DeepSeek DeepEP
DeepEP 是一款专为混合专家(MoE)和专家并行(EP)设计的高性能通信库。它具有高效的全连接 GPU 内核(通常称为 MoE 分发和合并),能够实现出色的吞吐量和极低的延迟。此外,DeepEP 支持包括 FP8 在内的低精度计算,确保了深度学习工作负载的灵活性。
DeepEP的核心亮点
全场景覆盖的通信内核:提供高吞吐量内核(支持NVLink/RDMA混合转发)和超低延迟内核(纯RDMA通信),分别适配训练/预填充阶段和实时解码需求。同时支持FP8低精度计算,进一步提升通信效率。
异构带宽转发优化:针对不同网络域之间的通信进行了优化,支持异构带宽转发,实现NVLink与RDMA的高效协同,实测节点间通信带宽达46 GB/s(接近硬件极限)。
计算与通信重叠技术:引入基于hook的通信-计算重叠方法,不占用SM资源,实现网络传输与模型计算的并行化。
一、MoE简要回顾
MoE全称是Mixture of Expert, 它是训练超大模型的核心关键,从架构上是在Transformer Block输出之前做最后的特性提取。它的本质是通过一个门控逻辑让神经网络选择某一块Transformer激活,而不是全部,这样稀疏化的结构可以在运行时减少不必要的计算,同时保持了网络大参数量带来的高性能,是提高预训练效率与推理的神器,让Transformer架构具备非常好的可扩展性。从下图可以看到,在DeepSeek的MoE里面主要分为Routed Expert和Shared Expert 两个部分。这样设计的背后逻辑是将专家进行更细粒度的划分,以实现更高的专家专业化程度和更精准的知识获取;同时隔离一些共享专家,以减轻路由到的专家之间的知识冗余,效果远好于标准的GShard架构。
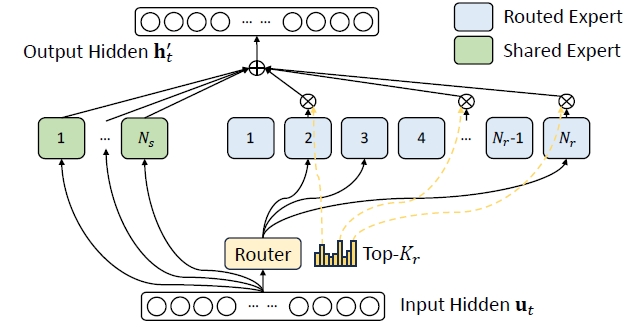
在 DeepSeek‐V3 的 MoE 模块中,主要包含两类专家:
- 路由专家(Routed Experts):每个 MoE 层包含 256 个路由专家,这些专家主要负责处理输入中某些特定、专业化的特征。
- 共享专家(Shared Expert):每个 MoE 层中还有 1 个共享专家,用于捕捉通用的、全局性的知识,为所有输入提供基本的特征提取支持。
token传入MoE时的处理流程:
计算得分:首先,经过一个专门的 Gate 网络,该网络负责计算 token 与各个路由专家之间的匹配得分。
选择专家:基于得分,Gate 网络为每个 token 选择 Top-K 个最合适的路由专家(DeepSeek‐V3 中通常选择 8 个)
各自处理:被选中的专家各自对 token 进行独立处理,产生各自的输出。
合并输出:最终,根据 Gate 网络给出的权重加权聚合这些专家的输出,再与共享专家的输出进行融合,形成当前 MoE 层的最终输出表示。
DeepSeek MoE的公式
其中:
