Meta世界模型 V-JEPA 2
一、简介
Meta开源发布V-JEPA 2世界模型:一个能像人类一样理解物理世界的AI模型。世界模型简单说,就是能够对真实物理世界做出反应的AI模型。它应该具备以下几种能力:
- 理解:世界模型应该能够理解世界的观察,包括识别视频中物体、动作和运动等事物。
- 预测:一个世界模型应该能够预测世界将如何演变,以及如果智能体采取行动,世界将如何变化。
- 规划:基于预测能力,世界模型应能用于规划实现给定目标的行动序列。
V-JEPA 2(Meta Video Joint Embedding Predictive Architecture 2 )是首个基于视频训练的世界模型(视频是关于世界信息丰富且易于获取的来源)。它提升了动作预测和物理世界建模能力,能够用于在新环境中进行零样本规划和机器人控制。
V-JEPA 2的核心思想是通过自监督学习方法,结合海量互联网视频数据和少量机器人交互数据,构建一个强大的模型,使其能够理解、预测和规划物理世界中的动作。该模型旨在打破传统深度学习对大量标注数据的依赖,展示其在新环境中的适应能力和实用性。
V-JEPA 2 的架构如下,同 Cosmos 一样可以搭配 Robot Data 做 Post-Training,这类 Model 则称为 V-JEPA 2-AC (Action-Conditioned)。
V-JEPA 2 的基础来自于最早的 I-JEPA ,Meta 在这篇论文提出 Joint-Embedding Predictive Architecture (JEPA)的概念。在这之前,先花介绍 Masked Autoencoder ,MAE 是较早提出 Masked Patched Prediction 的模型。
二、MAE (Masked AutoEncoder)
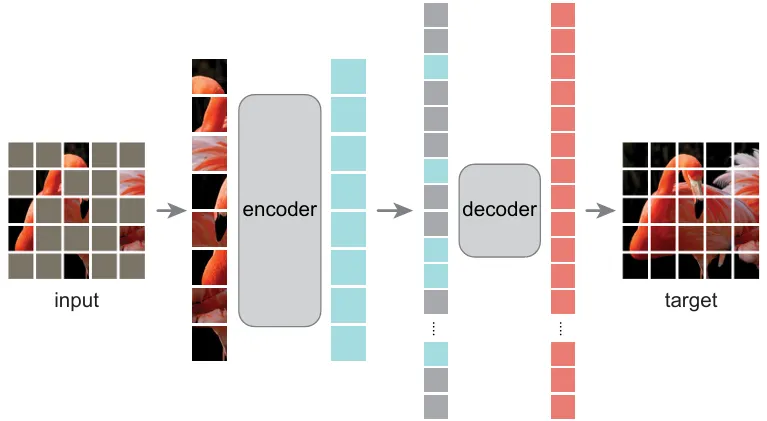
同 I-JEPA,MAE 以一定比例随机 mask 掉图片中的一些图像块(Patch),然后重建他们的像素值(如下图)。

何恺明在 CV 领域提出 Masked Autoencoder 这类想法,也是基于现在模型越来越大,一般玩家根本玩不起。于是在 ViT 的急速发展下,参照 NLP 这边的趋势发展(如 BERT)提出针对 Visual Representation 的 Masked Auto-encoder,其具体架构如下:
2.1 Encoder of MAE
设计重点在于, Encoder 仅处理可见(un-masked)的 Patches
。会将图片切割为多个 Patch。实际切割方法是将图片
将 3 通道影像转为 dim(也就是从 dim
),转换为
