行为序列
一、用户行为序列建模
用户最近 n 次点击、点赞、收藏、转发等行为都是推荐系统中重要的特征,可以帮助召回和排序变得更精准。这节课介绍最简单的方法——对用户行为取简单的平均,作为特征输入召回、排序模型。
用户的LastN行为序列可以反映出用户对什么样的物品感兴趣,召回的双塔模型、粗排的三塔模型、还有精排模型都可以用LastN特征。LastN特征很有效,把它用到召回和排序模型中,所有指标都会大涨。
简单平均
- 早期的做法
- 现在也很常用
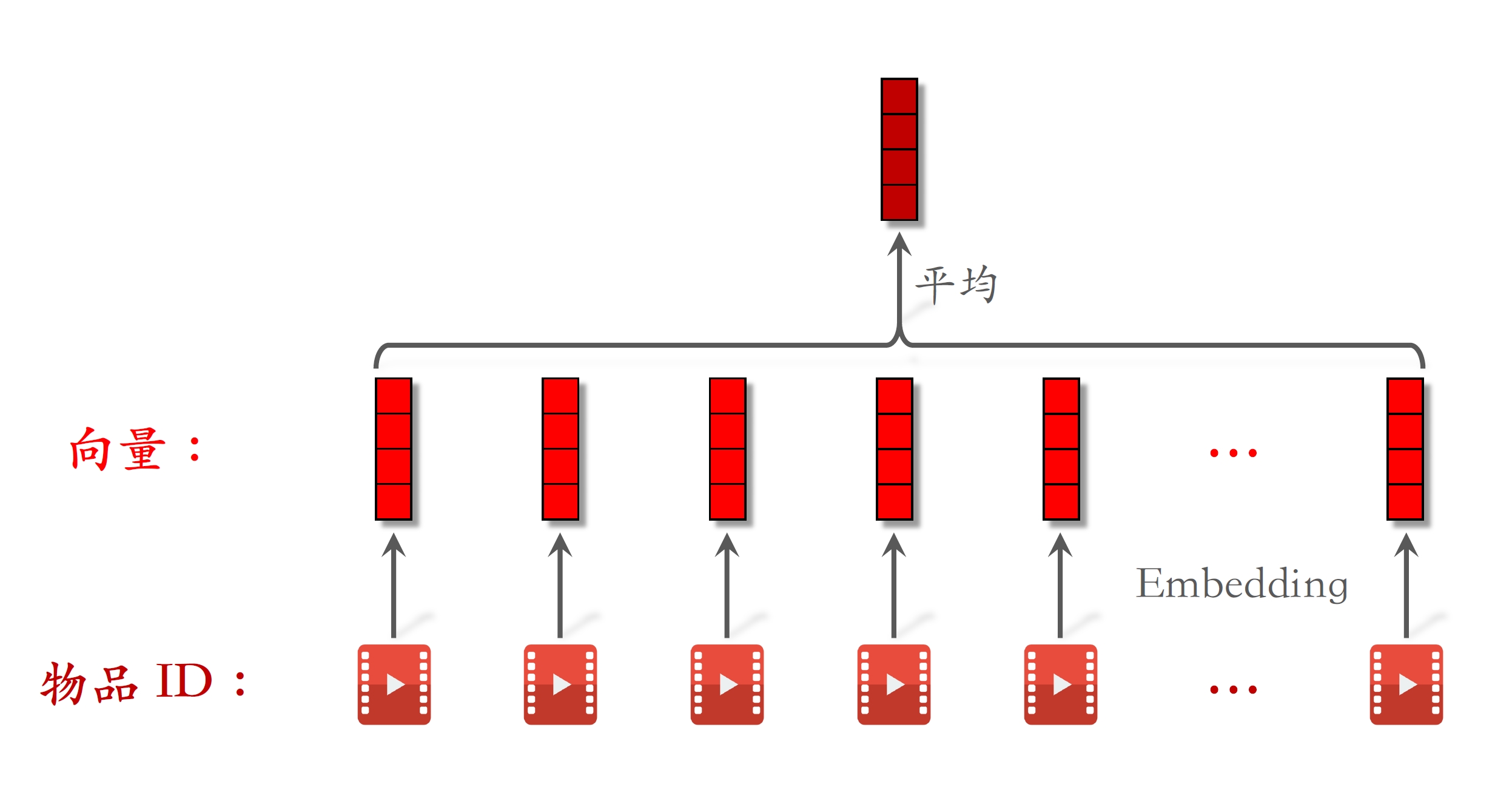
- LastN:⽤户最近的
次交互(点击、点赞等)的物品ID。 - 对LastN物品ID做embedding,得到
个向量。 - 把
