多模态大型语言模型(MLLM)
一、简介
- 模态的定义:模态(modal)是事情经历和发生的方式,我们生活在一个由多种模态(Multimodal)信息构成的世界,包括视觉信息、听觉信息、文本信息、嗅觉信息等等。
- MLLMs 的定义:由LLM扩展而来的具有接收与推理多模态信息能力的模型。
- 多种模型概念:
- 单模态大模型
- 跨模态模型
- 多模态模型
- 多模态语言大模型
1.1 单模态大模型
单模态大模型是指模型输入和输出是同一种模态,例如大语言模型(LLM)是文本模态。还有一种视觉大模型(LVM),输入输出视觉信号,例如下图:

1.2 跨模态模型
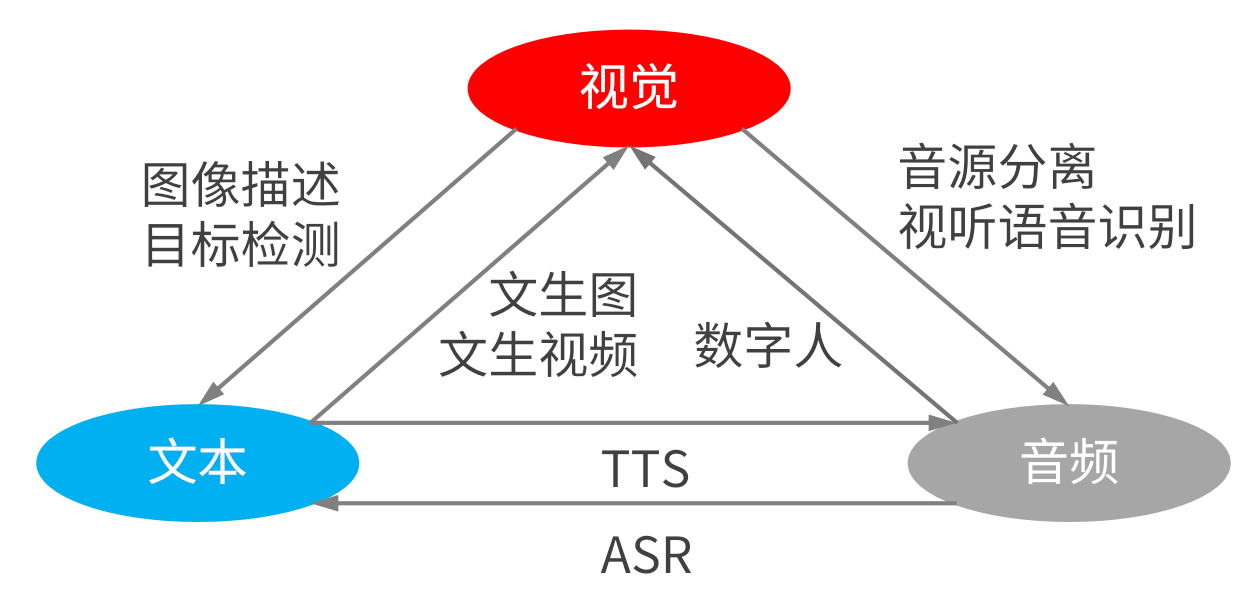
跨模态是指模型输入和输出为不同模态,如文生图,文生视频,文转语音,语音转文字等等,如上图。
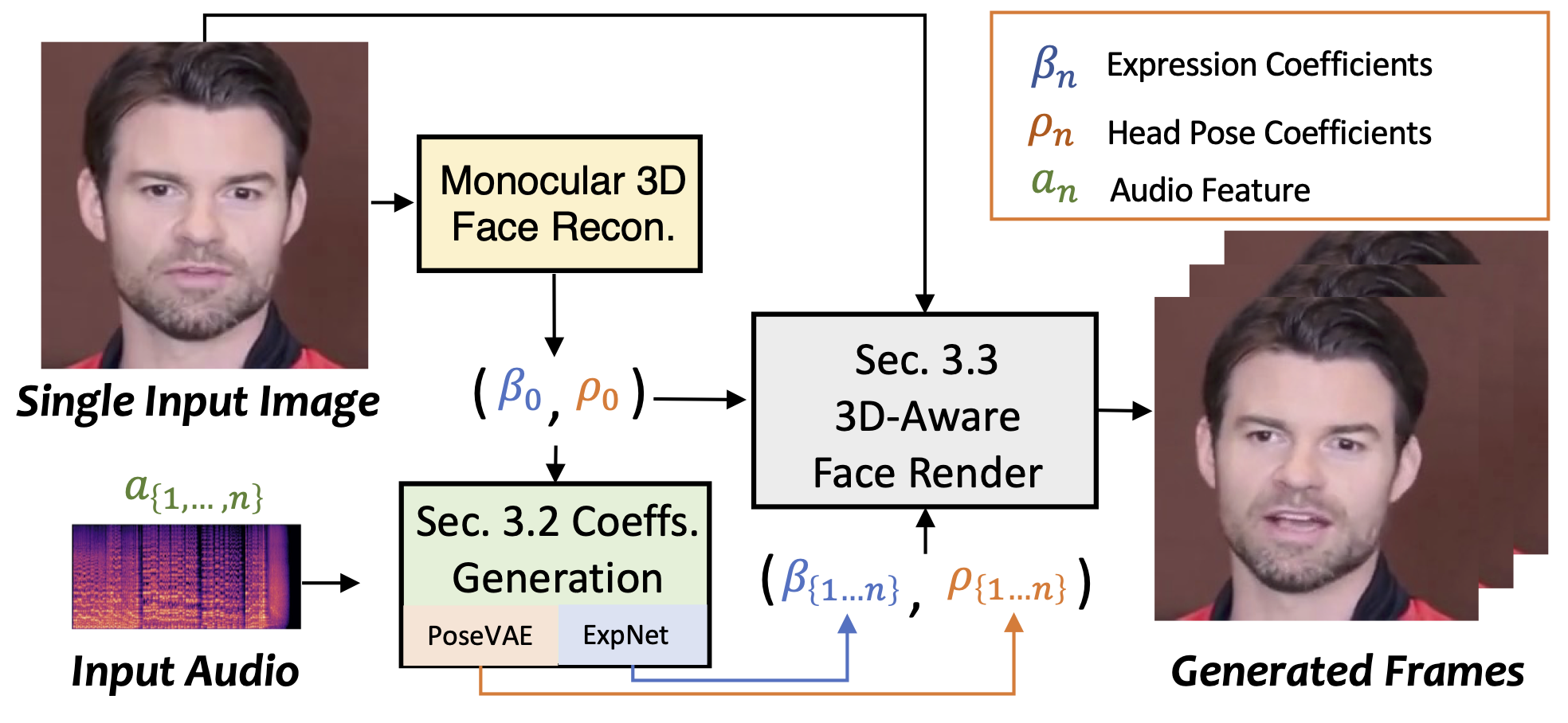
- SadTalker:单张肖像图像 + 音频 = 头部特写视频(https://github.com/OpenTalker/SadTalker)
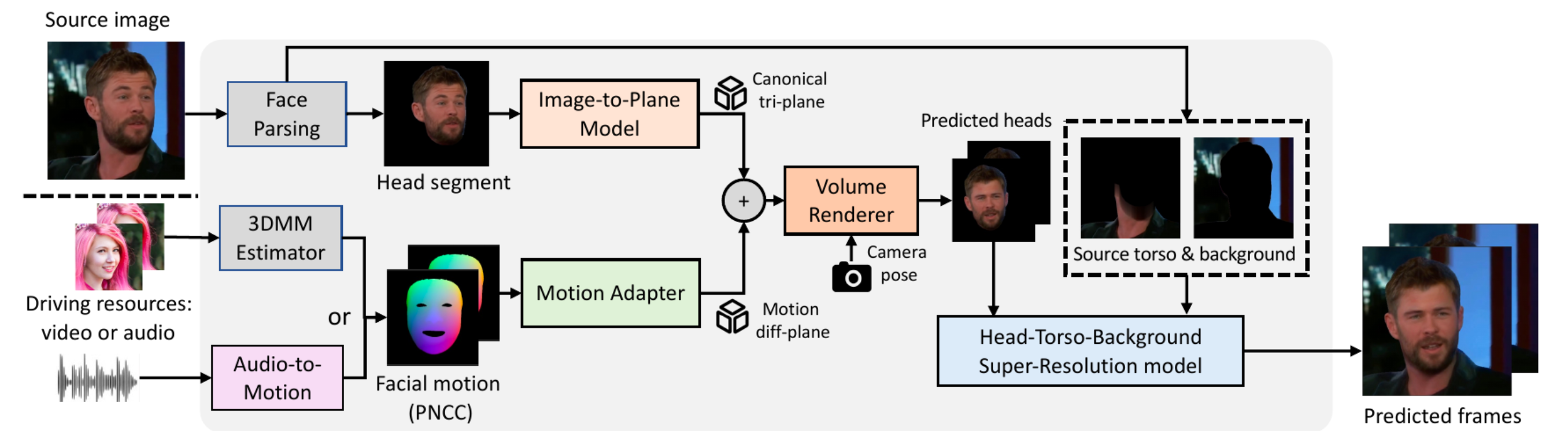
Real3D-Portrait: 用于实现单参考图(one-shot)、高视频真实度(video reality)的虚拟人视频合成。(https://github.com/yerfor/Real3DPortrait)
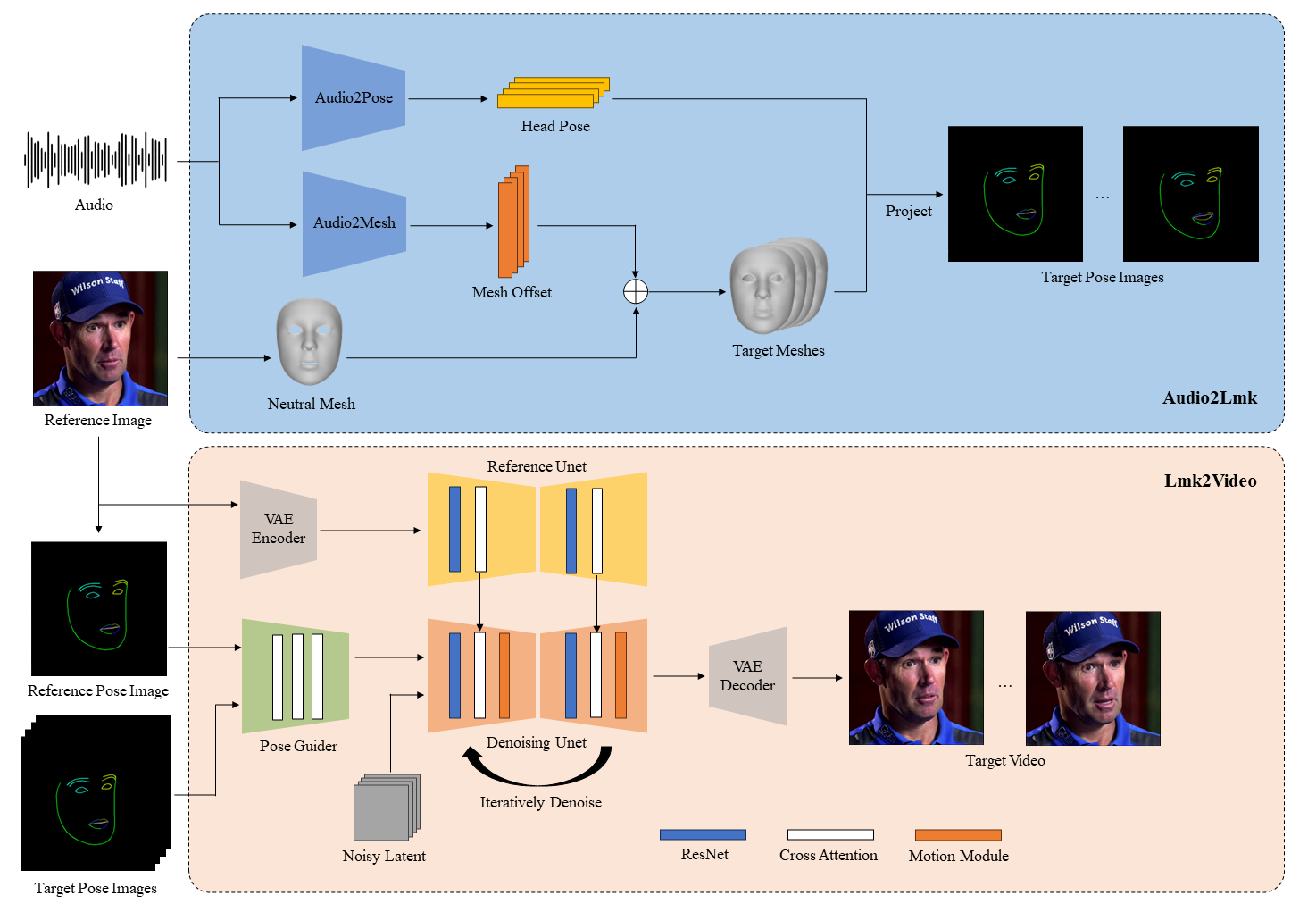
AniPortrait:音频驱动的真实肖像动画合成
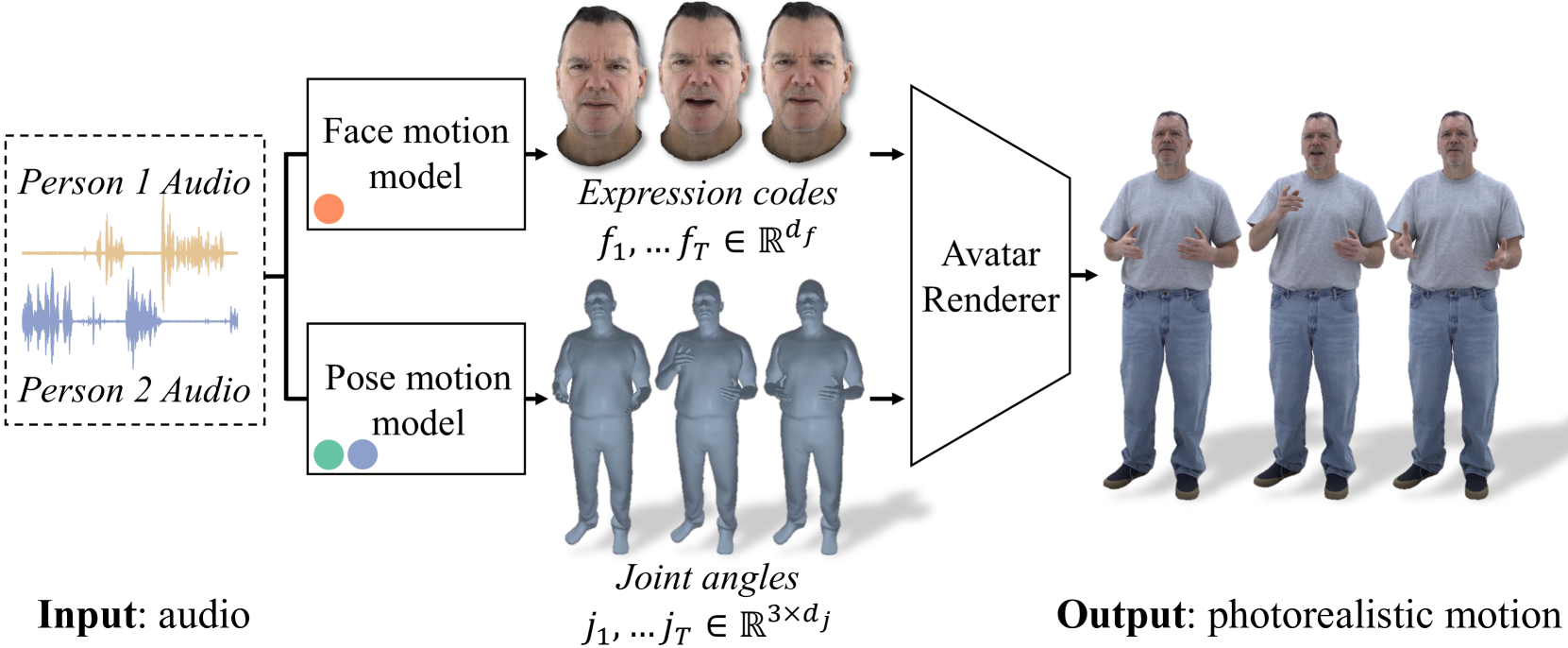
- Audio2Photoreal:将对话音频作为输入并生成相应的面部代码和身体手部姿势。然后,输出姿势被输入到经过训练的头像渲染器中,生成逼真的视频。(https://github.com/facebookresearch/audio2photoreal)
TTS:TTS(Text-To-Speech)这是一种文字转语音的语音合成。
- GPT-SoVITS:(https://github.com/RVC-Boss/GPT-SoVITS)
- 零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
- 少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
- 跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
- WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
- ChatTTS:(https://github.com/2noise/ChatTTS)
- 对话式 TTS: ChatTTS针对对话式任务进行了优化,实现了自然流畅的语音合成,同时支持多说话人。
- 细粒度控制: 该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。
- 更好的韵律: ChatTTS在韵律方面超越了大部分开源TTS模型。同时提供预训练模型,支持进一步的研究。
- SpeedTTS:(https://bytedancespeech.github.io/seedtts_tech_report/)
- Seed-TTS,这是一系列大规模自回归文本转语音 (TTS) 模型,能够生成与人类语音几乎没有区别的语音。
- Seed-TTS 作为语音生成的基础模型,在语音上下文学习方面表现出色,在说话者相似度和自然度方面的表现在客观和主观评估方面都与真实的人类语音相匹配
- Seed-TTS 对各种语音属性(例如情感)具有出色的可控性,并且能够为自然界的说话者生成极具表现力和多样性的语音
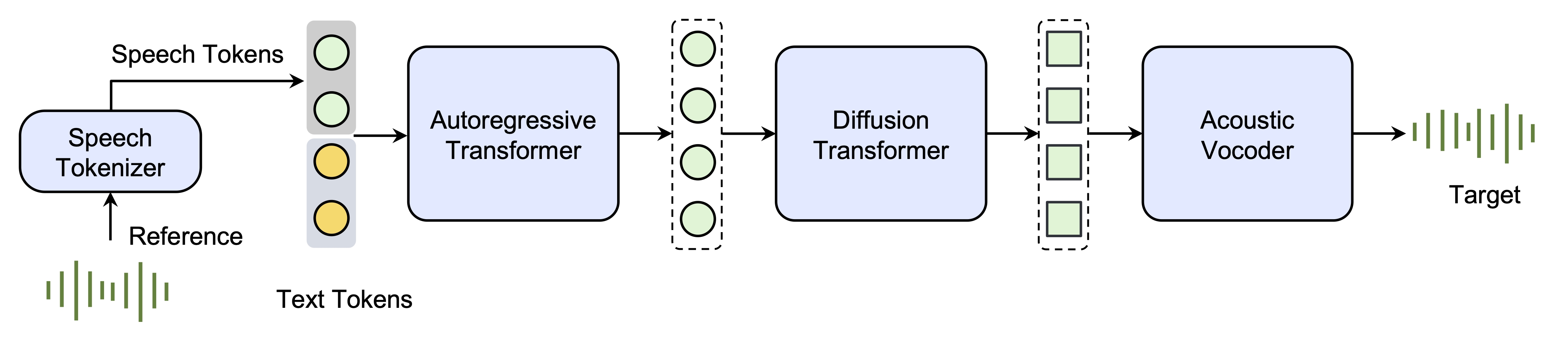
Seed-TTS 推理概述。 (1) 语音token器从参考语音中学习token。 (2)自回归语言模型根据条件文本和语音生成语音token。 (3) 扩散变换器模型以从粗到细的方式生成给定生成的语音token的连续语音表示。 (4) 声学声码器从扩散输出中产生更高质量的语音。
- GPT-SoVITS:(https://github.com/RVC-Boss/GPT-SoVITS)
Suno:从文本或歌词 -> 音乐生成(https://suno.com/)
1.3 多模态模型
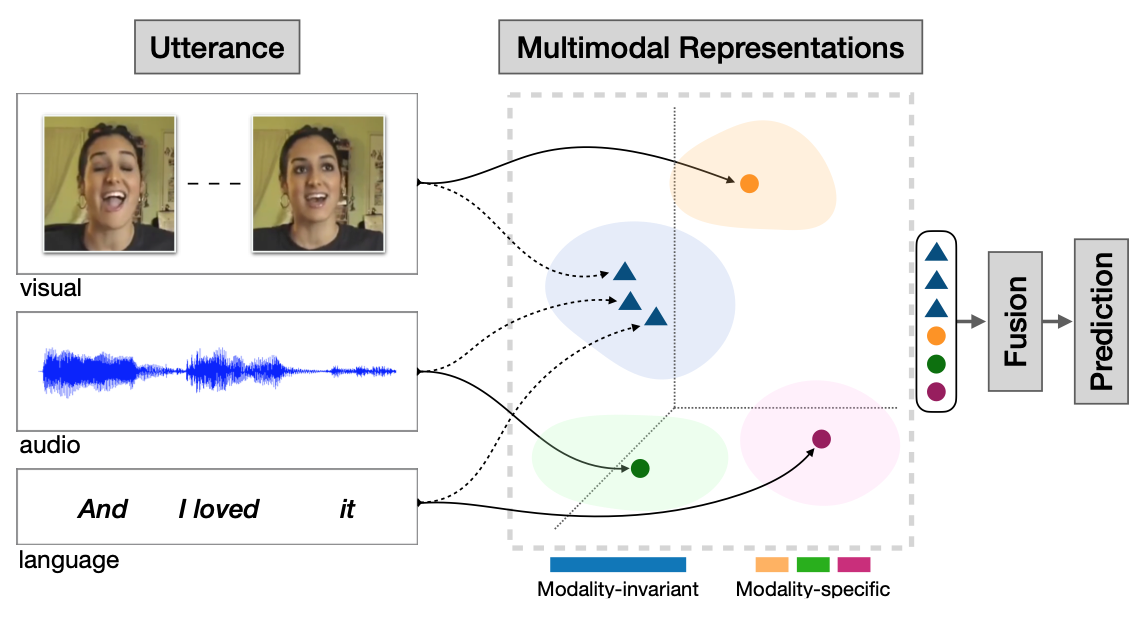
多模态机器学习是从多种模态的数据中学习并且提升自身的算法,它不是某一个具体的算法,它是一类算法的总称。
从语义感知的角度切入,多模态数据涉及不同的感知通道如视觉、听觉、触觉、嗅觉所接收到的信息;在数据层面理解,多模态数据则可被看作多种数据类型的组合,如图片、数值、文本、符号、音频、时间序列,或者集合、树、图等不同数据结构所组成的复合数据形式,乃至来自不同数据库、不同知识库的各种信息资源的组合。对多源异构数据的挖掘分析可被理解为多模态学习。
1.4 多模态大预言模型
由LLM扩展而来的具有接收与推理多模态信息能力的模型。
二、多模态模型的发展历程(图-文)
2.1 Vision Transformer (ViT)模型 [1]
Vision Transformer(ViT)的模型框架。简单而言,模型由三个模块组成:
Linear Projection of Flattened Patches(Embedding层)
Transformer Encoder
MLP Head(最终用于分类的层结构)

