DiC:重新思考扩散模型中的 3×3 卷积
一、背景
扩散模型现状:
- 主流架构从CNN-注意力混合(如U-Net)转向纯Transformer(如DiT、U-ViT),生成质量优异但推理速度慢(自注意力计算开销大)。
- 加速尝试(如高效注意力、SSM架构)效果有限,难以满足实时需求。
卷积的潜力:
- Conv3x3是硬件友好的极速操作(支持Winograd加速),但传统设计在扩散模型中性能不足(感受野有限,扩展性差)。
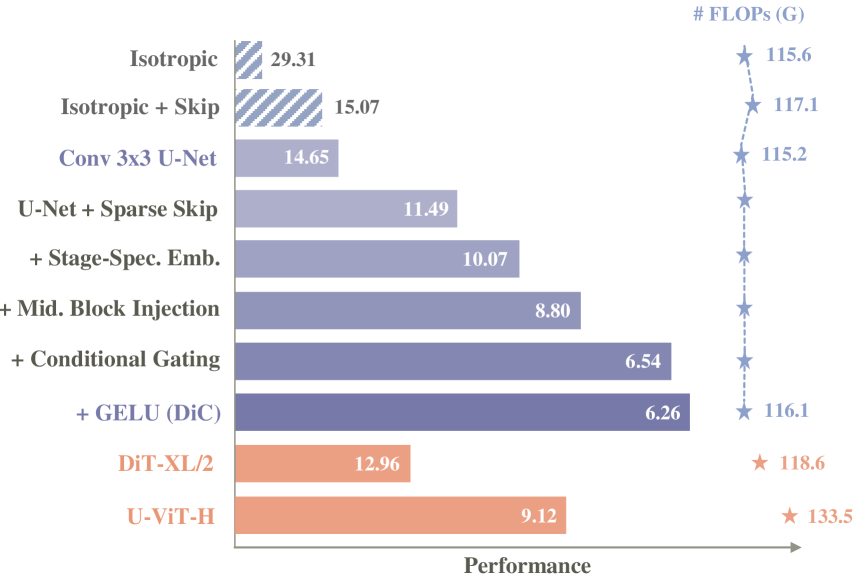
性能通过在训练 200K 次迭代时的 FID(↓)指标进行评估。一系列提出的模型改进使 DiC 相较于 Diffusion Transformer 拥有明显优势。
核心问题
如何设计纯Conv3x3架构,使其在扩散模型中同时实现:
- 高生成质量(对标Transformer)
- 极快推理速度
- 强可扩展性(模型增大时性能持续提升)
二、架构设计
2.1 基础模块:Conv 3x3
选择3x3卷积作为基础操作单元,是因为它速度极快,硬件(GPU)和算法(如Winograd)对其进行了极好的优化,计算量远低于其他卷积类型(如深度可分离卷积),并行度高且内存访问开销小,简单说就是“性价比”最高的基础模块;我们的目标正是仅用这个最简单的积木块来搭建高性能模型。在设计中,我们借鉴了老牌扩散模型(如DDPM的U-Net)中的卷积块结构,但进行了关键简化:直接移除自注意力模块,只保留纯卷积操作。具体而言,每个基本块由GroupNorm、SiLU激活、3x3卷积、GroupNorm、SiLU激活和3x3卷积顺序组成,并采用残差连接(输入直接加到输出上)且通道数保持不变,这构成了纯卷积扩散模型的起点,既保持了结构的简洁高效,又确保了高吞吐量和硬件友好性。
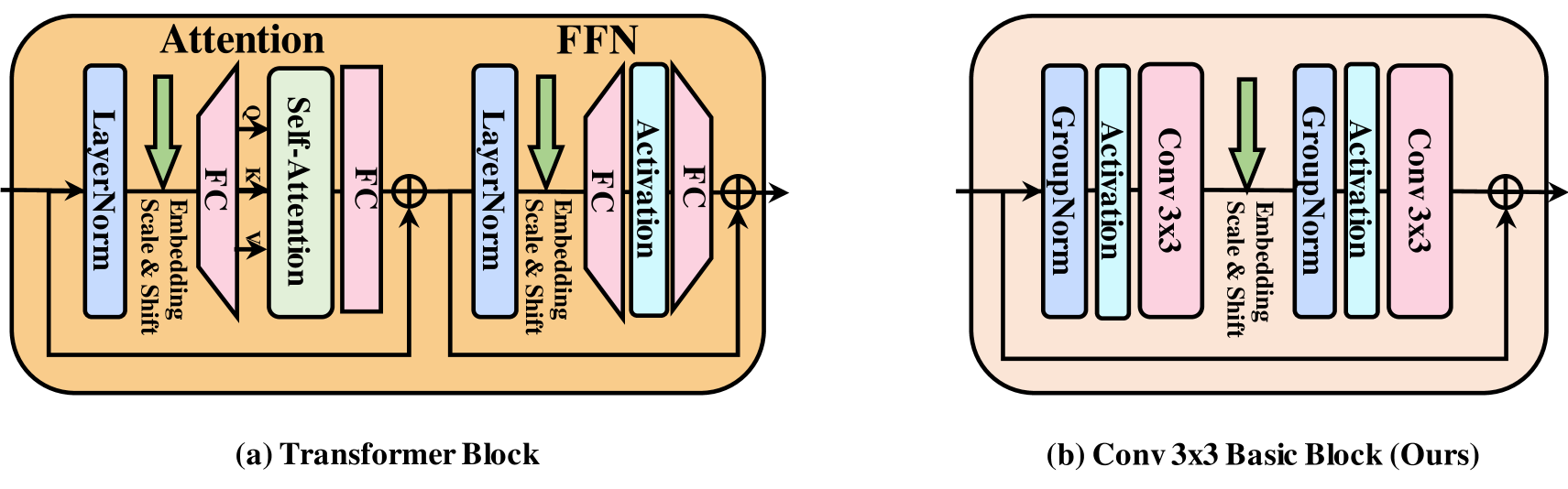
相比于广泛使用的复杂 Transformer 模块,我们的 Conv 3x3 基础模块更加简单,且具有更好的硬件支持,是实现高吞吐量的关键。
2.2 模型结构
几种网络结构的探讨:
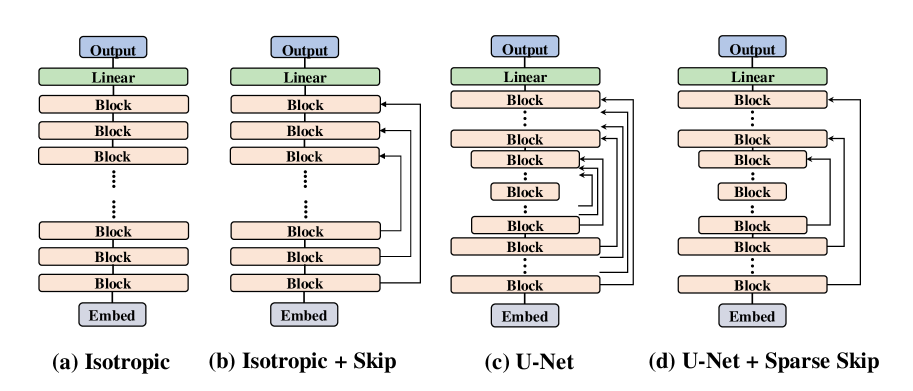
- 直筒型 (Isotropic):像 DiT/Transformer 那样,从头到尾特征图大小不变(不上下采样),就是一层层堆叠基本块。
