H-Net与动态分块技术
一、简介
当我们阅读文本时,大脑会毫不费力地将字母组合成单词,再将单词组合成有意义的短语。我们不会刻意去思考一个单词在哪里结束,另一个单词在哪里开始,一切自然而然地发生了。然而,事实证明,在人工智能中复制这种自然能力是自然语言处理领域最持久的挑战之一。
几十年来,AI 系统一直依赖于一种名为tokenization的预处理步骤,将文本分解成易于管理的块。目前主流的方法是Byte-Pair Encoding (BPE),它利用统计模式来决定如何拆分文本。虽然这种方法已经为 GPT 模型系列和 Claude 模型系列等众多优秀的语言模型提供了支持,但它也存在一些根本性的局限性,限制了 AI 以类似人类的灵活性处理语言的能力。
BPE 的工作原理看似简单。它分析海量文本,计算特定字符对一起出现的频率。最频繁出现的字符对会被合并成单个 token,并重复此过程,直到系统构建出一个包含常见文本片段的词汇表。下图以一个案例“AI conference in Paris July 2025.”, 展示了 BPE 如何识别像 “AI” 和 “25” 这样的高频字符对,并通过迭代步骤逐步将它们合并成 token,从而展现了这种方法纯粹由频率驱动的本质。
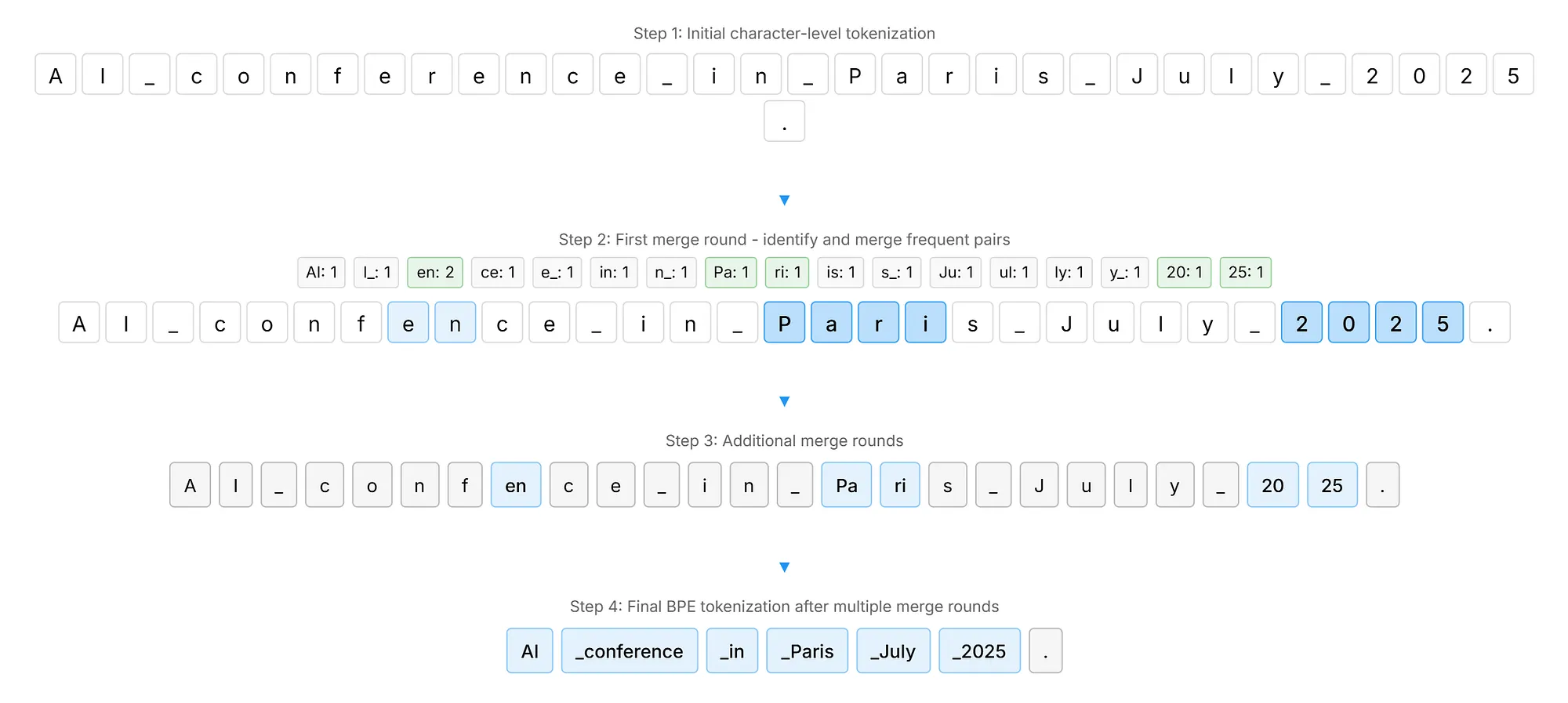
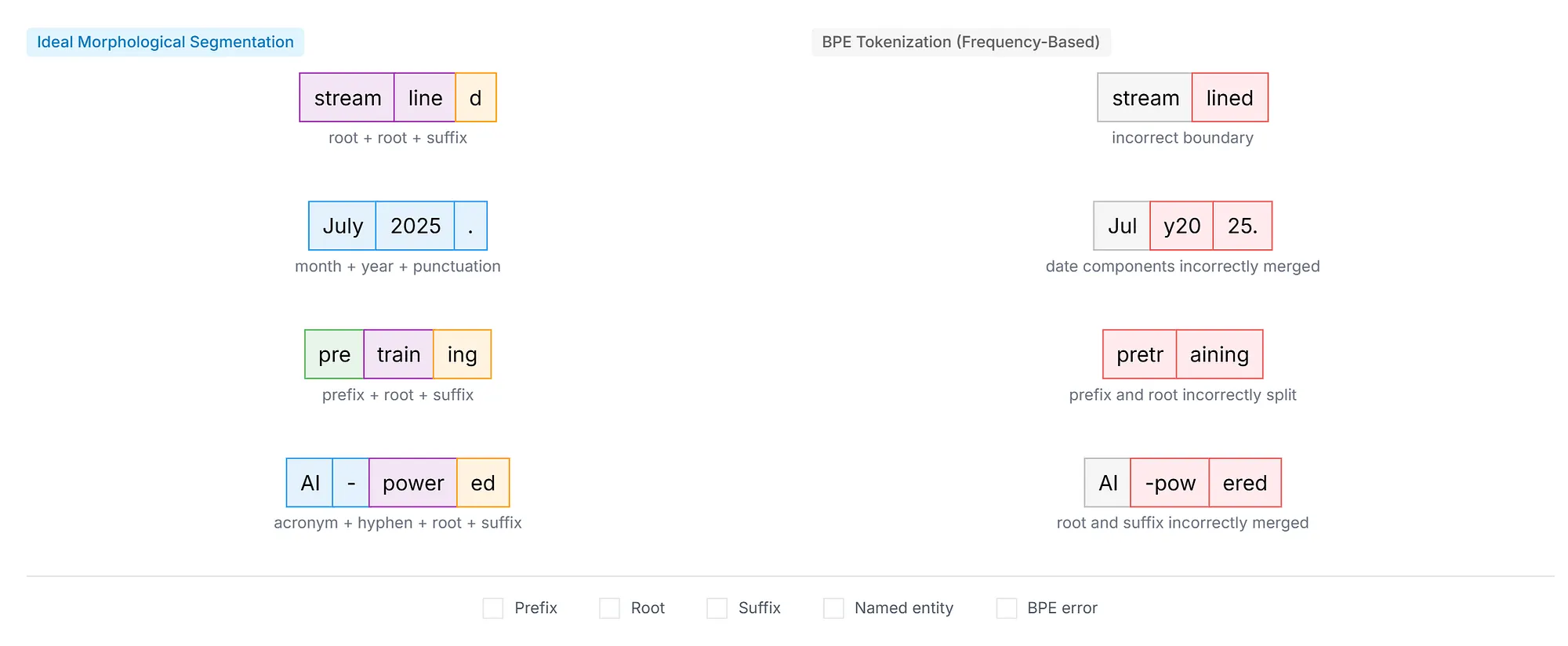
这种基于频率的方法会产生一些问题,研究人员已对此进行了广泛的记录。Bostrom 和 Durrett 在 2020 年的一项研究表明,BPE 常常未能尊重有意义的语言边界。下图提供了一个直观的比较,展示了 BPE 贪婪的构造过程如何经常将有意义的语言单元(例如前缀和后缀)吸收到相邻的tokens中,从而导致分割效果不佳。该图将 “streamlined” (stream + line + d)等词的理想形态边界与 BPE 的实际输出进行了对比,在 BPE 的实际输出中,有意义的词缀被错误地与相邻字符合并,有时会产生缺乏语义连贯性的tokens。
并且有研究表明,BPE 生成了大约 1500 个很少使用的 “垃圾” tokens——这些碎片是在合并过程中产生的,但几乎从未在实际文本中独立出现。下图通过全面的tokens频率分布分析展示了 BPE tokens化中固有的词汇效率低下问题。对数图揭示了tokens使用情况的特征幂律分布,从高频tokens到长尾的很少使用的tokens,急剧下降。
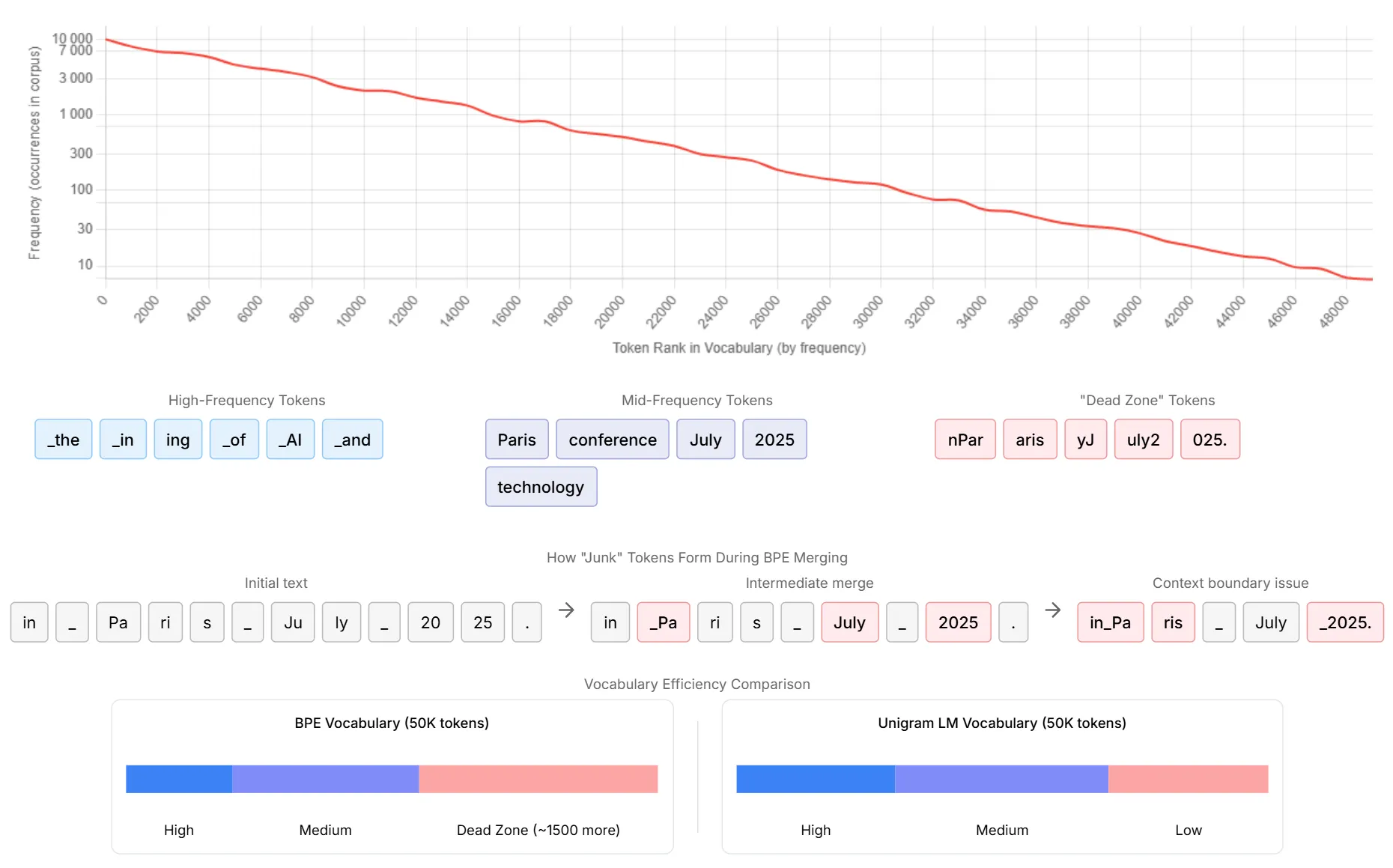
该图将tokens分为三个不同的区域:高频tokens(包括 “the” “in” “ing” “of” “AI” “and” 等常用词),中频tokens(例如 “Paris” “conference” “July” “2025” “technology” )和有问题的“dead zone”tokens(包括 “nPar” “aris” “yJ” “uly2” “025” 等片段)。
