贝叶斯分类器
1.贝叶斯公式
条件概率公式
设
全概率公式
如果事件
上式即为全概率公式(formula of total probability)
全概率公式的意义在于,当直接计算
贝叶斯公式
与全概率公式解决的问题相反,贝叶斯公式是建立在条件概率的基础上寻找事件发生的原因(事件
上式即为贝叶斯公式(Bayes formula),
2.朴素贝叶斯法
2.1 基本方法
设输入空间
由
朴素贝叶斯法通过训练数据集学习联合概率分布
条件概率分布
于是学习到联合概率分布
条件概率分布
朴素贝叶斯法对条件概率分布做了条件独立性的假设。由于这是一个较强的假设,朴素贝叶斯也由此得名。条件独立的假设是
朴素贝叶斯是生成模型,它学习到的是生成数据的机制。条件独立假设等价于用于分类的特征在类确定的条件下都是条件独立的。这个假设使朴素贝叶斯法变得简单,但有时会使分类的准确率降低。
朴素贝叶斯法分类时,对给定的输入
将后验概率最大的类作为
根据条件独立性假设可得
这便是朴素贝叶斯的基本公式,朴素贝叶斯分类器可表示为
其中分母对所有
2.2 后验概率最大化含义
朴素贝叶斯法将实例分到后验概率最大的类中,这等价于期望风险最小化。假设选择0-1损失函数
其中
期望是对联合分布
为了使期望风险最小化,只需对
由以上推导就得到了后验概率最大化准则
2.3 朴素贝叶斯参数估计
2.3.1 极大似然估计
在朴素贝叶斯法中,学习意味着估计
可以应用极大似然估计法估计相应概率,则
设第
条件概率的极大似然估计
式中,
2.3.2 贝叶斯估计
极大似然估计可能会出现所要估计的概率为0的情况。这时会影响到后验概率的计算结果,使分类产生偏差。使用贝叶斯估计可解决这一问题,如下:
其中
先验概率的贝叶斯估计是
3.贝叶斯网路
3.1 定义
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型(directed acyclic graphical model),是一种概率图模型,于1985年由Judea Pearl首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(DAG)。
贝叶斯网络的有向无环图中的节点表示随机变量
假设节点

把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。其主要用来描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)。
令
则称
于任意的随机变量,其联合概率可由各自的局部条件概率分布相乘而得出:
3.2 结构
给定如下图所示的一个贝叶斯网络:
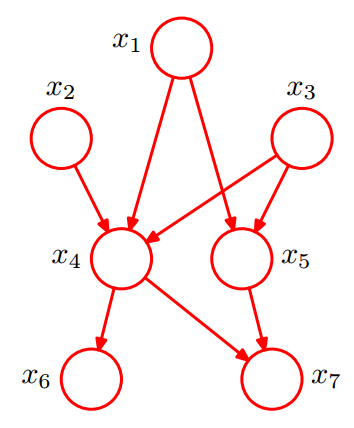
则其联合分布为:
贝叶斯网络中三个变量之间的典型依赖关系有:同父结构(tail-to-tail),V型结构(head-to-head),顺序结构(head-to-tail).
