DeepSeek DeepGEMM
大多数AI技术的核心,背后其实都离不开一种计算——矩阵乘法(GEMM)。别把这个当做数学教科书的一种公式计算,实际上 GEMM 就像是深度学习的“心脏”,几乎每个AI模型训练、每次预测,都少不了它的身影。
DeepGEMM 是一个专为 NVIDIA Hopper 架构设计的高效 FP8 矩阵乘法库,支持普通和混合专家模型(MoE)分组矩阵乘法,通过简洁的实现和即时编译技术,实现了高性能和易用性。
一、GEMM与TensorCore
1.1 GEMM
GEMM(General Matrix Multiplications)即通用矩阵乘法,是将两个矩阵的进行相乘的计算。这种方法称为一般矩阵乘法 (GEMM)。科学计算库(如 Numpy、BLAS 等)和大模型都使用了GEMM。此实现仅适用于方阵。这样做是为了避免使算法过于复杂而无法处理矩形矩阵。
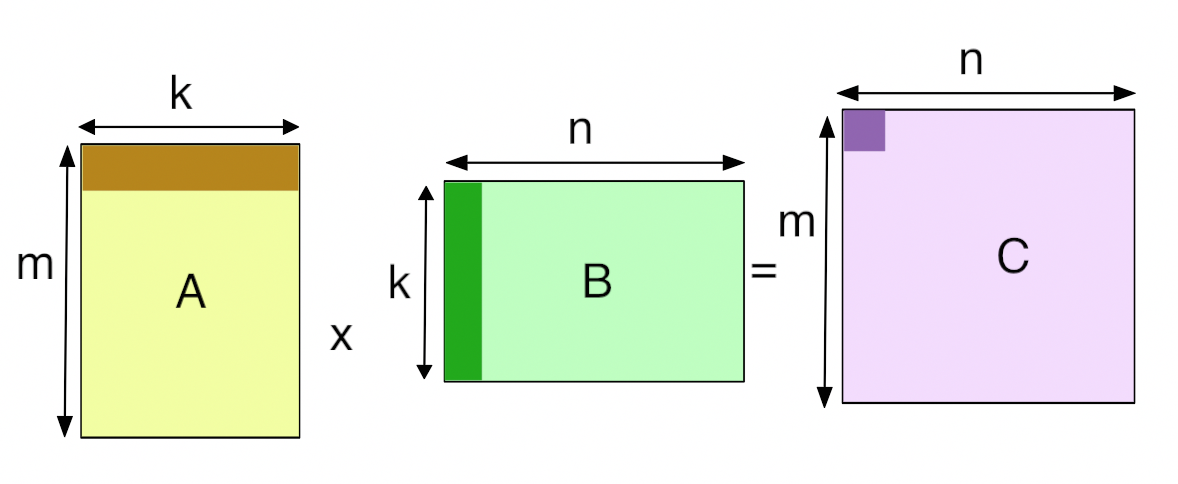
在GPU中,GEMM 定义为运算
GPU 通过将输出矩阵划分为图块来实现
GEMM,然后将其分配给线程块。图块大小(Tile
Size)通常是指这些图块的尺寸。每个线程块通过单步执行图块中的 K 维度,从
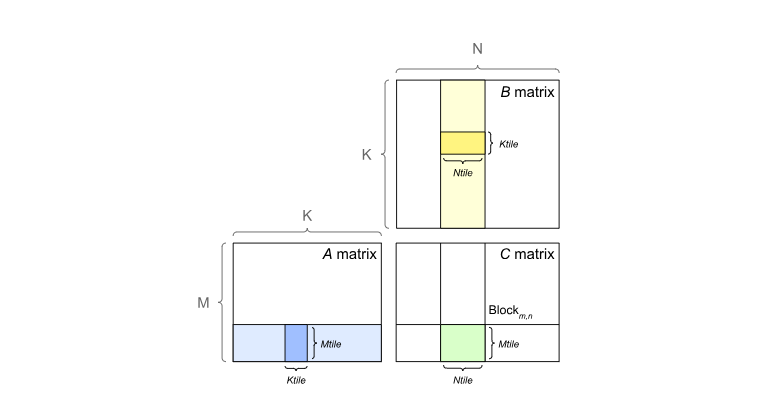
1.2 Tensor Core
英伟达GPU 引入了 Tensor Core(张量核心) 来最大限度地提高GEMM的速度。使用 Tensor Core 的要求取决于 英伟达库的版本。
第一代 Tensor Core 是随 Volta 架构引入的,从 V100 开始,随着数据格式的变化,Tensor Core也在不断更新。
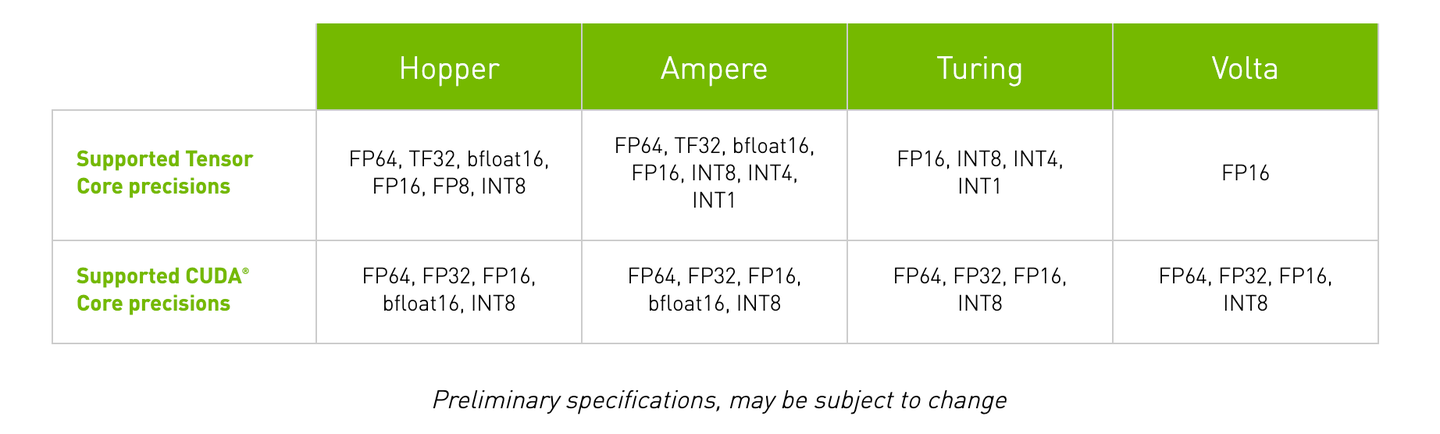
GEMM的实现效率与Tensor Core结构和数据格式密切相关,受数据的调度方式影响很大。因此基于Tensor Core的硬件架构进行计算优化就显得十分重要。好的优化往往能取得数倍的性能提升。
二、DeepGEMM
- FP8 低精度支持:DeepGEMM 最大的特色在于从架构上优先设计为 FP8 服务。传统GEMM库主要优化FP16和FP32,而DeepGEMM针对FP8的特殊性进行了优化设计。
- 极致性能与极简核心实现:DeepGEMM在NVIDIA Hopper GPU上实现了高达1350+ FP8 TFLOPS的计算性能,同时其核心代码仅有约300行