底部部分以 “in _ Pa ri s _ July _ 20 25” 为例,说明了 “垃圾” tokens在 BPE 合并过程中是如何形成的。该图展示了中间合并步骤是如何产生伪像的:初始文本在一次合并后变成了 “in Pa ri s July _ 2025” ,在进一步合并后变成了 “in_Pa ris _ July _2025” ,从而产生了上下文边界问题,导致有意义的单元被不恰当地拆分。
底部的词汇效率比较清楚地说明了 BPE 的问题:与 Unigram LM 词汇相比,BPE 词汇包含明显更多的 “dead zone” tokens(约多 1500 个)。这种低效率意味着词汇空间被浪费,而这些空间本可以更好地分配给更有意义的语言单元,这也解释了为什么 BPE 贪婪的、基于频率的构造会导致语言模型训练的tokenization效果不佳。
这些限制不仅仅局限于效率问题。BPE 表现出明显的语言偏见 ,它主要针对英语进行了优化,使其词与词之间有方便的空格。结构不同的语言则面临系统性劣势。中文文本完全没有词义界限,因此经常被拆分成有意义的字符。通过复杂的词形修饰来构建意义的黏着性语言的情况更糟。或许最大的限制在于 BPE 的不灵活性,无论上下文如何,相同的字符序列总是会得到相同的tokens,这意味着系统无法根据不同的领域或含义调整其处理方式。
为了打破这副“枷锁”,来自卡内基梅隆大学和Cartesia AI的研究者们提出了一种名为H-Net(Hierarchical Network,分层网络)的全新架构。其核心是一种革命性的动态分词(Dynamic Chunking, DC)机制,它能够让模型在训练过程中自动学习如何根据内容和上下文进行分段。
二、H-Net 设计与实现
2.1 整体架构:U-Net 的「序列建模」变体
H-Net 的核心思想是构建一个端到端、递归、数据依赖的动态分块机制,让模型自己学会如何「切分」原始数据。它巧妙地融合了层次化结构、创新的动态分块机制和一系列训练优化技巧。
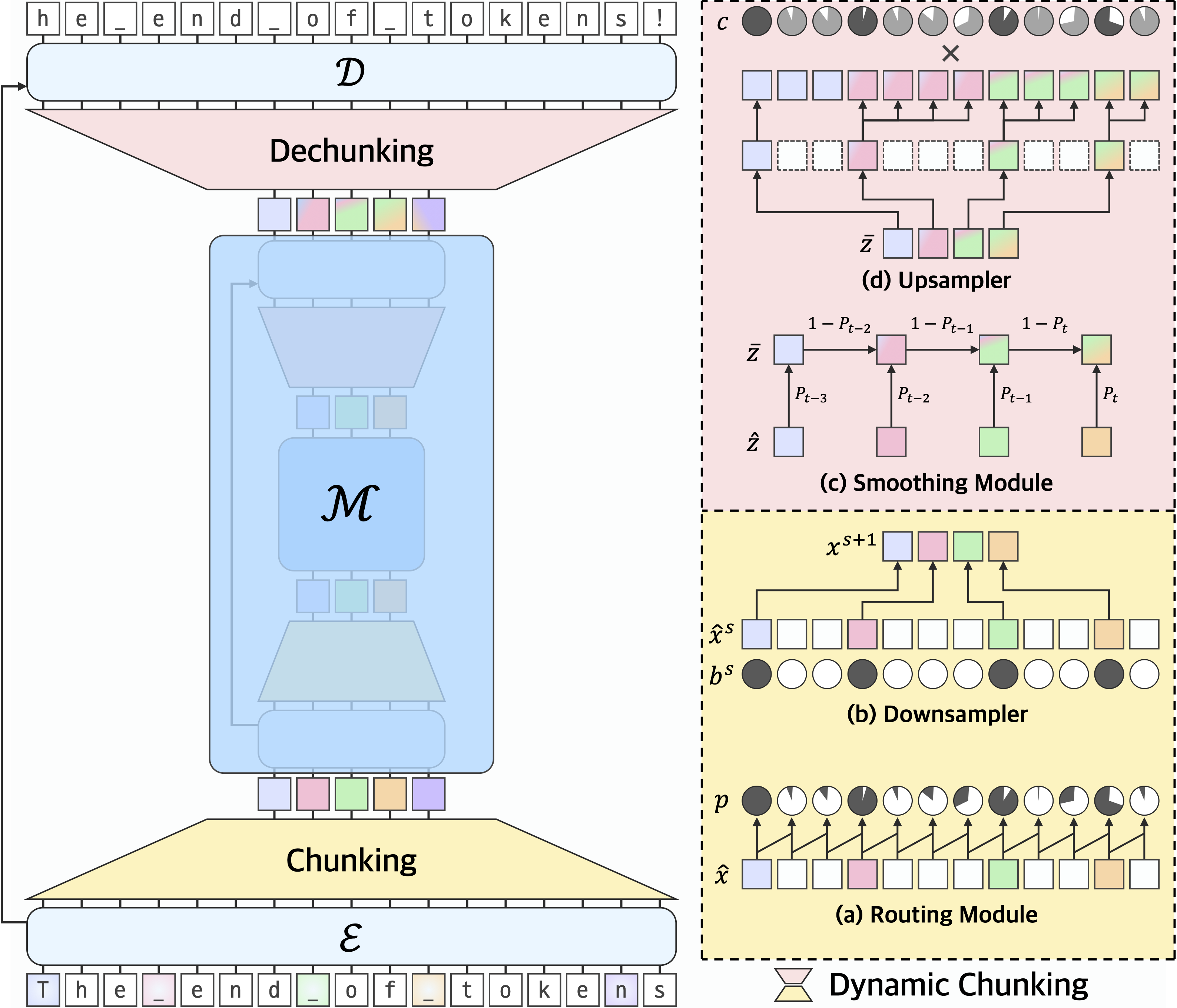
H-Net 借鉴了图像分割领域著名的 U-Net 架构。U-Net 的特点是有一个「下采样」(编码)路径,将图像压缩成更抽象的特征,然后有一个「上采样」(解码)路径,将特征恢复到原始分辨率。同时,编码路径和解码路径之间有跳跃连接(skip connection),用于保留细粒度的信息。
H-Net 将这一思想应用到序列建模中(上图左):
- 编码器网络 (
):接收原始数据(例如字节流),对其进行初步处理,并提取特征。 - 分块层 (Chunking Layer):根据编码器提取的特征,动态地决定哪些部分应该被「压缩」成一个块,并传递给下一层。
- 主网络(