将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到[16, 16, 3] -> [768]
在代码实现中,直接通过一个卷积层来实现。
以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
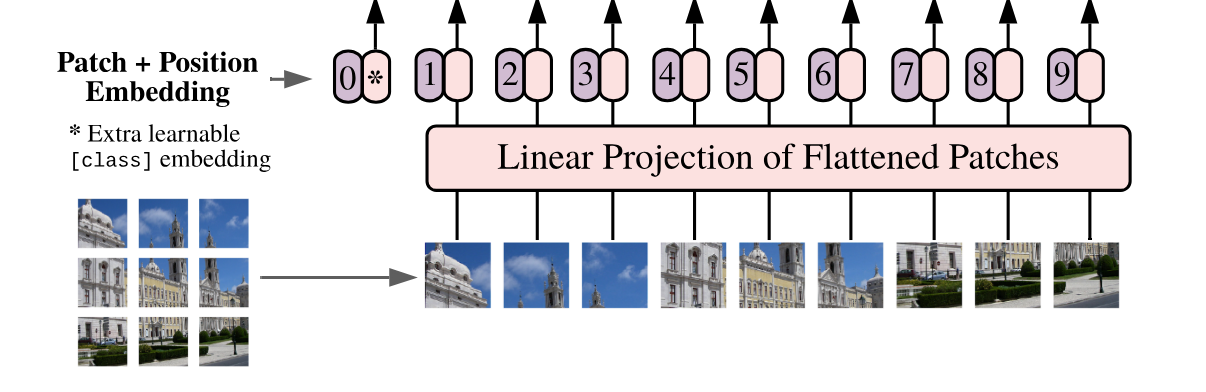
在输入Transformer Encoder之前注意需要加上[class]token以及Position
Embedding。
在原论文中,作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,Cat([1, 768], [196, 768]) -> [197, 768]。然后关于Position
Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position
Embedding采用的是一个可训练的参数(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197,
768],那么这里的Position
Embedding的shape也是[197, 768]。
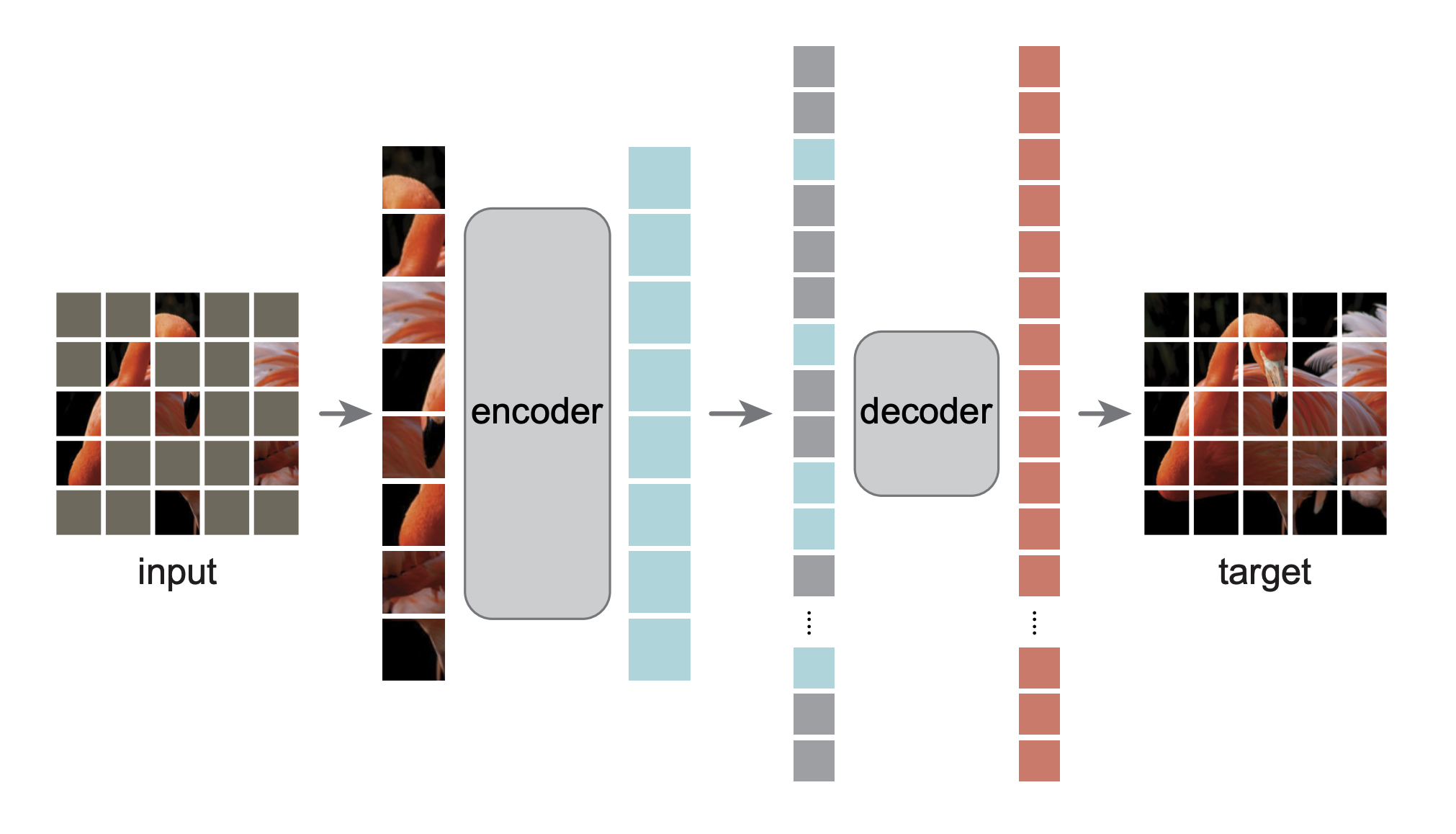
- Mask Image Modeling 无监督图像特征学习 [2]
2.2 基于Transformer架构的图像-文本联合建模
以VisualBert [3] 为例,VisualBert核心是重用 Transformer 中的自注意力机制来隐式对齐输入文本的元素和输入图像中的区域。
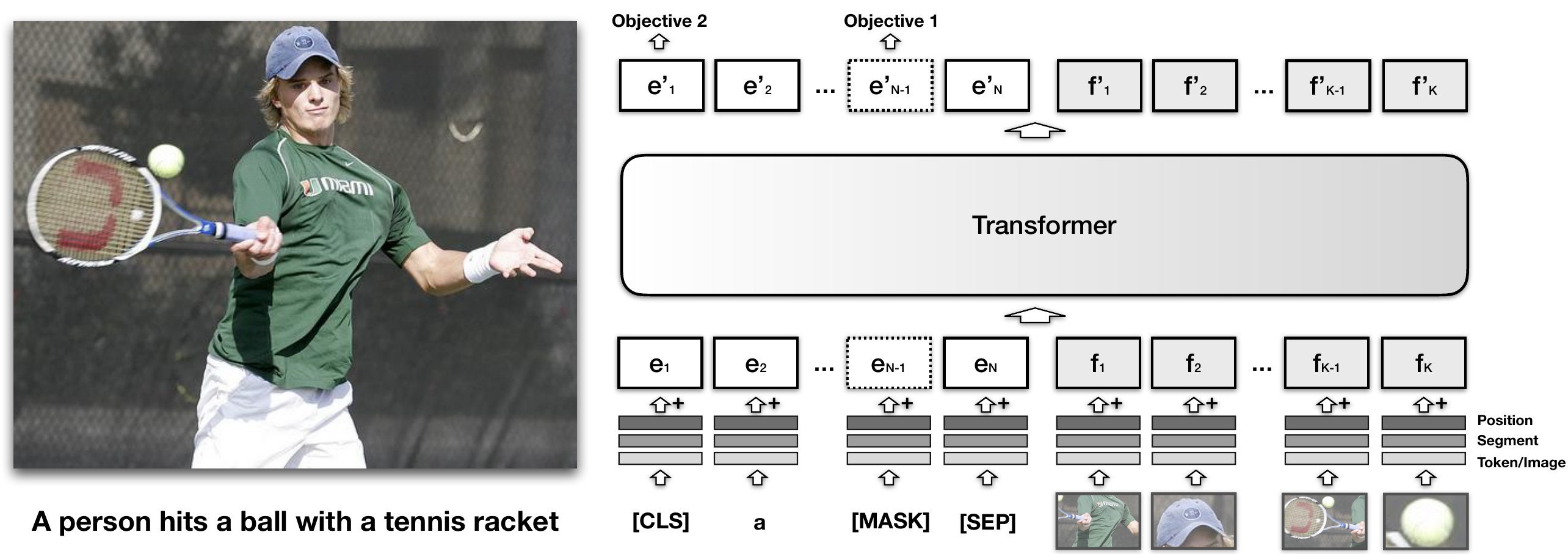
两种训练视觉语言模型的预训练任务:
一部分文本被mask掉,根据剩余的文本和图像信息来预测被mask掉的信息。
模型来预测提供的文本是否和图片匹配。作者发现这种在图片标注数据上的预训练对于visualBert 学习文本和图像的表征非常重要。
文本向量 输入句子中的所有子词都映射到一组嵌入
- token embedding
,特定的token - segment embedding
,指示token来自文本的哪一部分(the hypothesis from an entailment pair) - position embedding
,指示token在句子中的位置
图像向量 视觉嵌入
:由卷积神经网络计算得出的 边界区域的视觉特征表示 :图像segment embedding,不是文本segment embedding :position embedding,在对齐时使用单词和边界区域之间的值作为输入的一部分提供,并设置为与对齐单词相对应的位置嵌入的总和
训练遵循以下3个过程: 1. Task-Agnostic Pre-Training:这里,根据前面提到的目标,在 COCO 数据集上对 VisualBERT 进行训练。在此阶段,模型学习区分实际图像标题和一些随机标题。 2. Task-Specific Pre-Training:这涉及使用预训练的权重在具有屏蔽文本的特定于任务的数据集上训练模型。 3. Fine-tuning:包括根据要求对transformer进行特定目标、输入和输出的培训。
2.3 大规模 图-文 Token对齐模型
2.3.1 CLIP [4]
CLIP模型特点:
统一的向量空间:CLIP的一个关键创新是将图像和文本都映射到同一个向量空间中。这使得模型能够直接在向量空间中计算图像和文本之间的相似性,而无需额外的中间表示。
对比学习:CLIP使用对比学习的方式进行预训练。模型被要求将来自同一个样本的图像和文本嵌入映射到相近的位置,而将来自不同样本的嵌入映射到较远的位置。这使得模型能够学习到图像和文本之间的共同特征。
无监督学习:CLIP的预训练是无监督的,这意味着它不需要大量标注数据来指导训练。它从互联网上的文本和图像数据中学习,使得它在各种领域的任务上都能够表现出色。
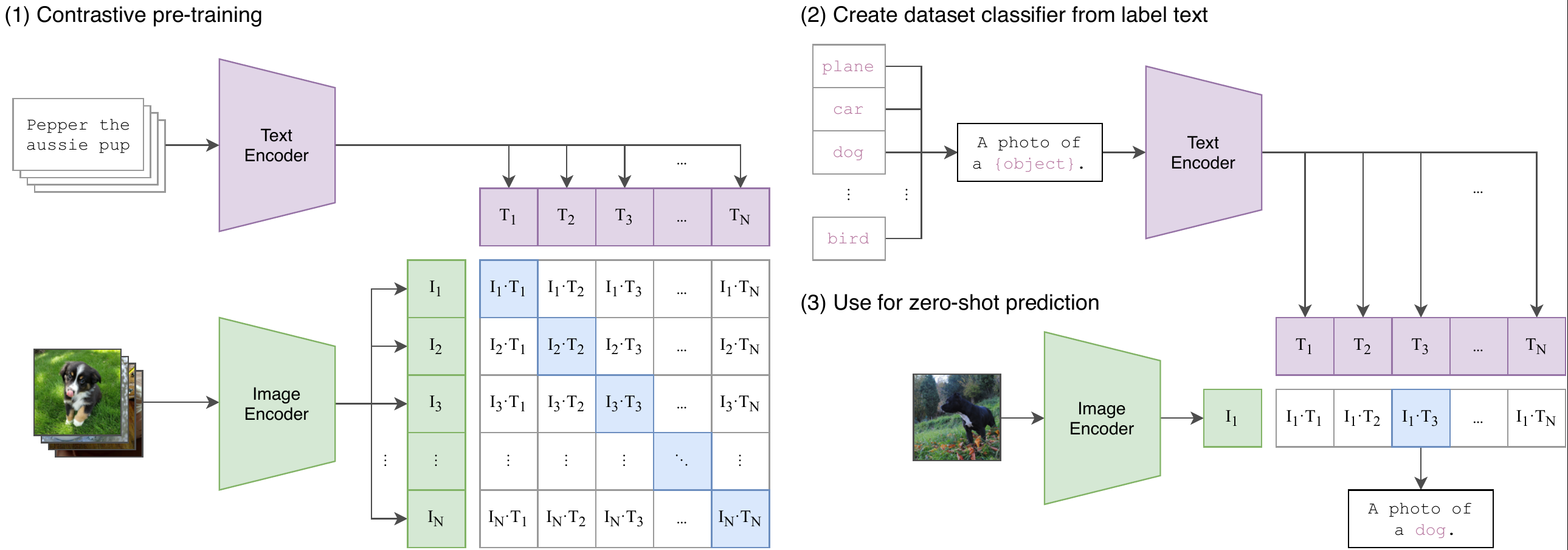
CLIP模型训练分为三个阶段:
- Contrastive pre-training:预训练阶段,使用图片 - 文本对进行对比学习训练;
- Create dataset classifier from label text:提取预测类别文本特征;
- Use for zero-shot predictiion:进行 Zero-Shoot 推理预测;
阶段1:Contrastive pre-training
在预训练阶段,对比学习十分灵活,只需要定义好正样本对和负样本对就行了,其中能够配对的图片-文本对即为正样本。具体来说,先分别对图像和文本提特征,这时图像对应生成
阶段2:Create dataset classifier from label text 基于400M数据上学得的先验,仅用数据集的标签文本,就可以得到很强的图像分类性能。现在训练好了,然后进入前向预测阶段,通过 prompt label text 来创建待分类的文本特征向量。 阶段3:Use for zero-shot predictiion 最后就是推理见证效果的时候,对于测试图片,选择相似度最大的那个类别输出。在推理阶段,无论来了张什么样的图片,只要扔给 Image Encoder 进行特征提取,会生成一个一维的图片特征向量,然后拿这个图片特征和 N 个文本特征做余弦相似度对比,最相似的即为想要的那个结果,比如这里应该会得到 “A photo of a guacamole.”
Chinese-CLIP:https://github.com/OFA-Sys/Chinese-CLIP
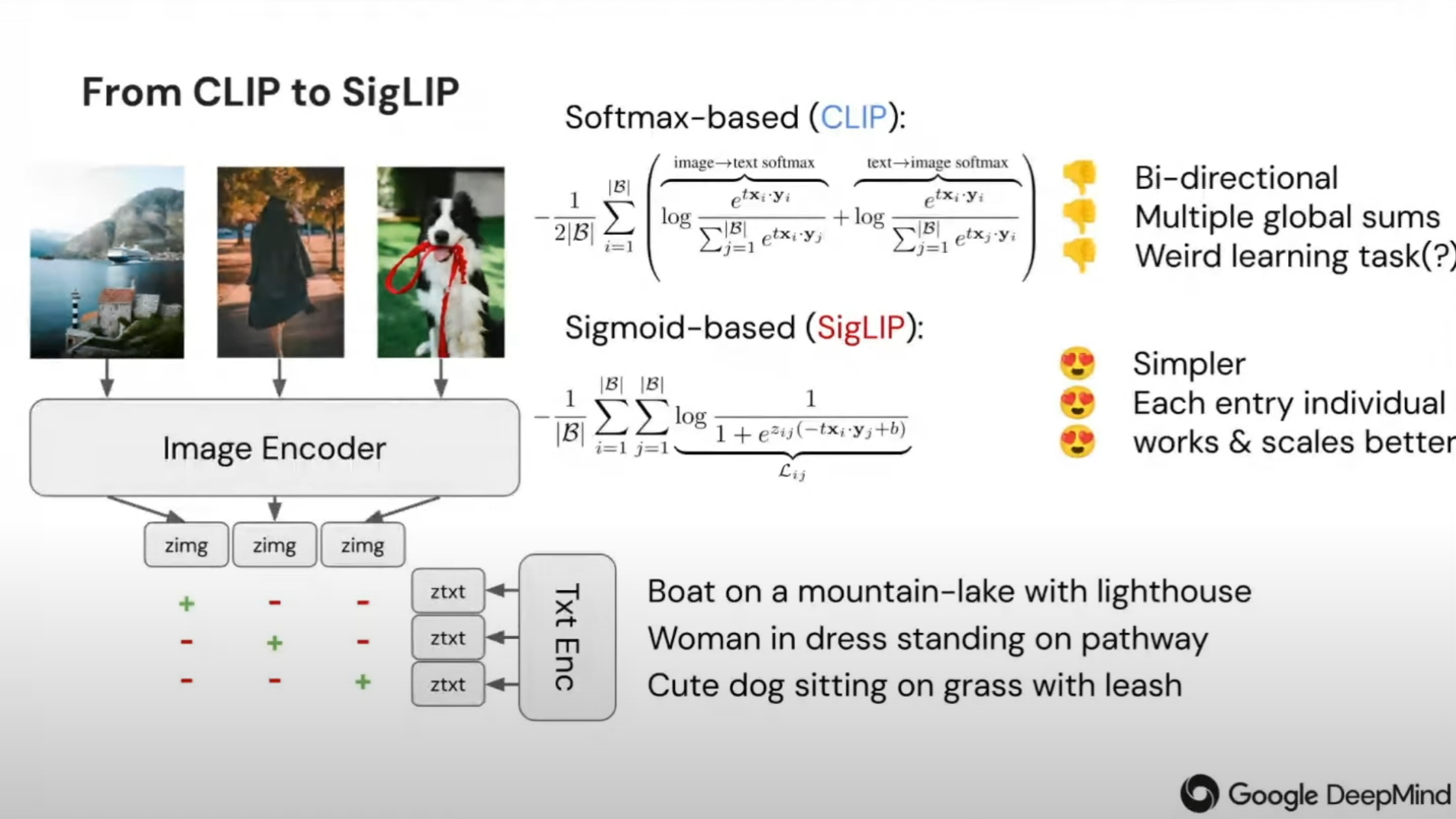
2.3.2 SigLIP [5]
SigLIP是一种与 CLIP 类似的图像嵌入模模型,它跟CLIP的主要区别在于其训练损失。SigLIP采用成对Sigmoid损失,允许模型独立地对每个图像-文本对进行操作,而无需对批次中的所有对进行全局查看。这种损失函数是在文字Tokens和图像Tokens的两个序列的基础上计算出来的,它指导模型训练朝着相同样本对(图,文)的点积值越大,而不同图文对的点积值越小的目标迈迈进。这种设计解决了CLIP训练中InfoNCE Loss里的softmax导致的存储问题,提高了训练效率。
2.3.3 开域(Open Set)下的图像分类-目标检测-图像分割
Open Set问题指的是在分类任务中,系统需要能够识别已知类别(Known Classes),同时还能够识别未知类别(Unknown Classes)。在实际应用中,往往会出现一些未见过的类别或样本,而传统的分类模型往往只能识别已知的类别,无法判断未知类别,这就是Open Set问题。
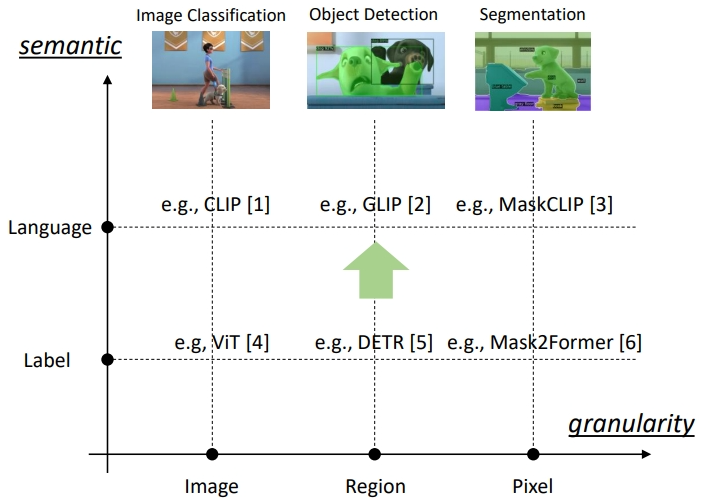
GLIP:Grounded Language-Image Pre-training MaskCLIP: Masked Self-Distillation Advances Contrastive Language-Image Pretraining DETR:End-to-End Object Detection with Transformers Mask2Former:Masked-attention Mask Transformer for Universal Image Segmentation
2.3.4 文生图任务的复兴
Open Set促进文生图发展。
2.4 多模态大语言模型
2.4.1 GPT4v [6]
支持图-文交替输出,不支持视频,但支持含多张图像的序列输入
输入:可以接收文本、图像信息输入 输出:自然语言文本