个向量取平均,作为⽤户的⼀种特征。 - 适⽤于召回双塔模型、粗排三塔模型、精排模型。
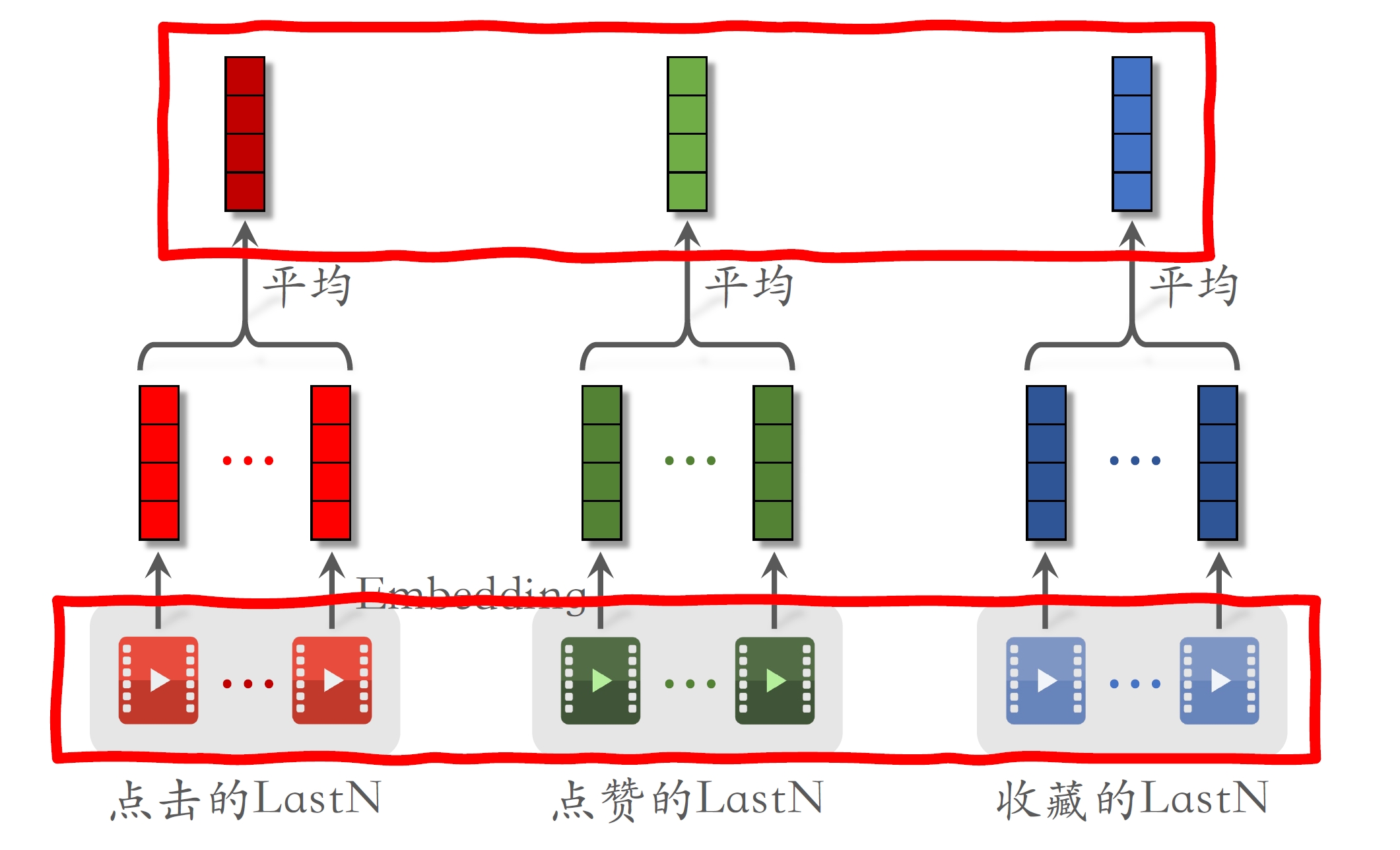
- 对各种交互行为序列单独做平均,将平均后的向量拼接起来。
- 实际用LastN的时候,不只是用物品ID,还用物品的其他特征,比如物品类目。
- 把ID embedding和其他特征的embedding拼在一起,这样比只用ID embedding效果更好。
二、DIN模型[1]
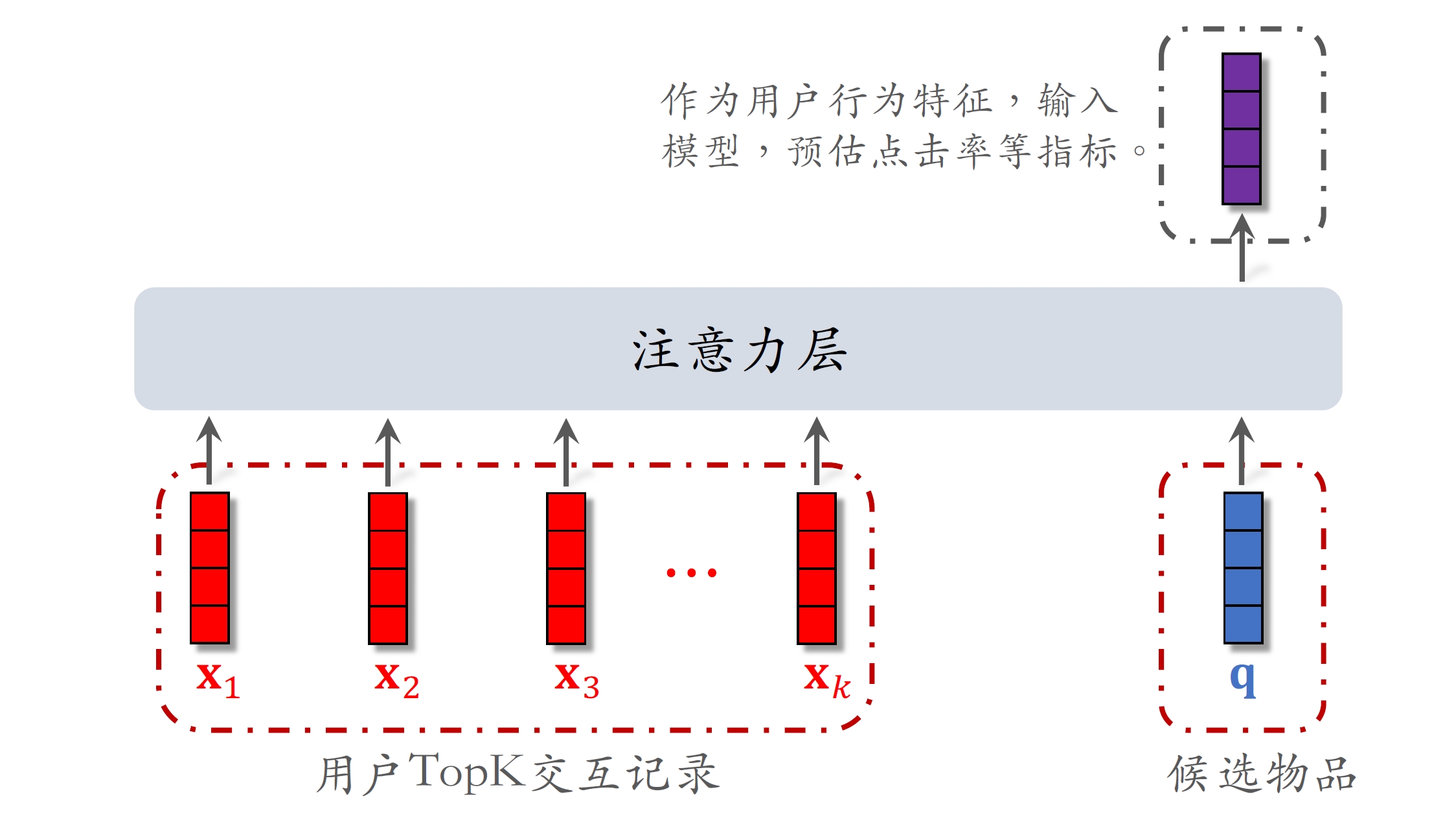
DIN 模型,它是对 LastN 序列建模的一种方法,效果优于简单的平均。DIN 的本质是注意力机制(attention)。
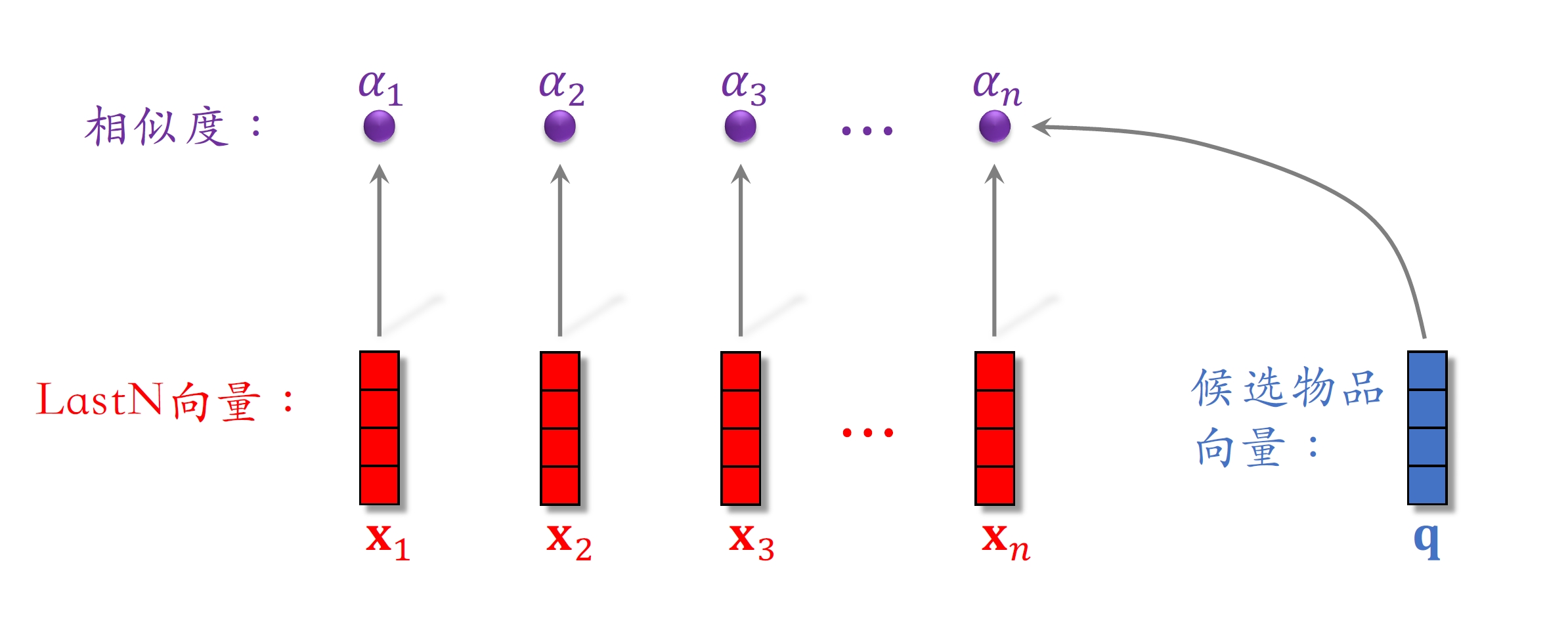