和 分别表示共享专家和路由专家的数量; 和 分别表示第 个共享专家和第 个路由专家; 表示激活的路由专家数量; 是第 个专家的门控值; 是 token 与专家的亲和度,DeepSeek v3是sigmoid,v2是softmax; 是第 个路由专家的中心; 表示为第 个 token 和所有路由专家计算出的亲和力得分中, 个最高得分组成的集合。
为了避免细粒度的专家切分导致网络巨大,DeepSeek对MoE架构加了一层限制,让专家最多分布在M个设备中,在每次选择Topk之前,先对筛选出M个有着最高亲和性的设备。同时,研究表明,如果expert负载不均衡,会导致routing崩塌。通常的做法是增加一个auxiliary loss, deepseek则通入引入bias item来实现负载均衡与模型性能之间的平衡。
1.1 传统MoE通信问题
- 高通信开销:MoE模型中的all-to-all通信操作(如分发和聚合)需要在不同设备之间传输大量数据。在大规模分布式训练中,这种高通信开销严重影响了模型的训练效率。
- 低GPU利用率:MoE模型的通信操作通常是同步的,这意味着在通信过程中,GPU需要等待数据传输完成才能继续执行计算任务,这种同步通信约束导致GPU利用率低下。此外,由于MoE模型的稀疏性,不同专家模块的负载可能不均衡,进一步加剧了GPU资源的浪费。
- 异构网络环境的复杂性:在实际部署中,MoE模型通常运行在异构网络环境中,传统的通信方案难以高效地利用这种异构带宽。
1.2 DeepEP的解决方案
DeepEP 提供了两类内核模式,使其能同时服务训练和推理两种截然不同的需求。
- 高吞吐量的全对全(all-to-all)GPU内核,能很好的支持MoE的分发(dispatch)和合并(combine)操作,适用于大规模分布式训练和推理预填充阶段。
- 低延迟内核专门优化了推理解码阶段的通信延迟,能够将延迟降低到163微秒。通过纯RDMA通信,避免了NVLink和RDMA之间的切换延迟,从而实现了高效的实时推理。
| 场景类型 | 技术方案 | 性能提升 |
|---|---|---|
| 训练预填充 | 批量聚合+流水线调度 | 吞吐量↑320% |
| 推理解码 | RDMA零拷贝+轻量化协议栈 | 延迟↓67% |
| 动态专家调度 | 拓扑感知路由+专家负载均衡 | 资源消耗↓45% |
通过这种全场景覆盖的设计,DeepEP能够满足不同阶段的通信需求,显著提升系统的整体性能。
二、异构带宽转发优化
异构网络环境通常包括两种主要的通信技术:NVLink 和 RDMA。这两种技术在性能和应用场景上各有特点,但它们的协同优化是提升通信效率的关键。
2.1 MoE 的 All-to-All 通信
All-to-All 通信是一种多对多的通信模式,其中每个参与进程都向所有其他进程发送不同的数据,同时接收来自所有其他进程的数据。这种通信模式允许每个进程与其他所有进程进行数据交换,从而实现全局数据的共享和分发。
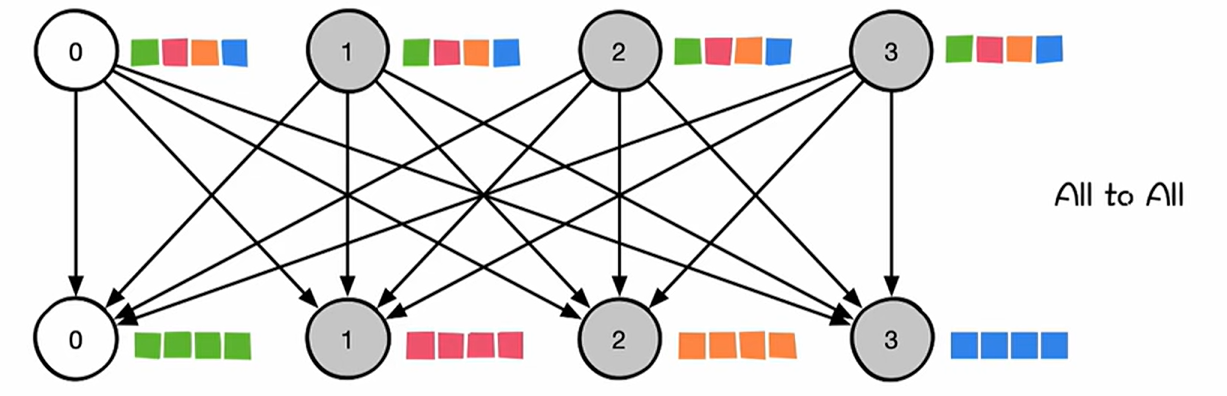