- 特性一:遵循文字提示
- 特性二:理解视觉指向和参考
- 特性三:支持视觉+文本联合提示
- 特性四:少样本上下文学习
- 特性五:强大的视觉认知能力
- 特性六:时序视觉信号理解
GPT4-o
输入:可以接收文本、语音、图像、视频信息输入 输出:自然语言、语音、图像、视频(未开放)
2.4.2 Gemini [7]
输入:可以接收文本、语音、图像、视频信息输入 输出:自然语言文本、图像
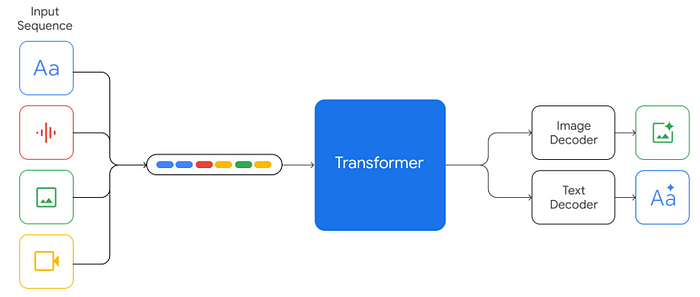
- 特性一:支持多模态内容输出
- 特性二:复杂图像理解与代码生成
2.5 多模态大语言模型的应用
2.5.1 工业
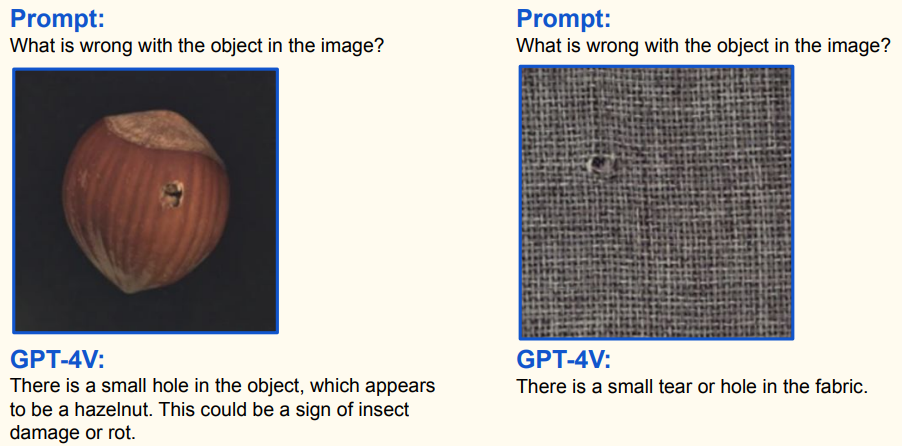
2.5.2 医疗
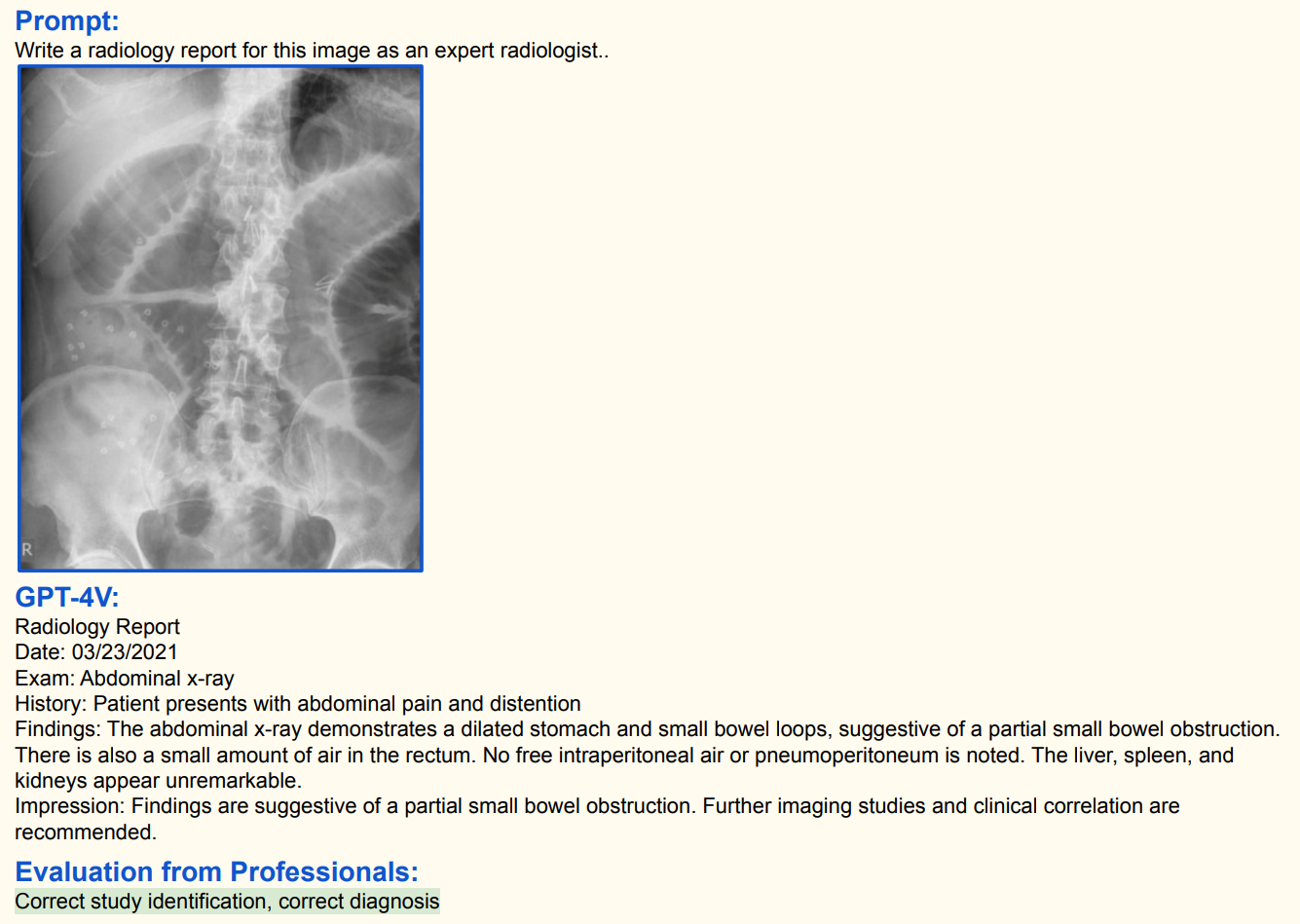
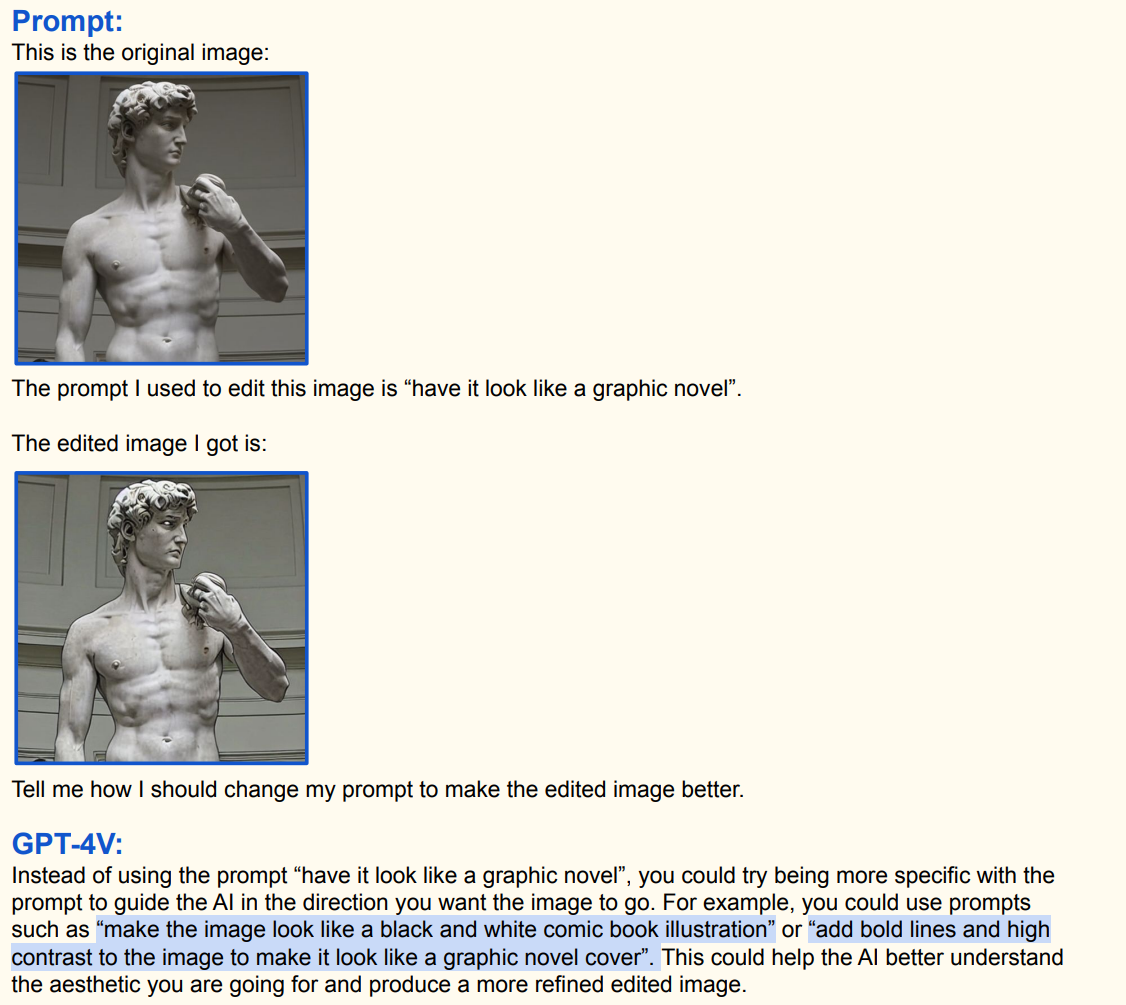
2.5.3 视觉内容认知与编辑

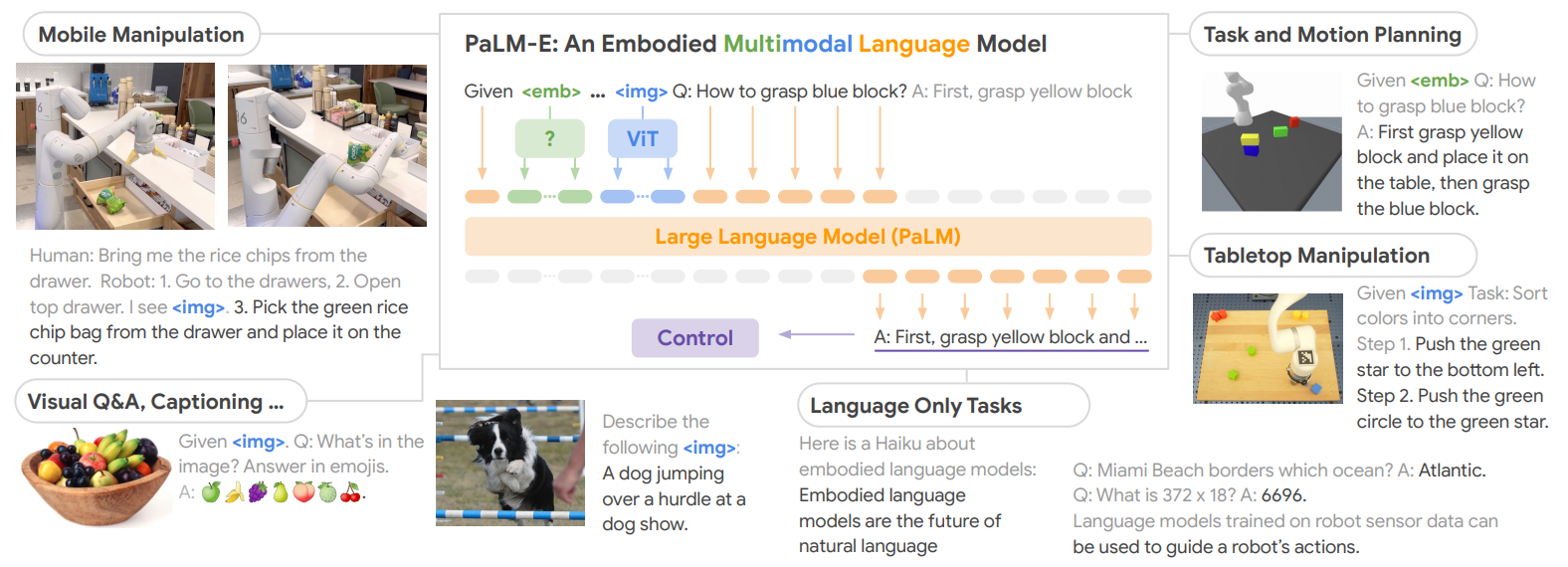
2.5.4 具身智能
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances PaLM-E: An Embodied Multimodal Language Model GitHub:Do As I Can, Not As I Say
2.5.5 新一代人机交互
Self-Operating Computer: https://github.com/OthersideAI/self-operating-computer
三、LLaVA–多模态大语言模型的训练过程
LLaVA 这里使用的 adaper 就是最简单的 linear 线性映射,采用 CLIP 的 ViT-L/14 作为 visual encoder,采用 Vicuna(LLaMa 的一个 SFT 指令微调版本) 作为基座 LLM。
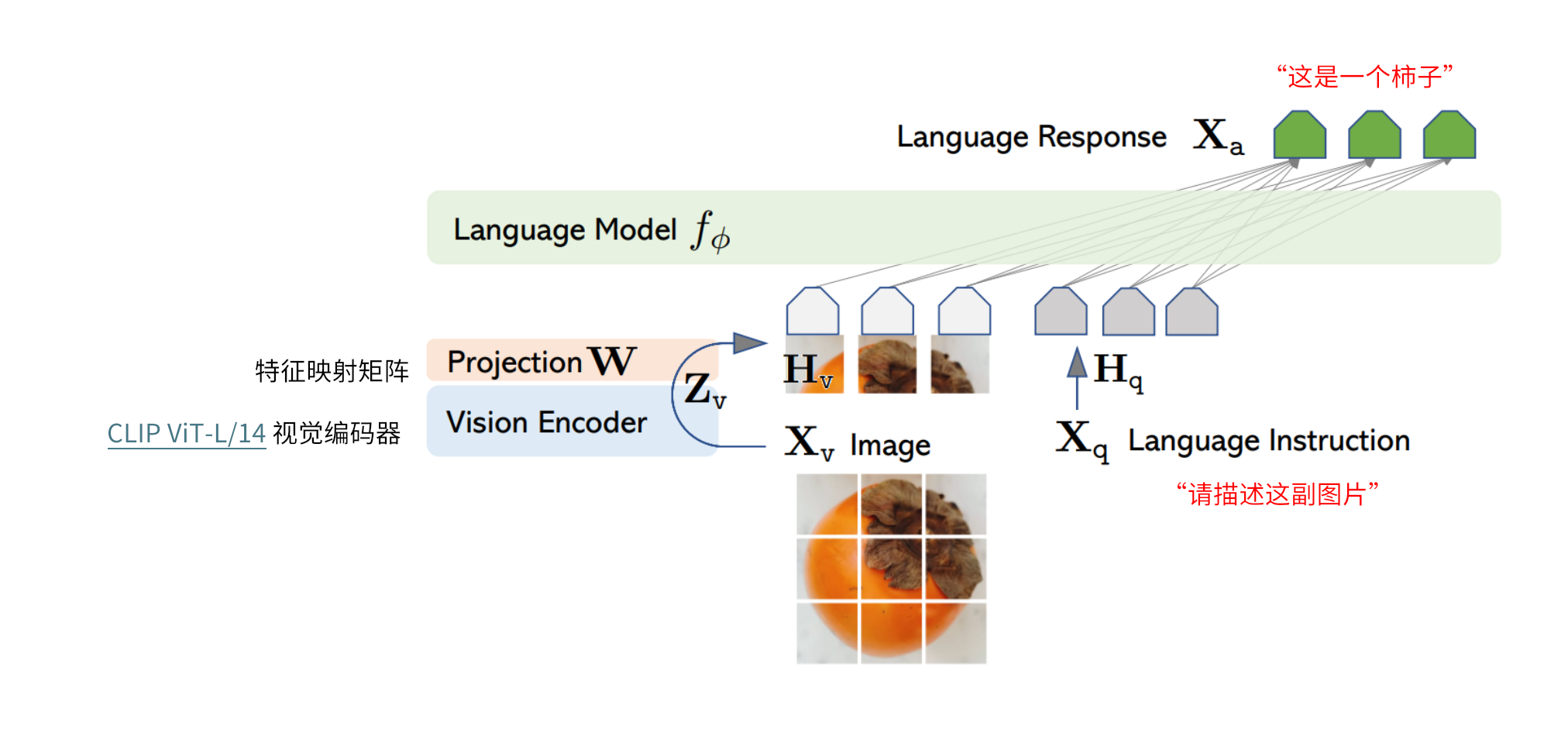
两阶段训练过程: 阶段一:特征对齐的预训练。只更新特征映射矩阵 阶段二:端到端微调。特征投影矩阵和LLM都进行更新
3.1 数据准备
3.1.1 数据来源
图-文对齐数据来源: * LAION Dataset * Conceptual Captions Dataset * SBU Captions Dataset
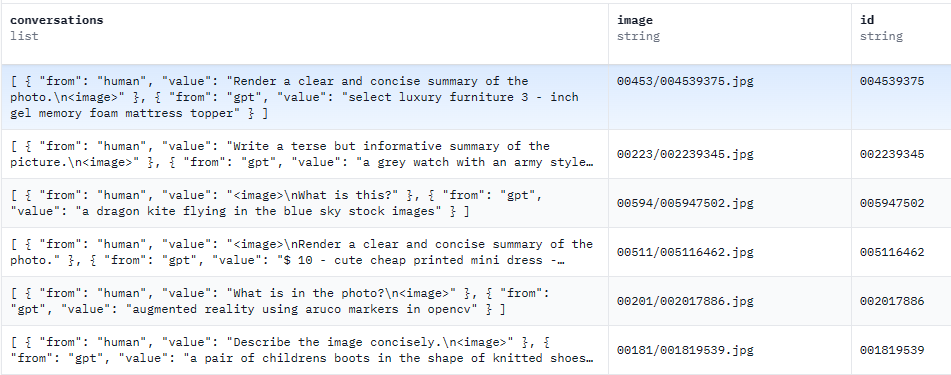
图-文指令数据来源:

共计665K条数据
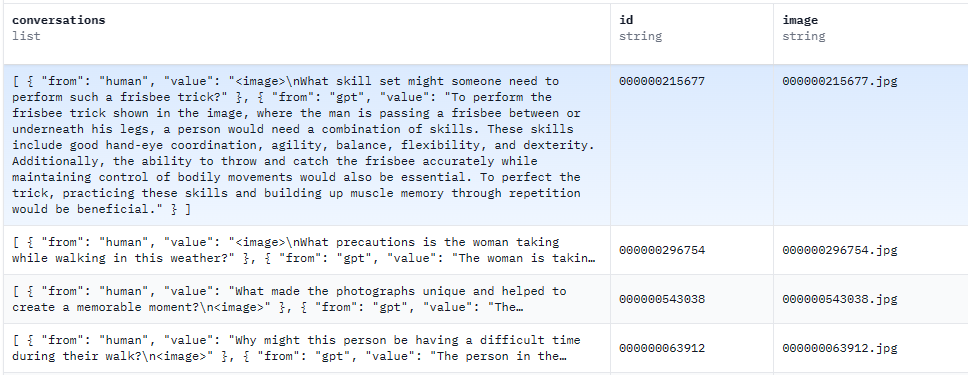
GPT4生成数据
图片的简单描述+使用精度较高的目标检测模型,把图片中所有物体的坐标信息;然后将这些纯文本信息传递给GPT4(不涉及图像信息)生成一些更加精细的秒伤或对话信息等。

图-文对齐数据样例
1 | |
图-文指令数据样例
1 | |
图像解析所需模型:
- RAM: https://huggingface.co/spaces/xinyu1205/recognize-anything/blob/main/ram_swin_large_14m.pth
- RAM++: https://huggingface.co/xinyu1205/recognize-anything-plus-model/blob/main/ram_plus_swin_large_14m.pth
- GroundingDINO:https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
将上面两个模型,下载后保存至models/下。
安装所需要的图像解析依赖包:
- RAM (Recognize Anything): 用于给定一张图片,识别出图片中包含的所有物体类别
- Grounding DINO: 用于对于给定的物体标签,框出其所在图像中的位置坐标
1 | |
- 图像解析
- 给定任意一张图片,可以将图像中的所有包含的物体信息抽取出来,并获得其对应在图像上的坐标信息。
任务一: 抽取出图像中包含的所有物体
使用 RAM 完成上述任务。与 CLIP 不同,RAM 默认提供了可识别的物体类别列表(共计4,585类标签的识别)
1 | |

1 | |
任务二:根据抽取出来的物体列表,获取其在图像中的位置信息
使用 GroundingDINO 完成上述任务。
1 | |
1 | |
1 | |
1 | |

1 | |
- 生成 LLaVA 所需训练数据
准备 GPT4 API 调用函数:
query_gpt4_vision: 调用 gpt-4v 接口,生成详细图像描述;query_gpt4_text: 调用 gpt4 文本模型接口,生成对话语料以及复杂逻辑推理问题。
1 | |
数据类型一:生成图像描述

1 | |
1 | |
数据类型二:生成对话类数据
1 | |
1 | |
数据类型三:生成复杂推理类问题
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
3.1.2 自定义数据准备