- 带跳跃的直筒型 (Isotropic + Skip):还是特征图大小不变,但在堆叠的块之间加长距离跳跃连接(像 U-ViT)。
- 沙漏型/U-Net (U-Net Hourglass):5经典编码器-解码器结构。编码器一路下采样(缩小图,增大感受野),解码器一路上采样(放大图),中间还有密集的跳跃连接(把编码器信息直接传给解码器对应层)。
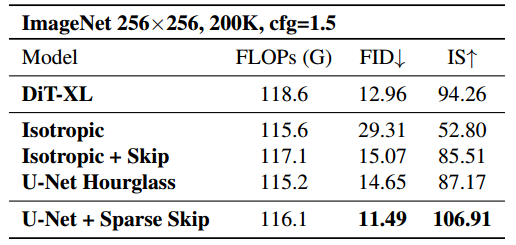
实验分析表明,尽管基于 Conv3×3 的多种架构在初步测试中性能普遍有限,但我们从中识别出若干关键规律,为构建高效的纯卷积扩散模型提供了重要依据。
首先,对于完全由 3x3 卷积组成的扩散模型而言,编码器-解码器沙漏架构是必不可少的。这源于 3x3 卷积的一个基本局限:其感受野天然受限。在一个完全各向同性、类 Transformer 的标准架构中,每个 3x3 卷积仅能在每个方向扩展一个像素的感受野。因此,要获得全局感受野就必须堆叠大量卷积层,从而导致计算与参数上的低效。相较之下,编码器-解码器架构能显著缓解这一限制。通过在编码器中逐步下采样,并在解码器中对称上采样,高层阶段的 3x3 卷积能有效感知输入的更大区域。例如,在较深层级中,一个 3x3 卷积即可覆盖原始图像空间中的 6x6 或 12x12 区域,显著扩大模型的感受野。这种层级结构使模型能够高效捕捉局部与全局上下文信息,使其在生成任务中更加有效。
其次,在基于 Conv3x3 的架构中,跳跃连接至关重要。一方面,在编码器-解码器结构中,它们通过将特征图直接传递给解码器,缓解了下采样过程中的信息丢失,增强了解码器的表达能力。另一方面,跳跃连接通过提供额外的梯度路径与保留关键特征,加速了模型训练并提升了生成质量,从而实现更高效、更有效的扩散建模。
综上所述,我们采用 U-Net 作为主要的模型架构。
通过步进跳跃改进 U-Net。然而,随着我们扩展基于 Conv3x3 的扩散模型,需要堆叠大量卷积层,密集的块级跳跃连接成为一个瓶颈。大量块级跳跃特征必须在对应的解码模块中按通道维度拼接并融合,造成了高昂的计算成本。这种低效性限制了模型的可扩展性。 为了解决这一问题,我们提出了步进跳跃连接(strided skip connections),即每隔几个模块才添加一次跳跃连接,而非每个模块之后都连接。该方法提高了性能,并且我们的实验结果(见上表)显示其相比于密集跳跃连接在生成质量上取得了更优表现。