- DIN ⽤加权平均代替平均,即注意⼒机制(attention)。
- 权重:候选物品与⽤户LastN物品的相似度。
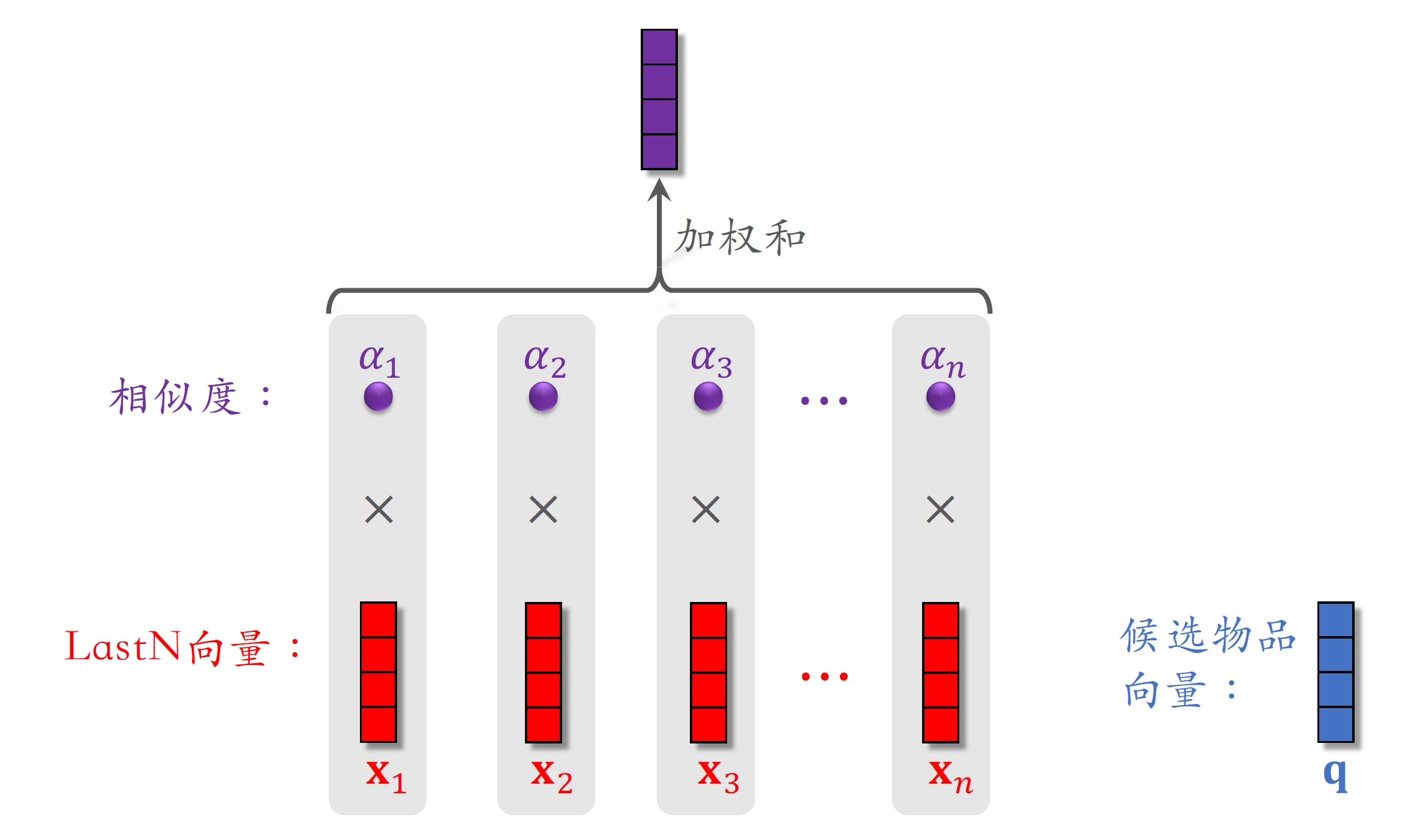
- 对于某候选物品,计算它与⽤户LastN物品的相似度。
- 以相似度为权重,求⽤户LastN物品向量的加权和,结果是⼀个向量。
- 把得到的向量作为⼀种⽤户特征,输⼊排序模型,预估(⽤户,候选物品)的点击率、点赞率等指标。
- 本质是注意⼒机制(attention)。
假设粗排选出了500个物品,用DIN给500个物品打分保留分数最高的几十个: 1. 500个物品依次和LastN向量求相似度(内积、余弦相似度,或更复杂的方法) 2. 将相似度作为权重,计算LastN物品的加权和,作为用户的LastN特征,输入精排模型
