DeepSeek Flash MLA
FlashMLA是一种在变长序列场景下的加速版MLA(Multi-Head Linear Attention),针对decoding阶段优化。目前deepseek已将其开源:FlashMLA。
特点:
- 存算优化:双warp group计算流设计与应用(存算重叠、数据双缓存);
- 分页缓存:KV page block管理提升显存利用率,更好适应变长序列;
- SM负载均衡:动态调整block数据,充分利用GPU算力。
一、计算原理分析
1.1 计算公式
MLA计算主要包含升/降秩线性计算和attention计算部分,FlashMLA完成MLA中MHA计算部分,不负责升/降秩的线性乘法操作。MLA的结构如下图所示:
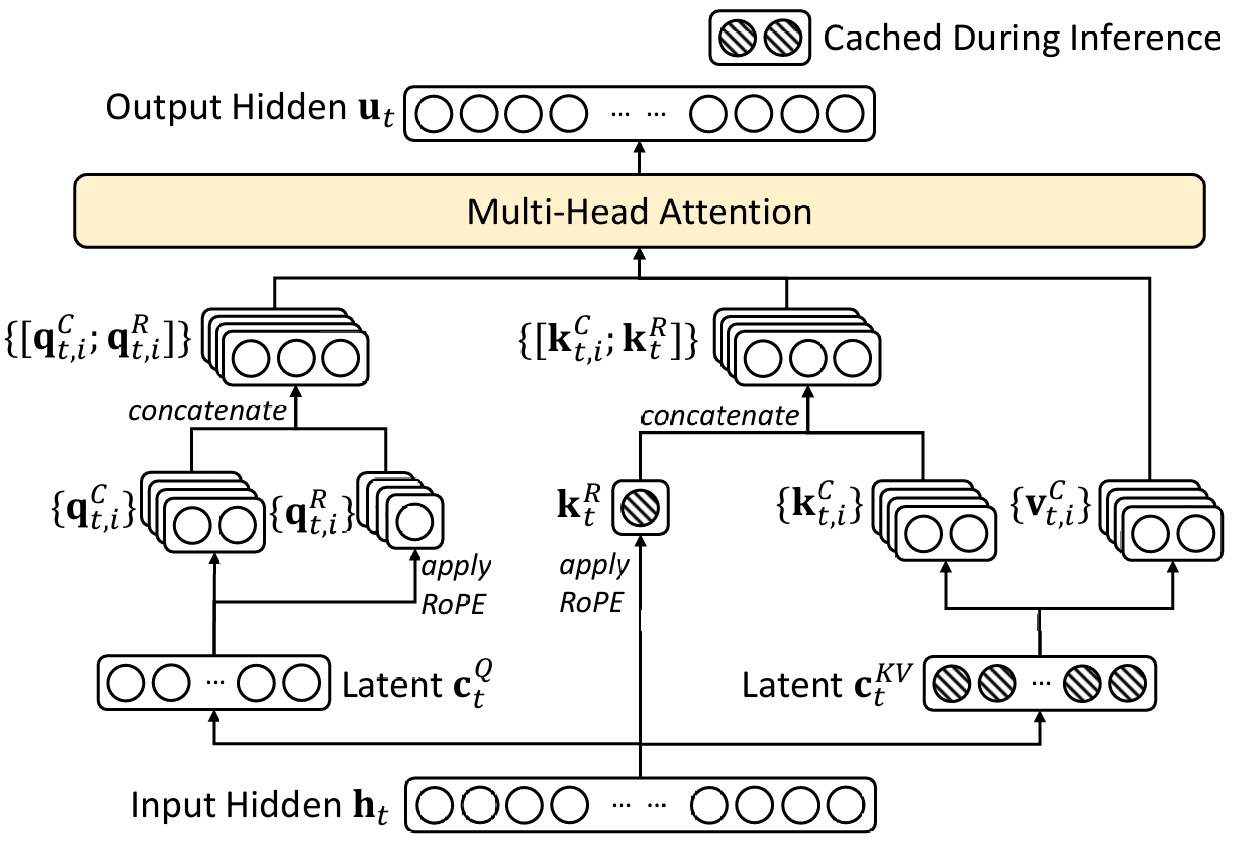
计算MLA的MHA和通常的MHA计算存在差异,一般而言,计算MHA时需要Q/K/V三个输入值,而MLA由于引入升降秩操作,算MHA时输入值发生了变化。
MLA的公式如下,FlashMLA完成
在deepseekV2中有提到矩阵W可以调整,具体是
对公式进行一下调整:
输入的参数变为
1 | |
输入的Q/K Head_dim:为
1.2 Attention分块运算
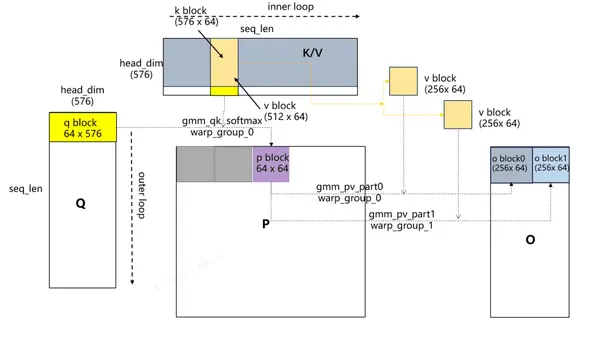
输入、输出明确后需要对KQV进行分块计算(按照FlashAttention类型原理), FlashMLA的分块逻辑如下:
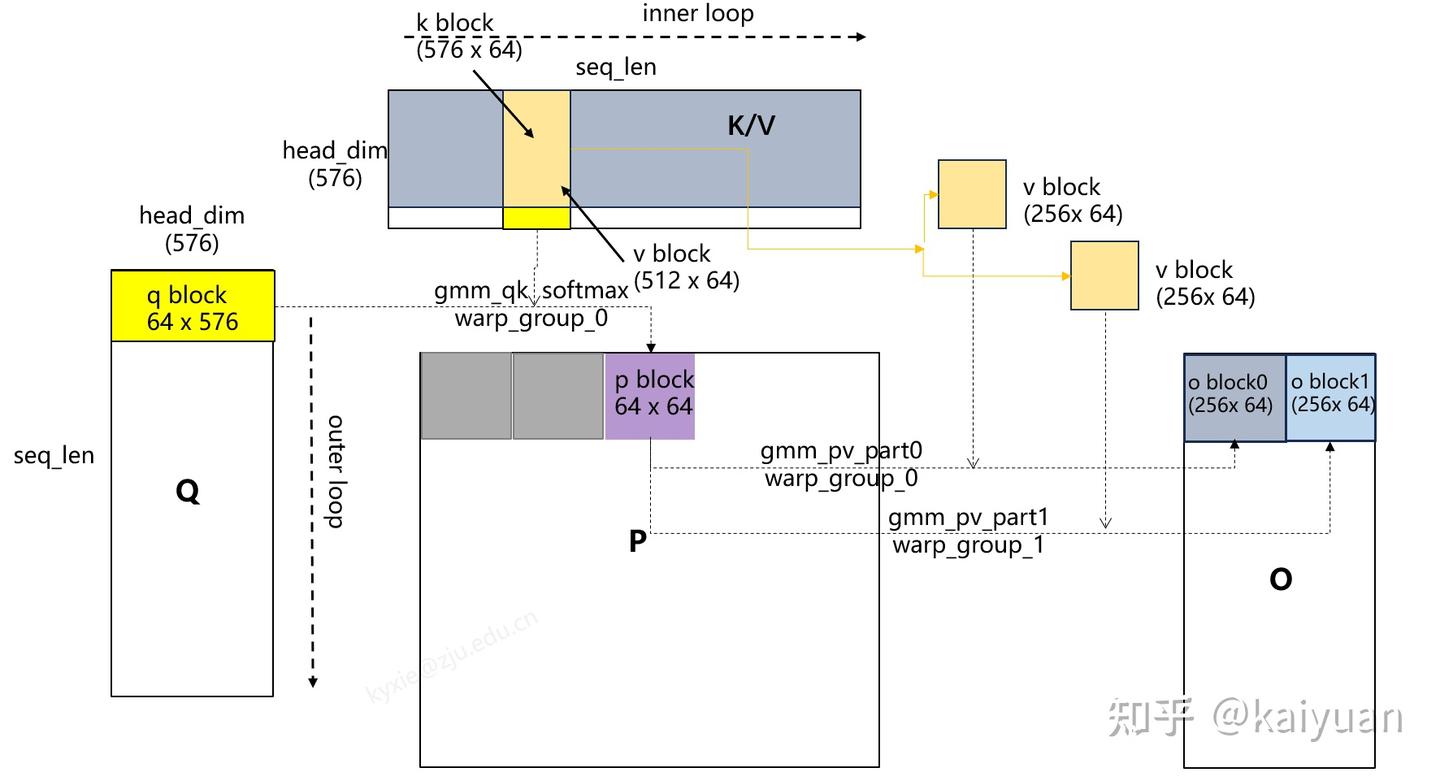
大致步骤:
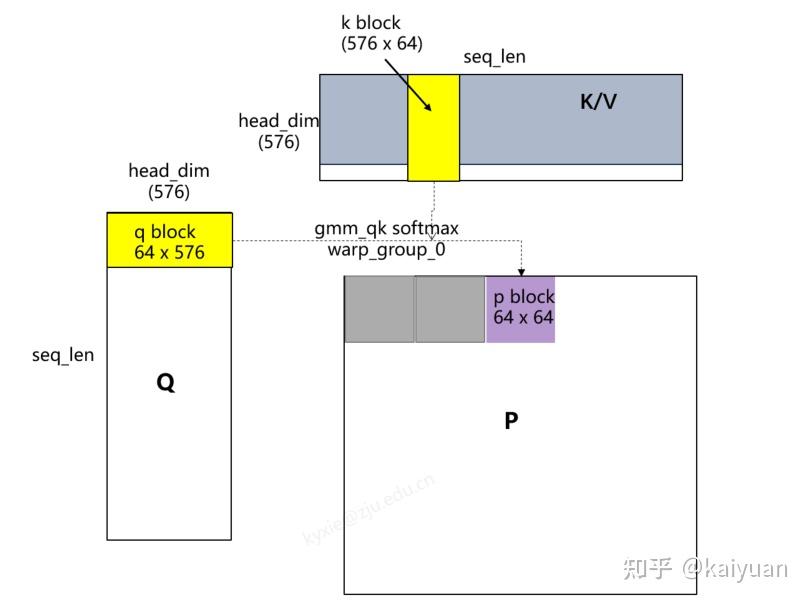
- 从Q取q_block单位,从K取k_block单位完成qk运算、softmax运算得到p_block;
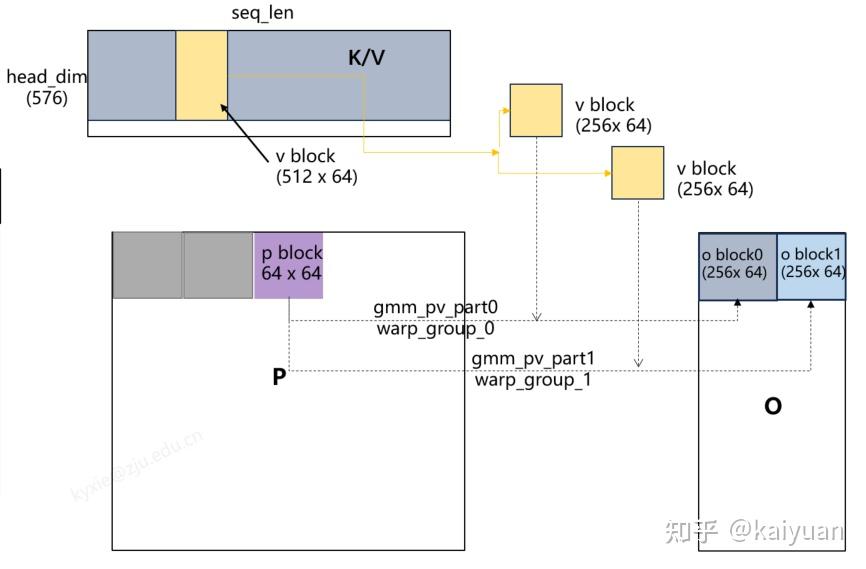
- 从V取v_block单位,然后分块成两份,分别与p_block计算得到o_block0和o_block1刷新到结果O上;
- 外层循环(outer loop):每次加载一个q_block;
- 内层循环(inner loop):每次加载一个kv_block;
其中分块运算,使用两个不同warp group完成。
二、计算流程分析
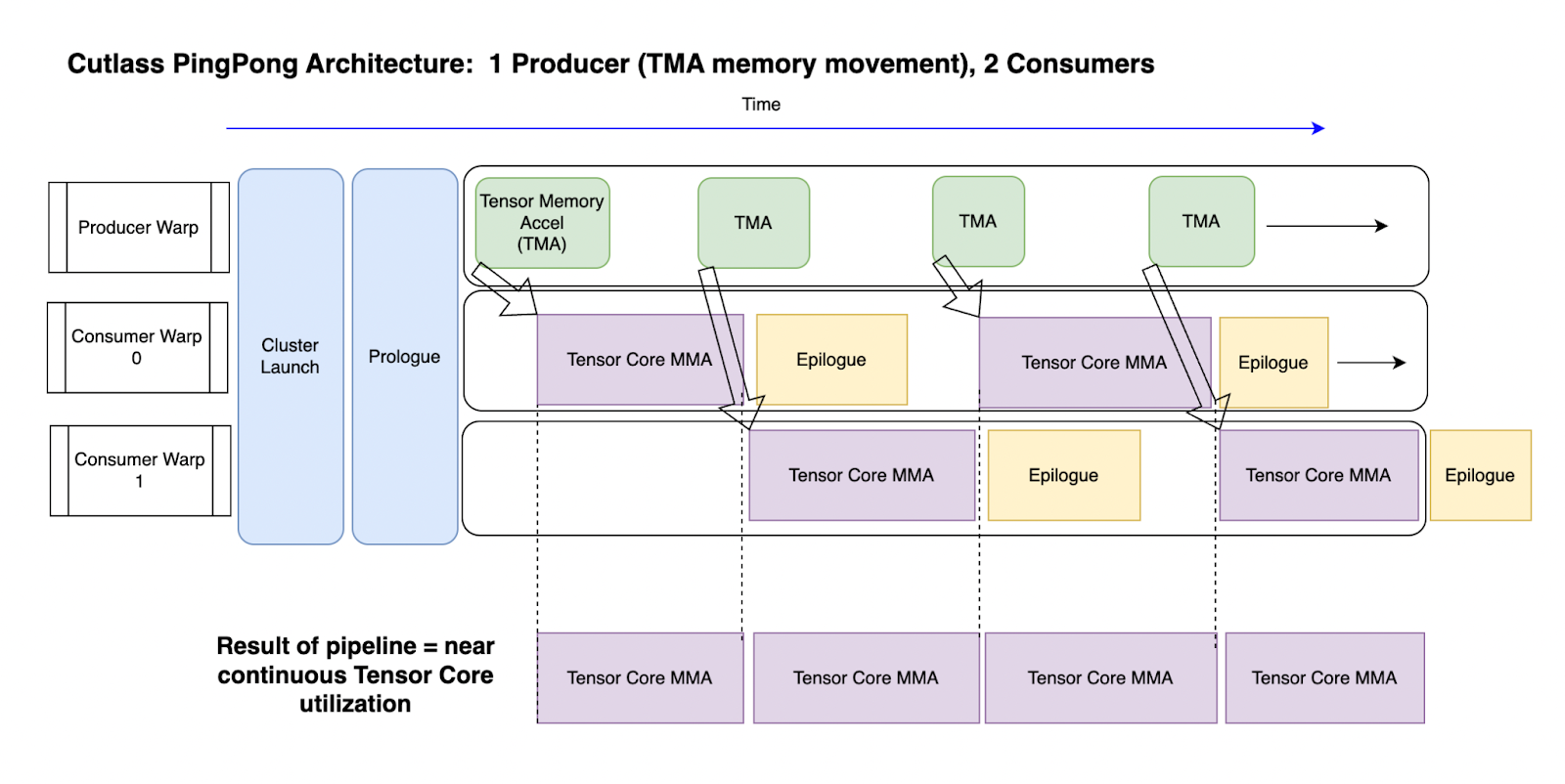
hopper架构的cutlass库:Ping-Pong计算方式。
该操作采用生产者(Producer)、消费者(Consumer)模式。Cutlass的Ping-Pong例子中包含1个生产者、2个消费者,如下图所示,生产者专门负责搬运数据,消费者完成计算。采用这种模式能够更充分的利用TensorCore。
Ping-Pong的流水线对硬件调用如下图所示,涉及关键模块:计算warp组、访存warp组,SMEM、GMEM、TMA存储单元和TesnorCore计算单元。
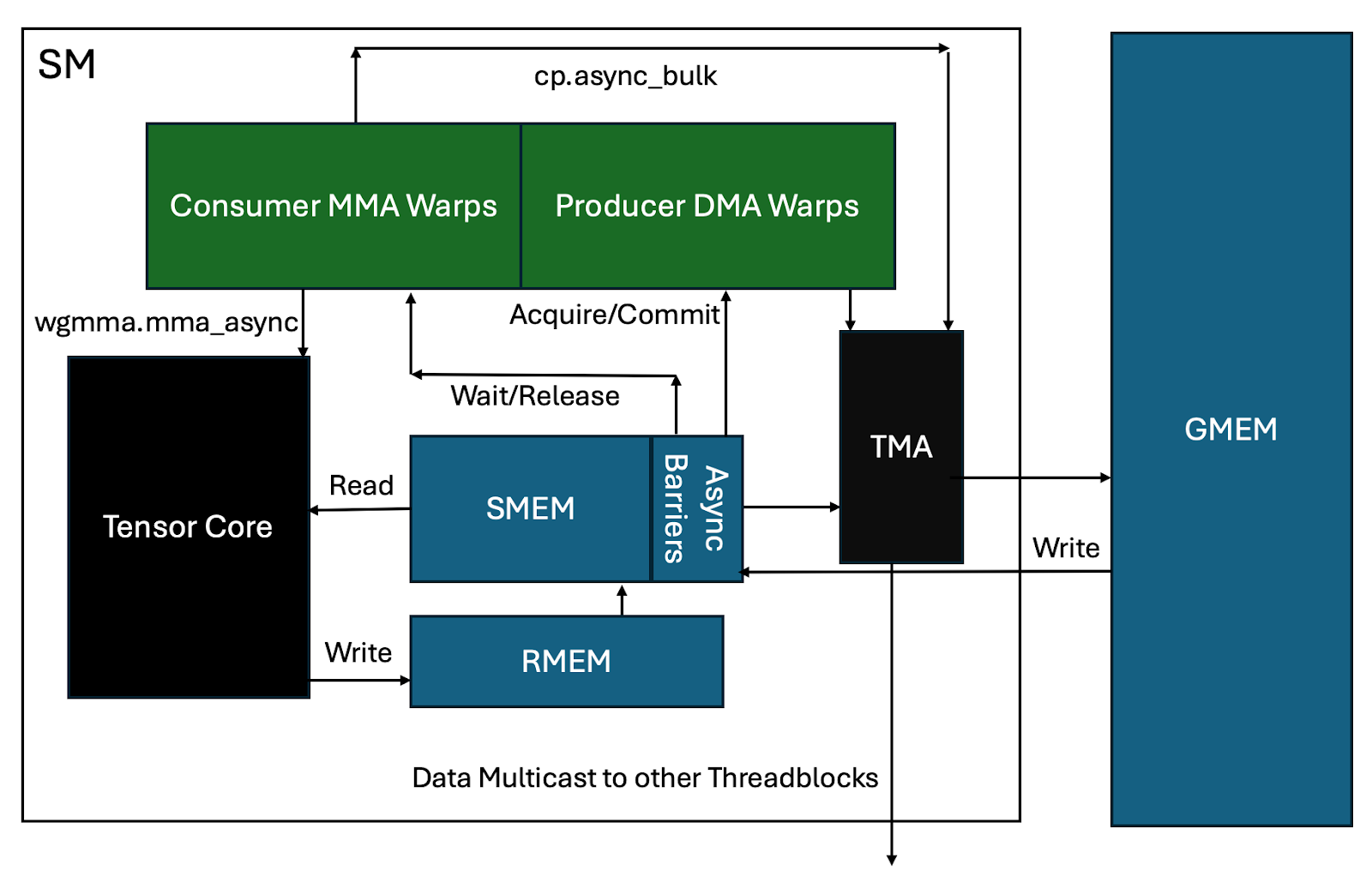
