推荐算法--CF
一、ItemCF
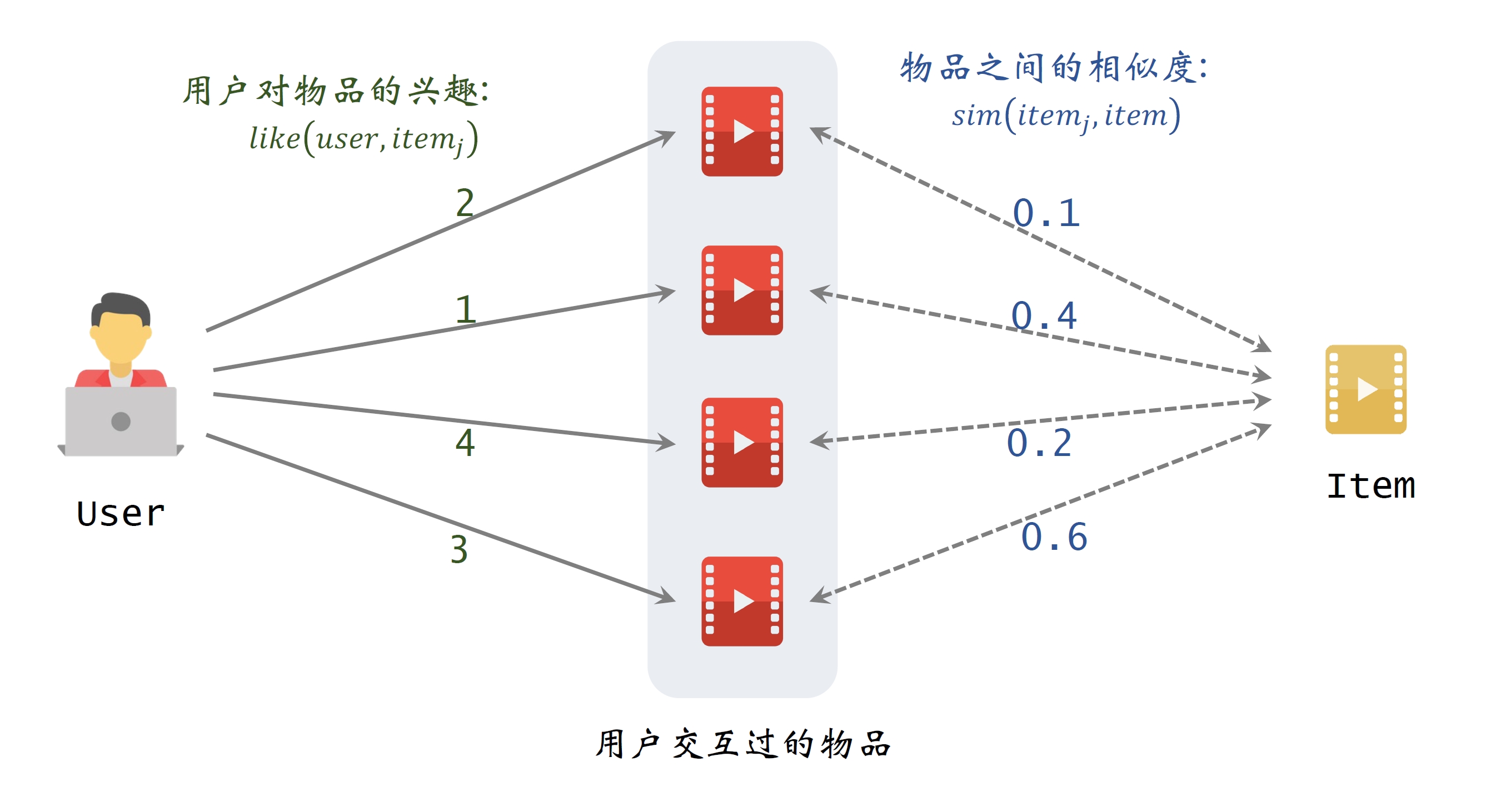
基于物品的协同过滤就是根据用户历史选择物品的行为,通过物品间的相似度,给用户推荐其他物品。
1.1 原理
- 计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表
1.2 物品相似度计算
- 喜欢物品
的⽤户记作集合 - 喜欢物品
的⽤户记作集合 - 定义交集
- 两个物品的相似度(余弦相似度):
预估⽤户对候选物品的兴趣:
1.3 ItemCF召回的完整流程
1.3.1 事先做离线计算
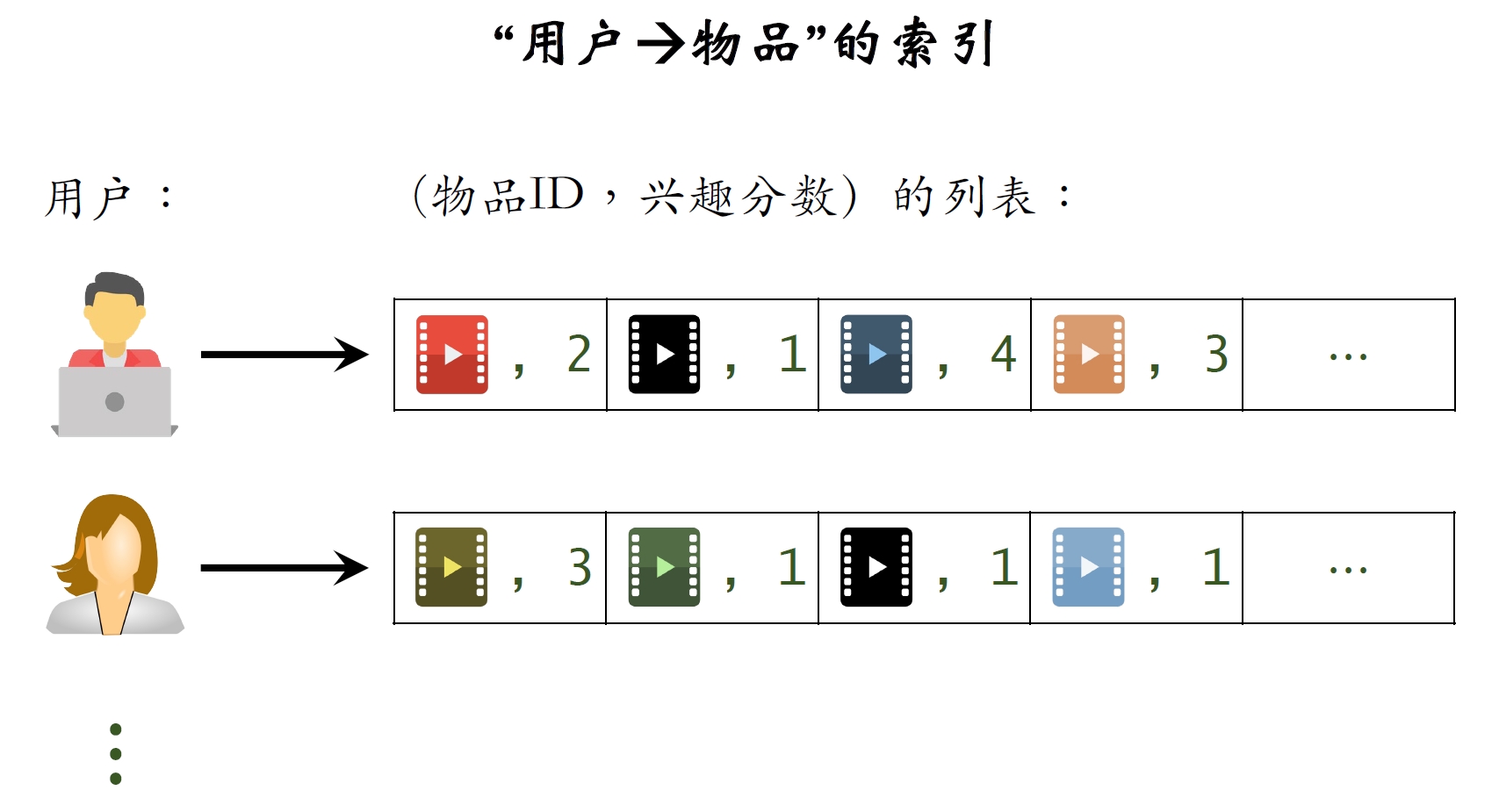
- 建⽴“用户
物品”的索引
- 记录每个⽤户最近点击、交互过的物品ID。
- 给定任意⽤户ID,可以找到他近期感兴趣的物品列表。
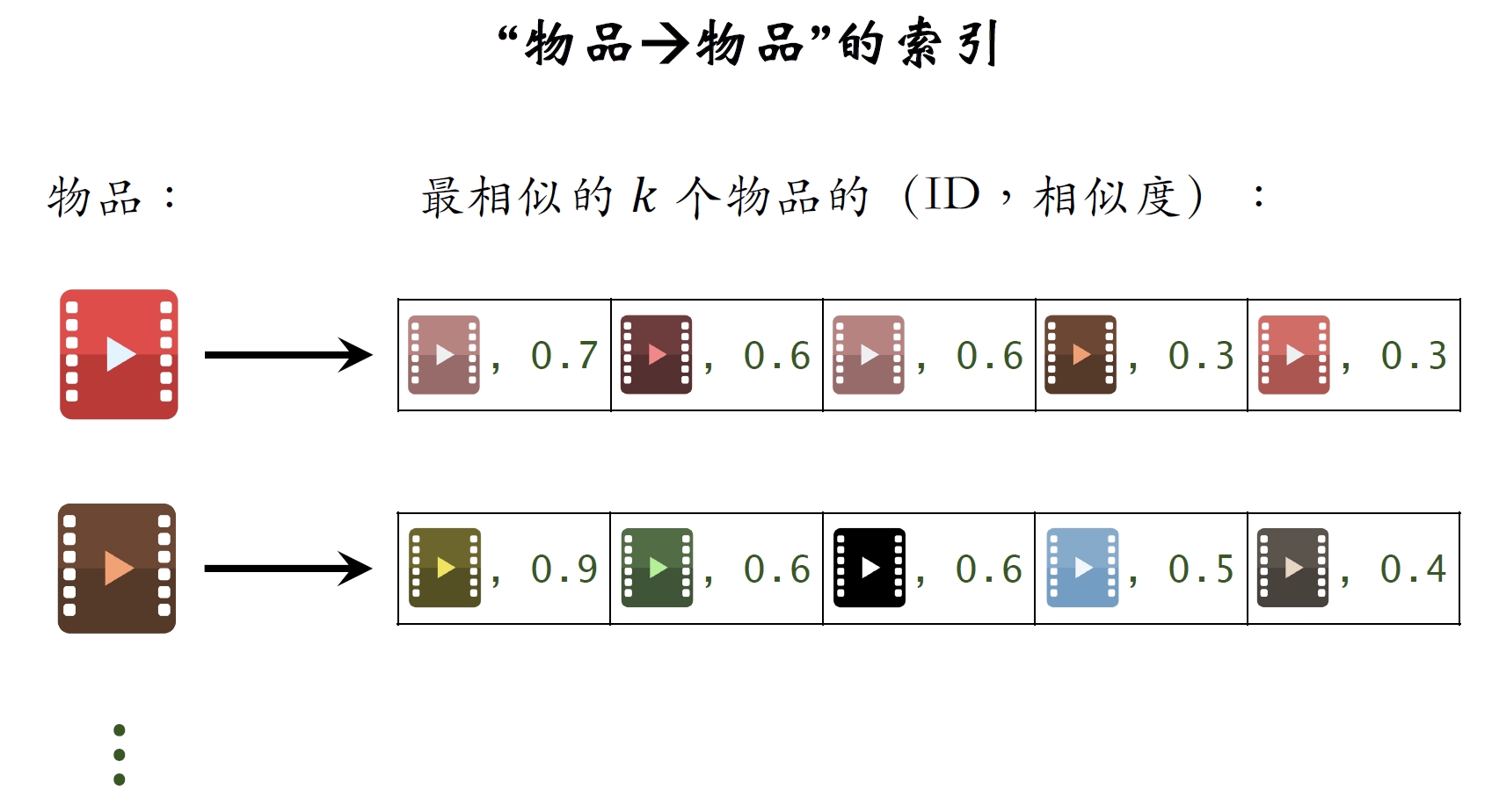
- 建⽴“物品
物品”的索引
- 计算物品之间两两相似度。
- 对于每个物品,索引它最相似的k个物品。
- 给定任意物品ID,可以快速找到它最相似的k个物品。