- JIT 即时编译:DeepGEMM 不是预先编译好所有可能配置的内核,而是利用 JIT 在运行时生成最佳内核。例如,根据矩阵大小、FP8尺度等参数,JIT 会即时优化指令顺序和寄存器分配。
2.1 FP8 支持优化
使用FP8框架进行训练的主要挑战在于精度与误差的处理,DeepSeek为其FP8低比特训练框架做了以下优化:
- 细粒度量化
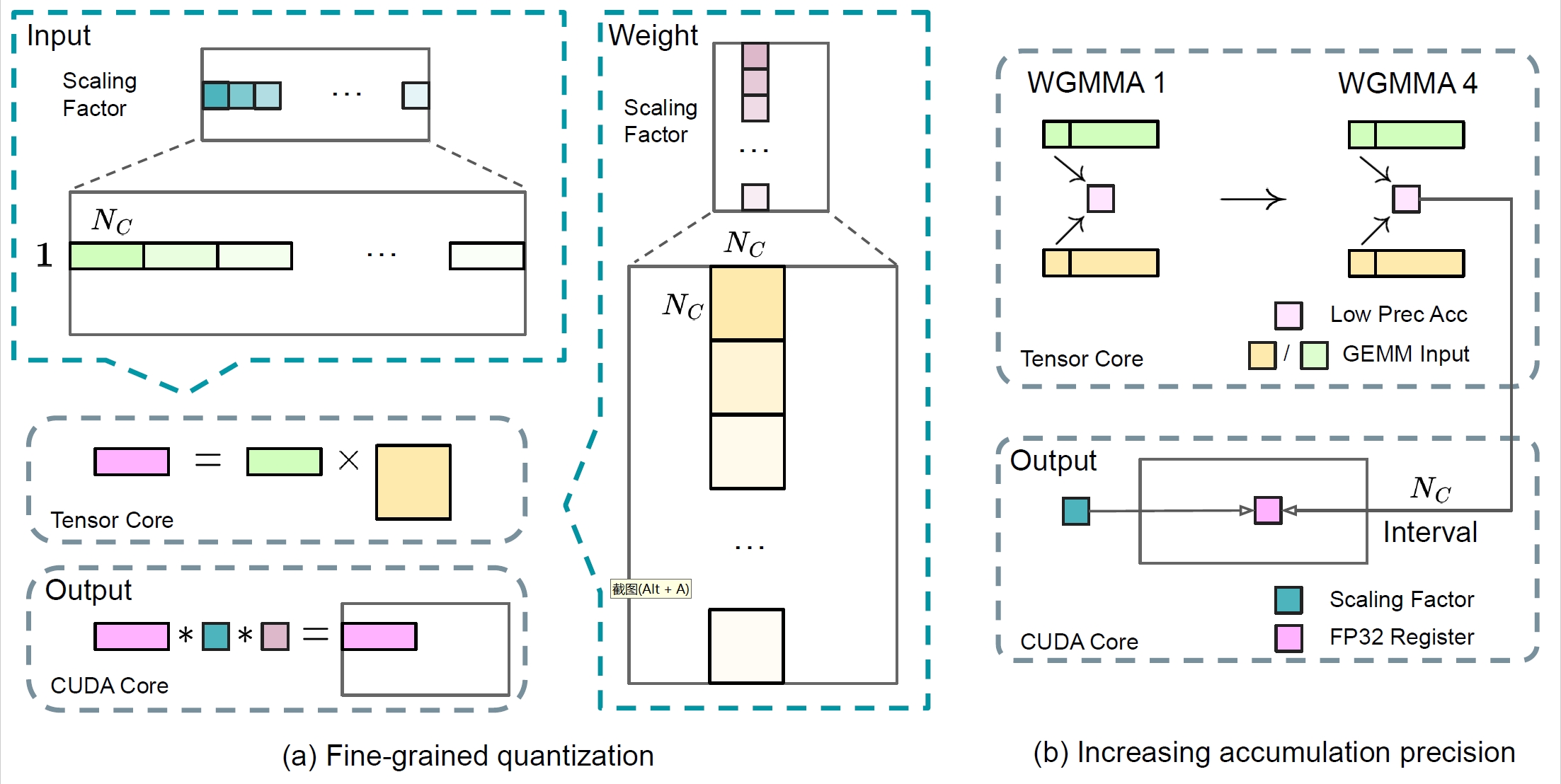
将数据分解成更小的组,每个组都使用特定乘数进行调整以保持高精度。这一方法类似于Tile-Wise或Block-Wise。对于激活,在1x128大小的基础上对计算数据进行分组和缩放;对于权重,以128x128大小对计算数据进行分组和缩放。该方法可以根据最大或最小数据调整缩放系数,来更好的适应计算中的异常值。
- 在线量化 为了提高精度并简化框架,该框架在线计算每个1x128激活块或128x128权重块的最大绝对值,在线推算缩放因子,然后将激活或权重在线转化为FP8格式,而不是采用静态的历史数据。相对静态的量化方法,该方法可以获得更高的转换精度,减小误差的累积。
- 提高累加精度
FP8在大量累加时会累积出现随机误差。例如FP8 GEMM在英伟达H800 GPU上的累加精度保留14位左右,明显低于FP32累加精度。以K= 4096的两个随机矩阵的GEMM运算为例,Tensor Core中的有限累加精度可导致最大相对误差接近2%。DeepSeek将中间结果储存计算升级为FP32(32位浮点),实行高精度累加,然后再转换回FP8,以降低大量微小误差累加带来的训练偏差。
- 低精度/混合精度存储与通信
为了进一步减少MoE训练中的显存和通信开销,该框架基于FP8进行数据/参数缓存和处理激活,以节省显存与缓存空间并提升性能,并在BF16(16位浮点数)中存储低精度优化器状态。该框架中以下组件保持原始精度(例如BF16或FP32):嵌入模块、MoE门控模块、归一化算子和注意力算子,以确保模型的动态稳定训练。为保证数值稳定性,以高精度存储主要权重、权重梯度和优化器状态。
2.2 持久化Warp专业化
Warp 的概念是 NVIDIA GPU 架构中的一个重要特性,它使得开发者能够更细致地控制线程的执行,以优化并行计算的性能。 在 CUDA 编程模型中,Warp 是 GPU 上并行执行的最小单元。一个 Warp 包含 32 个线程,这些线程在同一个周期内执行相同的指令。这意味着,如果一个 Warp 中的所有线程都执行相同的操作,那么它们可以并行地在 GPU 上执行,从而提高计算效率。