- RMEM(register Memory):寄存器;SMEM(Shared Memory):共享内存;GMEM(Global Memory):全局内存HBM
- TMA(Tensor Memory Accelerator):TMA 允许在 GPU 的全局内存(Global Memory)和共享内存(Shared Memory)之间异步传输
有了对ping-pong方法的理解后,阅读FlashMLA的计算逻辑就更容易了。FlashMLA里面也使用了两个warp组。与ping-pong不同的是,这两个warp组是一种协作关系。
- warp_group_0(线程0~127): 负责进行attention scores运算、mask、softmax、部分PV计算。
- warp_group_1(线程127~255):负责加载数据Q和K、部分PV计算。
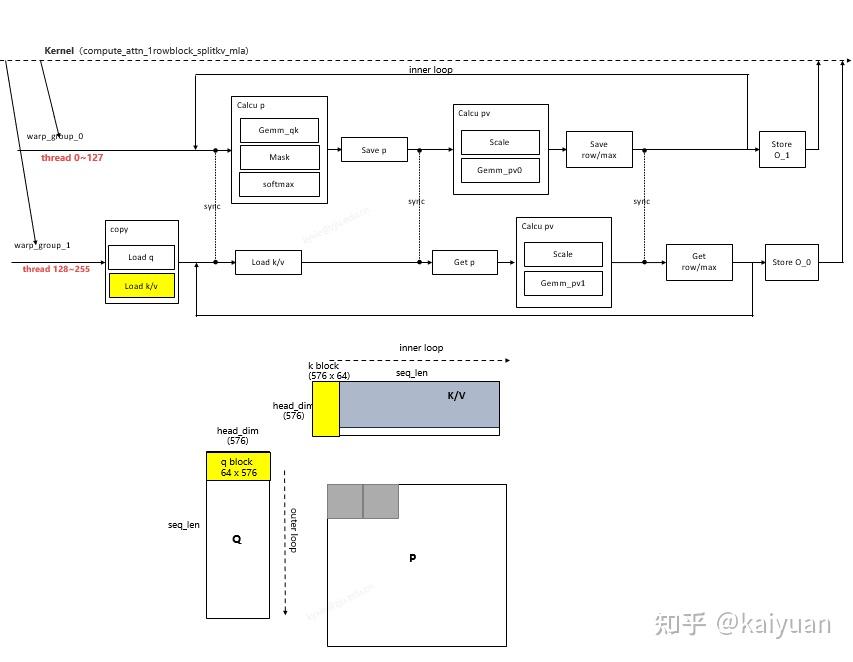
根据代码(flash_fwd_mla_kernel.h),其计算逻辑主要在compute_attn_1rowblock_splitkv_mla函数中,这里对其过程进行分析如下所示:
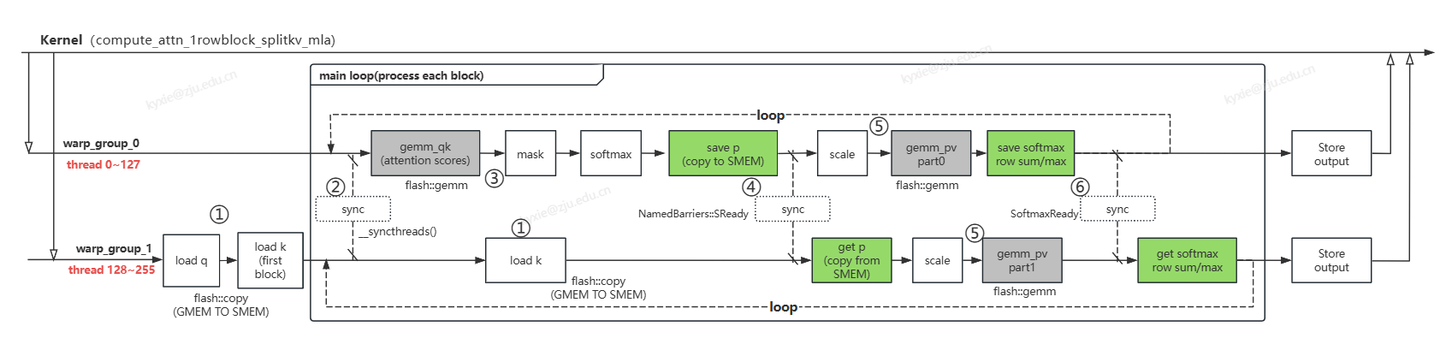
该kernel包含了一个row(一次外层循环迭代)的完整运算,其主要步骤:
- warp_group_1从GMEM加载数据q和第一个k_block数据到SMEM;每个kernel只加载一个q_block(outer loop); 在内层循环(inner loop)中每次迭代开始前加载一个k_block; block的大小为:64(kBlockM) × 576(kHeadDim)