2.3 其他改进
2.3.1 阶段特定嵌入(Stage-Specific Embeddings)
在传统扩散模型中,以前的模型共享一个唯一的 Embedding。Conv3×3 模型依靠 Encoder-Decoder 结构来扩展感受野。Encoder-Decoder 结构的每个 stage 都使用不同的 channel 进行操作,反映了 stage 之间显著的结构和功能差异。鉴于特征维度因 stage 而异,在不同阶段的所有块上均匀地应用相同的 Condition Embedding 可能不是理想的。单个 Embedding 可能无法充分捕获每个 stage 的不同特征,因此对不同 stage 定制 Condition Embedding 可能更有效。
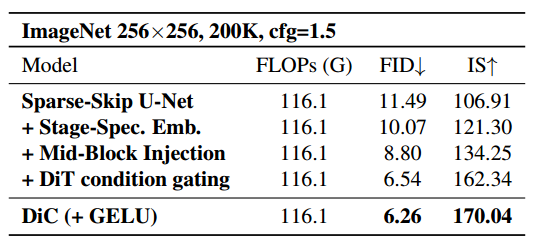
作者提出使用 Stage-Specific 的 Condition Embedding,对每个 stage 使用不一样的 Embedding,Embedding 的维度与这个 stage 的特征维度对齐。值得一提的是,作者分析了 Stage-Specific 的 Embedding 引入的开销。结果显示增加的开销很小。只会令模型大小增加了 14.06M 参数,仅占总模型大小的 2%。引入的计算开销仅增加了 12M FLOPs,对整体计算效率的影响很小。
2.3.2 条件注入位置(Condition Injection Position)
另一个重要的点是确定注入 Condition 信息的最佳位置。扩散模型中有两种流行的条件注入策略。第一种方法在每个 Block 的一开始就注入条件,通常通过 LayerNorm,如 DiT 等模型。第二种方法在 Block 中间引入条件,如 ADM。
通过实验,作者发现对于全卷积扩散架构,将条件注入每个 Block 内的第 2 个卷积层(就是图scale and shift的地方)会产生最佳性能。此放置有效地调制特征表示,在不影响其效率的情况下增强模型的生成质量。
2.3.3 条件门控(Conditional Gating)
那么选好了输入的地方,该怎么输入呢?