):这是 H-Net 的核心计算单元,参数量最大,负责处理分块层输出的「压缩」表示。它可以在更高层次的抽象上进行复杂的语言理解和建模。 - 解块层 (Dechunking Layer):将主网络处理后的「压缩」表示,动态地解压缩回原始分辨率。
- 解码器网络 (
):接收解块层的输出,并结合来自对应编码器网络的残差连接(保留了原始细粒度信息),最终生成预测结果。
而且,这个主网络(
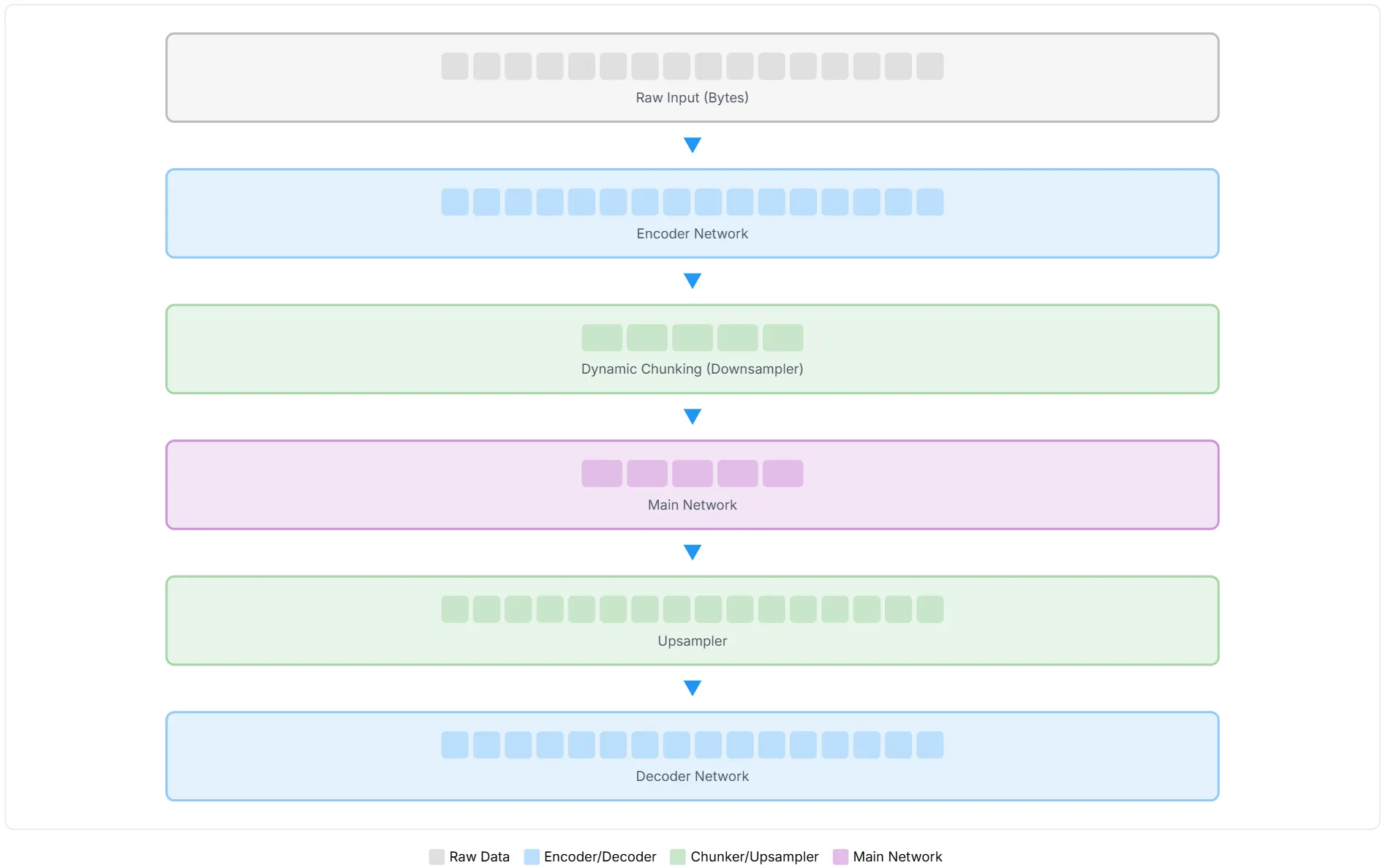
上图展现了 H-Net 如何实现计算效率:包含大量 token 的原始输入序列在中间层被压缩为更小的表示(如主网络中较少的块所示),然后再扩展回原始分辨率。这种分层压缩和解压缩方法使得计算成本高昂的主网络能够在压缩表示上运行,同时保持重建细粒度细节的能力。
2.2 核心机制:动态分块
动态分块(Dynamic Chunking, DC)机制是 H-Net 能够「无分词器」的关键,它由路由模块、下采样器、平滑模块和上采样器组成(见上节图右)。
2.2.1 分块层
分块层的任务是决定在哪里划定「边界」,从而将原始序列压缩成更短的块序列。
在自然语言中,有意义的边界往往出现在语义或上下文发生变化的地方。例如,一个单词的结束,一个句子的结束。
路由模块(Routing Module)
通过计算相邻表示之间的相似度来预测边界。它会从编码器输出的向量中提取查询
其中,
下采样器(Downsampler)非常直接,它根据路由模块生成的

该图有效地展示了动态组块如何适应实际语义内容,将 “AI” 保留为一个独立的、有意义的单元,将 “summit July” 分组为一个连贯的短语,并将 “2025” 保留为一个独特的时间标记。这种基于上下文感知的分割方法与 BPE 的频率驱动方法形成了鲜明的对比,后者可能仅基于字符级统计数据来划分这些有意义的单元。
2.2.2 解块层
解块层则负责将主网络处理后的压缩表示,解压缩回原始分辨率。但这里有一个巨大的挑战:分块决策是离散的(要么分,要么不分)。离散操作通常会导致梯度无法回传,让模型无法通过反向传播来学习如何更好地分块。H-Net 通过以下两个设计解决这个问题:
- 平滑模块(Smoothing Module),将离散的解压缩操作转化为连续可微分的计算。
具体来说,采用指数移动平均(EMA),公式是:
其中,
下图展示了这一点:在处理 …new product!
时,如果分块不理想(如 du
被单独分出),没有平滑模块会导致信息流混乱。有了平滑模块,模型会平滑这些低置信度的分块,确保信息正确传播,并能通过梯度学习更优的边界。
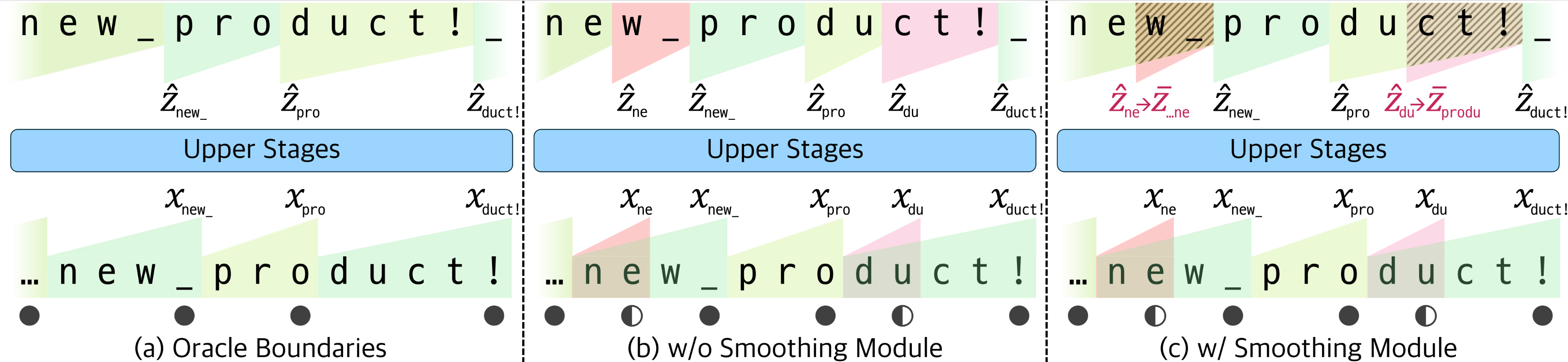
这种平滑处理使得整个解块过程对
其二是上采样器(Upsampler) :
- 引入一个系数
来量化路由模块决策的置信度。它鼓励模型在真正的边界处
- 而且使用了经典的直通估计器(STE)技巧:
- 前向传播时: STE 会将
的值「四舍五入」到 1.0,模拟离散的硬性选择。 - 反向传播时:TE
