循环神经网络(Recurrent Neural
Network,RNN)是一类用于处理序列数据的神经网络,它在时间步上有循环连接,能够捕捉序列中的时间依赖关系。RNN广泛应用于自然语言处理(NLP)、时间序列预测、语音识别等领域。
一、序列模型
1.1 自回归模型
对于股票,用时间步 (time
step)
为了实现这个预测,可以使用回归模型,有一个主要问题:输入数据的数量,输入
第一种策略,假设在现实情况下相当长的序列自回归模型 (autoregressive
models),因为它们是对自己执行回归。
第二种策略,如图所示,是保留一些对过去观测的总结隐变量自回归模型 (latent
autoregressive models)。
隐变量自回归模型
整个序列的估计值可以通过以下的方式获得:
如果处理的是离散的对象(如单词),而不是连续的数字,则上述的考虑仍然有效。唯一的差别是,对于离散的对象,需要使用分类器而不是回归模型来估计
1.2 马尔可夫模型
在自回归模型的近似法中,使用马尔可夫条件 (Markov
condition)。特别是,如果一阶马尔可夫模型 (first-order Markov
model),
当
当假设
利用这一事实,只需要考虑过去观察中的一个非常短的历史:
1.3 因果关系
基于条件概率公式将
如果基于一个马尔可夫模型,还可以得到一个反向的条件概率分布。然而,在许多情况下,数据存在一个自然的方向,即在时间上是前进的。很明显,未来的事件不能影响过去。因此,如果改变
二、语言模型
2.1 文本预处理
2.1.1 加载数据
时光机器 中加载文本。有30000多个单词,下面的函数(将数据集读取到由多条文本行组成的列表中 ),其中每条文本行都是一个字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import collectionsimport refrom d2l import torch as d2l'time_machine' ] = (d2l.DATA_URL + 'timemachine.txt' ,'090b5e7e70c295757f55df93cb0a180b9691891a' )def read_time_machine ():"""将时间机器数据集加载到文本行的列表中""" with open (d2l.download('time_machine' ), 'r' ) as f:return [re.sub('[^A-Za-z]+' , ' ' , line).strip().lower() for line in lines]
2.1.2 词元化
下面的tokenize函数将文本行列表(lines)作为输入,列表中的每个元素是一个文本序列(如一条文本行)。每个文本序列又被拆分成一个词元列表 ,词元 (token)是文本的基本单位。最后,返回一个由词元列表组成的列表,其中的每个词元都是一个字符串(string)。
1 2 3 4 5 6 7 8 9 10 11 12 def tokenize (lines, token='word' ): """将文本行拆分为单词或字符词元""" if token == 'word' :return [line.split() for line in lines]elif token == 'char' :return [list (line) for line in lines]else :print ('错误:未知词元类型:' + token)学习语言模型for i in range (11 ):print (tokens[i])
1 2 3 4 5 6 7 8 9 10 11 ['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
2.1.3 词表
词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。现在,构建一个字典,通常也叫做词表 (vocabulary),用来将字符串类型的词元映射到从 。先将训练集中的所有文档合并在一起,对它们的唯一词元进行统计,得到的统计结果称之为语料 (corpus)。然后根据每个唯一词元的出现频率,为其分配一个数字索引。很少出现的词元通常被移除,这可以降低复杂性。另外,语料库中不存在或已删除的任何词元都将映射到一个特定的未知词元“<unk>”。