图-文对齐数据
1 | |
图-文指令数据
1 | |
3.2 模型训练
3.2.1 图文特征对齐预训练
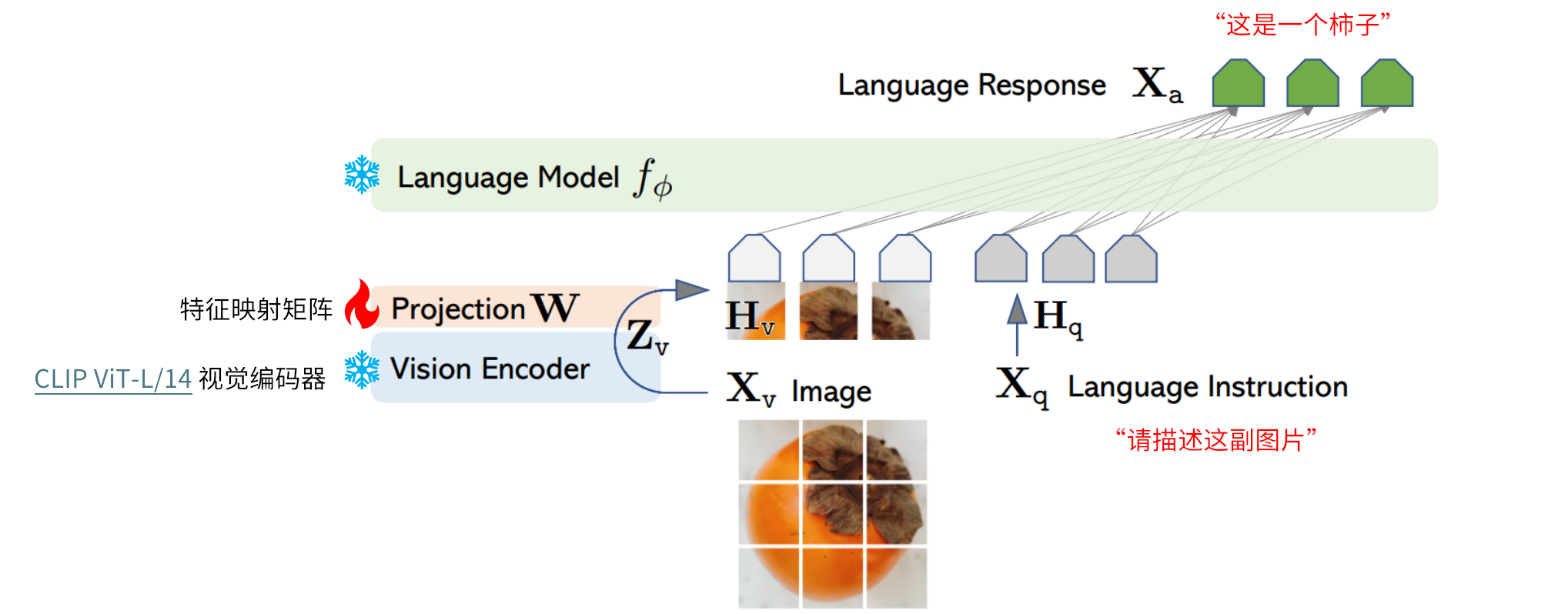
基本数据格式:
1 | |
开始训练
| Hyperparameter | Global Batch Size | Learning rate | Epochs | Max length | Weight decay |
| LLaVA-v1.5-13B | 256 | 1e-3 | 1 | 2048 | 0 |
- 8x A100 (80GB) 耗时 5.5h
- 基于 DeepSpeed ZeRO2
- 输入图像分辨率 336 px
- 训练参数:特征映射层结构(2 层全连接层)
- 训练脚本
pretrain.sh
3.2.2 图-文指令微调训练
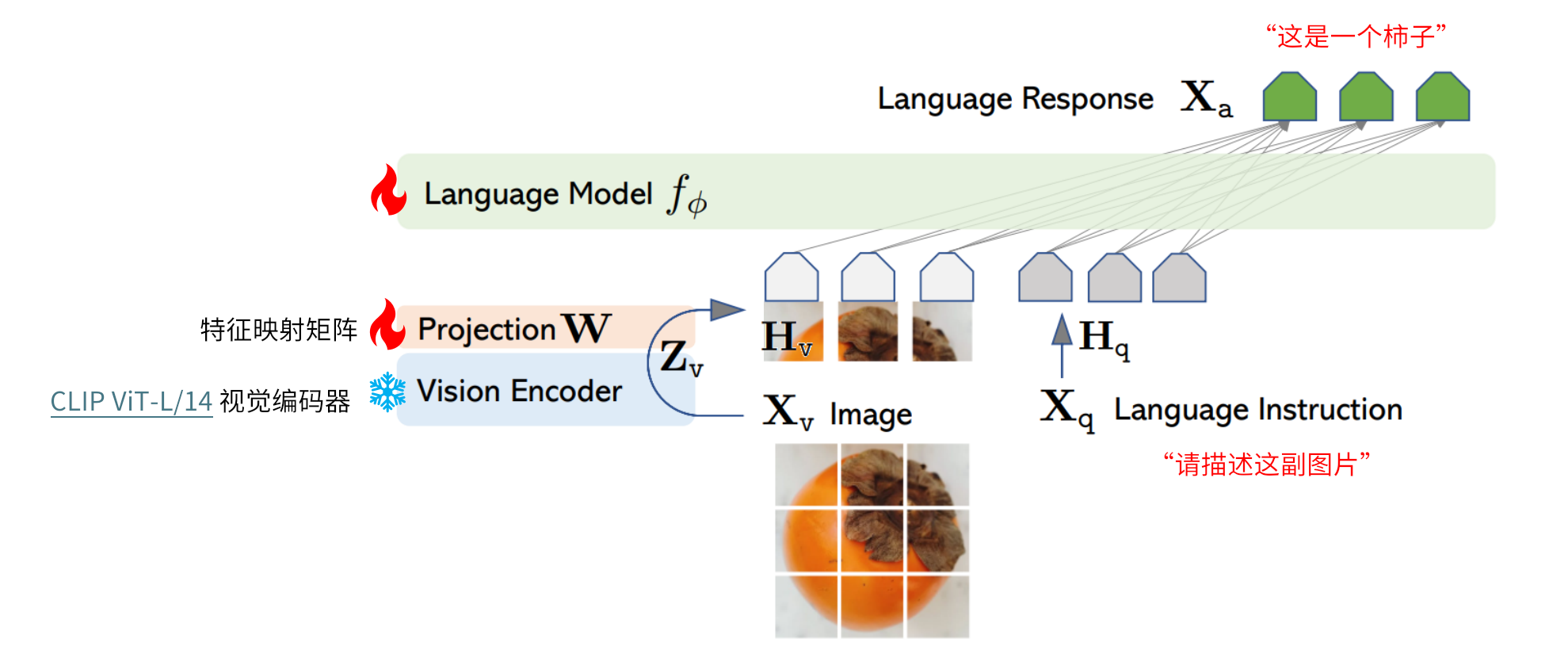
基本数据格式:
1 | |
下载 LLaVA 训练所需文本数据集: llava_v1_5_mix665k.json
下载 LLaVA 训练所需图像数据集:
- COCO: train2017
- GQA: images
- OCR-VQA: download
script, we save all files as
.jpg - TextVQA: train_val_images
- VisualGenome: part1, part2
开始训练
| Hyperparameter | Global Batch Size | Learning rate | Epochs | Max length | Weight decay |
| LLaVA-v1.5-13B | 128 | 2e-5 | 1 | 2048 | 0 |
- 8x A100 (80GB) 耗 20h
- 基于 DeepSpeed ZeR3
- 输入图像分辨率 336 px
- 训练参数:特征映射层结构(2 层全连接层以及 LLM
训练脚本: finetune.sh
LoRA 训练脚本: finetune_lora.sh
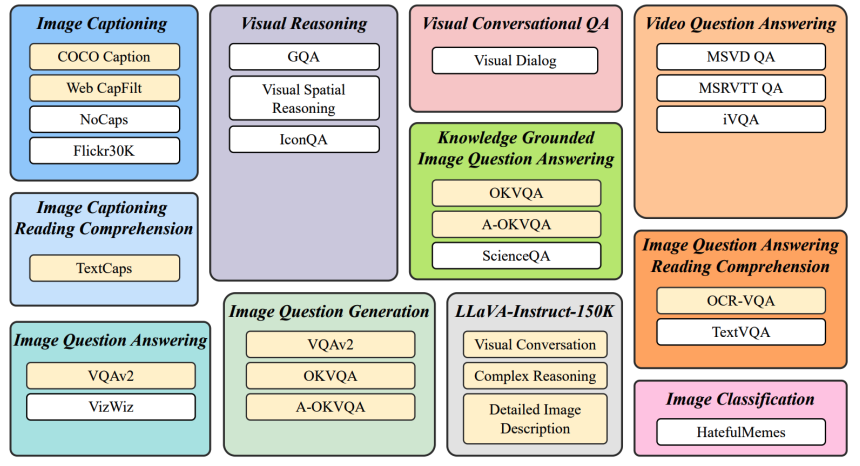
3.2.3 图文多模态大语言模型的评测
各类benchmark上的综合测试
3.3 模型部署
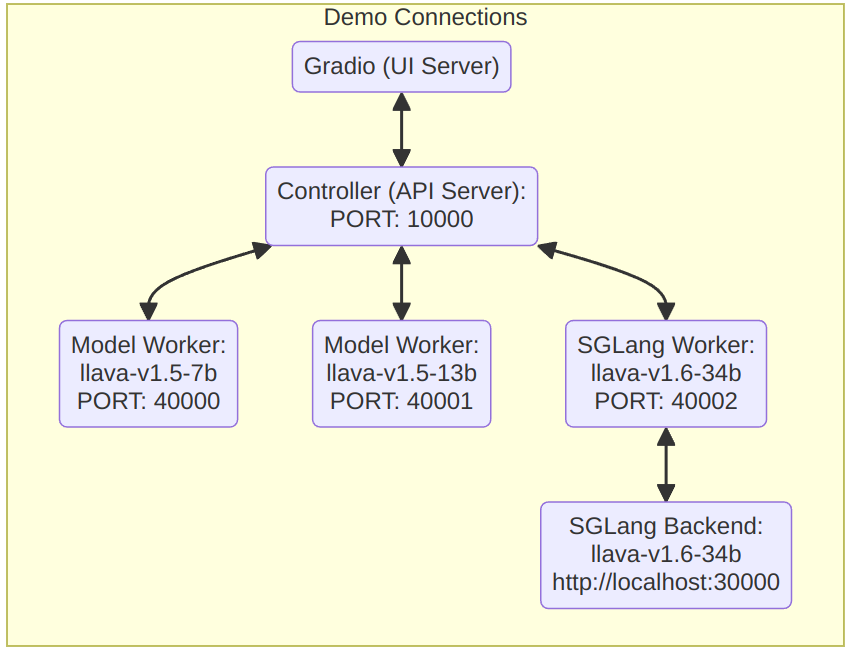
- 启动API server:
1
python -m llava.serve.controller --host 0.0.0.0 --port 10000 - 启动WebUI:
1
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b - 启动SGLang worker
1
2
3
4
5
6
7# Single GPU
CUDA_VISIBLE_DEVICES=0 python3 -m sglang.launch_server --model-path liuhaotian/llava-v1.5-7b --tokenizer-path llava-hf/llava-1.5-7b-hf --port 30000
# Multiple GPUs with tensor parallel
CUDA_VISIBLE_DEVICES=0,1 python3 -m sglang.launch_server --model-path liuhaotian/llava-v1.5-13b --tokenizer-path llava-hf/llava-1.5-13b-hf --port 30000 --tp 2
python -m llava.serve.sglang_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --sgl-endpoint http://127.0.0.1:30000 - 启动Worker:
1
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port <different from 40000, say 40001> --worker http://localhost:<change accordingly, i.e. 40001> --model-path <ckpt2> --load-4bit
3.4 LLaVa衍生
AI导盲: LLaVAVision
AI就诊: LLaVA-Med

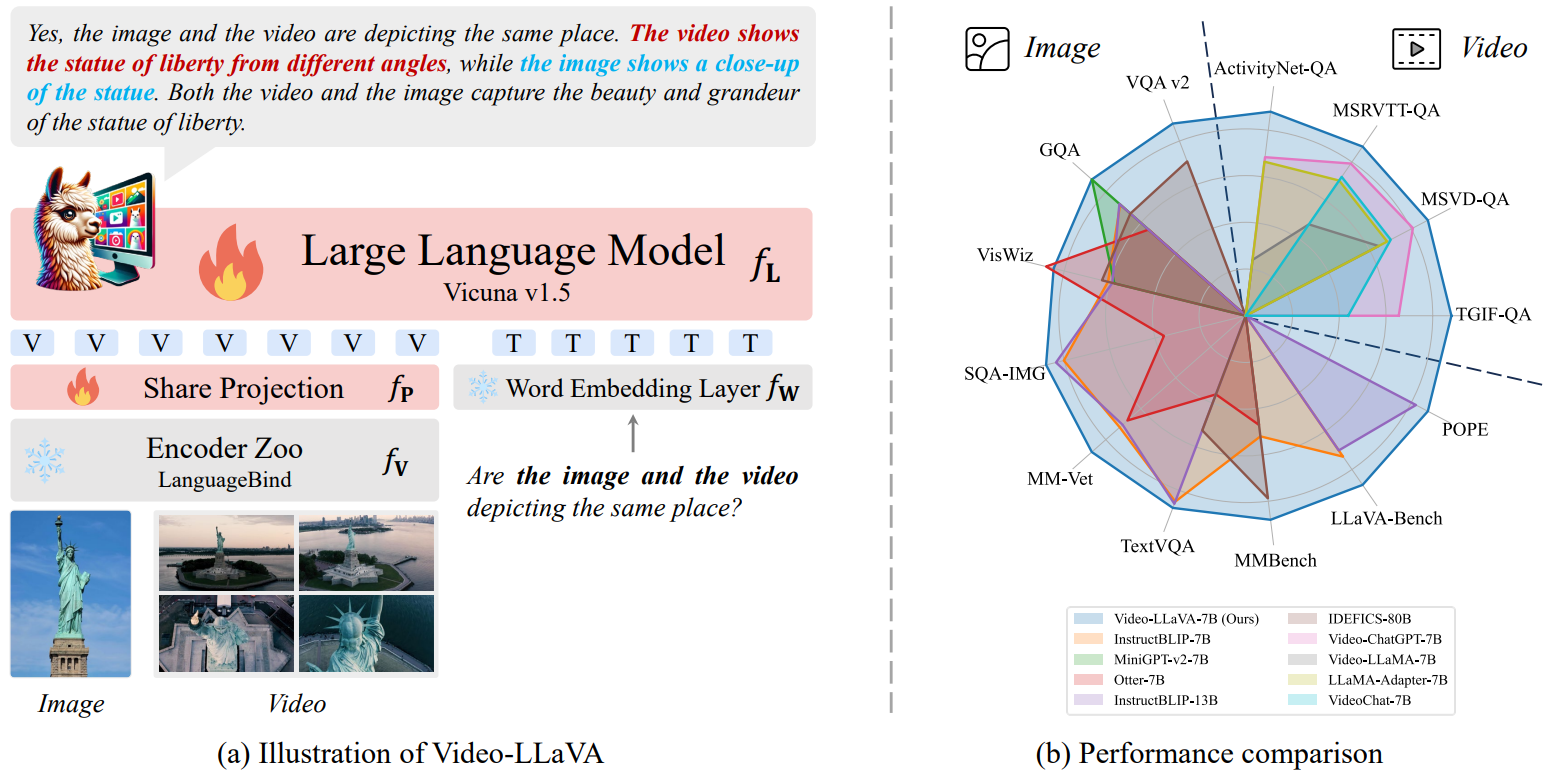
视频相关: Video-LLaVA
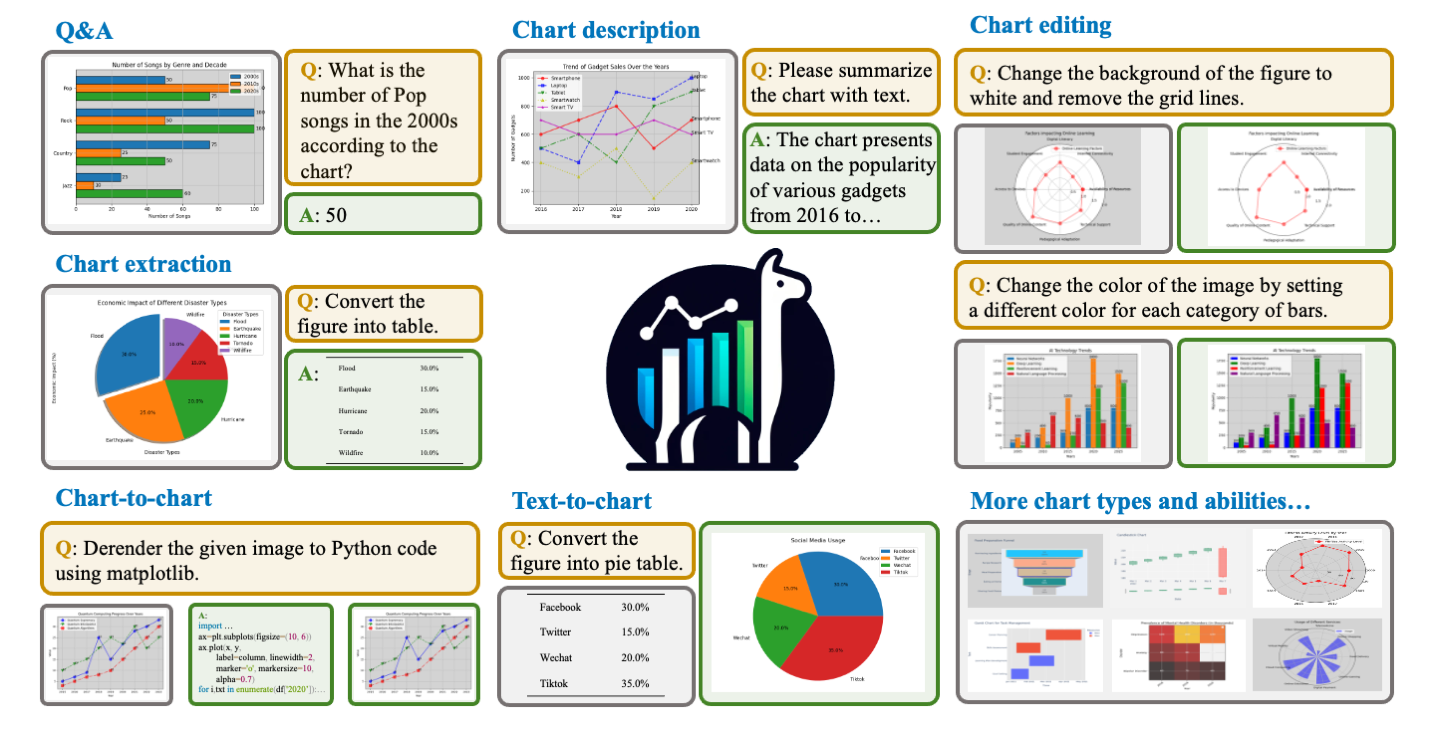
- 图表问答与生成:ChartLlama-code
3.5 LLaVA改进
改进方向:
- Vision Encoder改进
- Projection改进
3.5.1 Vision Encoder改进
3.5.1.1 LLaVA1.6 (LLaVA-Next)
主要改进:
- 将输入图像分辨率增加到更多的像素,这使它能够抓住更多的视觉细节。它支持三种宽高比,最高分辨率可达672x672、336x1344、1344x336。
- 通过改进的视觉指令调整数据混合,实现更好的视觉推理和OCR能力。
- 在更多场景下进行更好的视觉对话,涵盖不同的应用。
- 具备更好的世界知识和逻辑推理能力。 通过SGLang实现高效部署和推理。
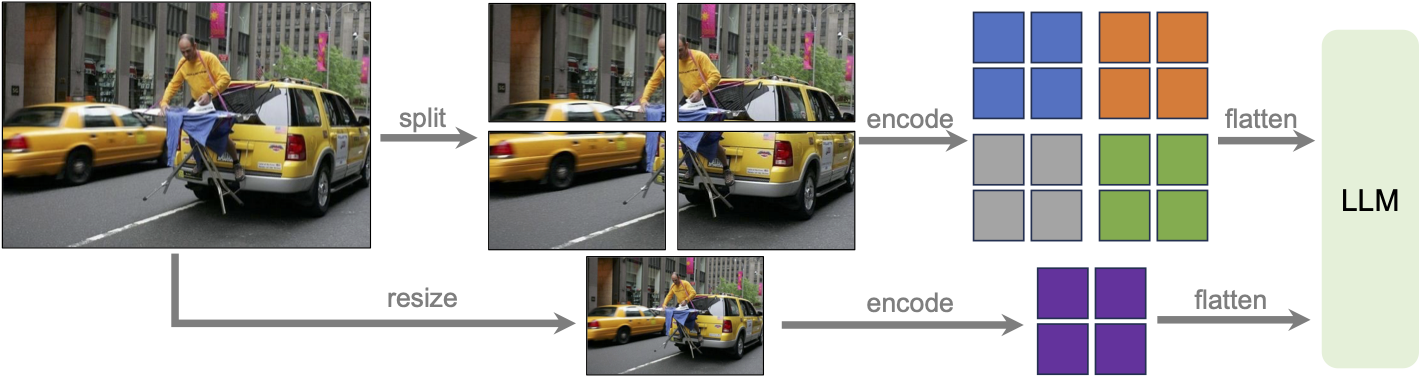
通过将图像划分为视觉编码器最初训练的分辨率较小的图像块并对其进行独立编码来克服图像分辨率限制为
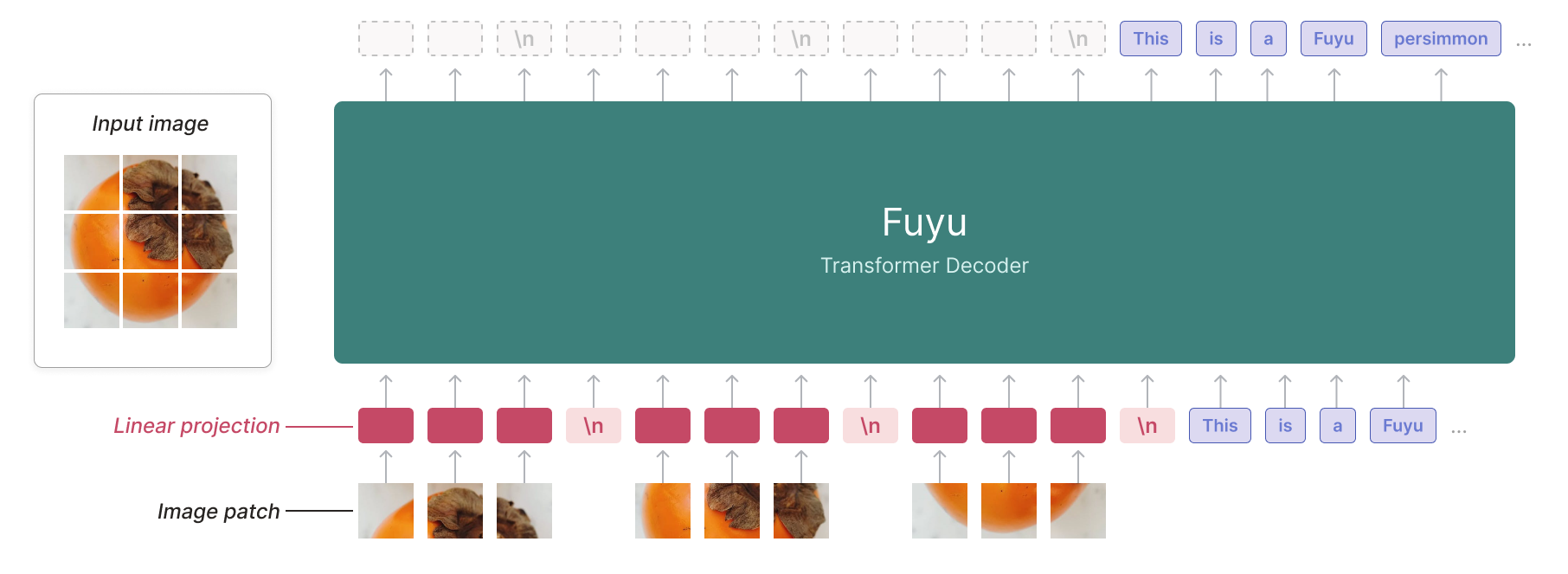
3.5.1.2 Fuyu-8B
Fuyu 是一个decoder-only transformer,没有专门的图像编码器。图像块直接线性投影到transformer的第一层,绕过嵌入查找。这种简化的架构支持任意图像分辨率,并极大地简化了训练和推理。
3.5.1.3 MiniCPM-Llama3-V 2.5
主要改进:
- 采用了类似LLaVa1.6的分区+整图组合的图像编码方式
- 使用了支持更高分辨率图像特征提取的SigLip替代了CLIP
- siglip-so400m-14-980-flash-attn2-navit
- 采用了类似q-former的技术来支持任意分辨率图像映射到固定长度的视觉编码。
- 通过模型量化、CPU、NPU、编译优化等高效加速技术,实现高效的终端设备
3.5.2 Projection机制改进
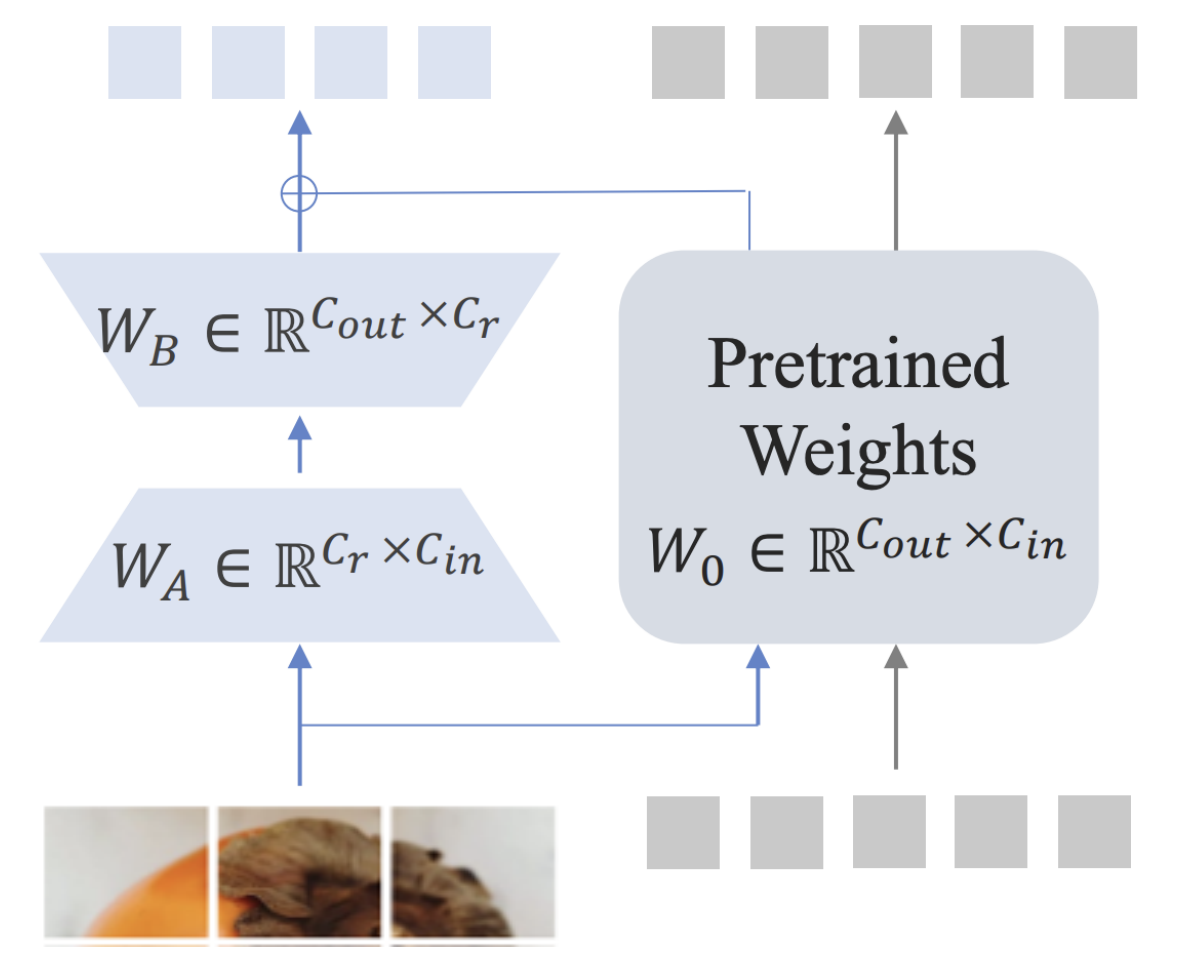
Partial LoRA,这是一个多功能插件模块,旨在将新模态的知识与 LLM 对齐。如上图所示,Partial LoRA 汲取了原始 LoRA 的灵感,并采用了低秩适应,专门应用于输入token的新模态部分。在特定配置中,Partial LoRA 应用于所有视觉token。
对于LLM块中的每个线性层
四、多模态LLM
4.1 InternVL 1.5—开源的SoTA 多模态LLM

