path NAS
而相对于 DNAS 的另外一个种类 single-path NAS,便是直接将整个 NAS 的程序拆成两个独立的步骤,分别为: Supernet training 以及 Architecture searching。
Supernet training: 在这个阶段,每次只会从 supernet 当中 sample 出 single path 并且更新其对应到的参数,透过这样的方式,除了可以模拟实际在 search space 当中离散的 neural architecture,同时也可以大幅度的减少 GPU memory 需求。而如何训练 supernet 在现今的 NAS 研究当中也是一个很重要的研究方向,原因在于我们会希望 Supernet 是一个可以正确评估 neural architectures 好坏的 performance estimator,因此假如 supernet 并没有被稳定且公平的训练,会使得 supernet 本身产生一定的 bias 进而使得我们没有办法良好的评估 neural architectures 之间的好坏。
Architecture searching: 当 supernet 训练完毕之后,supernet 本身便可以作为一个 performance estimator,并且结合不同的 search strategy(eg, random search 以及 evolution algorithm) 来进行搜索。
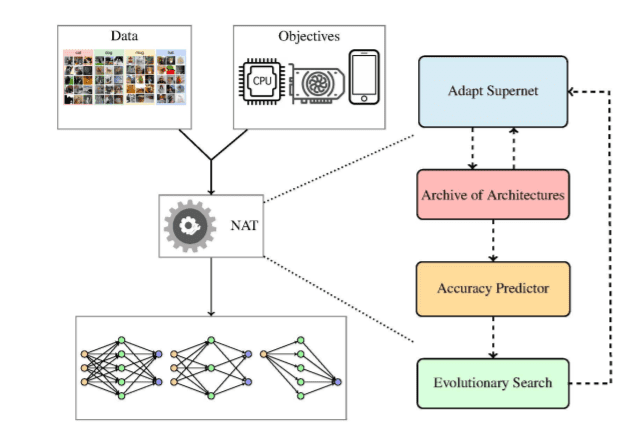
2.8 Neural Architecture Transfer
NAT(神经架构迁移)的作者提出了在 NAS 环境中使用迁移学习的想法,即将现有的超网络迁移到特定任务的超网络。同时,他们还可以搜索能够更好地解决多个目标的架构。因此,迁移学习与搜索过程相结合。多目标是指存在多个相互冲突的目标。在多目标问题中,算法应考虑所有目标,并在它们之间提供最佳权衡。在 NAS 的背景下,目标的示例包括推理时间限制、内存容量、最终模型的大小等。多目标 NAS 是一个快速发展的研究领域。
NAT 分为三个部分:a)准确率预测器 b)进化搜索过程 c)supernet。整个过程如下:
- 从经过训练的supernet列表开始,他们均匀地对其中的一组进行采样。
- 对supernet的性能进行了评估。
- 然后构建准确度预测器,目的是在考虑多个目标的情况下推动搜索。
- 进化搜索提出了一组有前景的架构。
- 架构回到supernet的原始列表,并且该过程不断迭代,直到满足终端条件。
三、Jet-Nemotron实现方法
3.1 PostNAS的动机和路线图
与之前从头开始训练以探索新模型架构的方法不同,PostNAS在预训练的Transformer模型基础上进行构建。同时支持对注意力块设计的灵活探索,从而大大降低了开发新语言模型架构的成本和风险。PostNAS首先确定全注意力层的最佳放置位置,然后再搜索改进的注意力块设计。
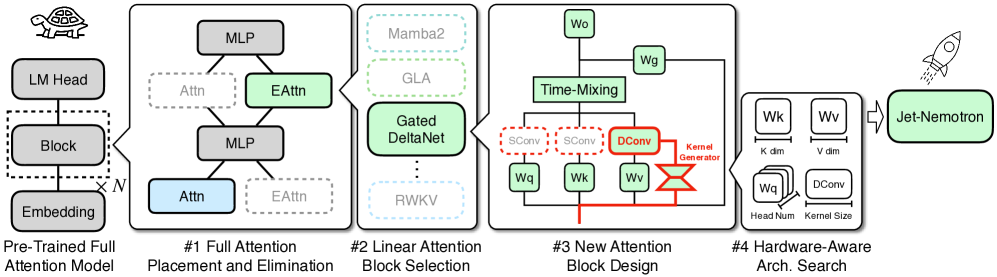
上图展示了 PostNAS 的发展路线图。它从预先训练的全注意力模型入手,冻结 MLP 权重,并通过四个关键步骤以由粗到细的方式探索注意力模块的设计:
- 全注意力模块的放置与消除
- 线性注意力模块的选择
