一、深度卷积神经网络(AlexNet)
AlexNet和LeNet的架构非常相似,这里是一个稍微精简版本的AlexNet。
从LeNet(左)到AlexNet(右)
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
AlexNet使用ReLU而不是sigmoid作为其激活函数。
1.1 模型设计
在AlexNet的第一层,卷积窗口的形状是
在最后一个卷积层后有两个全连接层,分别有4096个输出。这两个巨大的全连接层拥有将近1GB的模型参数。由于早期GPU显存有限,原版的AlexNet采用了双数据流设计,使得每个GPU只负责存储和计算模型的一半参数。
1.2 激活函数
此外,AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。相反,ReLU激活函数在正区间的梯度总是1。因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
1.3 容量控制和预处理
AlexNet通过dropout控制全连接层的模型复杂度,而LeNet只使用了权重衰减。为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。这使得模型更健壮,更大的样本量有效地减少了过拟合。
1.4 代码实现
定义模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import torchfrom torch import nnfrom d2l import torch as d2l1 , 96 , kernel_size=11 , stride=4 , padding=1 ), nn.ReLU(),3 , stride=2 ),96 , 256 , kernel_size=5 , padding=2 ), nn.ReLU(),3 , stride=2 ),256 , 384 , kernel_size=3 , padding=1 ), nn.ReLU(),384 , 384 , kernel_size=3 , padding=1 ), nn.ReLU(),384 , 256 , kernel_size=3 , padding=1 ), nn.ReLU(),3 , stride=2 ),6400 , 4096 ), nn.ReLU(),0.5 ),4096 , 4096 ), nn.ReLU(),0.5 ),4096 , 10 ))
查看模型形状
1 2 3 4 X = torch.randn(1 , 1 , 224 , 224 )for layer in net:print (layer.__class__.__name__,'output shape:\t' ,X.shape)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 Conv2d output shape: torch.Size([1, 96, 54, 54])
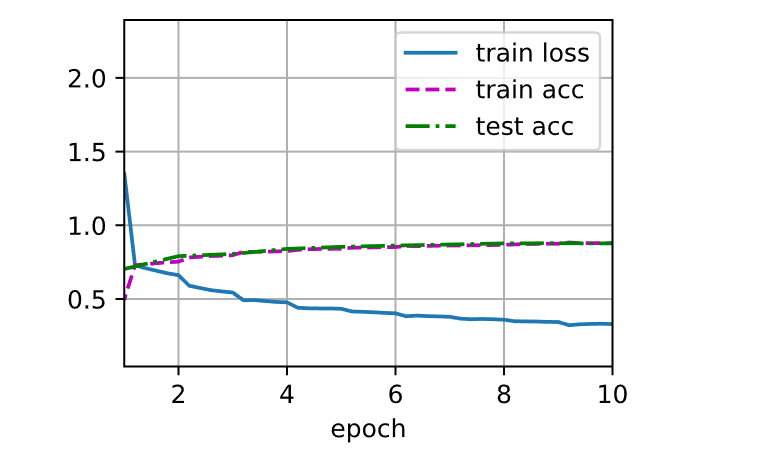
加载数据并训练
1 2 3 4 batch_size = 128 224 )0.01 , 10
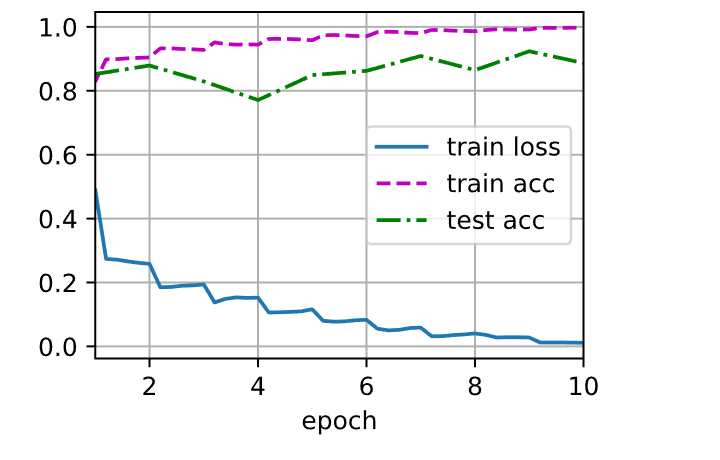
1 2 loss 0.331, train acc 0.879, test acc 0.877
二、VGG
2.1 VGG块
经典卷积神经网络的基本组成部分是下面的这个序列:
带填充以保持分辨率的卷积层;
非线性激活函数,如ReLU;
池化层,如最大池化层。
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大池化层。在最初的VGG论文中使用了带有vgg_block的函数来实现一个VGG块。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import torchfrom torch import nnfrom d2l import torch as d2ldef vgg_block (num_convs, in_channels, out_channels ):for _ in range (num_convs):3 , padding=1 ))2 ,stride=2 ))return nn.Sequential(*layers)