可以选择增加一个列表,用于保存那些被保留的词元,例如:填充词元(“<pad>”);序列开始词元(“<bos>”);序列结束词元(“<eos>”)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 class Vocab :"""文本词表""" def __init__ (self, tokens=None , min_freq=0 , reserved_tokens=None ):if tokens is None :if reserved_tokens is None :self ._token_freqs = sorted (counter.items(), key=lambda x: x[1 ],True )self .idx_to_token = ['<unk>' ] + reserved_tokensself .token_to_idx = {token: idxfor idx, token in enumerate (self .idx_to_token)}for token, freq in self ._token_freqs:if freq < min_freq:break if token not in self .token_to_idx:self .idx_to_token.append(token)self .token_to_idx[token] = len (self .idx_to_token) - 1 def __len__ (self ):return len (self .idx_to_token)def __getitem__ (self, tokens ):if not isinstance (tokens, (list , tuple )):return self .token_to_idx.get(tokens, self .unk)return [self .__getitem__(token) for token in tokens]def to_tokens (self, indices ):if not isinstance (indices, (list , tuple )):return self .idx_to_token[indices]return [self .idx_to_token[index] for index in indices] @property def unk (self ): return 0 @property def token_freqs (self ):return self ._token_freqsdef count_corpus (tokens ): """统计词元的频率""" if len (tokens) == 0 or isinstance (tokens[0 ], list ):for line in tokens for token in line]return collections.Counter(tokens)
使用时光机器数据集作为语料库来构建词表 ,然后打印前几个高频词元及其索引。
1 2 vocab = Vocab(tokens)print (list (vocab.token_to_idx.items())[:10 ])
1 [('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8), ('that', 9)]
将每一条文本行转换成一个数字索引列表
1 2 3 for i in [0 , 10 ]:print ('文本:' , tokens[i])print ('索引:' , vocab[tokens[i]])
1 2 3 4 文本: ['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
该函数返回corpus(词元索引列表)和vocab(时光机器语料库的词表)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def load_corpus_time_machine (max_tokens=-1 ): """返回时光机器数据集的词元索引列表和词表""" 'char' )for line in tokens for token in line]if max_tokens > 0 :return corpus, vocablen (corpus), len (vocab)
2.2 学习语言模型
假设在单词级别对文本数据进行词元化,依据自回归中对序列模型的分析,从基本概率规则开始:
例如,包含了四个单词的一个文本序列的概率是:
为了训练语言模型,需要计算单词的概率,以及给定前面几个单词后出现某个单词的条件概率。这些概率本质上就是语言模型的参数。
假设训练数据集是一个大型的文本语料库。训练数据集中词的概率可以根据给定词的相对词频来计算。例如,可以将估计值
其中
一种常见的策略是执行某种形式的拉普拉斯平滑 (Laplace
smoothing),具体方法是在所有计数中添加一个小常量。用
其中,
然而,这样的模型很容易变得无效,原因如下:首先,需要存储所有的计数;其次,这完全忽略了单词的意思。例如,“猫”(cat)和“猫科动物”(feline)可能出现在相关的上下文中,但是想根据上下文调整这类模型其实是相当困难的。最后,长单词序列大部分是没出现过的,因此一个模型如果只是简单地统计先前“看到”的单词序列频率,那么模型面对这种问题肯定是表现不佳的。
