DeepSpeed
DeepSpeed是一个深度学习优化软件套件,使分布式训练和推理变得简单、高效和有效。它可以做训练/推理具有数十亿或数万亿参数的密集或稀疏模型;实现出色的系统吞吐量并有效扩展到数千个GPU;在资源受限的GPU系统上进行训练/推理;实现前所未有的低延迟和高吞吐量的推理;以低成本实现极限压缩,实现无与伦比的推理延迟和模型尺寸减小。
一、DeepSpeed简介

DeepSpeed 提供了系统创新的融合,使大规模深度学习训练变得有效、高效,大大提高了易用性,并在可能的规模方面重新定义了深度学习训练格局。 ZeRO、3D-Parallelism、DeepSpeed-MoE、ZeRO-Infinity 等创新属于training支柱。
DeepSpeed 汇集了张量、流水线、专家和 ZeRO 并行等并行技术的创新,并将它们与高性能自定义推理内核、通信优化和异构内存技术相结合,以前所未有的规模实现推理,同时实现无与伦比的延迟、吞吐量和成本降低。这种用于推理的系统技术的系统化组合属于推理支柱。
为了进一步提高推理效率,DeepSpeed 为研究人员和从业人员提供易于使用且组合灵活的压缩技术来压缩他们的模型,同时提供更快的速度、更小的模型大小并显着降低的压缩成本。此外,ZeroQuant 和 XTC 等 SoTA 在压缩方面的创新也包含在压缩支柱下。
DeepSpeed4Science计划,旨在通过人工智能系统技术创新构建独特的能力,帮助领域专家解开当今最大的科学谜团。
- DeepSpeed软件架构
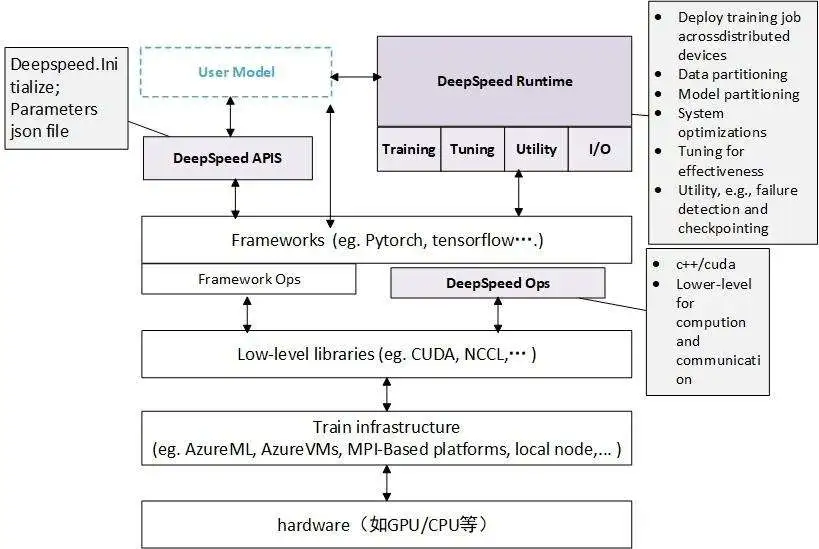
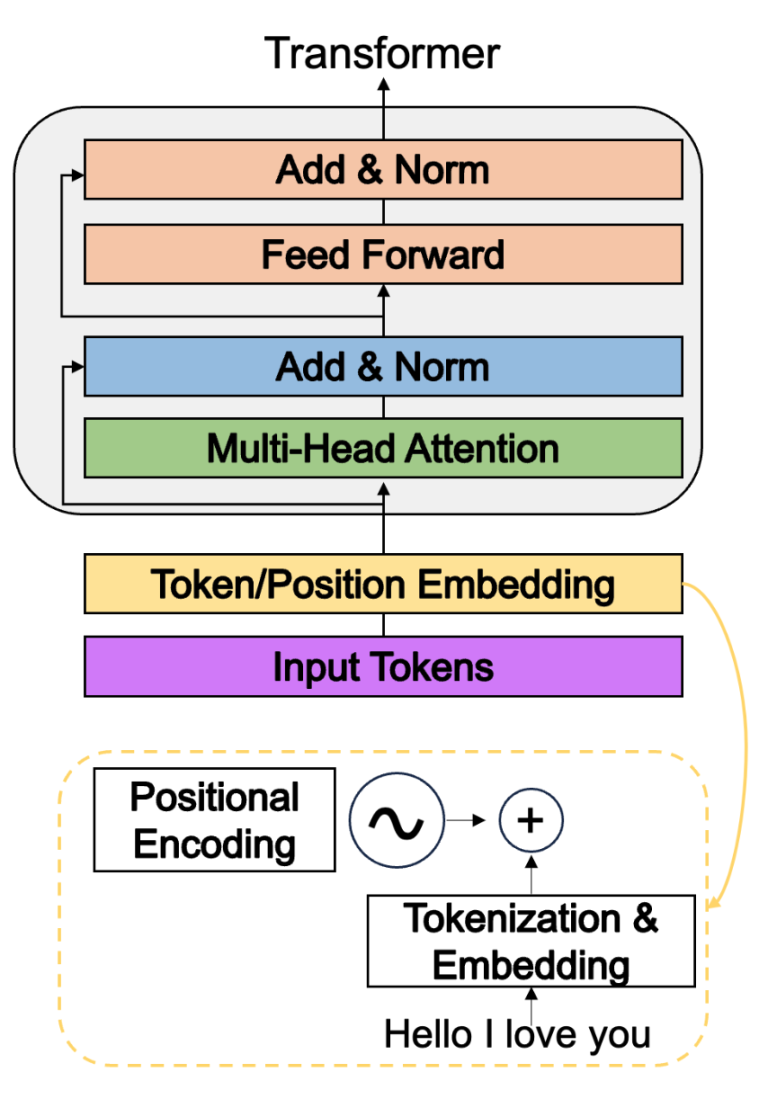
deepspeed在深度学习模型软件体系架构中所处的位置:
deepspeed主要包含三部分:
- APIs:配置参数都在ds_config.json文件中,上层通过简单的API接口就可以训练模型和推断。
- RunTime:DeepSpeed的核心运行时组件,使用Python语言实现,负责管理、执行和优化性能。它承担了将训练任务部署到分布式设备的功能,包括数据分区、模型分区、系统优化、微调、故障检测以及检查点的保存和加载等任务。
- DeepSpeed的底层内核组件,使用C++和CUDA实现。它优化计算和通信过程,提供了一系列底层操作等。
二、 DeepSpeed-Training
2.1 混合精度训练
一个拥有 1.5B 参数的 GPT-2 在使用 FP16 训练时只需要
- Model States 解析:模型本身相关且必须存储的内容,如下所示: (1)Parameters:模型参数 (2)Gradients:模型梯度 (3)Optimizer States:Adam优化算法中的momentum和variance
- Residual States 解析:非模型本身必须,但在训练过程中产生的内容,如下所示: (1)Activation:激活值 (2)Temporary Buffers:临时存储 (3)Unusable Fragmented Memory:碎片化存储空间
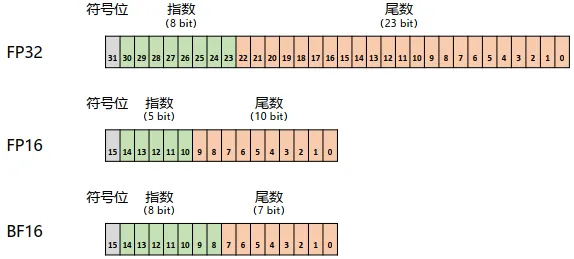
混合精度训练就是一部分参数使用FP32(4B)存储,另一部分参数使用FP16或BF16(2B)存储,以此来减轻存储压力。FP32中第31位为符号位,第30到第23位用于表示指数,第22到第0位用于表示尾数。FP16中第15位为符号位,第14到第10位用于表示指数,第9到第用于表示尾数。BF16中第15位为符号位,第14到第7位用于表示指数,第6到第0位用于表示尾数。如下所示:
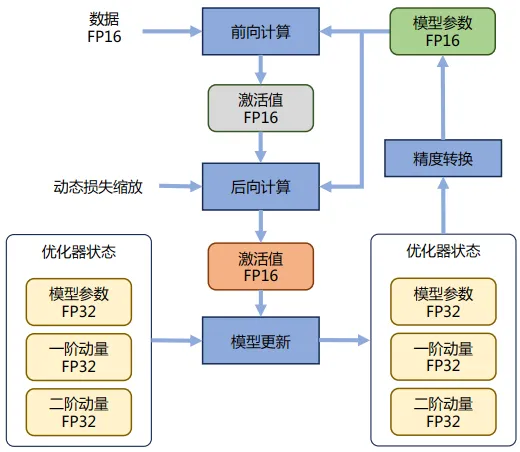
Adam 在 SGD 基础上,为每个参数梯度增加了一阶动量(momentum)和二阶动量(variance)。而混合精度训练,字如其名,同时存在 FP16 和 FP32 两种格式的数值,其中模型参数、模型梯度都是 FP16,此外还有 FP32 的模型参数备份,如果优化器是 Adam,则还有 FP32 的 momentum 和 variance。
假设使用 Adam 优化器并使用混合精度训练。假设模型拥有
如果使用 Adam 优化器和混合精度训练, Optimizer States 占用了整体内存开销的 75%,这导致 Model States 的内存开销为 24GB 远高于用于存储模型的 3GB。
激活值(Activations):用序列长度为 1K、批量大小为 32 去训练 1.5B 参数的 GPT-2 模型需要约 60 GB 的内存。这开销显然是非常大的,一个常见的优化方法是 Activation checkpointing,使用该方法后可以将内存开销降低为 8GB,但是对于极大规模的模型,即使使用 Activation checkpointing 激活内存也会相当的大。
临时存储:当模型大小很大时,由于某些操作/高性能库的原因,会等待装填或者分配一个非常大的融合缓冲区去执行操作,这虽然会带来带宽和效率上的优势,但是有时却成为了内存瓶颈。例如对于一个 1.5B 的模型,一个 FP32 的融合缓冲区将消耗 6GB 的内存。
2.2 ZeRO
2020年,微软DeepSpeed团队通过论文《ZeRO: Memory Optimizations Toward Training Trillion Parameter Models》提出Zero Redundancy Optimizer(简称ZeRO)。
零冗余优化器(ZeRO)是一种用于大规模分布式深度学习的新颖内存优化技术,它可以大大减少模型和数据并行性所需的资源,同时可以大量增加可训练的参数数量。
ZeRO是一系列显存优化方法的统称,它分为ZeRO-DP(Zero Redundancy Optimizer-Data Parallel)和ZeRO-R(Zero Redundancy Optimizer-Reduce)两部分。
2.2.1 ZeRO-DP: Optimizing Model States Memory
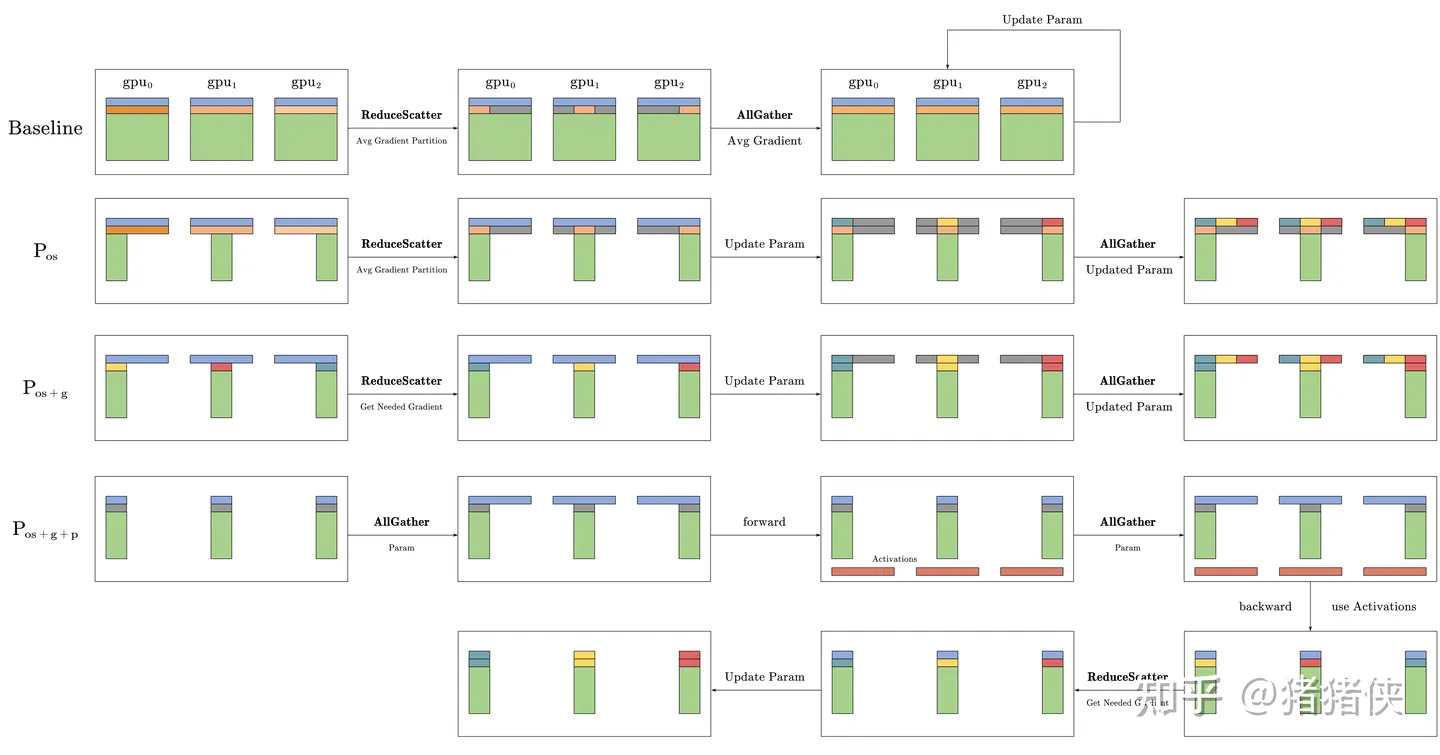
ZeRO-DP 分割 Model States,而不是在某个设备中复制它们,并使用动态通信调度,利用 Model States 的内在时间性质,同时将通信量降到最低。通过这样做,ZeRO-DP 随着DP 并行程度的增加线性减少了每个设备的模型内存占用,同时保持通信量接近基础 DP 的水平(这对效率非常关键)。
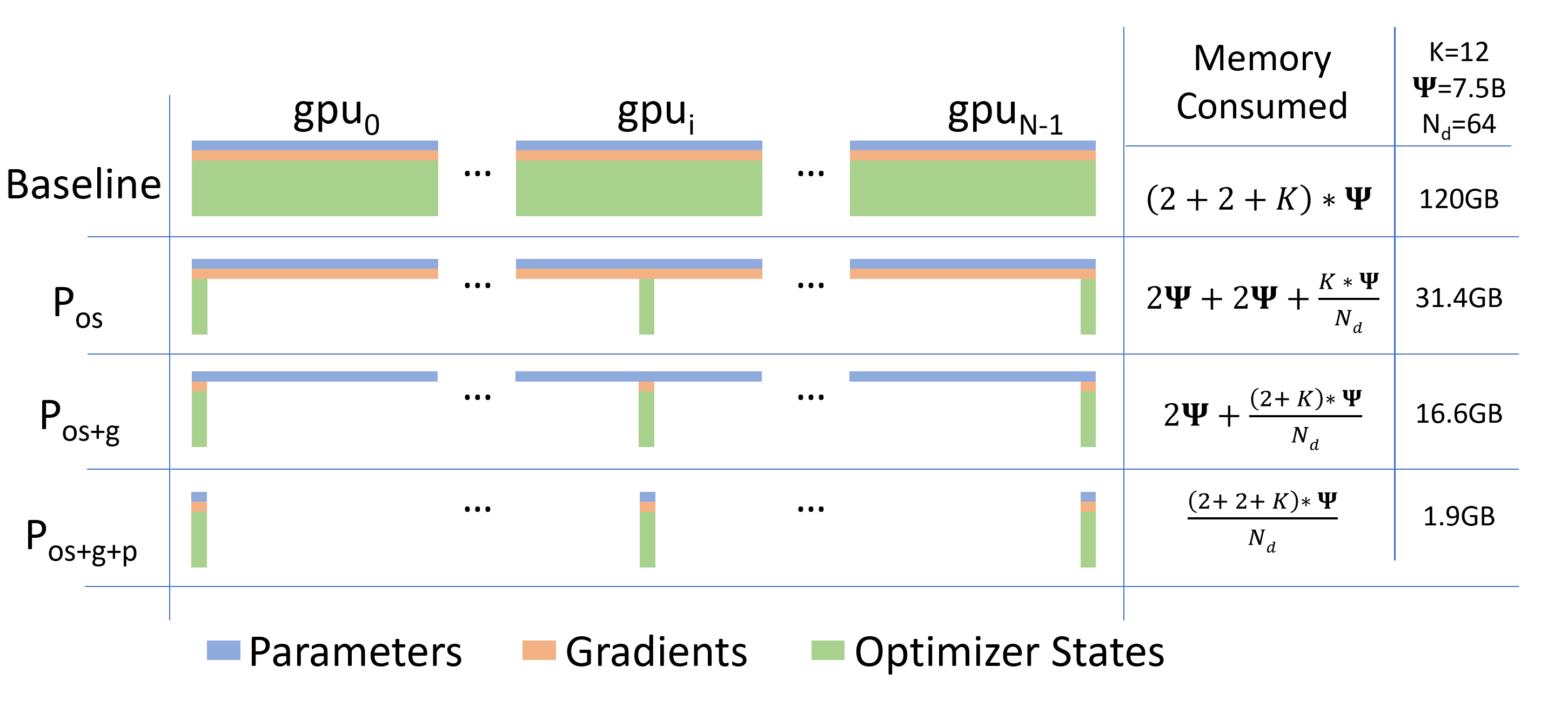
比较模型状态的每设备内存消耗,其中 ZeRO-DP 优化分为三个阶段。
ZeRO-DP 的优化主要分别三层:
: Optimizer State Partitioning
将占用 Model States 比例最高的 Optimizer States划分为
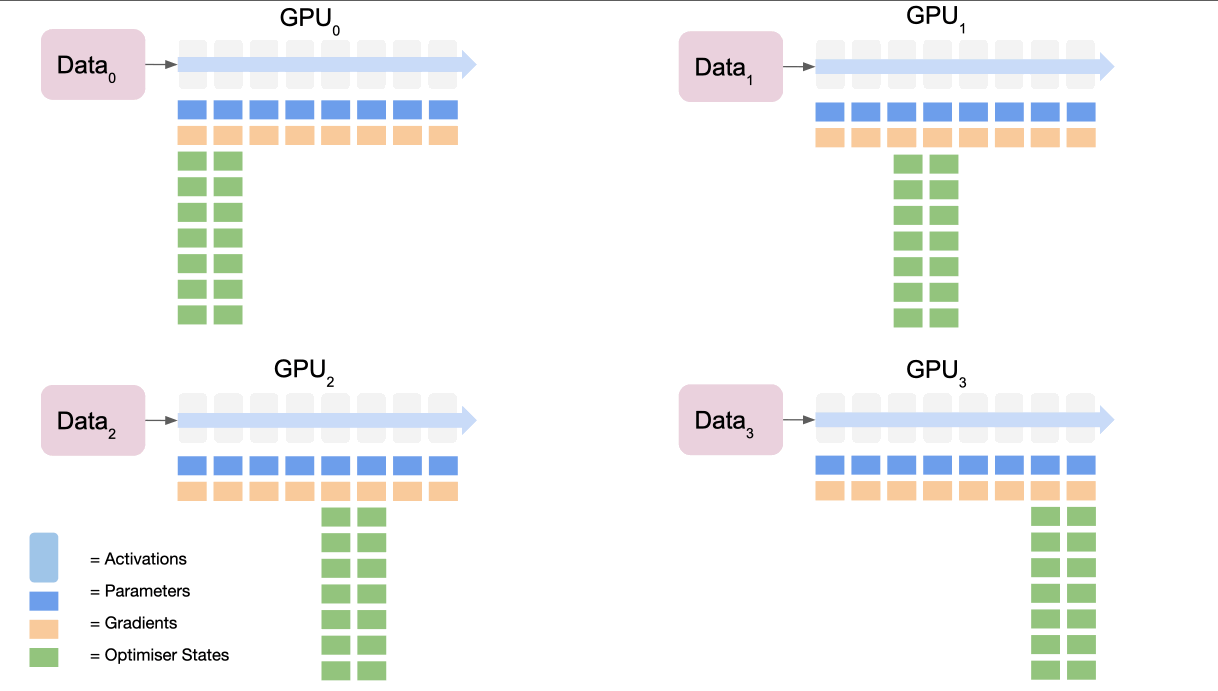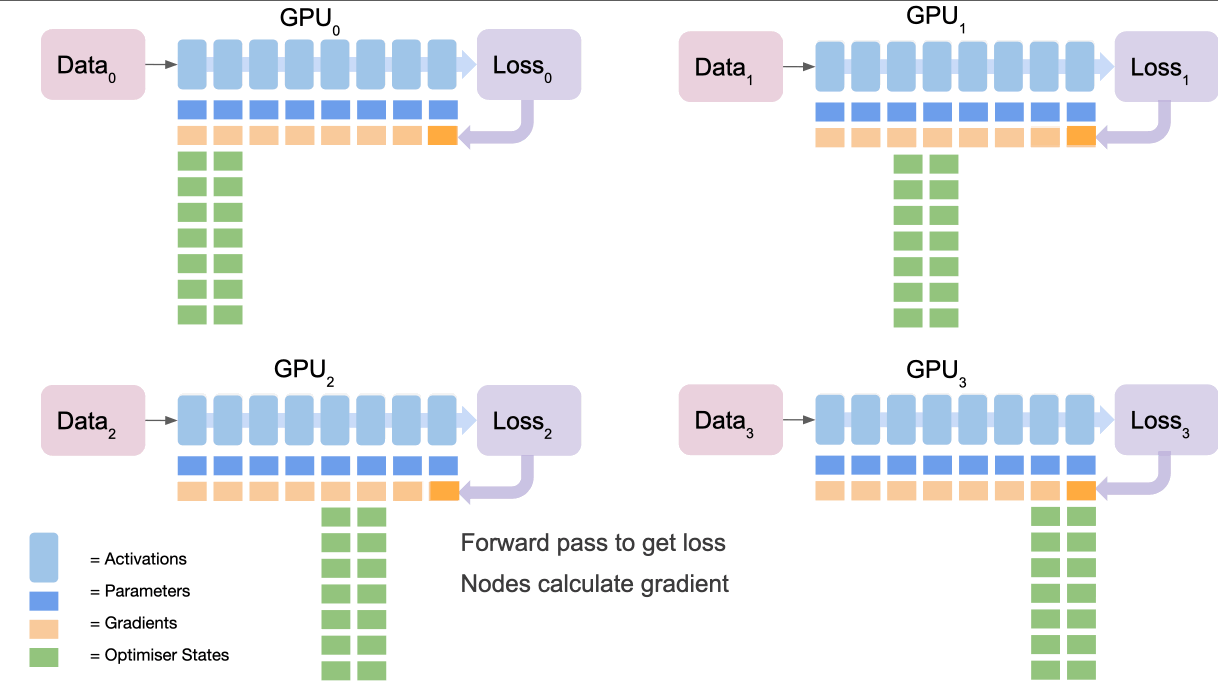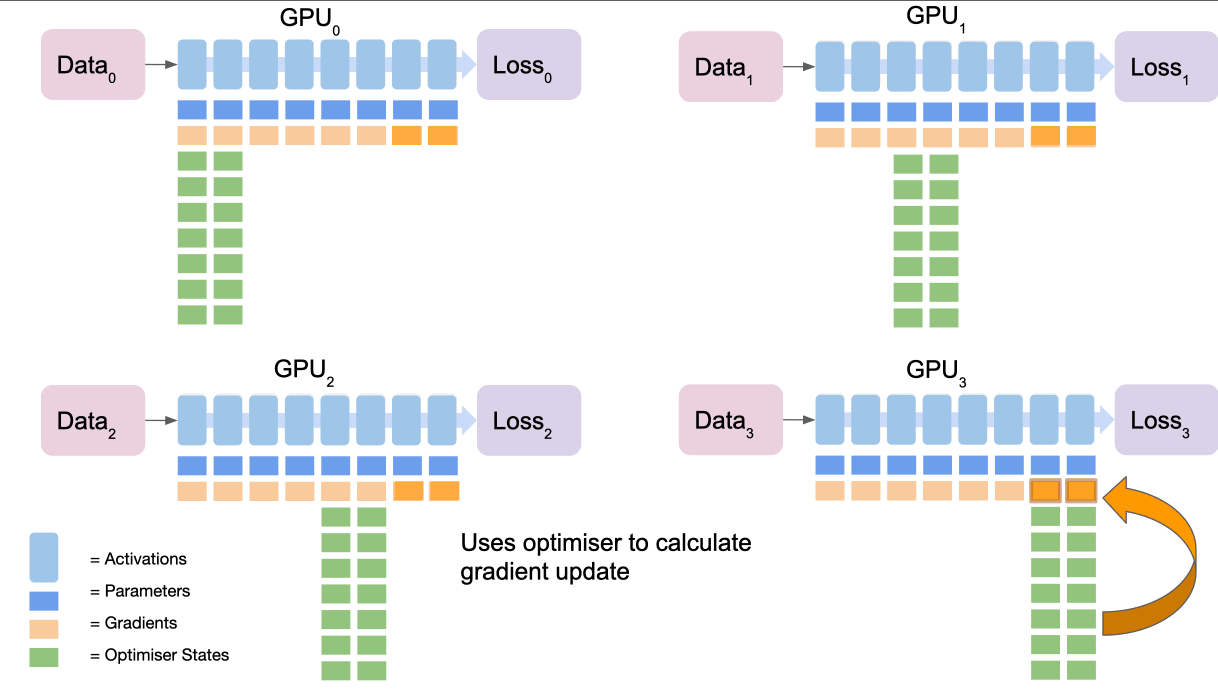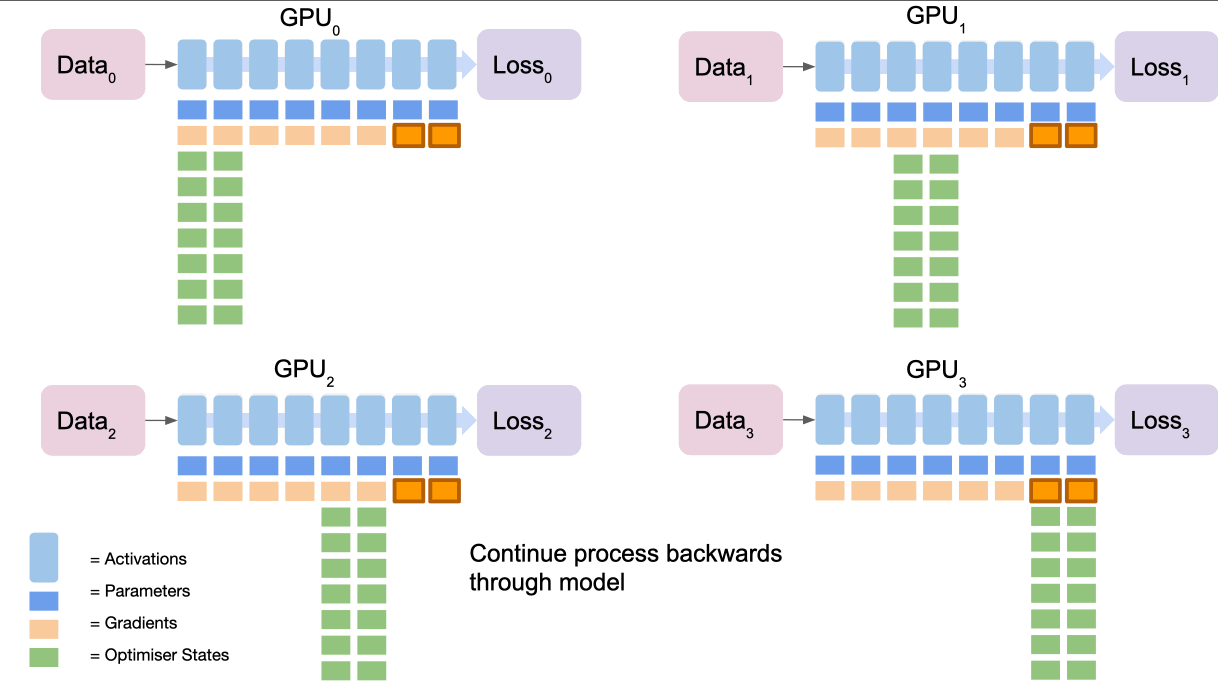
将其视为 5 个步骤的过程:
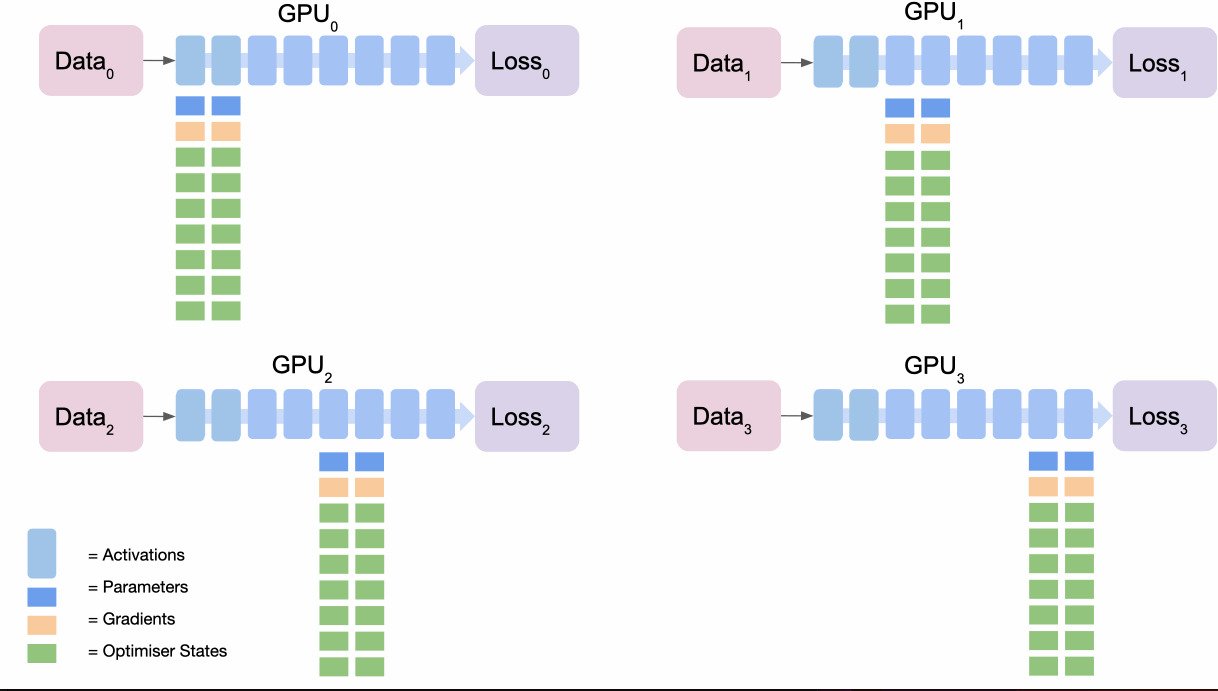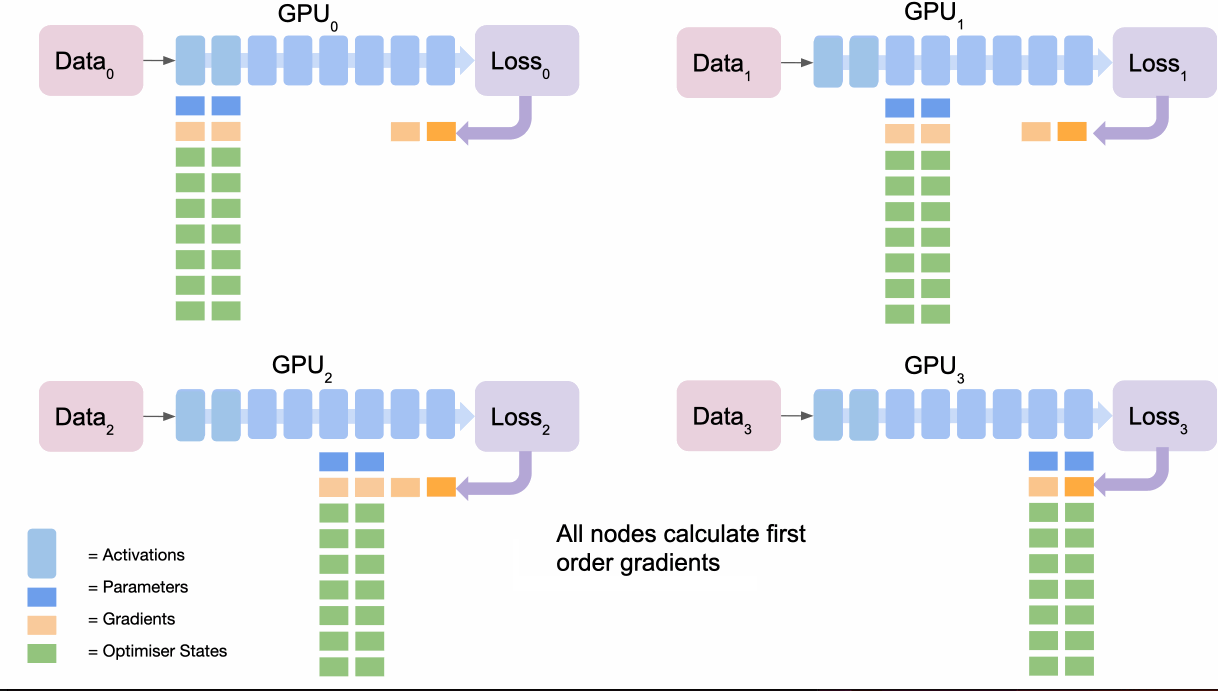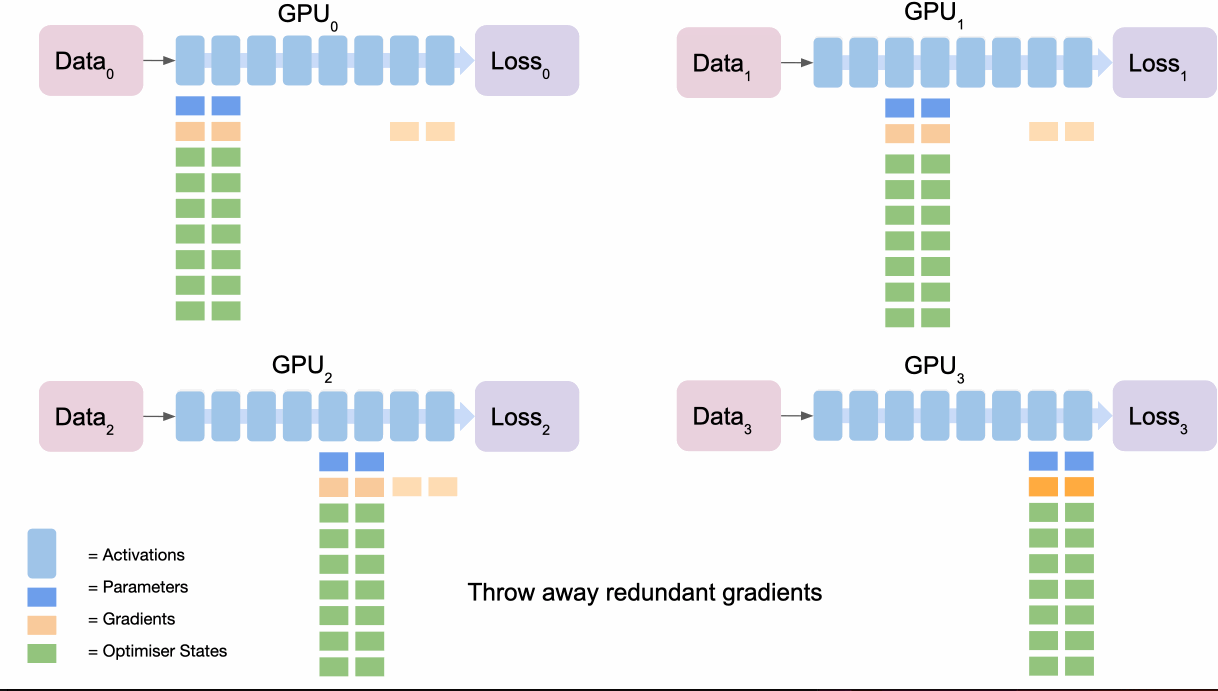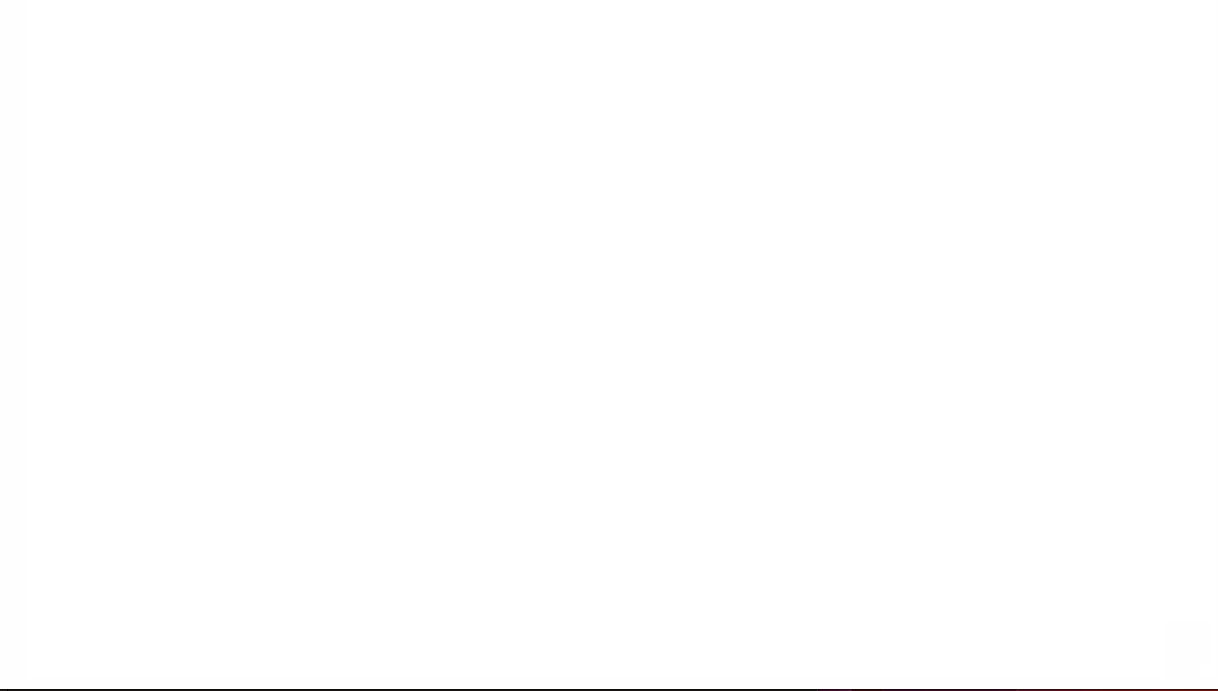
- 所有节点都根据其损失计算梯度,它们都对不同的数据进行了前向传递,因此它们的损失会不同
- 最终节点通过
reduce收集所有节点的梯度并对其进行平均 - 最终节点使用优化器状态计算梯度更新
- 最终节点
broadcasts向所有节点的新gradients。 - 重复倒数第二部分等以完成梯度更新
: Optimizer State Partitioning
同理,在这个部分进行 Gradient 的划分,将其划分为
也就是,通过
: Parameter Paritionging
这具有深远的意义:它代表只要有足够数量的设备来共享 Model States,ZeRO 就可以使 DP 适应任意规模的模型。
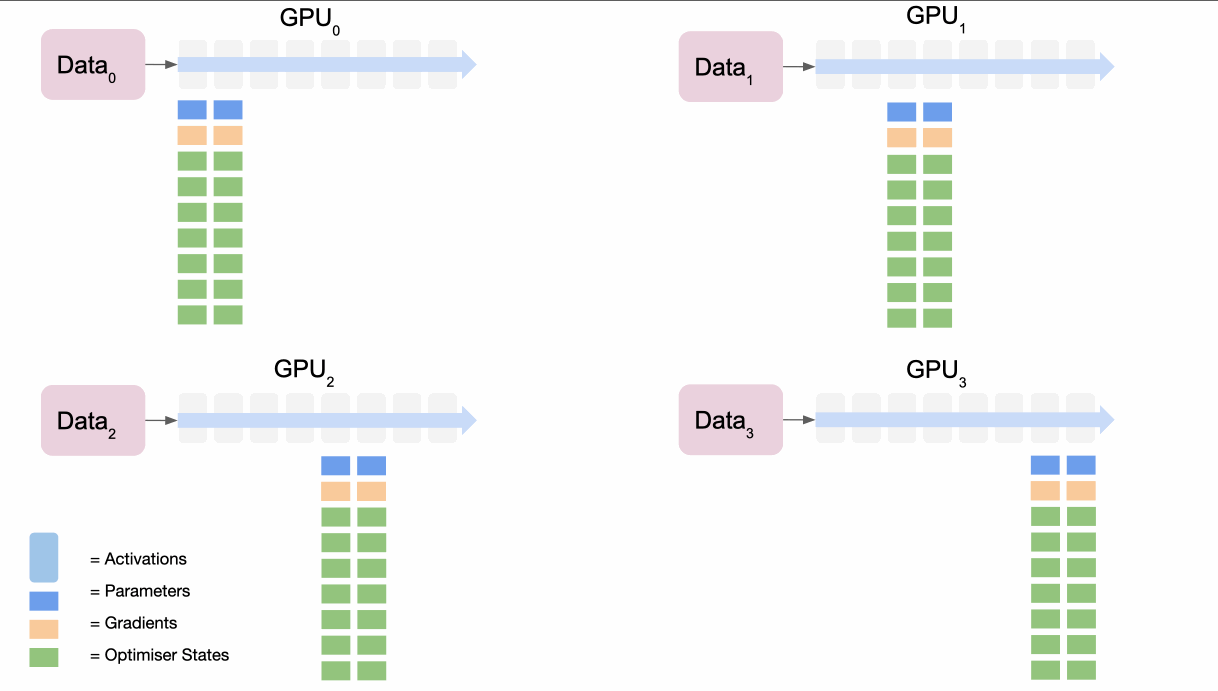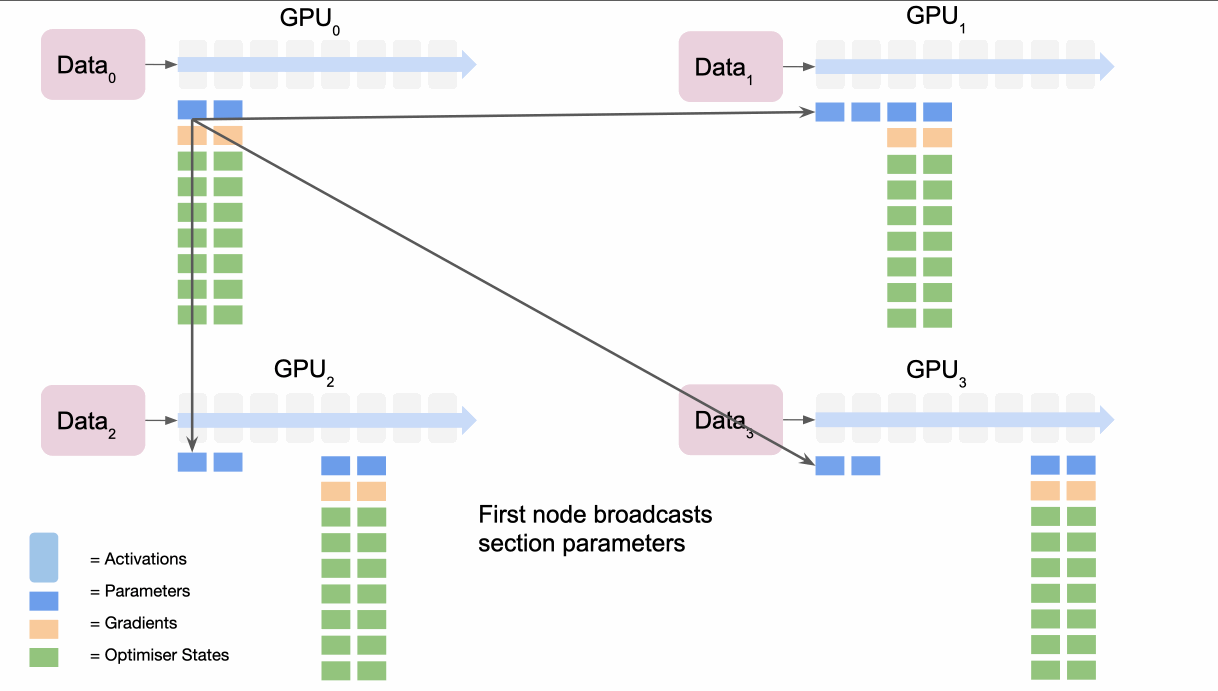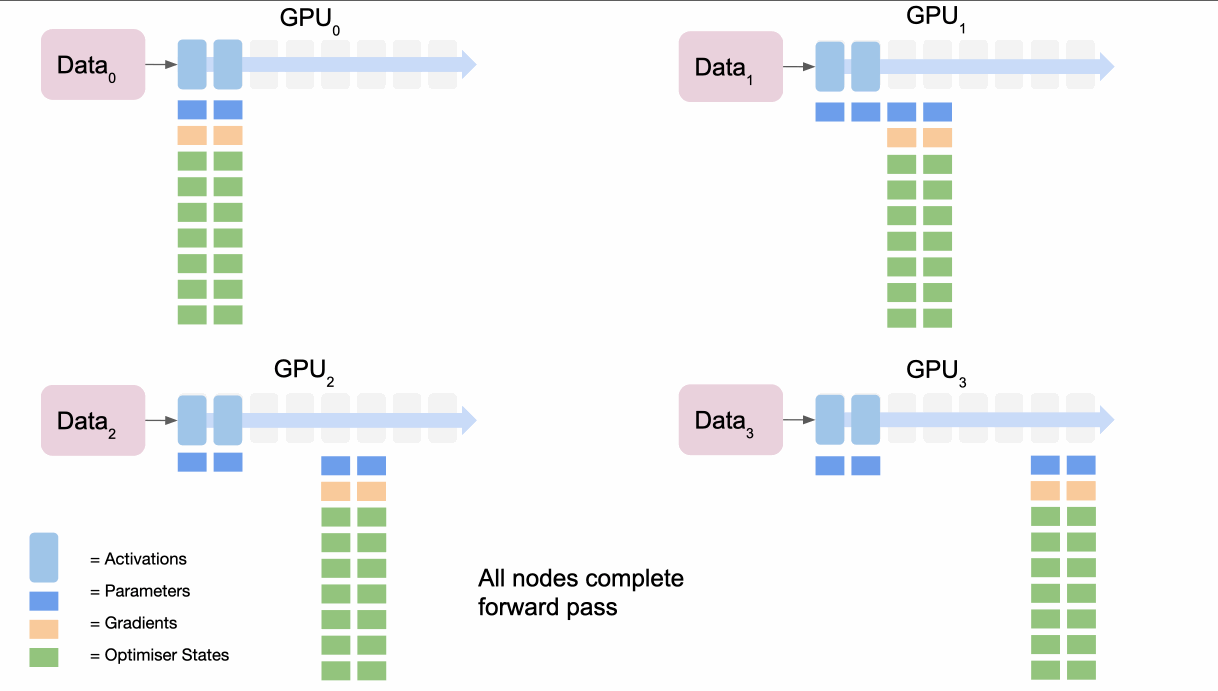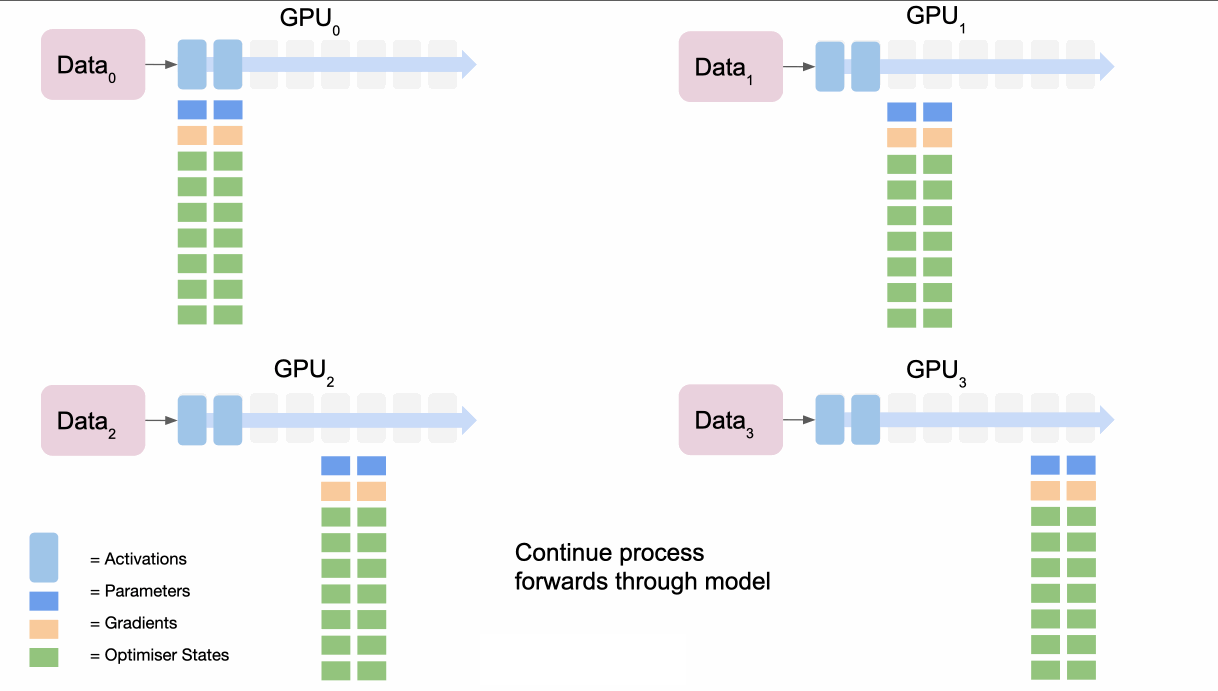