2.2 VGG网络
与AlexNet、LeNet一样,VGG网络可以分为两部分:第一部分主要由卷积层和池化层组成,第二部分由全连接层组成。如图中所示。
VGG神经网络连接的几个VGG块(在vgg_block函数中定义)。其中有超参数变量conv_arch。该变量指定了每个VGG块里卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。
实现VGG
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 conv_arch = ((1 , 64 ), (1 , 128 ), (2 , 256 ), (2 , 512 ), (2 , 512 ))def vgg (conv_arch ):1 for (num_convs, out_channels) in conv_arch:return nn.Sequential(7 * 7 , 4096 ), nn.ReLU(), nn.Dropout(0.5 ),4096 , 4096 ), nn.ReLU(), nn.Dropout(0.5 ),4096 , 10 ))
查看形状
1 2 3 4 X = torch.randn(size=(1 , 1 , 224 , 224 ))for blk in net:print (blk.__class__.__name__,'output shape:\t' ,X.shape)
1 2 3 4 5 6 7 8 9 10 11 12 13 Sequential output shape: torch.Size([1, 64, 112, 112])
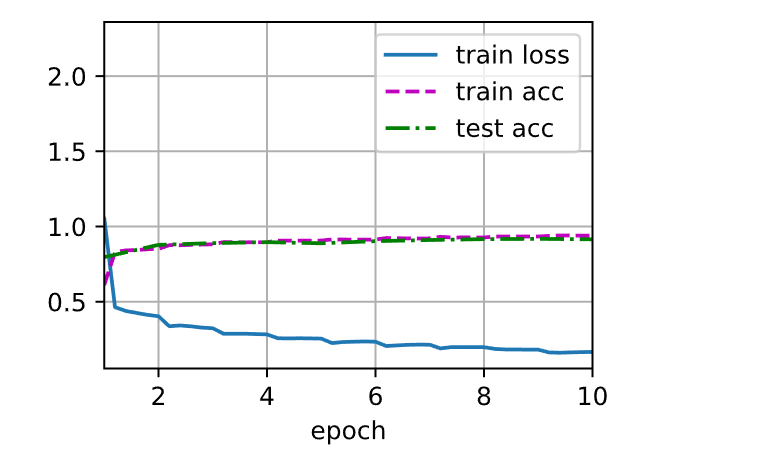
加载数据训练
1 2 3 lr, num_epochs, batch_size = 0.05 , 10 , 128 224 )
1 2 loss 0.166, train acc 0.939, test acc 0.915
三、网络中的网络(NiN)
LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与池化层来提取空间结构特征;然后通过全连接层对特征的表征进行处理。AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块。或者,可以想象在这个过程的早期使用全连接层。然而,如果使用了全连接层,可能会完全放弃表征的空间结构。网络中的网络 (NiN )提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机。
3.1 NiN块
卷积层的输入和输出由四维张量组成,张量的每个轴分别对应样本、通道、高度和宽度。另外,全连接层的输入和输出通常是分别对应于样本和特征的二维张量。NiN的想法是在每个像素位置(针对每个高度和宽度)应用一个全连接层。如果将权重连接到每个空间位置,可以将其视为
下图说明了VGG和NiN及它们的块之间主要架构差异。NiN块以一个普通卷积层开始,后面是两个
对比 VGG 和 NiN
及它们的块之间主要架构差异。
1 2 3 4 5 6 7 8 9 10 11 import torchfrom torch import nnfrom d2l import torch as d2ldef nin_block (in_channels, out_channels, kernel_size, strides, padding ):return nn.Sequential(1 ), nn.ReLU(),1 ), nn.ReLU())
3.2 NiN模型
NiN使用窗口形状为全局平均池化层 (global
average pooling layer),生成一个对数几率
(logits)。NiN设计的一个优点是,它显著减少了模型所需参数的数量。然而,在实践中,这种设计有时会增加训练模型的时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 net = nn.Sequential(1 , 96 , kernel_size=11 , strides=4 , padding=0 ),3 , stride=2 ),96 , 256 , kernel_size=5 , strides=1 , padding=2 ),3 , stride=2 ),256 , 384 , kernel_size=3 , strides=1 , padding=1 ),3 , stride=2 ),0.5 ),384 , 10 , kernel_size=3 , strides=1 , padding=1 ),1 , 1 )),