2.3 马尔可夫模型与
在讨论包含深度学习的解决方案之前,我们需要了解更多的概念和术语。回想一下在序列模型中对马尔可夫模型的讨论,
并且将其应用于语言建模。如果
通常,涉及一个、两个和三个变量的概率公式分别被称为一元语法 (unigram)、二元语法 (bigram)和三元语法 (trigram)模型。
2.4 自然语言统计
使用时光机器数据集构建的词表, 打印前
10个最常用的(频率最高的)单词。
1 2 3 4 for line in tokens for token in line]10 ]
1 2 3 4 5 6 7 8 9 10 [('the', 2261),
(出现次数 )看起并没有太大作用的词,这些词通常(被称为停用词 )(stop
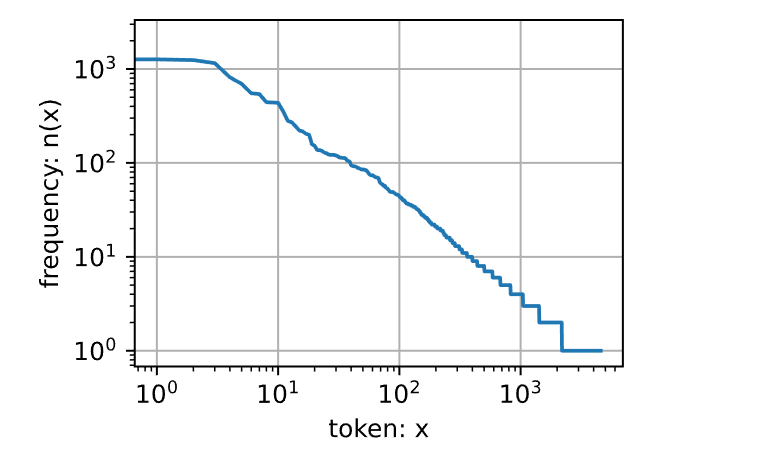
words),因此可以被过滤掉。尽管如此,它们本身仍然是有意义的,仍然会在模型中使用它们。此外,还有个明显的问题是词频衰减的速度相当地快。例如,最常用单词的词频对比,第画出的词频图 ]:
1 2 3 freqs = [freq for token, freq in vocab.token_freqs]'token: x' , ylabel='frequency: n(x)' ,'log' , yscale='log' )
通过此图可以发现:词频以一种明确的方式迅速衰减。将前几个单词作为例外消除后,剩余的所有单词大致遵循双对数坐标图上的一条直线。这意味着单词的频率满足齐普夫定律 (Zipf’s
law),即第
等价于
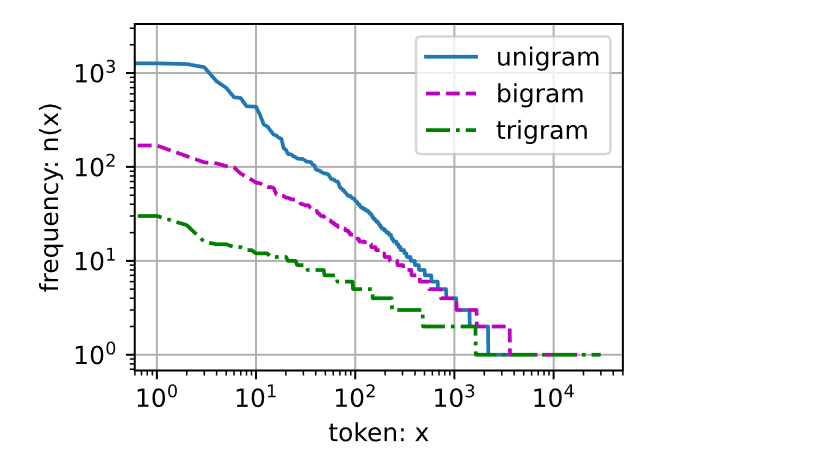
其中其他的词元组合,比如二元语法、三元语法等等,又会如何呢? ]接下来看看二元语法的频率是否与一元语法的频率表现出相同的行为方式。
1 2 3 bigram_tokens = [pair for pair in zip (corpus[:-1 ], corpus[1 :])]10 ]
1 2 3 4 5 6 7 8 9 10 [(('of', 'the'), 309),
在十个最频繁的词对中,有九个是由两个停用词组成的, 只有一个与“the
time”有关。 再进一步看看三元语法的频率是否表现出相同的行为方式。
1 2 3 4 trigram_tokens = [triple for triple in zip (2 ], corpus[1 :-1 ], corpus[2 :])]10 ]
1 2 3 4 5 6 7 8 9 10 [(('the', 'time', 'traveller'), 59),
直观地对比三种模型中的词元频率: 一元语法、二元语法和三元语法。
1 2 3 4 5 bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]for token, freq in trigram_vocab.token_freqs]'token: x' ,'frequency: n(x)' , xscale='log' , yscale='log' ,'unigram' , 'bigram' , 'trigram' ])
除了一元语法词,单词序列似乎也遵循齐普夫定律,尽管公式齐普夫定律 中的指数
词表中
很多
2.5 读取长序列数据
由于序列数据本质上是连续的,因此在处理数据时需要解决这个问题。在序列模型中章节中写了一种方式做到了这一点:当序列变得太长而不能被模型一次性全部处理时,对序列进行拆分方便模型读取。
假设使用神经网络来训练语言模型,模型中的网络一次处理具有预定义长度(例如随机生成一个小批量数据的特征和标签以供读取。 ]
首先,由于文本序列可以是任意长的,于是任意长的序列可以被划分为具有相同时间步数的子序列。当训练神经网络时,这样的小批量子序列将被输入到模型中。假设网络一次只处理具有
分割文本时,不同的偏移量会导致不同的子序列
可以选择任意偏移量来指示初始位置。如果只选择一个偏移量,那么用于训练网络的、所有可能的子序列的覆盖范围将是有限的。因此,可以从随机偏移量开始划分序列,以同时获得覆盖性 (coverage)和随机性 (randomness)。
2.5.1 随机采样
在随机采样中,每个样本都是在原始的长序列上任意捕获的子序列。 在迭代过程中,来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻。对于语言建模,目标是基于到目前为止看到的词元来预测下一个词元,因此标签是移位了一个词元的原始序列。