由于按照均匀分布随机采样部分 Patches,并将剩余部分 Mask 掉(实验证实 75%的遮蔽比例可以得到最好的效果),因此可以训练一较大较强的 Encoder (可以是 ResNet 或 ViT)。
2.2 Decoder of MAE
Decoder 不仅要处理经过 Encoder 编码的 Un-masked Tokens,还得处理
Masked Tokens。 需注意的是, 所有 Masked Patches 只对应到一个
dim 的 Token。
最后再透过 Position Embedding 区分 Masked Token 的位置信息。
由于会有 dim 的
Token 的条件下,会将该 Token 复制
Decoder 在 Pre-training 时仅用来重建影像,因此在 Downstream 的应用中,就没 Decoder 的事了。也就是 Encoder 和 Decoder 是解藕的,主要是 Encoder 在学习影像特征。因此 MAE 的 Decoder 通常可以设计得很轻量 ,搭配 Unmasked Patch 数有限的 Encoder,可以达到非常好的执行速度。
2.3 Loss Function
MAE Pre-training 的目标是重建 Masked Patch 的 Pixel 值,计算 Loss 的方式即 MSE 。
在 Decoder 解码后的所有 Tokens 中取出 Masked
Tokens,并送入全全连接层,映射到一个 Patch 的像素数量
三、Image JEPA (I-JEPA)
粗略将elf-Supervised Learning分成两类:
Invariance-based Method:Invariance-based 的方法试着学习一 Encoder,能将裁减,旋转,缩放,Color Jittering 等人工后处理过的同一张影像,生成相似的 Embedding。这样的作法容易造成模型有偏见,对 Downstream 的任务有害。
Generative (Reconstruction) Method:预测模型是 Generative Method 的核心,试着预测并补全有缺陷的内容,其中 Masked Denoising 的学习法几乎不需对图片做任何人工后处理,因此可以得到范化性较佳的表示预测能力。然而这类 Generative Method 得到的表示通常在下游任务表现得不如 Invariance-based Method,原因是 Generative Method 学习到的语意(Semantics)不够深入。
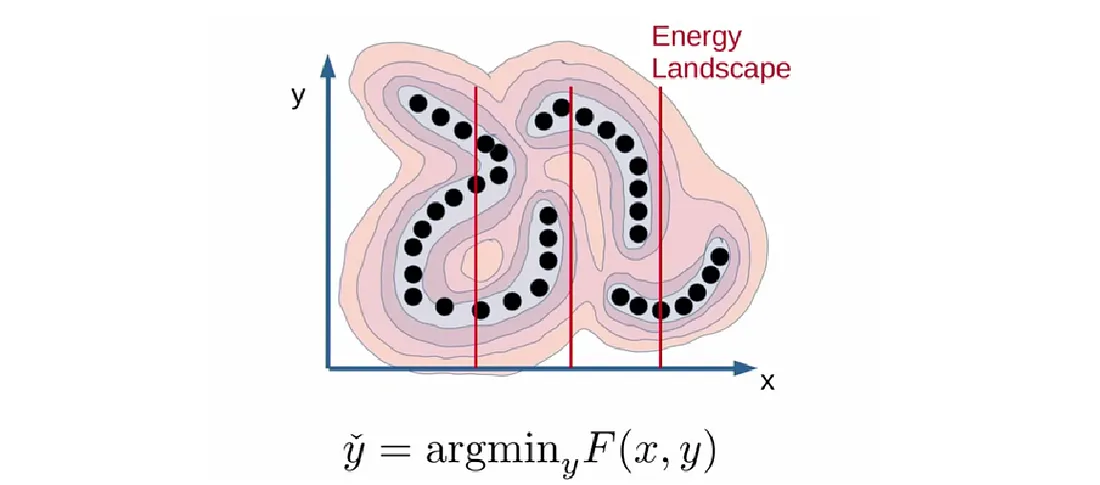
3.1 Energy-based Model