- 第一个节点
broadcasts模型第一部分的参数 - 所有节点都完成模型第一部分数据的前向传递
- 然后他们丢弃模型第一部分的参数
- 重复第二部分等即可得到损失
- 最终节点
broadcasts其梯度 - 每个节点都反向传播自己的损失以获得下一个梯度
- 与之前一样,最终节点累积并平均所有梯度(
reduce),使用优化器计算梯度更新,然后broadcasts结果,可用于下一部分 - 一旦使用,所有梯度都会被不负责该部分的节点丢弃
- 重复倒数第二部分等以完成梯度更新。
- ZeRO-DP通信量分析
标准 DP 通信量分析
在标准的 DP 训练中,在反向传播结束后,所有的 Gradient 会被平均。这个平均的过程使用 AllReduce。对于规模极大的模型,AllReduce 通信是整个通信带宽的瓶颈,因此分析主要集中在 AllReduce 上。因此,我们将分析限制为发送至每个 DP 进程和来自每个 DP 进程的总通信量。
而 AllReduce 实际上是分为 ReduceScatter 和 AllGather
两步操作的这两步如果我们都使用最优的实现方式也就是:Ring-RedcueScatter
和 Ring-AllGather,那么单个设备在 Ring-RedcueScatter 或者 Ring-AllGather
的过程中,都会有
由于
每张显卡实际上拥有完整的Gradient,但是由于 Optimizer States
的分区,每个显卡只需要一部分 Gradient。这里实际上每张卡都冗余存储了
Gradient。 这也是为什么
由于对 Gradient 进行了分区,在更新参数前,先通过 ReduceScatter 把每个
Optimizer States 所需要的 Gradient
发送到对应的设备上。所以,这个操作的通信量仍然是
每个分区好的 Optimizer Sates 获得对应的 Gradient
更新其参数后,只需要执行一次
AllGather,把自己更新的模型参数发出去并收集别人更新的模型参数,这同样是
由于对参数进行了分区,那么一个显而易见的实时是在前向和反向传播阶段都需要一次 AllGather 来进行保证计算的正确。值得说明的是,模型参数的分发是按神经网络的计算顺序去流水线分发的,因为如果不考虑计算的过程直接分发会导致一些参数被多次的分发并直接丢弃。从整宏观的角度来看,相当于每次训练需要多两次 AllGather 操作。由于模型参数恰好也分区了,所以不需要更新完参数后通过 AllGather 去共享模型参数了。只需要在更新参数前,使用 ReduceScatter 把对应的 Gradient 进行分发。
综上,总的通信量为
2.2.2 ZeRO-R: Optimizing Residual States Memory
- 激活检查点(Partitioned Activation Checkpointing),activation的存储非常灵活,更需要设计好实验。
- 临时缓冲区(Constant Size Buffer),固定大小的内存Buffer。
- 空间管理(Memory Defragmentation),主要是将碎片化内存空间重新整合为连续存储空间。
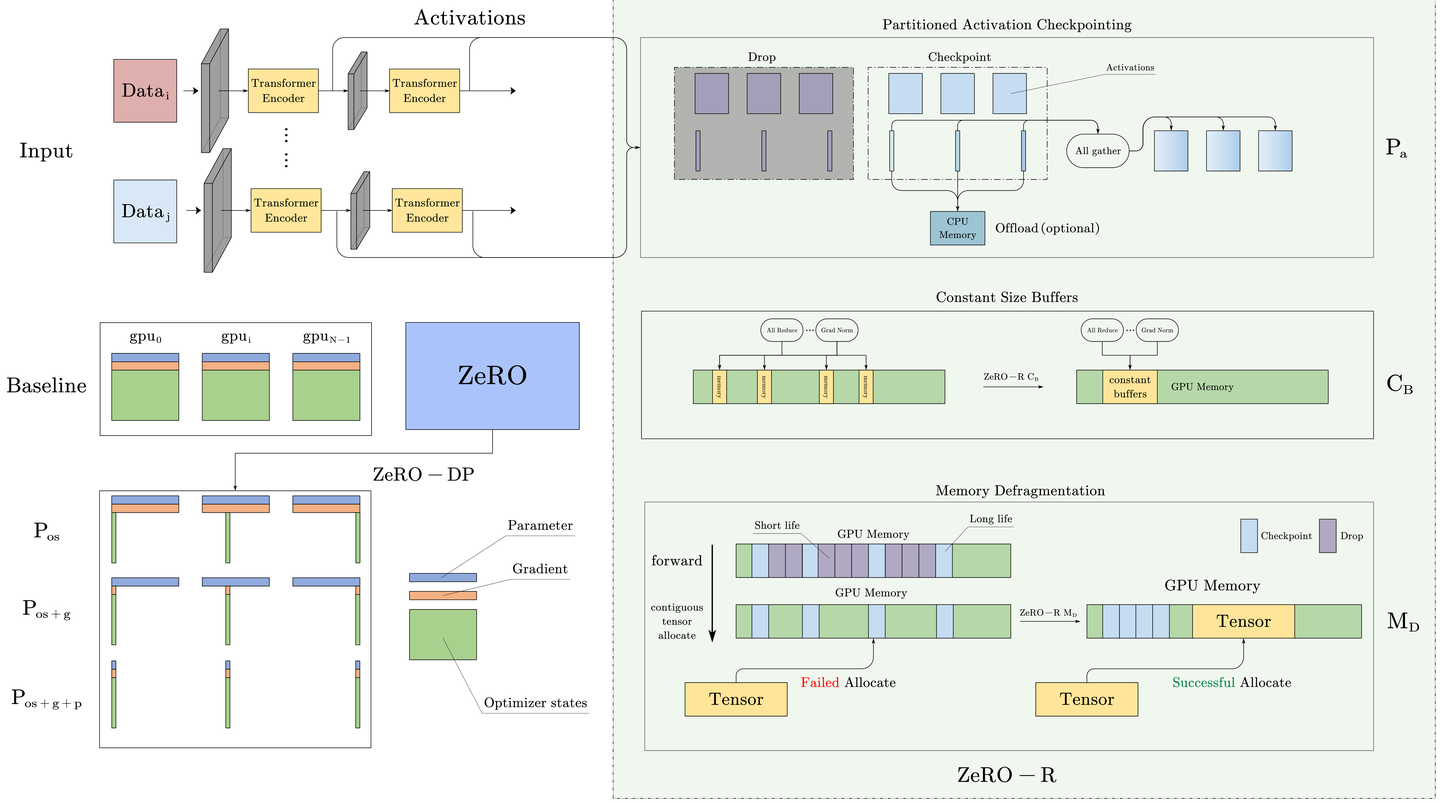
:Partitioned Activation Checkpointing
ZeRO 同样通过 Activations
分区来降低内存冗余。结合图进行描述,一旦计算出模型层的前向传播,输入
Activation 就会在所有 MP
进程中进行分区,直到在反向传播期间再次需要它为止(参考紫色和蓝色的色块)。此时,ZeRO
使用 AllGather 操作来重新实现Activation
的复制副本。我们将此优化称为
设 MP 中设备数/程度为
:Partitioned Activation Checkpointing
ZeRO-R 使用恒定大小的缓冲区来避免临时缓冲区随着模型大小的增加而爆炸,同时使缓冲区足够大以保持效率。因为,当模型大小很大时,由于某些操作/高性能库的原因,会等待装填或者分配一个非常大的融合缓冲区去执行操作,这虽然会带来带宽和效率上的优势,但是有时却成为了内存瓶颈。例如对于一个 1.5B 的模型,一个 FP32 的融合缓冲区将消耗 6GB 的内存。这显然是无法接受的,速度慢是可以接受的,无法训练是难以接受的。
:Memory Defragmentation
为什么会产生内存碎片进行了简单的介绍。其中主要是:Activations
Checkpoints 和 Gradient 的生命周期太长导致的。ZeRO-R 通过为 Checkpoints
和 Gradient
预先分配连续的内存块(如图所示,蓝色色块被聚合在一起代表
Checkpoint
放在连续内存中),并在生成时将它们复制到预先分配的内存中,即时进行内存碎片整理,并将该优化命名为
2.2.3 ZeRO-Offload
论文:<<ZeRO-Offload: Democratizing Billion-Scale Model Training>>
ZeRO-Offload的切分思路是:
图中有四个计算类节点:FWD、BWD、Param
update和float2half,前两个计算复杂度大致是
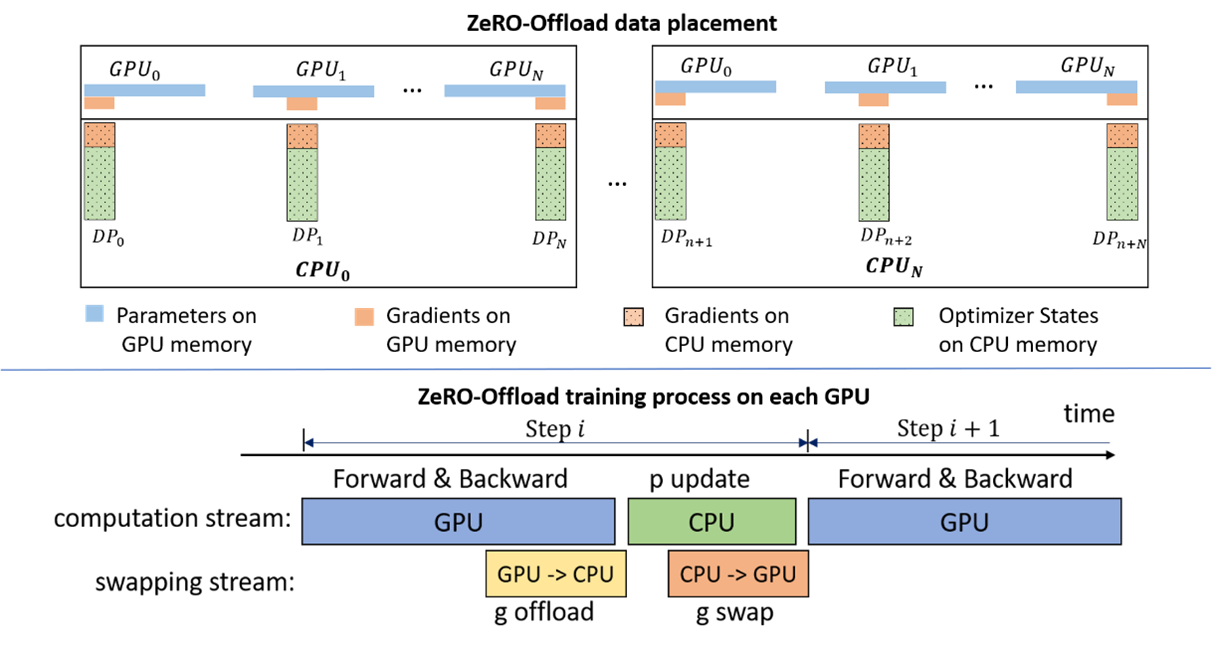
现在的计算流程是,在GPU上面进行前向和后向计算,将梯度传给CPU,进行参数更新,再将更新后的参数传给GPU。为了提高效率,可以将计算和通信并行起来,GPU在反向传播阶段,可以待梯度值填满bucket后,一边计算新的梯度一边将bucket传输给CPU,当反向传播结束,CPU基本上已经有最新的梯度值了,同样的,CPU在参数更新时也同步将已经计算好的参数传给GPU,如下图所示。
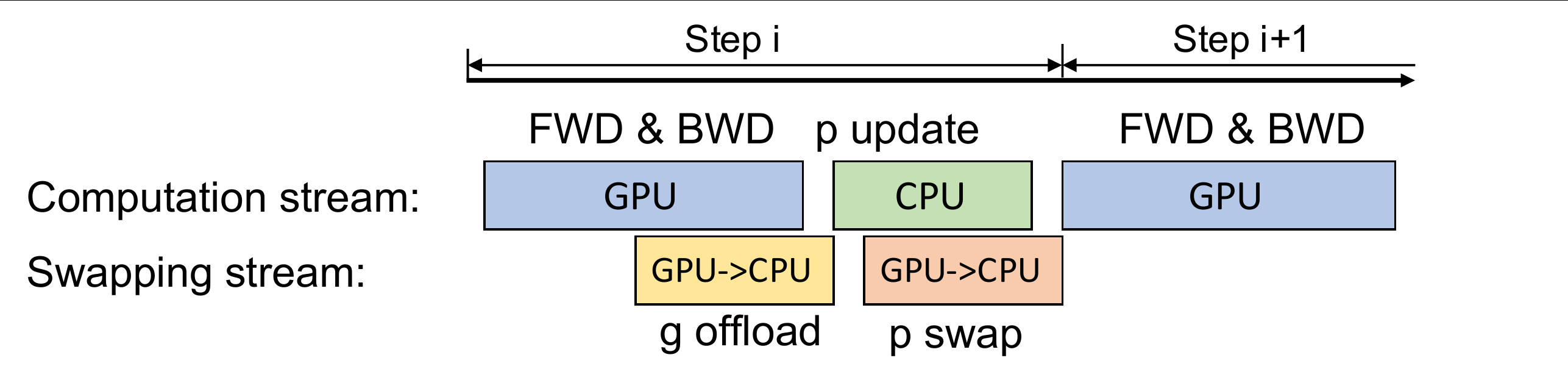
在多卡场景,ZeRO-Offload利用了ZeRO-2,回忆下ZeRO-2是将Adam状态和梯度进行了分片,每张卡只保存
并且CPU和GPU的通信量和
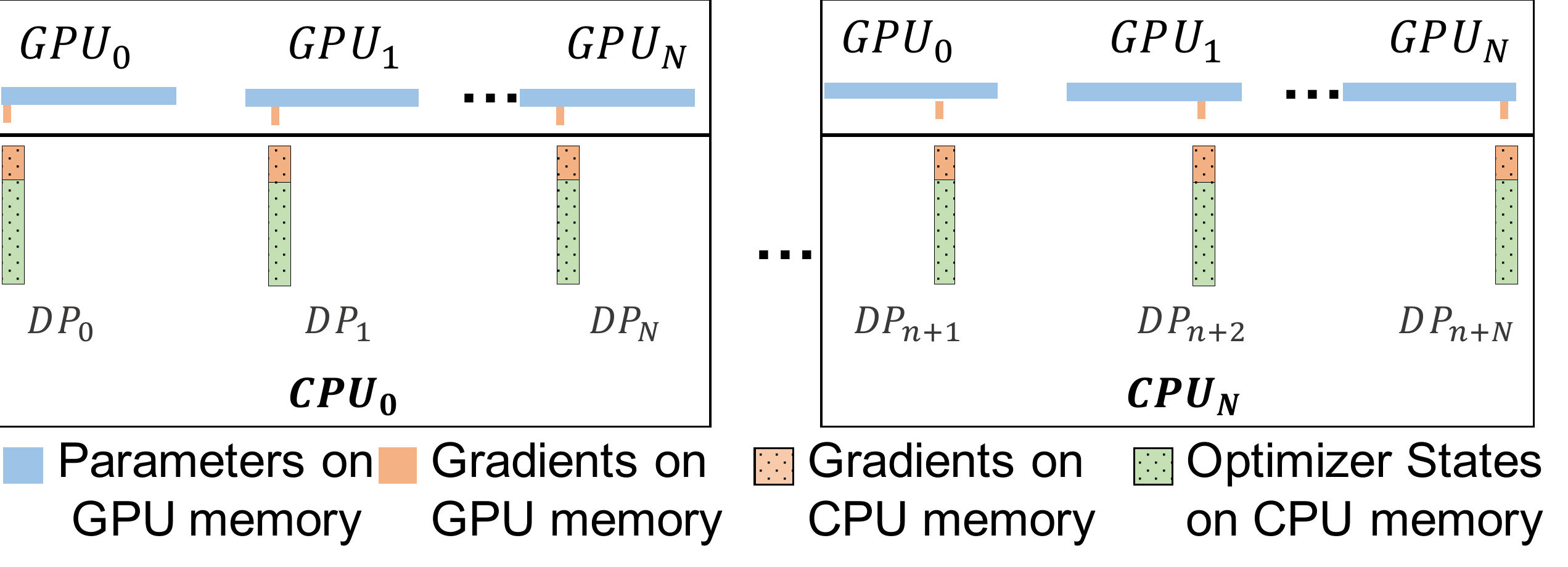
ZeRO-Offload 不在每块 GPU 上保持优化器状态和梯度的分割,而是将二者卸载至主机 CPU 内存。在整个训练阶段,优化器状态都保存在 CPU 内存中;而梯度则在反向传播过程中在 GPU 上利用 reduce-scatter 进行计算和求均值,然后每个数据并行线程将属于其分割的梯度平均值卸载到 CPU 内存中(参见下图 g offload),将其余的抛弃。一旦梯度到达 CPU,则每个数据并行线程直接在 CPU 上并行更新优化器状态分割(参见下图 p update)。
之后,将参数分割移回 GPU,再在 GPU 上执行 all-gather 操作,收集所有更新后的参数(参见下图 g swap)。
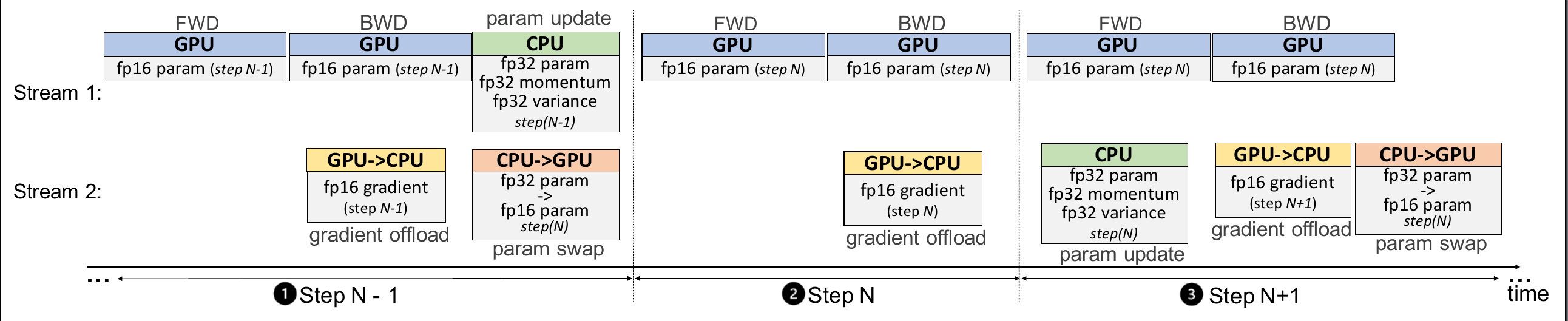
ZeRO-Offload 专为使用 Adam 的混合精度训练而设计。也就是说,当前版本的 ZeRO-Offload 使用 Adam 的优化版本 DeepCPUAdam。其主要原因是避免 CPU 计算成为整个过程中的瓶颈。DeepCPUAdam 的速度是 Adam PyTorch 实现的 6 倍。
同时,文章进一步提出了One-Step Delayed,在模型后期得到了充分的收敛后,CPU的参数计算和更新可以放到下一轮迭代期间完成。当然,这会带来振荡的收敛,但是同时也大幅度的稀释了CPU计算的时间,论文中有证明在模型训练的后期开启该方案是可行的,虽然会带来一定的振荡,但总体不会对训练的收敛效果产生影响。
2.2.4 ZeRO-Infinity
论文:<<ZeRO-Infinity:Breaking the GPU Memory Wall for Extreme Scale Deep Learning>>
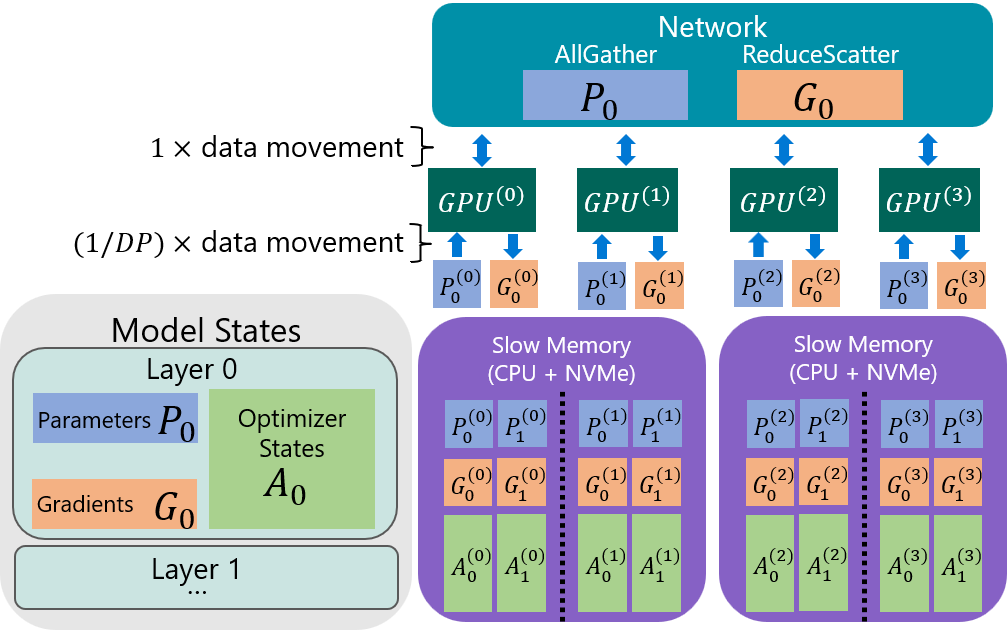
ZeRO-Infinity 在四个数据并行 (DP)
列上训练具有两层的模型的快照。描述了第一层的向后传递的通信。分区参数从慢速内存移动到
GPU,然后收集以形成完整层。计算梯度后,它们被聚合、重新分区,然后卸载到慢速内存。层用下标表示,DP
等级用上标表示。例如,
ZeRO-Infinity的设计分为几个关键点:
解决超大规模的设计(Design for Unprecedented Scale)
- Infinity offload engine for model states:用到了ZeRO-DP的