tail-to-tail
如下图为tail-to-tail类型:
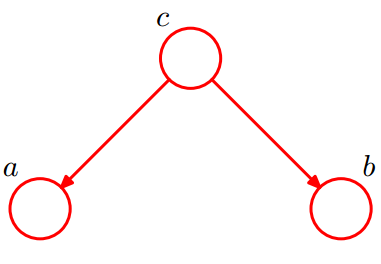
考虑
在
此时,没法得出
在
所以,在
head-to-head
如下图为head-to-head类型:
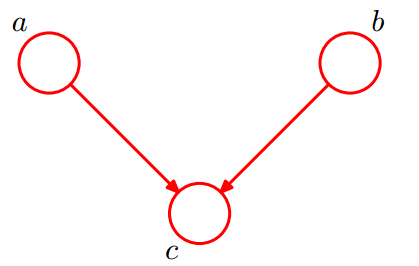
联合分布为:
有:
即在
head-to-tail
如下图为head-to-tail类型:
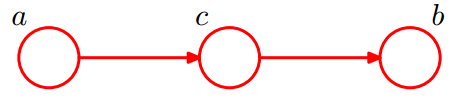
即
则有:
所以,在
这个head-to-tail其实就是一个链式网络,如下图所示:

在
广义的讲,对于任意的结点集
和 的“head-to-tail型”和“tail-to-tail型”路径都通过 ; 和 的“head-to-head型”路径不通过 以及 的子孙;
3.3 因子图
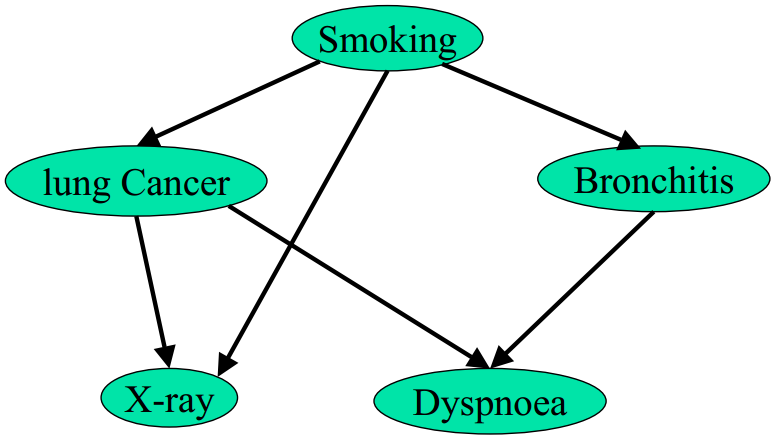
对于上图,在一个人已经呼吸困难(dyspnoea)的情况下,其抽烟(smoking)的概率是:
上式首先对联合概率关于
3.3.1 因子图定义
将一个具有多变量的全局函数因子分解,得到几个局部函数的乘积,以此为基础得到的一个双向图叫做因子图(Factor Graph)。
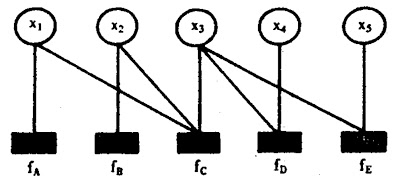
例如,假定对函数
其对应的因子图
1.变量节点
2.因子(函数)节点
3.边
通俗来讲,所谓因子图就是对函数进行因子分解得到的一种概率图。一般内含两种节点:变量节点和函数节点。我们知道,一个全局函数通过因式分解能够分解为多个局部函数的乘积,这些局部函数和对应的变量关系就体现在因子图上。
如下全局函数,其因式分解方程为:
其中
其对应的因子图为:
且上述因子图等价于:
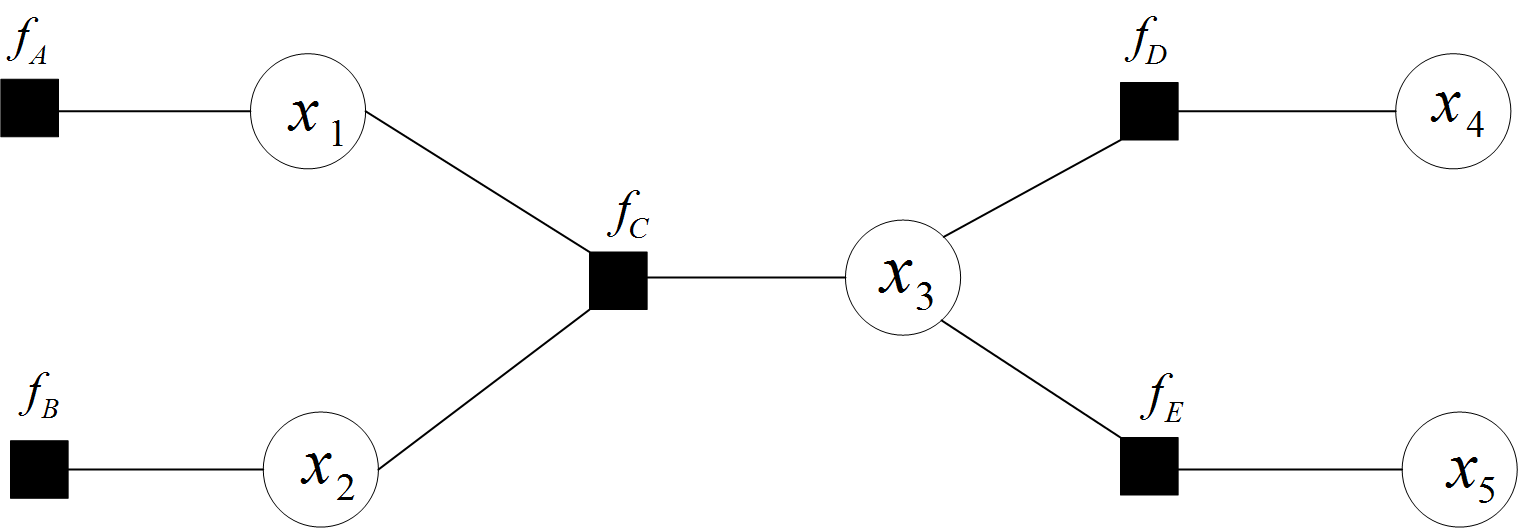
在因子图中,所有的顶点不是变量节点就是函数节点,边线表示它们之间的函数关系。因子图跟贝叶斯网络和马尔科夫随机场(Markov Random Fields)一样,也是概率图的一种。
- 有向图模型,又称作贝叶斯网络(Directed Graphical Models, DGM, Bayesian Network)。
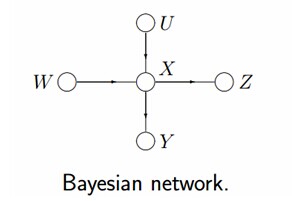