基于InternViT-6B-448进行视觉特征编码。
动态高分辨率:InternVL 1.5能够根据输入图像的长宽比和分辨率,动态地将图像划分为不同大小的图块,最高支持4K分辨率的输入。

采用了pixel-shuffle压缩视频编码至1/4。
支持多图推理(视频打标)
4.1.1 Pixel Shuffle
- PixelShuffleUp (upsampling) PixelShuffle (Sub-Pixel Convolutional Neural Network)是一种经典的上采样方法,可以对缩小后的特征图进行有效的放大操作。与反卷积相比,PixelShuffle克服了反卷积的易产生棋盘格的问题
![]()
超分辨率图像的生成过程:首先对一个大小为
- PixelShuffle的功能:对特征图进行shape变换:
—> - PixelShuffle的理解:将一个低分辨率像素划分为
份,默认是由特征图对应像素位置的 个特征像素组成一个低分辨率像素。在组成的过程中通过不断优化每组组合的权重来达到最好的上采样效果。
如下图是一个超分辨率图像的生成完整过程卷积层kernel(output channels,
input channels, kernel width, kernel height):
- PixelShuffleDown (downsampling)
PixelShuffleDown与PixelShuffleUp是互逆操作,PixelShuffleDownz早期被用于图像增强、图像超分,后来也有被用于图像分类模块。
在图像复原里面,直接在输入图像分辨率层面计算的话,会导致计算量过大,而采用stride=2的卷积、MaxPooling、AvgPooling等方式进行下采样会造成信息损失与性能下降,而PixelShuffle不仅不会造成信息损失,同时具有更低的计算量、参数量。
- PixelShuffle的功能:对特征图进行shape变换
—>
InternVL 1.5 中的pixelShuffle
1 | |
4.2 MoE-LLaVA
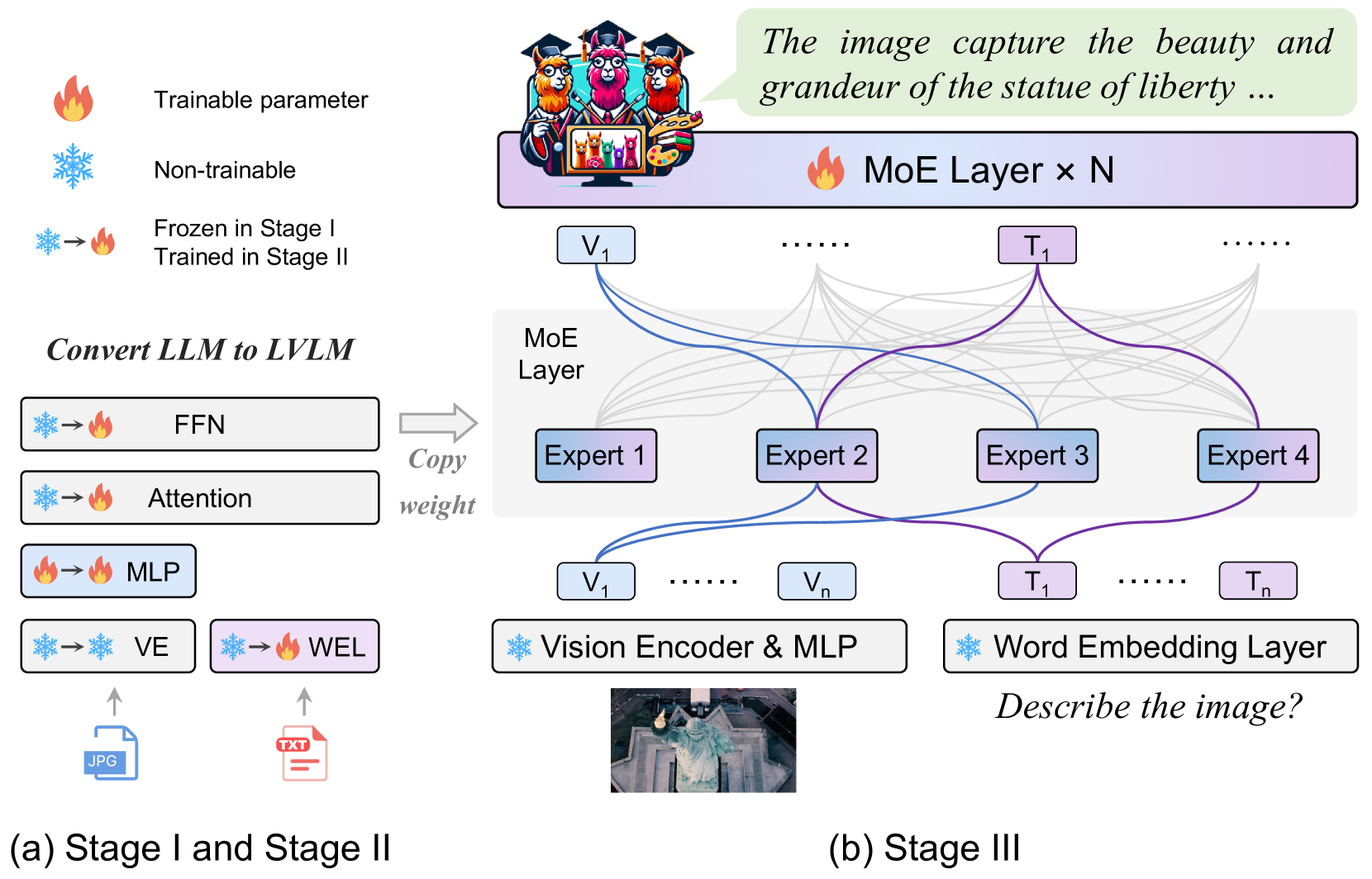
vision encoder处理输入图片得到视觉token序列。利用一个投影层将视觉tokens映射成LLM可接受的维度。相同的,与图片配对的文本经过一个word embedding layer被投影得到序列文本tokens。
MoE-LLaVA采用三阶段的训练策略:
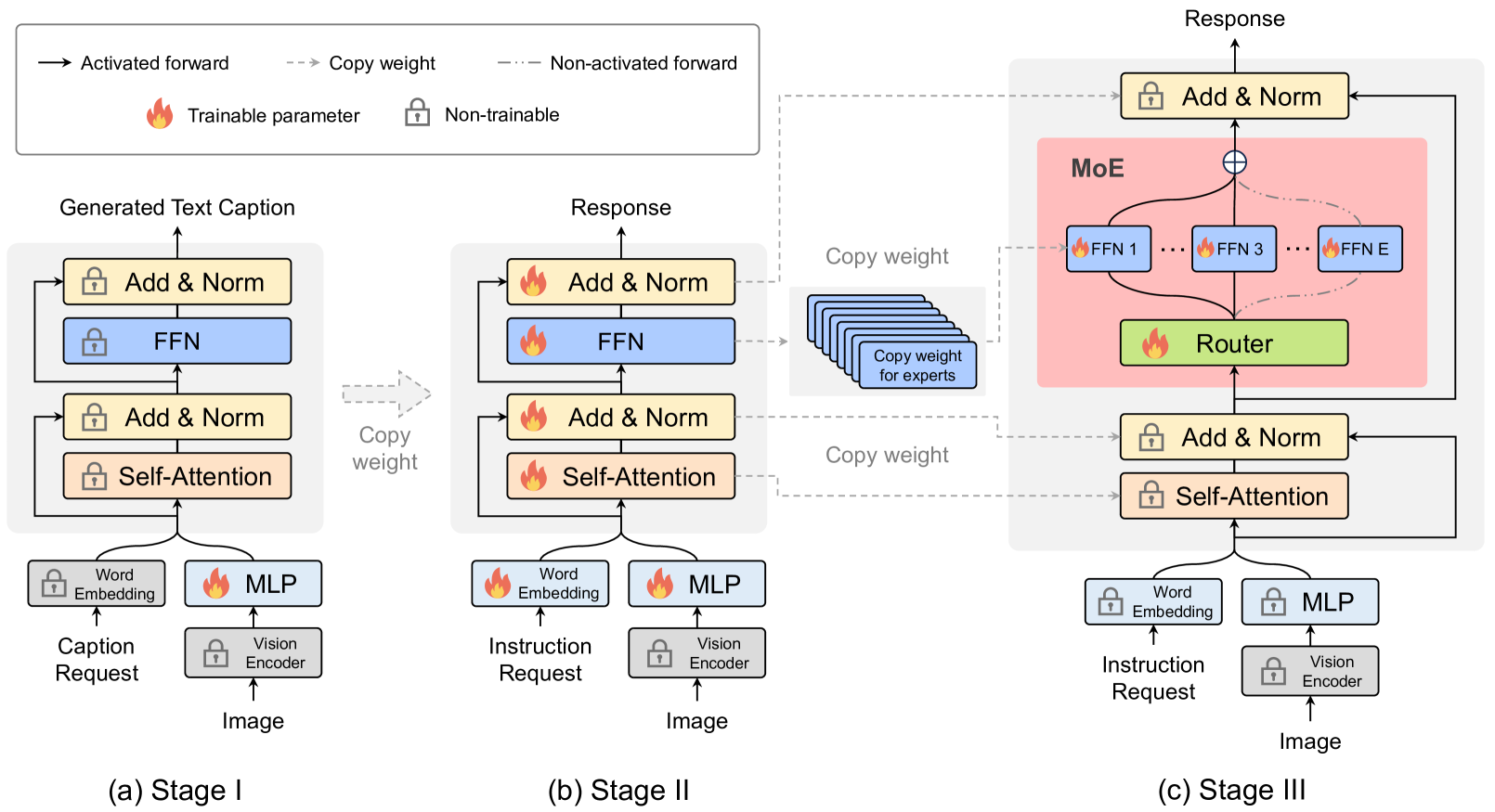
阶段1:在此阶段,目标是使图像token适应LLM,使LLM能够理解图像中的实例。为了实现这一目标,采用 MLP 将图像token投影到 LLM 的输入域中,将图像块视为伪文本token。在此阶段,LLM 被训练来描述图像。在此阶段,MoE 层不会应用于 LLM。
第二阶段:多模态指令数据调优是增强大型模型能力和可控性的关键技术。在这个阶段,LLM被调整为具有多模态理解的LVLM。使用更复杂的指令,包括图像逻辑推理和文本识别等任务,这需要模型具有更强的多模态理解。通常,对于密集模型,LVLM 训练在此阶段被认为已完成。然而,在将 LLM 转换为 LVLM 并稀疏化 LVLM 的同时遇到了挑战。因此,MoE-LLaVA利用第二阶段的权重作为第三阶段的初始化,以减轻稀疏模型的学习难度。
第三阶段:多次复制 FFN 来初始化专家。当图像token和文本token被输入 MoE 层时,路由器会计算每个token与专家之间的匹配权重。然后,每个token都由top-
个专家处理,并根据路由器的权重通过加权求和来聚合输出。当top- 个专家被激活时,其余专家保持沉默。这种建模方法形成了具有无限可能的稀疏路径的 MoE-LLaVA,提供了广泛的功能。
MoE-LLAVA特性:
- 支持Qwen、Phi2、StableLM、Mistral、MiniCPM等多个LLM架构的LLaVa改造训练
- 支持SigLip、CLIP视觉编码器
- 基本代码结构与LLaVa类似
4.3 TinyLLaVA Factory
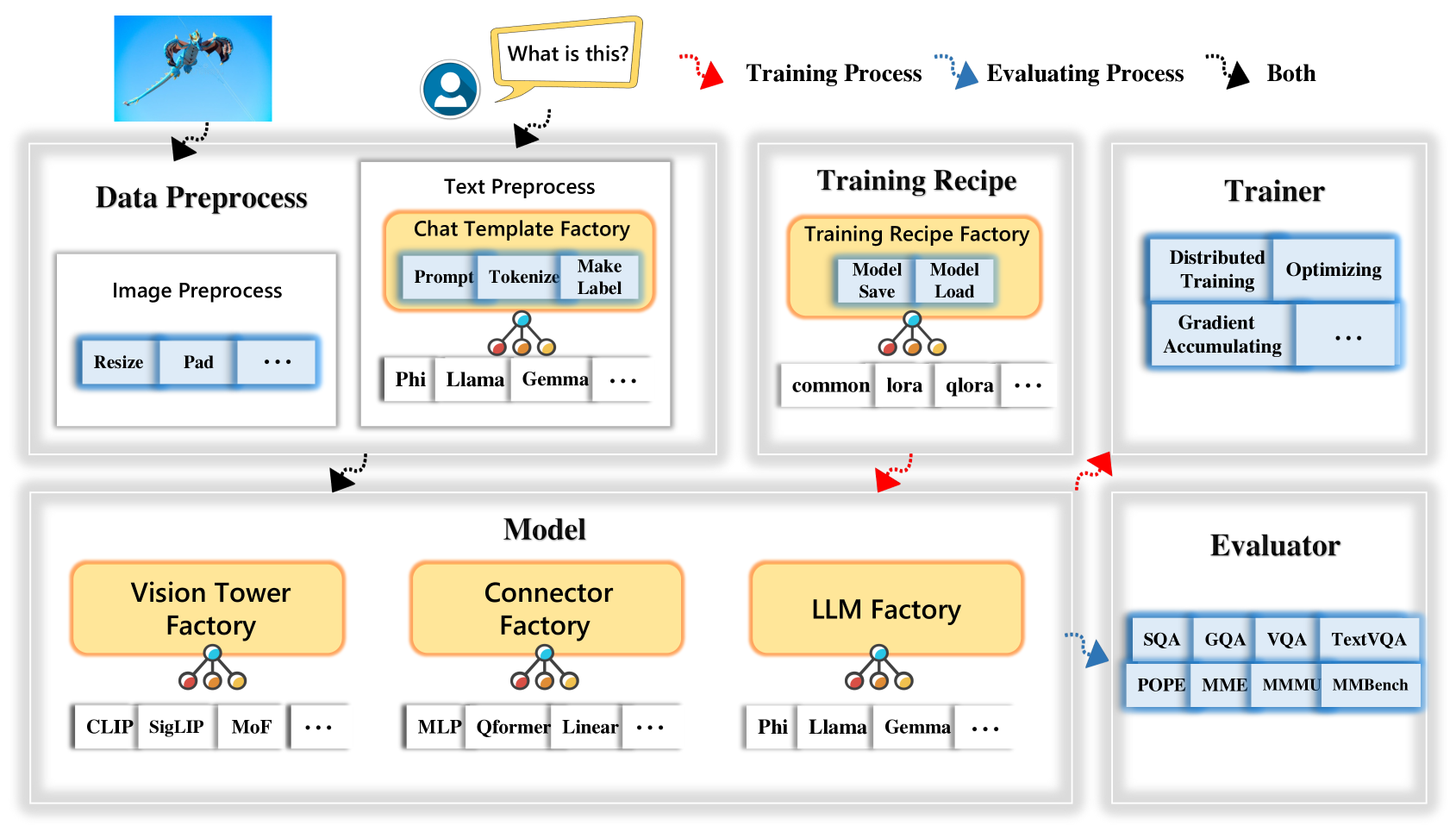
- 摒弃了 LLaVA 代码中繁杂的图片处理和 Prompt 处理过程,提供了标准的、可扩展的图片和文本预处理过程,清晰明了
- 图片预处理可自定义 Processor,也可使用一些官方视觉编码器的 Processor,如 CLIP ViT 和 SigCLIP ViT 自带的 Image Processor。
- 对于文本预处理,定义了基类 Template,提供了基本的、共用的函数,如添加System Message (Prompt)、Tokenize、和生成标签 Ground Truth 的函数,用户可通过继承基类就可轻松扩展至不同 LLM 的 Chat Template
4.4 X-LLM
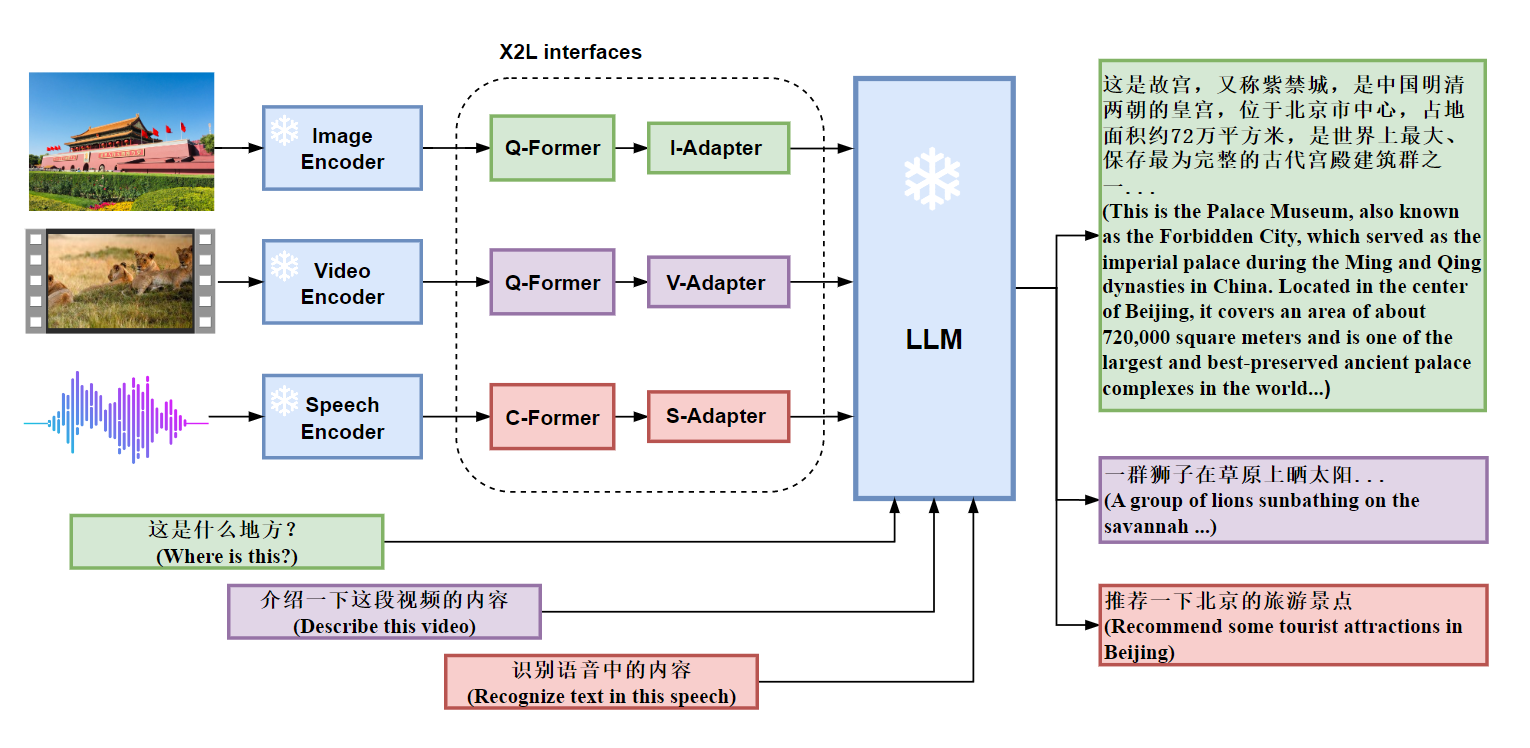
X-LLM使用X2L接口将多模态(图像、语音、视频)转换为外语(对于LLM),并将其输入到大型语言模型(ChatGLM)中以完成多模态LLM,实现令人印象深刻的多模式聊天功能。X-LLM 是一个通用的多模态 LLM 框架,它允许将各种信息模态合并到 LLMs 中,例如 (1) 非语音音频,从而使LLM进行音频对话。 (2)终端设备状态信息,LLM控制终端设备等。
4.4.1 Q-Former
按照两阶段策略预训练一个轻量级Querying Transformer(Q-Former)来弥补模态差距
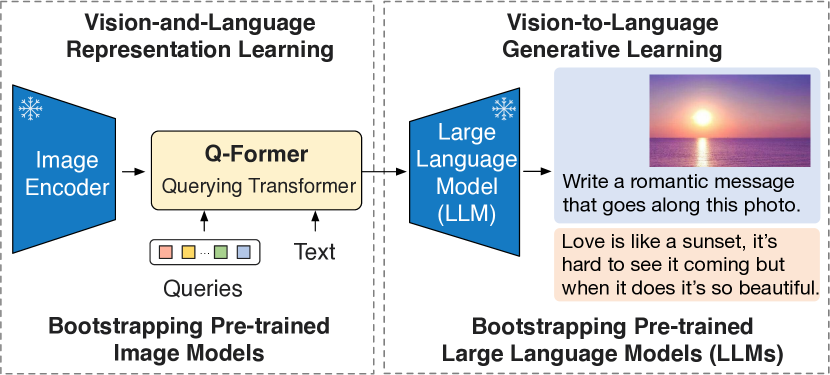
Q-Former 是一种轻量级transformer,它采用一组可学习的查询向量从冻结图像编码器中提取视觉特征。它充当冻结图像编码器和冻结 LLM 之间的信息瓶颈,为 LLM 提供最有用的视觉特征以输出所需的文本。在第一个预训练阶段,执行视觉语言表示学习,强制 Q-Former 学习与文本最相关的视觉表示。在第二个预训练阶段,通过将 Q-Former 的输出连接到冻结的 LLM 来执行视觉到语言的生成学习,并训练 Q-Former 使其输出视觉表示可以由 LLM 解释。
4.4.1.1 Q-Former架构
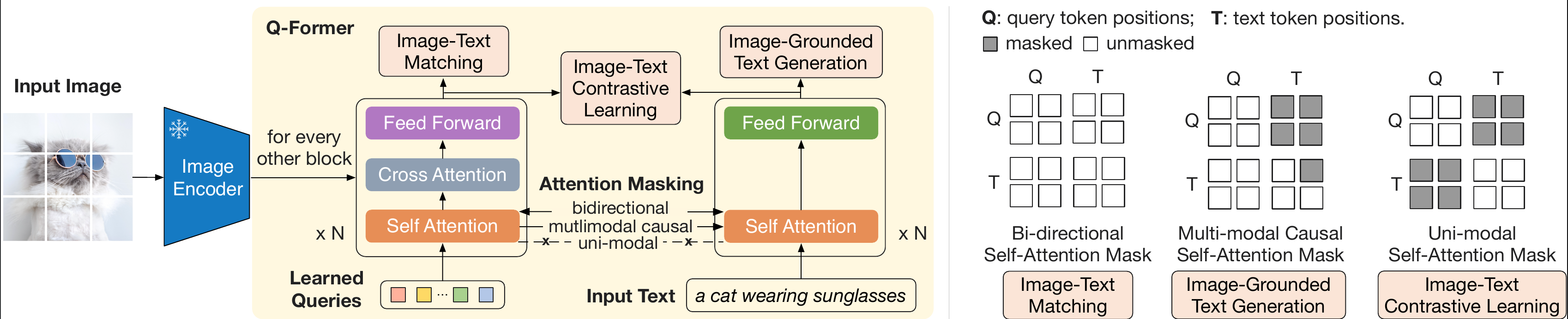
Q-Former 由两个共享相同自注意力层的transformer子模块组成:(1)
与冻结图像编码器交互以进行视觉特征提取的图像transformer,(2)
可以运行的文本transformer作为文本编码器和文本解码器。创建一组可学习的查询嵌入作为图像transformer的输入。查询通过自注意力层相互交互,并通过交叉注意力层(插入每个其他transformer块)与冻结图像特征交互。查询还可以通过相同的自注意力层与文本进行交互。根据预训练任务,我们应用不同的自注意力掩码来控制查询文本交互。使用
4.4.1.2 从 frozen image encoder 中自主学习 Vision-Language Representation
在 representation 学习阶段将 Q-Former 连接到冻结图像编码器,并使用图像文本对进行预训练。目标是训练 Q-Former,以便查询能够学习提取最能提供文本信息的视觉表示。联合优化了三个共享相同输入格式和模型参数的预训练目标。每个目标在查询和文本之间采用不同的注意力屏蔽策略来控制它们的交互。如上图右。
- Image-Text Contrastive Learning
(ITC):学习对齐图像表示和文本表示,以使它们的互信息最大化。它通过将正对的图像文本相似性与负对的图像文本相似性进行对比来实现这一点。将图像transformer的输出查询表示