为增强条件响应的灵活性,DiC直接借鉴了Diffusion Transformer (DiT) 中的AdaLN机制,引入条件门控(Conditional Gating),其核心不仅对特征图进行常规的缩放(scale)和平移(shift),还额外学习一个通道维度的门控向量,如同为每个特征通道配置可动态调节的“小开关”,实现更精细的特征调控,使模型能自适应不同条件(如图像类别),进一步将FID降至6.54;尽管该设计非原创,但因其高效易集成且收益显著,成为提升模型性能的关键补充。
2.3.4 采用GELU而不是SiLU (借助ConvNeXt的成功经验)
作为一项次要但有效的优化,DiC 模型将原先广泛用于 CNN 的 SiLU(Swish)激活函数统一替换为 Transformer 领域标配的 GELU;这一改动直接借鉴了 ConvNeXt 的成功经验(该工作通过引入 Transformer 风格组件显著提升了 CNN 性能),在 DiC 的纯卷积结构中验证有效——尽管提升幅度有限,却能稳定优化生成质量(FID 指标从 6.54 降至 6.26);作者虽知存在更新的激活函数候选,但为兼顾实现简单性与训练稳定性,最终选择了经过大规模实践验证的 GELU,以最小代价换取可靠收益。
三、实验结果:性能与速度双丰收
3.1 超越 DiT,性能更优
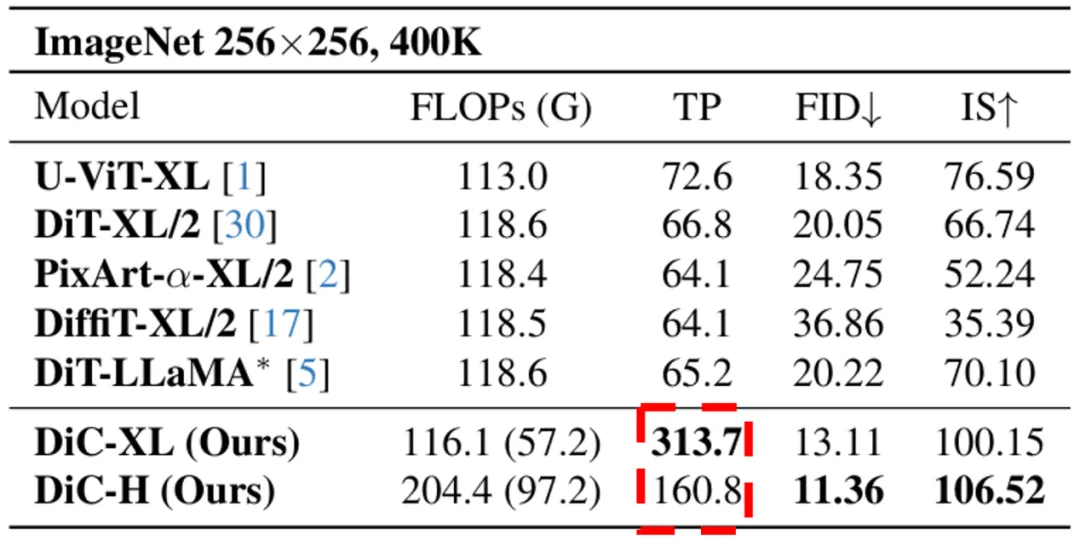
在同等计算量(FLOPs)和参数规模下,DiC 在各个尺寸上都显著优于 DiT。以 XL 尺寸为例,DiC-XL 的 FID 分数(越低越好)从 DiT-XL/2 的 20 降低到了 13,IS 分数(越高越好)也大幅提升,生成图像的质量和多样性都更胜一筹。