- 但在有些情况下,强制对某些结点之间的边增加方向是不合适的。使用没有方向的无向边,形成了无向图模型(Undirected Graphical Model,UGM), 又被称为马尔科夫随机场或者马尔科夫网络(Markov Random Field, MRF or Markov network)。
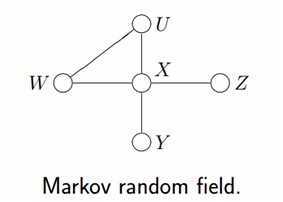
- 设
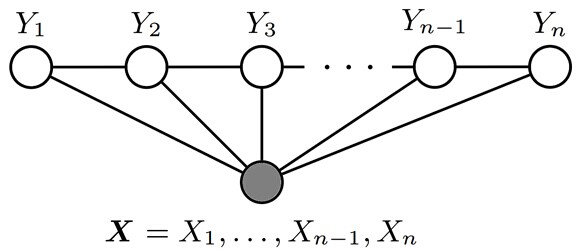
和 都是联合随机变量,若随机变量Y构成一个无向图 表示的马尔科夫随机场(MRF),则条件概率分布P(Y|X)称为条件随机场(Conditional Random Field, 简称CRF)。如下图所示,便是一个线性链条件随机场的无向图模型:
在概率图中,求某个变量的边缘分布是常见的问题。这问题有很多求解方法,其中之一就是把贝叶斯网络或马尔科夫随机场转换成因子图,然后用sum-product算法求解。换言之,基于因子图可以用sum-product 算法高效的求各个变量的边缘分布。
接下来首先说明如何把贝叶斯网络(和马尔科夫随机场),以及把马尔科夫链、隐马尔科夫模型转换成因子图后的情形,然后再来看如何利用因子图的sum-product算法求边缘概率分布。
给定下图所示的贝叶斯网络或马尔科夫随机场:
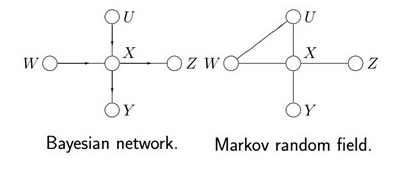
根据各个变量对应的关系,可得:
其对应的因子图为(以下两种因子图的表示方式皆可):
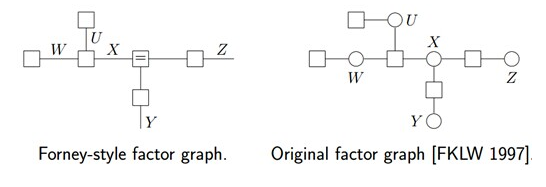
由上述例子总结出由贝叶斯网络构造因子图的方法:
- 贝叶斯网络中的一个因子对应因子图中的一个结点
- 贝叶斯网络中的每一个变量在因子图上对应边或者半边
- 结点
和边 相连当且仅当变量 出现在因子 中。
再比如,对于下图所示的由马尔科夫链转换而成的因子图:
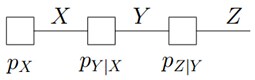 有:
有:
而对于如下图所示的由隐马尔科夫模型转换而成的因子图:
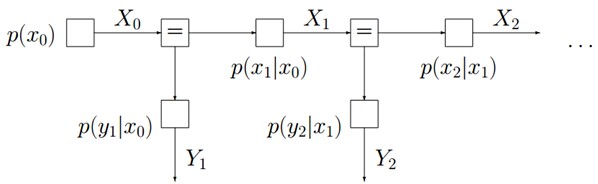
有:
3.3.2 Sum-product算法
对于下图所示的因子图:
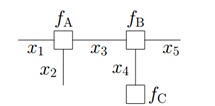
有:
联合概率分布和边缘概率分布:
- 联合概率表示两个事件共同发生的概率.