下面的代码每次可以从数据中随机生成一个小批量。在这里,参数batch_size指定了每个小批量中子序列样本的数目,参数num_steps是每个子序列中预定义的时间步数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import randomimport torchdef seq_data_iter_random (corpus, batch_size, num_steps ): """使用随机抽样生成一个小批量子序列""" 0 , num_steps - 1 ):]len (corpus) - 1 ) // num_stepslist (range (0 , num_subseqs * num_steps, num_steps))def data (pos ):return corpus[pos: pos + num_steps]for i in range (0 , batch_size * num_batches, batch_size):for j in initial_indices_per_batch]1 ) for j in initial_indices_per_batch]yield torch.tensor(X), torch.tensor(Y)
生成一个从
1 2 3 my_seq = list (range (35 ))for X, Y in seq_data_iter_random(my_seq, batch_size=2 , num_steps=5 ):print ('X: ' , X, '\nY:' , Y)
1 2 3 4 5 6 7 8 9 10 11 12 X: tensor([[21, 22, 23, 24, 25],
2.5.2 顺序分区
在迭代过程中,除了对原始序列可以随机抽样外,还可以保证两个相邻的小批量中的子序列在原始序列上也是相邻的 。这种策略在基于小批量的迭代过程中保留了拆分的子序列的顺序,因此称为顺序分区。
1 2 3 4 5 6 7 8 9 10 11 12 13 def seq_data_iter_sequential (corpus, batch_size, num_steps ): """使用顺序分区生成一个小批量子序列""" 0 , num_steps)len (corpus) - offset - 1 ) // batch_size) * batch_size1 : offset + 1 + num_tokens])1 ), Ys.reshape(batch_size, -1 )1 ] // num_stepsfor i in range (0 , num_steps * num_batches, num_steps):yield X, Y
基于相同的设置,通过顺序分区读取每个小批量的子序列的特征X和标签Y 。通过将它们打印出来可以发现:迭代期间来自两个相邻的小批量中的子序列在原始序列中确实是相邻的。
1 2 for X, Y in seq_data_iter_sequential(my_seq, batch_size=2 , num_steps=5 ):print ('X: ' , X, '\nY:' , Y)
1 2 3 4 5 6 7 8 X: tensor([[ 5, 6, 7, 8, 9],
定义了一个函数load_data_time_machine,它同时返回数据迭代器和词表。方便后续的模型训练时使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class SeqDataLoader : """加载序列数据的迭代器""" def __init__ (self, batch_size, num_steps, use_random_iter, max_tokens ):if use_random_iter:self .data_iter_fn = seq_data_iter_randomelse :self .data_iter_fn = seq_data_iter_sequentialself .corpus, self .vocab = load_corpus_time_machine(max_tokens)self .batch_size, self .num_steps = batch_size, num_stepsdef __iter__ (self ):return self .data_iter_fn(self .corpus, self .batch_size, self .num_steps)def load_data_time_machine (batch_size, num_steps, use_random_iter=False , max_tokens=10000 ):"""返回时光机器数据集的迭代器和词表""" return data_iter, data_iter.vocab
三、RNN
在
其中隐状态 (hidden
state),也称为隐藏变量 (hidden
variable),它存储了到时间步
对于上式中的函数
多层感知机具有隐藏单元的隐藏层。值得注意的是,隐藏层和隐状态指的是两个截然不同的概念。如上所述,隐藏层是在从输入到输出的路径上(以观测角度来理解)的隐藏的层,而隐状态则是在给定步骤所做的任何事情(以技术角度来定义)的输入 ,并且这些状态只能通过先前时间步的数据来计算。