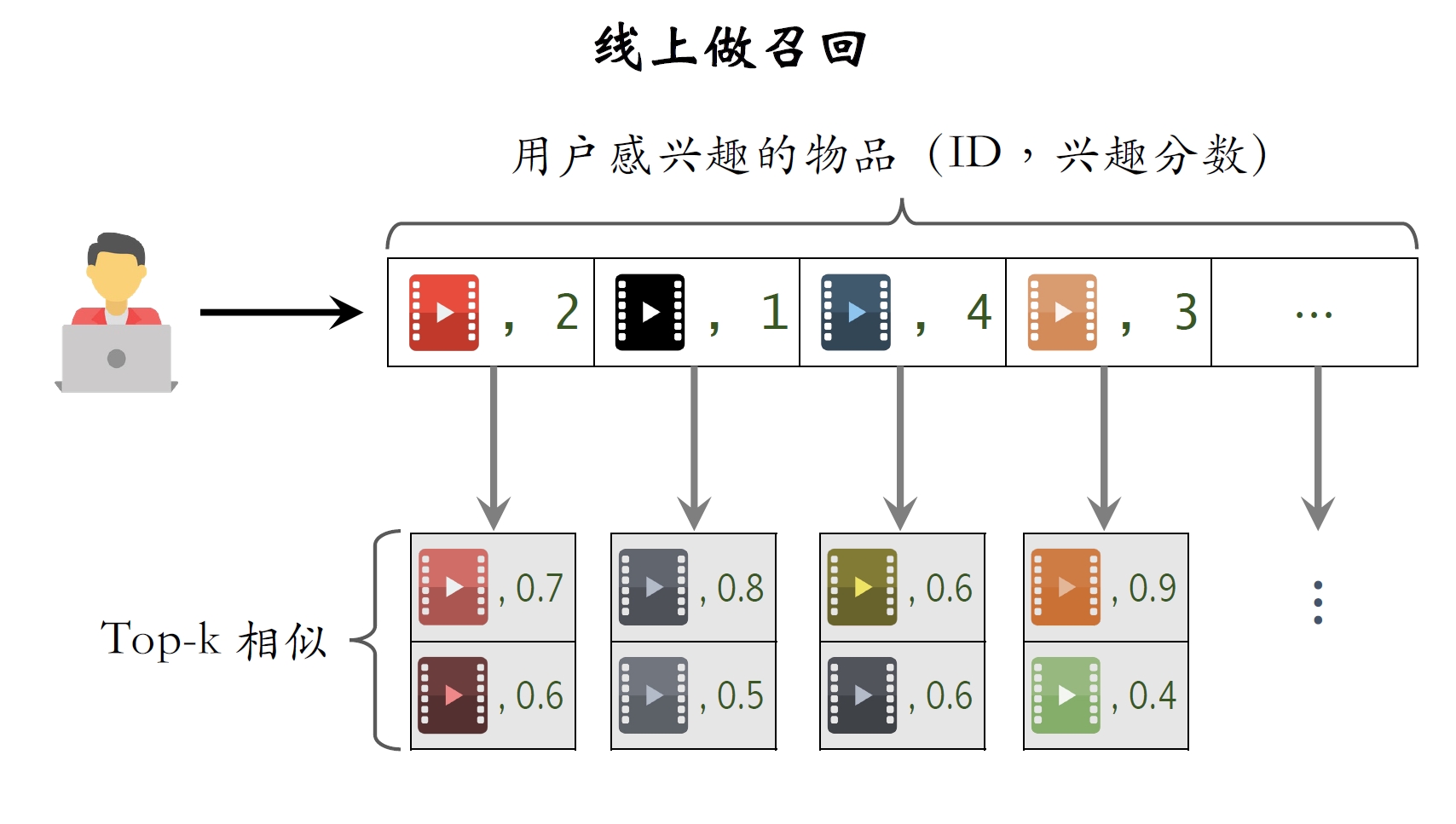
1.3.2 线上做召回
- 给定⽤户ID,通过“用户
物品”索引,找到⽤户近期感兴趣的物品列表(last-n)。 - 对于last-n列表中每个物品,通过“物品
物品”的索引,找到top-k相似物品。 - 对于取回的相似物品(最多有
个),⽤公式预估⽤户对物品的兴趣分数。 - 返回分数最⾼的top-n个物品,作为推荐结果。
索引的意义在于避免枚举所有的物品。⽤索引,离线计算量⼤,线上计算量⼩。