与 的联合概率表示为 或者 . - 边缘概率(又称先验概率)是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率)。这称为边缘化(marginalization)。
的边缘概率表示为 , 的边缘概率表示为 。
某个随机变量
对
如果有
那么
假定现在我们需要计算如下式子的结果:
同时,
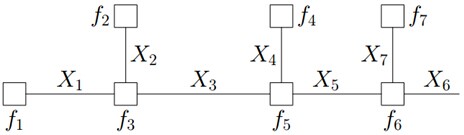
提取公因子:
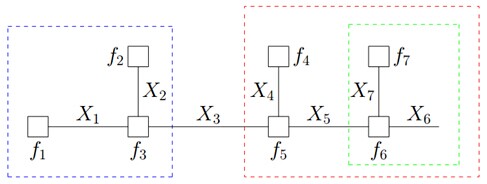
因为变量的边缘概率等于所有与他相连的函数传递过来的消息的积,所以计算得到:
可以发现,其中用到了类似“消息传递”的观点,且总共两个步骤。
第一步,对于
可得:
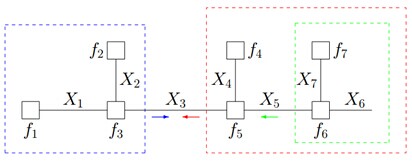
第二步,根据蓝色虚线框、红色虚线框围住的两个box内部的消息传递:
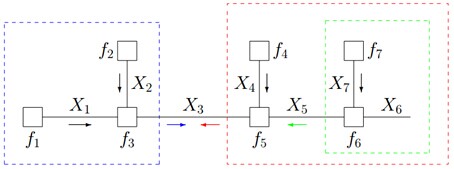
根据
有
上述计算过程将一个概率分布写成两个因子的乘积,而这两个因子可以继续分解或者通过已知得到。这种利用消息传递的观念计算概率的方法便是sum-product算法。基于因子图可以用sum-product算法可以高效的求各个变量的边缘分布。sum-product算法,也叫belief propagation,有两种消息:
- 一种是变量(Variable)到函数(Function)的消息:
, 此时,变量到函数的消息为 ,如下图所示:

- 另外一种是函数(Function)到变量(Variable)的消息:
, 此时,函数到变量的消息为: ,如下图所示:

sum-product算法的总体框架:
- 1.给定如下图所示的因子图:
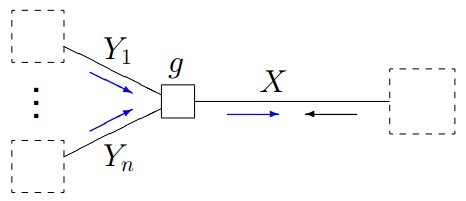
- 2.sum-product 算法的消息计算规则为:
- 3.根据sum-product定理,如果因子图中的函数
没有周期,则有:
如果因子图是无环的,则一定可以准确的求出任意一个变量的边缘分布,如果是有环的,则无法用sum-product算法准确求出来边缘分布。
比如,下图所示的贝叶斯网络:
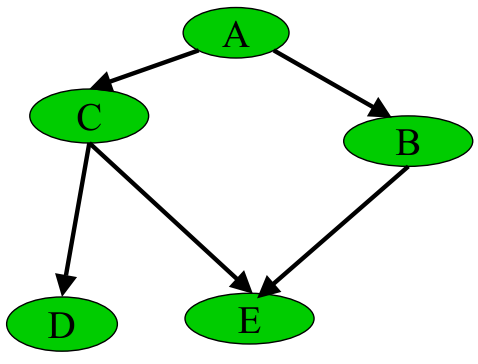
其转换成因子图后,为:
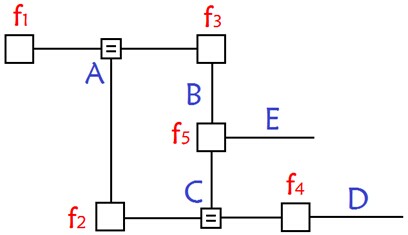
