DeepSeek DualPipe & EPLB
LLM的训练中,高效利用计算资源、降低通信开销以及维持负载均衡是亟待解决的关键问题。尤其在面对超大规模模型和海量数据时,传统训练方法往往难以应对。DeepSeek 团队在这一领域取得了突破性进展,其中 DualPipe 和 EPLB 作为两项核心技术,为优化大规模模型训练提供了创新解决方案。
DualPipe 是一种创新的双向流水线并行算法。 它通过在流水线的两端同时注入微批次,实现了前向和反向传播的完全重叠,从而大幅减少了流水线空闲时间(Pipeline Bubble),显著提高了计算资源的利用率。
EPLB(Expert Parallelism Load Balancer)则是一种专家并行负载均衡算法。 通过冗余专家策略和分组限制专家路由,优化了专家并行(EP)中的负载分配,确保不同 GPU 之间的负载均衡,提高训练效率。
一、DualPipe 详解
1.1 流水线并行策略
流水线并行根据执行的策略,可以分为 F-then-B 和 1F1B 两种模式。
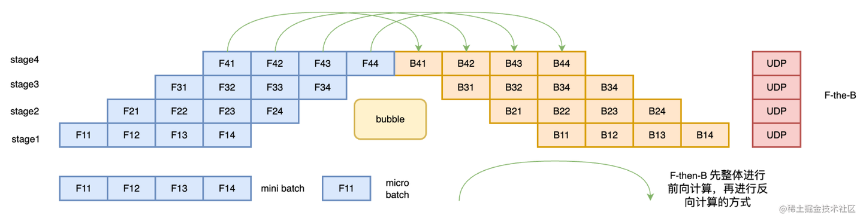
- F-then-B 策略
F-then-B 模式,先进行前向计算,再进行反向计算。该模式由于缓存了多个 micro-batch 的中间变量和梯度,显存的实际利用率并不高。
- 1F1B策略
1F1B(One Forward pass followed by One Backward pass)模式是一种前向计算和反向计算交叉进行的方式。此模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量(如下图所示,F42 在计算前,F41 的反向 B41 已经计算结束,即可释放 F41 的中间变量,从而 F42 可以复用 F41 中间变量的显存。)
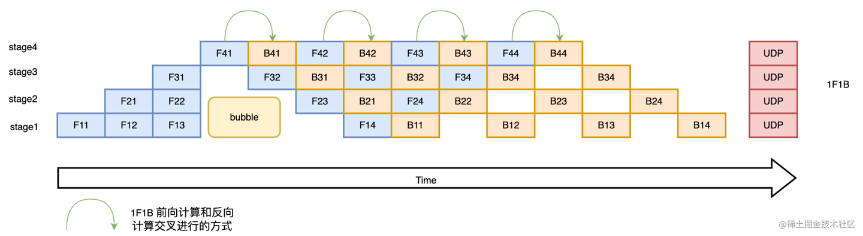
朴素流水线并行以及 GPipe 都是 F-then-B 模型,而 PipeDream 和 ZBPP 则是 1F1B 模式。
1.2 朴素流水线并行