Meta 提出 JEPA 的架构,试着让 Self-Supervised Learning 保有范化性以及较为深度的语意学习。
从 EBM 的角度来看,Self-Supervised Learning 的目的即是给予不匹配的输入输出较高的能量,给予匹配的输入输出较低的能量,参考下图,即是在 Energy Landscape 上找到较低的点:
透过 EBM 的框架,Self-Supervised Learning可以分为以下三种架构:
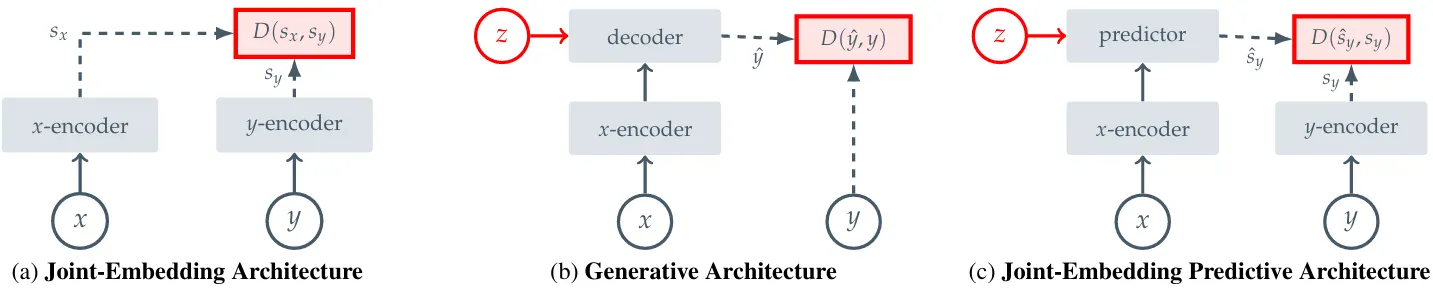
3.1.1 Joint-Embedding Architecture
首先来看上图左边 JEA,事实上 Invariance-based Method
即是被归类在这个架构。 Encoder 试着 Output 相似的 Embedding 给匹配的输入
JEA 最大的问题是 Representation Collapse,以 Energy-based Model 来看,可以想像成 Energy Landscape 非常的平坦,也就是 Encoder 无法区分输入与输出的组合,都只给予一常数值。
3.1.2 Generative Architecture
如上图中间所示,生成式架构试着透过 Decoder 加上 Latent Variable
这边可以透过上面的 Masked Autoencoder 来说明。
3.1.3 Joint-Embedding Predictive Architecture
与 Generative Architecture 不同的地方在于,JEPA 是在 Embedding Space 进行预测以及比对。举 I-JEPA 为例,许多不重要的 Pixel-level 信息得以被忽略。
与在pixel/token空间中预测的生成方法相比, I-JEPA
使用抽象的预测目标,
从而可能消除不必要的像素级细节,从而使模型学习更多的语义特征。JEPA 与
JEA 一样,会有 Representation Collapse 的问题,因此设计上采用非对称的
Encoder,也就是输入的 context
3.2 Method and Design of I-JEPA
I-JEPA 设计上与 MAE 类似,都采用 Masking 的设计,如下图所示:
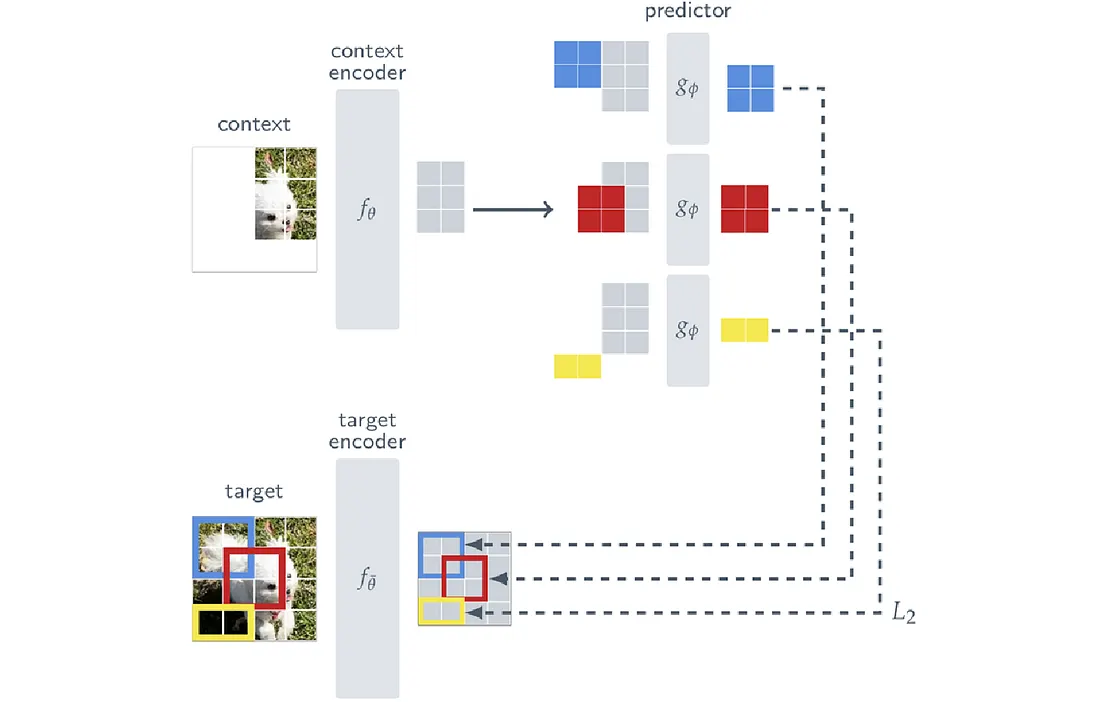
MAE 是属于 Generative Architecture,输入
3.2.1 TargetMeta还透露了公司在通往高级机器智能之路上的下一步计划。
目前,V-JEPA 2只能在单一时间尺度上学习和进行预测。
然而,许多任务需要跨多个时间尺度的规划。
所以一个重要的方向是发展专注于训练能够在多个时间和空间尺度上学习、推理和规划的分层次JEPA模型。