All-to-All通信是MoE模型中不可或缺的机制,其作用是确保输入数据正确分发到各个专家,同时将专家的输出结果正确整合。通常分为两个阶段:
- Dispatch(分发):在这一阶段,输入数据(如tokens)根据门控函数的决策被发送到目标GPU上的专家模块。
- Combine(组合):在专家模块完成计算后,结果需要被发送回原始的GPU,以便进行后续的处理。
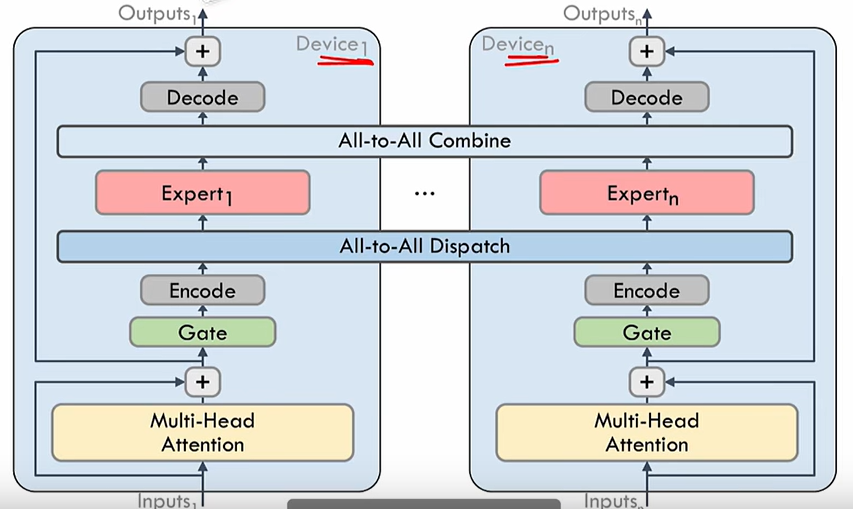
2.2 NVLink介绍
NVLink 是一种专门设计用于连接 NVIDIA GPU 的高速互联技术。它允许 GPU 之间以点对点方式进行通信,绕过传统的PCIe总线,实现了更高的带宽和更低的延迟。NVLink 可用于连接两个或多个 GPU,以实现高速的数据传输和共享,为多 GPU 系统提供更高的性能和效率。
2.3 RDMA介绍
DMA(Direct Memory Access) 的核心目标是加速设备(如硬盘、显卡、网卡)与本地内存之间的数据流动,允许外部设备能够绕过CPU直接访问主机的系统主存;
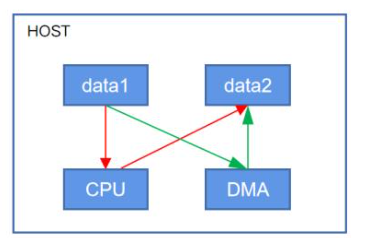
RDMA(Remote Direct Memory Access)在概念上是相对于DMA而言的。指外部设备能够绕过CPU,不仅可以访问本地主机的主存,它还可以访问另一台远端主机上用户态的系统主存。它不仅继承了 DMA 的核心能力,还扩展到了网络通信范畴,提供了远程节点间的高效、零拷贝通信。
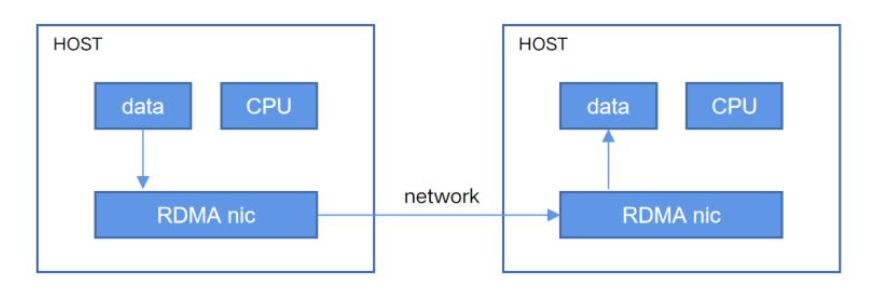
2.4 NVLink 和 RDMA 的协同优化
在MoE模型中,通信任务通常涉及节点内(如GPU之间的通信)和节点间(如跨服务器的通信)两种场景。NVLink和RDMA分别在这些场景中表现出色,但传统的通信方案难以充分利用它们的异构带宽。
DeepEP主要通过以下策略优化异构带宽转发优化:
- 混合带宽转发机制
DeepEP支持将数据从NVLink域高效转发到RDMA域,通过优化数据传输路径,确保数据在NVLink和RDMA之间的切换过程中不会引入额外的延迟。从而在节点内和节点间通信中实现无缝切换。同时,根据通信任务的大小和目标设备的带宽特性,DeepEP可以动态选择最优的转发路径。
- 非对称带宽优化
针对NVLink和RDMA的带宽差异,DeepEP引入了非对称带宽优化策略。在从NVLink域到RDMA域的数据转发中,对数据进行压缩,以减少在低带宽网络中的传输延迟。同时,通过动态调整通信任务的分配,确保在异构带宽环境中充分利用每种通信技术的优势。
- 低延迟内核设计
在实时推理任务中,通信延迟是关键性能指标之一。DeepEP提供了纯RDMA的低延迟内核,专门优化了跨节点通信的延迟。引入了基于Hook的通信-计算重叠机制,确保在通信过程中不占用GPU的SM资源,从而实现计算与通信的并行化。
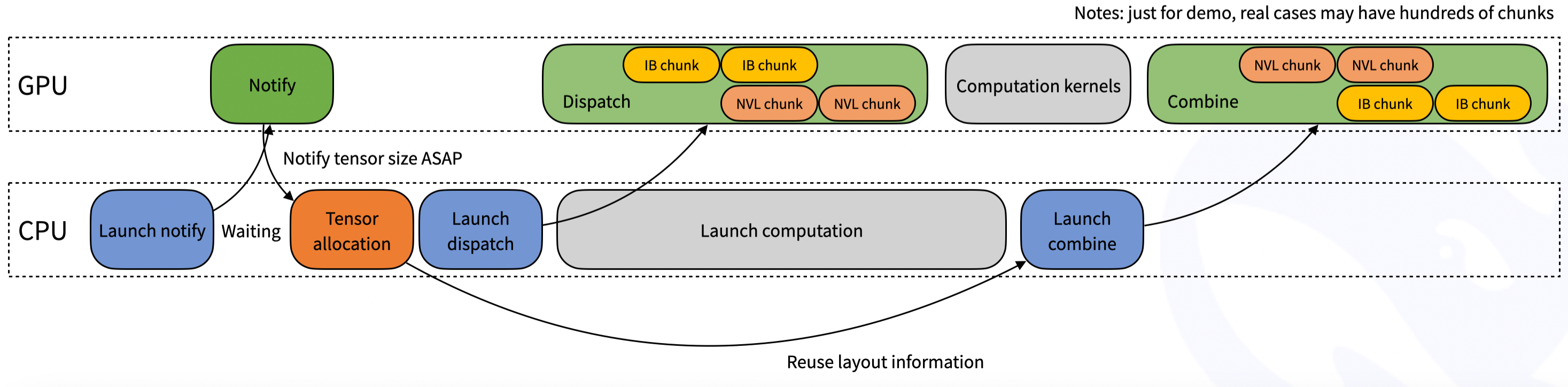
三、计算与通信重叠技术