查看每个块的输出形状
1 2 3 4 X = torch.rand(size=(1 , 1 , 224 , 224 ))for layer in net:print (layer.__class__.__name__,'output shape:\t' , X.shape)
1 2 3 4 5 6 7 8 9 10 Sequential output shape: torch.Size([1, 96, 54, 54])
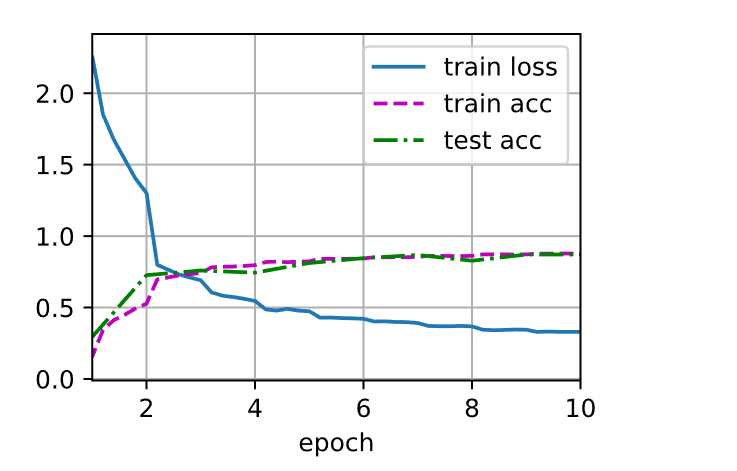
训练模型
1 2 3 lr, num_epochs, batch_size = 0.1 , 10 , 128 224 )
1 2 loss 0.330, train acc 0.877, test acc 0.871
NiN使用由一个卷积层和多个
NiN去除了容易造成过拟合的全连接层,将它们替换为全局平均池化层(即在所有位置上进行求和)。该池化层通道数量为所需的输出数量(例如,Fashion-MNIST的输出为10)。
移除全连接层可减少过拟合,同时显著减少NiN的参数。
四、GoogLeNet
GoogLeNet吸收了NiN中串联网络的思想,并在此基础上做了改进。在GoogLeNet中,基本的卷积块被称为Inception块 (Inception
block)。
4.1 Inception块
Inception块的架构。
Inception块由四条并行路径组成。前三条路径使用窗口大小为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import torchfrom torch import nnfrom torch.nn import functional as Ffrom d2l import torch as d2lself .p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1 )self .p2_1 = nn.Conv2d(in_channels, c2[0 ], kernel_size=1 )self .p2_2 = nn.Conv2d(c2[0 ], c2[1 ], kernel_size=3 , padding=1 )self .p3_1 = nn.Conv2d(in_channels, c3[0 ], kernel_size=1 )self .p3_2 = nn.Conv2d(c3[0 ], c3[1 ], kernel_size=5 , padding=2 )self .p4_1 = nn.MaxPool2d(kernel_size=3 , stride=1 , padding=1 )self .p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1 )def forward (self, x ):self .p1_1(x))self .p2_2(F.relu(self .p2_1(x))))self .p3_2(F.relu(self .p3_1(x))))self .p4_2(self .p4_1(x)))return torch.cat((p1, p2, p3, p4), dim=1 )
4.2 GoogLeNet模型
如下图所示,GoogLeNet一共使用9个Inception块和全局平均池化层的堆叠来生成其估计值。Inception块之间的最大池化层可降低维度。第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均池化层避免了在最后使用全连接层。
GoogLeNet架构。
现在,逐一实现GoogLeNet的每个模块。第一个模块使用64个通道、
1 2 3 b1 = nn.Sequential(nn.Conv2d(1 , 64 , kernel_size=7 , stride=2 , padding=3 ),3 , stride=2 , padding=1 ))