另一个重要的方向是多模态JEPA模型,这些模型能够使用多种感官(包括视觉、音频和触觉)进行预测。
Target 指的就是某些 Image Blocks 所对应的 Embedded Representation,整个 Target 的设计流程如下:
给定一张 Image
接着从
这里要注意的是,Blocks 是透过 Masking Target Encoder 的 Output 获得,而不是 Input。
3.2.2 Context
I-JEPA 的目标是透过 Context Block,预测被 Masked 掉的 Target Blocks
Representation。设

将 Context Block
3.2.3 Prediction
Predictor 的目的即可定义为,给定
与 MAE Decoder 相似,Mask Target Token
3.2.4 Loss
由于我们有 M 个 Target Blocks,因此会 Predict M 次。 Loss
的计算单纯去计算这 M 次预测的 Embedded Representation Vector 与
3.2.5 Result
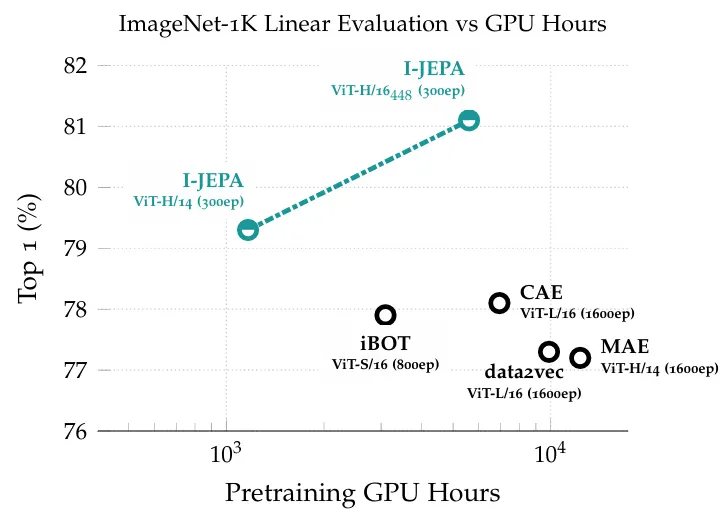
下图显示出 I-JEPA 架构在 Performance 以及训练时间上的优异表现:
四、V-JEPA
作为 Feature Predictor,V-JEPA 的任务就是找出不同 Frame 背后 Representation 的关联。而 JEPA 就是透过预测遗失的信息来学习这种 Representation 之间的关联性。通过预测特征空间中的缺失信息来学习表示的想法也是联合嵌入预测架构(JEPA)的核心。
4.1 Methodology
下图 JEPA 架构:
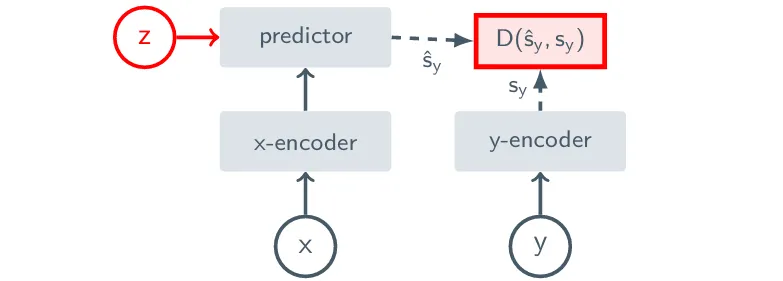
V-JEPA 这边的目的跟 I-JEPA 相同,即 Video 片段
其中
4.2 Theoritical Motivation
BYOL中介绍了避免
Representation Collapse 的策略,V-JEPA 将其延伸至 L1 Loss
的分析。为方便解释,先无视 Conditioning Variable
之前的
其中 MAD 指的是 Median Absolute Deviation。这代表 Encoder 必须尽力吸取影片的资讯,缩小与 Target 之间的 Deviation,避免 Representation Collapse。
4.3 Prediction and Network Parameterization
延续 I-JEPA 的 Masking 策略,Target