朴素流水线并行是实现流水线并行训练的最直接的方法。我们将模型按照层间切分成多个部分(Stage),并将每个部分(Stage)分配给一个 GPU。
假设有
- 总面积为:
- 有效面积为:
- Bubble面积为:
- Bubble面积占比为:
1.3 GPipe 微批次流水线并行
微批次(MicroBatch)流水线并行与朴素流水线几乎相同,但它通过将传入的小批次(minibatch)分块为微批次(microbatch),并人为创建流水线来解决 GPU 空闲问题,从而允许不同的 GPU 同时参与计算过程。
假设有
- 总面积为:
- 有效面积为:
- Bubble面积为:
- Bubble面积占比为:
1.4 PipeStream
Gpipe 的流水线的问题:
- 将 mini-batch 切分成 m 份 micro-batch 后,将带来更频繁的流水线刷新(Pipeline flush),这降低了硬件效率,导致空闲时间的增加。
- 将 mini-batch 切分成 m 份 micro-batch 后,需要缓存 m 份 activation,导致内存增加。
为此,微软 DeepSpeed 提出的 PipeDream(1F1B 策略),针对这些问题进行了改进。其解决思路就是努力减少每个 activation 的保存时间,即这就需要每个微批次数据尽可能早的完成后向计算,从而让每个 activation 尽可能早释放。
PipeDream 具体方案:
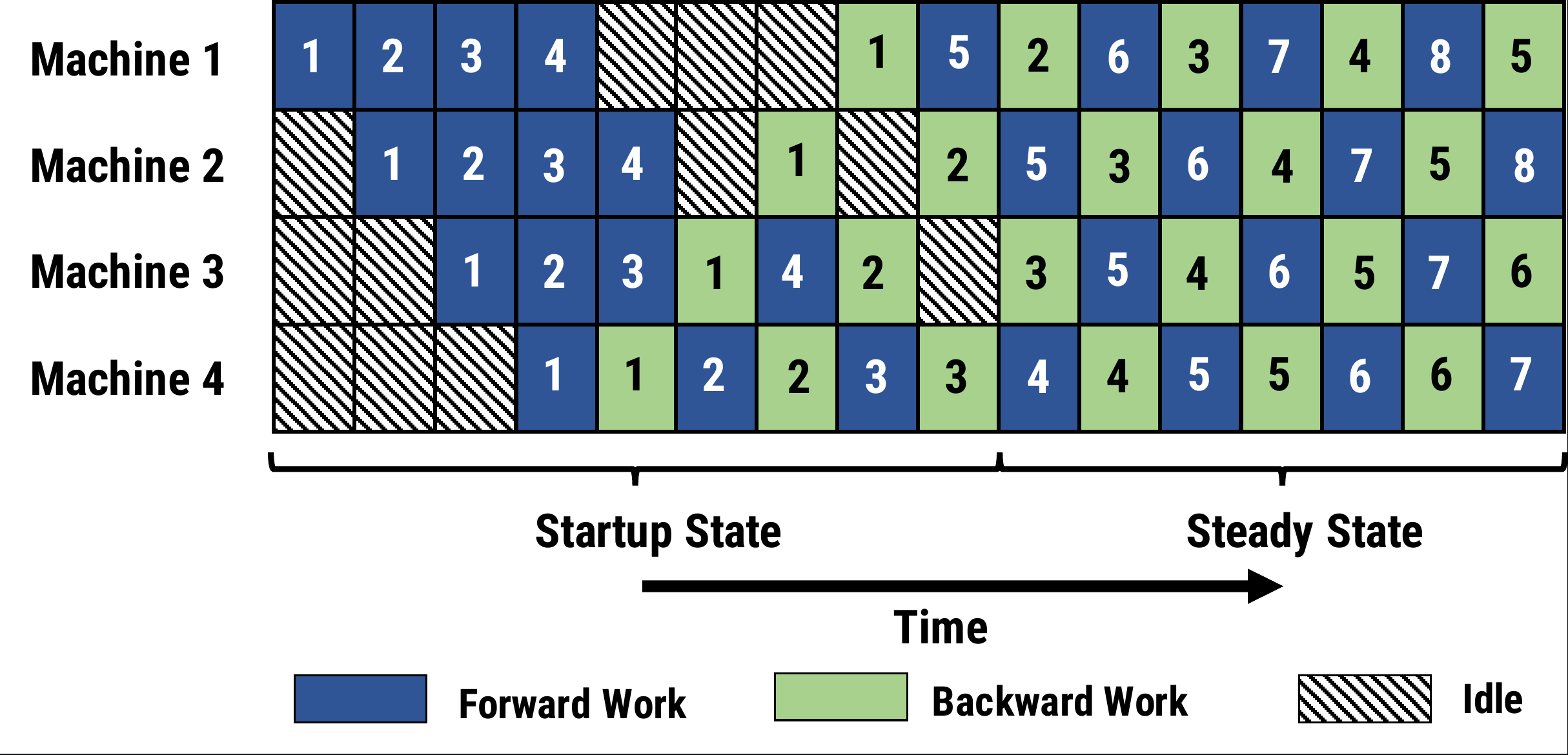
- 一个阶段(stage)在做完一次 micro-batch 的前向传播之后,就立即进行 micro-batch 的后向传播,然后释放资源,这就可以让其他 stage 尽可能早的开始计算,这就是 1F1B 策略。
- 在 1F1B 的稳定状态(steady state)下,会在每台机器上严格交替的进行前向计算/后向计算,这样使得每个GPU上都会有一个 micro-batch 数据正在处理,从而保证资源的高利用率(整个流水线比较均衡,没有流水线刷新(Pipeline Flush),这样就能确保以固定周期执行每个阶段上的参数更新。