遵循CUTLASS的设计,DeepGEMM中的内核是warp专业化的,能够重叠数据移动、张量核心MMA指令和CUDA核心提升。下图展示了这一过程的简化示意图:

- TMA Warps:负责异步数据加载,通过 TMA 指令减少内存访问延迟。
- Math Warps:执行实际的矩阵乘法计算(WGMMA 表示张量核心矩阵乘法)。
- Promotion:在计算过程中进行数据的累加操作。
2.3 Tensor Memory Accelerator (TMA)
Tensor Memory Accelerator(TMA) 是NVIDIA Hopper架构中的一项新功能,它旨在加速GPU的内存访问。TMA通过使用全局内存(GMEM)和共享内存(SMEM)进行数据复制,从而提高GPU的整体性能。 在DeepGEMM中,TMA被用于以下操作:
- TMA 多播(Multicast):一次性将数据广播到多个计算单元,减少重复加载。
- TMA 描述符预取:提前加载数据地址信息,避免计算过程中的延迟。
- 用于LHS、LHS缩放因子和RHS矩阵的TMA加载
- 用于输出矩阵的TMA存储
- 效果:在 DeepSeek-V3 的 MoE 模型中,TMA 使数据搬运效率提升 30%,显著减少计算等待时间。
2.4 动态 JIT 编译
2.4.1 JIT 技术的定义与原理
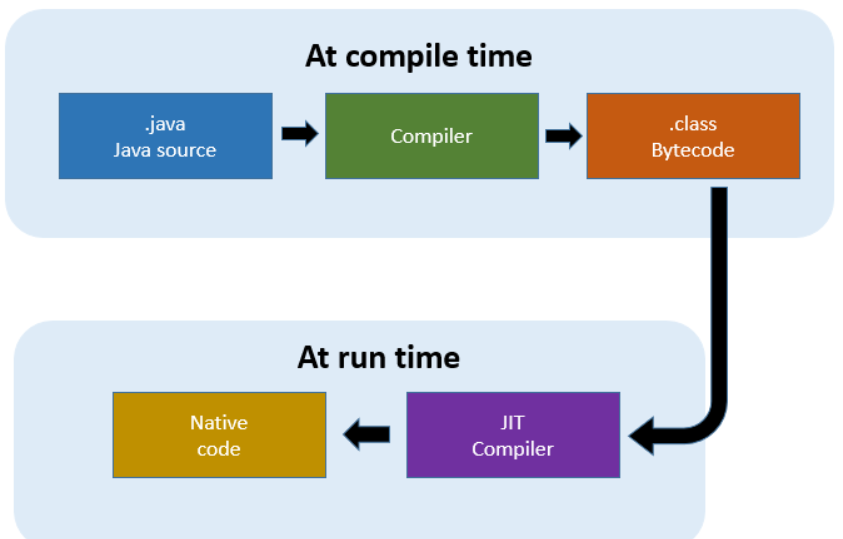
即时编译(JIT)是一种在程序运行时动态生成和优化代码的技术。与传统的编译方式(如提前编译,Ahead-Of-Time,AOT)不同,JIT 编译器不会在程序安装或部署时生成最终的可执行代码,而是在程序运行时根据实际的输入和运行环境动态生成优化后的代码。这种技术的核心思想是“延迟编译”,即在代码真正需要执行时才进行编译和优化,从而针对具体的运行场景生成最高效的目标代码。
2.4.2 JIT 技术的优势
JIT 技术在现代计算中具有广泛的应用,尤其是在高性能计算和动态语言运行环境中。它相比传统的静态编译方式具有以下显著优势:
- 更高的性能:JIT 编译器可以根据运行时的具体输入和硬件环境动态生成优化代码。例如,它可以针对不同的矩阵大小、数据类型或硬件特性选择最适合的算法和优化策略,从而实现比静态编译更高的性能。