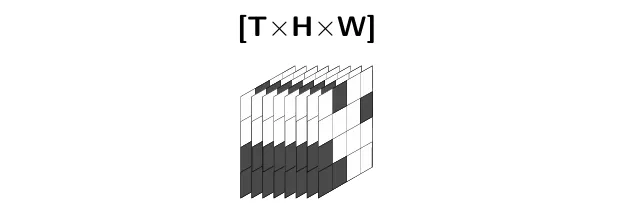
V-JEPA 同样采 Vision Transformer (ViT)作为骨干,其中影像被切为
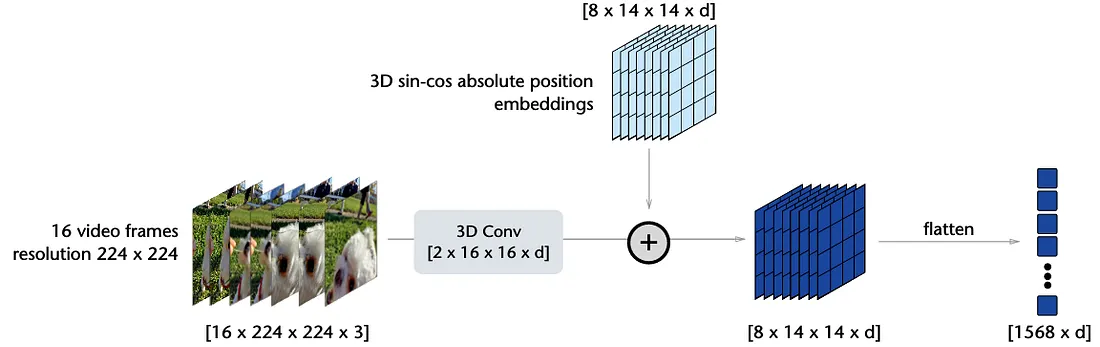
而这些 Patch Tokens 会直接被送入 Transformer 做编码,如下:
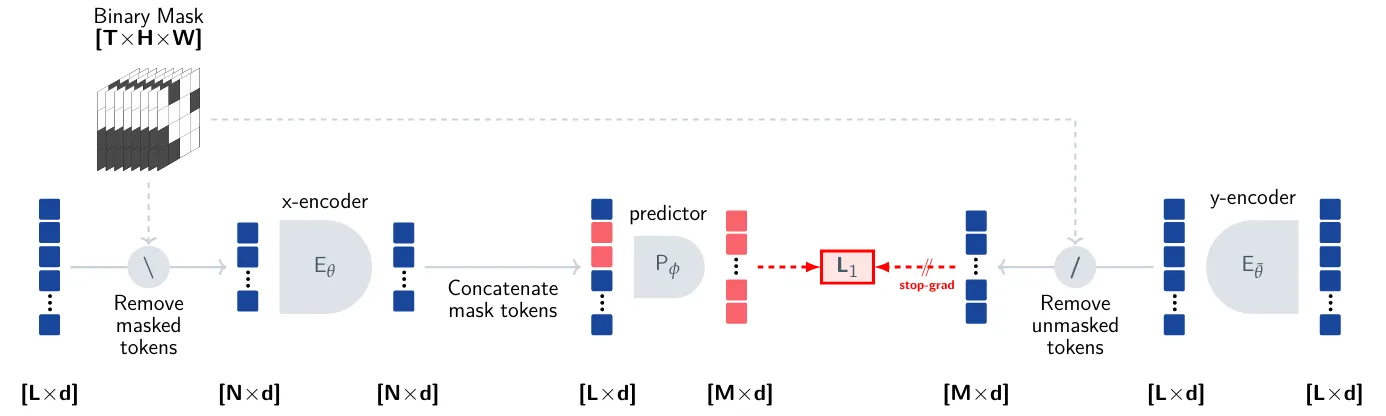
4.4 Evaluation
下图为 V-JEPA 在 Downstream Tasks 的比较:
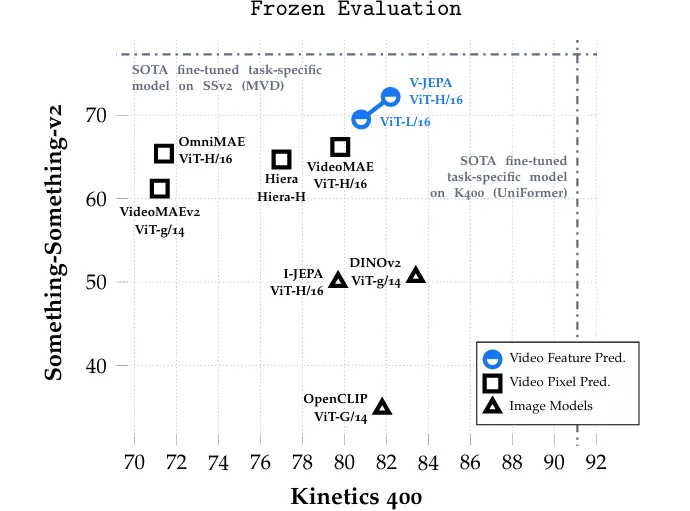
其中 V-JEPA 利用 Attentive Probing 的方式来评估整体的 Frozen Backbone。
Attentive Probing 与 Linear Probing 的主要区别在于:在编码器(Encoder)与线性分类头之间加入了一个跨注意力(cross attention)模组 。该模组将编码器输出的表征作为键(key)和值(value),同时额外设置了一个可学习的类别标记(class token)作为查询(query)。
五、V-JEPA 2
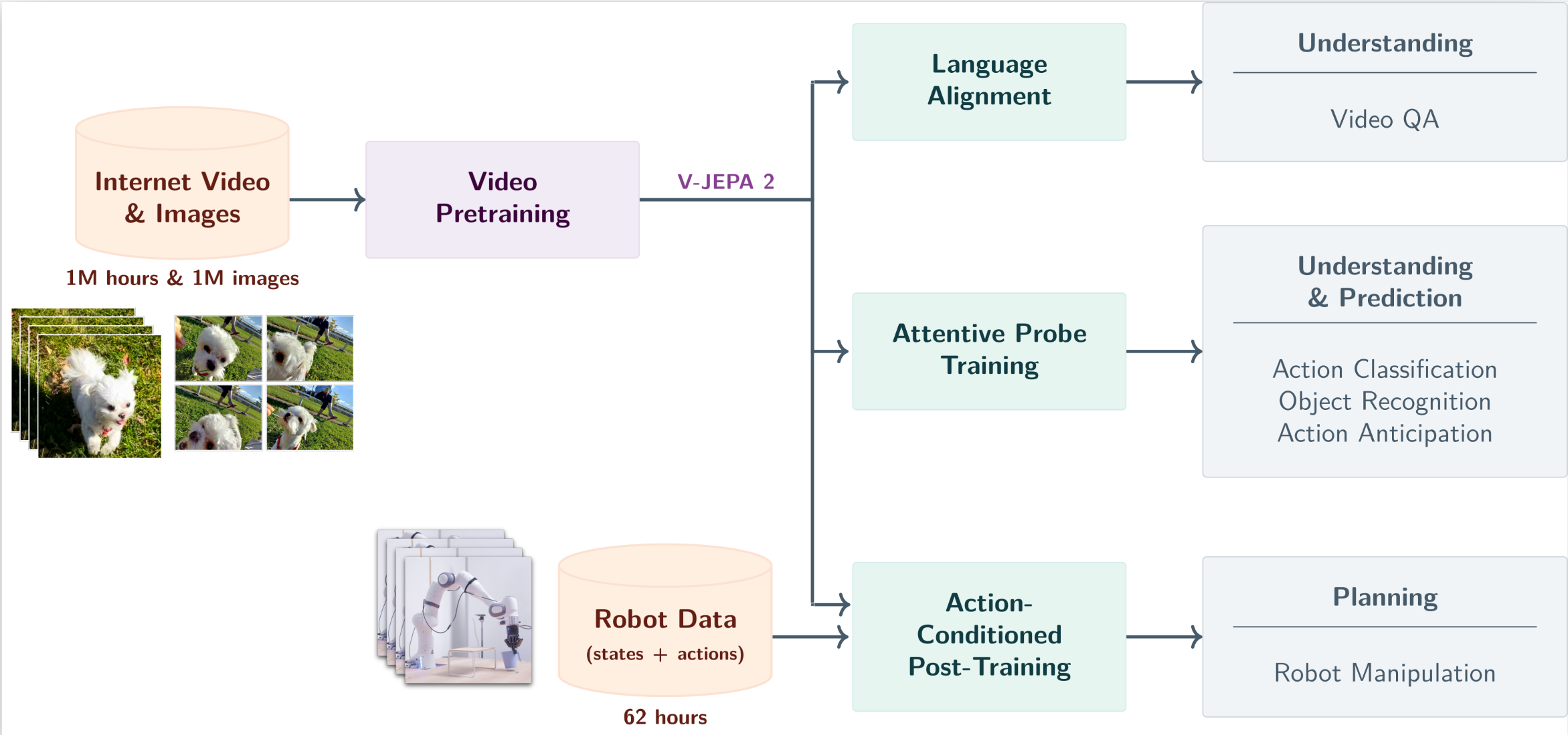
V-JEPA 2 在 V-JEPA 的基础上,扩增了参数,训练资料等规模,并加入 Robot Control 的资料,Post-train V-JEPA 2-AC 模型。
上图清晰地展示了如何从大规模视频数据预训练到多样化下游任务的全过程:
输入数据:利用100万小时互联网视频和100万图片进行预训练。
训练过程:使用视觉掩码去噪目标进行视频预训练。
上图可以看出 V-JEPA 2 所能达成的四种任务:
Understanding — Probe-based Classification:透过 Attentive Probing,V-JEPA 2 在 Something-Something v2 的语义分类上可以达到很好的效果。
Understanding — Video Question-Answering:V-JEPA 2 编码器也可以用来训练 Multi-modal 的 LLM,用来针对影片回答问题。
Prediction:透过Attentive Probing,V-JEPA 2在Epic-Kitchens-100的Human-action Anticipation任务中表现不俗。
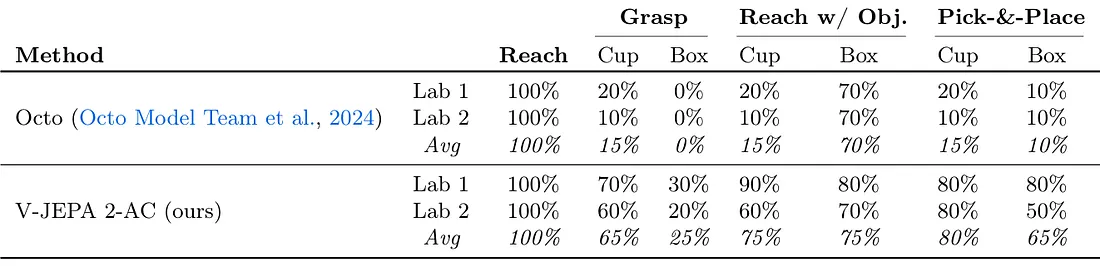