- warp_group进行计算前有个线程同步,保证数据加载完成/运算结束;
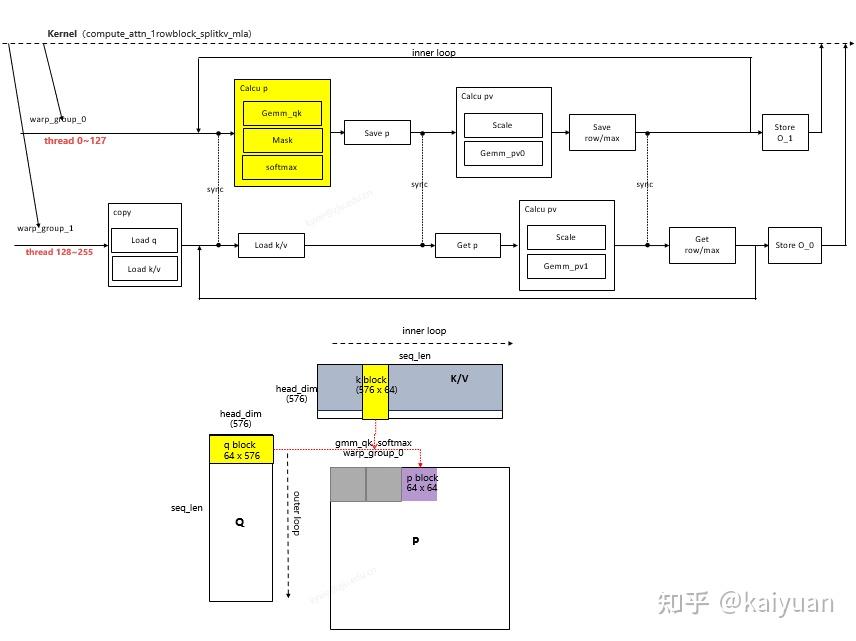
- warp_group_0调用gemm完成attention scores获得QK值,然后进行mask和softmax计算,得到P值;
- warp_group_0将P值copy一份到共享内存中,接着warp_group_0和1进行一次同步, 确保copy完成后。warp_group_1从共享内存中加载一份P值;
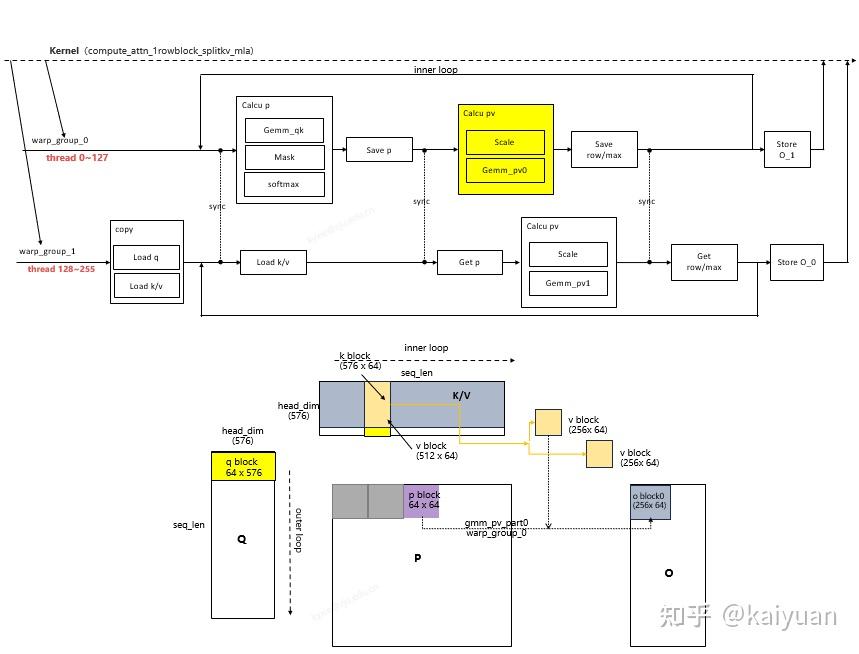
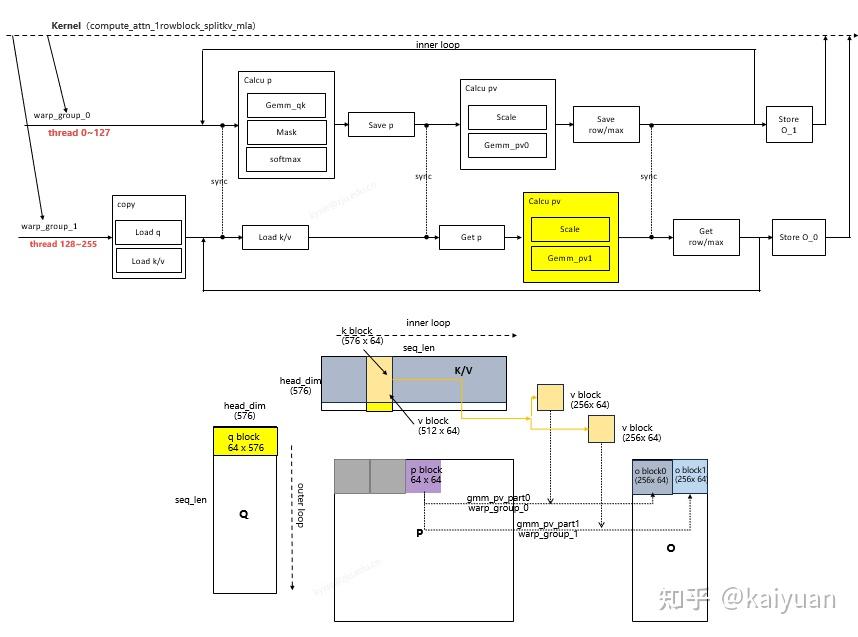
- warp_group_0和warp_group_1调用gemm完成 PV计算,分别获得O结果的一部分(两者合起来O值:64* 512)
- warp_group_0把softmax计算的row_sum以及row_max存入共享内存,两个warp组同步后,warp_group_1从共享内存获得该值。
- KV内层循环完成一个O的刷新,Q外层循环完成整个结果刷新。
把这些步骤结合模块运算
包含两层循环的完整的运算流程: 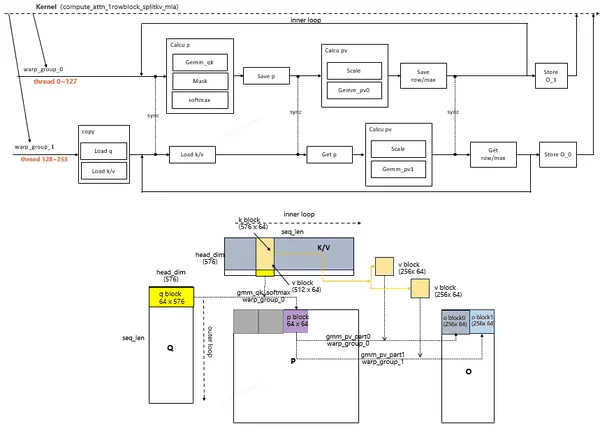
ShareMem
flashMLA的share memory包含六个变量。