- 灵活性与可扩展性:由于 JIT 编译器在运行时生成代码,因此它可以轻松适应不同的硬件架构和输入数据特征。这种灵活性使得 JIT 技术特别适合于需要处理多种输入场景和硬件环境的应用程序。
- 减少编译时间与资源消耗:在传统的静态编译中,编译器需要考虑所有可能的输入情况并生成通用的代码。这往往导致复杂的编译过程和较长的编译时间。而 JIT 编译器只需在运行时针对当前输入生成代码,因此可以显著减少编译时间和资源消耗。
2.4.3 在 DeepGEMM 中的应用
DeepGEMM 采用完全即时编译(JIT)设计,安装时无需编译。所有内核在运行时使用轻量级 JIT 实现进行编译。这种方法具有以下几个优点:
- GEMM形状、块大小和流水线阶段数被视为编译时常量
- 节省寄存器
- 编译器可以进行更多优化
- 自动选择块大小、warpgroup数量、最佳流水线阶段和TMA集群大小
- 但没有自动调优,确定性地选择最佳方案
- 完全展开MMA流水线,为编译器提供更多优化机会
- 对于小形状非常重要
2.5 其他
- FFMA 指令交错优化
DeepGEMM 通过修改编译后的 GPU 指令(SASS),在FFMA(浮点乘加)指令中插入Yield和Reuse控制位,实现了10% 以上的性能提升。
原来的GPU线程会因为资源竞争导致停滞,现在是相当于指令重排,让某些线程主动让出计算资源,从而减少浪费。
- 支持分组GEMM
与 CUTLASS 中传统的分组 GEMM 不同,DeepGEMM 仅对 M 轴进行分组,而 N 和 K 可保持不变。(可专门针对 MoE 模型中的专家量身定制)
- 使用PTX指令进行性能优化
使用stmatrix PTX 指令。
三、代码分析
3.1 FP8: 提升速度的基础
为什么是 FP8?这都是为了效率。torch.float8_e4m3fn与 BF16 的 16 位或 FP32 的 32 位相比,FP8(特别是在 PyTorch 中)仅使用 8 位来表示浮点数。这意味着:
- 减少内存占用: 将存储权重和激活所需的内存减少一半。
- 增加内存带宽:每个时钟周期移动两倍的数据。
- 更快的张量核心操作: Hopper 的张量核心专为 FP8 设计,可实现峰值性能。
然而,FP8 的动态范围较小,这就是 DeepGEMM 包含细粒度缩放的原因。这涉及动态调整比例因子,以确保相乘的值落在 FP8 的可表示范围内。
1 | |