与文本transformer的文本表示 对齐,其中 是 的输出嵌入token。由于 包含多个输出嵌入(每个查询一个),首先计算每个查询输出与 之间的成对相似度,然后选择最高的一个作为图像文本相似度。为了避免信息泄漏,采用单峰自注意力掩码,其中查询和文本不允许互相看到。由于使用了冻结图像编码器,与端到端方法相比,可以在每个 GPU 上容纳更多样本。因此,在 BLIP 中使用批内负数而不是动量队列。 - Image-grounded Text Generation (ITG):训练 Q-Former
在给定输入图像作为条件的情况下生成文本。由于 Q-Former
的架构不允许冻结图像编码器和文本token之间直接交互,因此必须首先通过查询提取生成文本所需的信息,然后通过自注意力层传递给文本token。因此,查询被迫提取捕获有关文本的所有信息的视觉特征。采用多模态因果自注意力掩码来控制查询文本交互。查询可以相互关注,但不能关注文本token。每个文本token可以处理所有查询及其先前的文本token。还将
token替换为新的 token,作为指示解码任务的第一个文本token。 - Image-Text Matching
(ITM):旨在学习图像和文本表示之间的细粒度对齐。这是一个二元分类任务,要求模型预测图像文本对是正(匹配)还是负(不匹配)。使用双向自注意力掩码,所有查询和文本都可以相互关注。因此,输出查询嵌入
捕获多模式信息。将每个输出查询嵌入到二类线性分类器中以获得 logit,并将所有查询的 logit 平均作为输出匹配分数。使用了负难例挖掘,来提取出难的 negative pairs。
4.4.1.3 使用 Frozen LLM 来自主学习 Vision-to-Language 生成
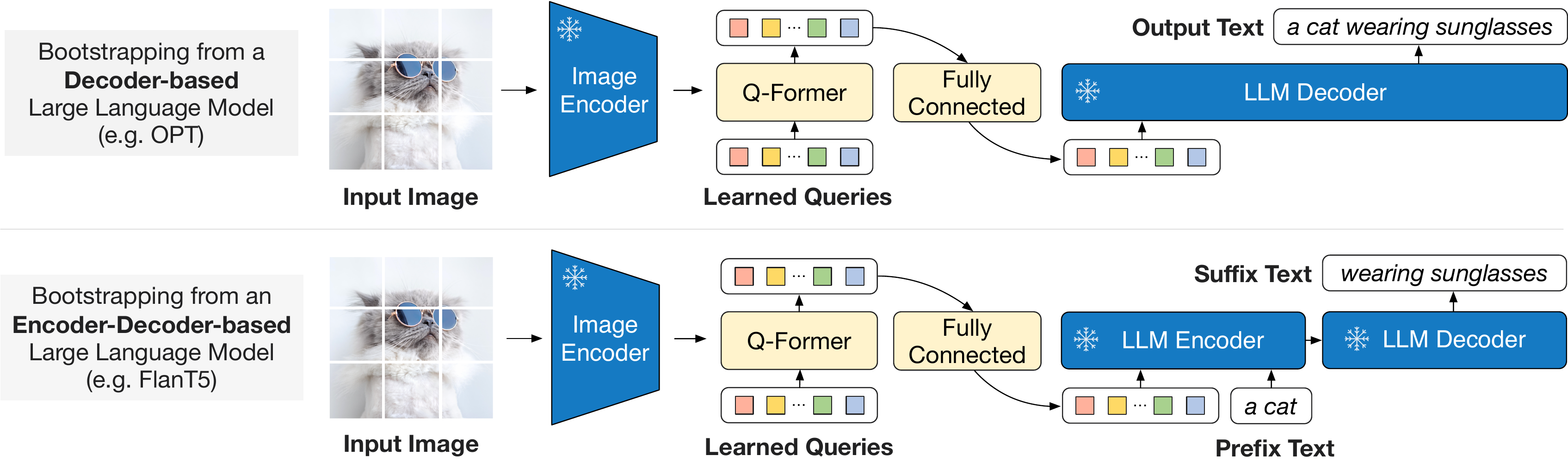
在生成任务的预训练阶段,作者将 Q-Former(已经基于 frozen image encoder 预训练过的)和 frozen LLM 进行结合,来获得 LLM 的语言生成能力
如上图所示:
- 首先,使用全连接层将输出查询嵌入
进行线性映射投影到与 LLM 的文本嵌入相同的维度。 - 然后将投影的查询嵌入添加到输入文本嵌入之前。它们充当 soft visual prompts根据 Q-Former 提取的视觉表示来调节 LLM。
- 由于 Q-Former 已经过预训练,可以提取包含语言信息的视觉表示,因此它可以有效地充当信息瓶颈,将最有用的信息提供给 LLM,同时删除不相关的视觉信息。这减轻了LLM学习视觉语言对齐的负担,从而减轻了灾难性的遗忘问题。
4.4.2 C-Former
C-Former 是 CIF 模块和 12 层token结构的组合。
一种低复杂度并具有单调一致性的序列转换机制——连续整合发放(Continuous Integrate-and-Fire,CIF)。CIF会对先后到来的声学信息依次进行整合,当整合的信息量达到识别阈值,将整合后的信息发放以用作后续识别。其与注意力模型的对齐形态对比如下图。
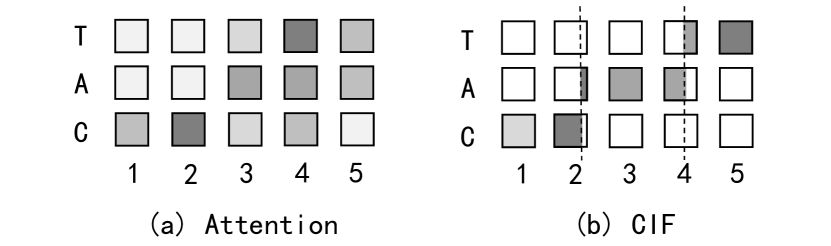
CIF应用于编解码框架。在每一个编码时刻,CIF分别接收编码后的声学编码表示及其对应的权重(表征了蕴含的信息量)。之后,CIF不断地积累权重并对声学编码表示进行整合(加权求和的形式)。
当积累的权重达到阈值后,意味一个声学边界被定位到。此时,CIF模拟了整合发放模型的处理思想,将当前编码时刻的信息分为两部分(如上图右图所示):
一部分用来完成当前标签的声学信息整合(权重可构建一个完整分布)。
另一部分用作下一个标签的声学信息整合。
之后CIF将整合后的当前声学信息(声学Embedding)发放到解码器以立即预测对应的标签。以上过程一直执行到编码后序列的末尾。
4.4.3 X-LLM 训练
X-LLM使用X2L接口连接多个预训练的单模态编码器(例如ViT-g视觉编码器)和大语言模型ChatGLM。三阶段的训练程序:
- 第一阶段:转换多模式信息。通过X2L interfaces将多模态信息转换为外语(对于LLM),仅更新X2L interfaces参数
- 第二阶段:将 X2L 表示与 LLM 对齐。 LLM中注入外语(对于LLM),仅更新X2L interfaces参数
- 第三阶段:整合多种模式。集成多模态,仅更新X2L interfaces中的adapter
Q-former初始化自BLIP-2;C-former初始化自ASR模型。
4.5 NExT-GPT:Any-to-Any Multimodal LLM
通过将 LLM 与多模态适配器和扩散解码器连接,NExT-GPT 实现了通用多模态理解以及任意模态输入和输出。
NExT-GPT 由三个主要层组成:编码阶段、LLM理解和推理阶段以及解码阶段。
Multimodal Encoding Stage: 利用 ImageBind,它是跨六种模式的统一高性能编码器。借助 ImageBind,无需管理大量异构模式编码器。然后,通过线性投影层,不同的输入表示被映射为LLM可以理解的类似语言的表示。
- LLM Understanding and Reasoning Stage:NExT-GPT的核心代理是LLMLLM 将不同模态的表示作为输入,并对输入进行语义理解和推理。它输出 1) 直接文本响应,以及 2) 每种模态的信号token,用作指示解码层是否生成多模态内容以及如果生成则生成什么内容的指令。
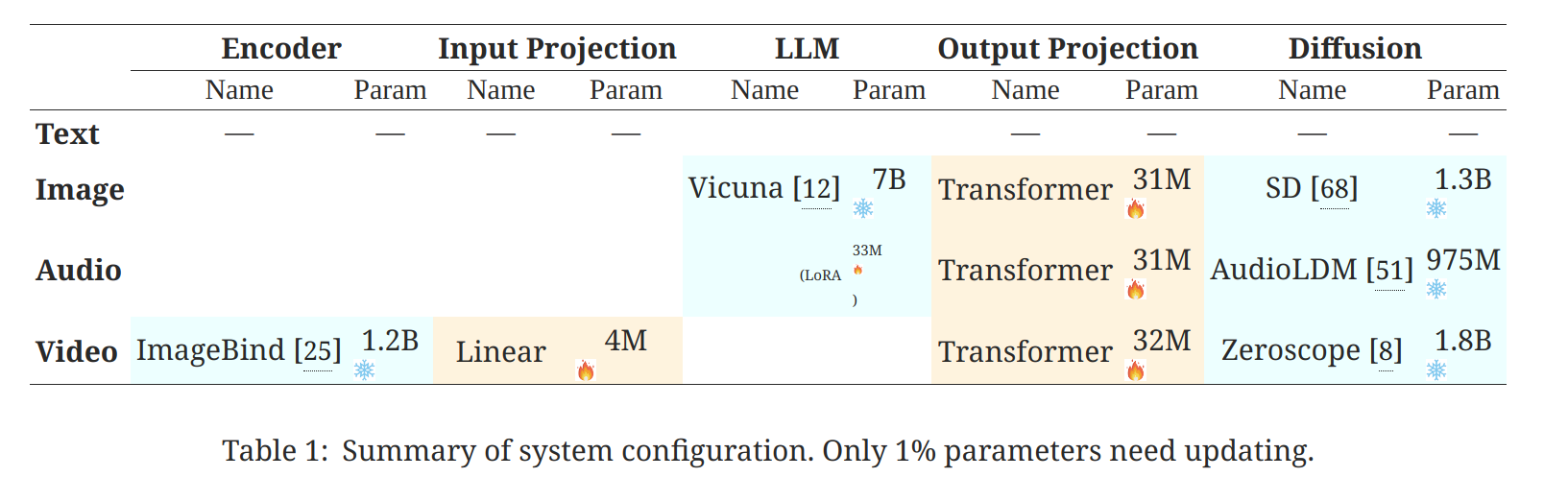
- Multimodal Generation Stage:从LLM(如果有)接收具有特定指令的多模态信号,基于 Transformer 的输出投影层将信号token表示映射为后续多模态解码器可以理解的表示形式。Stable Diffusion1.5用于图像合成,Zeroscope3用于视频合成,AudioLDM(audioldm-l-full)用于音频合成。
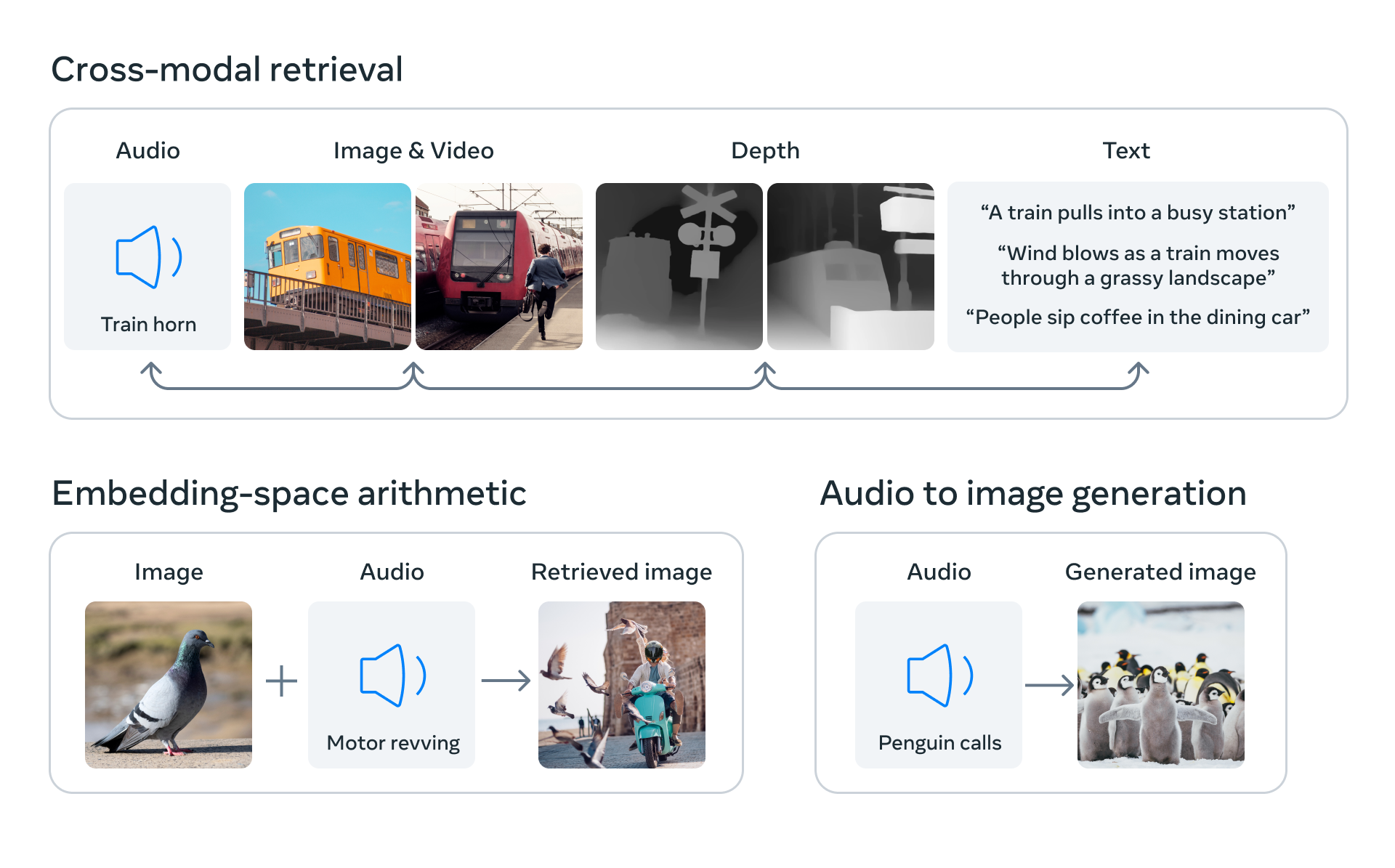
通过将六种模态的嵌入对齐到一个公共空间中,ImageBind 可以对未同时观察到的不同类型的内容进行跨模态检索,添加来自不同模态的嵌入以自然地组成其语义,并通过以下方式生成音频到图像:使用音频嵌入和预训练的 DALLE-2 解码器来处理 CLIP 文本嵌入。
4.5.1 三阶段训练过程
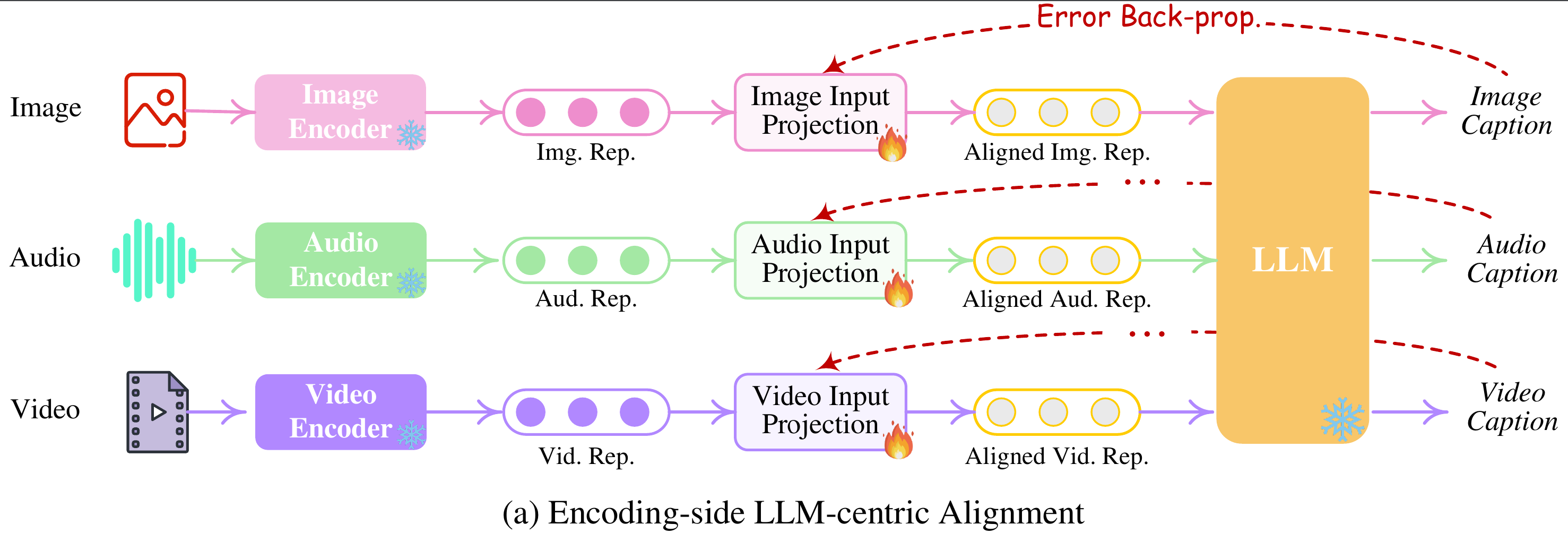
- 以LLM为中心的Encoder特征对齐
考虑将不同的输入多模态特征与文本特征空间对齐,即核心LLM可以理解的表示。因此,这被直观地命名为以 LLM 为中心的多模态对齐学习。为了完成对齐,从现有语料库和基准中准备“X-caption”对(“X”代表图像、音频或视频)数据。强制 LLM 根据黄金标题(gold caption)生成每个输入模态的标题。下图说明了学习过程。只更新input projection layer。
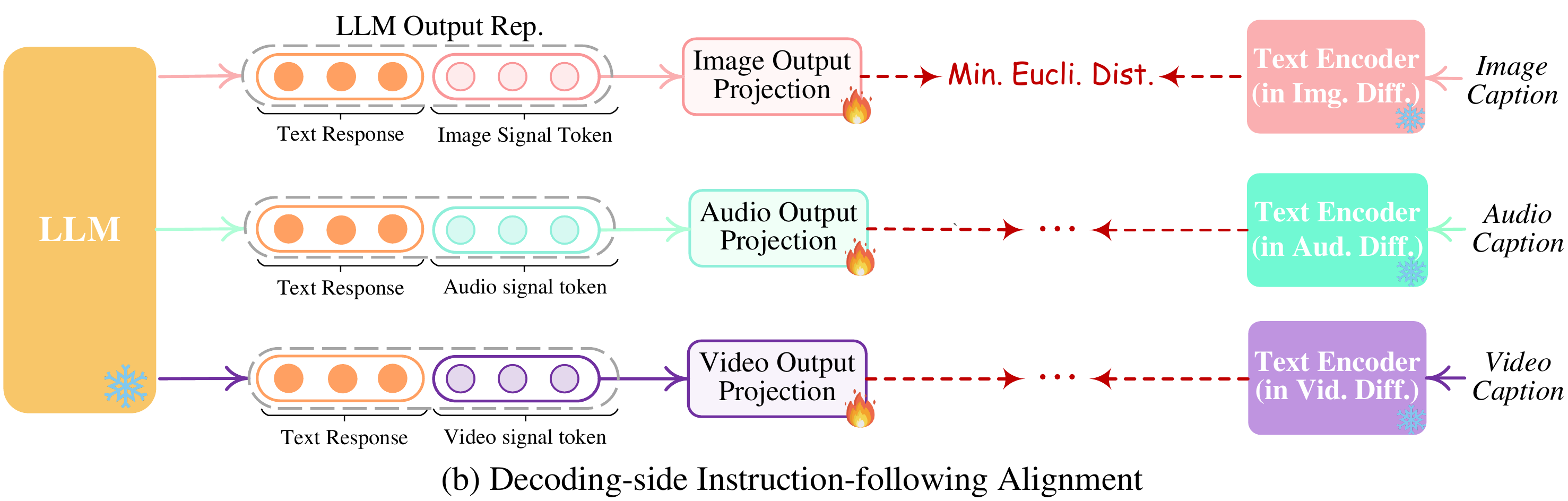
- Decoder段输出结果与指令对齐
在解码端,集成了来自外部资源的预训练条件扩散模型。主要目的是将扩散模型与 LLM 的输出指令保持一致。然而,在每个扩散模型和 LLM 之间执行全面的对齐过程将带来巨大的计算负担。在这里探索一种更有效的方法,即解码端指令跟随对齐,如下图所示。具体来说,由于各种模态的扩散模型仅以文本token输入为条件。这种调节与系统中 LLM 的模态信号令牌显着不同,这导致扩散模型对 LLM 指令的准确解释存在差距。因此,考虑最小化 LLM 的模态信号token表示(在每个基于 Transformer 的项目层之后)与扩散模型的条件文本表示之间的距离。由于仅使用文本条件编码器(扩散主干冻结),因此学习仅基于纯粹的字幕文本,即没有任何视觉或音频资源。这也确保了高度轻量级的训练。只更新output projection layer。
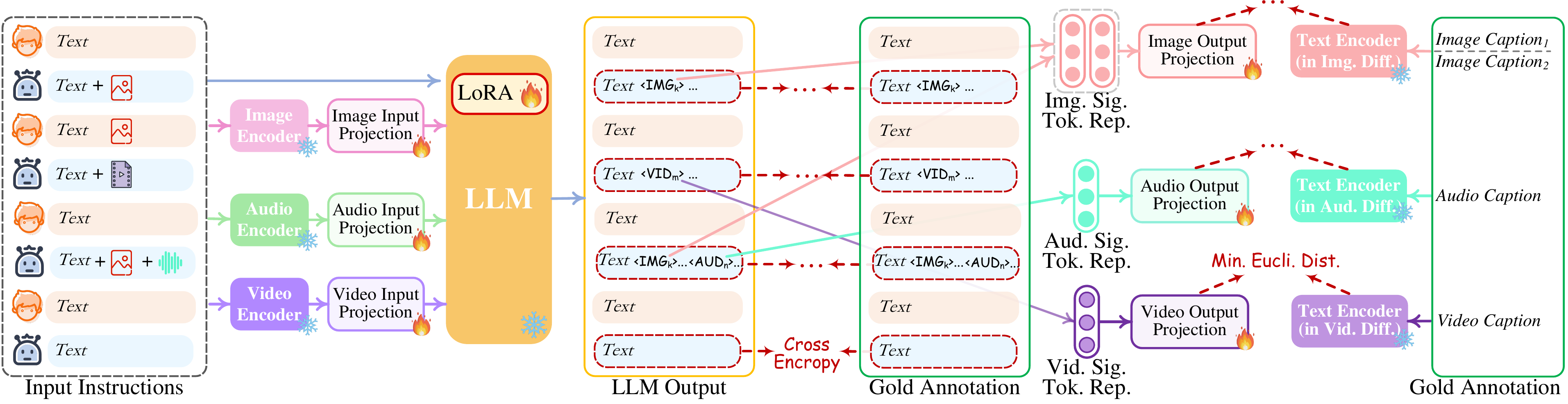
- 指令微调