二、Swing
假如重合的用户是一个小圈子,两篇不相似的文章也会被ItemCF认为相似:
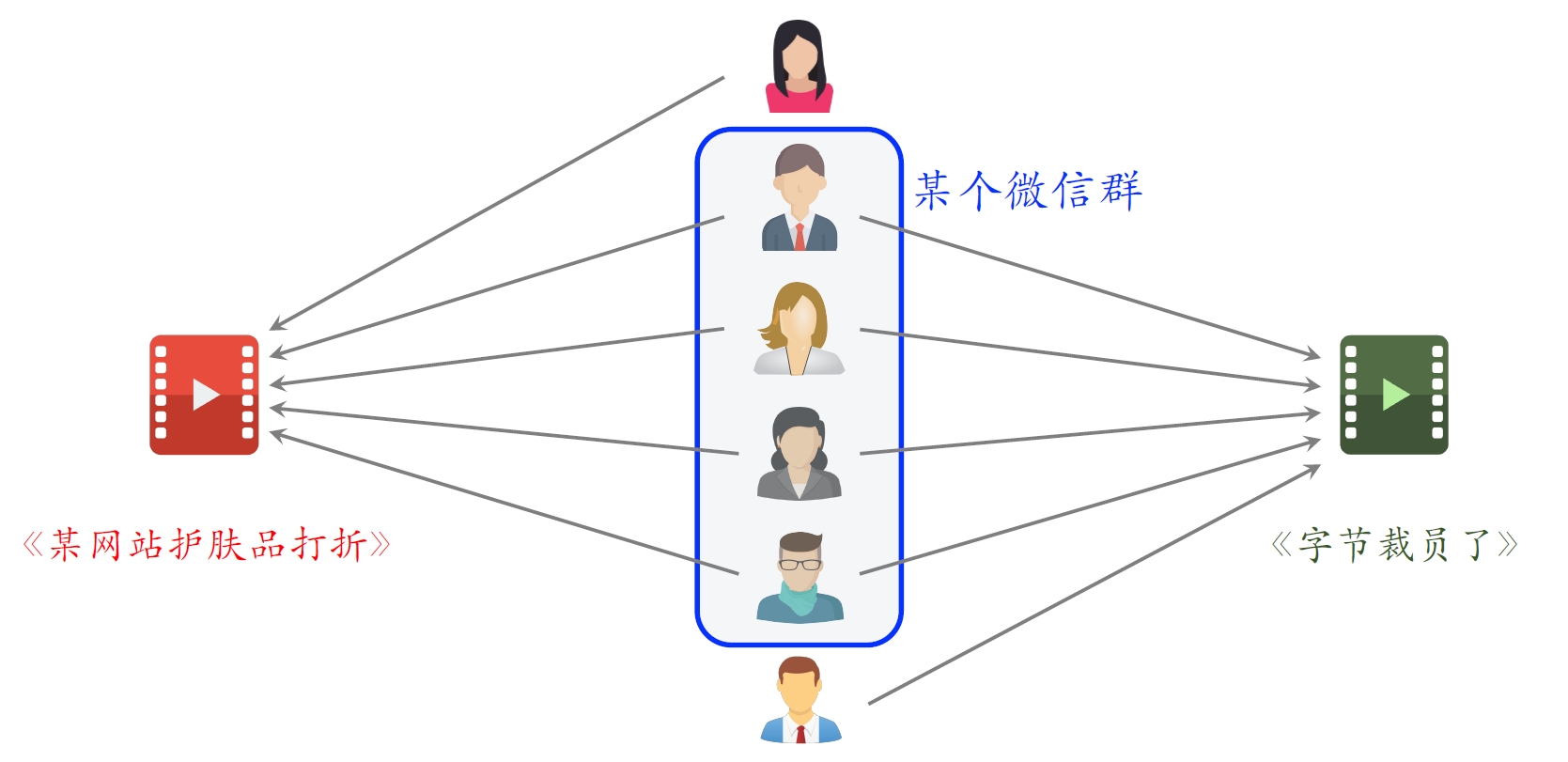
为解决上述问题Swing模型做以下调整
- ⽤户
喜欢的物品记作集合 。 - ⽤户
喜欢的物品记作集合 。 - 定义两个⽤户的重合度:
- ⽤户
和 的重合度⾼,则他们可能来⾃⼀个⼩圈⼦,要降低他们的权重。
Swing模型
- 喜欢物品
的⽤户记作集合 - 喜欢物品
的⽤户记作集合 - 定义交集
- 两个物品的相似度:
Swing 与ItemCF 唯⼀的区别在于物品相似度。
- ItemCF:两个物品重合的⽤户⽐例⾼,则判定两个 物品相似。
- Swing:额外考虑重合的⽤户是否来⾃⼀个⼩圈⼦。
- 同时喜欢两个物品的⽤户记作集合
- 对于
中的⽤户 和 ,重合度记作 - 两个⽤户重合度⼤,则可能来⾃⼀个⼩圈⼦,权重降低。
- 同时喜欢两个物品的⽤户记作集合
三、UserCF
基于用户的协同,就是说找到兴趣相同的用户,把其中某个用户选择过的东西,推荐给其他的用户。
推荐系统如何找到跟我兴趣非常相似的网友呢?