此代码片段演示了 DeepGEMM 如何缩放输入张量x以适应 FP8 范围。它计算每个 128 个元素块的最大绝对值 (x_amax),并使用此值缩放输入,然后将其转换为 FP8。然后存储缩放因子以供以后使用。
3.2 TMA:数据迁移大师
张量内存加速器 (TMA) 是 Hopper 上的一项重大变革。它是专用于异步数据移动的硬件单元,可释放 CUDA 核心进行计算。DeepGEMM 利用 TMA 实现以下功能:
- 加载 LHS、RHS 和缩放因子: 更快、更有效地获取数据。
- 存储输出矩阵: 异步写入全局内存。
- TMA 多播: 跨多个线程复制 LHS 数据,减少内存流量。
TMA 核心的 ASCII 图(简化):
1 | |
TMA 充当全局内存和 CUDA 核心之间的中介,允许数据传输与计算并行进行。多播功能通过减少加载 LHS 矩阵所需的内存访问次数进一步提高了性能。
1 | |
此 C++ 代码片段展示了 DeepGEMM 如何为 LHS、RHS、缩放因子和输出矩阵配置 TMA 描述符。这些描述符告诉 TMA 如何加载、存储和多播数据。
DeepGEMM遵循 CUTLASS 设计, 其内核为 warp 专用,支持重叠式的数据移动、张量核心 MMA 指令和 CUDA 核心优化。
- TMA(Tensor Memory Accelerator):Hopper 架构的硬件特性,用于异步数据加载或移动(如 LHS 矩阵、缩放因子等),减少内存访问延迟。
- 指令重叠:内核采用 warp-specialized 设计,允许数据移动、张量核心 MMA(矩阵乘加)指令和 CUDA 核心累加操作重叠。
- FP8 微调:通过修改编译后二进制的 FFMA(融合乘加)指令,调整 yield 和 reuse 位,进一步提升性能(据称在某些情况下提升 10%+)。
- 区块调度器:通过统一的调度器调度所有非分组和分组内核,栅格化(Rasterization )以增强 L2 缓存的复用/重用。
这些优化使得 DeepGEMM 在大多数矩阵大小上优于专家调优的内核,同时保持代码简洁。
3.3 JIT:可变形的内核
DeepGEMM 采用即时 (JIT) 编译。这意味着内核在运行时进行编译,并根据特定的矩阵形状和硬件配置进行定制。这允许:
- 形状特定优化: 为每个 GEMM 操作选择最佳的块大小、warpgroup 数量和管道阶段。
- 编译器展开: 完全展开 MMA 管道,为编译器提供更多的优化机会,尤其是对于小形状。