- 新的注意力模块设计
- 硬件感知架构搜索

上图展示了这些步骤带来的准确率提升。
3.2 Full Attention Placement and Elimination
引入少量全注意力层已成为提升准确率的常用策略 。标准方法是将全注意力均匀地应用于固定的层子集,其余层则使用线性注意力。然而,这种统一策略并非最优,尤其是在基于预先训练好的全注意力模型的环境中。

论文提出了一种自动高效地确定全注意力层位置的方法。整体方法如上图所示。通过用替代的线性注意力路径扩充预先训练的全注意力模型,构建了一个一次性超级网络。在训练过程中,在每个步骤随机采样一条活动路径,形成一个子网络,并使用特征蒸馏损失进行训练。

训练结束后,执行集束搜索,
以确定给定约束(例如,两个全注意力层)下全注意力层的最佳布局。搜索目标与任务相关:对于
MMLU,选择正确答案损失最小的配置(即最大化
上图(a) 展示了 Qwen2.5-1.5B 的搜索结果。对于每一层,从超级网络中提取相应的子网络,方法是将该层配置为完全注意力机制,同时将其余所有层设置为线性注意力机制。我们评估每个子网络在给定任务上的准确率或损失,并使用热图将结果可视化。我们的分析揭示了三个关键发现:
- 在预训练的全注意力模型中,并非所有注意力层都同等重要。对于MMLU,只有两层具有关键重要性,而对于检索任务,只有两到三层特别关键。
- 不同的注意力层贡献不同的能力。对MMLU准确性至关重要的层不一定是检索任务中的重要层。
- 对于数学推理等复杂任务,注意力重要性模式变得更加复杂。幸运的是,为MMLU和检索识别出的关键层集合已经涵盖了数学所需的大部分关键层。
除了这些关键发现之外,我们还观察到,使用不同的线性注意力操作时,搜索结果保持一致。在最终实验中,我们在 Once-for-all 超级网络训练中使用了 GLA,以简化训练过程并略微提高吞吐量。
3.3 Linear Attention Block Selection
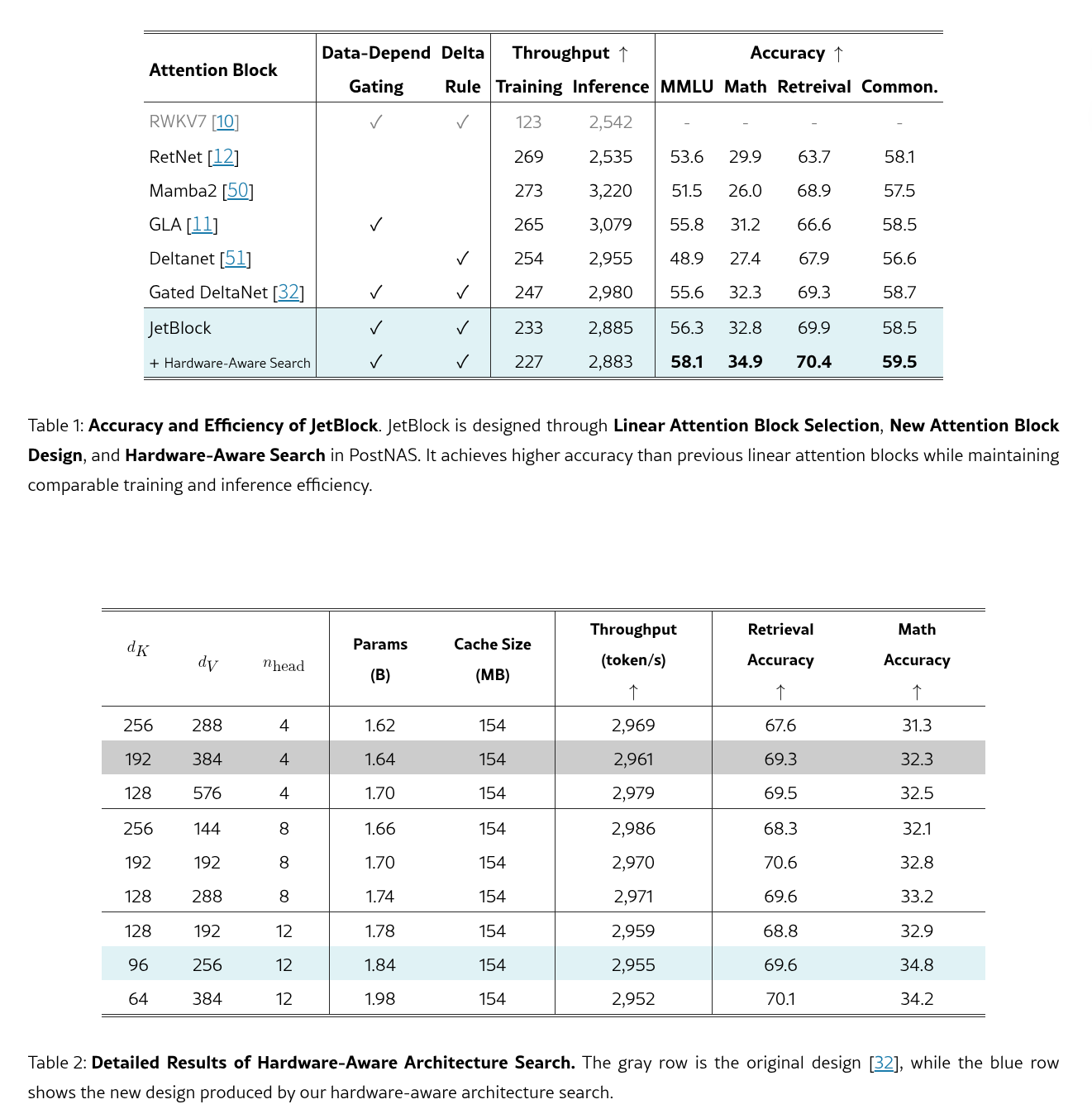
基于已发现的全注意力层布局,我们进行了注意力块搜索,以确定最适合我们设置的线性注意力块。在实验中,我们评估了六个 SOTA 线性注意力块,包括 RWKV7、RetNet、Mamba2、GLA、Deltanet 和 Gated DeltaNet。
在初始效率分析之后,我们观察到 RWKV7 与其他线性注意块相比表现出明显较低的训练吞吐量,这可能是由于内核实现不够理想所致。因此,我们将其排除在训练实验之外。下表中总结的结果表明,门控 DeltaNet 在所评估的线性注意块中实现了最佳的整体准确率。这归因于两个因素的结合:
- 数据依赖型门控机制,它动态控制模型应该更多地关注当前 token 还是历史状态;
- Delta 规则,它使用来自当前 token 的信息增量更新历史状态,以节省有限的状态内存。
因此,我们在实验中继续使用 Gated DeltaNet。
3.4 New Attention Block Design
我们提出了一个新的线性注意力模块 JetBlock,旨在通过将动态卷积融入线性注意力模块来增强模型的表达能力。事实证明,卷积对于在许多线性注意力模块中实现较高的准确率至关重要然而,先前的研究通常使用静态卷积核,这些核无法根据输入调整其特征提取模式。