- 面对流水线带来的异步性,1F1B 使用不同版本的权重来确保训练的有效性。
相比 GPipe,表面上看 PipeDream 在Bubble率上并没有优化,Bubble
时间仍然为:
1.5 ZBPP
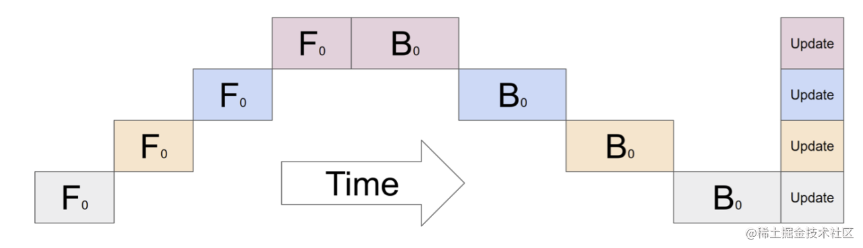
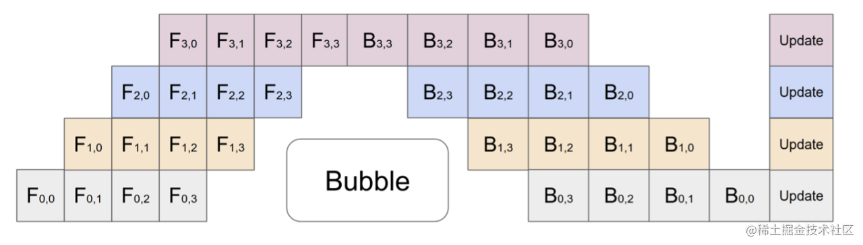
(ZBPP)Zero Bubble Pipeline Parallelism 提出一种新的调度方法,实现了近似零流水线空闲。这一改进背后的关键思想是将反向计算分为两个部分,一个计算输入的梯度,另一个计算参数的梯度。

图中 F 表示前向传递,B 和 W 分别表示计算相对于输入 x 和层级参数 W 的梯度。
ZBPP核心原理是通过在预热阶段引入更多的前向计算(F)来填补第一个反向传播(B)之前的气泡,并在尾部重新排序权重更新(W),将流水线的布局从梯形变为平行四边形,从而消除了流水线中的所有气泡。
1.6 DualPipe
DualPipe 的架构基于 Transformer 框架,并针对流水线并行进行了深度优化。其在ZB-PP划分粒度的基础上,DualPipe做了针对前向传播与后向传播都需要计算的情况,做了更细致的拆分。
DualPipe的核心思想是在一对单独的前向和反向块中重叠计算和通信。具体来说,每个计算块被划分为四个部分:Attention、All-to-All Dispatch、MLP 和 All-to-All Combine。对于后向传播块,Attention 和 MLP 进一步细分为输入梯度计算(Backward for Input)和权重梯度计算(Backward for Weights)。

如上图所示,对于一对前向和反向块,DualPipe通过重新排列这些组件,并手动调整专用于通信与计算的GPU SM(Streaming Multiprocessors)的比例,可以确保在执行过程中,全对全和PP通信都可以完全隐藏。

完整的DualPipe调度如图所示。它采用双向流水线调度,同时从流水线的两端输入微批次,并且可以完全重叠大量的通信。这种重叠还确保了随着模型进一步扩展,只要保持恒定的计算与通信比,仍然可以在节点间使用细粒度的专家,并实现接近零的全对全通信开销。