3.1 Hook机制介绍
Hook机制是一种在程序运行时动态拦截和修改程序行为的技术。它通过在程序的关键位置插入自定义代码,实现对程序执行流程的监听和修改。Hook机制的核心在于拦截和重定义函数调用。
Hook机制的工作原理分为以下几个关键步骤:
- 定义拦截点:确定需要拦截的函数或方法。例如,在MoE模型中,拦截点可能是All-to-All通信的入口函数。
- 创建代理函数:通过动态代理或函数指针,创建一个代理函数来替代原始函数。代理函数中可以插入自定义逻辑。
- 执行自定义逻辑:在代理函数中,执行自定义逻辑(如日志记录、数据压缩等),然后调用原始函数。
- 恢复原始行为:在某些情况下,需要在自定义逻辑执行完成后恢复原始函数的行为。
3.2 计算与通信重叠优化
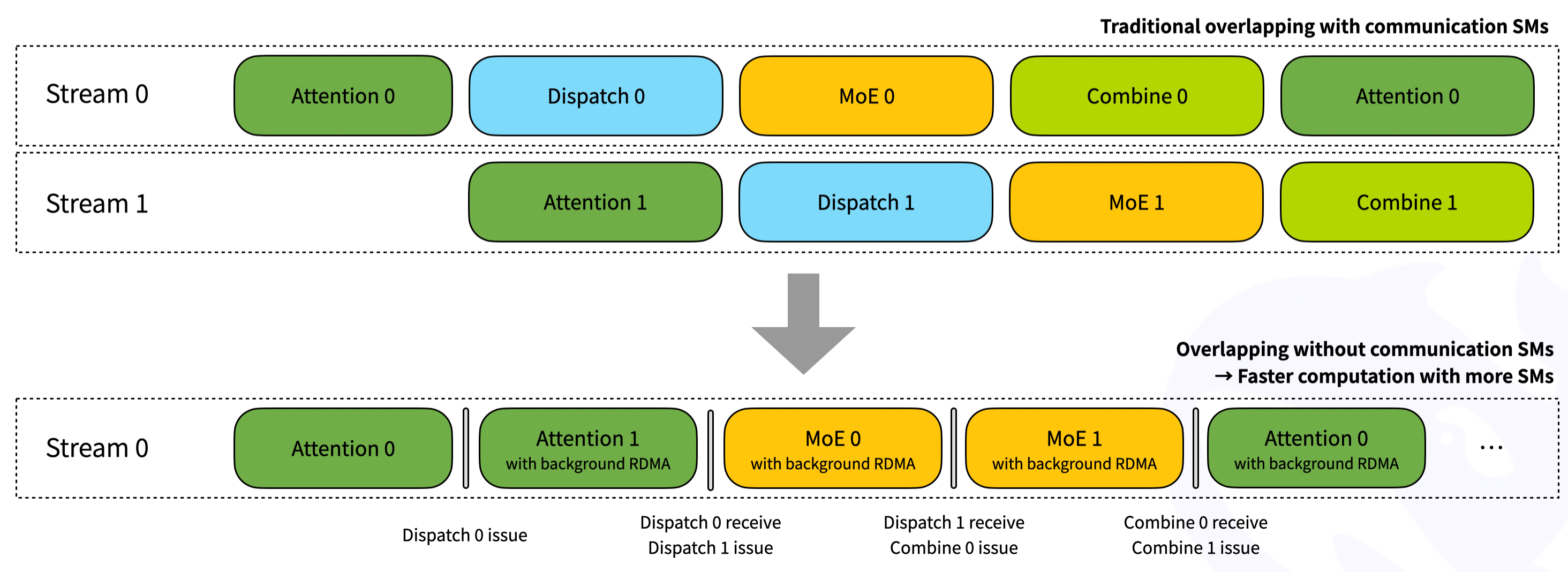
如图中上半部分所示,在传统的通信重叠方法中,通信操作(如Dispatch和Combine)和计算操作(如Attention和MoE)在不同的CUDA流(Stream)中串行执行。这种方法存在以下问题:
- 通信与计算的串行执行:通信操作和计算操作在不同的流中依次执行,导致通信操作完成后才能开始计算操作,增加了等待时间。
- 占用通信SM:通信操作需要占用专门的通信SM(Streaming Multiprocessors),这些SM在通信过程中无法执行计算任务,降低了GPU的利用率。
图中下半部分,DeepEP通过引入基于Hook的通信-计算重叠方法,使用异步通信机制(如RDMA),在后台执行通信操作,而不阻塞计算操作的执行,实现了计算与通信的并行化。通过Hook机制,DeepEP避免了通信操作占用专门的通信SM,从而可以利用更多的SM进行计算,提高了GPU的利用率。
- Stream 0:
- Attention 0:计算操作,执行Attention机制。
- Attention 1 with background RDMA:在执行Attention 1的同时,后台执行RDMA通信(Dispatch 0)。
- MoE 0 with background RDMA:在执行MoE 0的同时,后台继续执行RDMA通信(Dispatch 1)。
- Attention 0 with background RDMA:在执行Attention 0的同时,后台执行RDMA通信(Combine 0)。
- …
通过这种优化方法,DeepEP实现了计算与通信的高效重叠,减少了等待时间,提高了GPU的利用率,从而显著提升了MoE模型在大规模分布式环境中的性能。
四、DeepEP剖析
代码结构
第三方依赖
- GDRCopy:英伟达官方基于GPUDirect RDMA技术的低延迟显存数据拷贝库
- NVSHMEM:英伟达官方提供的一个编程接口,它在一组 NVIDIA GPU 之间实现了分区全局地址空间(Partitioned Global Address Space,PGAS)模型。
inference decoding使用示例