模式,把模型状态都进行了分区,并且所有模型参数存储都放到了CPU或者NVME上 - CPU Offload for activations:激活值的ckpt也放到了CPU内存中
- Memory-centric tiling for working memory:可以简单理解为把大张量的计算拆分成多个较小的线性算子序列,用时间换空间的方式防止显存不够用
解决训练效率的设计(Design for Excellent Training Efficiency)
- Efficiency w.r.t Parameter and Gradients:提出一种基于带宽的划分策略来提高参数和梯度的传递效率,并允许通过PCIe的重叠通信
- Efficiency w.r.t Optimizer States:其实就是基于ZeRO-Offload的优化器状态参数传递策略,CPU一边计算参数一边并行传递给GPU,不过在这里用NVME offload时需要经过一次NVME
- Efficiency w.r.t Activations:也是基于ZeRO-Offload的激活值传递策略,每个GPU通过PCIe并行写数据到CPU,可以超过80%的效率,很显然如果减少激活值ckpt的频率的话也能提升该效率(代价就是增加激活值重算的时间)
解决易用性的设计(Design for Ease of Use)
其实就是基于PyTorch在代码层封装好了各种算子操作(如reduce-scatter和all-gather等),不需要用户自行再写相关的代码了
- automated data movement:自动在FWD和BWD后触发收集和分区的相关操作,把数据同步到CPU或者NVME
- automated model partitioning during initialization:初始化时自动分区模型和参数
视频展示了 ZeRO-Infinity 如何通过以下方式有效地利用 GPU、CPU 和 NVMe:1) 在所有数据并行进程中对每个模型层进行分区,2) 将分区放置在相应的数据并行 NVMe 设备上,以及 3) 协调计算前向/后向传播和计算所需的数据移动分别对数据并行 GPU 和 CPU 进行权重更新。
2.2.5 ZeRO++
论文:<<ZeRO++: Extremely Efficient Collective Communication for Giant Model Training>>

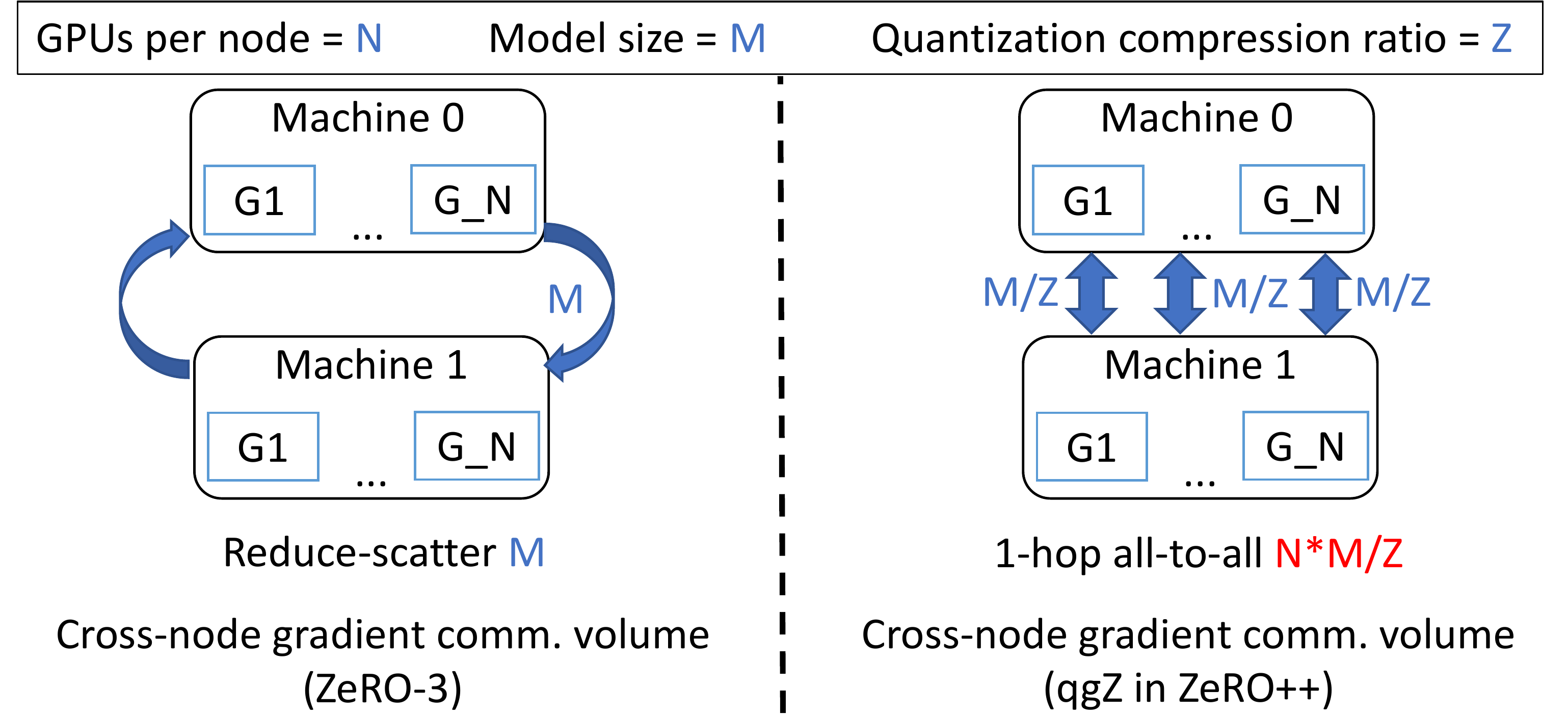
ZeRO 是数据并行(Data Parallelism)的一种内存高效版本,其中模型状态会被分割储存在所有 GPU 上,而不需要在训练期间使用基于gather/broadcas的通信进行复制和重建。这使 ZeRO 能够有效地利用所有设备的聚合 GPU 内存和计算力,同时提供简单易用的数据并行训练。
假设模型大小为 M。在前向传播过程中,ZeRO 执行全收集/广播(all-gather/broadcast)操作以在需要之时为每个模型层收集参数(总共大小为 M)。 在向后传递中,ZeRO 对每一层的参数采用类似的通信模式来计算其局部梯度(总大小为 M)。 此外,ZeRO 在对每个局部梯度计算完毕后会立刻使用 reduce 或 reduce-scatter 通信进行平均和分割储存(总大小为 M)。 因此,ZeRO 总共有 3M 的通信量,平均分布在两个全收集/广播(all-gather/broadcast)和一个减少分散/减少(reduce-scatter/reduce)操作中。
为了减少这些通信开销,ZeRO++ 进行了三组通信优化,分别针对上述三个通信集合:
- ZeRO通信过程中的权重量化 (qwZ)
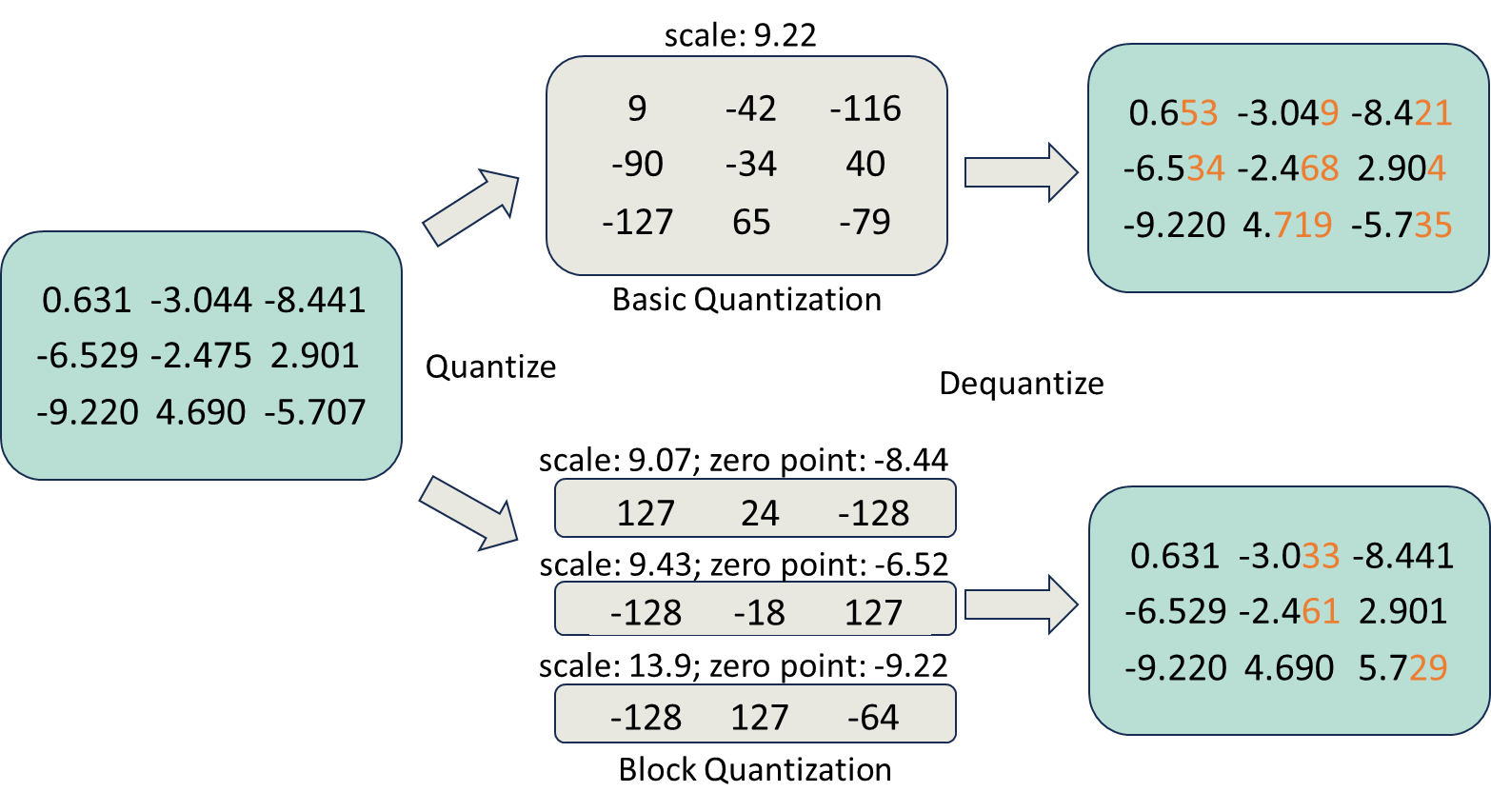
首先,为了减少 all-gather 期间的参数通信量,采用权重量化在通信前将每个模型参数从 FP16(两个字节)动态缩小为 INT8(一个字节)数据类型,并在通信后对权重进行反量化。 然而,简单地对权重进行量化会降低模型训练的准确性。为了保持良好的模型训练精度,采用分区量化,即对模型参数的每个子集进行独立量化。目前尚且没有针对分区量化的高性能现有实现。 因此,从头开始实现了一套高度优化的量化 CUDA 内核,与基本量化相比,精度提高 3 倍,速度提高 5 倍。
- ZeRO模型权重的分层分割存储 (hpZ)
其次,为了减少向后传递期间全收集(all-gather)权重的通信开销,用 GPU 内存进行通信。 更具体地说,不像在 ZeRO 中那样将整个模型权重分布在所有机器上,而是在每台机器中维护一个完整的模型副本。 以更高的内存开销为代价,这允许用机器内的模型权重全收集/广播(all-gather/broadcast)代替昂贵的跨机器全收集/广播(all-gather/broadcast),由于机器内通信带宽更高,这使得通信速度大幅提升。
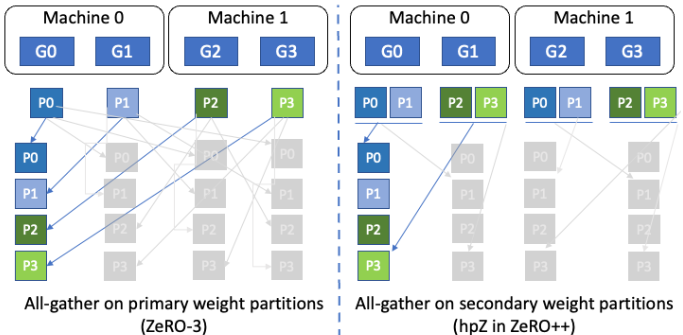
考虑一个 64 节点集群,每个节点有 8 个 GPU。模型权重分为两个阶段:i)跨所有 512 个 GPU,称之为主分区,ii)相同的权重也在计算节点内跨 8 个 GPU 进行分区,称之为辅助分区。在此示例中,对于辅助分区,集群中的每个计算节点都保存在节点内的 8 个 GPU 之间划分的 FP16 权重的完整副本,总共有 64 个这样的副本。
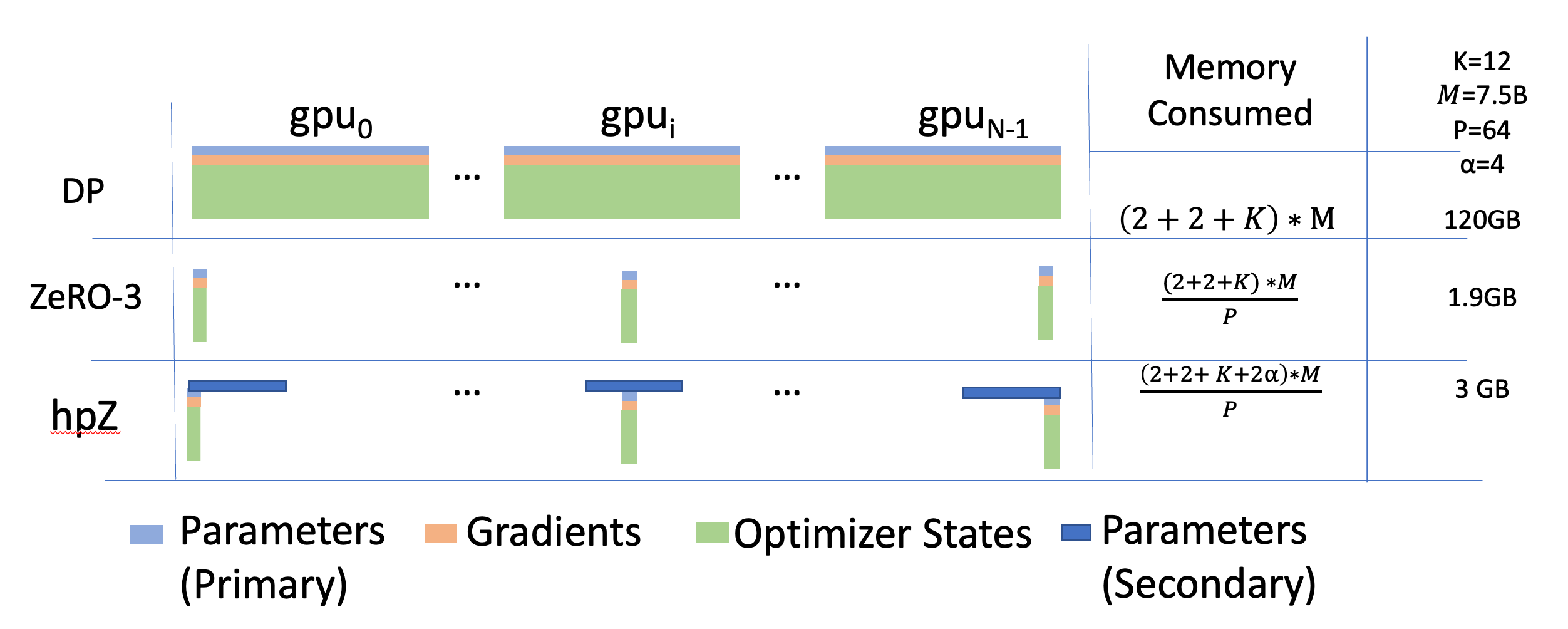
标准数据并行 (DP)、ZeRO 第 3 阶段 (ZeRO-3) 和 ZeRO 参数的拟议分层分区
(ℎ𝑝𝑍) 的每设备内存消耗分析。
- ZeRO通信过程中梯度量化 (qgZ)
第三,要降低梯度的reduce-scatter通信成本更具挑战性。 因为直接应用量化来减少通信量是不可行的。 即使使用分区量化来降低量化误差,梯度reduce也会累积并放大量化误差。 为了解决这个问题,只在通信之前量化梯度,但在任何reduce操作之前将它们反量化到原有精度。 为了有效地做到这一点,我们发明了一种名为 qgZ 的基于 all-to-all 的新型量化梯度通信范式,它在功能上等同于压缩的归约-分散(reduce-scatter)操作。
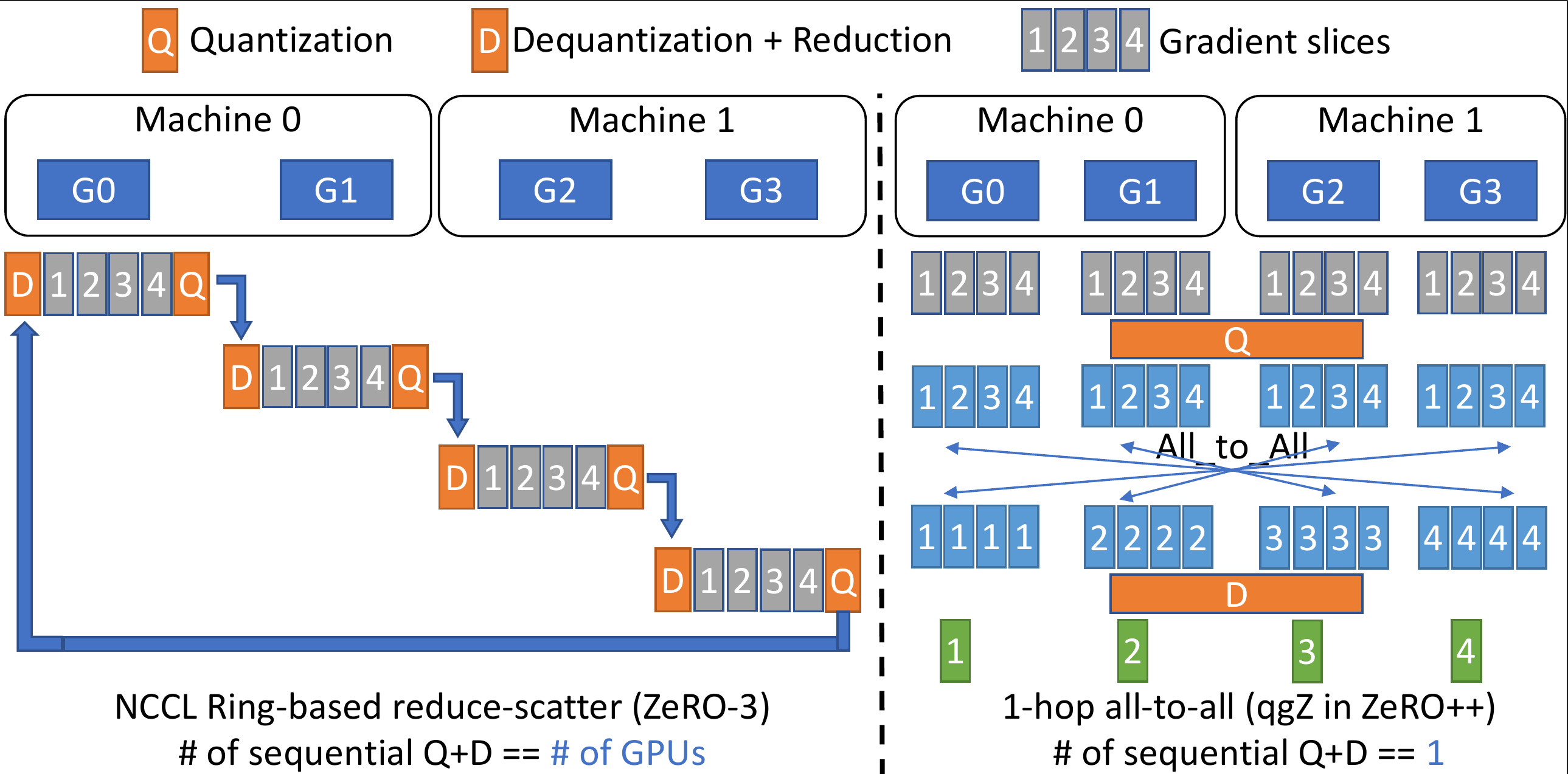
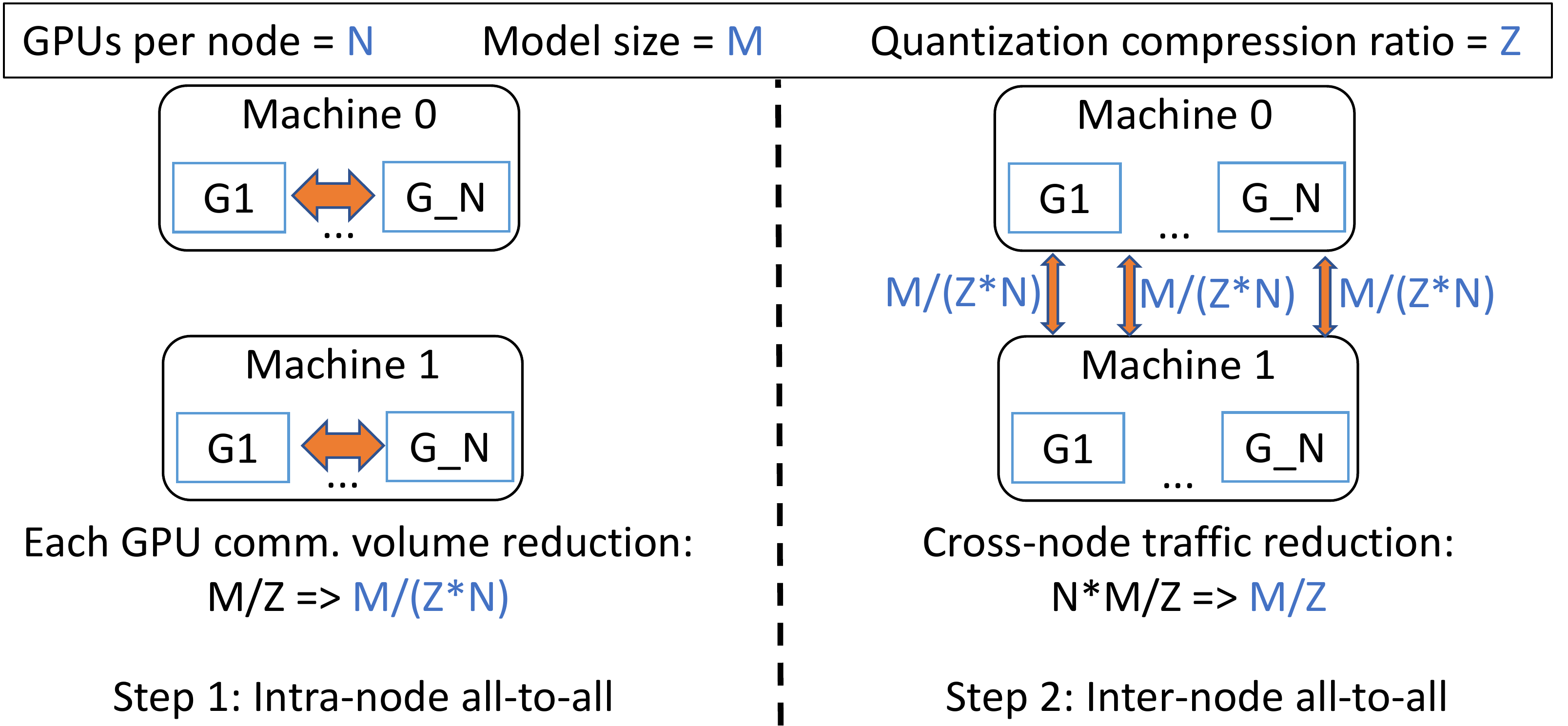
qgZ 旨在解决两个挑战:i) 如果简单地在 INT4/INT8 中实施 reduce-scatter 会导致显著精度损失,以及 ii) 在传统tree或ring-based reduce-scatter中使用量化需要一长串量化和反量化步骤,这直接导致误差积累和显著的延迟,即使在全精度上进行reduce。为了解决这两个挑战,qgZ 不使用tree或ring-based reduce-scatter算法,而是基于一种新颖的分层 all-to-all 方法。
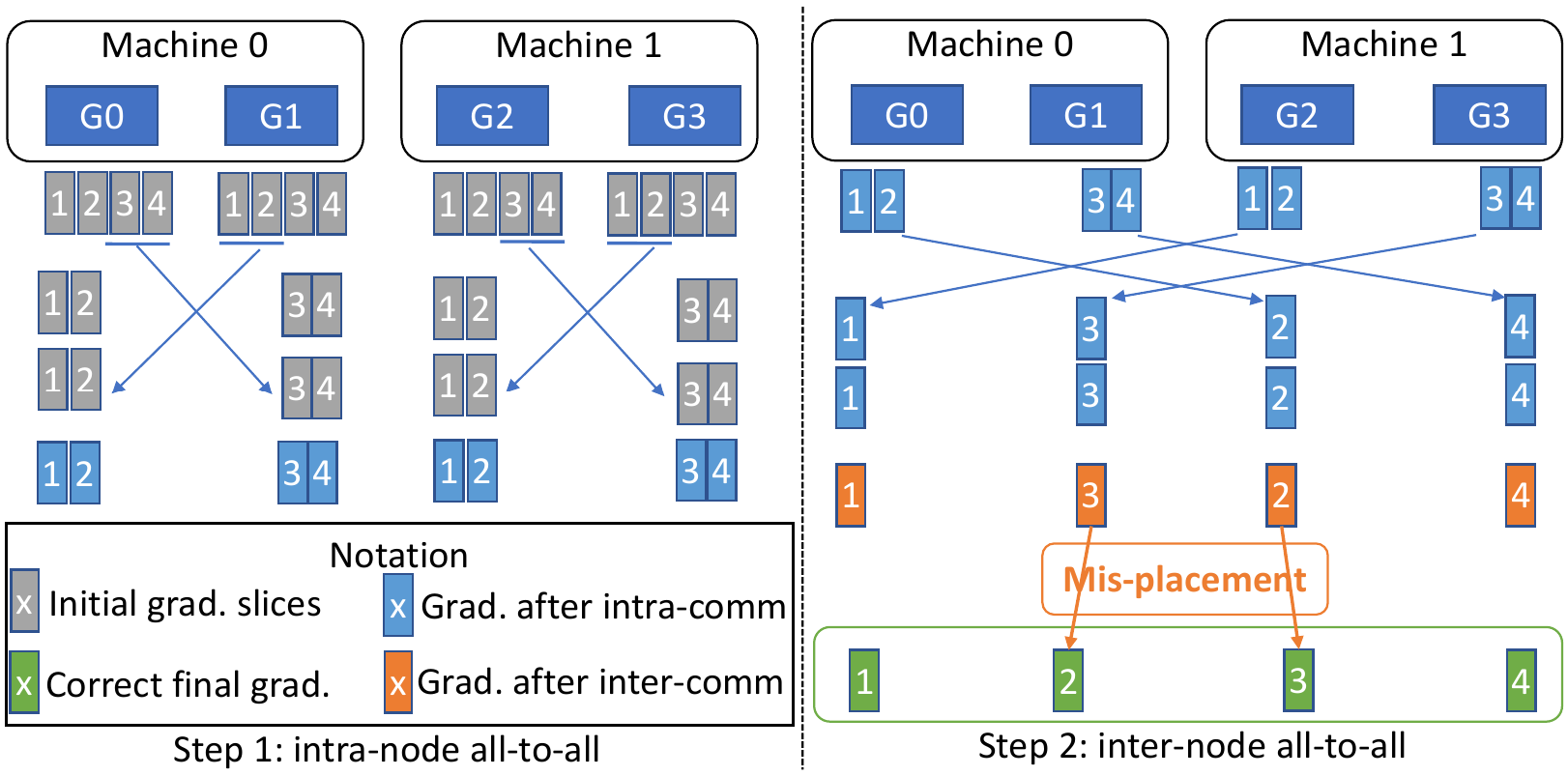
qgZ
中有三个主要步骤:i)梯度切片重新排序,ii)节点内通信和reduce,以及
iii)节点间通信和reduce。
首先,在任何通信发生之前,对梯度进行切片并对张量切片重新排序,以保证通信结束时每个
GPU 上的最终梯度位置(即下图中的绿色块)是正确的。
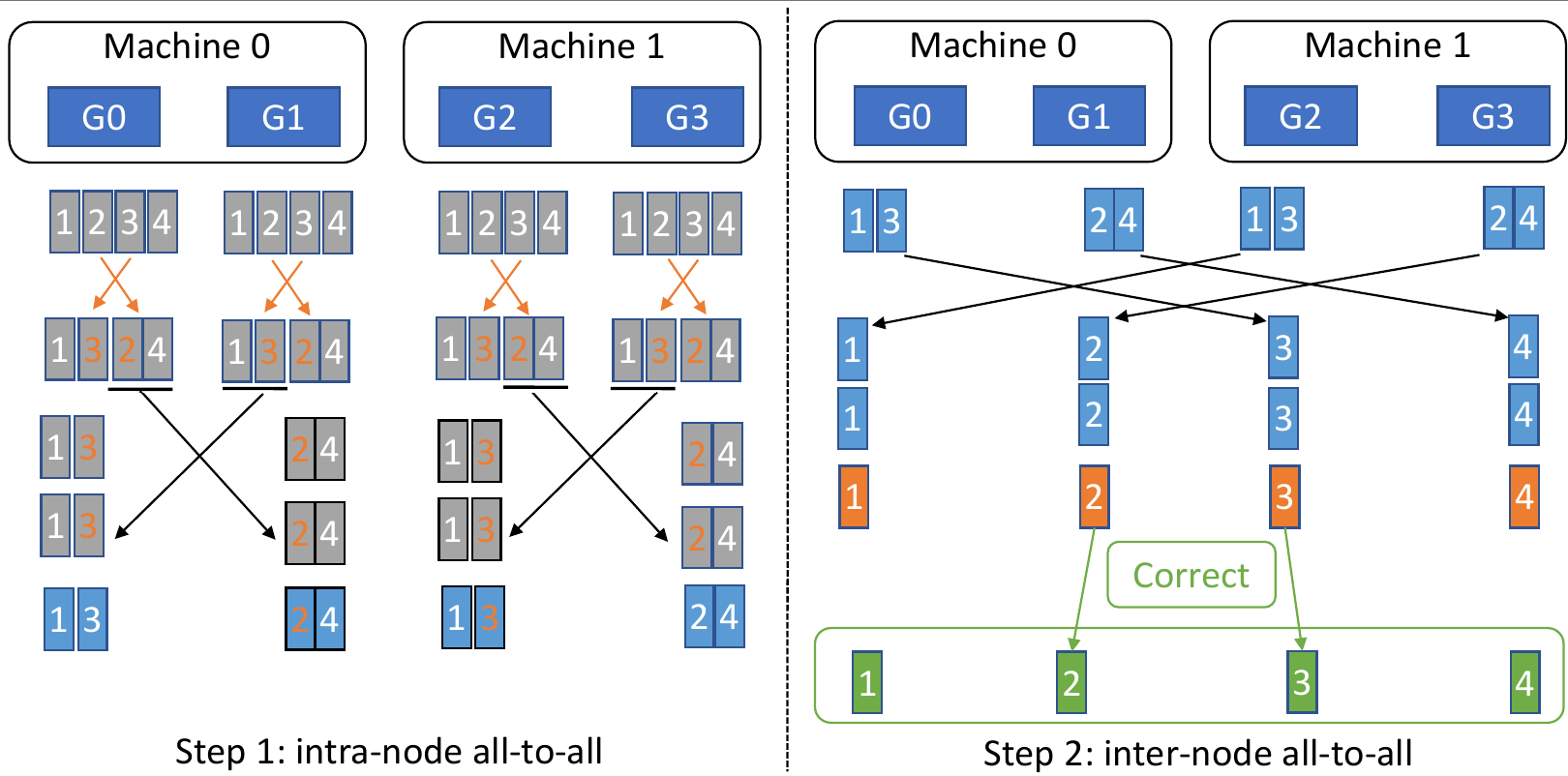
其次,量化重新排序的梯度切片,在每个节点内进行 all-to-all 通信,从
all-to-all 中对接收到的梯度切片进行反量化,并进行局部reduce。
第三,再次量化局部reduce后的梯度,进行节点间的all-to-all通信,再次对接收到的梯度进行反量化,并计算最终的高精度梯度reduce,得到下图中绿色块的结果。
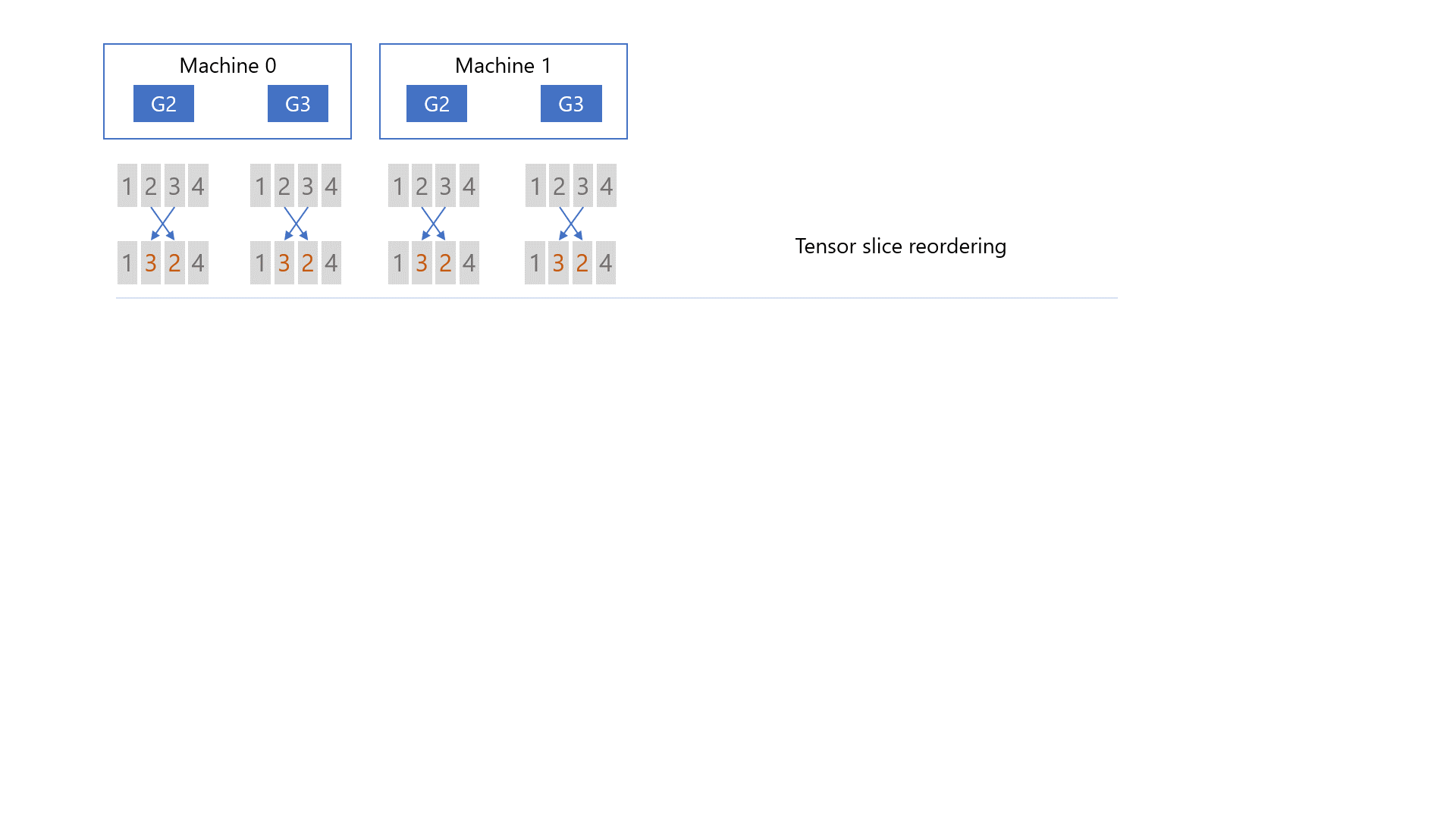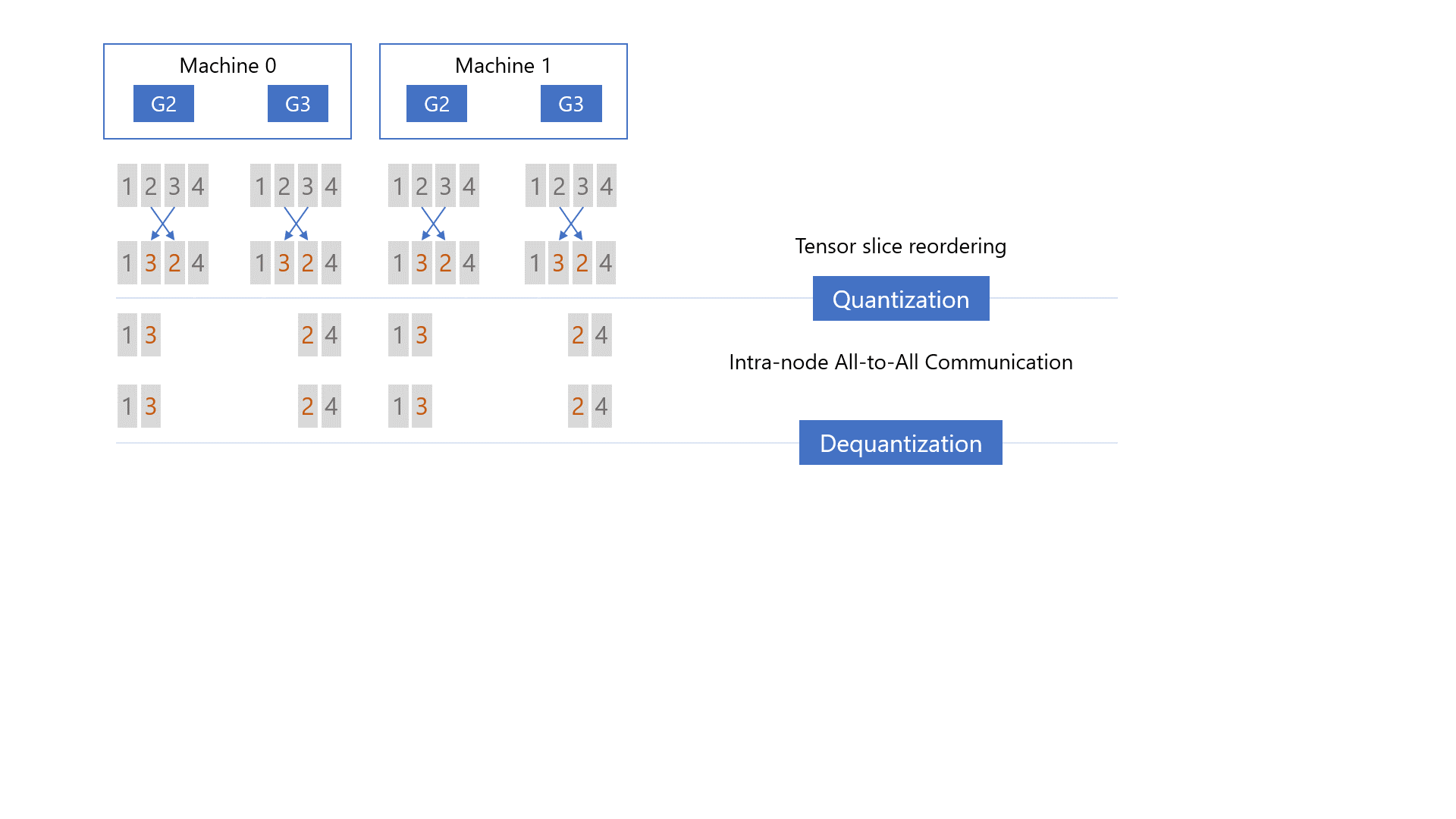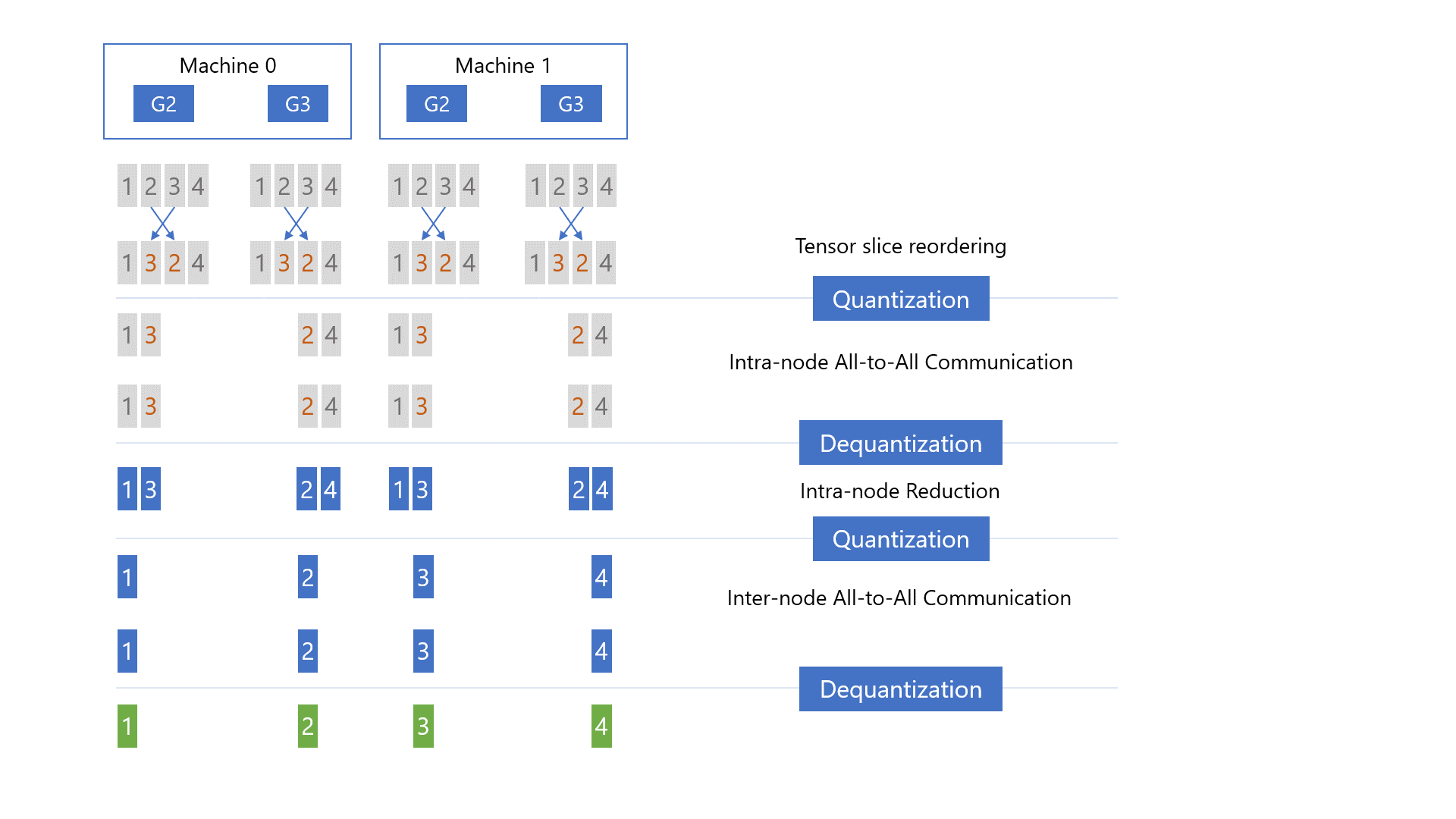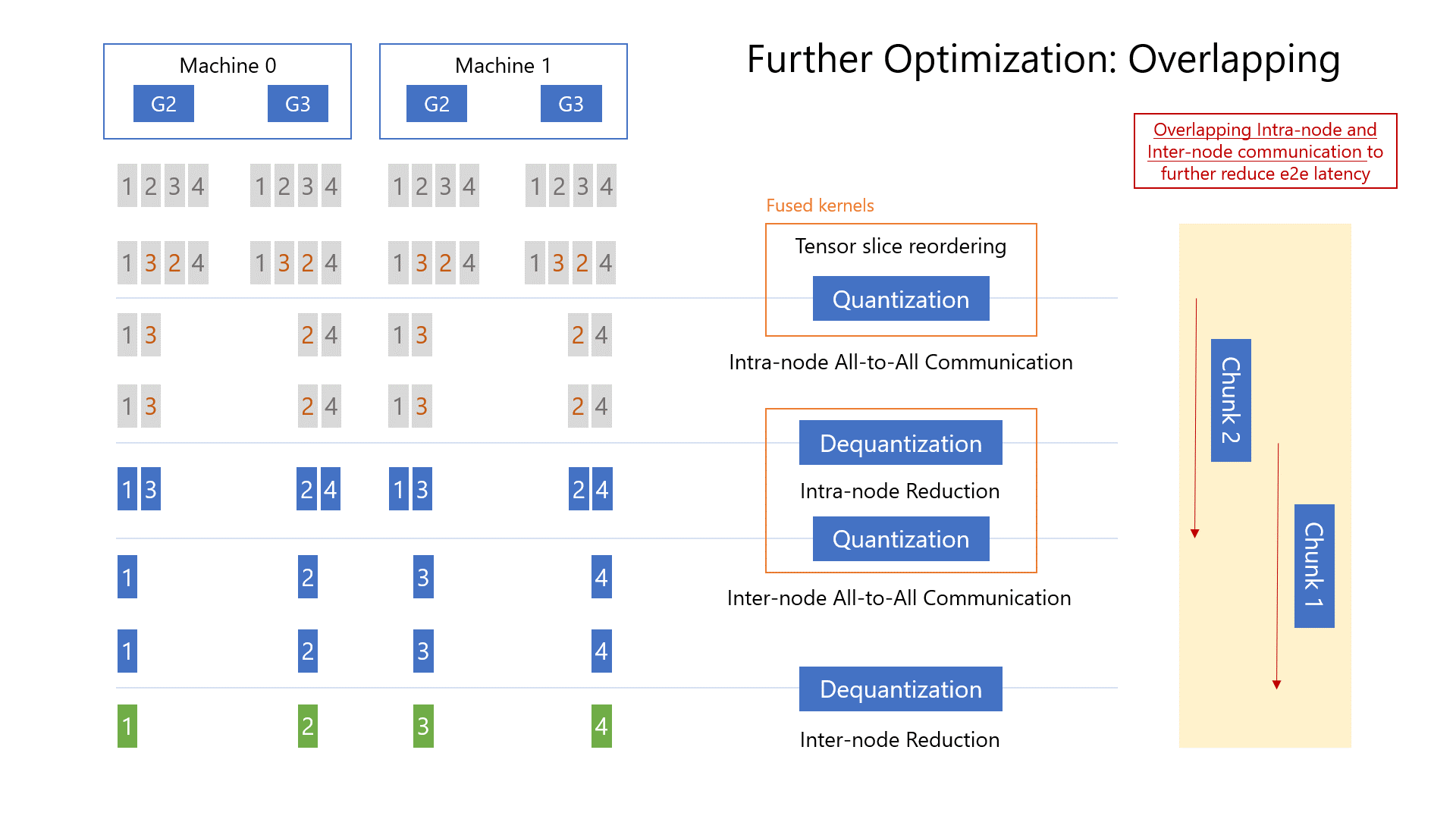