循环神经网络 (recurrent neural
networks,RNNs)是具有隐状态的神经网络。
3.1 无隐状态的神经网络
看一下只有单隐藏层的多层感知机。设隐藏层的激活函数为
在公式中,拥有的隐藏层权重参数为
其中,
3.2 有隐状态的循环神经网络
有了隐状态后,情况就完全不同了。假设在时间步
与无隐状态的神经网络相比,这里多添加了一项隐状态 (hidden
state)。由于在当前时间步中,隐状态使用的定义与前一个时间步中使用的定义相同,因此上述公式的计算是循环的 (recurrent)。于是基于循环计算的隐状态神经网络被命名为循环神经网络 (recurrent
neural
network)。在循环神经网络中执行计算的层称为循环层 (recurrent
layer)。
对于时间步
循环神经网络的参数包括隐藏层的权重
下图展示了循环神经网络在三个相邻时间步的计算逻辑。在任意时间步
拼接当前时间步
将拼接的结果送入带有激活函数
模型参数是
具有隐状态的循环神经网络
隐状态中X、W_xh、H和W_hh,它们的形状分别为, , , , X乘以W_xh,将H乘以W_hh,然后将这两个乘法相加,得到一个形状为,
1 2 3 X, W_xh = torch.normal(0 , 1 , (3 , 1 )), torch.normal(0 , 1 , (1 , 4 ))0 , 1 , (3 , 4 )), torch.normal(0 , 1 , (4 , 4 ))
1 2 3 tensor([[ 1.5601, 0.1154, -3.8533, 0.0946],
沿列(轴1)拼接矩阵X和H,沿行(轴0)拼接矩阵W_xh和W_hh。这两个拼接分别产生形状
1 torch.matmul(torch.cat((X, H), 1 ), torch.cat((W_xh, W_hh), 0 ))
1 2 3 tensor([[ 1.5601, 0.1154, -3.8533, 0.0946],
3.3
基于循环神经网络的字符级语言模型
语言模型,的目标是根据过去的和当前的词元预测下一个词元,因此将原始序列移位一个词元作为标签。看一下如何使用循环神经网络来构建语言模型。设小批量大小为1,批量中的文本序列为“machine”。为了简化后续部分的训练,考虑使用字符级语言模型 (character-level
language
model),将文本词元化为字符而不是单词。如何通过基于字符级语言建模的循环神经网络,使用当前的和先前的字符预测下一个字符。
基于循环神经网络的字符级语言模型:输入序列和标签序列分别为“machin”和“achine”
在训练过程中,对每个时间步的输出层的输出进行softmax操作,然后利用交叉熵损失计算模型输出和标签之间的误差。由于隐藏层中隐状态的循环计算,图中的第
在实践中,使用的批量大小为
3.4 困惑度(Perplexity)
可以通过一个序列中所有的
其中困惑度 (perplexity)的量。简而言之,它是上述公式的指数:
困惑度的最好的理解是“下一个词元的实际选择数的调和平均数”。
在最好的情况下,模型总是完美地估计标签词元的概率为1。在这种情况下,模型的困惑度为1。
在最坏的情况下,模型总是预测标签词元的概率为0。在这种情况下,困惑度是正无穷大。
在基线上,该模型的预测是词表的所有可用词元上的均匀分布。在这种情况下,困惑度等于词表中唯一词元的数量。
3.5 梯度裁剪
对于长度为
一般来说,当解决优化问题时,对模型参数采用更新步骤。假定在向量形式的利普希茨连续的 (Lipschitz
continuous)。也就是说,对于任意
在这种情况下,可以安全地假设:如果通过
这意味着不会观察到超过
有时梯度可能很大,从而优化算法可能无法收敛。可以通过降低
通过这样做,梯度范数永远不会超过
1 2 3 4 5 6 7 8 9 10 def grad_clipping (net, theta ):"""裁剪梯度""" if isinstance (net, nn.Module):for p in net.parameters() if p.requires_grad]else :sum (torch.sum ((p.grad ** 2 )) for p in params))if norm > theta:for param in params:
3.6 代码实现
定义模型
构造一个具有256个隐藏单元的单隐藏层的循环神经网络层rnn_layer
1 2 3 4 5 6 7 8 9 10 11 import torchfrom torch import nnimport mathfrom torch.nn import functional as Ffrom d2l import torch as d2l32 , 35 256 len (vocab), num_hiddens)
