曝光过滤
如果⽤户看过某个物品,则不再把该物品曝光给该⽤户。对于每个⽤户,记录已经曝光给他的物品。对于每个召回的物品,判断它是否已经给该⽤户曝光过,排除掉曾经曝光过的物品。⼀位⽤户看过
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中。和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。
算法: 1. 首先需要k个hash函数,每个函数可以把key散列成为1个整数 2. 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0 3. 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1 4. 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
在推荐中的应用: - Bloom filter
判断⼀个物品ID是否在已曝光的物品集合中。 -
如果判断为no,那么该物品⼀定不在集合中。 -
如果判断为yes,那么该物品很可能在集合中。(可能误伤,错误判断未曝光物品为已曝光,将其过滤掉。)
- Bloom filter 把物品集合表征为⼀个
当只有一个hash函数是,Bloom Filter效果如下:
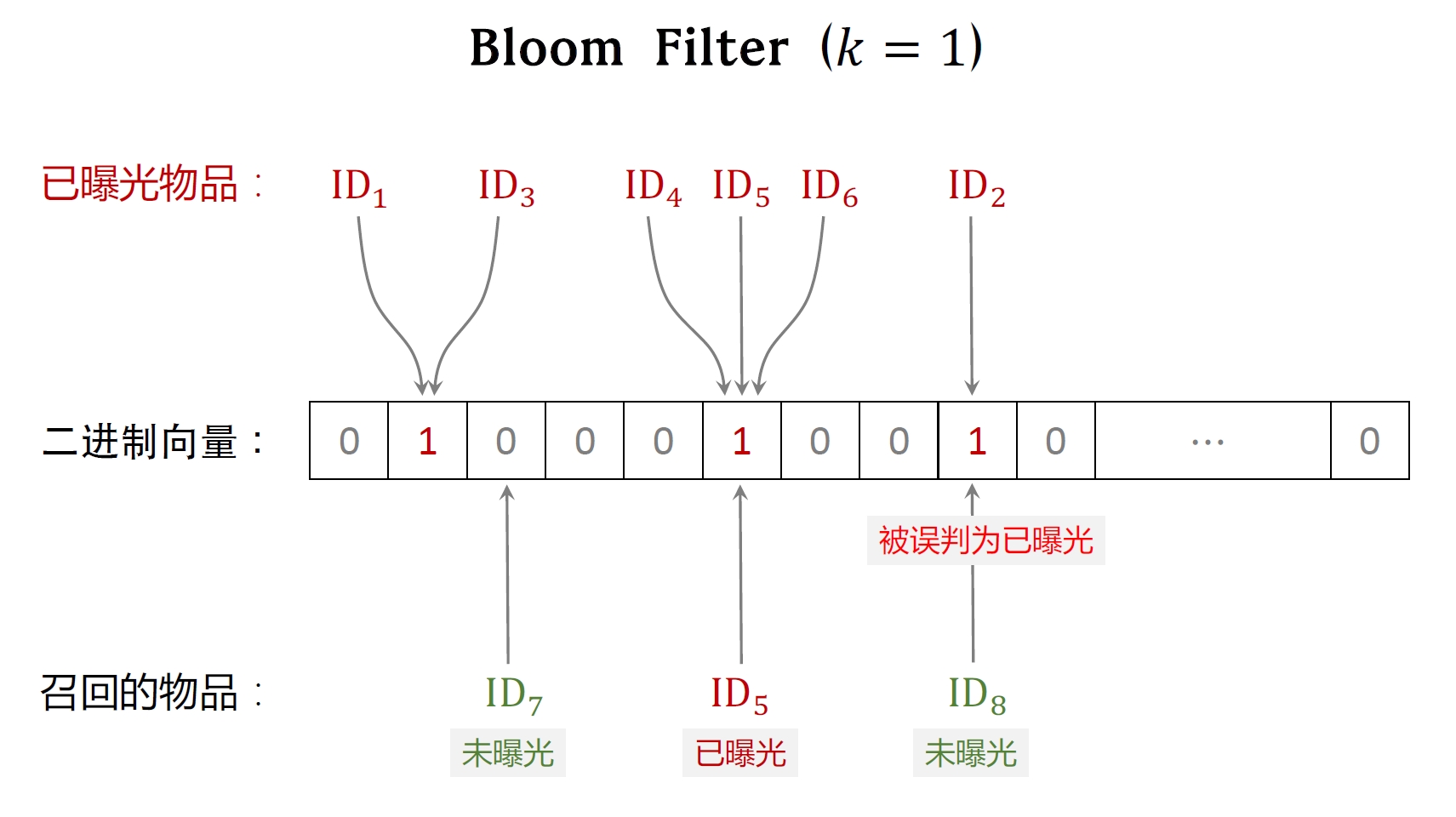
只有一个hash函数时冲突概率较高,误判率较高,一般使用多个hash函数,下图是使用3个hash函数:
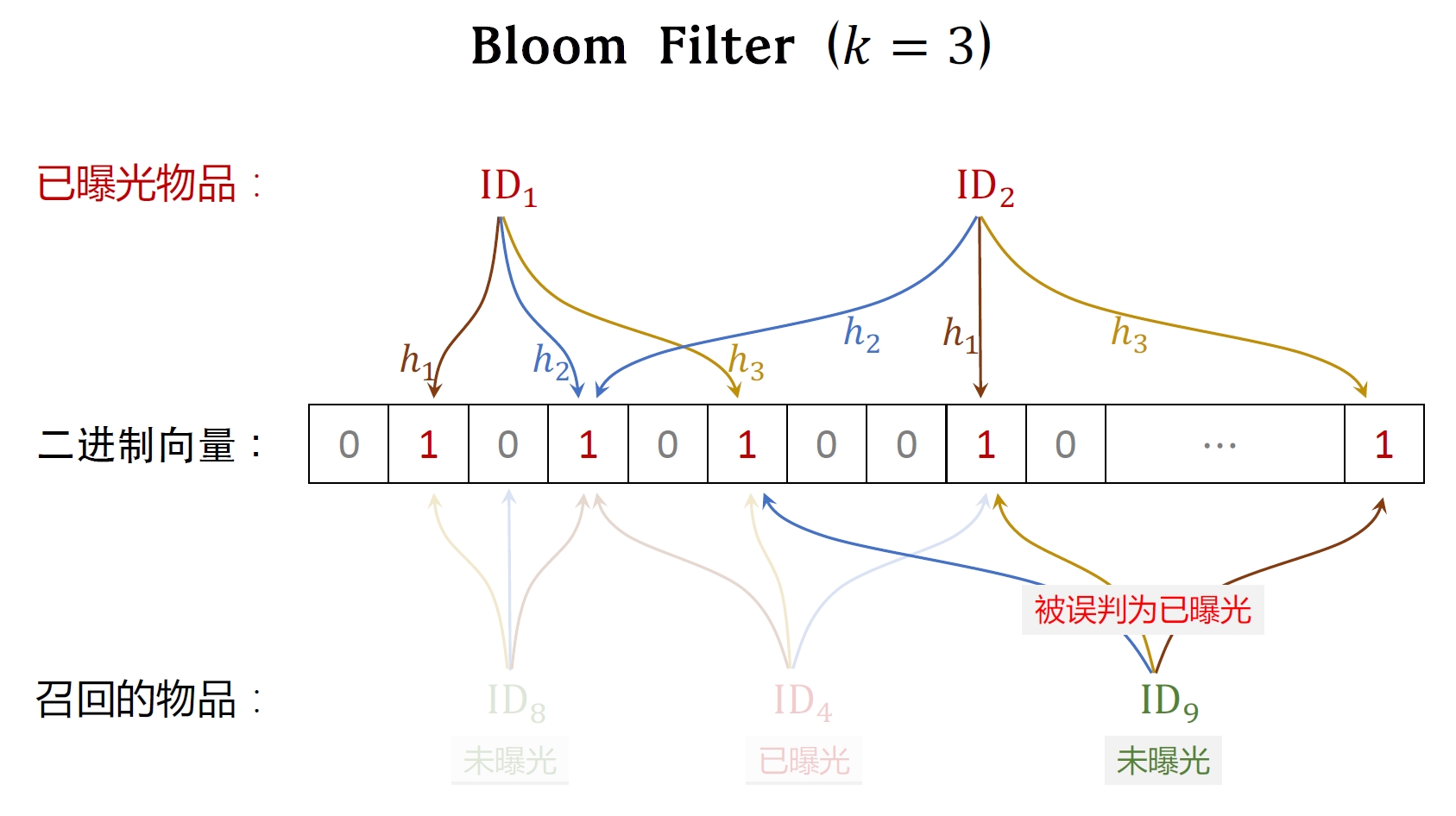
- 曝光物品集合⼤⼩为
,⼆进制向量维度为 ,使⽤ 个哈希函数 - Bloom filter 误伤的概率为
越⼤,向量中的1 越多,误伤概率越⼤。(未曝光物品的 个位置恰好都是1 的概率⼤。) 越⼤,向量越长,越不容易发⽣哈希碰撞。 太⼤、太⼩都不好, 有最优取值。
- 设定可容忍的误伤概率为
,那么最优参数为:
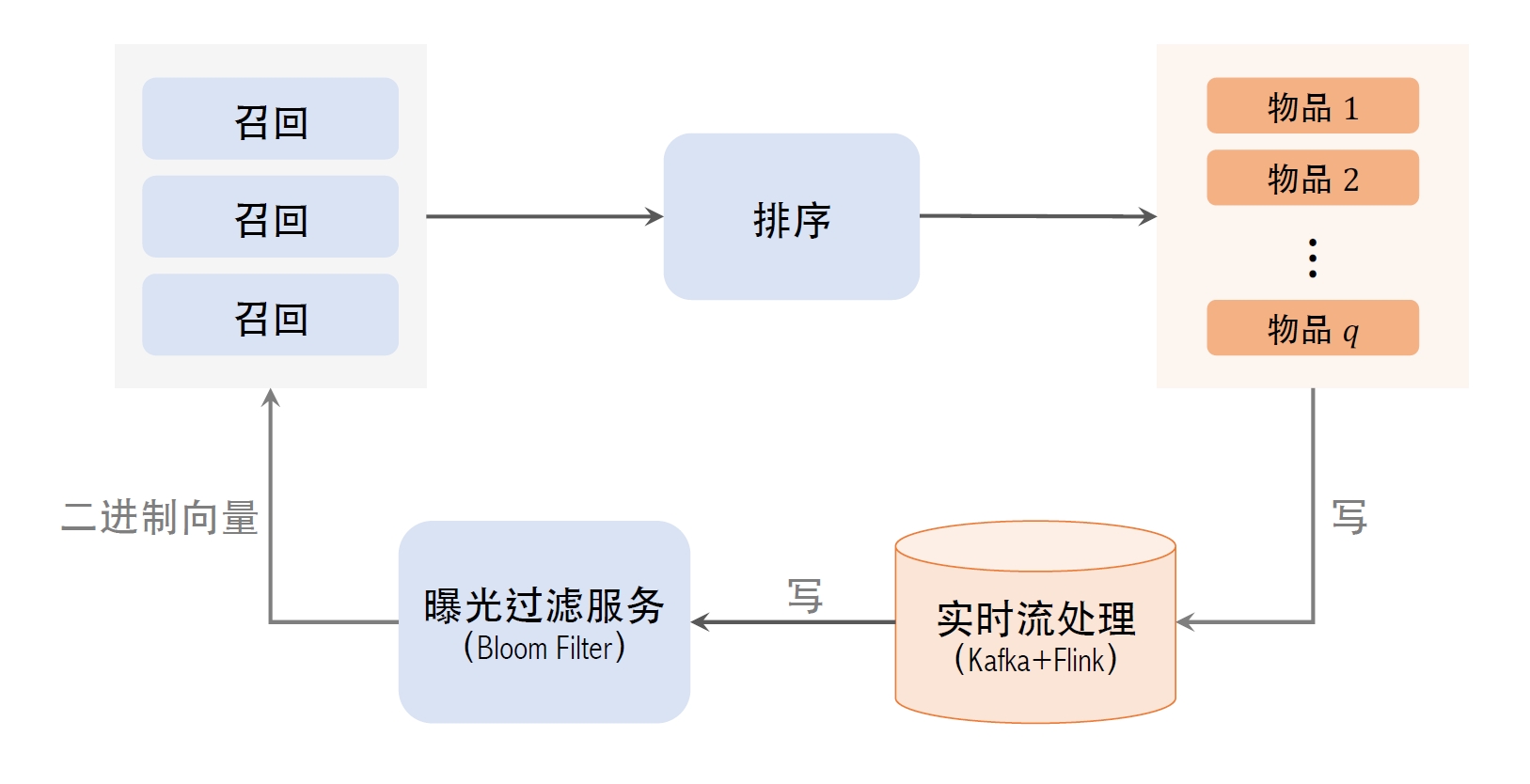
曝光过滤流程一般如下:
Bloom Filter的优缺点
优点: - 不需要存储key,采用位数组节省空间
缺点: - 算法判断key在集合中时,有一定的概率key其实不在集合中 - 无法删除