DIN的本质是注意力机制
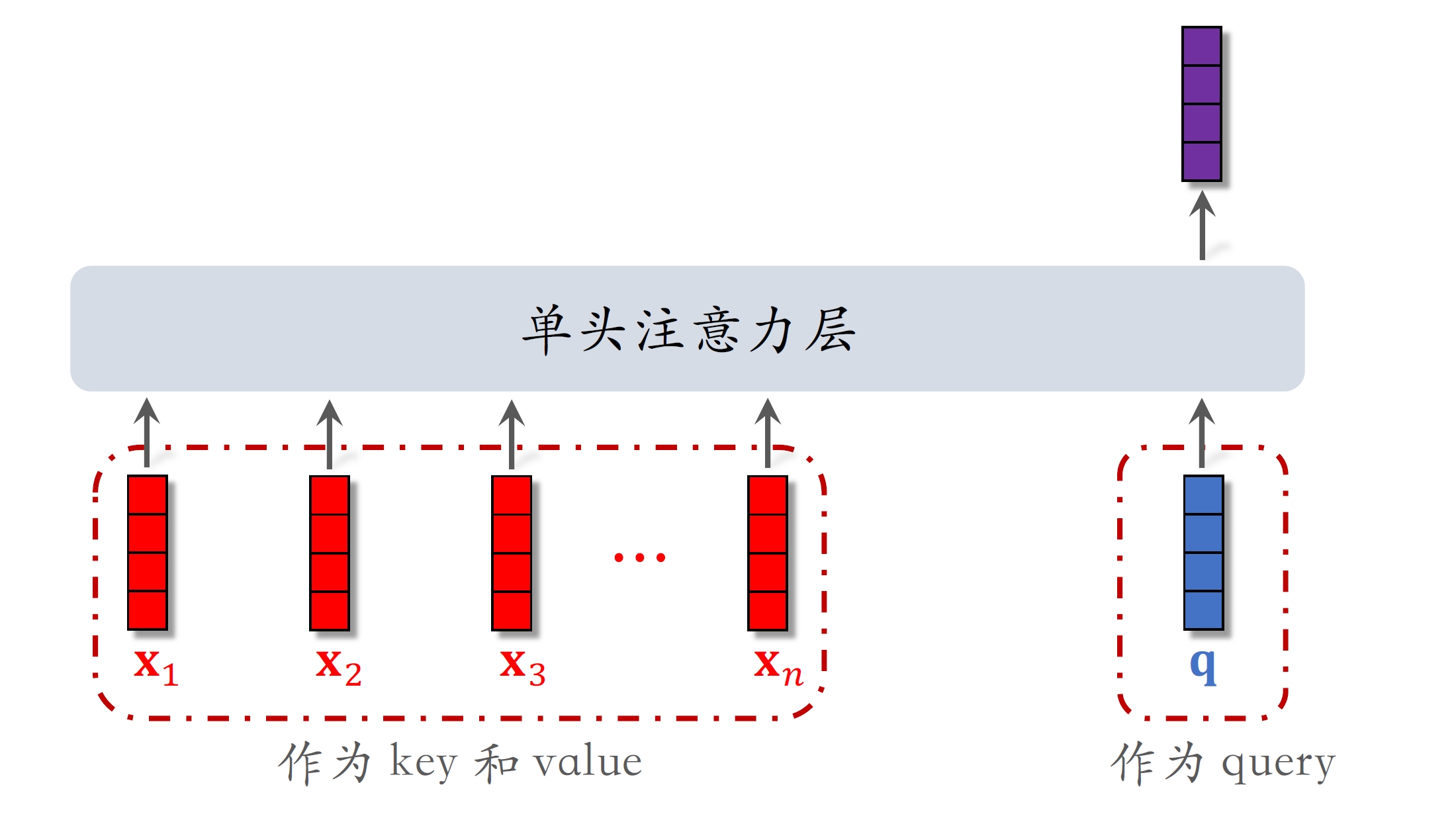
相似度越高权重越大。
DIN有效的原因
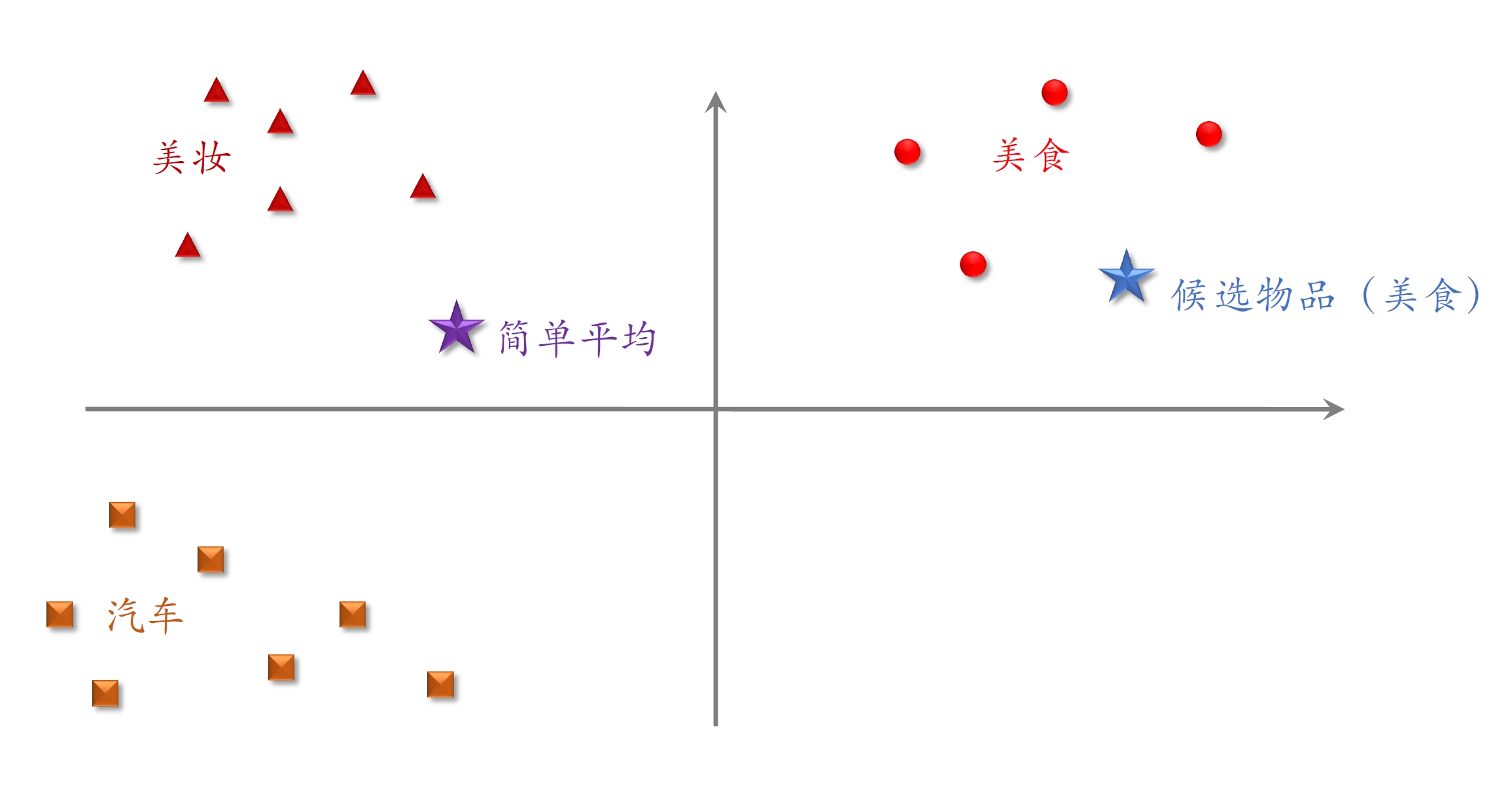
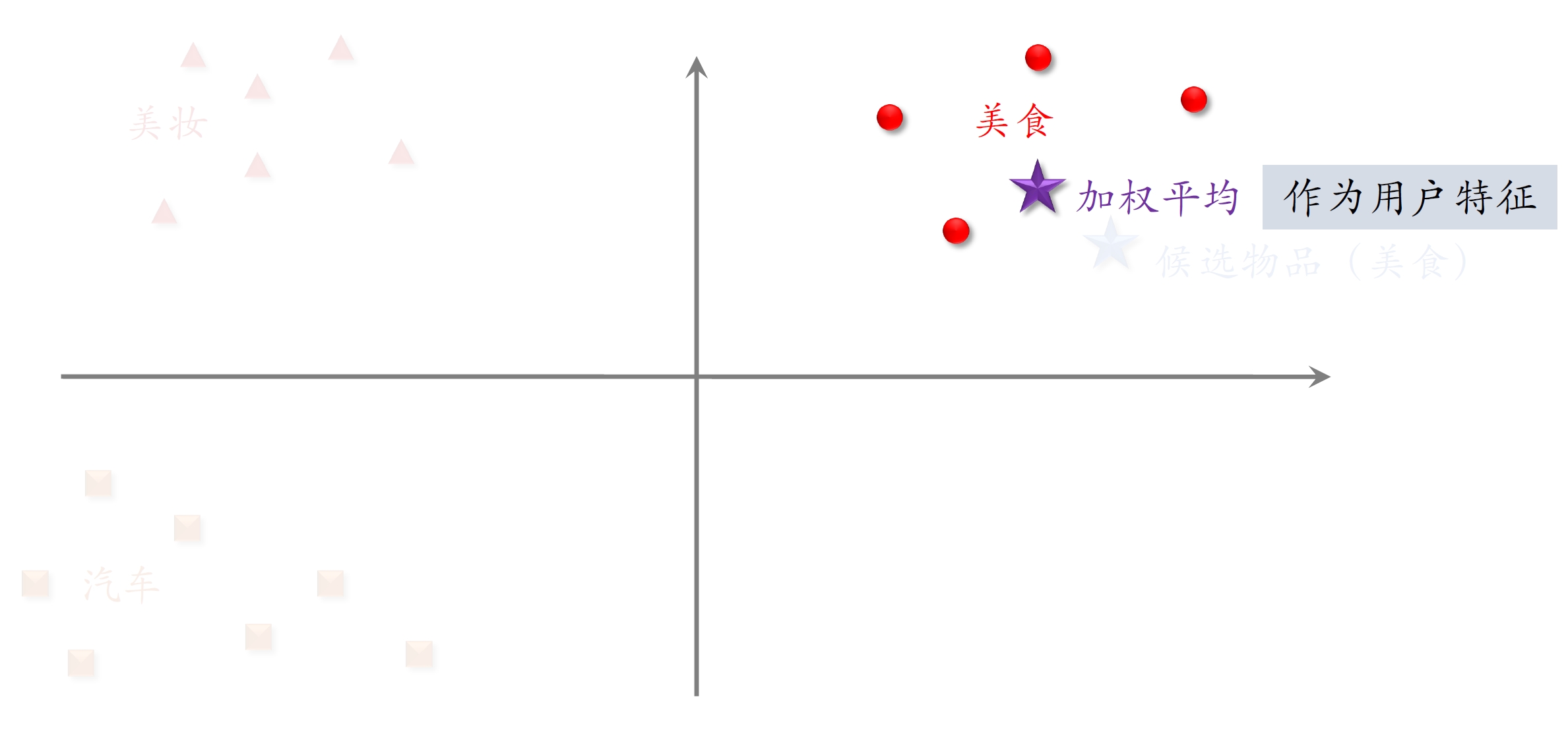
候选物品是美食类
- 用户近期交互过很多美食类笔记,则加权平均后的用户特征更接近同类笔记
- 比起简单平均,更加突出了近期兴趣中的“美食”特征(注意力)
- 因为候选物品是正样本,模型会学习到与行为序列相似的物品兴趣更大,排序分数更高
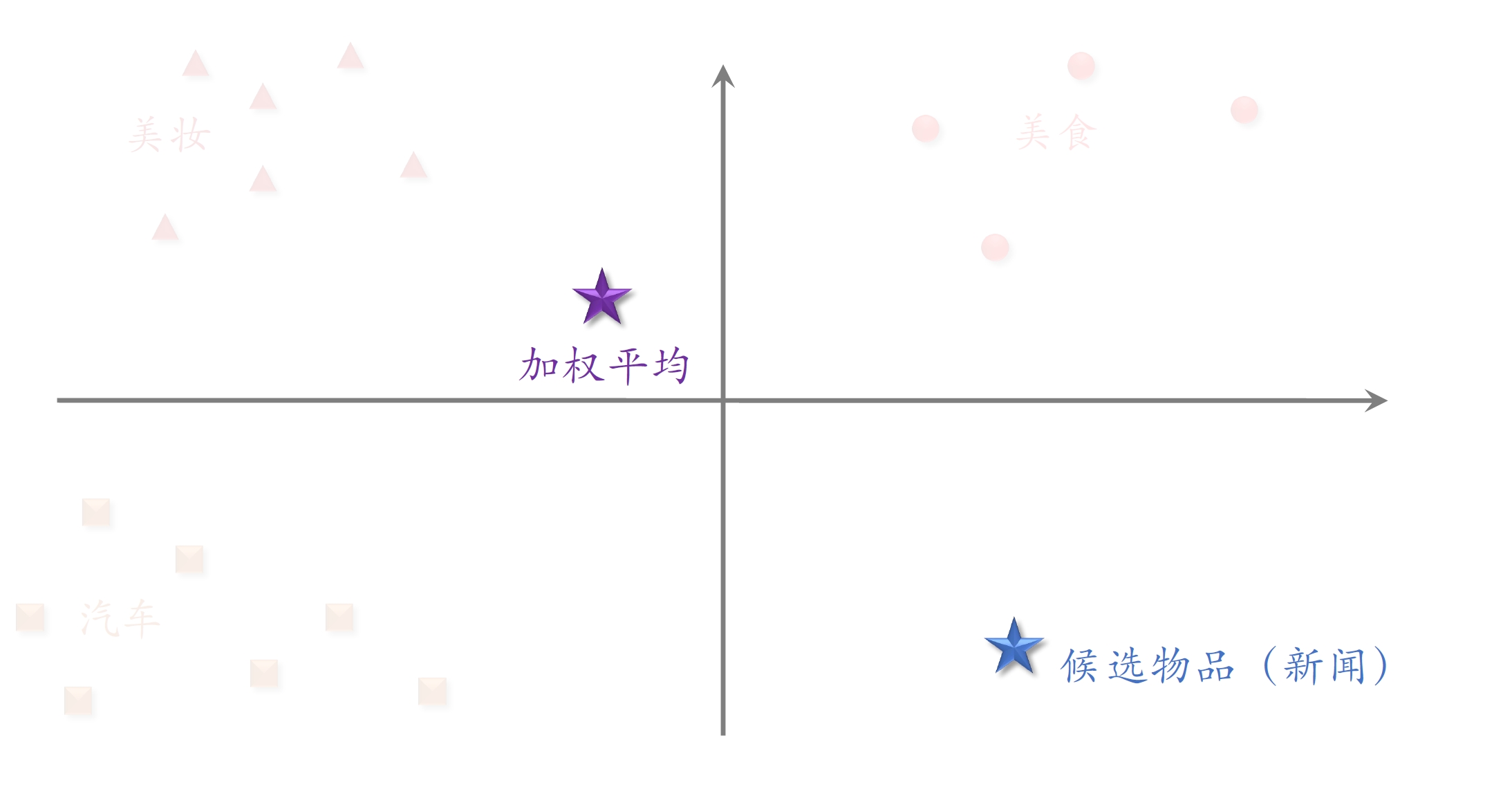
候选物品是新闻类