使用张量来初始化隐状态,它的形状是(隐藏层数,批量大小,隐藏单元数)。通过一个隐状态和一个输入,我们就可以用更新后的隐状态计算输出。需要强调的是,rnn_layer的“输出”(Y)不涉及输出层的计算:它是指每个时间步的隐状态,这些隐状态可以用作后续输出层的输入。
1 2 3 4 state = torch.zeros((1 , batch_size, num_hiddens)) len (vocab)))
循环神经网络模型定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class RNNModel (nn.Module):"""循环神经网络模型""" def __init__ (self, rnn_layer, vocab_size, **kwargs ):super (RNNModel, self ).__init__(**kwargs)self .rnn = rnn_layerself .vocab_size = vocab_sizeself .num_hiddens = self .rnn.hidden_sizeif not self .rnn.bidirectional:self .num_directions = 1 self .linear = nn.Linear(self .num_hiddens, self .vocab_size)else :self .num_directions = 2 self .linear = nn.Linear(self .num_hiddens * 2 , self .vocab_size)def forward (self, inputs, state ):self .vocab_size)self .rnn(X, state)self .linear(Y.reshape((-1 , Y.shape[-1 ])))return output, statedef begin_state (self, device, batch_size=1 ):if not isinstance (self .rnn, nn.LSTM):return torch.zeros((self .num_directions * self .rnn.num_layers,self .num_hiddens),else :return (torch.zeros((self .num_directions * self .rnn.num_layers,self .num_hiddens), device=device),self .num_directions * self .rnn.num_layers,self .num_hiddens), device=device))
训练与预测
预测
1 2 3 4 5 6 7 8 9 10 11 12 def predict8 (prefix, num_preds, net, vocab, device ): """在prefix后面生成新字符""" 1 , device=device)0 ]]]lambda : torch.tensor([outputs[-1 ]], device=device).reshape((1 , 1 ))for y in prefix[1 :]: for _ in range (num_preds): int (y.argmax(dim=1 ).reshape(1 )))return '' .join([vocab.idx_to_token[i] for i in outputs])
训练
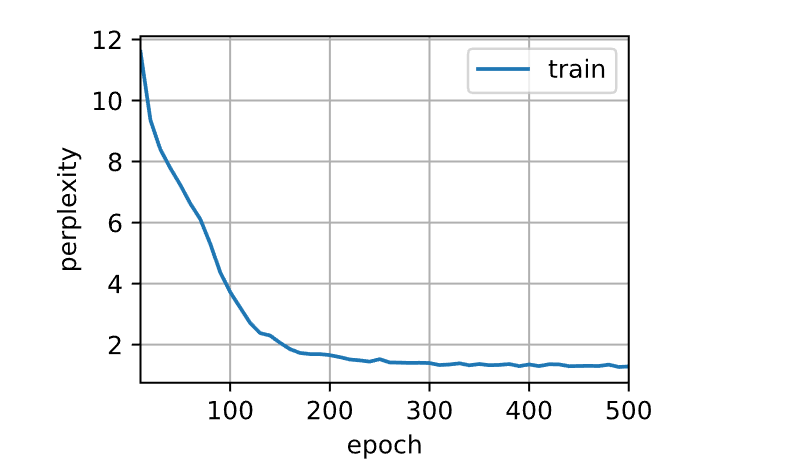
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 def train_epoch8 (net, train_iter, loss, updater, device, use_random_iter ):"""训练网络一个迭代周期""" None , d2l.Timer()2 ) for X, Y in train_iter:if state is None or use_random_iter:0 ], device=device)else :if isinstance (net, nn.Module) and not isinstance (state, tuple ):else :for s in state:1 )if isinstance (updater, torch.optim.Optimizer):1 )else :1 )1 )return math.exp(metric[0 ] / metric[1 ]), metric[1 ] / timer.stop()def train8 (net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False ):"""训练模型""" 