排序模型
排序的目标是根据业务目标来不断变化的,最早期,业务目标简单,需要聚焦的时候,往往会选取⼀个指标来重点优化,当做到中期的时候,就会发现单⼀指标对整体的提升已经非常有限了,或者说会出现很多问题,这个时候,往往就会引入多目标排序来解决这些问题。
排序的依据
- 排序模型预估点击率、点赞率、收藏率、转发率等多种分数。
- 融合这些预估分数。(⽐如加权和。)
- 根据融合的分数做排序、截断。
一、多目标模型
1.1 特征
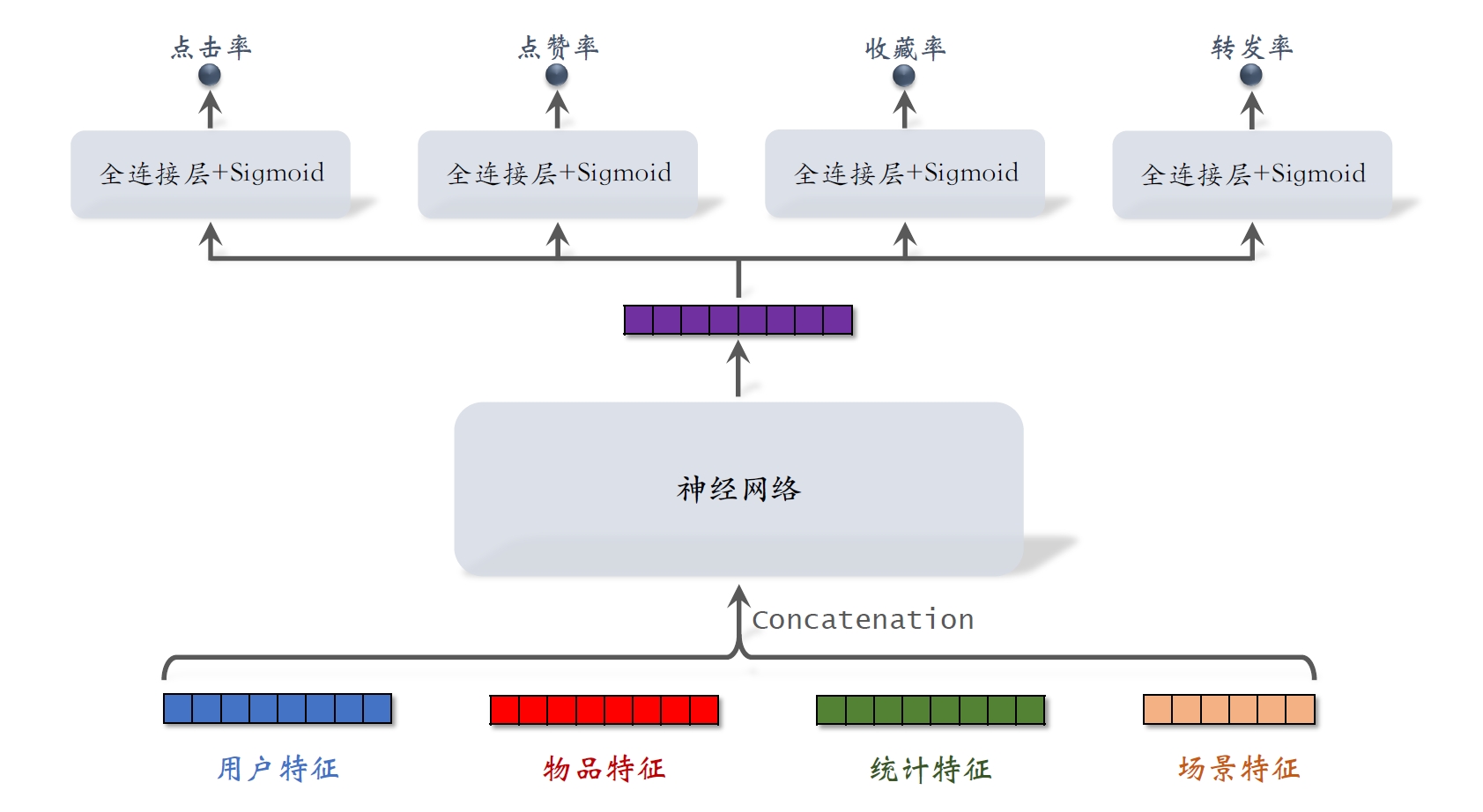
用户特征:
- ⽤户ID(在召回、排序中做embedding)。
- ⼈⼝统计学属性:性别、年龄。
- 账号信息:新⽼、活跃度……
- 感兴趣的类⽬、关键词、品牌。
- ……
物品特征:
- 物品ID(在召回、排序中做embedding)。
- 发布时间
- 所在城市
- 标题、类⽬、关键词、品牌……
- 字数、图⽚数、视频清晰度、标签数……
- 内容信息量、图⽚美学……
- ……
用户统计特征:
- ⽤户最近30天(7天、1天、1⼩时)的曝光数、点击数、点赞数、收藏数……
- 按照文章图⽂/视频分桶。(⽐如最近7天,该⽤户对图⽂的点击率、对视频的点击率。)
- 按照类⽬分桶。(⽐如最近30天,⽤户对美妆的点击率、对美⾷的点击率、对科技数码的点击率。)
- ……
文章统计特征:
- 最近30天(7天、1天、1⼩时)的曝光数、点击数、点赞数、收藏数……
- 按照⽤户性别分桶、按照⽤户年龄分桶……
- 作者特征:
- 发布数
- 粉丝数
- 曝光数、点击数、点赞数、收藏数
- ……
场景特征:
- ⽤户定位GeoHash(经纬度编码)、城市。
- 当前时刻(分段,做embedding)。
- 是否是周末、是否是节假⽇。
- ⼿机品牌、⼿机型号、操作系统。
- 网络类型
- ……
特征处理
- 离散特征:做embedding。
- ⽤户ID、文章ID、作者ID
- 类⽬、关键词、城市、⼿机品牌。
- 连续特征:做分桶,变成离散特征。
- 年龄、文章字数、视频长度。
- 连续特征:其他变换。
- 曝光数、点击数、点赞数等数值做log 1 + 𝑥 。
- 转化为点击率、点赞率等值,并做平滑。
1.2 训练

总损失函数:
对损失函数求梯度,做梯度下降更新参数。
困难:类别不平衡。
- 每100次曝光,约有10次点击、90次无点击(假设值)。
- 每100次点击,约有10次收藏、90次无收藏(假设值)。
解决⽅案:负样本降采样(down-sampling)。