进一步的指令微调(IT)对于增强LLM的能力和可控性是必要的。为了促进任意 MM-LLM 的开发,提出了一种新颖的模态切换指令调整(MosIT)。如下图所示,当 IT 对话样本输入系统时,LLM 会重建并生成输入的文本内容(并使用多模态信号token表示多模态内容)。优化是根据黄金注释和 LLM 的输出进行的。除了LLM调优之外,还对NExT-GPT的解码端进行了微调。将输出投影编码的模态信号token表示与扩散条件编码器编码的黄金多模态标题表示对齐。从而,全面的调优过程更加接近与用户忠实有效交互的目标。更新LLM Lora,input以及output projection layers
4.6 AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
所有模态都被标记为离散token,LLM 在此基础上以自回归方式执行多模态理解和生成。只需要数据预处理和后处理,模型的架构和训练目标保持不变。
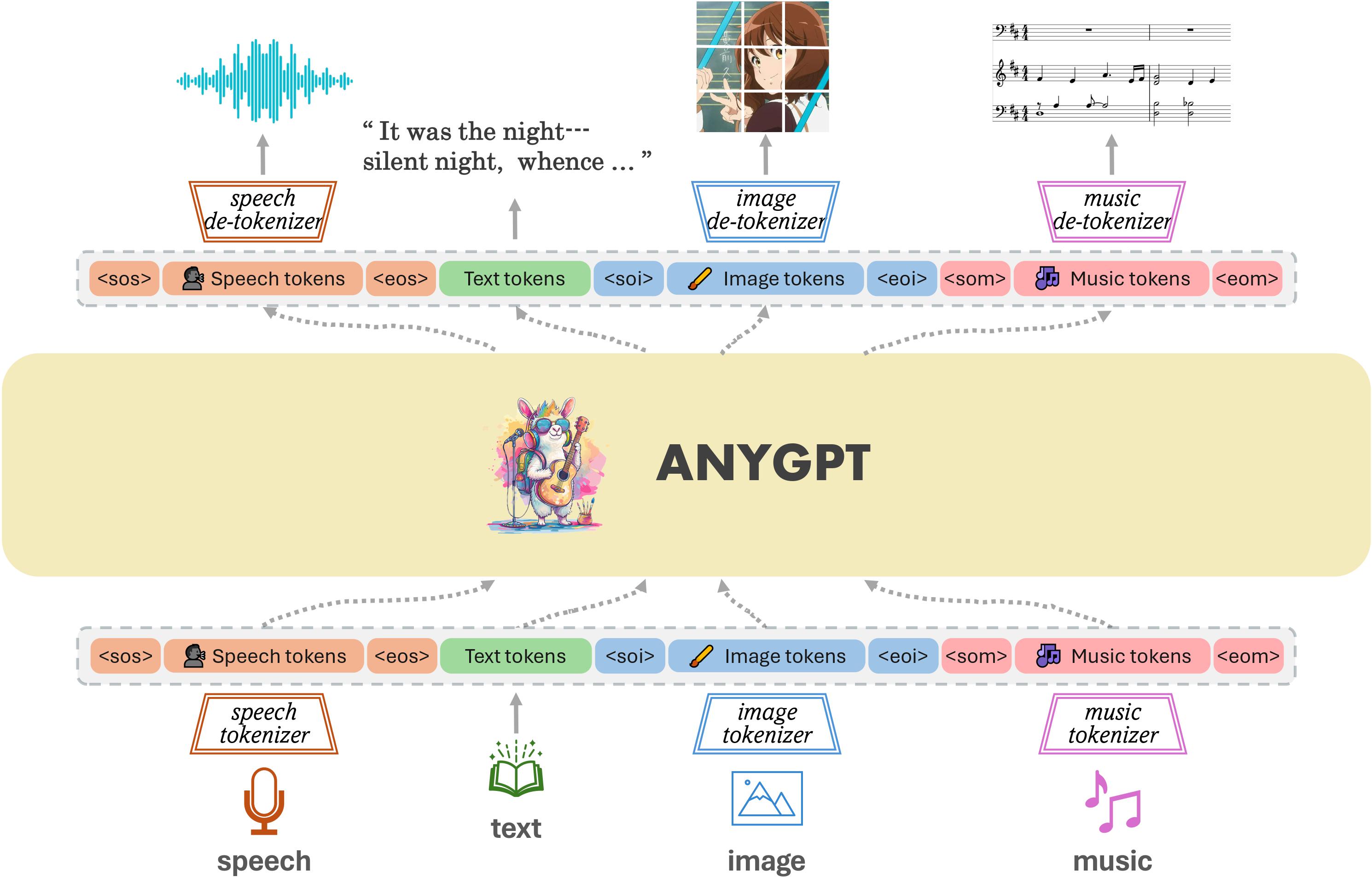
AnyGPT,这是一种任意对任意的多模态语言模型,它利用离散表示来统一处理各种模态,包括语音、文本、图像和音乐。 AnyGPT 可以稳定地训练,而不需要对当前的大语言模型(LLM)架构或训练范式进行任何改变。相反,它完全依赖于数据级预处理,促进新模式无缝集成到 LLMs 中,类似于合并新语言。构建了一个以文本为中心的多模态数据集,用于多模态对齐预训练。
- Image Tokenizer:SEED tokenizer
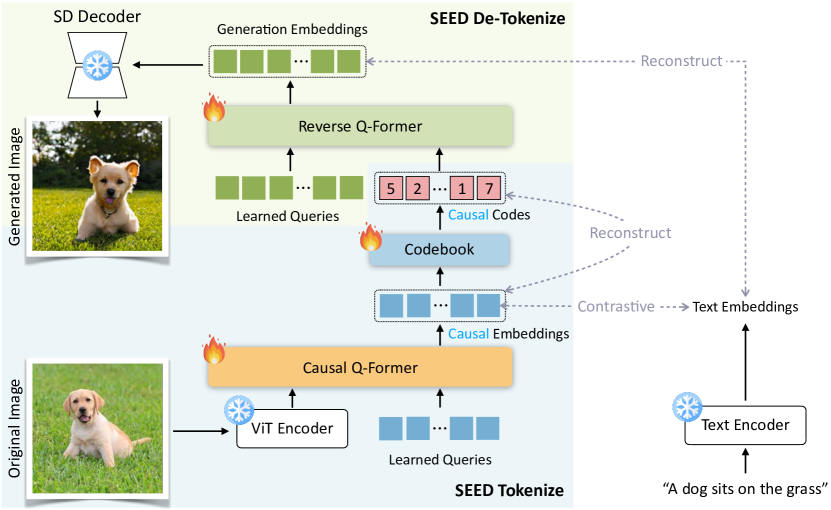
SEED 分词器由多个组件组成,包括 ViT 编码器、因果 Q-Former、VQ
代码本、多层感知(MLP)和 UNet解码器。SEED 将
- Speech Tokenizer:SpeechTokenizer
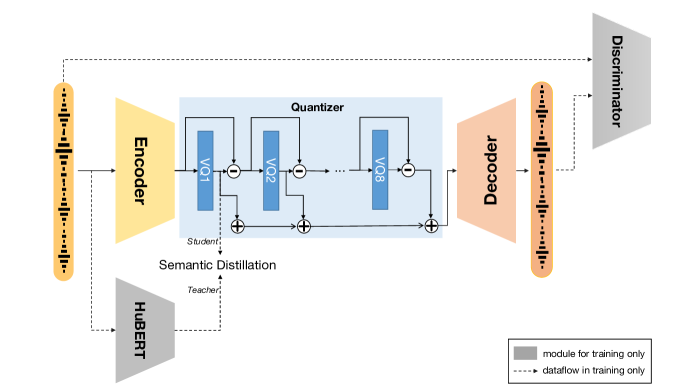
SpeechTokenizer,它是专门为语音大语言模型设计的,通过分层地解开语音信息的不同方面来统一语义和声学token。采用带有残差矢量量化
(RVQ) 的编码器-解码器架构。SpeechTokenizer
使用八个分层量化器(每个量化器有 1,024
个条目)将单通道音频序列压缩为离散矩阵,并实现 50 Hz
的帧速率。第一个量化器层捕获语义内容,而第 2 至 8
层则编码副语言细节。因此,10 秒的音频被转换为
- Music Tokenizer:Encodec
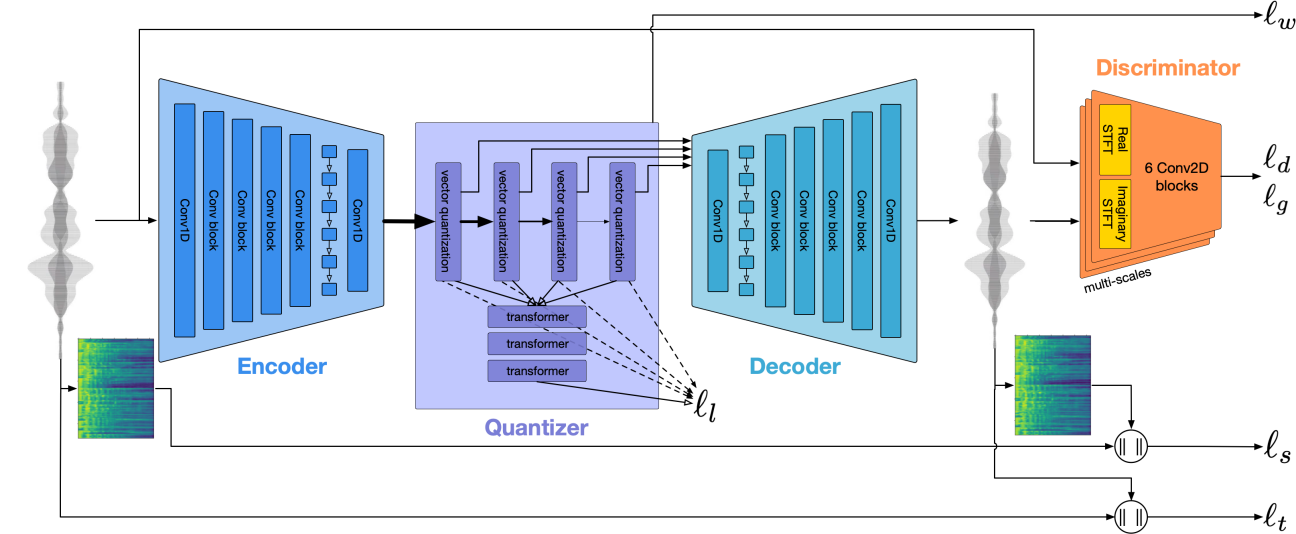
尽管语音和音乐共享相似的数据格式,但它们在内容上的巨大差异导致我们将它们视为不同的模式,每种模式都配备了自己的标记器。Encodec一种卷积自动编码器,其潜在空间使用残差向量量化(RVQ)进行量化,作为音乐标记器。
4.7 VideoPoet:A large language model for zero-shot video generation
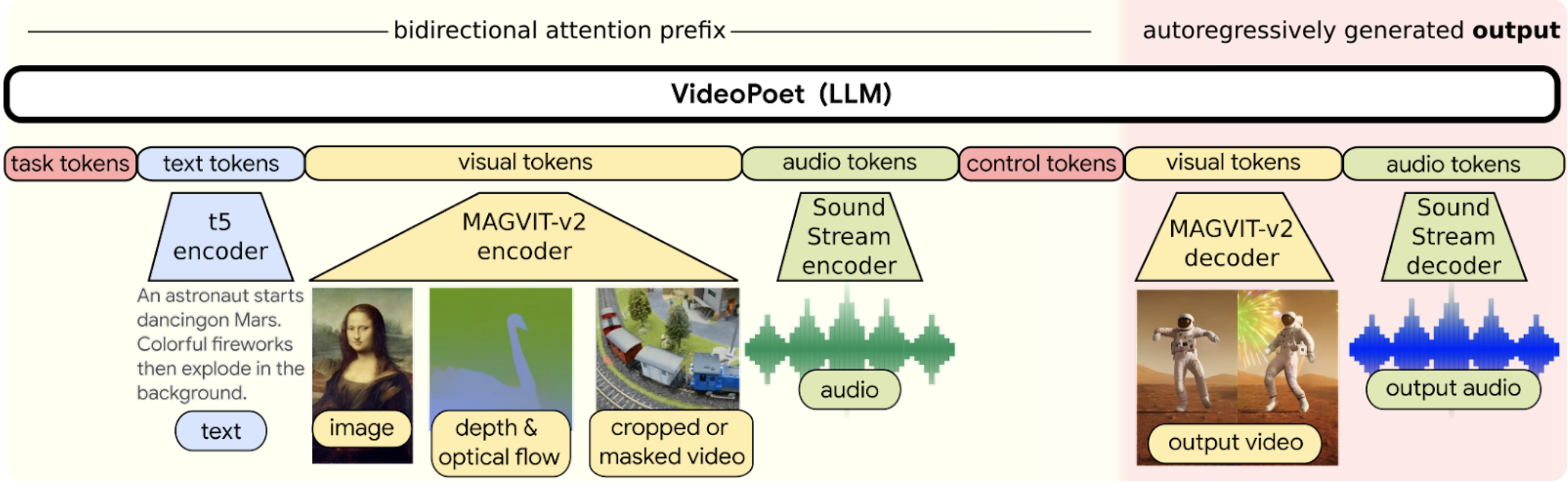
VideoPoet将所有模态编码到离散令牌空间中,以便可以直接使用大型语言模型架构进行视频生成。在<>中表示特殊标记。模态不可知标记为深红色;与文本相关的组件为蓝色;与视觉相关的组件为黄色;音频相关组件呈绿色。浅黄色布局的左侧部分表示双向前缀输入。深红色的右侧部分代表具有因果注意力的自回归生成的输出。
- Image and video tokenizer:MAGVIT-v2
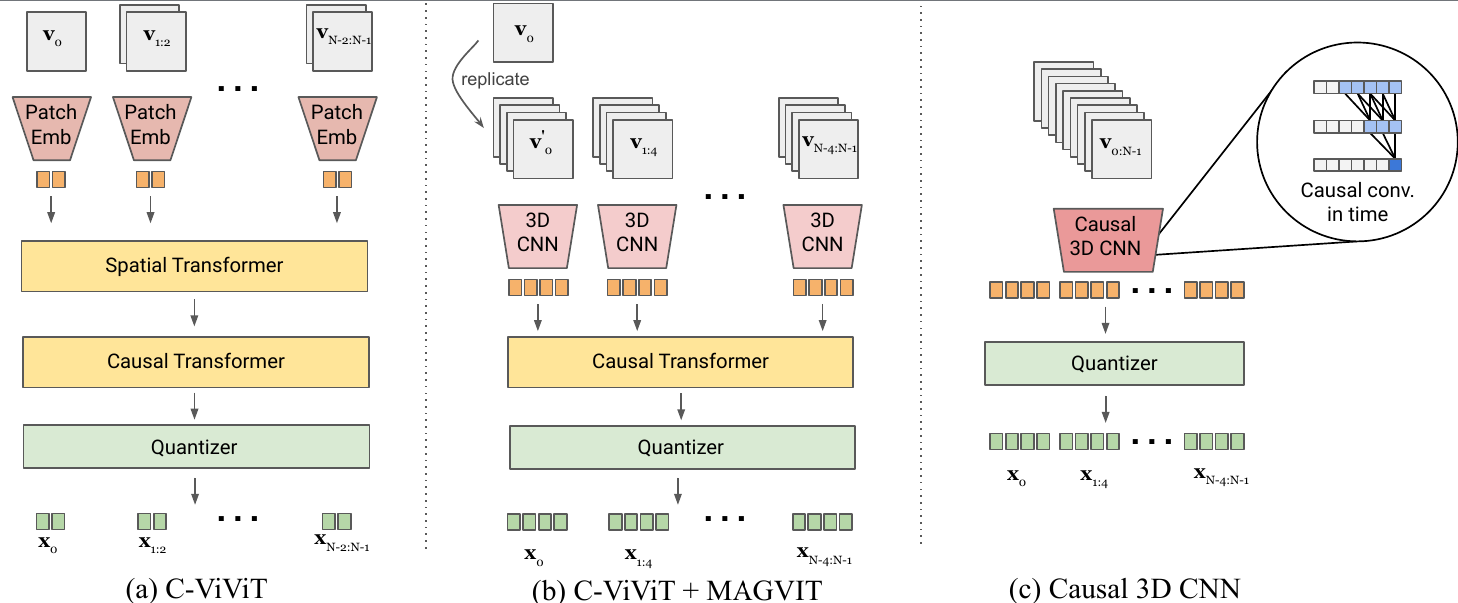
MAGVIT-v2,旨在使用共同的词汇表为视频和图像生成简洁而富有表现力的 token。它在视觉质量方面的性能高压缩能力,有效减少LLM所需的序列长度,从而有利于更加高效有效的学习。具体来说,视频剪辑被编码并量化为整数序列,并由解码器映射回像素空间。
- Audio tokenizer:SoundStream tokenizer
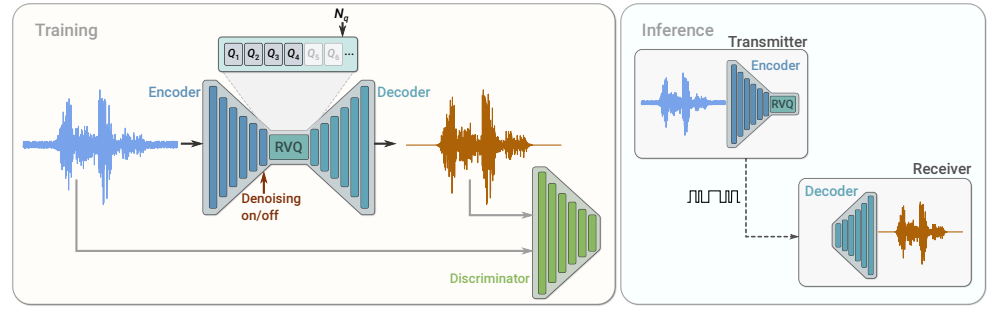
卷积编码器生成输入音频样本的潜在表示,该表示使用可变数量
- Super-Resolution
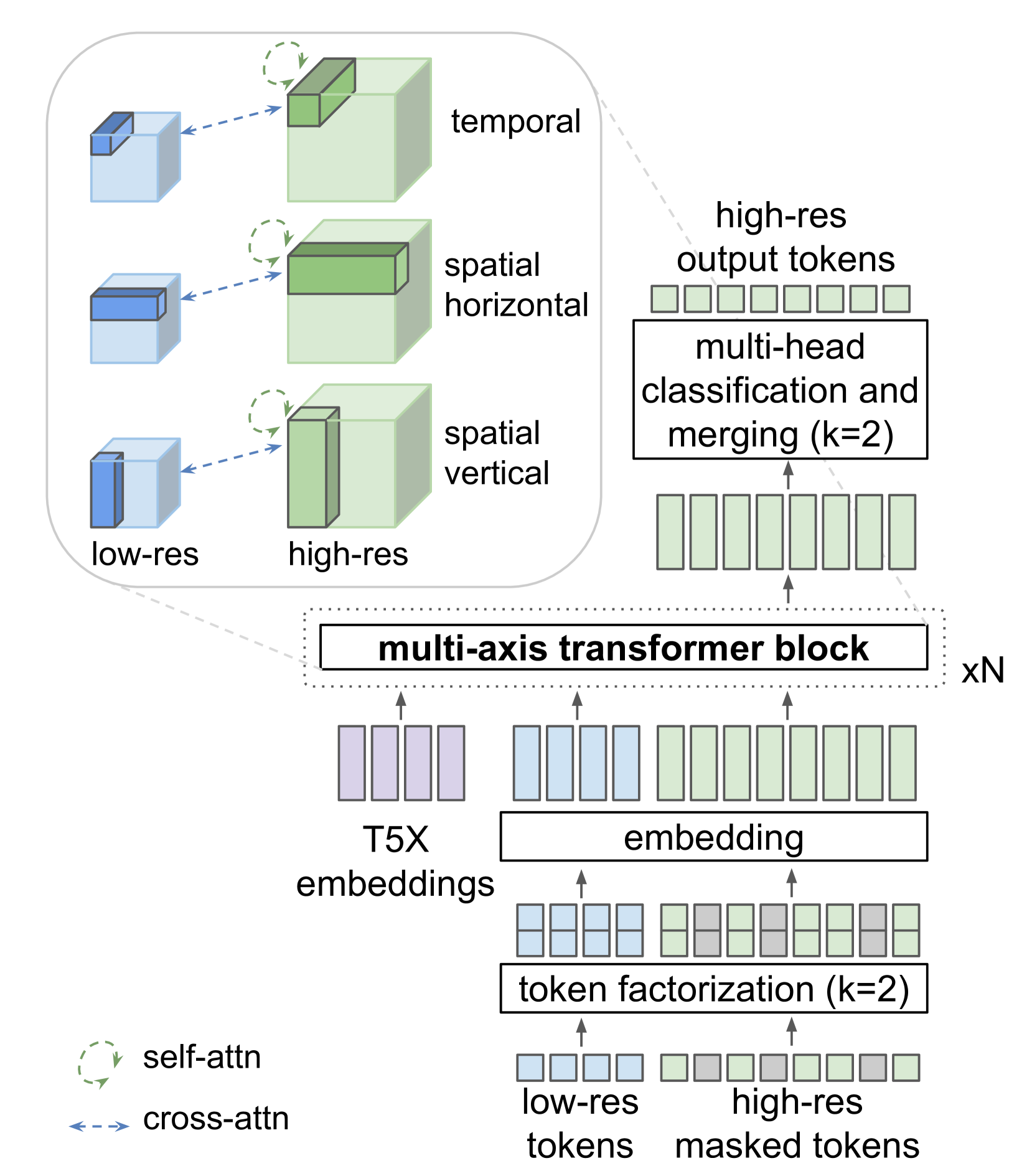
用于视频超分辨率的定制transformer架构. SR transformer由三个transformer层的块组成,每个transformer层在与三个轴之一对齐的局部窗口中执行自注意力:空间垂直、空间水平和时间。交叉注意力层关注低分辨率(LR)标记序列,并且也分为局部窗口,与自注意力层的窗口同构。所有块还包括对 T5 XL 文本嵌入的交叉关注。
五、使用MLLM完成更多任务
5.1 Multimodal Agents - Chaining Multimodal Experts with LLMs
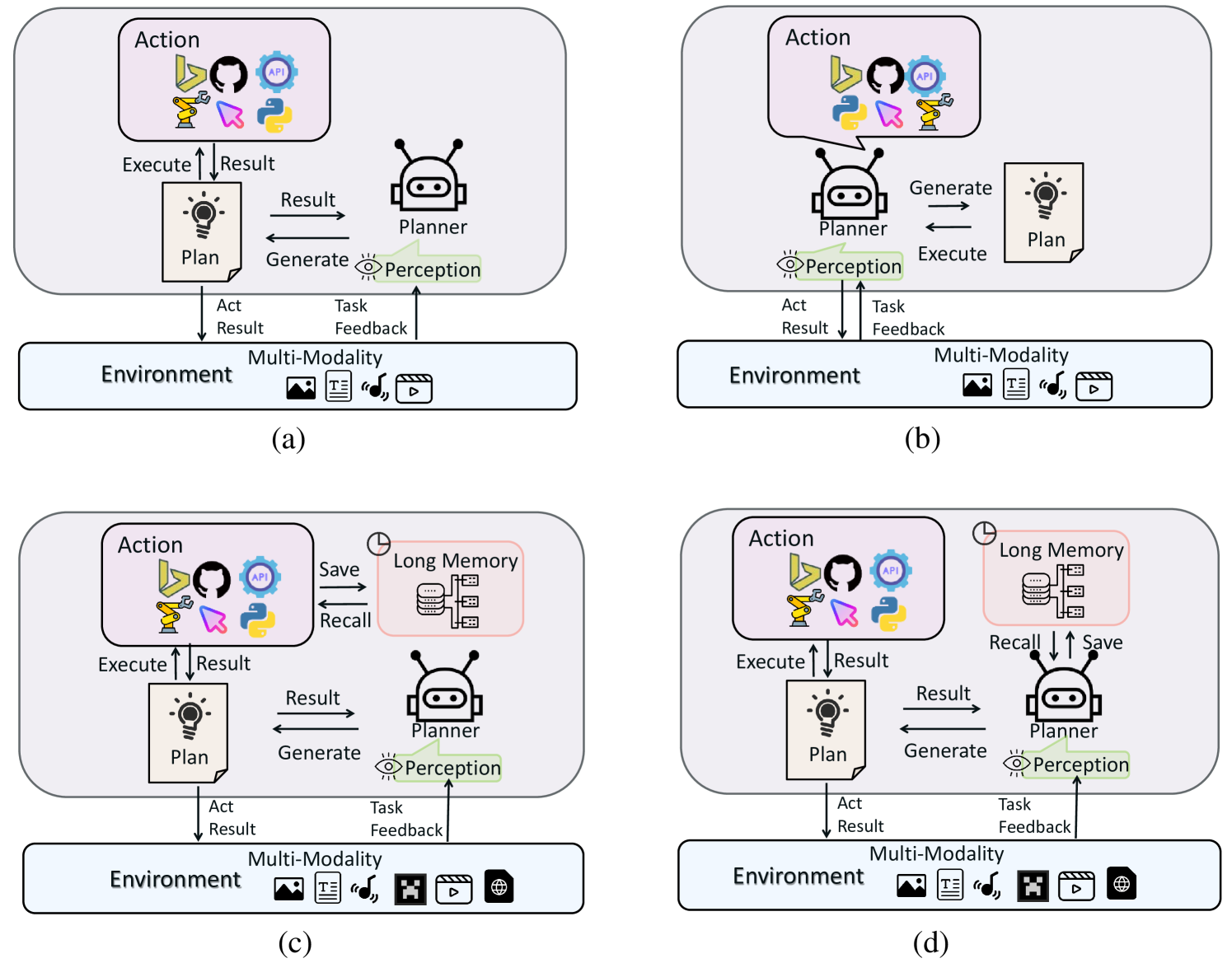
四种类型的 LMA(large multimodal agents) 的说明:
- 类型 I:闭源 LLMs 作为没有长期记忆的planner。他们主要利用提示技术来指导闭源LLMs决策和计划完成任务,无需长记忆。
- 类型 II:微调 LLMs 作为没有长期记忆的planner。他们利用与动作相关的数据来微调现有的开源大型模型,使其能够实现与闭源LLMs相当的决策、规划和工具调用能力。
与(a)和(b)不同,(c)和(d) 引入了长期记忆功能,进一步增强了它们在更接近现实世界的环境中的泛化和适应能力。然而,由于他们的planner使用不同的方法来检索记忆,因此他们可以进一步分为:
- 类型III:具有间接长期记忆的planner;
- 类型IV:具有本地长期记忆的planner。
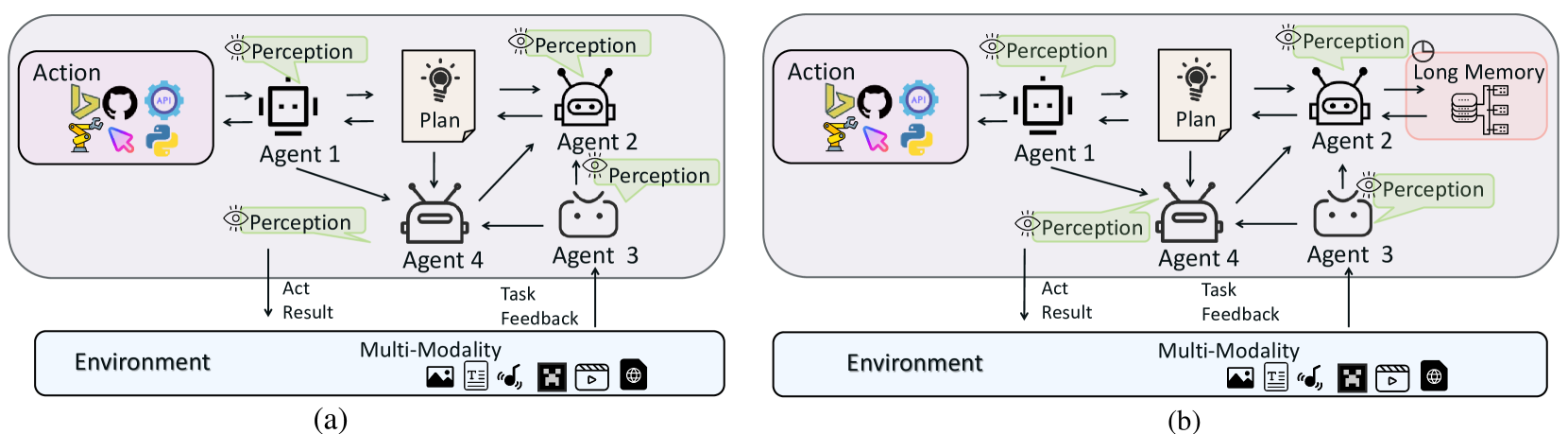
在这两种框架中,面对来自环境的任务或指令,完成依赖于多个智能体的合作。每个智能体负责特定的职责,可能涉及处理环境信息或处理决策和规划,从而分散由单个智能体承担完成任务的压力。框架(b)的独特之处在于其长期记忆能力。
Inspection & Reflection:LMA 在复杂的多式联运环境中始终如一地制定有意义且能完成任务的计划是一项挑战。该组件旨在增强鲁棒性和适应性。一些研究方法将成功的经验存储在长期记忆中,包括多模式状态,以指导规划。在规划过程中,他们首先检索相关经验,帮助规划者深思熟虑,减少不确定性。此外,还有利用人类在不同状态下执行相同任务时制定的计划。当遇到类似的状态时,规划者可以参考这些“标准答案”进行思考,从而得出更合理的规划。DoraemonGPT采用了更复杂的规划方法,如蒙特卡罗,扩大了规划搜索的范围,以找到最优的规划策略。
Planning Methods::现有规划策略可分为动态规划和静态规划两种。前者是指将目标分解为一系列目标基于初始输入的子计划,类似于思想链(CoT),也不会重新制定计划;后者意味着每个计划都是根据当前环境信息或反馈制定的。如果在计划中检测到错误,它将恢复到原始状态以重新规划。
5.2 LLaVA-Plus
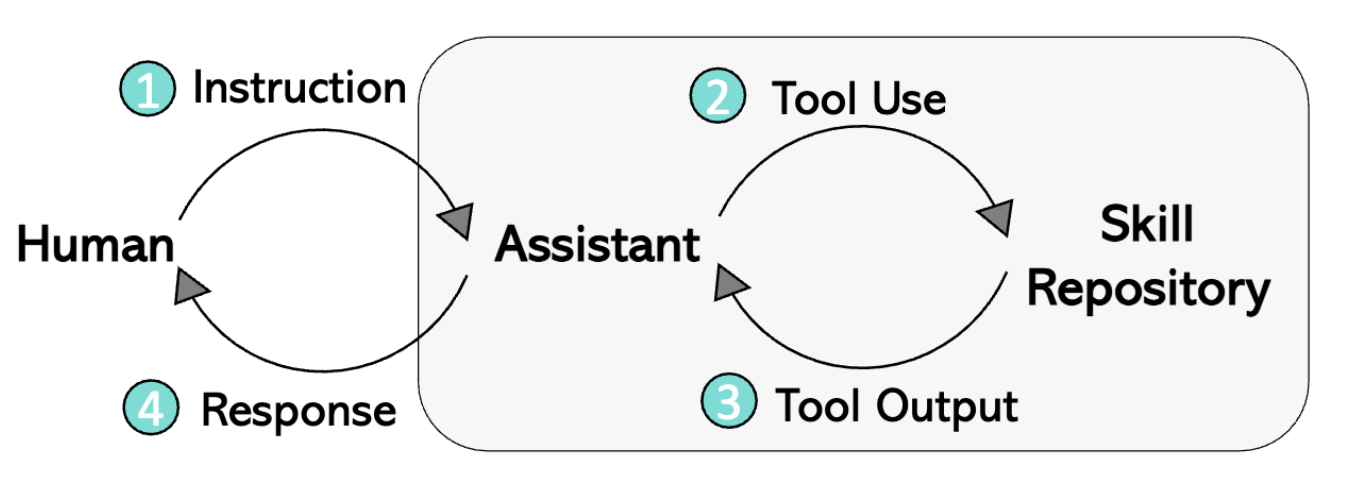
LLaVA Plus的四步过程:
- 用户提供任务文本指令以及相关图片输入
- LLM分析指令和图像,选择是否调用额外的工具完成指令,如果是,则生成调用工具所需要的prompt
- 运行工具,返回工具输出结果给LLM
- LLM汇总工具所输出结果,根据用户事先提供的文本指令和图片输入,生成相应的回复。
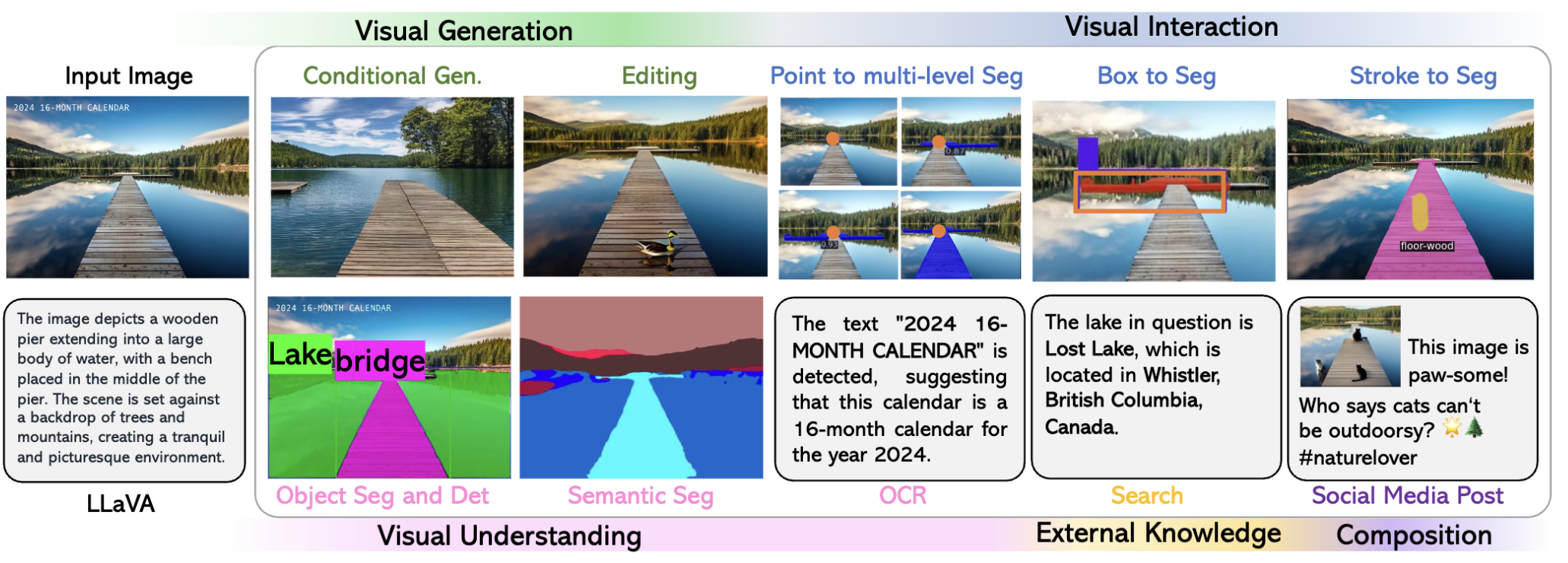
LLaVA-Plus拥有多样化的功能。除了能够处理基本的图像编辑任务,如物体检测、分割、打标签等,它还支持进行复杂的OCR处理和图像美化。此外LLaVA-Plus能够与外部知识进行交互,支持用户与模型的实时交互,如对点击区域进行实例分割等。