Planning: Post-training (62 小时的 Unlabeled Droid Dataset)后的 V-JEPA 2-AC,可以在新环境中做到如 Grasp 与 Pick-and-Place 等任务,达到 Zero-shot 的效果。
V-JEPA 2采用联合嵌入预测架构(JEPA),主要包含两个组件:
- 编码器:接收原始视频并输出能够捕捉有关观察世界状态的语义信息的嵌入。
- 预测器:接收视频嵌入以及关于要预测的额外上下文,并输出预测的嵌入。
研究团队用视频进行自监督学习来训练V-JEPA 2,这就能够在无需额外人工标注的情况下进行视频训练。
5.1 Architecture
V-JEPA 2的训练涉及两个阶段:先是无动作预训练(下图左侧),然后是额外的动作条件训练(下图右侧)。
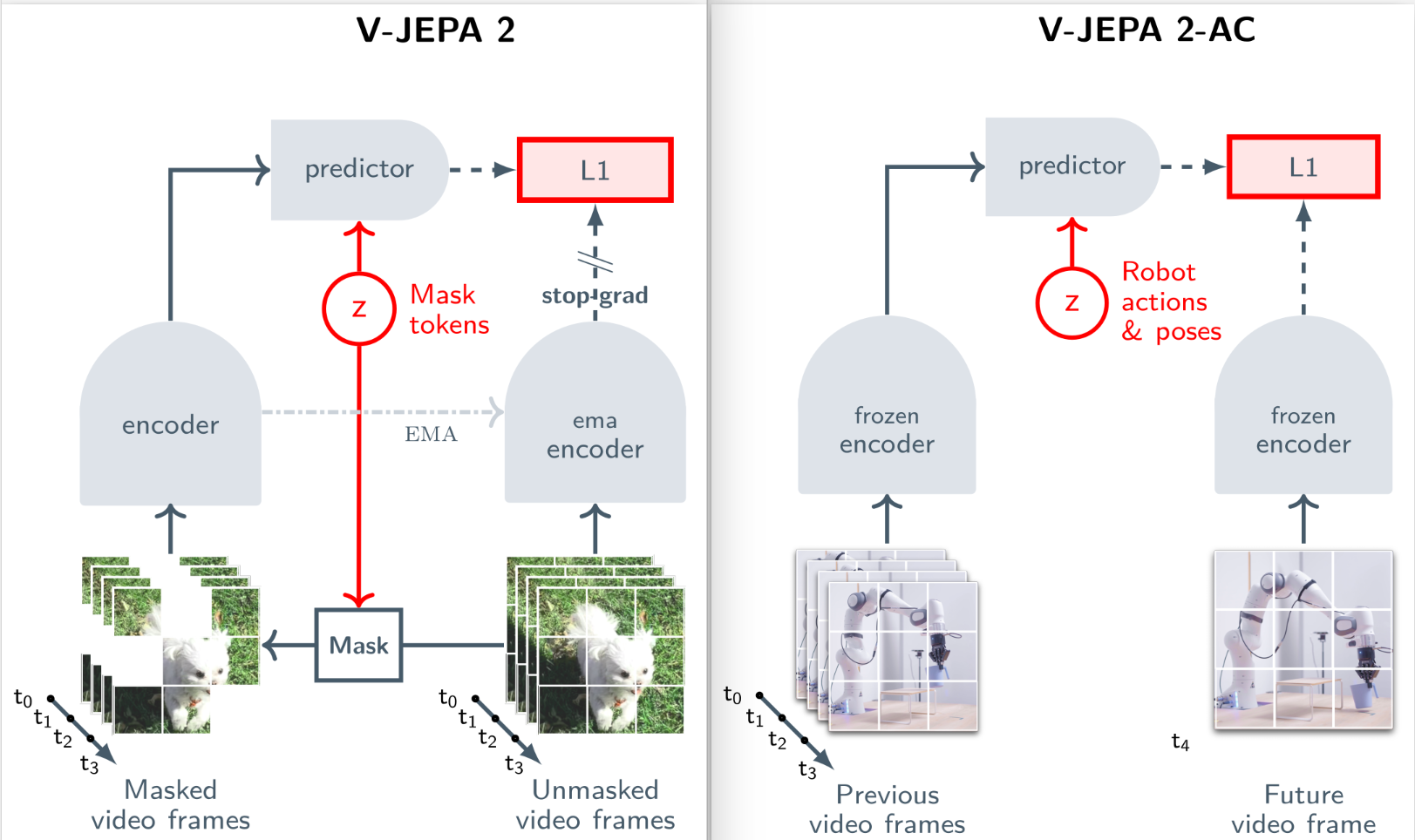
与 V-JEPA 相同,Target Encoder 同样是 Context Encoder 的 EMA (Exponential Moving Average。不同的地方在于,V-JEPA 2 采用了 RoPE 的位置编码,而非传统的 sincos 位置编码。
5.2 V-JEPA 2-AC: Learning an Action-Conditioned World Model
Pre-train 过的模型基本上有预测影片的能力,而 V-JEPA 2-AC 即是基于该 Pre-train 模型的 Encoder 再去训练一 Predictor,参考上图右侧。
V-JEPA 2-AC 的最终目的是训练出一强大的世界模型,以至于 Actor 只须采取传统 MPC 的控制方式。我们的目标是采用预训练后的 V-JEPA 2 模型,并获得一个潜在世界模型,该模型可用于通过闭环模型预测控制来控制具体代理系统。
5.3 Model Inputs
从 Droid Dataset 中 Sample 4 秒的影片,FPS 4,故总共 16 个
Frame。与之对应的 End-Effector 状态序列
而 Action 序列
5.4 Model Loss
5.4.1 Teacher Forcing Loss
16 个 Frame 经过 Pre-trained Encoder 后可以得到 Feature Maps
其中,
5.4.2 Rollout Loss
另外设计 Rollout Loss 以加强 Autoregressive 模型的预测能力。 Loss 公式如下:
实际上就是将 Predictor 的输出,再次当作 Predictor 的输入进行预测,如下图右侧:
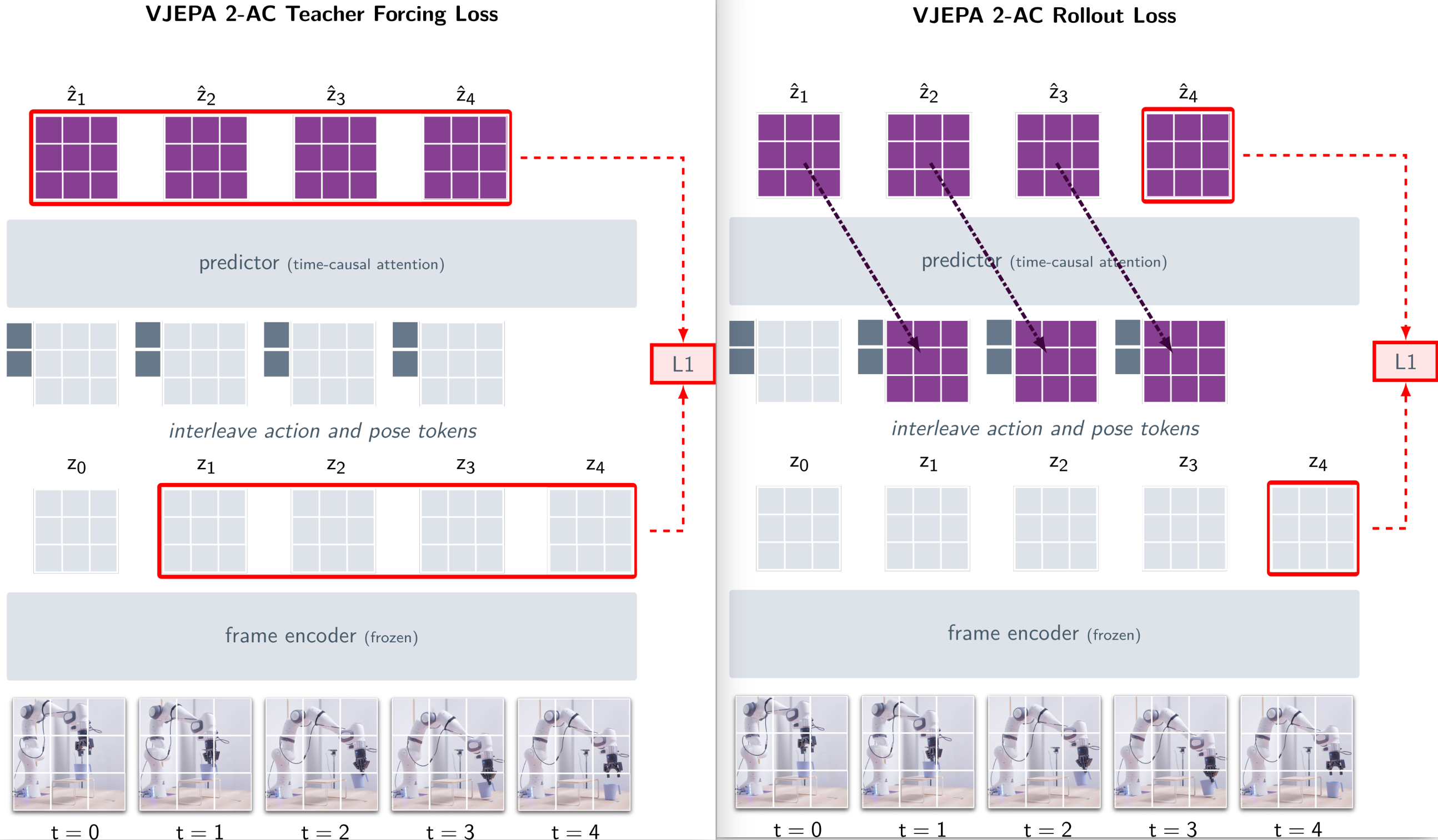
Totol Loss就是Teacher Forcing Loss + Rollout Loss