会「假装」这个四舍五入操作不存在,直接将梯度从下游传递给原始的连续值
。 - 公式:
。 stopgradient操作在前向时不起作用,反向时则阻止梯度流经其参数。
- 前向传播时: STE 会将
- 因果扩展:将每个压缩向量重复到下一个边界位置,确保重建后的每个位置都能获得其最近块的信息。
- 置信度加权解压:最终的解压向量会乘以其置信度分数,进一步激励路由模块做出高置信度、准确的决策。
平滑模块确保了从主网络到解码器这一通路上的梯度连续性,即使中间的「块」可能是不确定的。而 STE 则允许路由模块在生成离散决策的同时,其底层的连续概率也能接收到有效的梯度信号。两者结合,使得 H-Net 能够通过标准的梯度下降方法,端到端地学习和优化其动态分块策略。
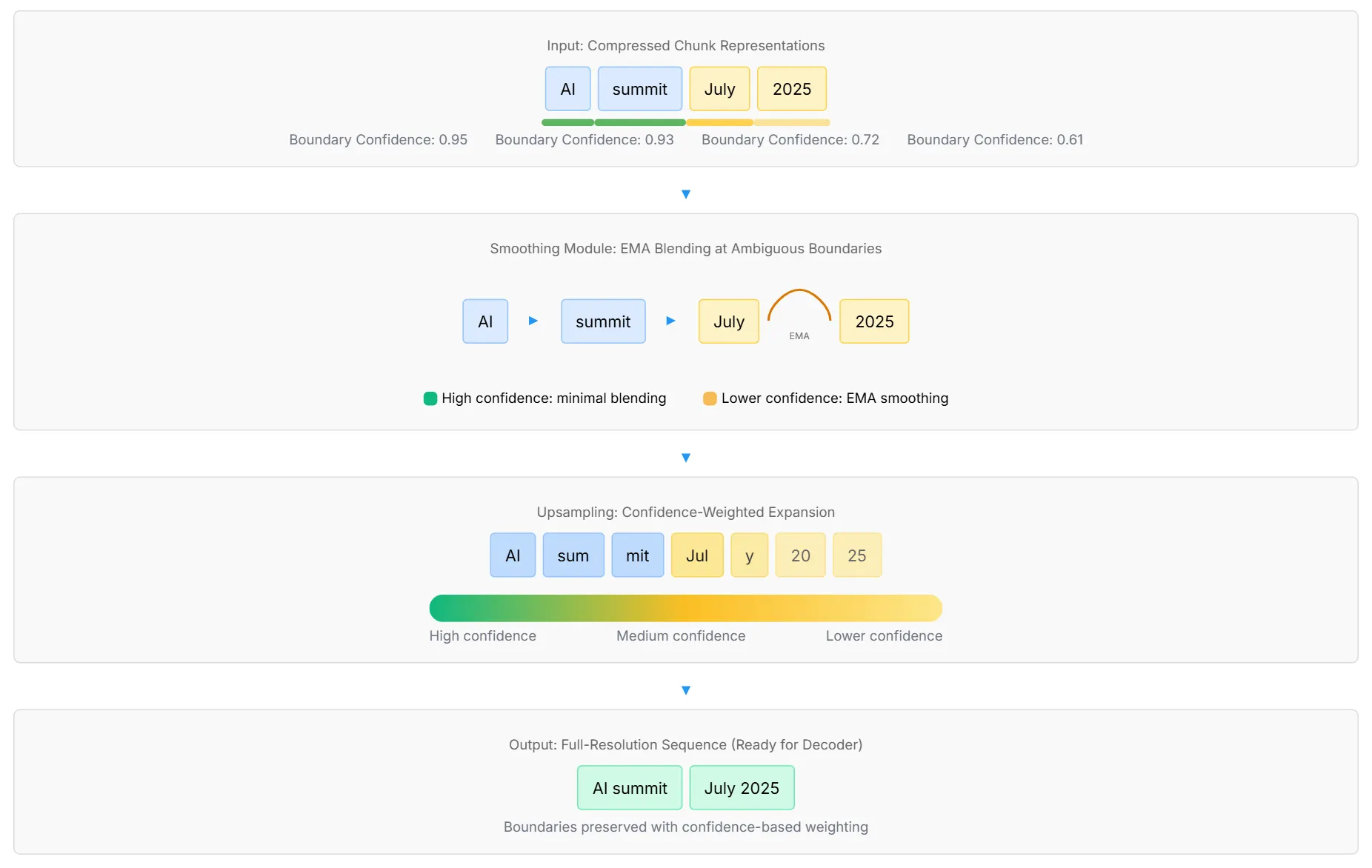
该图有效地展示了平滑和上采样模块如何协同工作,在训练期间保持可区分性,同时学习最佳分割策略,从而创建一个能够处理自然语言分割中固有的模糊性的强大系统。
2.3 架构和优化增强
为了让复杂的 H-Net 能够稳定地训练并高效扩展,论文还引入了一系列重要的工程和优化技巧:
- SSM (Mamba) 作为编码器/解码器:
- 为什么选择 Mamba?实验表明,Mamba-2 层(也是 Albert Gu 团队作品)在处理细粒度数据(如字节)时效率更高,且具有独特的 「压缩」归纳偏置。这意味着 Mamba 更擅长将长序列的信息有效压缩到固定大小的隐状态中,这与编码器将原始输入压缩成更抽象的「块」的任务完美契合。论文的消融实验证实,Mamba 层在编码器/解码器中表现远超 Transformer 层,甚至在处理 BPE token 时也显示出优势,这说明 Mamba 这种「压缩」的归纳偏置是其核心优势。
- 效率与功能兼顾:Mamba 不仅高效,更重要的是它在功能上与 H-Net 的层次化压缩和解压缩机制高度契合。
- 范数平衡(Norm Balance):
- 在深度神经网络中,残差连接(skip connection)非常重要。但如果不同路径的特征范数差异过大,深层网络(如主网络)的输出可能会「淹没」浅层编码器的残差信号,导致细粒度信息丢失。
- 解决方案是, 在每个网络组件(编码器、解码器、主网络)的末尾添加 RMSNorm 层。这确保了特征范数的平衡,让残差连接能够有效地将细粒度信息传递给解码器。
- 两流分离(Separation of Two Streams):
- 编码器的输出既要作为残差连接传递给解码器,又要作为输入传递给下一阶段的编码器或主网络。这两种用途可能需要不同的表示。
- 作者选择只对残差连接添加一个线性投影。这确保了主计算路径的梯度流完整性,同时允许残差连接通过学习到的投影来调整其贡献。
- 比率损失(Ratio Loss)用于控制压缩:
- 如果不加约束,模型可能会学习到极端的压缩策略(要么不压缩,要么过度压缩)。