这种分层方法的原因是为了减少跨节点通信量。 更准确地说,给定每个节点 N 个 GPU、M 的模型大小和 Z 的量化比率,单跳 all-to-all 将生成 MN/Z 跨节点流量。 相比之下,通过这种分层方法,将每个 GPU 的跨节点流量从 M/Z 减少到 M/(ZN)。 因此,总通信量从 MN/Z 减少到 MN/(Z*N) = M/Z。 通过重叠节点内和节点间通信以及融合 CUDA 内核来进一步优化 qgZ 的端到端延迟(张量切片重新排序 (Tensor Slice Reordering)+ 节点内量化(Intra-node quantization))和(节点内反量化 (Intra-node Dequantization) + 节点内梯度整合 (Intra-node Reduction) + 节点间量化(inter-node quantization))。
| Communication Volume | Forward all-gather on weights | Backward all-gather on weights | Backward reduce-scatter on gradients | Total |
|---|---|---|---|---|
| ZeRO | M | M | M | 3M |
| ZeRO++ | 0.5M | 0 | 0.25M | 0.75M |
通过结合以上所有三个组件,将跨节点通信量从 3M 减少到 0.75M。 更具体地说,使用 qwZ 将模型权重的前向全收集/广播从 M 减少到 0.5M。 使用 hpZ 消除了反向传播期间的跨节点 all-gather,将通信从 M 减少到 0。最后,使用 qgZ 将反向传播期间的跨节点 reduce-scatter 通信从 M 减少到 0.25M。
2.3 3D 并行
DeepSpeed 可灵活组合三种并行性方法:ZeRO 支持的数据并行、流水线并行和张量切片模型并行。 3D 并行性可适应工作负载需求的不同需求,为具有超过一万亿个参数的超大型模型提供支持,同时实现近乎完美的内存扩展和吞吐量扩展效率。此外,其改进的通信效率使用户能够在网络带宽有限的常规集群上以 2-7 倍的速度训练数十亿参数模型。
数据、模型和流水线并行性在提高内存和计算效率方面各自发挥着特定的作用。
内存效率:模型的各层被划分为流水线阶段,每个阶段的各层通过模型并行进一步划分。这种 2D 组合同时减少了模型、优化器和激活所消耗的内存。但是,无法无限地对模型进行分区,否则通信开销会限制计算效率。
计算效率:为了在不牺牲计算效率的情况下允许工作器数量超出模型和管道并行性,使用 ZeRO 支持的数据并行性 (ZeRO-DP)。ZeRO-DP 不仅通过优化器状态分区进一步提高内存效率,而且还允许通过利用拓扑感知映射以最小的通信开销扩展到任意数量的 GPU。
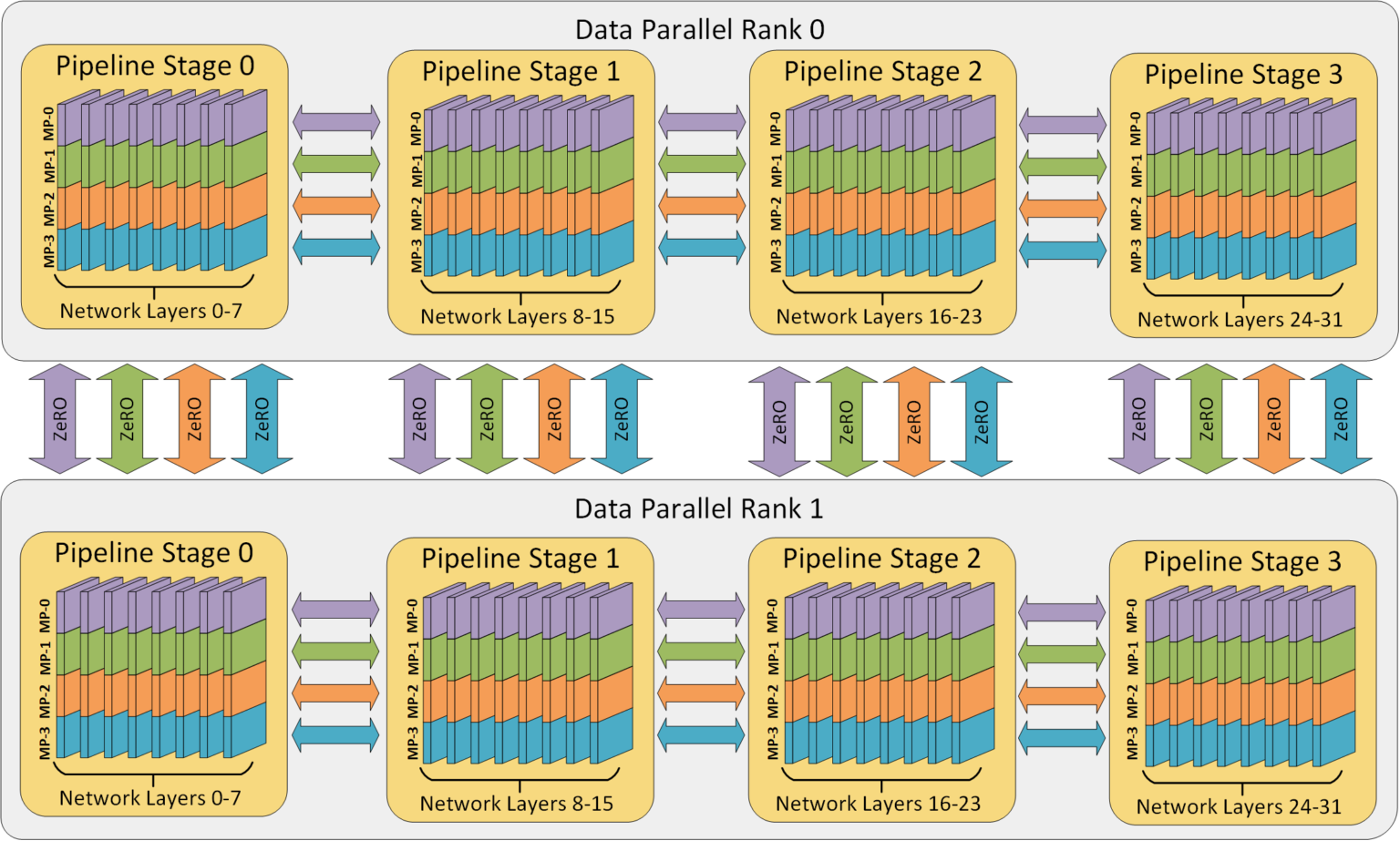
拓扑感知 3D 映射:通过利用两个关键的架构特性,3D 并行中的每个维度都被仔细地映射到工作器上,以实现最大的计算效率。
- 优化节点内和节点间通信带宽:模型并行在三种策略中具有最大的通信开销,因此优先将模型并行组放置在节点内,以利用更大的节点内带宽。在这里,应用 NVIDIA Megatron-LM 实现张量切片式模型并行。当模型并行不覆盖节点中的所有工作器时,数据并行组将放置在节点内。否则,它们将放置在节点之间。管道并行的通信量最低,因此可以跨节点调度管道阶段,而不受通信带宽的限制。
- 通过通信并行化实现带宽放大:每个数据并行组所传递的梯度大小通过流水线和模型并行化线性减小,因此总通信量比纯数据并行化有所减少。此外,每个数据并行组在本地工作者子集之间独立并行地执行通信。因此,通过减少通信量、增加局部性和并行性,数据并行通信的有效带宽得以放大。
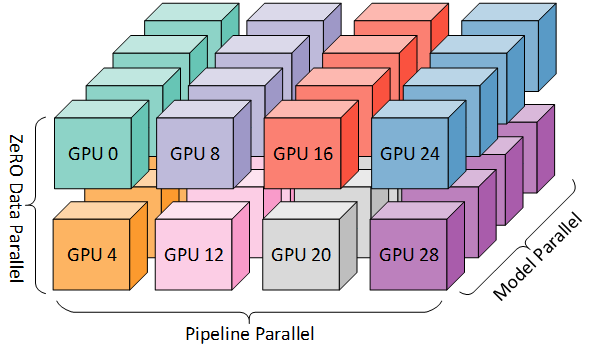
ZeRO DP+PP+TP
DeepSpeed 的主要功能之一是 ZeRO,它是 DP 的超级可伸缩增强版,通常它是一个独立的功能,不需要 PP 或 TP。但它也可以与 PP、TP 结合使用。当 ZeRO-DP 与 PP (以及 TP) 结合时,它通常只启用 ZeRO 阶段 1,它只对优化器状态进行分片。ZeRO 阶段 2 还会对梯度进行分片,阶段 3 也对模型权重进行分片。
虽然理论上可以将 ZeRO 阶段 2 与 流水线并行 一起使用,但它会对性能产生不良影响。每个 micro batch 都需要一个额外的 reduce-scatter 通信来在分片之前聚合梯度,这会增加潜在的显著通信开销。根据流水线并行的性质,我们会使用小的 micro batch ,并把重点放在算术强度 (micro batch size) 与最小化流水线气泡 (micro batch 的数量) 两者间折衷。因此,增加的通信开销会损害流水线并行。
此外,由于 PP,层数已经比正常情况下少,因此并不会节省很多内存。PP 已经将梯度大小减少了 1/PP,因此在此基础之上的梯度分片和纯 DP 相比节省不了多少内存。
ZeRO 阶段 3 也可用于训练这种规模的模型,但是,它需要的通信量比 DeepSpeed 3D 并行更多。
2.4 DeepSpeed Sparse Attention
Self Attention是
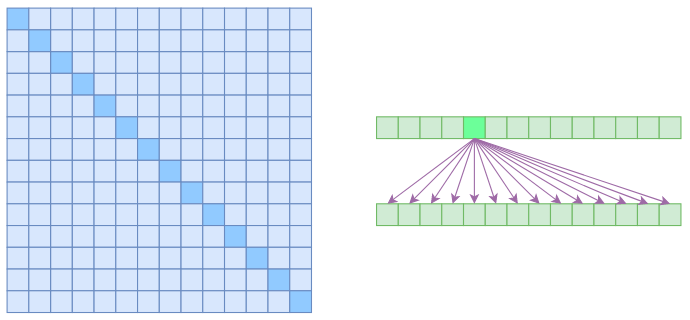
在上图中,左边显示了注意力矩阵,右边显示了关联性,这表明每个元素都跟序列内所有元素有关联。
2.4.1 Atrous Self Attention
Atrous Self
Attention,中文可以称之为“膨胀自注意力”、“空洞自注意力”、“带孔自注意力”等。Atrous
Self Attention就是启发于“膨胀卷积(Atrous
Convolution)”,如下右图所示,它对相关性进行了约束,强行要求每个元素只跟它相对距离为
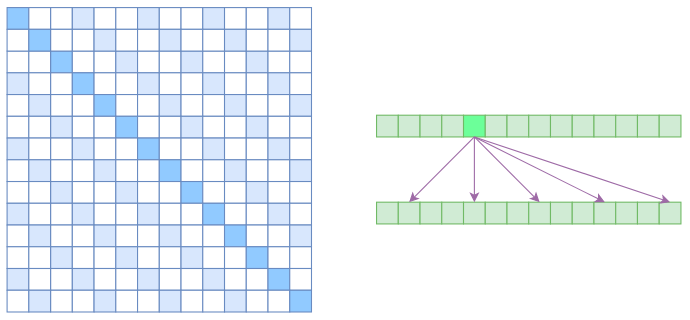
由于现在计算注意力是“跳着”来了,所以实际上每个元素只跟大约
2.4.2 Local Self Attention
Local Self
Attention,中文可称之为“局部自注意力”。其实自注意力机制在CV领域统称为“Non
Local”,而显然Local Self
Attention则要放弃全局关联,重新引入局部关联。具体来说也很简单,就是约束每个元素只与前后
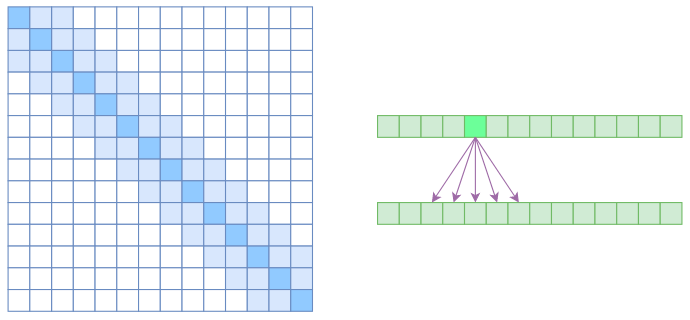
从注意力矩阵来看,就是相对距离超过
2.4.3 Sparse Self Attention
OpenAI的论文《Generating Long Sequences with Sparse Transformers》
Atrous Self Attention是带有一些洞的,而Local Self Attention正好填补了这些洞,所以一个简单的方式就是将Local Self Attention和Atrous Self Attention交替使用,两者累积起来,理论上也可以学习到全局关联性,也省了显存。假如第一层用Local Self Attention的话,那么输出的每个向量都融合了局部的几个输入向量,然后第二层用Atrous Self Attention,虽然它是跳着来,但是因为第一层的输出融合了局部的输入向量,所以第二层的输出理论上可以跟任意的输入向量相关,也就是说实现了长程关联。
但是OpenAI没有这样做,它直接将两个Atrous Self Attention和Local Self Attention合并为一个,如下图:
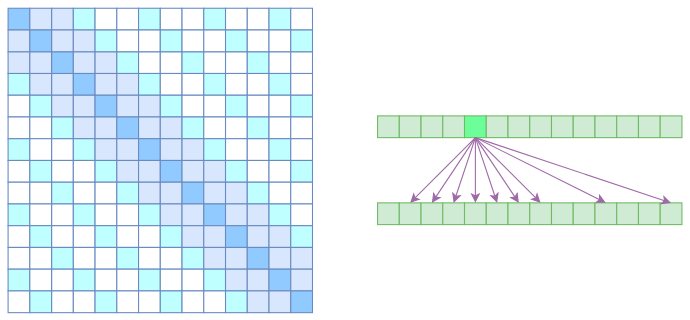
从注意力矩阵上看就很容易理解了,就是除了相对距离不超过
OpenAI开源了的实现:https://github.com/openai/sparse_attention
2.4.4 DeepSpeed Sparse Attention
DeepSpeed
提供了一套稀疏注意力内核——这是一种工具技术,可以通过块稀疏计算将注意力计算的计算和内存需求减少几个数量级。该套件不仅缓解了注意力计算的内存瓶颈,而且还能高效地执行稀疏计算。它的
API 允许与任何基于 Transformer
的模型方便地集成。除了提供广泛的稀疏结构外,它还具有处理任何用户定义的块稀疏结构的灵活性。更具体地说,稀疏注意力
(SA)
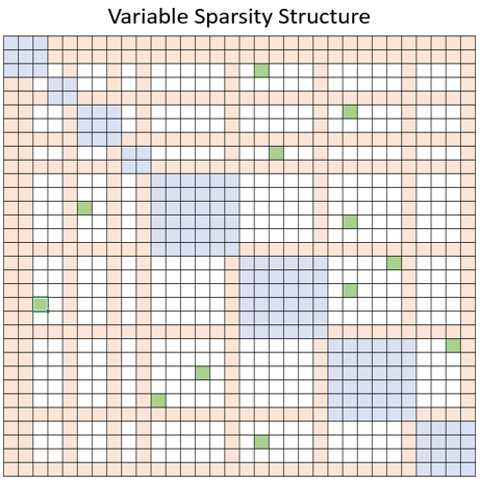
可以设计为计算附近token之间的局部注意力,或通过使用局部注意力计算的摘要token来计算全局注意力。此外,SA
还可以允许随机注意力,或局部、全局和随机注意力的任意组合,如下图分别以蓝色、橙色和绿色块所示。因此,SA
将内存占用减少到
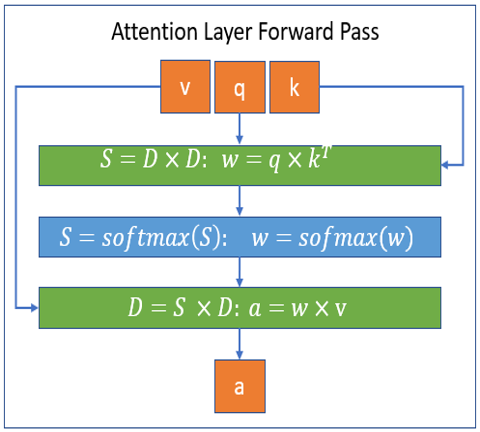
该库是 DeepSpeed 的扩展,可以通过 DeepSpeed 使用,也可以单独使用。下图分别说明了 DeepSpeed Sparse Attention 内核处理的块稀疏计算的前向和后向传递。图中, S 代表 block-sparse matrix , D 代表 dense matrix 。