为了解决这一限制,我们引入了一个内核生成器模块,该模块可以根据输入特征动态生成卷积核。整体结构如上图所示。该模块与 Q/K/V 投影层共享相同的输入,并以线性缩减层开始以提高效率,缩减率为 8。应用 SiLU 激活函数,然后是输出卷积核权重的最终线性层。我们采用 Gated DeltaNet 进行时间混合,因为它与其他设计相比性能最佳,如第 3.3 节所述。
我们将动态卷积核应用于值 (V) 标记,因为将其应用于查询 (Q) 或键 (K) 标记几乎没有任何好处。此外,我们发现,一旦将动态卷积应用于 V,Q 和 K 上的静态卷积就可以被移除,而对最终模型准确率的影响几乎可以忽略不计。我们在最终实验中采用了这种设计,因为它的效率略有提升。表 1 将 JetBlock 与之前的线性注意力模块进行了比较。它在数学推理和检索任务上提供了比门控 DeltaNet 更高的准确率,同时保持了相似的效率。
3.5 Hardware-Aware Architecture Search
在确定宏观架构(特别是全注意力层的放置)并选择线性注意力块之后,我们执行硬件感知架构搜索以优化核心架构超参数,包括键/值维度和注意力头的数量。
传统上,参数大小是指导模型架构设计的主要效率指标。然而,这种方法并非最优,因为参数数量与硬件效率并不直接相关。我们通过将生成吞吐量作为选择架构超参数的直接目标来解决这一限制。我们发现:
- KV缓存大小是影响长上下文和长生成吞吐量的最关键因素。当KV缓存大小保持不变时,具有不同参数数量的模型表现出相似的生成吞吐量(表2)。
这是因为解码阶段通常受内存带宽而非计算能力限制。在长上下文场景中,键值缓存通常比模型权重消耗更多的内存。减小其大小可以减少每个解码步骤的内存传输时间,并支持更大的批处理大小,从而提高生成吞吐量。
根据发现,修复KV 缓存大小以匹配原始设计,并对键维度、值维度和注意力头数量进行小规模网格搜索。表 2 总结了结果,其中所有变体都使用相同的线性注意力块(即 Gated DeltaNet),但具有不同的配置。蓝色行代表最终设计,而灰色行代表原始设计。最终配置实现了与原始配置相当的生成吞吐量,同时合并了更多参数并提高了准确性。从表 1 中我们可以看到,PostNAS 中的硬件感知搜索提高了 JetBlock 的准确性,同时保持了训练和推理吞吐量。
Reference
- Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search
- Jet-Nemotron(GitHub)
- 英伟达新模型上线,4B推理狂飙53倍,全新注意力架构超越Mamba 2
- 【论文阅读】Jet-Nemotron: 高效语言模型与后神经网络架构搜索
- NVIDIA Jet-Nemotron : End of Transformers? 50x Faster LLMs
- Neural Architecture Search (NAS): basic principles and different approaches
- Build the Baseline One-shot Neural Architecture Search by OSNASLib
- 提煉再提煉濃縮再濃縮:Neural Architecture Search 介紹
- NAS(神经结构搜索)学习记录
- 神经架构搜索(NAS)简要介绍
- NAS(神经结构搜索)综述