- 保留⼀⼩部分负样本。
- 让正负样本数量平衡,节约计算。
1.3 预估值校准
正样本、负样本数量为
- 真实点击率:
- 预估点击率:
由上⾯两个等式可得校准公式[1]
二、Multi-gate Mixture-of-Experts (MMoE)
2.1 MMoE[2]
MMoE是一种多目标排序模型。MMoE 用多个独立的塔提取特征,并对多塔提取的特征向量做加权平均,然后送入多头。MMoE 的训练容易出现极化现象(polarize),可以用 dropout 解决。
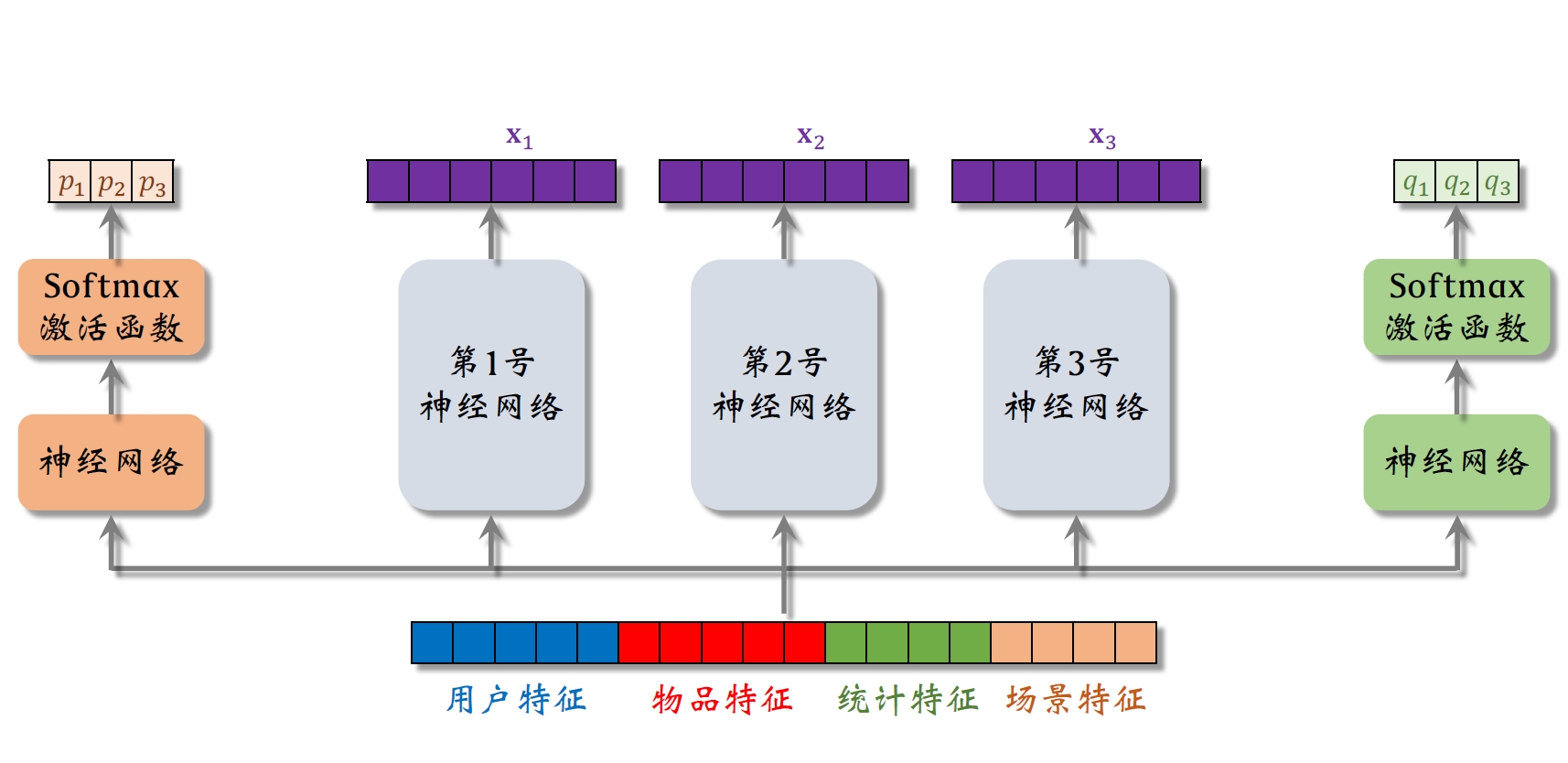
- 1-3号三个神经网络称为专家(实际运用时可能4-8个专家),三个神经网络不共享参数
- 三个神经网络会各输出一个向量