DeepSpeed开源了的实现:https://github.com/microsoft/DeepSpeed/tree/master/deepspeed/ops/sparse_attention
2.5 梯度量化
Adam使用两个辅助变量
这里
SGD (Vanilla SGD)
Momentum SGD
All-Reduce 通信占每步训练时间的很大一部分,不同节点间网络的集群上的实验,高达 94% 和 75%。 当节点数量较多、批量大小/梯度累积步长较小或网络带宽较低时,通信开销成比例地较大。这些是通信压缩可以提供最大好处的情况。
2.5.1 误差补偿
误差补偿的工作方式:将当前梯度加上上一次量化前的误差,再进行量化。
举个例子,假设第一轮量化时梯度为(2.8, -2.8),则量化后的结果为(1, -1),量化误差为(-1.8, 1.8),第二轮量化时梯度为( 1.6, -1.6),则需要加上前一轮的量化误差后再进行量化,即对(1.6-1.8, -1.6+1.8)进行量化,量化结果为(-1, 1),后续操作以此类推。
1)进行压缩,2) 记住压缩误差,然后 3) 在下一次迭代中将压缩误差加回
对于 SGD,当直接压缩梯度而不进行误差补偿时,更新规则变为:
历史压缩误差会累积,从而减慢收敛速度。当使用偏置压缩算子时,无法保证训练收敛。在每个压缩步骤应用误差补偿,如果则更新规则变为
通过使用误差补偿,每个步骤的压缩误差将在下一步中被抵消,而不是在步骤中累积。为了使误差补偿正常工作,必须确保更新规则中的误差抵消项
2.5.2 1-bit Adam
论文:《1-bit Adam: Communication Efficient Large-Scale Training with Adam’s Convergence Speed》 05 为什么Adam不能与误差补偿结合使用
对于 Adam,需要传递梯度
这里二次项
1-bit Adam
BERT-Large 预训练期间的 Adam 方差(序列长度
128)。在每一步中,我们融合所有参数的方差,并计算融合方差的范数。下图显示了每个步骤的融合方差范数。结果表明,方差范数在大约
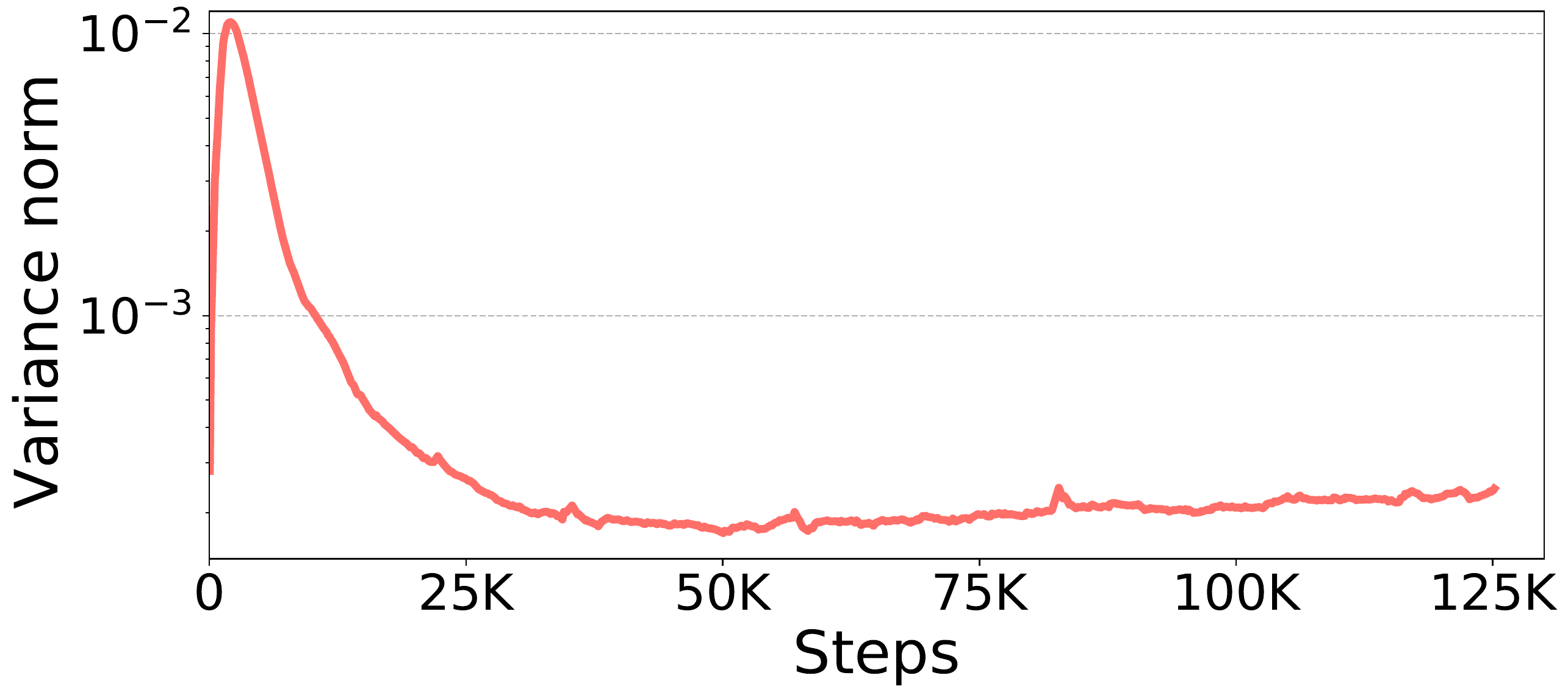
这个发现使得 1-bit Adam 能够在 Adam variance
变得稳定后”冻结”它,然后在 1-bit
误差补偿和压缩阶段将其用作前提条件。首先,使用 vanilla Adam
几个时期作为热身。热身阶段结束后,压缩阶段开始,停止更新方差项
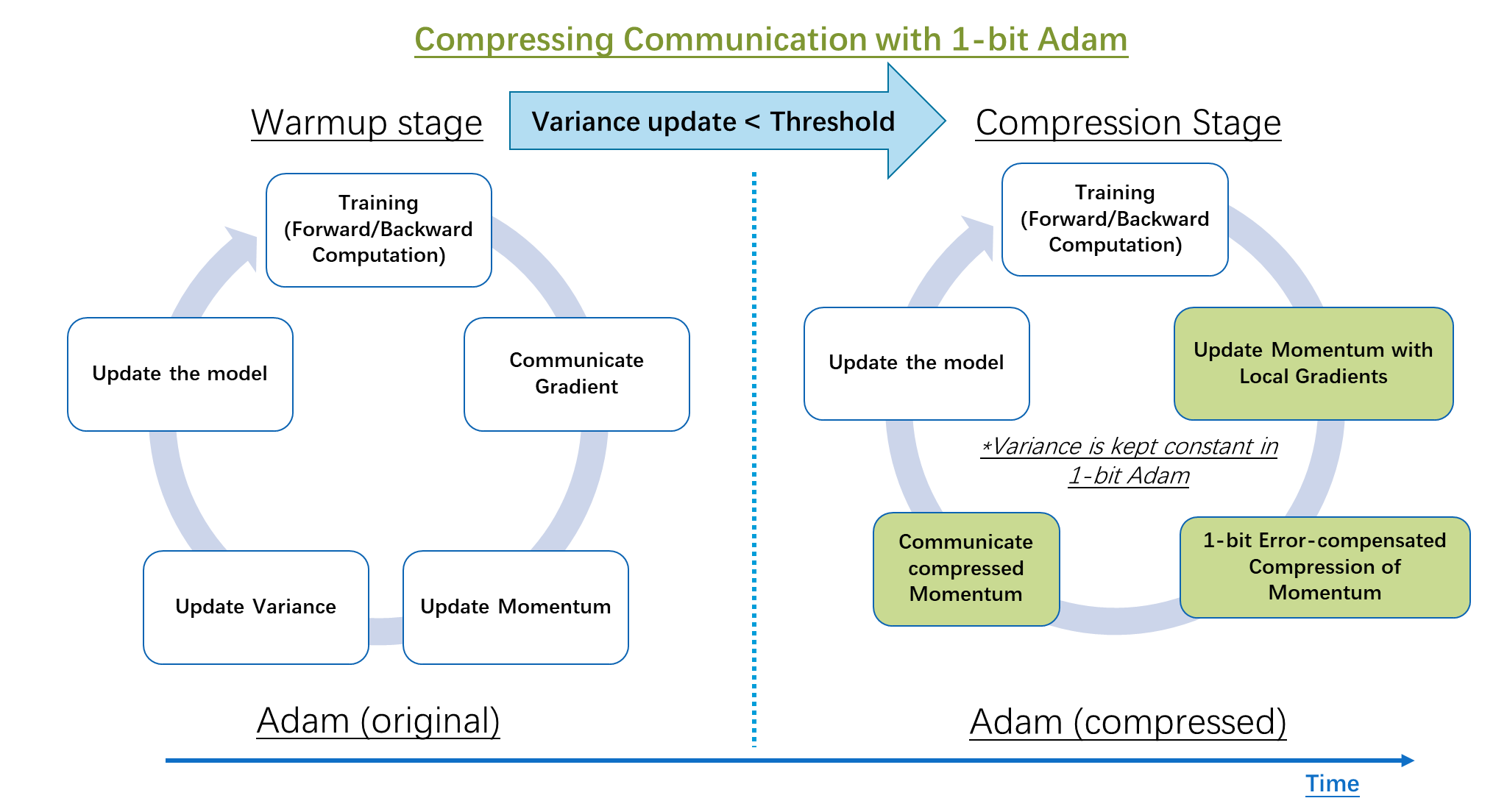
Algorithm: 1-bit Adam 1: 初始化:
,学习率 ,初始误差 , , ,总迭代次数 ,预热步骤 ,Adam的两个衰减因子 、 和 。
2: 运行原始Adam步,然后存储方差项(在原始Adam公式中定义为 ) 。 3: for do 4: (在第 个节点上) 5: 随机抽样 并计算局部随机梯度 。
6:根据 更新局部动量变量
7:将 压缩为 ,并将压缩误差更新为 。
8:将 发送到服务器
9:(在服务器上) 10: 对接收到的所有 取平均值并将其压缩为 并通过 相应地更新压缩误差。 11: 向所有workers发送 。 12: (在第 个节点上) 13: 设 ,并更新局部模型 14: end for 15: Output:
2.5.3 0/1 Adam
论文:《Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam》
为了最大限度地提高通信效率,理想情况下,我们希望有一种算法能够像 Adam 一样实现自适应收敛,同时允许积极压缩(例如 1-bit),并且在使用局部步骤时不需要对优化器状态进行额外的同步。0/1 Adam 从两个方面解决了这个问题。
Algorithm: 0/1 Adam 1: 要求:第
个节点上的局部模型 ,学习率 , , ,辅助缓冲区 ,总迭代次数 ,衰减因子 ,来自 Adam 的 ,数值常数 ,方差更新步骤索引集 ,同步步骤索引集 ,最近同步步骤 。 2: for do 3: 计算局部随机梯度 。 4: 更新动量: 。 5: 更新模型: 。 6: 更新缓冲区: 。 7: if then 8: 执行 1-bit AllReduce: = 。 9: 使用压缩缓冲区近似动量: 。 10: 使用压缩缓冲区更新模型: 。 11: 重置辅助缓冲区: 。 12: 更新同步步骤: 。 13: else 14: ; ; 。 15: end if 16: if then 17: 执行全精度 AllReduce: = 。 18: 更新方差: 。 19: else 20: 在下一次迭代中使用过时的方差: 。 22: end if 23: end for 24: return 。
- 自适应方差冻结
首先,0/1 Adam
创建了一个线性环境,可以自适应地冻结方差。Adam
中方差随步骤的变化通常是平滑的。虽然 1-bit Adam
通过一次性冻结捕获了合理的方差估计,但也可以合理地假设,在其冻结点之前,由于其平滑性,几个相邻步骤内的方差将保持接近。这促使我们将
1-bit Adam 中的一次性冻结策略扩展为自适应策略,让workers就给定步骤索引集
- 1-bit压缩和局部步骤
在方差冻结的情况下,我们根据方程Adam_update做出另一个观察,即工人的模型差异将线性依赖于动量。因此,只要动量的变化在近距离步骤内不会突然发生,就可以在本地近似动量,而不是根据传递的模型差异额外同步动量。正式地,将
基于误差反馈的 1bit-AllReduce 在理论和实践上都效果最佳。事实上,原始的 1-bit Adam 也采用了误差反馈设计。在下述算法中给出了此1bit-AllReduce 的完整描述。此算法不需要任何额外的假设来使我们的理论成立,因为这符合算法 4 和算法 1 中的黑盒程序。
Algorithm: 误差反馈 1-bit通信 (1bit-AllReduce) 的完整描述 1: 要求:通信缓冲区
、工作者错误 、服务器错误 、1 位压缩器 。工作者和服务器错误都将在 时初始化为 。 2: (在第 个节点上) 3: 将 压缩为 ,并将压缩误差更新为 。 4: 将 发送到服务器。 5: (在服务器上) 6: 对所有 取平均值,并将其压缩为 ,并通过 更新压缩误差。 7: 将 发送给所有workers。 8: (在第 个节点上) 9: Return , , 。
Algorithm:AllReduce的完整描述 1: 要求:通信缓冲区
。 2: (在第 个节点上) 3: 将 发送到服务器。 4: (在服务器上) 5: 对所有 取平均值,放入 。 6: 将 发送给所有workers。 7: (在第 个节点上) 8: Return 。
2.5.4 1-BIT LAMB
论文:《1-bit LAMB: Communication Efficient Large-Scale Large-Batch Training with LAMB’s Convergence Speed》
为了进一步提高大规模训练效率,能够在保持收敛速度的同时支持大型小批量是一个关键因素。作者发现
BERT 预训练很难在 16K 或更大的批量大小下保持Adam
的收敛速度。为此,他们提出了 LAMB,它可以被视为具有自适应分层学习率的
Adam。通过使用 LAMB,他们能够将 BERT 预训练的批量大小扩展到
这里
Algorithm: 1-bit LAMB 1: 初始化:每层的
、 、 、 。学习率 、初始误差 、总迭代次数 、预热步骤 、LAMB 动量、方差和缩放系数的三个衰减因子 、 、 。{} 的 、 、 、 。 2: 在 中运行原始 LAMB 步,并且每一步 。 3: 在步骤 结束时,对于每一层存储方差项(在 中定义为 ) ,同时在未来的步骤中仍然保持更新 。还停止更新 . 4: for do 5: (On -th node) 6: 随机采样 并计算局部随机梯度 ,并根据 更新局部动量 7: 压缩融合动量将 转换为 ,并通过 更新压缩误差。 8: 将 发送到服务器。 9: (在服务器上) 10: 对所有收到的 取平均值,并将其压缩为 并相应地通过 更新压缩误差。 11: 将 发送给所有workers。 12: (在第 个节点上) 13: 设置 . 14: for 第 层 do 15: 重建全局梯度 . 16: . 17: . 18: . 19: . 20: . 21: 第 层的更新模型 . 22: end for 23: end for 24: 输出: .