- 借鉴了 Mixture-of-Experts (MoE) 模型中用于负载均衡的机制。
- 引入一个辅助损失函数
,它鼓励模型将序列压缩到预期的比率 。 其中, 是实际选择的向量比例, 是平均边界概率。这个损失函数鼓励 和 都趋向于目标压缩比 。它让模型在压缩效率和预测精度之间找到平衡,从而学习到内容自适应的分块策略。
- 学习率调制:
- 层次化结构中,不同阶段处理的序列长度和隐藏维度不同,需要不同的学习率来保证训练动态平衡。
- 根据每个阶段的有效批次大小和模型维度,按比例调整学习率(外部阶段学习率更高)。这有助于加速分块机制的学习,并稳定整个层次结构的训练。
2.4 自回归训练与推理
H-Net 的所有组件都精心设计,以保持语言模型中至关重要的自回归(Autoregressive) 特性,确保模型只能看到过去的信息来预测未来。
- 训练:所有序列混合层都使用标准的因果掩码。动态分块机制通过仅依赖当前和先前表示来计算边界概率(如路由模块),并使用递归公式(如平滑模块的 EMA)来保持因果性。
- 推理:H-Net 以一种动态的方式自回归生成原始字节。它能在推理时为每个 token 动态决定使用多少计算资源。对于信息量大、需要复杂推理的字节,它会投入更多计算(激活主网络);对于信息量小、容易预测的字节,则投入更少计算。这与推测解码(speculative decoding) 的概念有相似之处,都是通过动态分配计算来提高推理效率。
三、效果
3.1 核心性能
- 论文将 H-Net 与多种基线模型进行比较,包括传统的 BPE 分词 Transformer (Llama 架构)、纯字节级模型 (LlamaByte, MambaByte)、基于外部启发式分块的模型 (SpaceByte, SpaceByte++) 以及静态分块模型 (H-Net)。
- 所有模型都在计算量 (FLOPs) 和数据预算上与 GPT-3 Large (760M 参数) 和 XL (1.3B 参数) 规模的 Transformer 进行严格匹配。
- 性能指标采用每字节比特数 (Bits-per-byte, BPB),这是一个衡量模型压缩和预测能力的通用指标。顾名思义,就是衡量模型平均需要多少比特来编码或预测一个字节(byte)Z 的信息,越低越好。
训练曲线:
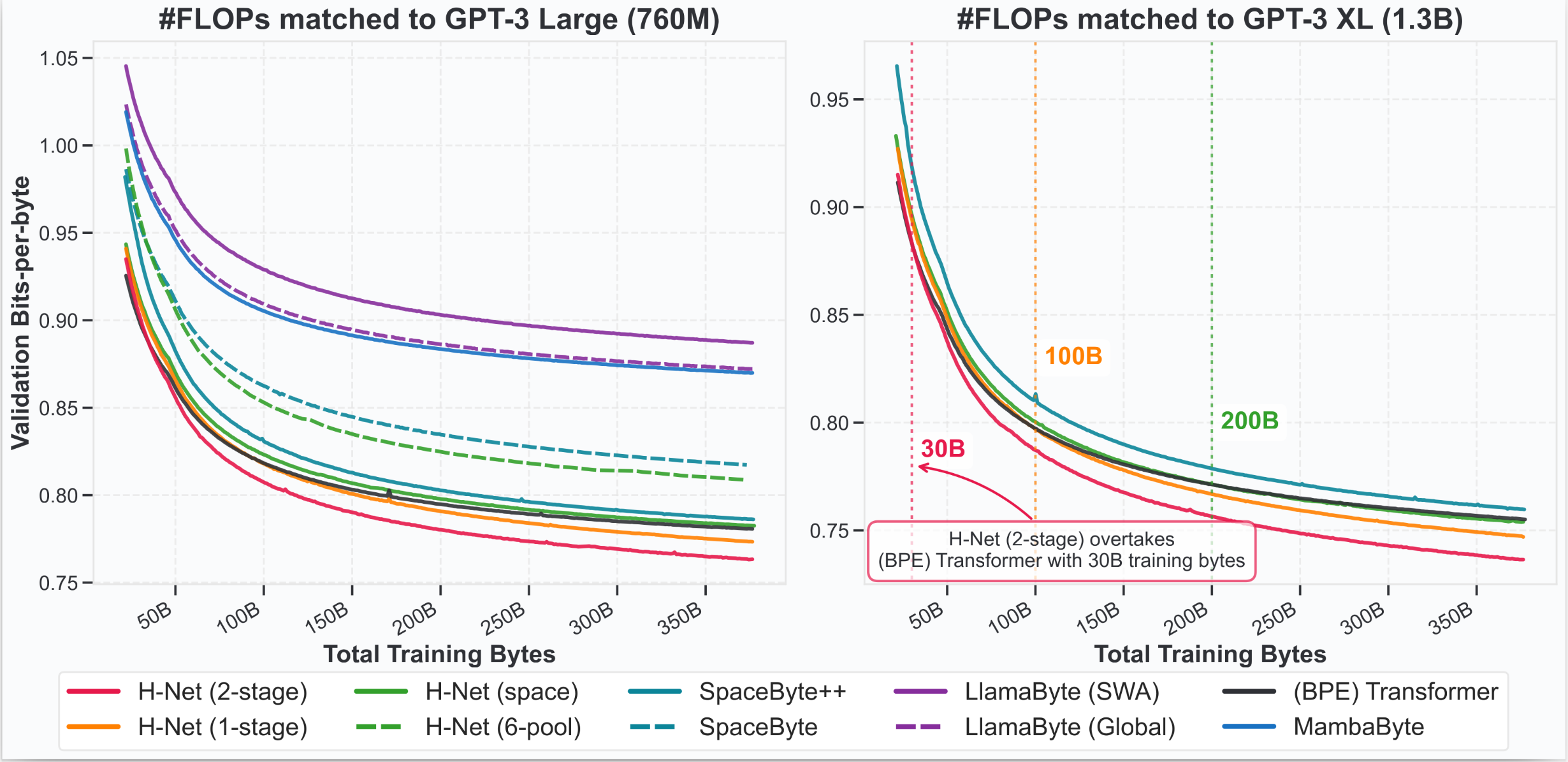
- 层次化模型的压倒性优势:所有层次化模型(包括 H-Net 变体和 SpaceByte++)都显著优于纯各向同性模型(Transformer, MambaByte, LlamaByte)。这表明层次化结构本身对于处理长序列和学习抽象非常有效。
- 动态分块的卓越性:
- H-Net (pool)(固定宽度分块)表现最差,验证了内容无关分块的低效
- H-Net (space)(基于空格启发式分块,但结合了 H-Net 的优化技巧)表现非常强劲,与 BPE Transformer 性能相当,这证明了数据依赖分块策略与良好设计的层次架构的强大结合。