DiC 生成能力的超越已经足够亮眼,而速度的优势则更具颠覆性。由于纯卷积架构对硬件的高度友好,DiC 的推理吞吐量(Throughput)远超同级别的 Transformer 模型。例如,在相同模型参数量和算力的情况下,DiC-XL 的吞吐量达到了 313.7,是 DiT-XL/2(66.8)的近 5 倍!
3.2 Scaling Law 上的探索
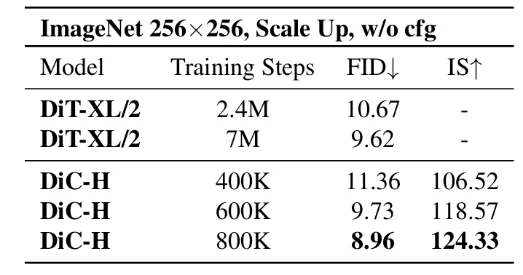
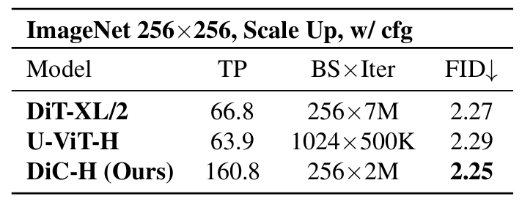 研究者们积极探索 DiC 图像生成能力的上限,发现模型收敛速度快。当不使用
cfg 时,在相同设定下 DiC 的收敛速度是 DiT 的十倍;在使用 cfg 时,FID
可以达到 2.25。
研究者们积极探索 DiC 图像生成能力的上限,发现模型收敛速度快。当不使用
cfg 时,在相同设定下 DiC 的收敛速度是 DiT 的十倍;在使用 cfg 时,FID
可以达到 2.25。

3.3 大图上的探索
当生成图像尺寸扩大时,Transformer 的二次方复杂度问题会急剧恶化。而 DiC 的线性复杂度使其优势更加突出。实验表明,在 512x512 分辨率下,DiC-XL 模型可以用比 DiT-XL/2 更少的计算量,远超后者的速度,达到更好的生成效果。
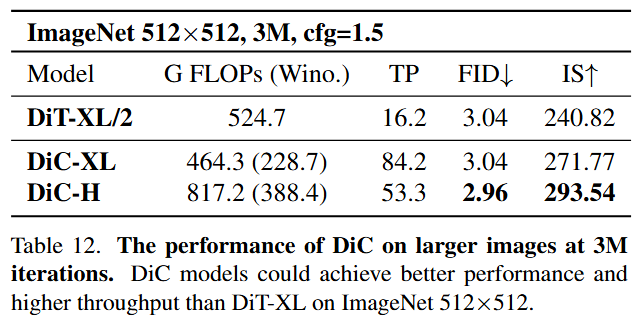
DiC 的出现,有力地挑战了「生成模型必须依赖自注意力」的固有观念。它向我们展示了,通过深入的理解和精巧的架构设计,简单、高效的卷积网络依然可以构建强大的生成模型。卷积,在视觉 AIGC 的广阔天地中仍然大有可为!