第二个模块使用两个卷积层:第一个卷积层是64个通道、
1 2 3 4 5 b2 = nn.Sequential(nn.Conv2d(64 , 64 , kernel_size=1 ),64 , 192 , kernel_size=3 , padding=1 ),3 , stride=2 , padding=1 ))
第三个模块串联两个完整的Inception块。第一个Inception块的输出通道数为
1 2 3 b3 = nn.Sequential(Inception(192 , 64 , (96 , 128 ), (16 , 32 ), 32 ),256 , 128 , (128 , 192 ), (32 , 96 ), 64 ),3 , stride=2 , padding=1 ))
第四模块更加复杂,它串联了5个Inception块,其输出通道数分别是
1 2 3 4 5 6 b5 = nn.Sequential(Inception(832 , 256 , (160 , 320 ), (32 , 128 ), 128 ),832 , 384 , (192 , 384 ), (48 , 128 ), 128 ),1 ,1 )),1024 , 10 ))
查看输出形状
1 2 3 4 X = torch.rand(size=(1 , 1 , 96 , 96 ))for layer in net:print (layer.__class__.__name__,'output shape:\t' , X.shape)
1 2 3 4 5 6 Sequential output shape: torch.Size([1, 64, 24, 24])
训练模型
1 2 3 lr, num_epochs, batch_size = 0.1 , 10 , 128 96 )
1 2 loss 0.235, train acc 0.911, test acc 0.901
Inception块相当于一个有4条路径的子网络。它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使用
GoogLeNet将多个设计精细的Inception块与其他层(卷积层、全连接层)串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
五、残差网络(ResNet)
5.1 批量规范化层
批量规范化应用于单个可选层(也可以应用到所有层),其原理如下:在每次训练迭代中,首先规范化输入,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。接下来,应用比例系数和比例偏移。正是由于这个基于批量 统计的标准化 ,才有了批量规范化 的名称。
如果尝试使用大小为1的小批量应用批量规范化,将无法学到任何东西。这是因为在减去均值之后,每个隐藏单元将为0。所以,只有使用足够大的小批量,批量规范化这种方法才是有效且稳定的。请注意,在应用批量规范化时,批量大小的选择可能比没有批量规范化时更重要。
从形式上来说,用
其中,拉伸参数 (scale)偏移参数 (shift)
由于在训练过程中,中间层的变化幅度不能过于剧烈,而批量规范化将每一层主动居中,并将它们重新调整为给定的平均值和大小(通过
从形式上来看,我们计算出公式中的
请注意,在方差估计值中添加一个小的常量
另外,批量规范化层在”训练模式“(通过小批量统计数据规范化)和“预测模式”(通过数据集统计规范化)中的功能不同。在训练过程中,无法得知使用整个数据集来估计平均值和方差,所以只能根据每个小批次的平均值和方差不断训练模型。而在预测模式下,可以根据整个数据集精确计算批量规范化所需的平均值和方差。
批量规范化和其他层之间的一个关键区别是,由于批量规范化在完整的小批量上运行,因此不能像以前在引入其他层时那样忽略批量大小。全连接层和卷积层,他们的批量规范化实现略有不同。
5.1.1 全连接层
通常,将批量规范化层置于全连接层中的仿射变换和激活函数之间。设全连接层的输入为x,权重参数和偏置参数分别为
回想一下,均值和方差是在应用变换的”相同”小批量上计算的。
5.1.2 卷积层
同样,对于卷积层,可以在卷积层之后和非线性激活函数之前应用批量规范化。当卷积有多个输出通道时,需要对这些通道的“每个”输出执行批量规范化,每个通道都有自己的拉伸(scale)和偏移(shift)参数,这两个参数都是标量。假设小批量包含