1 | |
关键代码
- DeepEP/csrc/config.hpp - LowLatencyBuffer,该类主要用于管理低延迟模式下的 RDMA 缓冲区,包括发送、接收数据和计数等相关缓冲区,同时提供了一个清理元数据的函数。
- DeepEP/csrc/deep_ep.cpp - 主要是包含节点内的dispatch和combine操作,以及节点间的dispatch和combine操作。
核心技术点
- Prefill内核工作负载:对于训练和推理中的Prefill阶段,通信过程主要在GPU对于token的分发和回收。CPU流中启动计算、分发和回收动作,GPU流中进行计算和通信操作。Prefill内核优化分发和回收通信中的NVL通信算子和IB通信算子。
- Decode内核工作负载:原有流程对于两个mbs会新建两个GPU SMs并在SM间进行计算和通信的overlap。因为一个mbs的训练过程是连续的(attn->dispatch->moe->combine),例如下图SM0、SM1。 改进后新增revice hook接口,将训练过程中计算和通信分离,只有计算部分占用SM,通信部分不占SM只占RDMA
- PTX优化:为了实现极致的性能,DeepSeek发现并使用了一种具有未定义行为的
PTX(并行线程执行,Parallel Thread Execution)用法:使用只读的 PTX 指令
ld.global.nc.L1::no_allocate.L2::256B来读取易变(volatile)数据。PTX 修饰符 .nc 表示使用了非一致性缓存。但在 Hopper 架构上,经测试证明使用.L1::no_allocate可以保证正确性,并且性能会好很多。猜测的原因可能是:非一致性缓存与 L1 缓存是统一的,并且 L1 修饰符不仅仅是一个提示,而是一个强选项,这样 L1 中没有脏数据就可以保证正确性。最初,由于 NVCC(NVIDIA CUDA 编译器)无法自动展开易变读取的 PTX 指令,尝试使用__ldg(即ld.nc)。即使与手动展开的易变读取相比,它的速度也明显更快(可能是由于额外的编译器优化)。然而,结果可能是不正确或有脏数据的。在查阅了 PTX 文档后,发现 Hopper 架构上 L1 缓存和非一致性缓存是统一的。推测.L1::no_allocate可能会解决这个问题,从而有了这个发现。
流量独立
为了防止不同流量之前的影响,将不同工作负载隔离到不同的虚拟通道(Virtual Lanes)中:Prefill内核工作负载、Decode内核工作负载、其他工作负载通过环境变量NVSHMEM_IB_SL指定虚拟通道。
自适应路由(AR)
自适应路由是ib交换机提供的一种高级路由特性,可以将流量均匀地分布在多条路径上。目前,低延迟内核支持自适应路由,而普通内核不支持(可能很快会添加支持)。
FP8操作
Prefill和Decode阶段分发数据类型为FP8,接受数据类型为BF16。
4.1 为什么在Perfill阶段没有使用计算通信分离操作?