- 左右两个神经网络各输出一个三维向量,对应中间三个专家的权重
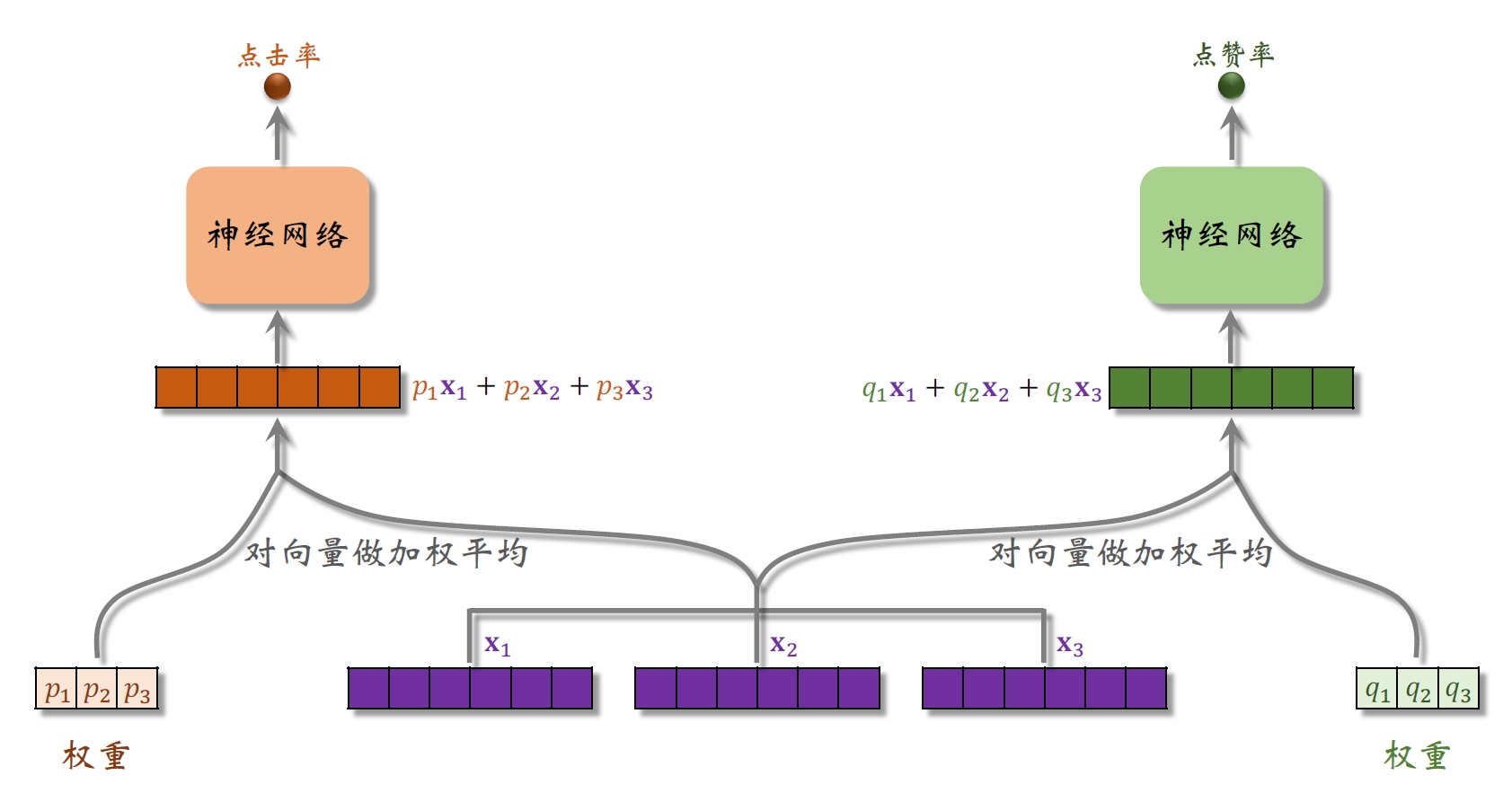
- 分别用两个权重对专家网路输出的向量做加权平均
- 加权平均后的向量通过神经网络后去对不同的目标做预估
- 两个目标有两组权重,10个目标的话就需要10组权重
2.1 极化现象
极化(polarize):Softmax输出值⼀个接近1,其余接近0。
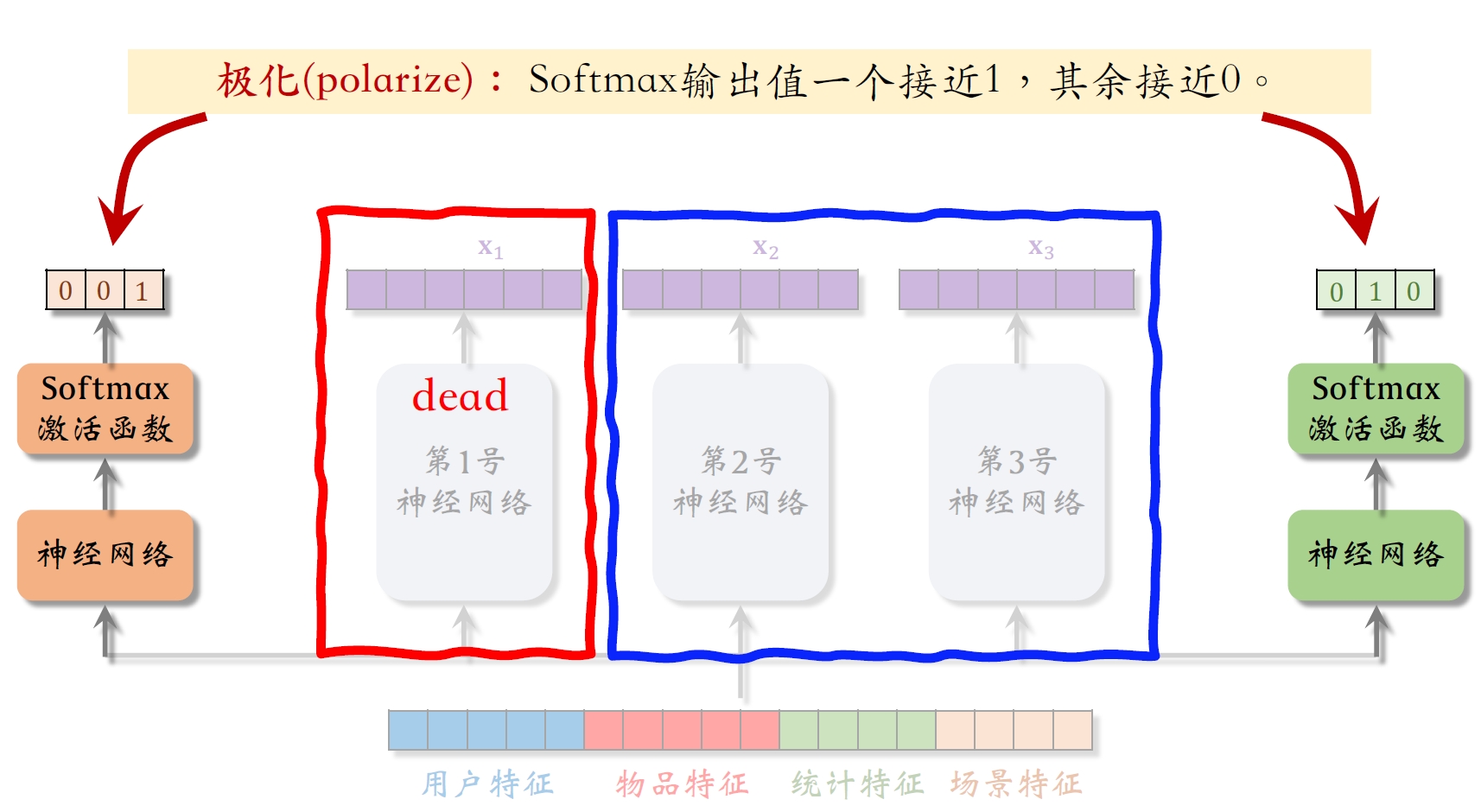
- 第一组权重输出
,第二组权重输出 - 做加权平均时,一号神经网络的向量就无作用,相当于一号神经网络dead
极化问题解决[3]
- 如果有
个“专家”,那么每个softmax 的输⼊和输出都是 维向量。 - 在训练时,对softmax 的输出使⽤dropout。