在上述算法中总结了1-bit
LAMB。在压缩阶段,冻结方差,以便正确应用误差补偿机制。然而,这给
LAMB 的情况带来了两个挑战:1)无法在基于 LAMB 算法的压缩阶段更新 LAMB
的缩放系数(
为此,1-bit LAMB使用一种新颖的方法在压缩阶段自适应地更新 LAMB 缩放系数,以补偿冻结方差和实际方差之间的差异。在预热阶段,使用 vallia LAMB 并跟踪每层缩放系数的移动平均值(在压缩阶段使用,因为缩放系数在开始时并不稳定)。在预热结束时,停止更新移动平均值,并存储冻结的方差以供压缩阶段使用。另一方面,仍然通过基于此步骤和上一步的压缩动量重建全局梯度来不断更新另一个“新鲜”方差。
为了在压缩阶段更新 LAMB 缩放系数,计算1-bit LAMB缩放比率,它是 (冻结方差/新鲜方差) 中的最大元素。使用最大元素作为缩放比率,因为根据实验,它计算起来既有效又便宜。为了避免极端比率和比率之间的剧烈变化,使用两种可由用户配置的剪辑。(在压缩阶段不使用 vanilla LAMB 算法的裁剪。)然后,使用 1-bit LAMB缩放比率和预热结束时的移动平均值计算此步骤的 LAMB 缩放系数,并使用它来更新模型。研究表明,方差不太稳定的层往往具有更动态的1-bit LAMB缩放比率,这证明了所需的自适应性。
三、DeepSpeed Inference
根据许多用户的要求,DeepSpeed 为具有数十亿参数的基于 Transformer 的大型模型(例如 Turing-NLG 17B 和 Open AI GPT-3 175B 规模的模型)推出了高性能推理支持。用于优化推理成本和延迟的新技术包括:
- Inference-adapted parallelism:推理适应并行性允许用户通过适应多 GPU 推理的最佳并行性策略来有效地服务大型模型,同时考虑推理延迟和成本。
- Inference-optimized CUDA kernels:推理优化的 CUDA 内核通过深度融合和新颖的内核调度充分利用 GPU 资源,从而提高每个 GPU 的效率。
- Effective quantize-aware training:有效的量化感知训练使用户能够轻松量化能够以低精度高效执行的模型,例如 8 位整数 (INT8) 而不是 32 位浮点 (FP32),从而在不损害内存的情况下节省内存并减少延迟准确性。
3.1 Inference-adapted parallelism
大型模型可能需要比单个 GPU 上可用的内存更多的内存。因此,多 GPU 并行是实现这些大型模型推理的必要的第一步。此外,通过将推理工作负载分散到多个GPU上,多GPU推理还可以减少推理延迟,以满足生产工作负载严格的延迟要求。然而,并行度的选择需要明智。多GPU并行引入了跨GPU通信,它还可以减少每GPU的计算粒度。这两个因素都会影响推理效率,导致当并行度太大时,延迟减少量减少,最终增加而不是减少延迟。因此,为了满足延迟要求,同时减少并行开销,有必要调整并行度并确定给定模型架构和硬件平台的最佳值。我们将这种能力称为推理适应并行性。
DeepSpeed 为推理适应并行性提供无缝支持。一旦基于 Transformer 的模型经过训练(例如,通过 DeepSpeed 或 HuggingFace),模型检查点就可以在推理模式下使用 DeepSpeed 加载,用户可以指定并行度。在此基础上,DeepSpeed Inference 自动在指定数量的 GPU 上对模型进行分区,并插入为 Transformer 模型运行多 GPU 推理所需的必要通信,用户无需更改模型代码。用户只需更改并行度即可调整模型性能以满足其延迟和效率要求。
DeepSpeed Inference 目前支持基于 Transformer 的模型在节点内和跨节点的基于张量切片的多 GPU 并行性,计划很快添加对流水线并行性的支持。
3.2 Inference-optimized kernels
由于批量大小较小,在推理过程中实现良好效率存在两个主要挑战:1)由于每个内核中的工作有限,内核调用时间和主内存延迟成为主要瓶颈; 2) 默认的 GeMM(通用矩阵乘法)库没有针对极小的批量大小进行很好的调整,导致性能不佳。 DeepSpeed Inference 为 Transformer 模块提供推理内核,具有两项创新优化功能,可应对这些挑战,从而显着减少延迟并提高吞吐量。
Deep fusion:DeepSpeed Inference 可以将多个算子融合到单个内核中,以减少内核调用次数和跨内核访问主内存的延迟。虽然内核融合是 PyTorch JIT 编译器、Tensorflow XLA 等中使用的常见技术,但 DeepSpeed 中的深度融合却有所不同。与主要融合按元素运算的现有融合技术不同,DeepSpeed 中的深度融合可以将按元素运算、矩阵乘法、转置和约简全部融合到单个内核中,从而显着减少内核调用次数以及主内存访问次数,从而减少主存访问延迟。
Inference-customized GeMM:小批量会导致瘦 GeMM 操作,其中激活是瘦矩阵,而参数是比激活大得多的矩阵,并且每个参数的总计算量受到批量大小的限制。因此,GeMM 的性能主要取决于从主存读取参数所需的时间,而不是计算时间本身。因此,为了实现最佳性能,DeepSpeed Inference 内核经过微调,以最大限度地提高加载参数时的内存带宽利用率。对于批量大小为 1-10 的推理工作负载,这种专业化使得 DeepSpeed Inference 内核的性能比 NVIDIA cuBLAS 高出 20%。
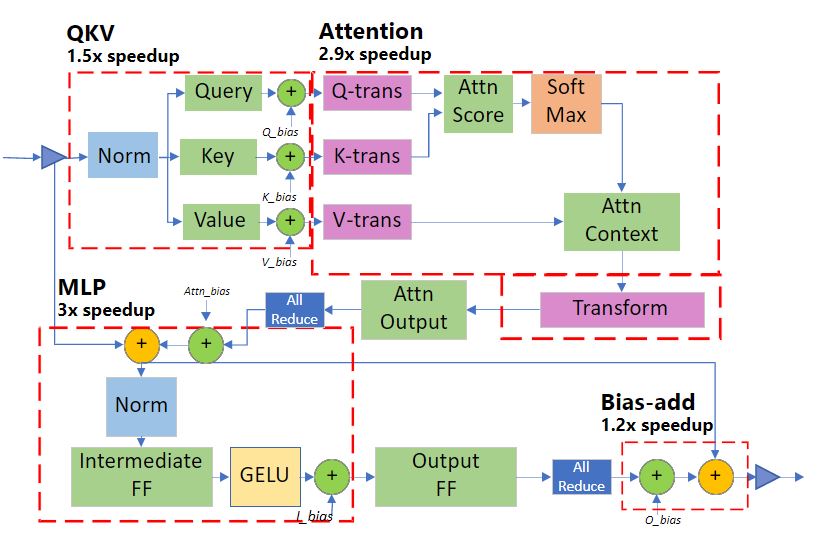
Generic and specialized Transformer kernels
DeepSpeed Inference 由两组 Transformer 内核组成,其中包含上述优化:
Generic Transformer 使用深度融合创建的高度优化的 DeepSpeed 版本取代了 Transformer 中的各个 PyTorch 运算符,例如 LayerNorm、Softmax 和偏差添加。
Specialized Transformer 通过创建融合调度,使深度融合更进一步,该调度不仅融合 PyTorch 宏运算符(例如 Softmax)内的微运算符,而且还融合多个宏运算符(例如 Softmax 和 LayerNorm 以及转置运算),以及甚至GeMM)。专用的 Transformer 内核的融合结构如上图所示。
3.3 Flexible quantization support
为了进一步降低大规模模型的推理成本,创建了 DeepSpeed Quantization Toolkit,它包含两部分:
Mixture of Quantization (MoQ):混合量化 (MoQ) 是一种新颖的量化感知训练方法,其设计基于以下观察:基于 Transformer 的大型小批量模型的推理时间主要由主内存中的参数加载时间决定。因此,仅量化参数就足以实现推理性能改进,同时可以计算激活并将其存储在 FP16 中。有了这种洞察力,MoQ 使用 DeepSpeed 中现有的 FP16 混合精度训练管道来支持训练期间参数的无缝量化。它只需将 FP32 参数值转换为较低精度(INT4、INT8 等)即可实现此目的。然后在权重更新期间将它们存储为 FP16 参数(FP16 数据类型,但值映射到较低精度)。
这种方法具有三个优点:1)它不需要用户更改任何代码,2)它不需要在训练期间使用实际的低精度数据类型或专门的内核,3)它允许我们动态调整量化位数随着培训的进展,提供使用灵活的量化计划和策略的能力。例如,MoQ 可以在训练期间利用二阶信息(如 Q-BERT 中所示的信息)来自适应调整每个模型层的量化计划和目标位。
凭借未量化的激活、灵活的量化计划和使用二阶信息的自适应目标,与相同压缩比的传统量化方法相比,MoQ 在准确性方面更加稳健。
High-performance INT8 inference kernels:高性能 INT8 推理内核是前面讨论的通用和专用 Transformer 内核的扩展,旨在与使用 MoQ 训练的 INT8 参数配合使用。这些内核提供与 FP16 版本相同的优化集,但它们不是从主内存加载 FP16 参数,而是加载 INT8 参数。一旦参数加载到寄存器或共享内存,它们就会在用于推理计算之前即时转换为 FP16。加载 INT8 而不是 FP16 可以将主内存中的数据移动量减少一半,从而使推理性能提高高达 2 倍。
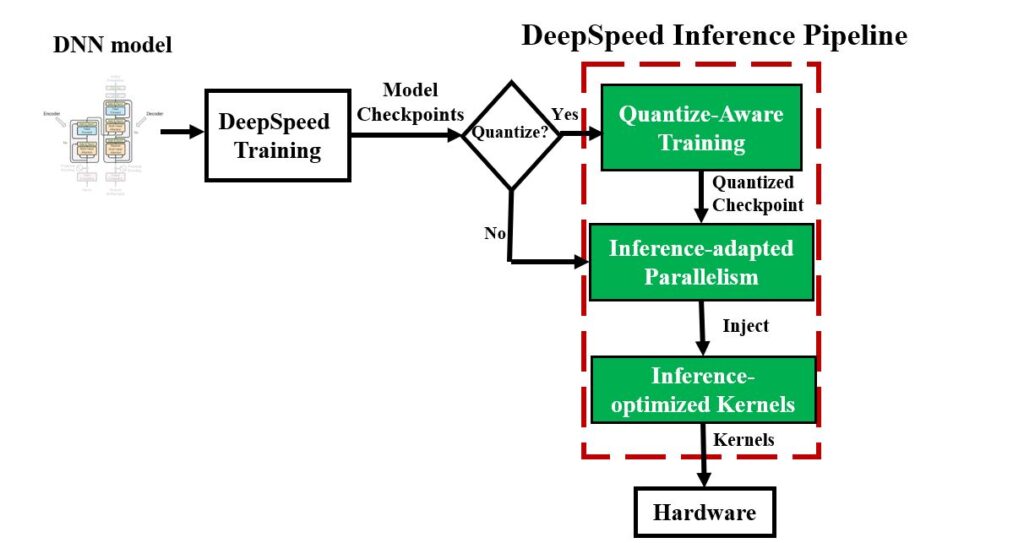
3.4 Ease of use: A seamless pipeline from training to inference
DeepSpeed 提供了一个无缝管道来利用这些优化、准备经过训练的模型并部署模型以实现快速且经济高效的推理,如下图所示。
3.5 Latency speedups on open-source models with publicly available checkpoints
DeepSpeed Inference 可加速各种开源模型:BERT、GPT-2 和 GPT-Neo 等。下图显示了 DeepSpeed Inference 在分别具有通用和专用 Transformer 内核的单个 NVIDIA V100 Tensor Core GPU 上的执行时间。结果表明,与 PyTorch 基线相比,通用内核为这些模型提供了 1.6-3 倍的加速。可以通过专门的内核进一步减少延迟,实现 1.9-4.4 倍的加速。由于这些模型的检查点是公开可用的,因此 DeepSpeed 用户可以按照教程直接轻松地利用这些模型的推理优势。
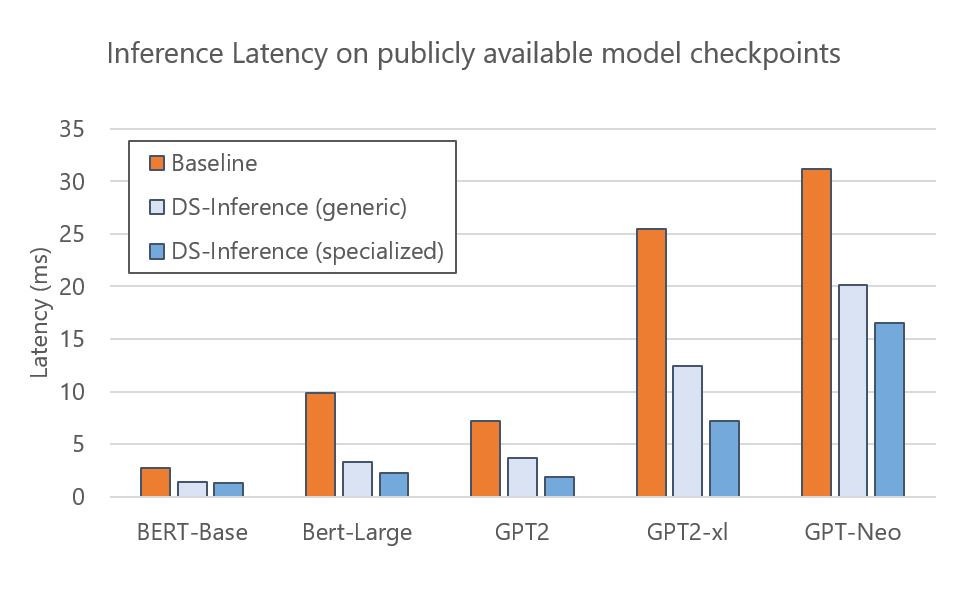
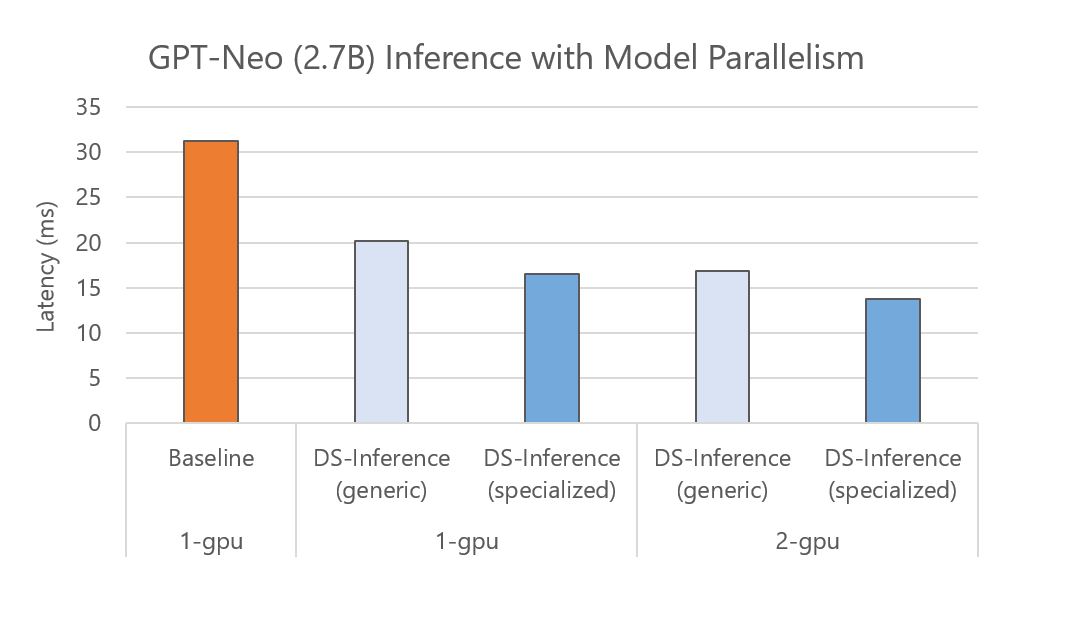
DeepSpeed Inference 还支持通过跨多个 GPU 的自动张量切片模型并行性进行快速推理。特别是,对于经过训练的模型检查点,DeepSpeed 可以加载该检查点并自动在多个 GPU 上分区模型参数以进行并行执行。下图显示了 GPT-Neo (2.7B) 在一个 GPU 和两个具有双向模型并行性的 GPU 上进行基线和 DeepSpeed Inference (DS-Inference) 的执行时间。一方面,DeepSpeed Inference 通过使用通用和专用 Transformer 内核,分别将单个 GPU 上的性能提高了 1.6 倍和 1.9 倍。另一方面,可以通过使用自动张量切片将模型划分到两个 GPU 上来进一步减少延迟。总的来说,通过将定制推理内核的影响与模型并行推理执行相结合,实现了 2.3 倍的加速。
3.6 DeepSpeed-FastGen
动态分割融合(Dynamic SplitFuse)合是一种用于提示处理和token生成的新型token组成策略。DeepSpeed-FastGen 利用动态分割融合策略,通过从提示中取出部分token并与生成过程相结合,使得模型可以保持一致的前向传递大小(forward size)。具体来说,动态分割融合执行两个关键行为:
- 将长提示分解成更小的块,并在多个前向传递(迭代)中进行调度,只有在最后一个传递中才执行生成。
- 短提示将被组合以精确填满目标token预算。即使是短提示也可能被分解,以确保预算被精确满足,前向大小(forward sizes)保持良好对齐。