- H-Net (1-stage) 优于 H-Net (space),这直接证明了动态分块机制能够成功学习上下文依赖的分割,超越了强硬的启发式规则。
- H-Net (2-stage) 显著优于 H-Net (1-stage),这验证了迭代动态分块(多层次抽象)能够进一步提升性能,更有效地利用计算和参数。
- 数据扩展性:字节级 H-Net 模型(特别是 H-Net (2-stage))展现出更好的数据扩展性。它们在训练初期可能略逊于 Transformer,但在足够数据量后迅速反超(H-Net (2-stage) 仅需 30B 字节数据就超越了 Transformer),并且性能优势随训练数据增加而持续扩大。这意味着 H-Net 随着数据量的增加,能够不断完善其分块策略,从而获得更大的收益。
下游任务评估(Zero-shot accuracy):
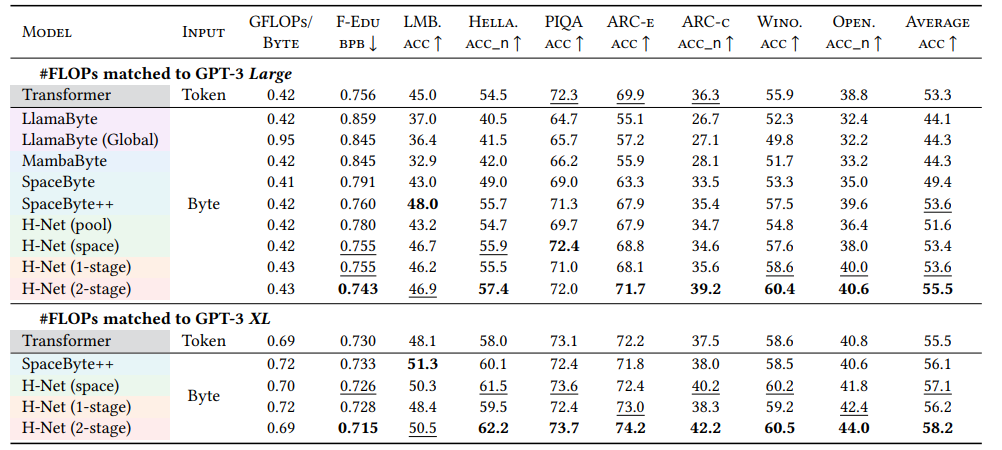
- H-Net (2-stage) 在各种下游基准测试(如常识推理、问答等)中基本都取得最高性能。
- Large 规模的 H-Net (2-stage) 竟然能够匹配 XL 规模 BPE Transformer 的平均下游性能,这表明 H-Net 在更小的模型尺寸下,也能通过高效的分块策略实现强大的能力。
3.2 鲁棒性与可解释性
对文本扰动的鲁棒性:
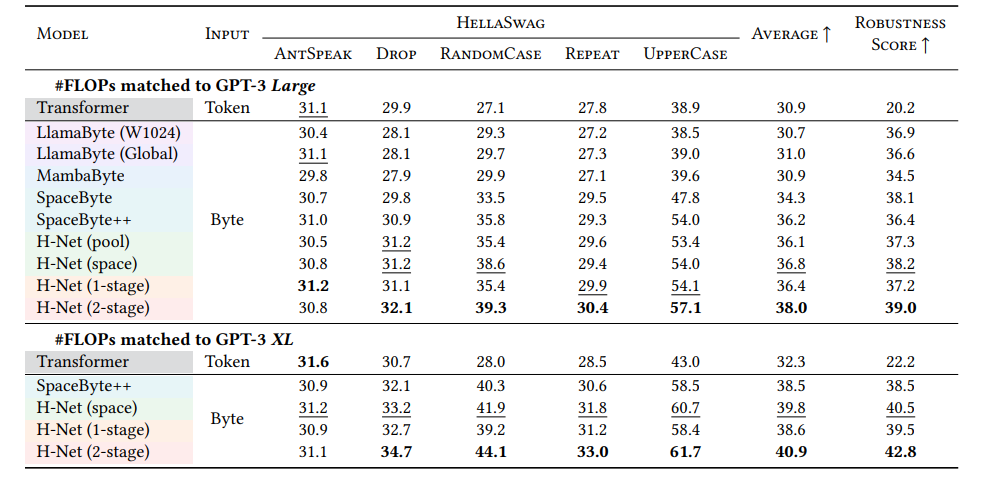
- 在未经任何噪声数据增强的情况下,H-Net (2-stage) 对文本扰动(如拼写错误、大小写变化、字符删除等)表现出显著增强的鲁棒性。其性能下降幅度远小于基于 token 的 Transformer。
- 这是因为 H-Net 直接操作字节,它能够「看到」并理解字符级的细微变化,而不是被分词器「误导」而将拼写错误视为完全不同的 token。这对于处理真实世界中充满噪声的文本数据至关重要。
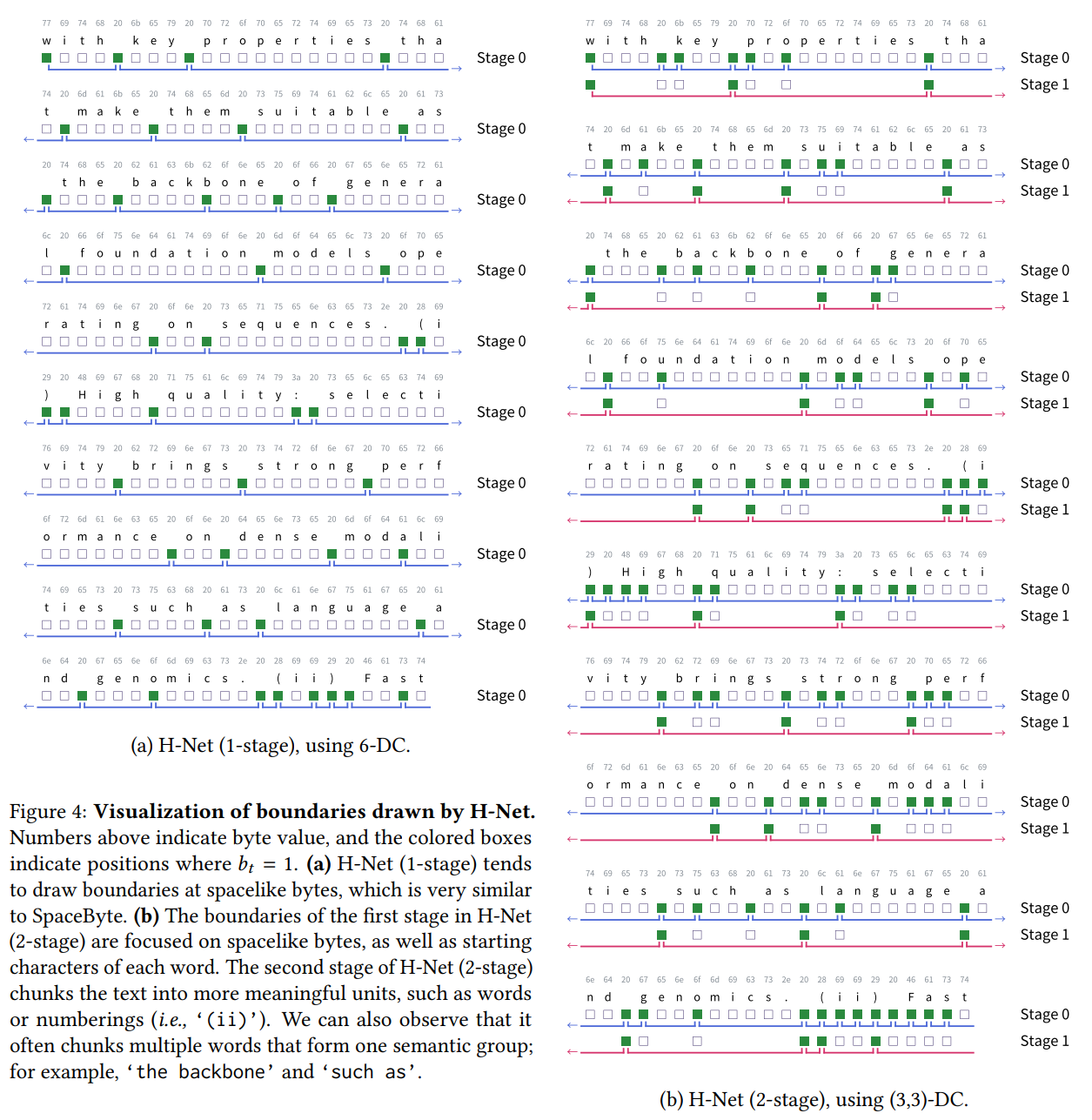
- 论文通过可视化 H-Net 学习到的分块边界,提供了直观的证据。
- H-Net (1-stage)
:确实主要在空格处放置边界,这表明模型自主学习到单词边界在英语文本中是自然的语义单元。这反过来也验证了
SpaceByte等基于空格启发式分词模型的有效性。 - H-Net (2-stage) : 展现出更复杂的层次化分块模式。第一阶段不仅关注空格,还可能结合单词的前几个字符。这种策略有助于模型:一旦单词的起始被识别,后续字符就高度可预测。
- 内容感知分块:H-Net
不仅仅遵循静态规则。它能够根据内容和上下文合并多个单词和类似空格的字符(例如,
the backbone、such as、(ii))。即使去除空格,H-Net 也能在语义词之间进行分块,这表明它真正理解了文本的内在结构。