smem_q:用于存放输入Q,大小为576x64x2B/1024=72KB
smem_k:用于存放输入K(也包含部分V),为双buffer,大小为2x64x576x2B/1024=144KB
smem_p:用于存放gemm 1的结果,用于wg 1和wg 2之间的数据中转,大小为2x2x128x8x2B/1024=8KB
smem_scale、smem_max、smem_sum、smem_o:用于存放split-kv做conbine所需的输入,都比较小,不计算了。
总共加起来一共是72+144+8=224KB,而Hopper架构的share memory大小为最大228KB,可以看到使用的smem几乎是贴着上限的。
这也说明,如果要原样移植到其他平台,首先需要share memory超过228KB,其次还需要wgmma的最大N超过256,这个要求还是很苛刻的。所以目前为止这个flashMLA还是只能在Hopper卡上达到最大效率。
Mainloop
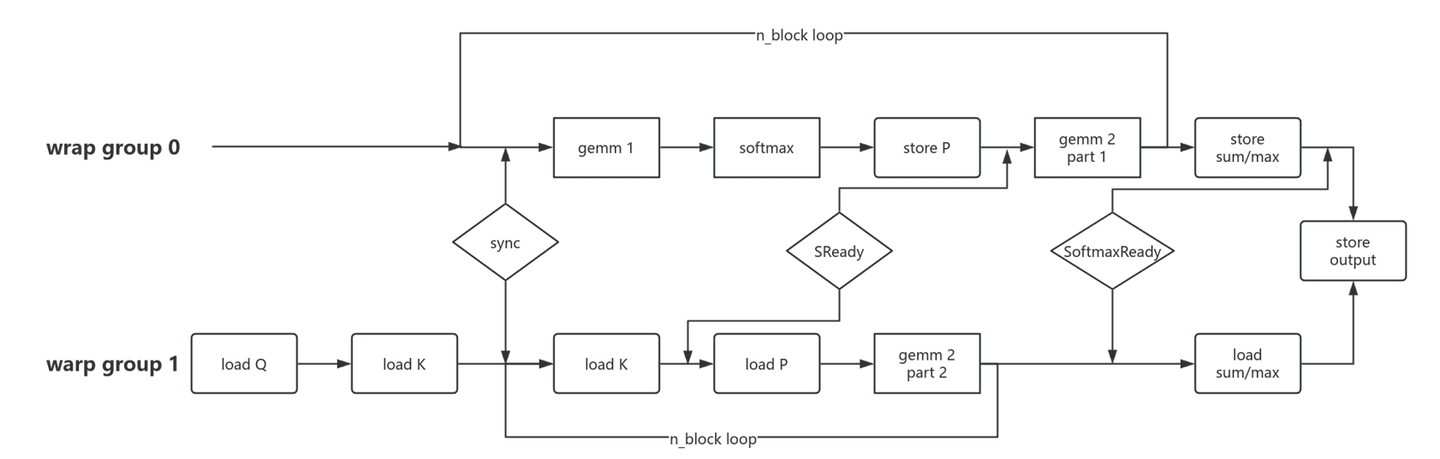
整体的main loop如图所示,两个warp group分别有自己的任务,其中warp group 0负责计算gemm 1,softmax和gemm 2的第一部分;warp group 1负责加载Q、K和计算gemm 2的第二部分。
流程中只有Q和K的加载,其中Q只加载一次,加载后一直存储于sharemem中。加载K在流程中出现了两次,因为K是double buffer的设置。