- 与用户近期交互过的笔记都不相同,则加权平均后的用户特征距离候选物品不会很近
简单平均v.s. 注意力机制
- 简单平均和注意⼒机制都适⽤于精排模型。
- 简单平均适⽤于双塔模型、三塔模型。
- 简单平均只需要⽤到LastN,属于⽤户⾃⾝的特征。
- 把LastN 向量的平均作为⽤户塔的输⼊。
- 注意⼒机制不适⽤于双塔模型、三塔模型。
- 注意⼒机制需要⽤到LastN + 候选物品。
- ⽤户塔看不到候选物品,不能把注意⼒机制⽤在⽤户塔。
三、SIM模型[2]
- 让记录的行为序列变长,可以显著提升推荐系统所有的指标;
- 但是暴力增加序列长度是不划算的增加的计算量太大,带来的收益却不够多,性价比不高
3.1 DIN模型缺点与改进
缺点
- 注意⼒层的计算量
(⽤户⾏为序列的长度)。 - 只能记录最近⼏百个物品,否则计算量太⼤。
- 缺点:关注短期兴趣,遗忘长期兴趣。
改进
- ⽬标:保留⽤户长期⾏为序列(
很⼤),⽽且计算量不会过⼤。 - 改进DIN:
- DIN 对LastN 向量做加权平均,权重是相似度。
- 如果某LastN 物品与候选物品差异很⼤,则权重接近零。
- 快速排除掉与候选物品无关的LastN 物品,降低注意⼒层的计算量。
改进思路:快速排除掉对加权和贡献不大的物品
3.2 SIM模型
- 保留⽤户长期⾏为记录,
的⼤⼩可以是⼏千。 - 对于每个候选物品,在⽤户LastN记录中做快速查找,找到
个相似物品。 - 把LastN变成TopK,然后输⼊到注意⼒层。
- SIM模型减⼩计算量(从
降到 )。
3.2.1 第一步:查找
- ⽅法⼀:Hard Search