IBRC 更适合大消息的批量传输,用于Prefill场景。IBGDA 更适合涉及大量小消息的细粒度通信,用于Decode场景。在IBGDA基础上改造实现计算通信分离。
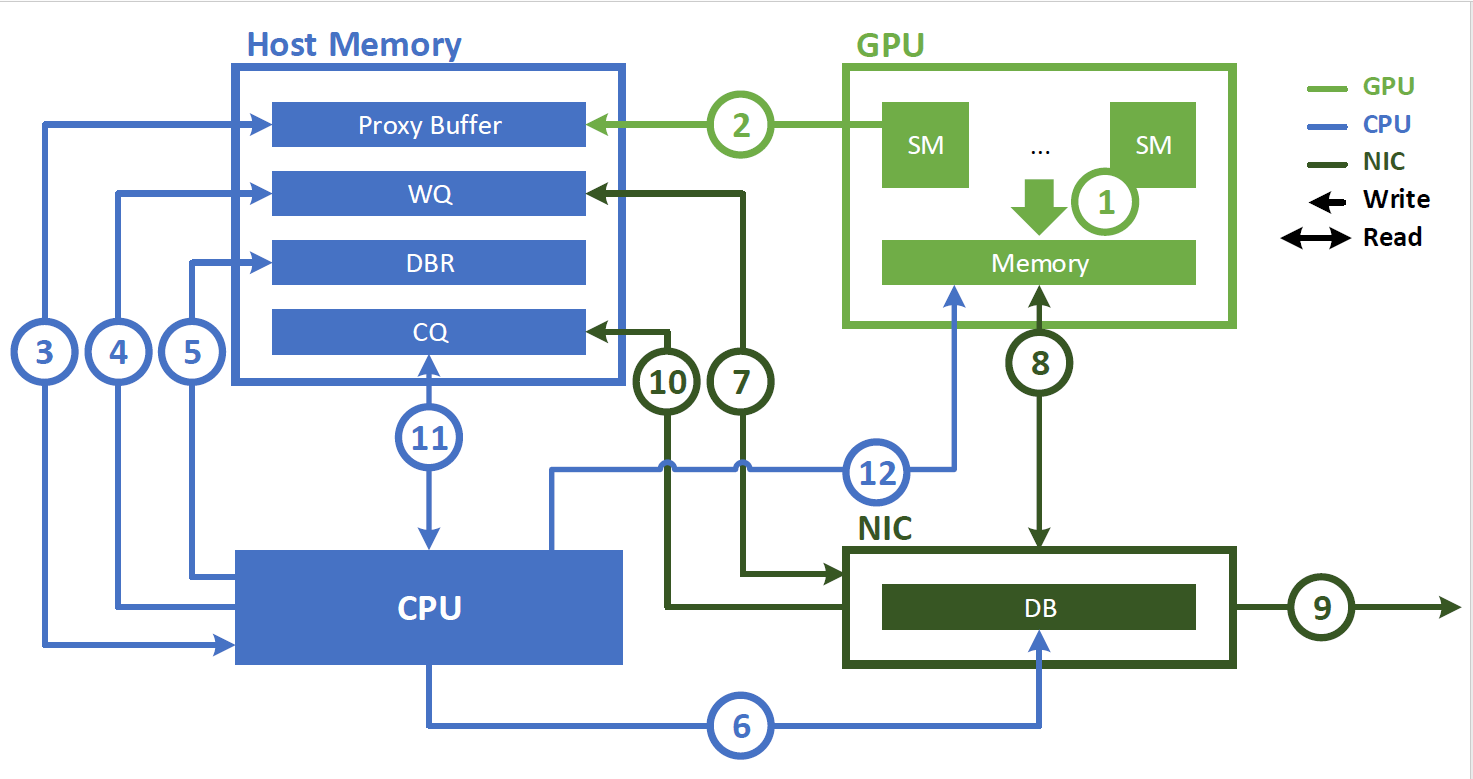
IBRC(InfiniBand Reliable Connection):IBRC 是一种基于代理的传输方式,使用 CPU 代理线程来管理通信。
使用 NVLink 进行节点内通信可以通过 GPU 流式多处理器( SM )启动的加载和存储指令实现。然而,节点间通信涉及向网络接口控制器( NIC )提交工作请求以执行异步数据传输操作。
在引入 IBGDA 之前, NVSHMEM InfiniBand Reliable Connection ( BGDA 是一种直接在 GPU 上进行通信的传输方式,不依赖 CPU 代理线程。 )传输使用 CPU 上的代理线程来管理通信(。使用代理线程时, NVSHMEM 执行以下操作序列:
- 应用程序启动 CUDA 内核,在 GPU 内存中生成数据。
- 应用程序调用 NVSHMEM
操作(例如
nvshmem_put)以与另一个处理元件( PE )通信。当执行细粒度或重叠通信时,可以在 CUDA 内核内调用此操作。 NVSHMEM 操作将工作描述符写入主机内存中的代理缓冲区。 - NVSHMEM 代理线程检测工作描述符并启动相应的网络操作。
以下步骤描述了与 NVIDIA InfiniBand 主机通道适配器( HCA )(如 ConnectX-6 HCA )交互时代理线程执行的操作顺序:
- CPU 创建一个工作描述符,并将其排入工作队列( WQ )缓冲区,该缓冲区位于主机内存中。
- 此描述符指示请求的操作(如 RDMA 写入),并包含源地址、目标地址、大小和其他必要的网络信息。