有两个namedbarrier,SReady用于同步softmax是否计算完成,如果计算完成,就将结果P存储于sharemem中;wg1检测这个同步标志,如果存储结束,就尝试读取P,作为gemm 2的输入。
wg 0和wg 1各自负责gemm 2的一半。有意思的是,wgmma最大支持N=256,刚好是headdimV的一半,因此两个warp group刚好完成一整个gemm 2的计算。
n_block loop结束之后,通过SoftmaxReady做了一个sum/max的同步,让两个warp group都取得相同的数据,最后一起做一个写出。
三、Hopper GPU优化详解
3.1 内存子系统
- 分页KV缓存与合并访问 FlashMLA采用分页KV缓存机制(块大小64),将长序列切分为固定大小的块,对齐Hopper GPU的HBM3内存总线(256位宽),实现连续内存访问。这种设计不仅减少了显存碎片化,还通过合并内存事务将内存带宽提升至3000 GB/s。
- BF16混合精度支持 采用Brain Float 16(BF16)格式进行KV缓存和计算,相比FP32减少50%内存占用,同时保持模型精度。这一优化在Hopper的第三代Tensor Core上进一步加速矩阵运算,使计算性能达到580 TFLOPS。
3.2 计算性能
- Tensor Core与低秩分解
通过将全局注意力计算分解为低秩矩阵乘法(如