- softmax输出的
个数值被mask 的概率都是10%。 - 每个“专家”被随机丢弃的概率都是10%。
- softmax输出的
三、视频播放建模
3.1 视频播放时长
图文vs 视频
- 图⽂笔记排序的主要依据:点击、点赞、收藏、转发、评论……
- 视频排序的依据还有播放时长和完播。
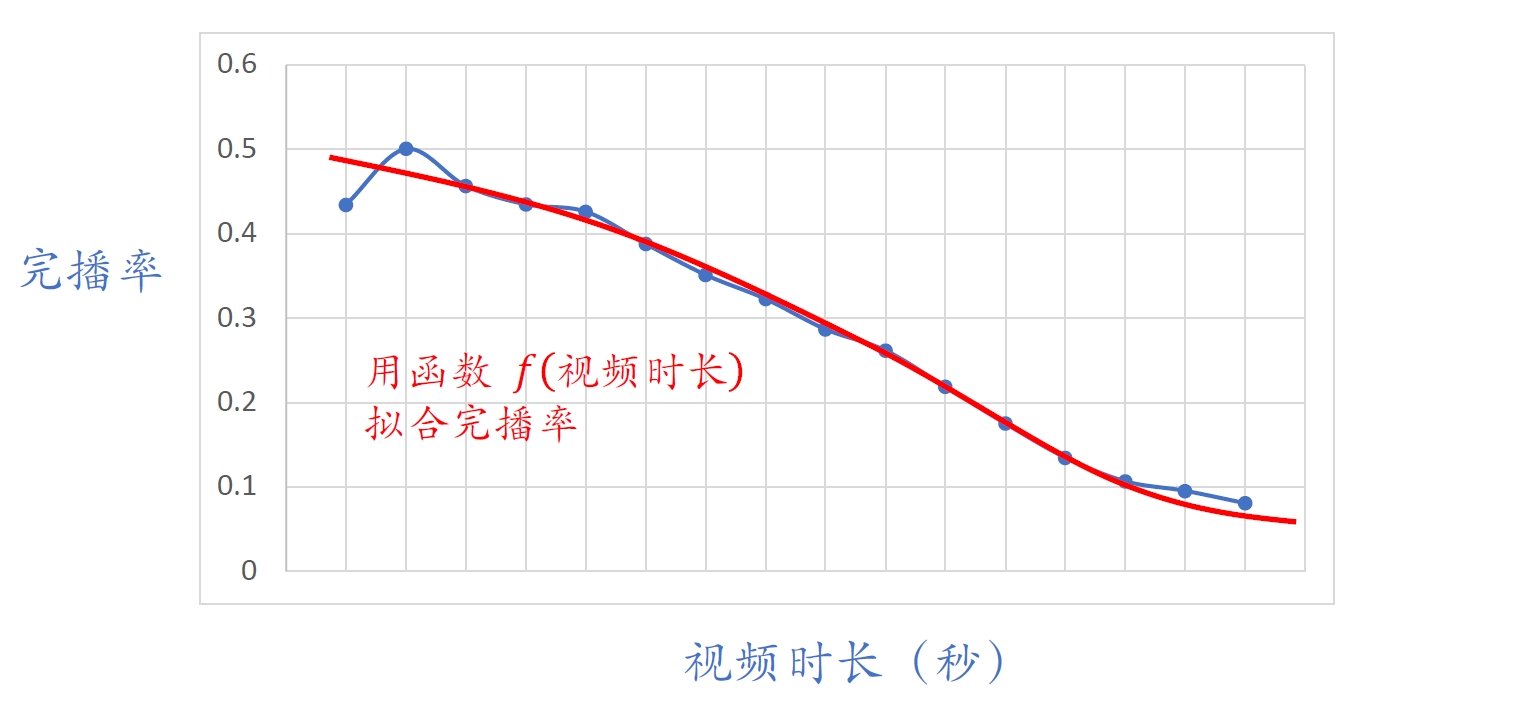
- 直接⽤回归拟合播放时长效果不好。建议⽤YouTube的时长建模[4]
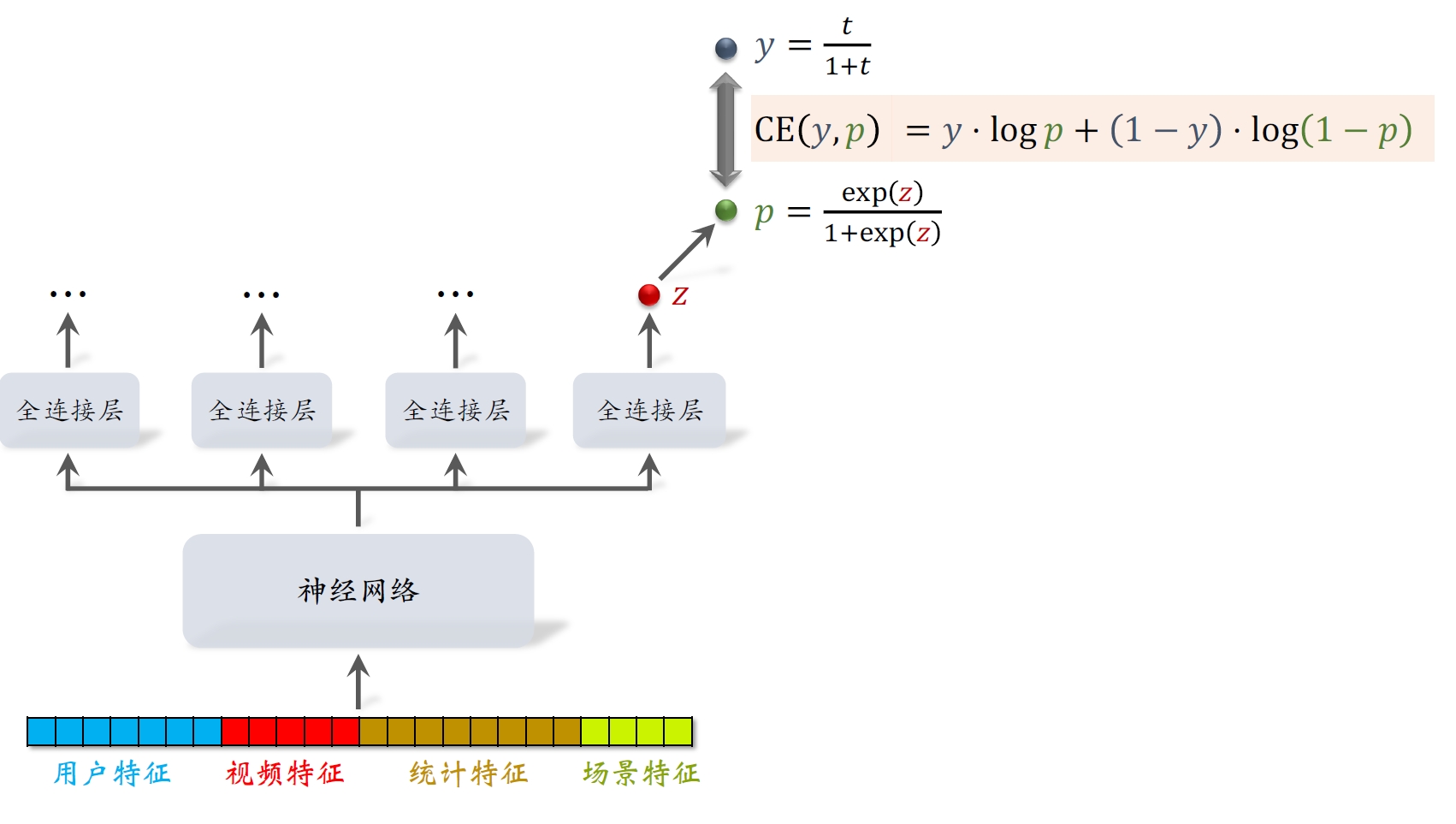
把最后⼀个全连接层的输出记作
。设 实际观测的播放时长记作
。(如果没有点击,则 。) 做训练:最⼩化交叉熵损失
如果
,那么 。 做推理:把
作为播放时长的预估。 把