动态分割融合(Dynamic SplitFuse)提升了以下性能指标:
- 更好的响应性: 由于长提示不再需要极长的前向传递来处理,模型将提供更低的客户端延迟。在同一时间窗口内执行的前向传递更多。
- 更高的效率: 短提示的融合到更大的token预算使模型能够持续运行在高吞吐量状态。
- 更低的波动和更好的一致性: 由于前向传递的大小一致,且前向传递大小是性能的主要决定因素,每个前向传递的延迟比其他系统更加一致。生成频率也是如此,因为DeepSpeed-FastGen不需要像其他先前的系统那样抢占或长时间运行提示,因此延迟会更低。
因此,与现有最先进的服务系统相比,DeepSpeed-FastGen 将以允许快速、持续生成的速率消耗来自提示的token,同时向系统添加token,提高系统利用率,提供更低的延迟和更高的吞吐量流式生成给所有客户端。
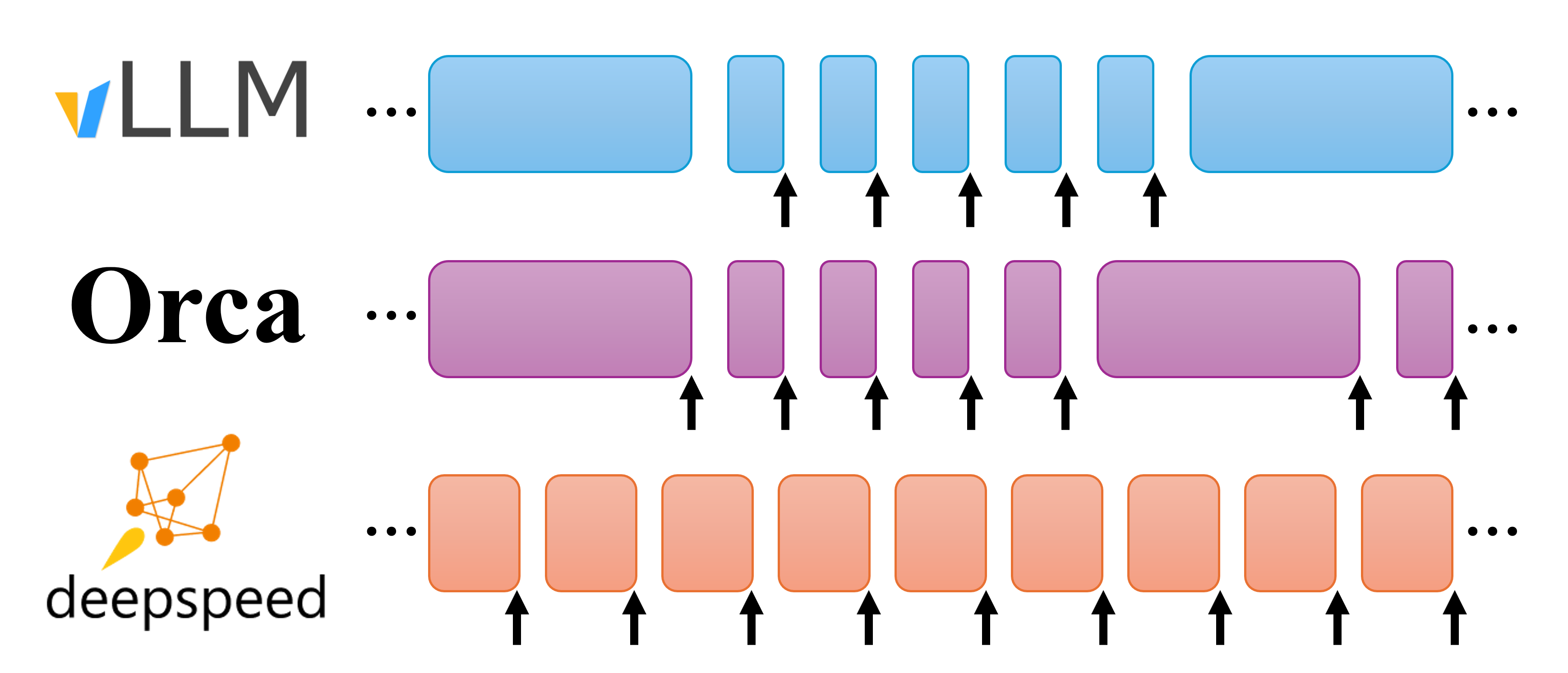
每个块显示一个前向传递的执行。箭头表示前向传递有一个或多个生成的token序列。vLLM 在一个前向传递中要么生成token,要么处理提示;token生成抢占提示处理。Orca 在生成过程中以完整长度处理提示。DeepSpeed-FastGen动态分割融合则执行固定大小批次的动态组合,包括生成和提示token。
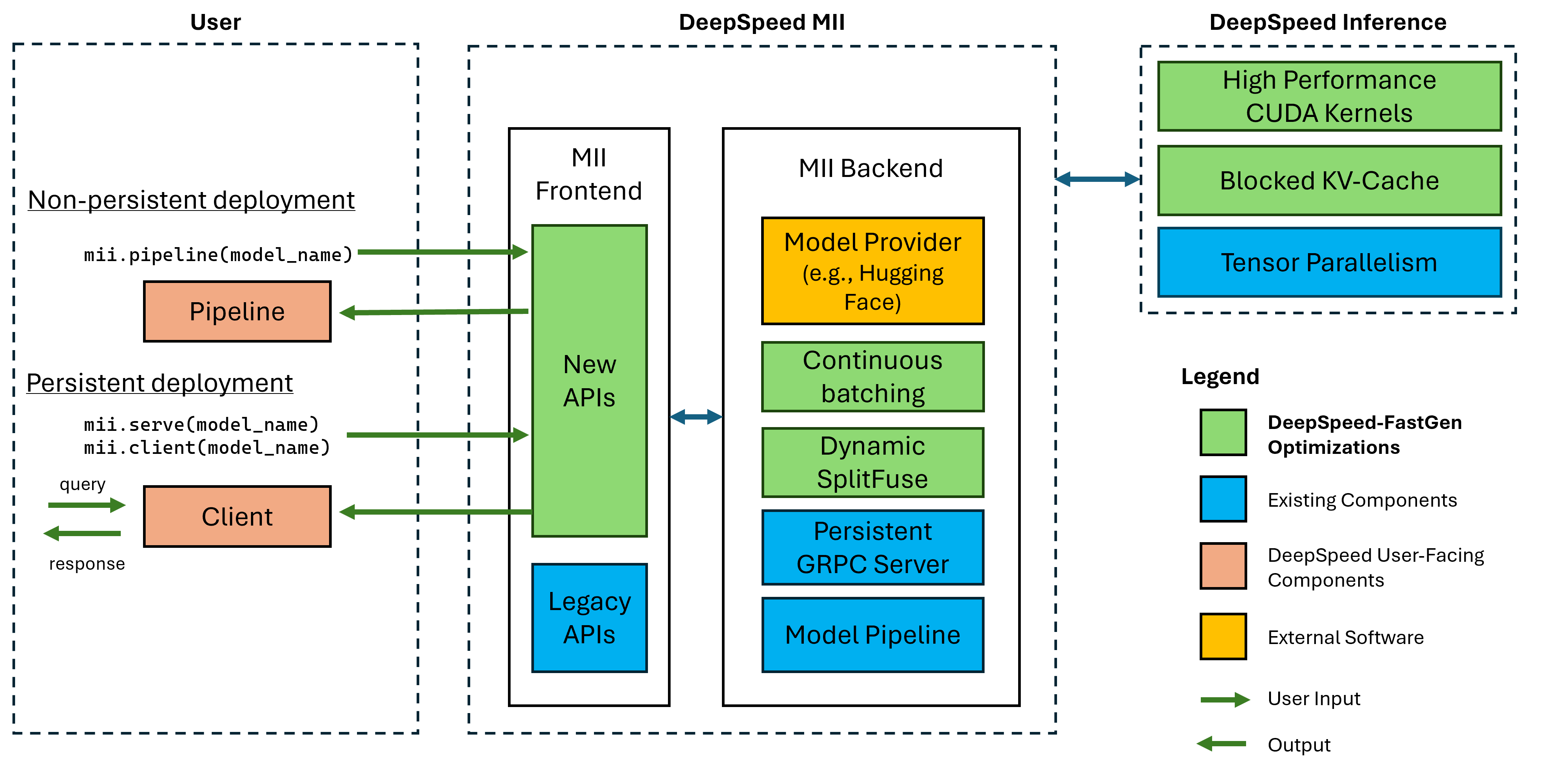
DeepSpeed-FastGen 是 DeepSpeed-MII 和 DeepSpeed-Inference 的协同组合,如下图所示。这两个软件包共同提供了系统的各个组成部分,包括前端 API、用于使用动态 SplitFuse 调度批次的主机和设备基础设施、优化的内核实现,以及构建新模型实现的工具。
3.7 System optimizations
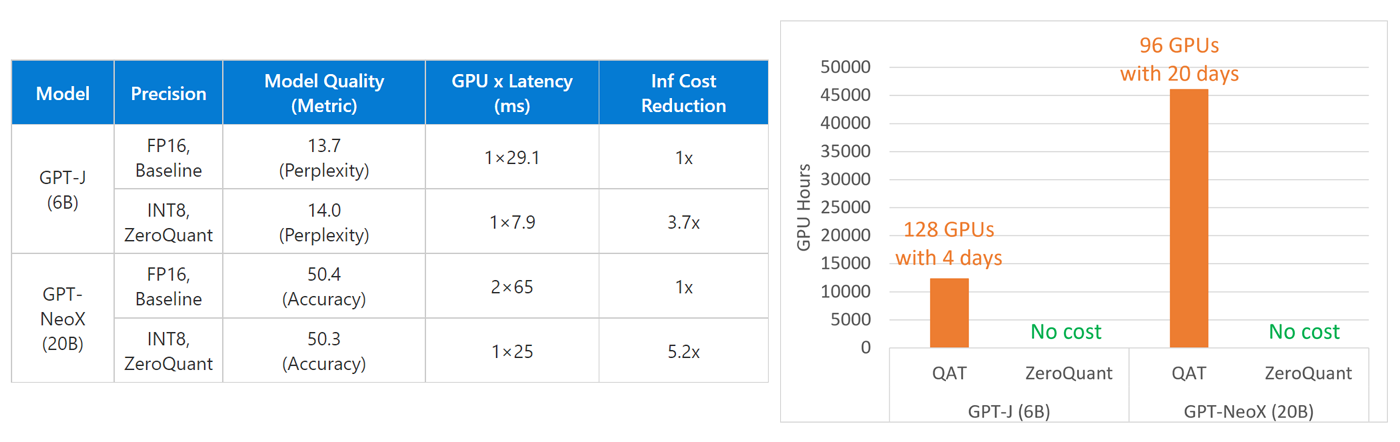
系统优化在有效利用可用硬件资源并通过 ONNX 运行时和 DeepSpeed 等推理优化库释放其全部功能方面发挥着关键作用。这些工作建立在 DeepSpeed 推理之上,它提供了具有推理优化内核、并行性和内存优化的高性能模型,涵盖了针对延迟敏感和吞吐量导向型应用程序的各种模型。除了利用这些之外,还扩展了推理能力以支持压缩格式的模型。例如,DeepSpeed开发了高效低位计算的变体,例如 INT8 GeMM 内核。这些内核将 INT8 参数和激活从 GPU 设备内存加载到寄存器,并使用在针对不同批量大小进行调整的 CUTLASS 之上实现的定制 INT8 GeMM,以提供更快的 GeMM 计算。内核还在GeMM前后融合了量化和反量化操作,进一步减少了内核调用开销并提高了内存带宽利用率。此外,推理引擎支持多 GPU transformer层,以便使用推理适应并行策略跨 GPU 提供transformer模型。对于内存占用较小的压缩模型,推理引擎可以自动减少服务模型所需的 GPU 数量,从而减少跨 GPU 通信和硬件成本。例如,DeepSpeed 压缩利用 GPT-NeoX (20B) 的 INT8,将服务模型的 GPU 要求从 2 个减少到 1 个,将延迟从 65 毫秒减少到 25 毫秒,并实现 5.2 倍的成本降低。 如下图所示,与DeepSpeed自己的 FP16 内核相比,DeepSpeed INT8 内核可以将性能提升高达 2 倍,并且与 PyTorch 中的基准 FP16 相比,它们实现了 2.8-5.2 倍的延迟成本降低,从而显着降低了大规模计算的延迟和成本。比例模型推断。
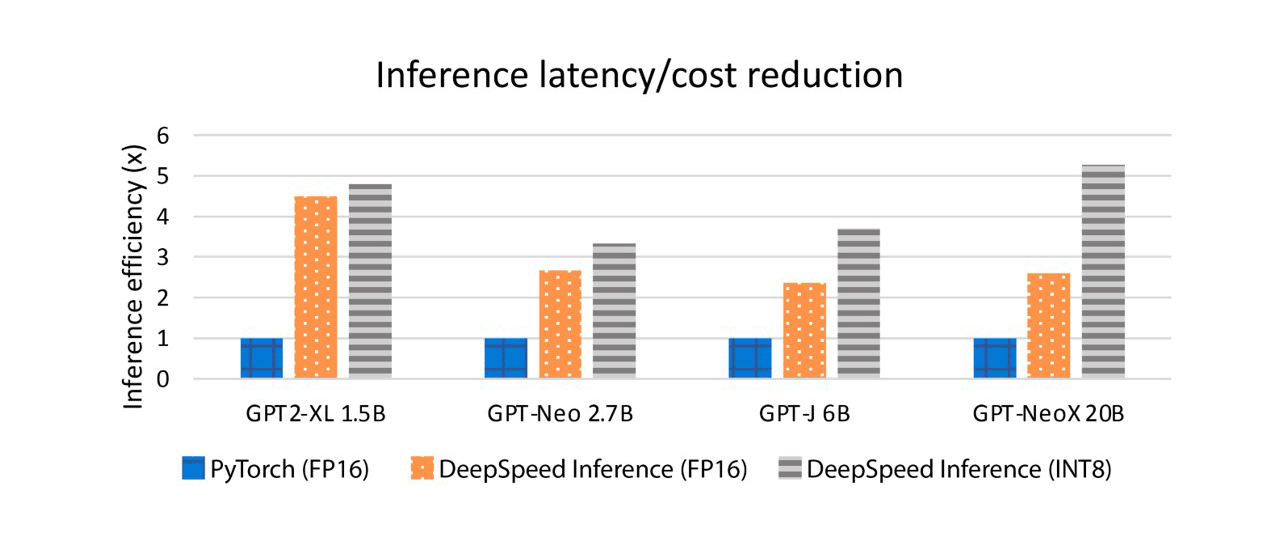
四、DeepSpeed Compression
4.1 XTC
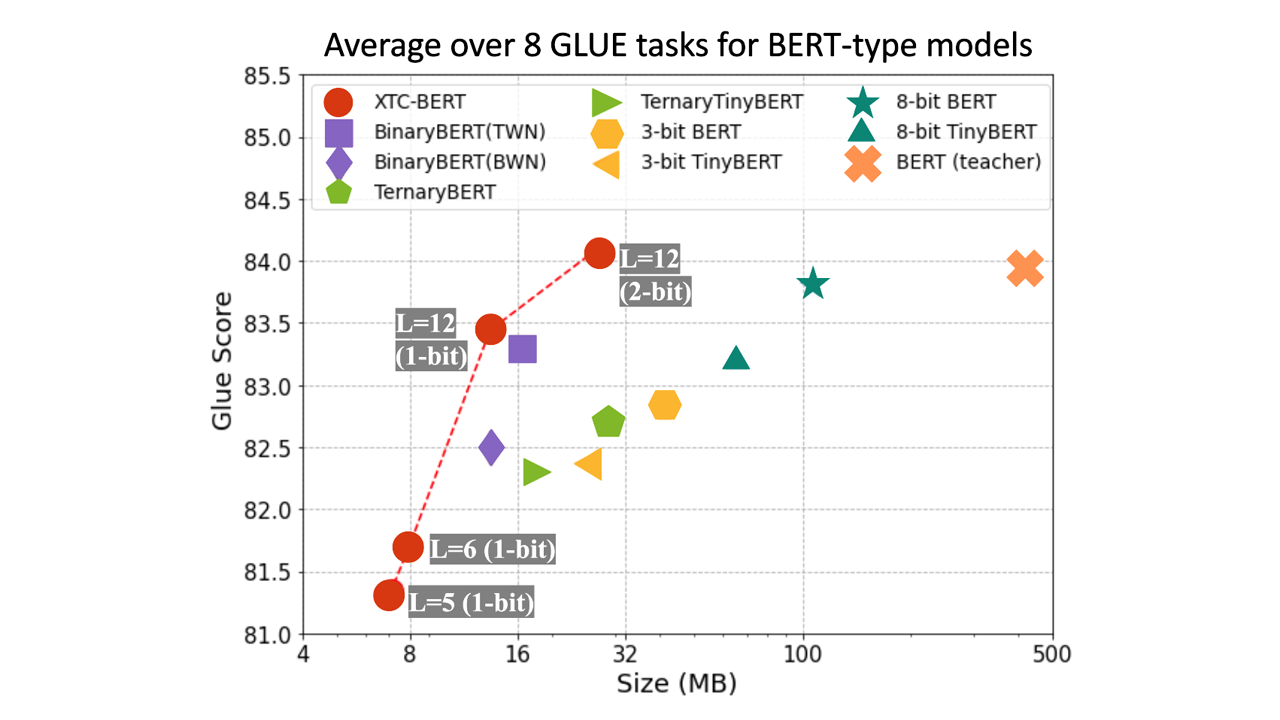
XTC(eXTreme Compression)通过轻量级层减少和强大的二值化将模型压缩到极限。XTC 通过简单而有效的二值化技术将模型大小减少了 32 倍,而 GLUE 任务的平均分数几乎没有损失。通过结合极端量化和轻量级层减少,可以进一步改进二值化模型,实现 50 倍的模型大小减少,同时保持 97% 的准确率。论文:《Extreme Compression for Pre-trained Transformers Made Simple and Efficient》
4.1.1 二值量化
论文:《BinaryConnect: Training Deep Neural Networks with binary weights during propagations》中提出了基于量化的模型压缩方法,核心是将模型中的参数转换成1或-1这两种数值,从而将乘法运算转换为加法运算,进而实现减小运行开销和压缩模型尺寸。
BinaryConnect的核心主要在于两点,一个是如何将参数实数值转换为1或-1,另一个是二值化后的参数如何参与网络训练和参数更新。针对第一点,文中提出两种二值化方法,第一种是大于0的参数映射到1,其他参数映射到-1;第二种是随机二值化,根据权重大小生成一个概率,映射到1或-1,公式如下:
第二个点是如何应用BinaryConnect,在前向传播和反向传播过程中,使用二值化的参数参与计算,在梯度更新参数时,使用原始精度更高的参数更新。因为在随机梯度下降中,参数的更新需要保证较高的精度才能使更新过程稳定。

二值化的一个好处是,相当于给权重和激活函数增加了噪声,起到了网络参数正则化的作用,和dropout等有类似的功效。BinaryConnect方法存在的问题是,量化的过程没有可学习的参数,模型不知道如何调整量化的尺度适应模型训练过程中的损失。在量化权重参数时,由于权重的分布比较集中,并且可以加正则化约束,因此问题不大。但是在量化激活函数时,relu的输出没有上界,因此如何选择量化的阈值对于量化效果至关重要。《PACT: Parameterized Clipping Activation for Quantized Neural Networks》提出了PACT方法,让模型动态学习量化的clipping阈值,截断部分离群点,让参数的量化结果更精确。《Learned Step Size Quantization》中则对反量化进行优化,通过网络学习反量化的step size实现更精准的参数还原。
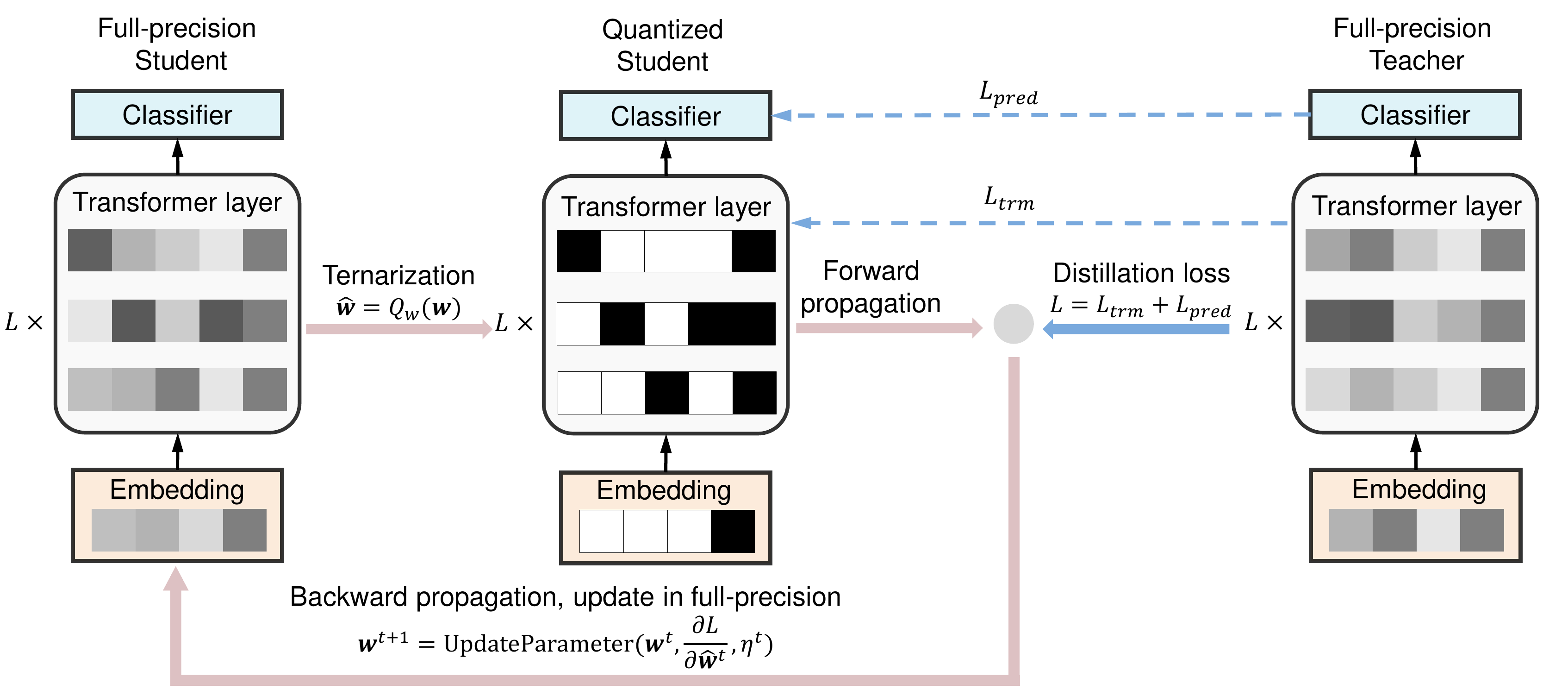
4.1.2 针对BERT模型的量化压缩
论文:《TernaryBERT: Distillation-aware Ultra-low Bit BERT》将BERT中的权重参数三值化为{-1, 0, 1}中的一个值,以及一个缩放参数,并且对于每层网络、每列参数使用不同的缩放参数。对于激活函数则用min-max的方法量化到8bit。由于量化后的BERT表征能力变弱,本文还是用了知识蒸馏的方式,让量化BERT作为student网络,使用一个teacher网络指导student网络的学习。整体的网络结构如下图所示:
Ternarybert对于权重的量化公式如下,目标是让缩放函数

4.1.3 BERT 1-bit压缩
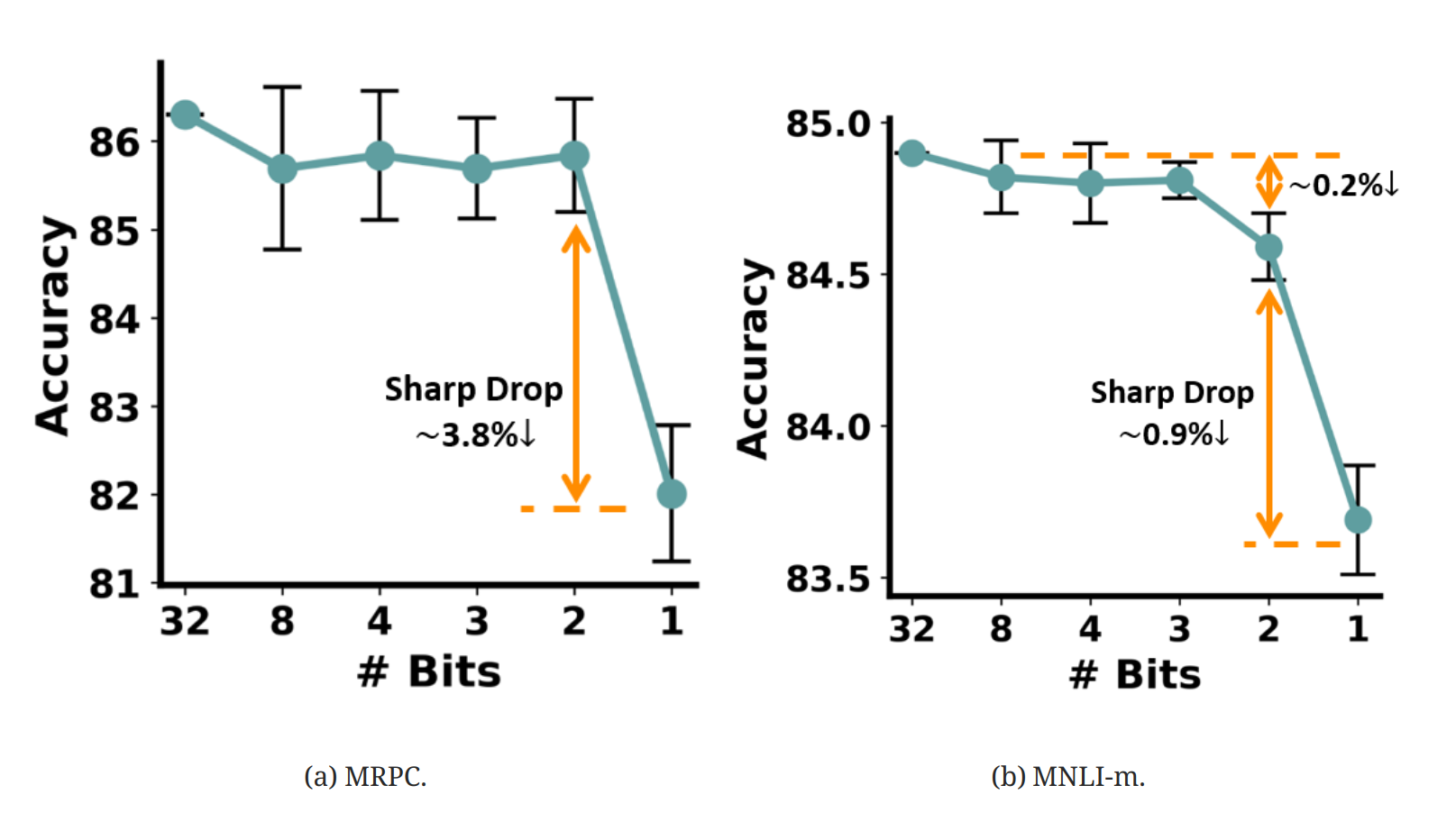
论文:《BinaryBERT: Pushing the Limit of BERT Quantization》对BERT实现了进一步的1-bit压缩。一般的方法压缩到1-bit效果损失很严重(如下图所示)。
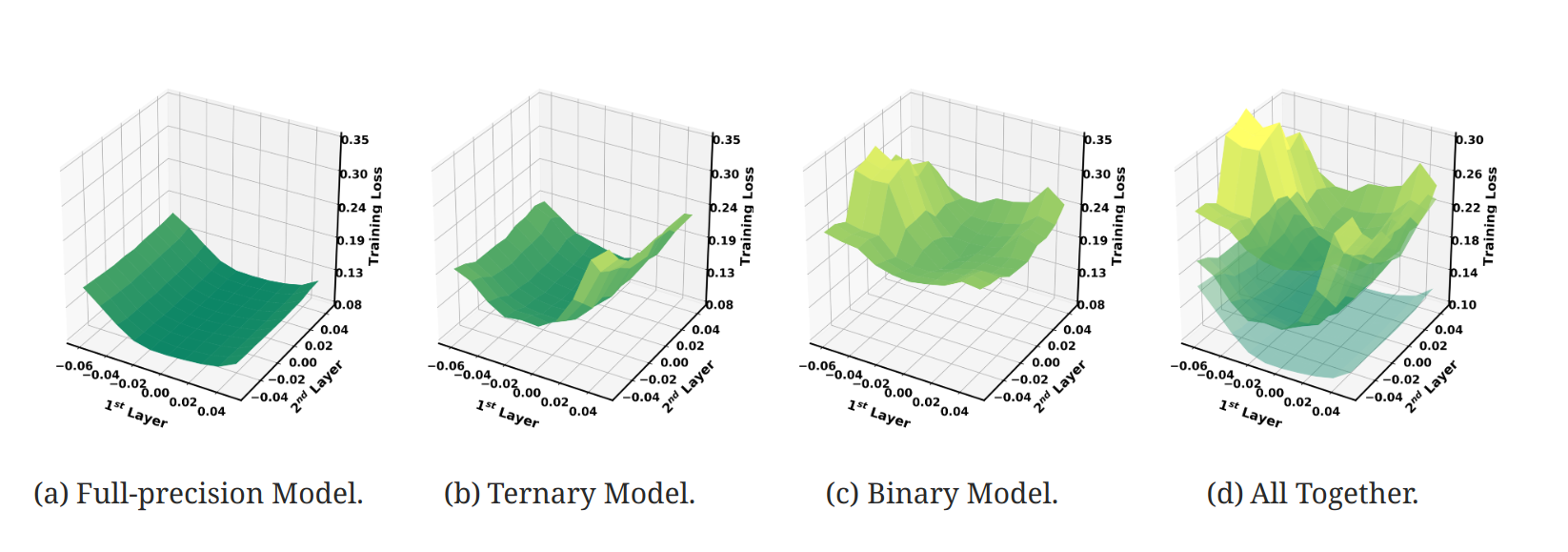
造成binary压缩效果损失很大的原因在于,1-bit量化后的优化超平面非常复杂,导致模型的训练过程很困难,下面是一个可视化的优化超平面图,可以看到binary model由于量化过细导致超平面被分割成很多不平滑的区间:
为了解决这个问题,论文采用的思路是首先训练一个最终模型尺寸一半的TernayBERT,利用其更加平滑的超平面实现初始参数的学习。然后利用TWS Operator将参数进行转换,作为BinaryBERT的初始化参数,再基于此参数进行模型finetune。
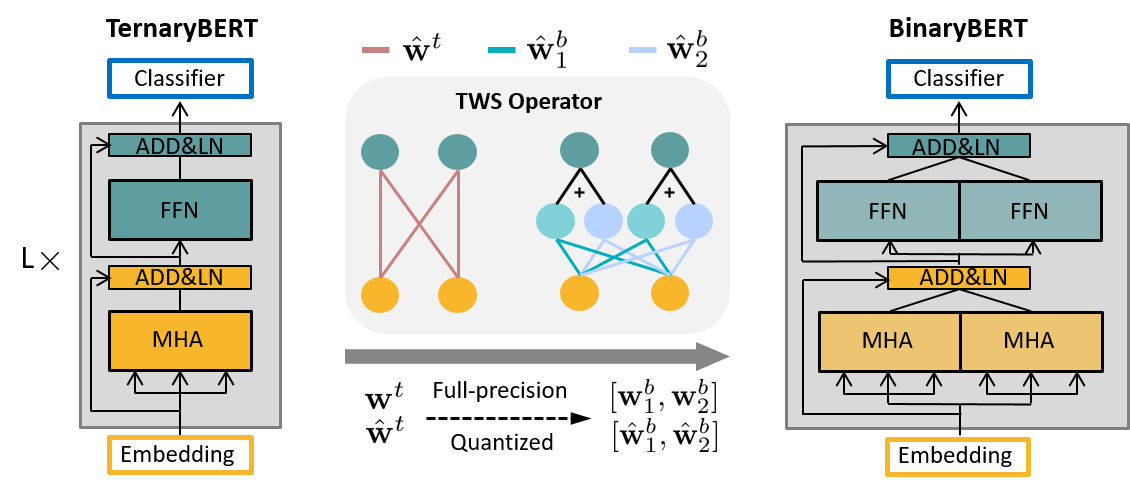
Ternary Weight Splitting
考虑到二元 BERT
损失优化比较有挑战,论文提出了三元权重分割(ternary weight
splitting,
TWS),它利用三元损失情况的平坦性作为二元模型的优化代理。如图上图所示,首先训练半尺寸的三元
BERT 收敛,然后通过TWS 算子将潜在全精度权重
虽然方程~
其中
其中
Quantization Details
接下来,对于 Transformer 层中的每个权重矩阵,我们使用逐层三元化(即,权重矩阵中的所有元素都有一个缩放参数)。对于词嵌入,使用逐行三元化(即,嵌入中的每一行都有一个缩放参数)。拆分后,两个拆分矩阵中的每一个都有自己的缩放因子。
除了权重二值化之外,还在所有矩阵乘法之前同时量化激活,这可以加速专用硬件上的推理。接下来,跳过所有层规范化~(LN) 层的量化,跳过连接和偏差,因为它们的计算与矩阵乘法相比可以忽略不计。最后一个分类层也没有量化,以避免准确率大幅下降。
Training with Knowledge Distillation
知识蒸馏被证明有利于 BERT 量化。接下来,首先从全精度教师网络的嵌入
然后,通过小化量化的学生逻辑
Further Fine-tuning
从半尺寸三元模型中分离出来后,二元模型在全宽的新架构上继承了其性能。然而,三元模型的原始最小值可能在分裂后的新损失环境中不成立。因此,进一步通过预测层蒸馏进行微调,以寻找更好的解决方案。将生成的模型称为 BinaryBERT。
4.1.4 XTC(eXTreme Compression)
论文:《Extreme Compression for Pre-trained Transformers Made Simple and Efficient》提出了一种简单而有效的方法,专为极轻量压缩而设计。
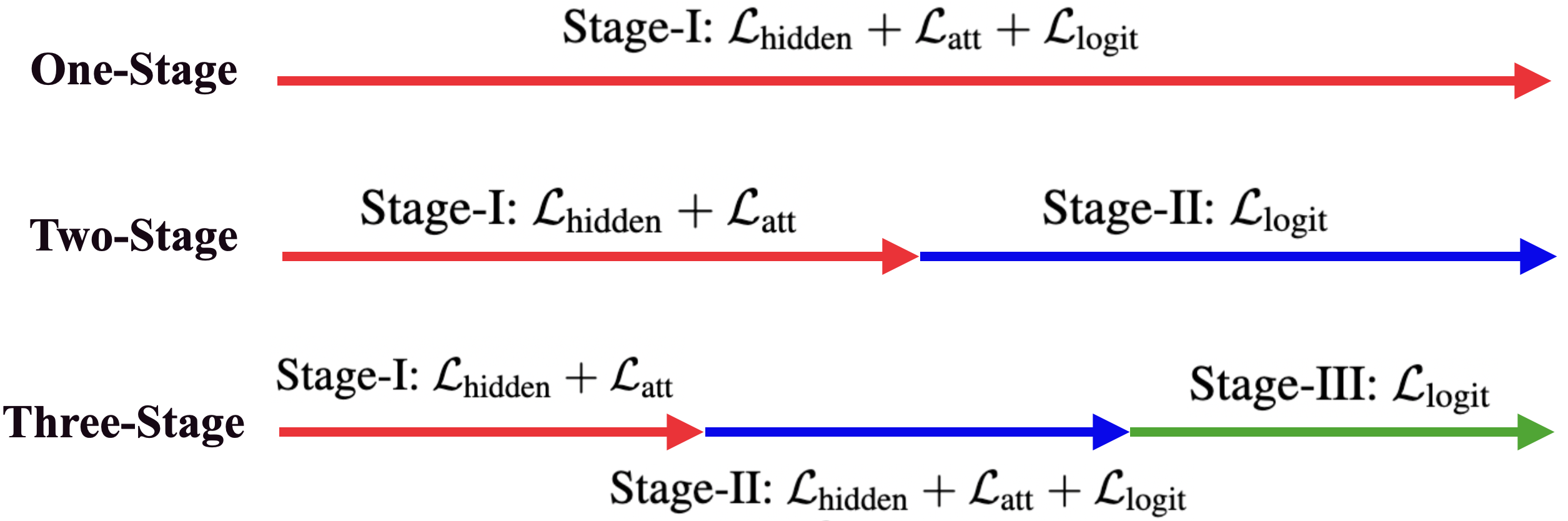
三种类型的知识蒸馏。 1S-KD (顶部红色箭头线)涉及从训练开始到结束的所有隐藏状态、注意力和逻辑输出。 2S-KD(中间的红色和蓝色箭头线)将隐藏状态和注意力与逻辑部分分开。虽然 3S-KD(底部红、蓝、绿箭头线)继承了 2S-KD,但它还在训练中间增加了一个过渡阶段。

上图右为XTC,它仅包含 2 个步骤:
- 步骤 I:轻量级层减少。与常见的层减少方法(通过计算成本高昂的预训练蒸馏获得层减少模型)不同,XTC选择微调教师权重的子集作为轻量级层减少方法来初始化层减少模型。当与本文中确定的其他训练策略结合使用时,发现与其他现有方法相比,这种轻量级方案可以实现更大的压缩比,同时创下新的最先进结果。
- 步骤 II:通过应用 1S-KD 和 DA 以及长时间训练进行 1-bit量化。一旦获得了层数减少的模型,就应用量化感知的 1S-KD。具体来说,使用ultra-low bit (1-bit/2-bit)量化器来压缩层数减少的模型权重以进行前向传递,然后在后向传递期间使用 STE(straight-through estimator) 来传递梯度。同时,通过启用数据增强和更长的训练 Budget-C(使得训练损失接近于零)来最小化单阶段深度知识蒸馏目标。
STE:一种通过随机神经元的预期梯度估计器。这个想法只是通过硬阈值函数进行反向传播(如果参数为正则为 1,否则为 0),就好像它是恒等函数一样。它显然是一个有偏差的估计器,但是当考虑单层神经元时,它具有正确的符号(当通过更多隐藏层反向传播时,不再保证这一点)。