),利用Tensor Core的单周期8x8x16矩阵乘加(MMA)指令,最大化并行计算效率。在H800 GPU上,这一优化使计算性能接近理论峰值。 - 算子融合与流水线并行 FlashMLA将QKV投影、分组Pooling和注意力计算融合为单一内核,减少中间结果回写显存的次数。同时采用双缓冲流水线技术,异步预加载下一Token的Q向量至寄存器,实现计算与数据搬运的无缝重叠,降低端到端延迟。
3.3 硬件架构
- SM资源配置优化 每个线程块处理2个注意力头(共128线程),匹配Hopper SM的128 FP32核心设计,确保计算单元满载。共享内存分配64KB(48KB用于潜在状态缓存,16KB用于局部KV),减少全局内存访问。
- DPX指令加速动态逻辑 利用Hopper新增的Dynamic
Programming
Extensions(DPX)指令,加速分页缓存的地址偏移计算和动态序列调度,例如通过
dp4a指令快速聚合零散内存访问。
四、可变长序列优化详解
4.1 对KV Cache的理解
由于decoder是有因果性的(即一个token的注意力attention只依赖于它前面的token),当每生成一个新的
token 就会把这个新的 token
添加进之前的序列中,在将这个序列当作新的输入进行新的 token
生成,直到eos_token结束。这使得每次新序列输入时都需要取重复计算前面的
KV Cache 就是在这里使用的,我们在每次处理新的序列时,不需要对之前已经计算过的 Token 的 K 和 V 重新进行计算。因为对于之前的 Token 可以复用上一轮计算的结果,避免了重复计算,只需要计算当前 Token 的 Q、K、V。