5.4.3 Model Predictive Control
给定 Goal State 的影像 , V-JEPA 2-AC 的 Downstream Task 即是透过 Planning 达到该 State。
MPC 在每个 Time Step 我们都会规划出一段时间内的 Action Sequence,来 Minimize Goal-conditioned Energy Function。接着只采取第一个 Action,在之后每个 Step 都再 Re-planning。
设当下 End-effector State 为
也就是
参考下图,模型选取的 Action Sequence 即是一可以 Minimize World Model 在 T Steps 后生成的 Representation 以及 Goal Representation 之间 L1 Distance 的 Trajectory。
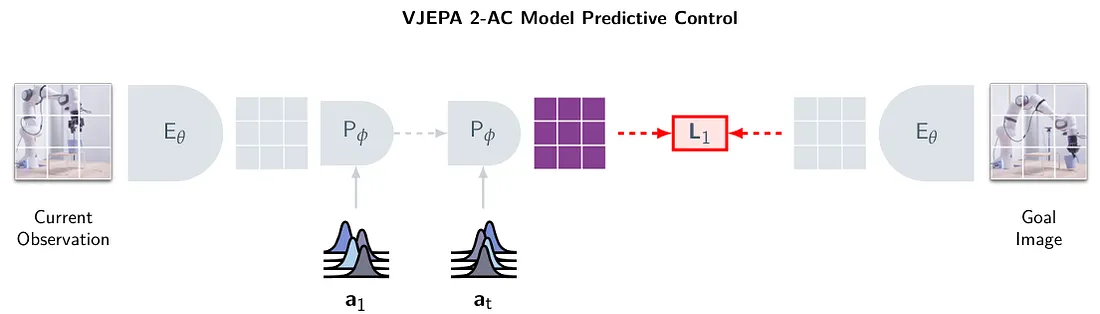
通过最小化世界模型的想象状态表示
5.4.4 Model Predictive Control
与 Octo VLA 模型比较结果如下:
与 Nvidia Cosmos 的比较结果如下:

六、Benchmarking physical understanding
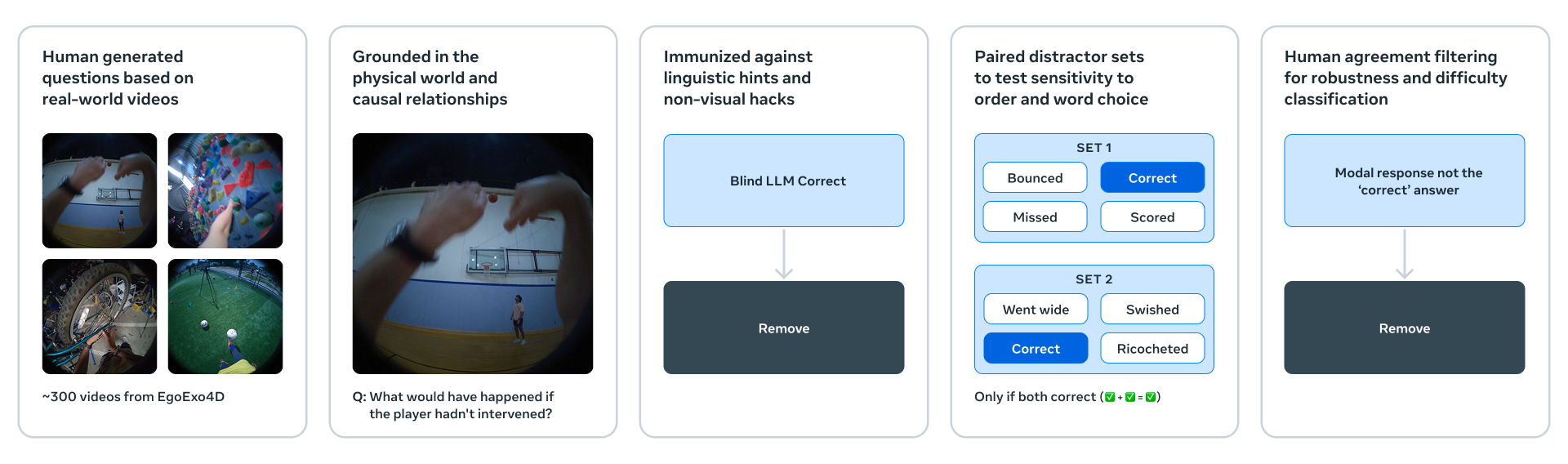
Meta还发布了三个新的基准测试,用于评估现有模型从视频中理解和推理物理世界的能力。
虽然人类在所有三个基准测试中表现良好(准确率85%–95%),但人类表现与包括V-JEPA 2在内的顶级模型之间存在明显差距,这表明模型需要改进的重要方向。
IntPhys 2是专门设计用来衡量模型区分物理上可能和不可能场景的能力,并在早期的IntPhys基准测试基础上进行构建和扩展。
团队通过一个游戏引擎生成视频对,其中两个视频在某个点之前完全相同,然后其中一个视频发生物理破坏事件。
模型必须识别出哪个视频发生了物理破坏事件。
虽然人类在这一任务上在多种场景和条件下几乎达到完美准确率,但当前的视频模型处于或接近随机水平。
Minimal Video Pairs (MVPBench)通过多项选择题测量视频语言模型的物理理解能力。
旨在减轻视频语言模型中常见的捷径解决方案,例如依赖表面视觉或文本线索以及偏见。
MVPBench中的每个示例都有一个最小变化对:一个视觉上相似的视频,以及相同的问题但答案相反。
为了获得一个示例的分数,模型必须正确回答其最小变化对。
CausalVQA测量视频语言模型回答与物理因果关系相关问题的能力。