5.1.3 预测过程中的批量规范化
批量规范化在训练模式和预测模式下的行为通常不同。首先,将训练好的模型用于预测时,不再需要样本均值中的噪声以及在微批次上估计每个小批次产生的样本方差了。其次,例如,可能需要使用我们的模型对逐个样本进行预测。一种常用的方法是通过移动平均估算整个训练数据集的样本均值和方差,并在预测时使用它们得到确定的输出。可见,和dropout一样,批量规范化层在训练模式和预测模式下的计算结果也是不一样的。
在模型训练过程中,批量规范化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定。
批量规范化在全连接层和卷积层的使用略有不同。
批量规范化层和dropout层一样,在训练模式和预测模式下计算不同。
批量规范化有许多有益的副作用,主要是正则化。另一方面,”减少内部协变量偏移“的原始动机似乎不是一个有效的解释。
5.2 函数类
首先,假设有一类特定的神经网络架构
那么,怎样得到更近似真正
对于非嵌套函数类,较复杂(由较大区域表示)的函数类不能保证更接近“真”函数(
因此,只有当较复杂的函数类包含较小的函数类时,才能确保提高它们的性能。对于深度神经网络,如果我们能将新添加的层训练成恒等映射 (identity
function)
针对这一问题,何恺明等人提出了残差网络 (ResNet),论文 。残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。于是,残差块 (residual
blocks)便诞生了,这个设计对如何建立深层神经网络产生了深远的影响。
5.3 残差块
如下图所示,假设原始输入为残差块 (residual
block)。在残差块中,输入可通过跨层数据线路更快地向前传播。
一个正常块(左图)和一个残差块(右图)。
ResNet沿用了VGG完整的
残差块的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import torchfrom torch import nnfrom torch.nn import functional as Ffrom d2l import torch as d2lclass Residual (nn.Module):def __init__ (self, input_channels, num_channels, use_1x1conv=False , strides=1 ):super ().__init__()self .conv1 = nn.Conv2d(input_channels, num_channels,3 , padding=1 , stride=strides)self .conv2 = nn.Conv2d(num_channels, num_channels,3 , padding=1 )if use_1x1conv:self .conv3 = nn.Conv2d(input_channels, num_channels,1 , stride=strides)else :self .conv3 = None self .bn1 = nn.BatchNorm2d(num_channels) self .bn2 = nn.BatchNorm2d(num_channels)def forward (self, X ):self .bn1(self .conv1(X)))self .bn2(self .conv2(Y))if self .conv3:self .conv3(X)return F.relu(Y)
如下图所示,此代码生成两种类型的网络:一种是当use_1x1conv=False时,应用ReLU非线性函数之前,将输入添加到输出。另一种是当use_1x1conv=True时,添加通过
包含以及不包含
下面来查看[输入和输出形状一致 ]的情况。
1 2 3 4 blk = Residual(3 ,3 )4 , 3 , 6 , 6 )
1 torch.Size([4, 3, 6, 6])
也可以在[增加输出通道数的同时,减半输出的高和宽 ]。
1 2 blk = Residual(3 ,6 , use_1x1conv=True , strides=2 )
1 torch.Size([4, 6, 3, 3])