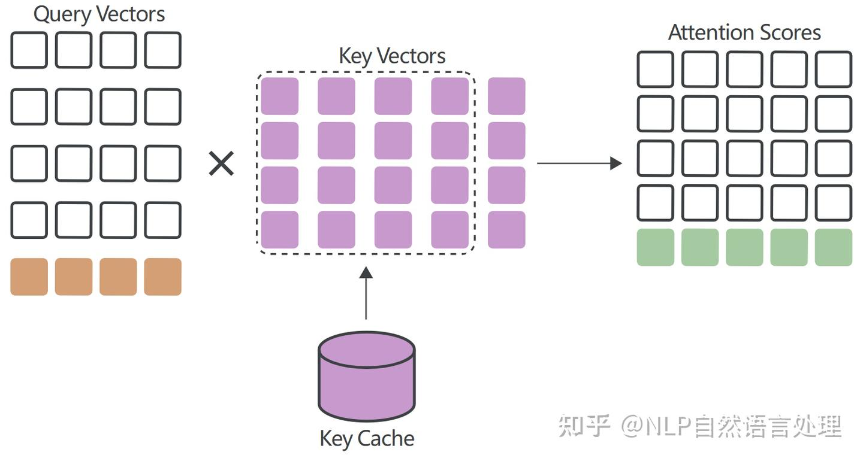
从Key Cache中提取先前计算的Key向量,并计算注意力分数矩阵的最后一行作为新Query向量与每个Key向量的点积:
与Key向量一样,每次迭代时只需要计算最后一个Value向量。所有其他Value向量都可以从Value Cache中提取并重复使用:
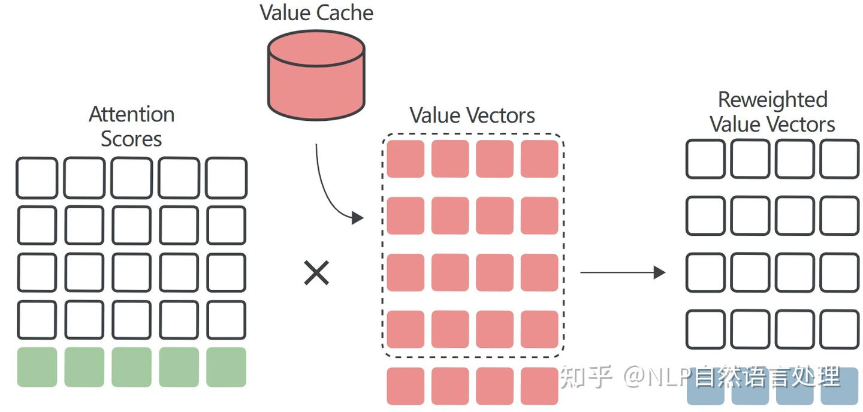
4.2 FlashMLA 对 KV Cache的优化
- Paged KV Cache 实现
- 显存分块:以64为单位(block_size = 64),通过block_table维护逻辑块到物理显存的映射。
- 流水线:分离数据加载与计算阶段,通过cp.async实现异步数据预取。
- 优化特性
- 分页KV缓存管理 针对长序列推理中显存碎片严重问题,Flash-MLA实现基于64-block Paged KV Cache,极大提高了显存利用率,缓解内存访问瓶颈。
- 异步内存拷贝 利用NVIDIA Hopper SM90架构特性,借助Tensor Memory Accelerator(TMA)异步内存拷贝指令,实现显存(HBM/GDDR)到SRAM零拷贝传输,接近理论峰值带宽。
- 双模式执行引擎 为适应不同输入序列长度场景,FlashMLA采用动态负载均衡算法,设计了双缓冲模式,短序列下采用计算优先模式,长序列下采用内存优先模式,使得整体延迟大幅降低。