- 寄存器计数控制:针对不同的 warpgroups 微调寄存器的使用。
1 | |
此 Python 代码片段展示了 DeepGEMM 如何使用 JIT 编译器为给定的矩阵形状和硬件配置生成专用内核。keys字典指定用于自定义内核的参数。
3.4 FFMA 交错:SASS 级别的秘密武器
这就是事情变得真正有趣的地方。DeepGEMM 在 SASS(CUDA 汇编)级别进行了低级优化。通过分析编译后的代码,开发人员发现翻转FFMA(融合乘加)指令中的特定位可以提高性能。
- 扭曲级并行性: 翻转的位控制yield行为,可能允许扭曲交错执行并改善扭曲级并行性。
- 寄存器重用: 位reuse也被翻转,创造了更多将 MMA 指令与提升FFMA指令重叠的机会。
1 | |
此 Python 代码片段展示了 DeepGEMM 如何修改FFMA已编译的 SASS 代码中的指令。它提取指令的十六进制表示形式,翻转reuse和yield位,然后用修改后的指令替换原始指令。
3.5 MoE 特定分组:连续和掩蔽
MoE 模型引入了新的复杂度。DeepGEMM 使用两种常见 MoE 布局的专用内核来解决这个问题:
- 连续布局: 专家处理不同数量的标记,这些标记被连接成一个张量。
- 掩蔽布局: 在推理解码期间使用,其中每个专家收到的标记数量是未知的。
连续布局:
1 | |
在连续布局中,m_indices张量指定 LHS 矩阵的每一行属于哪个专家。这使得内核能够有效地为每个专家执行 GEMM 操作。
掩蔽布局:
1 | |
在掩码布局中,masked_m张量指定每组中有效行的数量。这允许内核跳过无效行的计算,从而提高性能。
3.6 与其他库相比
- vLLM: vLLM 通过优化内存管理、调度和量化,专注于高吞吐量推理。虽然 vLLM 可能在内部使用优化的 GEMM 内核,但 DeepGEMM 为 Hopper 上的 FP8 GEMM 提供了更专业的解决方案。
- CUTLASS: CUTLASS 是一个全面的线性代数 CUDA 内核库。DeepGEMM 利用了 CUTLASS 的一些概念,但避免了对其模板和代数的过度依赖,而是选择了更简单、更易于访问的设计。
- CuTe:专注于张量操作的抽象,灵活但需要较深理解。
DeepGEMM 的主要优势在于它专注于最大限度地提高 Hopper 上 FP8 GEMM 的性能,尤其是在 MoE 模型的背景下。它通过结合 TMA 掌握、JIT 编译和 FFMA 交错等低级优化来实现这一点。