DualPipe的优势:
- DualPipe的流水线气泡更少,信道使用效率更高
- DualPipe将前向和后向传播中的计算和通信重叠解决了跨节点专家并行(EP)带来的繁重通信开销问题
- 在确保计算与通信比例恒定的情况下,具有很好的Scale-out能力
1.7 DualPipeV
ualPipeV 是由 DualPipe 通过“一分为二”的方法推导出的一种简洁的 V 形调度。如下图所示:

1.8 8. 流水线并行方案对比
| 方法 | 气泡大小 | 每设备参数量 | 每设备激活量 | 设备数量 |
|---|---|---|---|---|
| 1F1B | (PP-1)(𝐹+𝐵) | 1× | PP | PP |
| ZB1P | (PP-1)(𝐹+𝐵-2𝑊) | 1× | PP | PP |
| DualPipe | (PP/2-1)(𝐹&𝐵+𝐵-3𝑊) | 2× | PP+1 | PP |
| DualPipeV | (PP/2-1)(𝐹&𝐵+𝐵-3𝑊) | 2× | PP+1 | PP/2 |
PP 表示流水线并行阶段的数量(偶数)。𝐹 表示正向块的执行时间,𝐵 表示完整反向块的执行时间,𝑊 表示“反向权重”块的执行时间,𝐹&𝐵 表示两个相互重叠的正向和反向块的执行时间。
二、EPLB 详解
2.1 专家并行(EP)
专家并行(Expert Parallelism,EP) 是一种在混合专家模型(Mixture of Experts,MoE)中采用的训练方法。它将模型中的不同“专家”分配到不同的计算设备上,以提高计算效率。
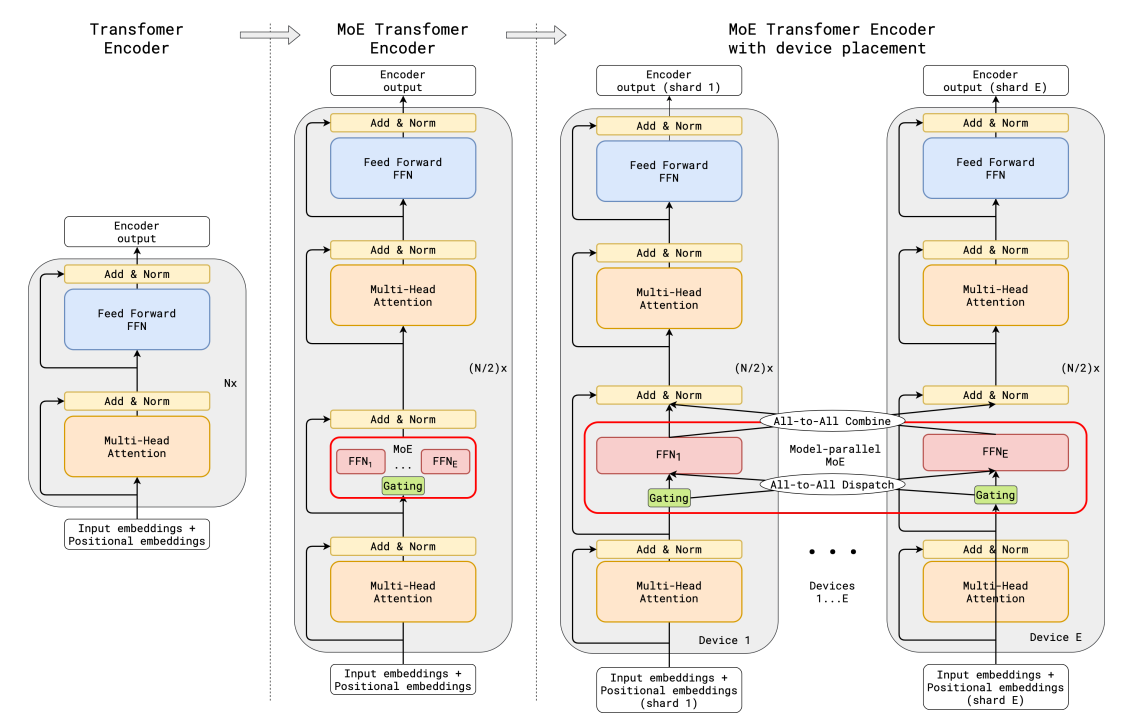
在专家并行中,负载均衡是一个关键挑战,因为不同专家分配在不同GPU上,负载往往不平均——有的专家经常被大量样本命中,成为热点,而有的却很少工作。这导致某些GPU忙不过来、成为瓶颈,而其他GPU又闲置浪费。这种木桶短板效应,限制了整体的吞吐。
2.2 EPLB 冗余专家策略
简单来说,冗余专家策略就是复制负载较重的专家。然后将这些复制的专家打包到 GPU 上,以确保不同 GPU 之间的负载平衡,从而提高模型训练的效率和稳定性。