- 根据候选物品的类⽬,保留LastN物品中类⽬相同的。
- 简单,快速,无需训练。
- ⽅法⼆:Soft Search
- 把物品做embedding,变成向量。
- 把候选物品向量作为query,做
近邻查找,保留LastN物品中最接近的 个。 - 效果更好,编程实现更复杂。
论文实验表明Soft Search效果更好,实践中取决于公司基建水平基建很强可以用Soft Search,否则用Hard Search就可以了。
3.2.2 第二步:注意力机制
与DIN区别只有输入的交互记录不同
使⽤时间信息
- ⽤户与某个LastN物品的交互时刻距今为
。 - 对
做离散化,再做embedding,变成向量 。 - 把两个向量做concatenation,表征⼀个LastN物品。
- 向量
是物品embedding。 - 向量
是时间的embedding
- 向量
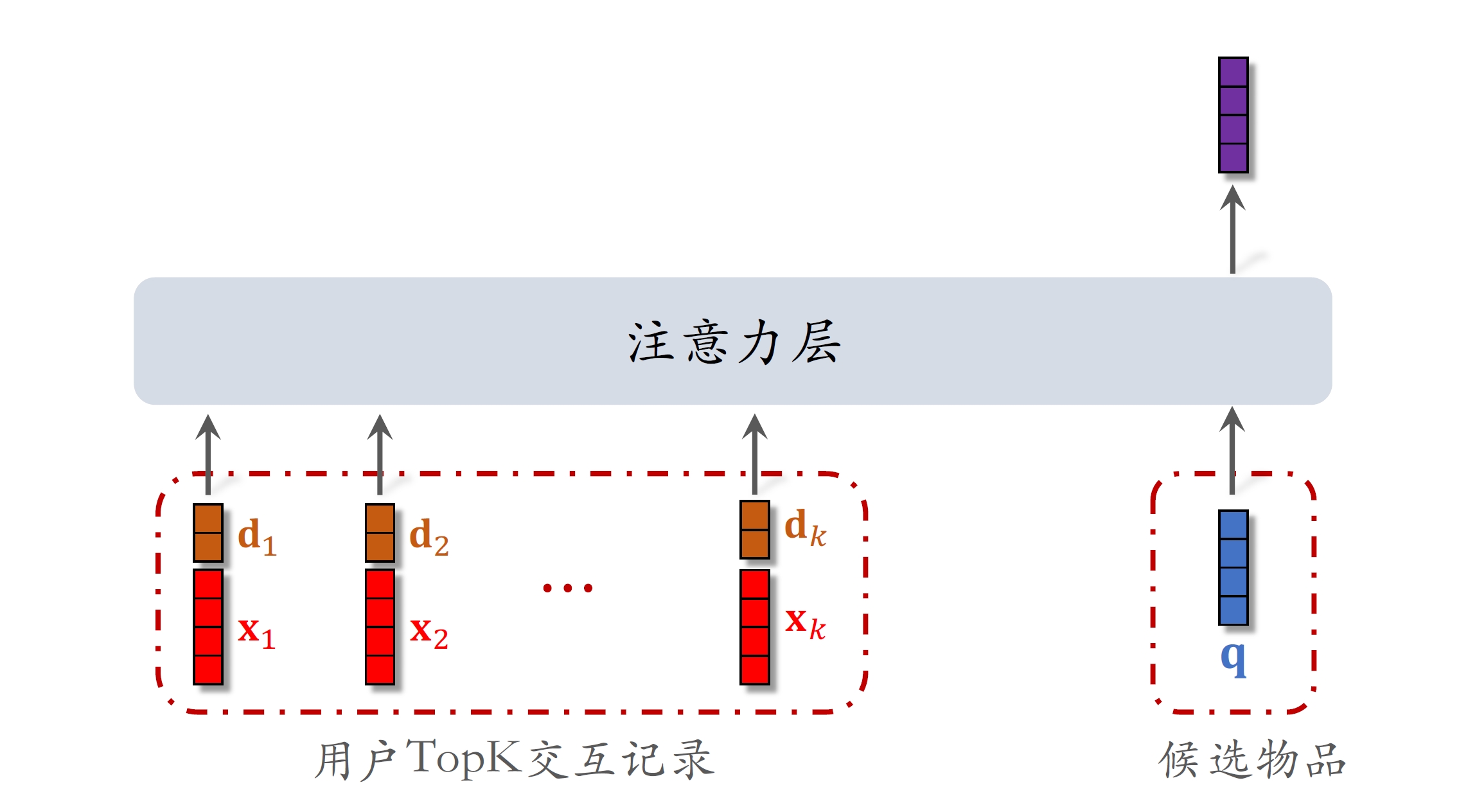
trick: 将时间划分成区间,如七天、三十天、一年、一年以上,embedding后与物品向量拼接(时间信息是物品的交互时刻距今过去多久,不需要对交互时刻做embedding)
为什么SIM使⽤时间信息
- DIN 的序列短,记录⽤户近期⾏为。
- SIM的序列长,记录⽤户长期⾏为。
- 时间越久远,重要性越低。
一年前和10分钟前的交互记录重要性不一样。
3.2.3 结论
- 长序列(长期兴趣)优于短序列(近期兴趣)。
- 注意⼒机制优于简单平均。
- Soft search还是hard search?取决于⼯程基建。
- 使⽤时间信息有提升。