该基准旨在专注于物理世界视频中的因果关系理解,包括反事实(如果……会发生什么)、预期(接下来可能发生什么)和计划(为了实现目标下一步应该采取什么行动)相关的问题。
虽然大型多模态模型在回答视频中“发生了什么”的问题方面能力越来越强,但在回答“可能发生了什么”和“接下来可能发生什么”的问题时仍然存在困难。
这表明在给定行动和事件空间的情况下,预测物理世界可能如何演变方面,与人类表现存在巨大差距。
七、未来计划
Meta还透露了公司在通往高级机器智能之路上的下一步计划。
目前,V-JEPA 2只能在单一时间尺度上学习和进行预测。
然而,许多任务需要跨多个时间尺度的规划。
所以一个重要的方向是发展专注于训练能够在多个时间和空间尺度上学习、推理和规划的分层次JEPA模型。
另一个重要的方向是多模态JEPA模型,这些模型能够使用多种感官(包括视觉、音频和触觉)进行预测。
Reference
- A self-supervised foundation world model
- V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning (GitHub)
- V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning (Paper)
- LeCun世界模型出2代了!62小时搞定机器人训练,开启物理推理新时代
- Meta世界模型 V-JEPA 2:自监督视频模型实现理解、预测与规划
- V-JEPA 2:自监督视频模型助力理解、预测与规划
- Yann LeCun Lecture on JEPA
- Introducing the V-JEPA 2 world model and new benchmarks for physical reasoning
- I-JEPA
- Masked Autoencoder
- 别再无聊地吹捧了,一起来动手实现 MAE(Masked Autoencoders Are Scalable Vision Learners) 玩玩吧!
- 漫談 Energy-based model
- Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
- Revisiting Feature Prediction for Learning Visual Representations from Video
- Bootstrap your own latent: A new approach to self-supervised Learning
- 来看看新一代 MIM 青年 CAE(Context AutoEncoder) 如何克服 MAE 中表征学习不充分的问题
- 十分钟读懂旋转编码(RoPE)