- CPU 更新主机内存中的门铃记录( DBR )缓冲区。此缓冲区用于恢复路径,以防 NIC 将写入数据丢弃到其门铃( DB )。
- CPU 通过向其 DB ( NIC 硬件中的寄存器)写入来通知 NIC 。
- NIC 从 WQ 缓冲区读取工作描述符。
- NIC 使用 GPUDirect RDMA 直接从 GPU 内存复制数据。
- NIC 将数据传输到远程节点。
- NIC 通过将事件写入主机存储器上的完成队列( CQ )缓冲区来指示网络操作已完成。
- CPU 轮询 CQ 缓冲器以检测网络操作的完成。
- CPU 通知 GPU 操作已完成。如果存在 GDRCopy ,则直接将通知标志写入 GPU 存储器。否则,它会将该标志写入代理缓冲区。 GPU 在相应的存储器上轮询工作请求的状态。
虽然这种方法是便携式的,可以为批量数据传输提供高带宽,但它有两个主要缺点:
- CPU 周期被代理线程连续消耗。
- 由于代理线程存在瓶颈,您无法达到细粒度传输的 NIC 吞吐量峰值。现代 NIC 每秒可以处理数以亿计的通信请求。虽然 GPU 可以以这种速度生成请求,但 CPU 代理的处理速度要低几个数量级,这为细粒度通信模式造成了瓶颈。
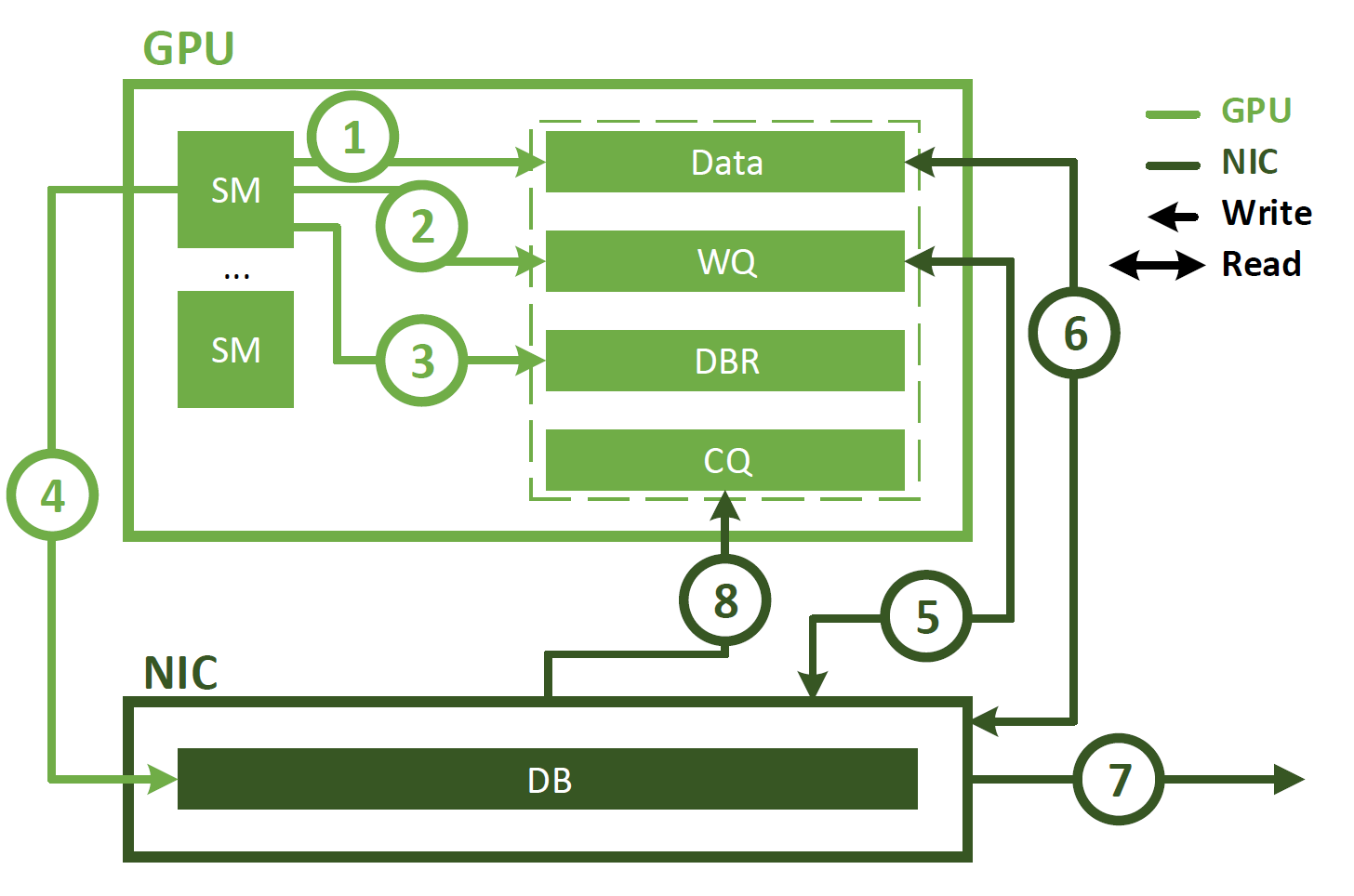
IBGDA(InfiniBand GPU Direct Asynchronous):BGDA 是一种直接在 GPU 上进行通信的传输方式,不依赖 CPU 代理线程。
与代理启动的通信不同, IBGDA 使用 GPUDirect Async – Kernel initiated ( GPUDirectAsync – KI )使 GPU SM 能够直接与 NIC 交互。这如图 2 所示,涉及以下步骤。