- 点击、点赞、收藏、转发的文章有很⼤的重合
- 关注的作者有很⼤的重合。
3.1 UserCF的基本思想
- 找到与你的目标用户有相同兴趣的用户。
- 给目标用户推荐相似用户有兴趣但是目标用户还没看过的物品。
3.2 用户之间的相似度
- 用户
喜欢的物品记作集合 - 用户
喜欢的物品记作集合 - 定义交集
- 两个⽤户的相似度:
预估⽤户对候选物品的兴趣:
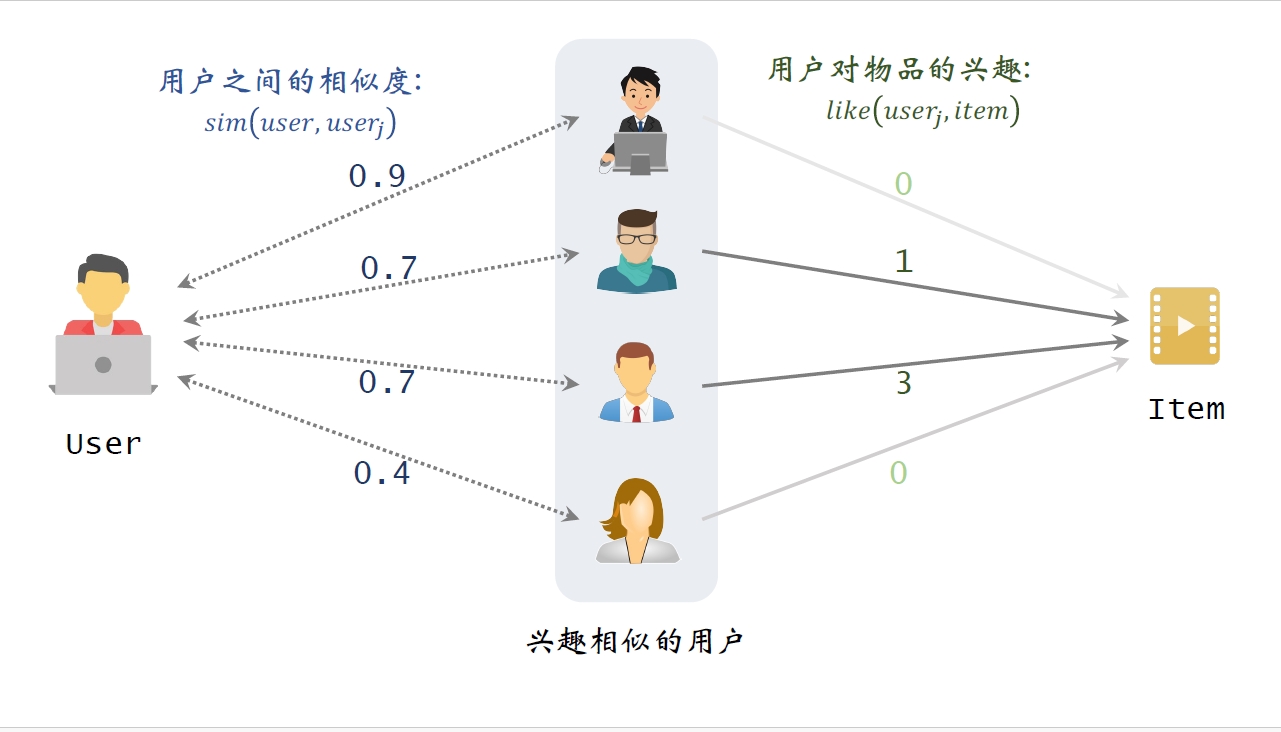
但是对于比较热门的物品可能大家都喜欢,这并不代表用户之间相似,所以要降低热门物品权重:
不论冷门、热门,物品权重都是1。
3.3 UserCF召回的完整流程
1.3.1 事先做离线计算
- 建⽴“用户
物品”的索引
- 记录每个⽤户最近点击、交互过的物品ID。