'epoch' , ylabel='perplexity' ,'train' ], xlim=[10 , num_epochs])lambda prefix: predict8(prefix, 50 , net, vocab, device)for epoch in range (num_epochs):if (epoch + 1 ) % 10 == 0 :print (predict('time traveller' ))1 , [ppl])print (f'困惑度 {ppl:.1 f} , {speed:.1 f} 词元/秒 {str (device)} ' )print (predict('time traveller' ))print (predict('traveller' ))
初始化网络并训练
1 2 3 4 5 device = try_gpu()len (vocab))500 , 1
1 2 3 困惑度 1.3, 1240132.1 词元/秒 cuda:0
四、通过时间反向传播
循环神经网络中的前向传播相对简单。通过时间反向传播 (backpropagation
through
time,BPTT)实际上是循环神经网络中反向传播技术的一个特定应用。它要求将循环神经网络的计算图一次展开一个时间步,以获得模型变量和参数之间的依赖关系。然后,基于链式法则,应用反向传播来计算和存储梯度。由于序列可能相当长,因此依赖关系也可能相当长。例如,某个1000个字符的序列,其第一个词元可能会对最后位置的词元产生重大影响。这在计算上是不可行的(它需要的时间和内存都太多了),并且还需要超过1000个矩阵的乘积才能得到非常难以捉摸的梯度。这个过程充满了计算与统计的不确定性。
4.1 循环神经网络的梯度分析
简化模型,将时间步
其中
对于反向传播,问题则有点棘手,特别是当计算目标函数
在上式中乘积的第一项和第二项很容易计算,而第三项
为了导出上述梯度,假设我们有三个序列
基于下列公式替换
在公式(4)中的梯度计算满足
虽然可以使用链式法则递归地计算
4.1.1 完全计算
显然,可以仅仅计算公式(7)中的全部总和,然而,这样的计算非常缓慢,并且可能会发生梯度爆炸,因为初始条件的微小变化就可能会对结果产生巨大的影响。也就是说,可以观察到类似于蝴蝶效应的现象,即初始条件的很小变化就会导致结果发生不成比例的变化。这对于想要估计的模型而言是非常不可取的。毕竟,正在寻找的是能够很好地泛化高稳定性模型的估计器。因此,在实践中,这种方法几乎从未使用过。
4.1.2 截断时间步
或者,可以在近似 ,只需将求和终止为
4.1.3 随机截断
最后,可以用一个随机变量替换
从
4.1.4 比较策略
比较RNN中计算梯度的策略,3行自上而下分别为:随机截断、常规截断、完整计算
上图说明了当基于循环神经网络使用通过时间反向传播分析《时间机器》书中前几个字符的三种策略:
第一行采用随机截断,方法是将文本划分为不同长度的片断;
第二行采用常规截断,方法是将文本分解为相同长度的子序列。这也是在循环神经网络实验中一直在做的;
第三行采用通过时间的完全反向传播,结果是产生了在计算上不可行的表达式。
遗憾的是,虽然随机截断在理论上具有吸引力,但很可能是由于多种因素在实践中并不比常规截断更好。首先,在对过去若干个时间步经过反向传播后,观测结果足以捕获实际的依赖关系。其次,增加的方差抵消了时间步数越多梯度越精确的事实。第三,真正想要的是只有短范围交互的模型。因此,模型需要的正是截断的通过时间反向传播方法所具备的轻度正则化效果。
4.2 通过时间反向传播的细节
与循环神经网络的梯度分析不同,下面展示如何计算目标函数相对于所有分解模型参数的梯度。为了保持简单,考虑一个没有偏置参数的循环神经网络,其在隐藏层中的激活函数使用恒等映射(
其中权重参数为
为了在循环神经网络的计算过程中可视化模型变量和参数之间的依赖关系,可以为模型绘制一个计算图,如下图所示。例如,时间步3的隐状态
上图表示具有三个时间步的循环神经网络模型依赖关系的计算图。未着色的方框表示变量,着色的方框表示参数,圆表示运算符
正如刚才所说,上图中的模型参数是
首先,在任意时间步
现在,可以计算目标函数关于输出层中参数
其中
接下来,如上图所示,在最后的时间步
当目标函数
为了进行分析,对于任何时间步
可以从公式(12)中看到,这个简单的线性例子已经展现了长序列模型的一些关键问题:它陷入到
最后,上图表明:目标函数
其中
由于通过时间反向传播是反向传播在循环神经网络中的应用方式,所以训练循环神经网络交替使用前向传播和通过时间反向传播。通过时间反向传播依次计算并存储上述梯度。具体而言,存储的中间值会被重复使用,以避免重复计算,例如存储
“通过时间反向传播”仅仅适用于反向传播在具有隐状态的序列模型。
截断是计算方便性和数值稳定性的需要。截断包括:规则截断和随机截断。
矩阵的高次幂可能导致神经网络特征值的发散或消失,将以梯度爆炸或梯度消失的形式表现。
为了计算的效率,“通过时间反向传播”在计算期间会缓存中间值。
参考
李沐-动手学深度学习第二版