可以发现,若贝叶斯网络中存在“环”(无向),则因此构造的因子图会得到环。而使用消息传递的思想,这个消息将无限传输下去,不利于概率计算。
解决方法有3个:
第一种
删除贝叶斯网络中的若干条边,使得它不含有无向环.比如给定下图中左边部分所示的原贝叶斯网络,可以通过去掉C和E之间的边,使得它重新变成有向无环图,从而成为图中右边部分的近似树结构:
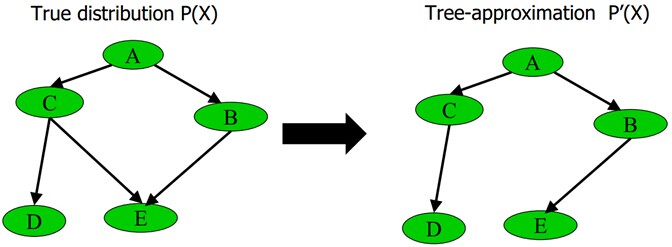
具体变换的过程为最大权生成树算法MSWT,通过此算法,这课树的近似联合概率
MSWT建树过程:
- 对于给定的分布
,对于所有的 ,计算联合分布
- 对于给定的分布
- 2.使用第1步得到的概率分布,计算任意两个结点的互信息
,并把 作为这两个结点连接边的权值; - 3.计算最大权生成树(Maximum-weight spanning tree)
- 初始状态:
个变量(结点),0条边
- 初始状态:
- 插入最大权重的边
- 找到下一个最大的边,并且加入到树中;要求加入后,没有环生成。否则,查找次大的边;
- 重复上述过程
过程直到插入了 条边(树建立完成)
- 重复上述过程
- 选择任意结点作为根,从根到叶子标识边的方向;
- 可以保证,这课树的近似联合概率
和原贝叶斯网络的联合概率 的相对熵最小。
- 可以保证,这课树的近似联合概率
第二种
重新构造没有环的贝叶斯网络
第三种
选择loopy belief propagation算法(可以简单理解为sum-product 算法的递归版本),此算法一般选择环中的某个消息,随机赋个初值,然后用sum-product算法,迭代下去,因为有环,一定会到达刚才赋初值的那个消息,然后更新那个消息,继续迭代,直到没有消息再改变为止。唯一的缺点是不确保收敛,当然,此算法在绝大多数情况下是收敛的。
此外,除了这个sum-product算法,还有一个max-product 算法。但只要弄懂了sum-product,也就弄懂了max-product 算法。因为max-product 算法就在上面sum-product 算法的基础上把求和符号换成求最大值max的符号即可!
最后,sum-product 和 max-product 算法也能应用到隐马尔科夫模型hidden Markov models上。
参考
- 周志华 《机器学习》
- 理解全概率公式与贝叶斯公式
- 全概率公式、贝叶斯公式推导过程
- 从贝叶斯方法谈到贝叶斯网络