3.3 跨语言与跨模态通用性

H-Net 的无分词器特性使其成为一个天然的通用序列模型架构,无需为不同语言或模态设计特定的分词器。
中文与代码:
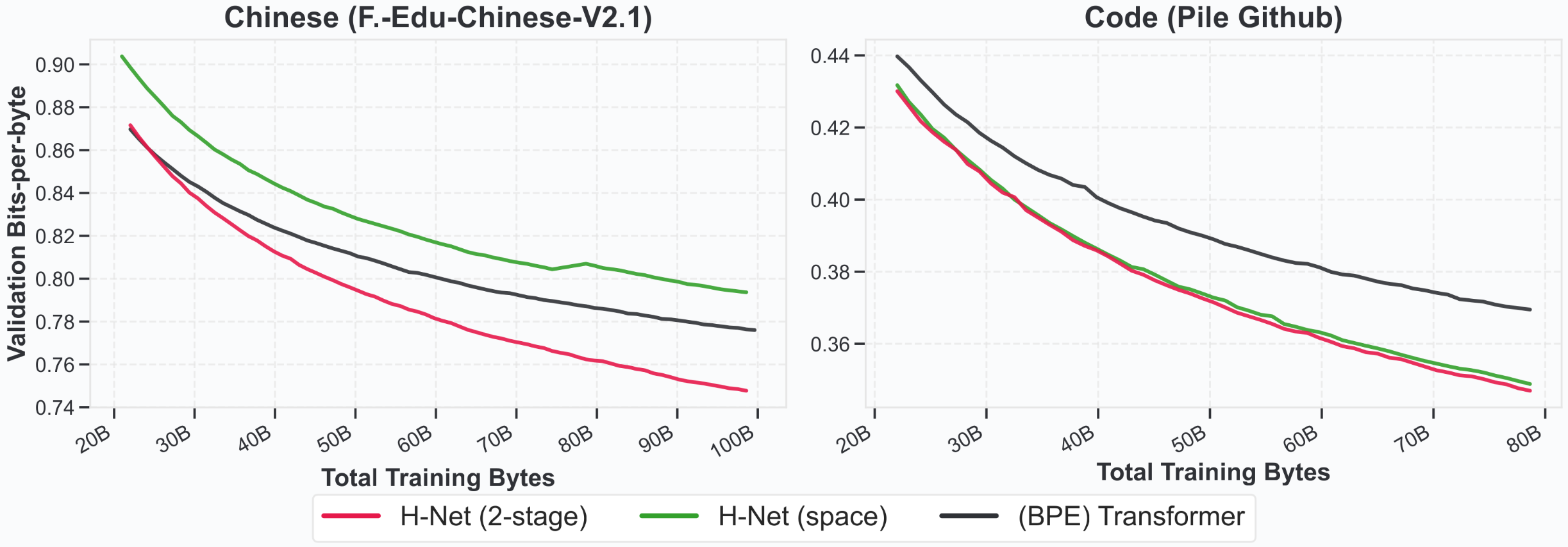

- 中文: 缺乏自然空格,传统分词是难题。H-Net (2-stage) 在中文语言建模和 XWinograd-zh(中文常识推理任务)上显著优于针对多语言设计的 Llama3 分词器和 H-Net (space)。这表明 H-Net 能够自主发现中文文本中更合理的语义单元。
- 代码: 含有大量空格和特定语法结构。H-Net (2-stage) 和 H-Net (space) 在代码建模上均显著优于 BPE Transformer。H-Net 能够更好地捕捉代码的逻辑结构。
DNA 序列:
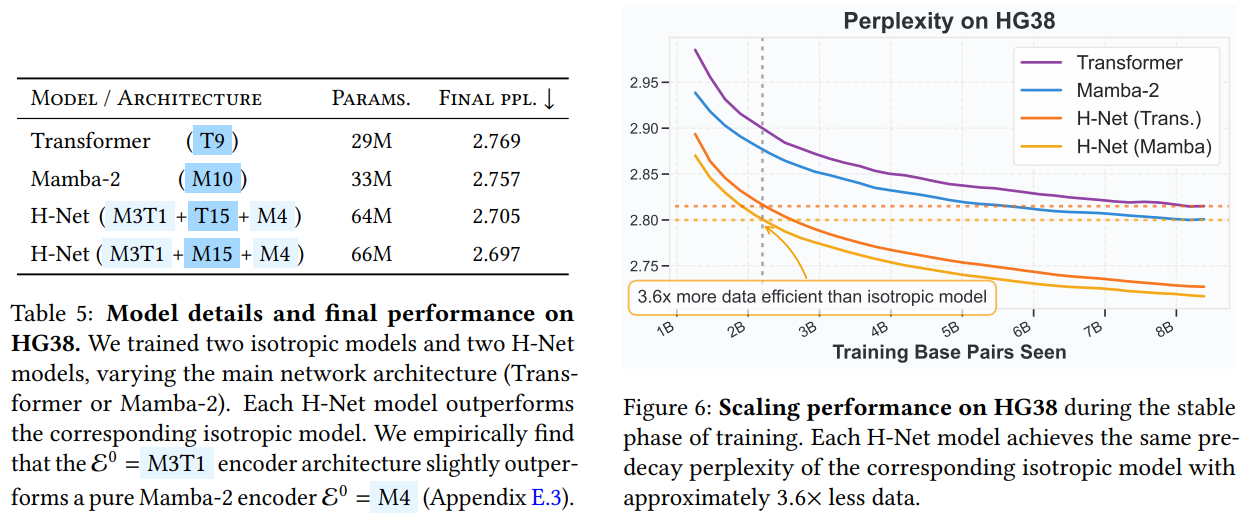
- 独特挑战: DNA 序列(A、C、G、T)没有自然分词线索,传统分词器完全不适用。但 DNA 又包含多层次的生物学功能单元(如密码子、基因、调控元件)。
- H-Net 优势: H-Net 直接在原始碱基对级别上操作,并通过动态分块机制自动发现 DNA 序列中的高分辨率结构和功能单元,而无需任何生物学启发式。
- 数据效率: H-Net 模型(无论是 Transformer 还是 Mamba-2 作为主网络)比对应的各向同性模型表现更好。H-Net 模型仅用约 3.6 倍少的数据就能达到与各向同性模型相似的性能,显示出极高的数据效率。这对于昂贵的生物学实验数据采集来说意义重大。
3.4 消融研究
- 平滑模块(Smoothing Module):被证明是稳定训练动态的核心。没有它,压缩比率会剧烈波动,模型无法学习一致的分块边界,导致性能显著下降(见原论文图 7)。
- 相似度路由模块和 STE:对训练稳定性和最终性能也很重要。
- Mamba 层在编码器/解码器中的作用:如前所述,Mamba 层对于有效的字节级序列处理至关重要,甚至在处理 BPE token 时也优于 Transformer 层(见原论文图 8、图 9、图 10),这进一步印证了 Mamba 在信息压缩和抽象构建方面的强大归纳偏置。
- 与 MoE 的比较: H-Net 可以被视为一种动态稀疏性。论文将其与 MoE 模型进行比较,发现在参数和计算量匹配的情况下,H-Net 远优于稀疏化的 MoE 模型(见原论文图 12)。这表明 H-Net 不仅实现了稀疏性,而且是以一种语义有意义的方式实现,从而带来更好的扩展性。
四、总结
4.1 贡献
- 端到端无分词器建模 H-Net 实现了无需预定义词表和分词器、从原始字节到预测的端到端语言建模,依赖动态分块(Dynamic Chunking, DC)机制,结合平滑模块和直通估计器(STE)解决离散决策的梯度传播难题。