- 给定任意⽤户ID,可以找到他近期感兴趣的物品列表。
- 建⽴“用户
用户”的索引
- 对于每个⽤户,索引他最相似的
个⽤户。 - 给定任意⽤户ID,可以快速找到他最相似的
个⽤户。

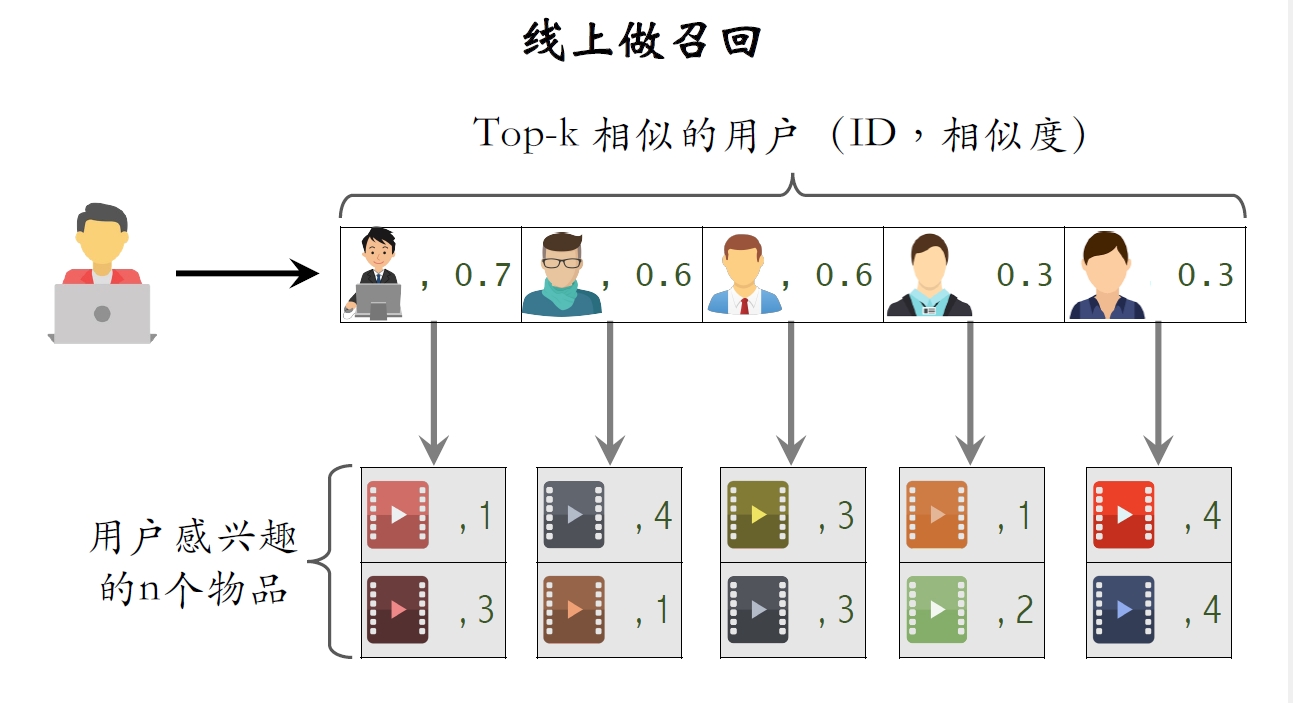
1.3.2 线上做召回
- 给定⽤户ID,通过“用户
用户”索引,找到top-k相似⽤户。 - 对于每个top-k相似⽤户,通过“用户
物品”的索引,找⽤户近期感兴趣的物品列表(last-n)。 - 对于取回的相似物品(最多有
个),⽤公式预估⽤户对物品的兴趣分数。 - 返回分数最⾼的top-n个物品,作为推荐结果。
推荐算法--CF
https://mztchaoqun.com.cn/posts/D62_CF/