5.4 ResNet模型
ResNet的前两层跟之前介绍的GoogLeNet中的一样:在输出通道数为64、步幅为2的
1 2 3 b1 = nn.Sequential(nn.Conv2d(1 , 64 , kernel_size=7 , stride=2 , padding=3 ),64 ), nn.ReLU(),3 , stride=2 , padding=1 ))
GoogLeNet在后面接了4个由Inception块组成的模块。ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为2的最大池化层,所以无须减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
1 2 3 4 5 6 7 8 9 10 def resnet_block (input_channels, num_channels, num_residuals, first_block=False ):for i in range (num_residuals):if i == 0 and not first_block:True , strides=2 ))else :return blk
接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
1 2 3 4 b2 = nn.Sequential(*resnet_block(64 , 64 , 2 , first_block=True ))64 , 128 , 2 ))128 , 256 , 2 ))256 , 512 , 2 ))
最后,与GoogLeNet一样,在ResNet中加入全局平均池化层,以及全连接层输出。
1 2 3 net = nn.Sequential(b1, b2, b3, b4, b5,1 ,1 )),512 , 10 ))
每个模块有4个卷积层(不包括恒等映射的
ResNet-18 架构
在训练ResNet之前,[观察一下ResNet中不同模块的输入形状是如何变化的 ]。在之前所有架构中,分辨率降低,通道数量增加,直到全局平均池化层聚集所有特征。
1 2 3 4 X = torch.rand(size=(1 , 1 , 224 , 224 ))for layer in net:print (layer.__class__.__name__,'output shape:\t' , X.shape)
1 2 3 4 5 6 7 8 Sequential output shape: torch.Size([1, 64, 56, 56])
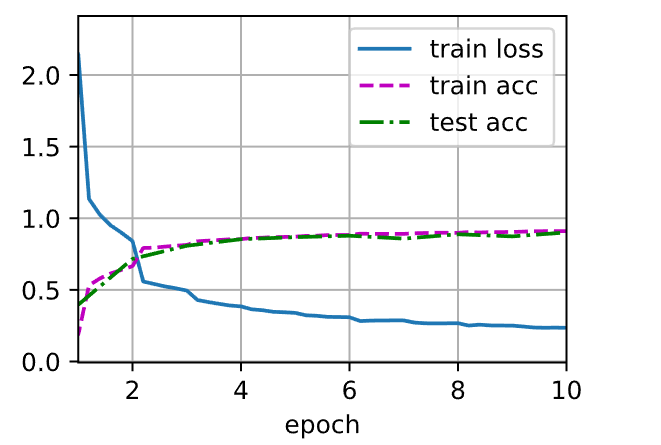
训练模型
1 2 3 lr, num_epochs, batch_size = 0.05 , 10 , 256 96 )
1 2 loss 0.012, train acc 0.997, test acc 0.887
学习嵌套函数(nested
function)是训练神经网络的理想情况。在深层神经网络中,学习另一层作为恒等映射(identity
function)较容易(尽管这是一个极端情况)。
残差映射可以更容易地学习同一函数,例如将权重层中的参数近似为零。
利用残差块(residual
blocks)可以训练出一个有效的深层神经网络:输入可以通过层间的残余连接更快地向前传播
六、稠密连接网络(DenseNet)
6.1 从ResNet到DenseNet
回想一下任意函数的泰勒展开式(Taylor
expansion),它把这个函数分解成越来越高阶的项。在
同样,ResNet将函数展开为
也就是说,ResNet将
ResNet(左)与
DenseNet(右)在跨层连接上的主要区别:使用相加和使用连结
如上图所示,ResNet和DenseNet的关键区别在于,DenseNet输出是连接 (用图中的
最后,将这些展开式结合到多层感知机中,再次减少特征的数量。实现起来非常简单:不需要添加术语,而是将它们连接起来。DenseNet这个名字由变量之间的“稠密连接”而得来,最后一层与之前的所有层紧密相连。稠密连接如下图所示。
稠密连接
稠密网络主要由2部分构成:稠密块 (dense
block)和过渡层 (transition
layer)。前者定义如何连接输入和输出,而后者则控制通道数量,使其不会太复杂。
6.2 稠密块体