- 性能超越传统分词模型 在相同计算和数据量下,H-Net(包括单阶段和多阶段结构)在语言建模和下游任务上均能匹配或超越 BPE-Transformer,展现出更好的数据扩展性和抽象能力。
- 显著提升鲁棒性与通用性 字节级处理带来更强的字符级鲁棒性,对拼写扰动、大小写变化等更不敏感;在中文、代码、DNA 等无明确分词线索的场景下表现突出,具备通用序列建模潜力。
- 验证 Mamba 层关键作用 通过消融实验,证明 Mamba-2 层在 H-Net 中优于 Transformer,具备独特的「压缩」归纳偏置,适合细粒度数据和高层抽象建模。
- 创新优化与架构设计 引入比率损失、学习率调制、范数平衡、两流分离等机制,提升模型稳定性和信息流动效率。
4.2 局限性
- 训练效率与工程挑战 动态分块导致训练速度较慢、内存管理复杂,现有实现比同规模 Transformer 慢约 2 倍,需定制化工程优化以适应大规模应用。
- 可扩展性验证有限 目前仅在 1.3B 参数规模验证,尚未在更大模型上测试,未来需关注大规模下的稳定性和性能。
- 缺乏正式缩放定律分析 论文未系统研究缩放定律,仅用启发式指标评估数据扩展性,缺乏对不同规模和数据量下性能趋势的全面揭示。
- BPB 计算精度问题 Token 模型的 BPB 计算存在高估风险,影响与 H-Net 的公平对比,需更精确的评估方法。
- 蒸馏与分词偏置难题 从 Token 模型蒸馏到字节级 H-Net 时,性能仍有差距,分词粒度差异带来「分词偏置」,难以完全弥合。
4.3 未来展望
- 更深层次层次结构探索 进一步研究三阶段及以上 H-Net,学习更高级别抽象和语义。
- 动态推理计算分配 利用 H-Net 推理时动态分配计算资源,提升推理效率和能力。
- 长文本建模能力提升 结合现有长上下文方法,进一步增强长文本理解与生成。
- 融合高效架构 与 MoE、Mamba-Transformer 等混合架构结合,提升参数效率和性能。
- 工程优化与大规模验证 优化训练推理效率,在更大规模模型上验证性能和稳定性。
- 缩放定律系统研究 正式分析 H-Net 的缩放定律,指导未来模型设计与扩展。
- 拓展多模态应用 推广至音频、视频等原始序列数据,成为通用基础模型骨干。
Reference
- Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
- H-Net(GitHub)
- Dynamic Chunking (H-Net) : A NewApproach to Tokenizer-Free AI Text Processing
- 无Tokenizer时代真要来了?Mamba作者再发颠覆性论文,挑战Transformer
- 超出tokenizer:Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
- 挣脱束缚,迈向真正的端到端:深度剖析H-Net与动态分块技术
- H-Net:告别分词器,迈向真正的端到端