LLaVA-Plus 工作流程的示例,该工作流程可插入并学习使用对象检测和分割技能,并通过丰富的区域语言描述得到增强。灰色文本不在训练序列中。
5.3 MM-ReAct

- 要启用图像作为输入,只需使用文件路径作为 ChatGPT 的输入。文件路径充当占位符,允许 ChatGPT 将其视为黑匣子。
- 每当需要特定属性(例如名人姓名或框坐标)时,ChatGPT 都应寻求特定视觉专家的帮助来识别所需信息。
- 专家输出被序列化为文本并与输入结合以进一步激活 ChatGPT。
- 如果不需要外部专家,直接将响应返回给用户。
六、小结
多模态学习的核心在于特征对齐;
多模态大语言模型的本质在于All-to-one(LMM)的特征对齐范式;
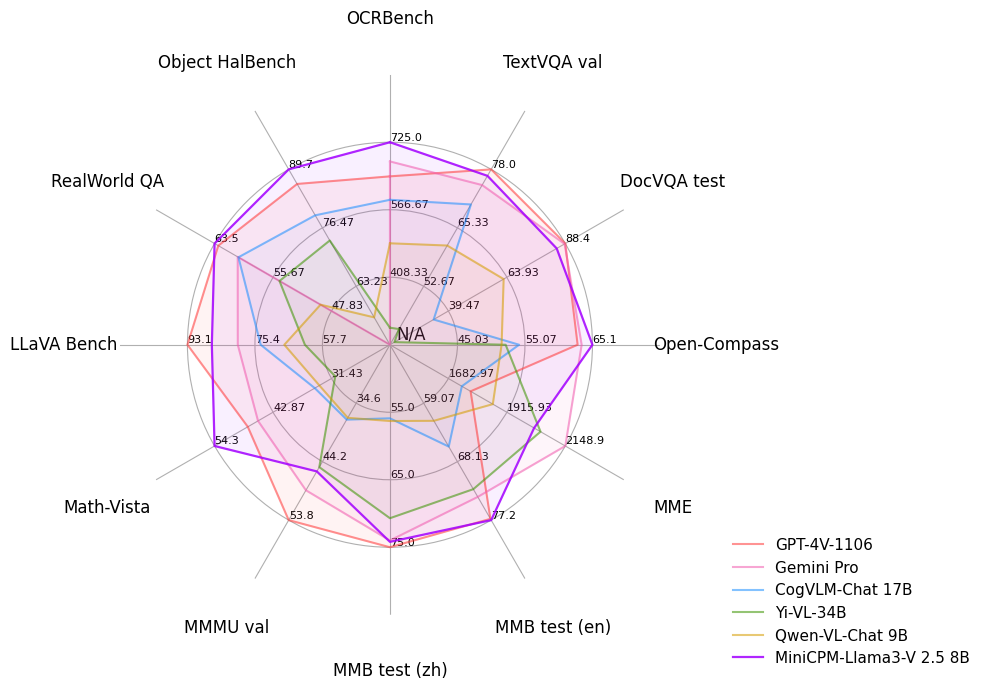
多模态大语言模型正处于飞速发展阶段:相比于LLaVA与textonly GPT4之间的差距,开源多模态大语言模型与GPT4V之间的差距更小。
多模态大模型领域的发展现状:技术发展先于应用,存在更多想象空间。
多模态大模型最全收录:包括多模态指令微调、多模态上下文学习、多模态Agent、多模态数据集等各类信息:https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
多模态大模型榜单:https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
参考
- SadTalker
- Real3DPortrait
- audio2photoreal
- AniPortrait
- GPT-SoVITS
- Seed-TTS
- ChatTTS
- Suno
- [论文解读]Visual bert
- VisualBERT: A Simple and Performant Baseline for Vision and Language
- 自然语言推断任务, 即给出一对(a pair of)句子, 判断两个句子是entailment(相近), contradiction(矛盾)还是neutral(中立)的. 由于也是分类问题, 也被称为sentence pair classification tasks.
- VisualBERT: A Simple and Performant Baseline for Vision and Language
- google-research/vision_transformer
- Vision Transformer详解
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Masked Autoencoders Are Scalable Vision Learners
- 多模态学习(MultiModal Learning)
- openai多模态大模型:clip详解及实战
- Learning Transferable Visual Models From Natural Language Supervision
- CV领域的Open Set和Open World区别在哪
- CLIP 与 SigLIP 文本图像对其算法学习理解
- Sigmoid Loss for Language Image Pre-Training
- medium:Sigmoid Loss for Language Image Pre-Training
- Softmax和Sigmoid应用之——CLIP和SiGLIP
- Cohere For AI - Community Talks: Lucas Beyer
- Gemini: A Family of Highly Capable Multimodal Models
- The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
- Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
- InternLM/InternLM-XComposer
- InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Model
- Fuyu-8B: A Multimodal Architecture for AI Agents
- adept/fuyu-8b
- MiniCPM-V 2.0: 具备领先OCR和理解能力的高效端侧多模态大模型
- OpenBMB/MiniCPM-V
- microsoft/LLaVA-Med
- PKU-YuanGroup/Video-LLaVA
- tingxueronghua/ChartLlama-code
- lxe/llavavision
- haotian-liu/LLaVA
- LLaVA: Visual Instruction Tuning
- LLaVA: Visual Instruction Tuning翻译
- LLaVA-NeXT: Improved reasoning, OCR, and world knowledge
- Improved Baselines with Visual Instruction Tuning
- huggingface InternVL-Chat-V1-5代码
- How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
- Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
- 上采样和下采样
- Is the deconvolution layer the same as a convolutional layer?
- Is (Convolution + PixelShuffle) the same as SubPixel convolution?
- Pixel Shuffle
- MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
- PKU-YuanGroup/MoE-LLaVA
- MoE-LLaVA——将多模态大模型稀疏化
- TinyLLaVA Factory: A Modularized Codebase for Small-scale Large Multimodal Models
- TinyLLaVA/TinyLLaVA_Factory
- phellonchen/X-LLM
- CIF: Continuous Integrate-and-Fire for End-to-End Speech Recognition
- X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages
- CIF:基于神经元整合发放的语音识别新机制
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 【多模态】6、BLIP-2 | 使用 Q-Former 连接冻结的图像和语言模型 实现高效图文预训练
- BLIP-2代码官方实现
- NExT-GPT:Any-to-Any Multimodal Large Language Model
- NExT-GPT/NExT-GPT
- ImageBind: Holistic AI learning across six modalities
- ImageBind: One Embedding Space To Bind Them All
- AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
- NExT-GPT: Any-to-Any Multimodal LLM
- OpenMOSS/AnyGPT
- AnyGPT:Unified Multimodal LLM with Discrete Sequence Modeling
- AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling(Paper)
- High Fidelity Neural Audio Compression
- facebookresearch/encodec
- SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models
- Planting a SEED of Vision in Large Language Model
- VideoPoet: A Large Language Model for Zero-Shot Video Generation(paper)
- SoundStream: An End-to-End Neural Audio Codec(Paper)
- wesbz/SoundStream
- Language Model Beats Diffusion – Tokenizer is Key to Visual Generation
- VideoPoet: A large language model for zero-shot video generation
- VideoPoet
- Large Multimodal Agents: A Survey
- Awesome Large Multimodal Agents
- AppAgent-TencentQQGYLab
- LLaVA-VL/LLaVA-Plus-Codebase
- LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents
- LLaVA-Plus:多模态大模型的新突破
- huggingface llava_plus
- microsoft/MM-REACT
- MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
- 多模态和多模态大模型
(LMM)[译]