DenseNet使用了ResNet改良版的“批量规范化、激活和卷积”架构。首先实现一下这个架构。
1 2 3 4 5 6 7 8 9 import torchfrom torch import nnfrom d2l import torch as d2ldef conv_block (input_channels, num_channels ):return nn.Sequential(3 , padding=1 ))
一个稠密块由多个卷积块组成,每个卷积块使用相同数量的输出通道。
然而,在前向传播中,将每个卷积块的输入和输出在通道维上连结。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class DenseBlock (nn.Module):def __init__ (self, num_convs, input_channels, num_channels ):super (DenseBlock, self ).__init__()for i in range (num_convs):self .net = nn.Sequential(*layer)def forward (self, X ):for blk in self .net:1 )return X
[定义一个 ]有2个输出通道数为10的(DenseBlock增长率 (growth
rate)。
1 2 3 4 blk = DenseBlock(2 , 3 , 10 )4 , 3 , 8 , 8 )
1 torch.Size([4, 23, 8, 8])
6.3 过渡层
由于每个稠密块都会带来通道数的增加,使用过多则会过于复杂化模型。而过渡层可以用来控制模型复杂度。它通过
1 2 3 4 5 def transition_block (input_channels, num_channels ):return nn.Sequential(1 ),2 , stride=2 ))
对上一个例子中稠密块的输出[使用 ]通道数为10的[过渡层 ]。此时输出的通道数减为10,高和宽均减半。
1 2 blk = transition_block(23 , 10 )
1 torch.Size([4, 10, 4, 4])
6.4 DenseNet模型
构造DenseNet模型。DenseNet首先使用同ResNet一样的单卷积层和最大池化层。
1 2 3 4 b1 = nn.Sequential(1 , 64 , kernel_size=7 , stride=2 , padding=3 ),64 ), nn.ReLU(),3 , stride=2 , padding=1 ))
接下来,类似于ResNet使用的4个残差块,DenseNet使用的是4个稠密块。与ResNet类似,可以设置每个稠密块使用多少个卷积层。这里设成4,从而与ResNet-18保持一致。稠密块里的卷积层通道数(即增长率)设为32,所以每个稠密块将增加128个通道。在每个模块之间,ResNet通过步幅为2的残差块减小高和宽,DenseNet则使用过渡层来减半高和宽,并减半通道数。
1 2 3 4 5 6 7 8 9 10 11 12 64 , 32 4 , 4 , 4 , 4 ]for i, num_convs in enumerate (num_convs_in_dense_blocks):if i != len (num_convs_in_dense_blocks) - 1 :2 ))2
与ResNet类似,最后接上全局汇聚层和全连接层来输出结果。
1 2 3 4 5 6 net = nn.Sequential(1 , 1 )),10 ))
模型训练
1 2 3 lr, num_epochs, batch_size = 0.1 , 10 , 256 96 )
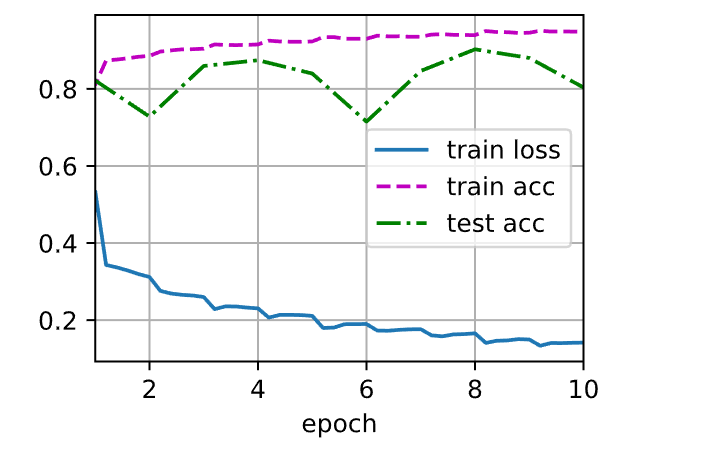
1 2 loss 0.142, train acc 0.948, test acc 0.803
!
在跨层连接上,不同于ResNet中将输入与输出相加,稠密连接网络(DenseNet)在通道维上连结输入与输出。
DenseNet的主要构建模块是稠密块和过渡层。
在构建DenseNet时,需要通过添加过渡层来控制网络的维数,从而再次减少通道的数量。
参考
李沐-动手学深度学习第二版











{kind=link}