- 应用程序启动 CUDA 内核,在 GPU 内存中生成数据。
- 应用程序调用 NVSHMEM 操作(如nvshmem_put)以与另一个 PE 通信。 NVSHMEM 操作使用 SM 创建 NIC 工作描述符,并将其直接写入 WQ 缓冲区。与 CPU 代理方法不同,此 WQ 缓冲区驻留在 GPU 内存中。
- SM 更新 DBR 缓冲区,该缓冲区也位于 GPU 存储器中。
- SM 通过写入 NIC 的 DB 寄存器来通知 NIC 。
- NIC 使用 GPUDirect RDMA 读取 WQ 缓冲区中的工作描述符。
- NIC 使用 GPUDirect RDMA 读取 GPU 内存中的数据。
- NIC 将数据传输到远程节点。
- NIC 通过使用 GPUDirect RDMA 写入 CQ 缓冲区来通知 GPU 网络操作已完成。
如图所示, IBGDA 从通信控制路径中消除了 CPU 。使用 IBGDA 时, GPU 和 NIC 直接交换通信所需的信息。 WQ 和 DBR 缓冲区也移动到 GPU 存储器,以提高 SM 访问时的效率,同时保留 NIC 通过 GPUDirect RDMA 的访问。
IBRC VS IBGDA
- 性能:
- IBRC 在大消息传输时能够达到高带宽,但对于小消息存在性能瓶颈。
- IBGDA 在小消息传输中表现出色,能够实现更高的吞吐量和更低的延迟。
- 并行性:
- IBRC 的代理线程会序列化操作,限制了通信的并行性。(代理线程成批处理请求,提交的操作可能会由代理线程的单独循环处理,代理的操作串行化会产生额外的延迟)
- IBGDA 支持更高的通信并行性,能够更好地利用 GPU 和 NIC 的内部并行性。
- 适用场景:
- IBRC 更适合大消息的批量传输。
- IBGDA 更适合涉及大量小消息的细粒度通信。