EPLB冗余专家策略的关键点:
负载检测:在线部署期间,EPLB持续收集关于各个专家负载的统计数据。这些数据用于识别哪些专家是高负载的。 专家复制:对于检测到的高负载专家,EPLB会在其他GPU上创建这些专家的副本,即冗余专家。目的是分散负载,避免某些GPU过载而其他GPU闲置。 定期调整:冗余专家的集合会定期(例如,每10分钟)根据观察到的负载进行调整,以确保负载均衡。 负载重分配:在确定冗余专家集之后,EPLB会根据当前的负载情况,重新安排专家在GPU之间的分布,以尽可能平衡负载,同时尽量减少跨节点的全对全通信开销。 动态冗余:EPLB还探索了动态冗余策略,即在每个推理步骤中,每个GPU可能承载更多的专家,但只有一部分会被激活,以进一步优化负载均衡。
2.3 负载均衡策略
EPLB负载均衡算法包含两种策略,用于不同的场景。
- 分层负载均衡
- 当服务器节点数能够整除专家组数时,使用该策略来利用分组限制专家路由。
- 首先将专家组均匀地分配到节点上,确保不同节点的负载平衡。然后,在每个节点内复制专家。最后,将复制的专家分配到各个 GPU 上,以确保不同 GPU 的负载平衡。
- 适用阶段:较小的专家并行规模的预填充阶段。
- 全局负载均衡
- 在全局范围内复制专家,而不考虑专家组,并将复制的专家分配到各个 GPU 上。
- 适用阶段:较大的专家并行规模的解码阶段。
- 接口和示例
以下代码展示了一个两层 MoE 模型的示例,每层包含 12 个专家。我们在每层引入 4 个冗余专家,总共 16 个副本被放置在 2 个节点上,每个节点包含 4 个 GPU。
1 | |
由分层负载均衡策略生成的输出,表示为下图所示的专家复制和放置计划。

- 与传统负载均衡技术对比
| 类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 静态分配 | 实现简单 | 资源浪费严重 | 小规模模型 |
| 动态路由 | 适应性较强 | 通信开销大 | 中等规模模型 |
| EPLB策略 | 资源利用率最大化 | 需要冗余计算资源 | 超大规模MoE模型 |