作为融分公式中的⼀项。
3.2 视频完播
回归⽅法
- 例:视频长度10分钟,实际播放4分钟,则实际播放率为
- 让预估播放率
拟合 :
- 线上预估完播率,模型输出
,意思是预计播放
⼆元分类⽅法
- 定义完播指标,⽐如完播
- 例:视频长度10分钟,播放>8分钟作为正样本,播放<8分钟作为负样本。
- 做⼆元分类训练模型:播放>80% vs播放<80%
- 线上预估完播率,模型输出
,意思是
不能直接把预估的完播率⽤到融分公式(对长视频不公平)
- 线上预估完播率,然后做调整:
- 把
作为融分公式中的⼀项。
四、粗排模型[5]
上述所介绍的模型一般用于精排:
- 前期融合:先对所有特征做concatenation,再输⼊神经⽹络。
- 线上推理代价⼤:如果有
篇候选文章,整⼤模型要做 次推理
粗排一般文章量在几千篇,用上述模型推理代价⼤,可能无法满足线上响应时长要求。
粗排的三塔模型
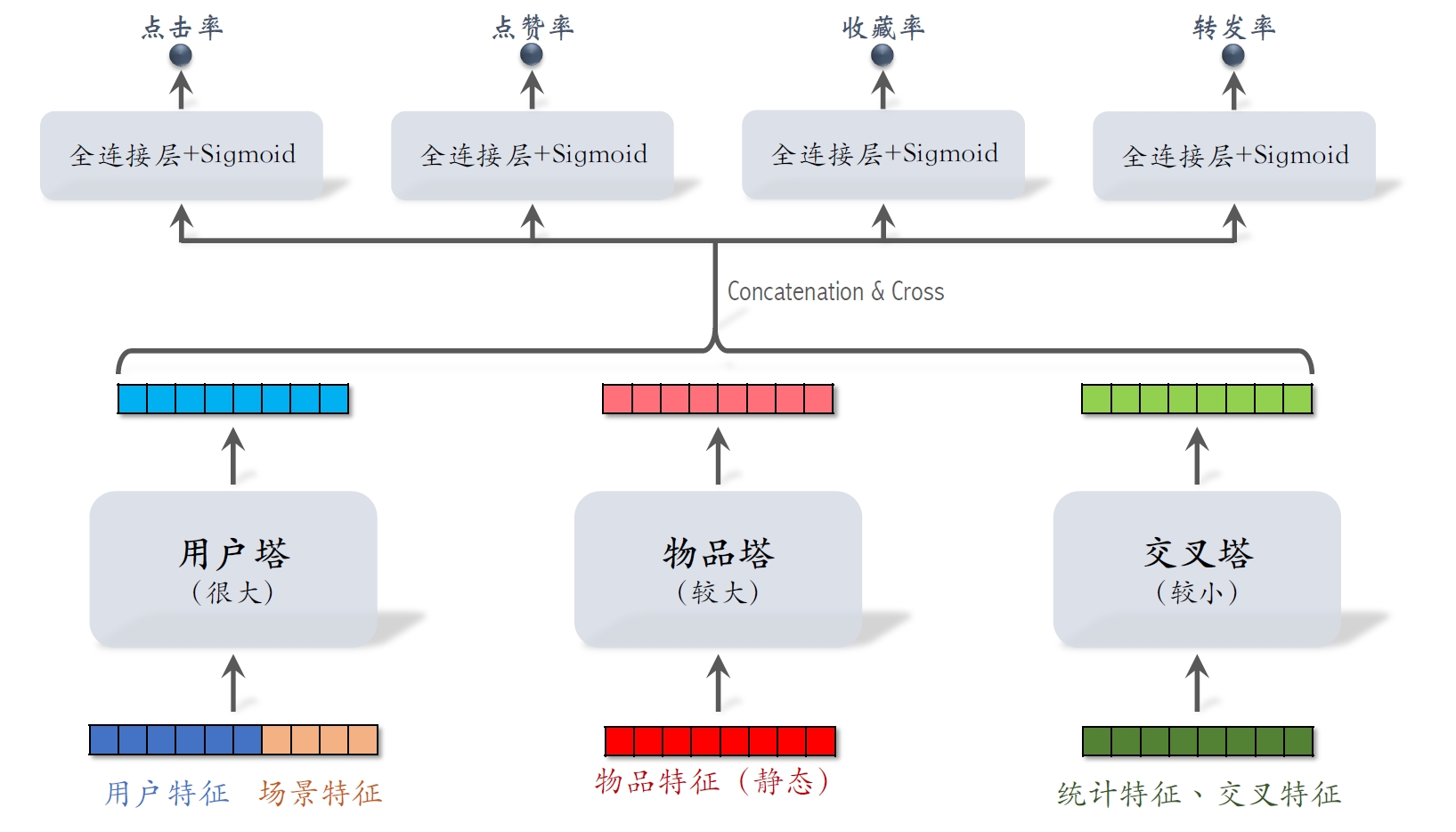
用户塔: - 只有⼀个⽤户,⽤户塔只做⼀次推理。 - 即使⽤户塔很⼤,总计算量也不⼤。
物品塔: - 有
交叉塔: - 统计特征动态变化,缓存不可⾏。 - 有
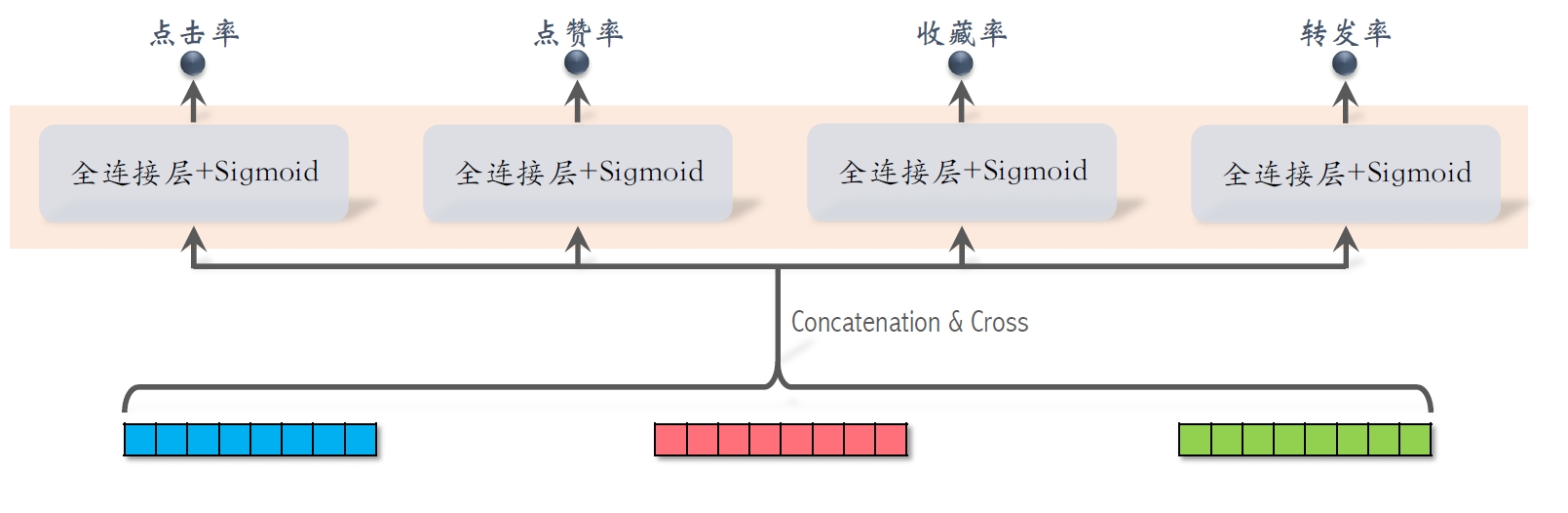
- 有
个物品,模型上层需要做 次推理。 - 粗排推理的⼤部分计算量在模型上层。
三塔模型的推理
- 从多个数据源取特征:
- 1个⽤户的画像、统计特征。
个物品的画像、统计特征。
- ⽤户塔:只做1次推理。
- 物品塔:未命中缓存时需要做推理。
- 交叉塔:必须做
次推理。 - 上层⽹络做
次推理,给 个物品打分。