XTC 通过简单而有效的二值化技术将模型大小减小了 32 倍,并且 GLUE 任务的平均得分几乎没有损失。通过结合极端量化和轻量级层缩减,可以进一步改进二值化模型,实现 50 倍的模型尺寸缩减,同时保持 97% 的精度。
4.2 ZeroQuant
论文:《ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers》
由于缺乏训练资源和/或数据访问,具有数千亿参数的大型transformer模型通常难以量化。为了解决这些问题,DeepSpeed提出了一种名为 ZeroQuant 的方法,该方法可以在有限的资源上以很少或没有微调成本来量化大型模型。在底层,ZeroQuant 包含两个主要部分:1) 硬件友好的细粒度量化方案,使我们能够以最小的错误将权重和激活量化为低位值,同时仍然能够在低量化/反量化的商用硬件上实现快速推理速度成本; 2)逐层知识蒸馏管道,对量化模型进行微调,以缩小与低精度(例如 INT4)量化的精度差距。
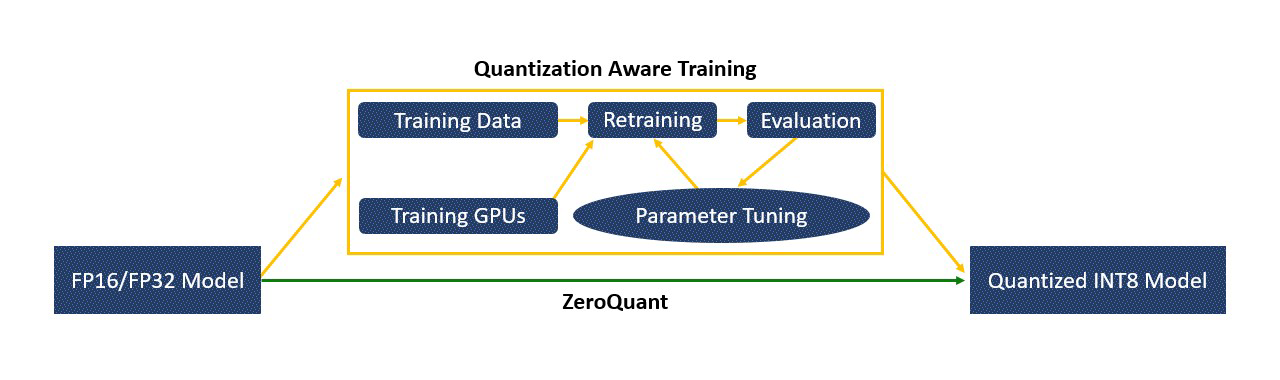
ZeroQuant 的好处有三个:首先,与之前需要昂贵的重新训练和参数调整的量化感知训练不同,ZeroQuant 能够将 BERT 和 GPT 式模型从 FP32/FP16 量化为 INT8 权重和激活,以保持准确性,而不会产生任何重新训练成本,如下图所示。其次,通过一次仅加载一层进行低精度(例如 INT4)量化,量化模型所需的最大内存占用量仅取决于单个层的大小,而不是整个模型的大小,允许人们用最少一个 GPU 来量化巨大的模型。第三,量化方法是无数据的,这意味着它不需要模型的原始训练数据来获得量化模型。例如,当由于隐私相关原因导致数据不可用时,这尤其有用。
INT8 PTQ 应用于 BERT/GPT-3 型模型也会导致准确性显着下降。关键挑战在于 INT8 的表示无法完全捕捉权重矩阵中不同行和不同激活token的不同数值范围。 解决此问题的一种方法是对权重矩阵(激活)使用group-wise(token-wise)量化。
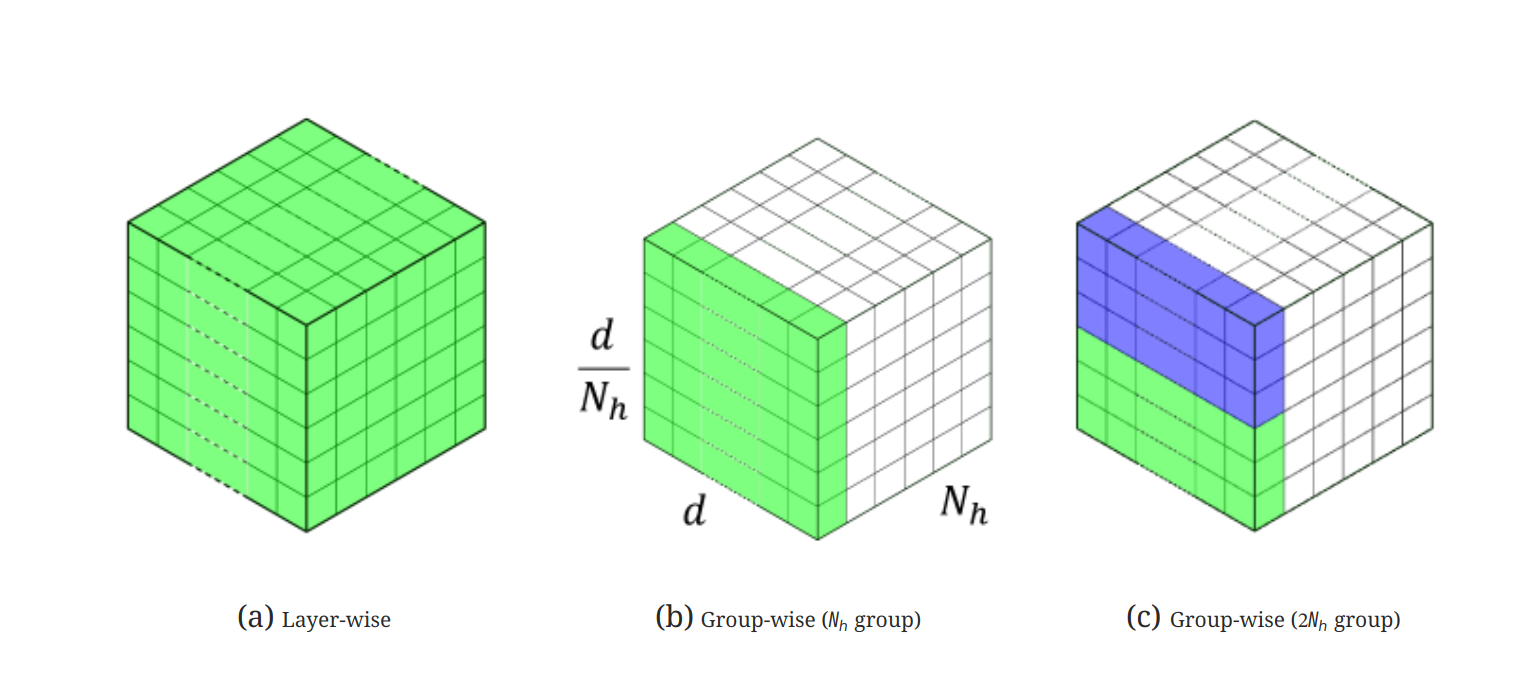
用多头自注意层的值矩阵来说明这一点。这里
权重的Group-wise量化:最早在《Q-BERT: Hessian Based Ultra Low
Precision Quantization of BERT》中提出,其中权重矩阵
在本文的设计中,考虑了 GPU 的 Ampere 架构(例如 A100)的硬件约束,其中计算单元基于 Warp Matrix Multiply and Accumulate (WMMA) 平铺大小以实现最佳加速。
用于激活的Token-wise量化:现有PTQ工作的一个常见做法是使用静态量化进行激活,其中最小/最大范围是在离线校准阶段计算的。这种方法可能适用于激活范围方差较小的小规模模型。但是,对于大规模 Transformer 模型,激活范围存在巨大差异。因此,静态量化方案(通常应用于所有 token/样本)会导致准确度大幅下降。克服此问题的一个自然想法是采用更细粒度的token-wise量化并动态计算每个 token 的最小/最大范围,以减少激活带来的量化误差。
但是,直接使用现有的 DL 框架(例如 PyTorch 量化套件)应用token-wise的量化会导致显著的量化和反量化成本,因为token-wise的量化会引入额外的操作,从而导致 GPU 计算单元和主内存之间昂贵的数据移动开销。为了解决这个问题,本文为 Transformer 模型的token-wise量化构建了一个高度优化的推理后端。例如,ZeroQuant的推理后端采用所谓的内核融合技术将量化运算符与其前一个运算符(如层规范化)融合,以减轻token-wise量化的数据移动成本。类似地,通过使用权重和激活量化尺度缩放 INT32 累积,可以减轻不同 GeMM 输出的反量化成本,然后将最终的 FP16 结果写回主内存以供下一个 FP16 运算符(如 GeLU)使用。
4.2.1 逐层蒸馏(layer-by-layer distillation,LKD)
知识蒸馏(KD)是缓解模型压缩后精度下降的最有力方法之一。然而,KD 存在一些局限性,特别是对于大规模语言模型上的隐藏状态 KD:(1)KD 需要在训练过程中将教师和学生模型放在一起,这大大增加了内存和计算成本; (2)KD通常需要对学生模型进行充分训练。因此,需要在内存中存储权重参数的多个副本(梯度、一阶/二阶动量)来更新模型; (3) KD通常需要原始训练数据,有时由于隐私/机密问题而无法访问。
为了解决这些限制,提出逐层蒸馏(LKD)算法。假设量化的目标模型有
其中
4.2.2 Quantization-Optimized Transformer Kernels

在实践中,优化推理延迟和模型大小对于服务于大规模 Transformer 模型都至关重要。在推理过程中,批处理大小通常相对较小,因此模型的推理延迟主要取决于从主内存加载推理所需数据的时间。通过将权重和激活量化为较低精度,减少了加载这些数据所需的数据量,从而可以更有效地利用内存带宽并提高加载吞吐量。但是,简单地将权重/激活转换为 INT8 并不能保证改善延迟,因为量化/反量化操作会产生额外的数据移动开销,如上图(红框)所示。这样的开销变得昂贵,在某些情况下甚至超过了使用低精度的性能优势。为了在获得改进延迟的同时从 token-wise 量化中获得准确性的提高,现在提出了优化方法,以最大限度地提高内存带宽利用率,从而加快ZeroQuant的推理延迟。
CUTLASS INT8 GeMM:为了支持 INT8 计算,使用针对不同批次大小进行调整的 CUTLASS INT8 GeMM 实现。与标准 GPU 后端库(例如 cuDNN)不同,使用 CUTLASS 能够更灵活地在 GeMM 之前和之后融合量化操作,以减少内核启动和数据移动开销。
Fusing Token-wise Activation Quantization:token-wise的量化/反量化引入了许多额外的操作,从而导致额外的数据移动成本。为了消除这些成本,使用内核融合将激活量化操作与其之前的逐个元素和/或减少操作(如 bias-add、GeLU 和LayerNorm)融合为单个运算符,如上图中的绿色框所示。对于反量化操作(例如,对 GeMM 运算符的整数输出进行反量化),同样将其与自定义 GeMM 计划融合,以避免对主内存进行额外的读/写访问,如上图中的蓝色框所示。
4.3 协同组合压缩算法和系统优化的库
DeepSpeed Compression 提出了一个无缝管道来解决压缩可组合性挑战,如下图所示。DeepSpeed Compression 的核心部分是一个称为压缩编辑器的组件,它包括几个重要的功能:
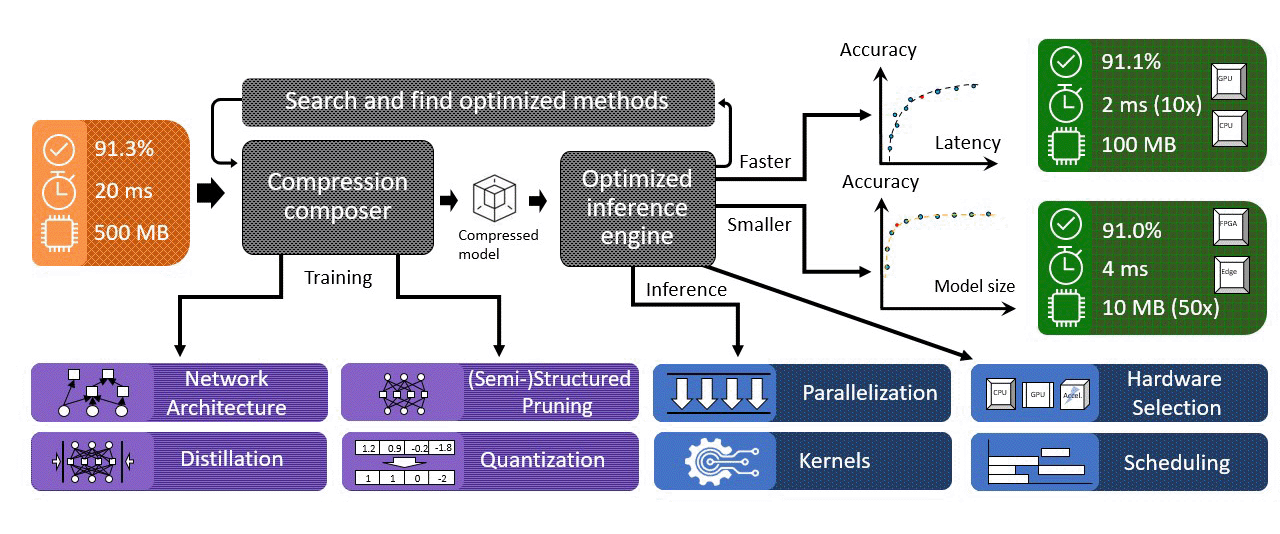
- 它提供了多种前沿的压缩方法,如下表所示,包括极端量化、head/row/channel剪枝、知识蒸馏等,可以有效降低模型大小和推理成本。随着DeepSpeed不断集成更多最先进的压缩方法,该列表将会扩大。

它提供了一个易于使用的 API,可以自动处理组装不同压缩技术的复杂性,以提供多种压缩方法的复合优势。例如,XTC需要轻量级层缩减、二值化和知识蒸馏的组合。然而,将它们组合在一起并非易事。借助压缩编辑器,应用极限压缩就像添加两个新的 API 调用来启用压缩并清理压缩模型一样简单。
它采用模块化方式设计,以便用户可以轻松添加新的压缩方案。例如,可以通过自定义压缩层添加额外的压缩方法,并且通过将它们注册到压缩编写器,新方法可以与已经由编写器管理的现有方法组合。
它与现有的 DeepSpeed 库无缝协作。这有两个好处。首先,可以像通过 JSON 文件进行 DeepSpeed 训练和推理一样指定和启用 DeepSpeed 压缩,其中启用不同的压缩技术组合只需要在 JSON 文件中进行几行修改。其次,一旦配置了压缩方案,压缩编辑器就会自动修改模型层和训练以启用压缩过程,并且不需要用户对模型结构或训练过程进行额外的更改。
DNN 模型被压缩后,DeepSpeed Compression 会用 DeepSpeed Inference 引擎中高度优化的内核替换压缩层,以最大限度地提高硬件效率。压缩编译器和推理引擎共同实现了压缩和系统优化的最佳效果,从而实现了降低推理成本的复合效果。
五、DeepSpeed4Science
DeepSpeed4Science的新计划,旨在通过AI系统技术创新帮助领域专家解锁当今最大的科学之谜。
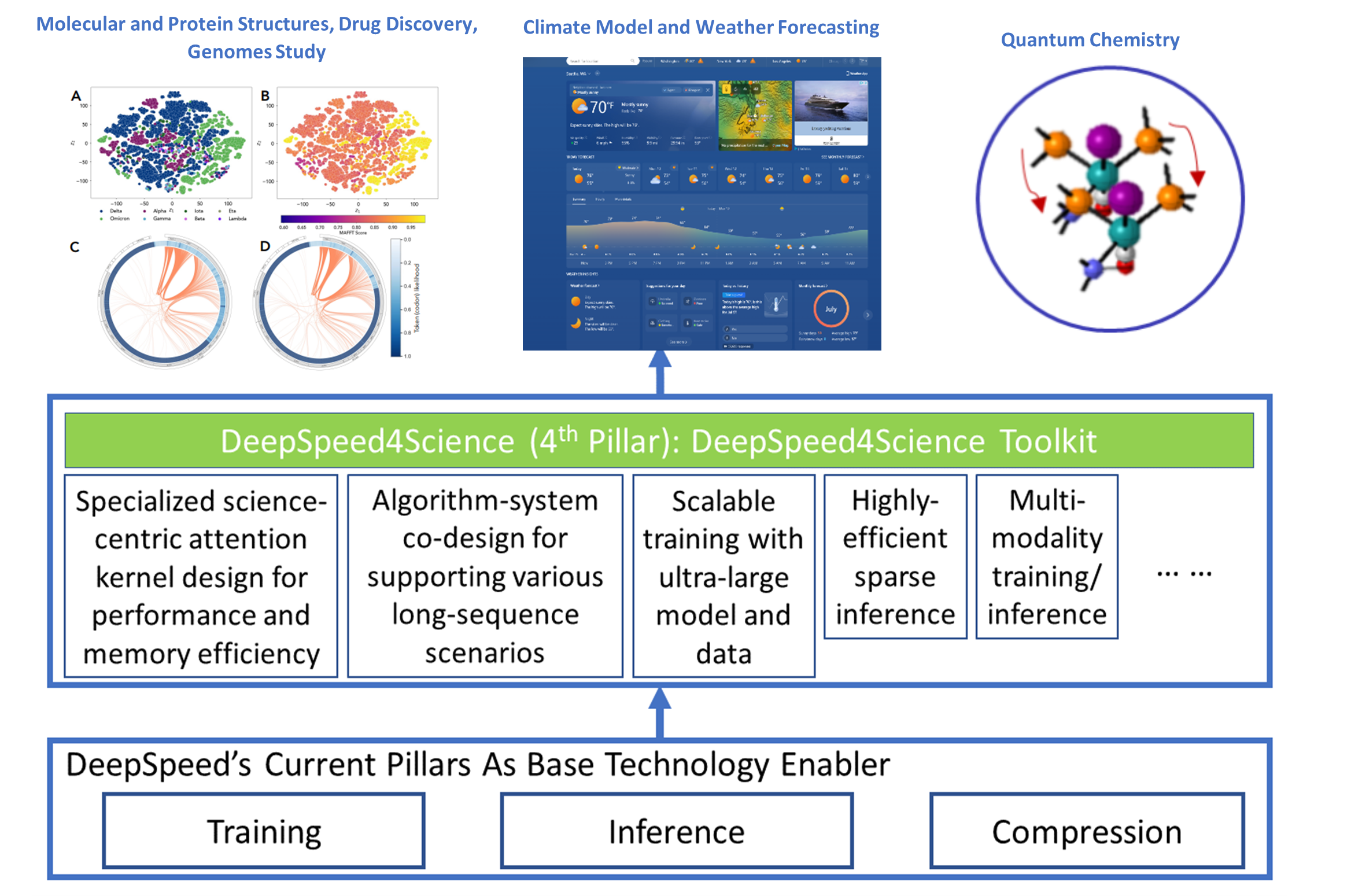
通过利用DeepSpeed当前的技术方案(训练、推理和压缩)作为基础技术推动器,DeepSpeed4Science将创建一套专为加速科学发现而量身定制的AI系统技术,以应对其独特的复杂性,超越用于加速通用大型语言模型(LLMs)的常见技术方法。我们与拥有科学AI模型的内部和外部团队紧密合作,以发现和解决领域特定AI系统的挑战。这包括气候科学、药物设计、生物学理解、分子动力学模拟、癌症诊断和监测、催化剂/材料发现、和其他领域。
5.1 科学基础模型
科学基础模型(Scientific Foundation Model,SFM),微软研究院AI4Science

科学基础模型(SFM)旨在创建一个统一的大规模基础模型,以支持自然科学发现,支持多种输入、多个科学领域(例如,药物、材料、生物学、健康等)和计算任务。DeepSpeed4Science合作伙伴关系将为SFM团队提供新的训练和推理技术,以支持他们的新生成AI方法(例如Distributional Graphormer)这样的项目进行持续研究。
5.2 ClimaX
ClimaX,微软研究院AI4Science
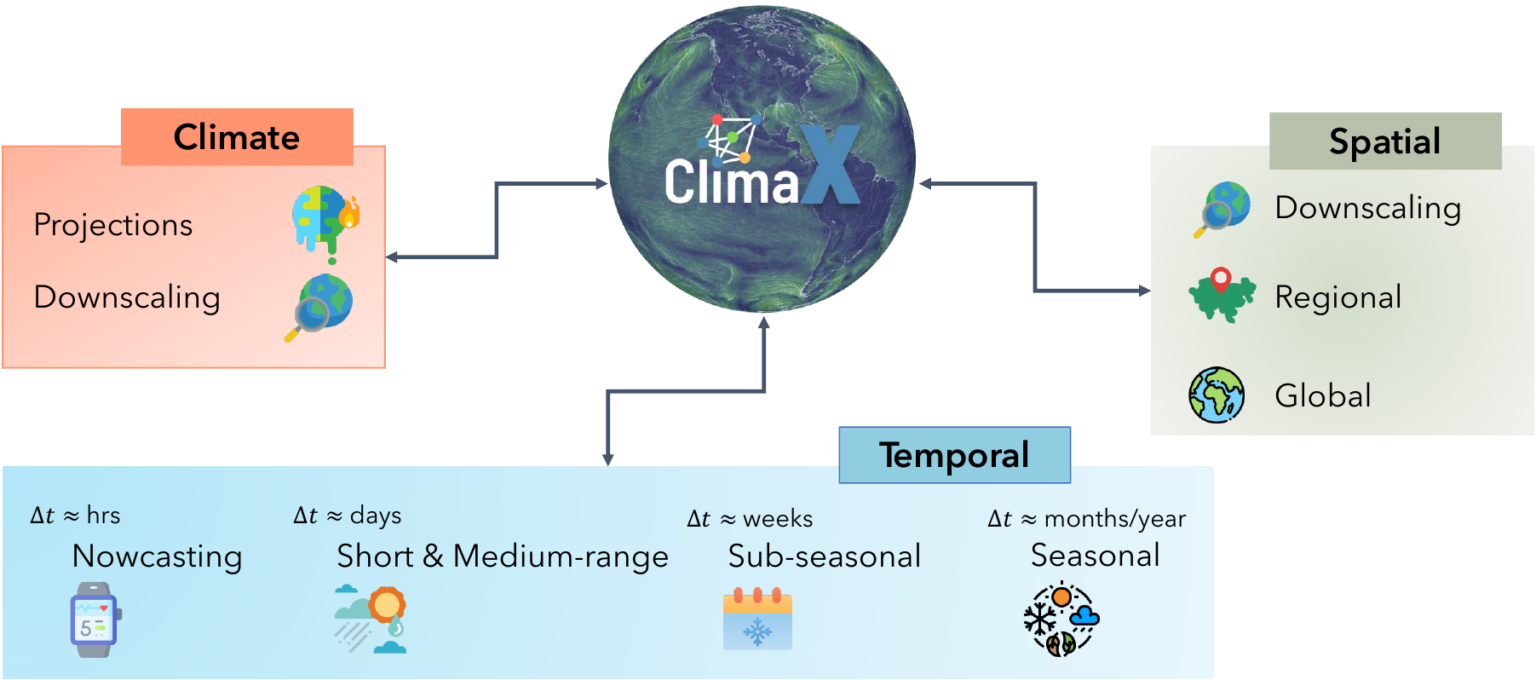
ClimaX是第一个设计用于执行各种天气和气候建模任务的基础模型。它可以吸收许多具有不同变量和分辨率的数据集以提高天气预报的准确性。DeepSpeed4Science正在为ClimaX创建新的系统支持和加速策略,以高效地预训练/微调更大的基础模型,同时处理非常大的高分辨率图像数据(例如,数十到数百PB)和长序列。
5.3 分子动力学和机器学习力场
分子动力学和机器学习力场(Molecular Dynamics and Machine Learning Force Field),微软研究院AI4Science

这个项目模拟了使用AI驱动的力场模型进行近似第一性原理计算精度的大型(百万原子)分子系统的动态模拟,同时保持了经典分子动力学的效率和可扩展性。这些模拟足够高效,可以生成足够长的轨迹来观察化学上有意义的事件。通常,这个过程需要数百万甚至数十亿的推理步骤。这对优化图神经网络(GNN)+ LLM模型的推理速度提出了重大挑战,DeepSpeed4Science将为此提供新的加速策略。
5.4 内存高效的 EvoformerAttention 内核
AlphaFold 2 中使用的带有 EvoformerAttention 的原始 OpenFold 实现。在训练/推理这些类型的蛋白质结构预测模型中,内存爆炸问题很常见。特别是,FlashAttention 无法有效支持此类科学注意力变体。DeepSpeed4Science 优化解决方案显着降低了总体峰值内存需求。
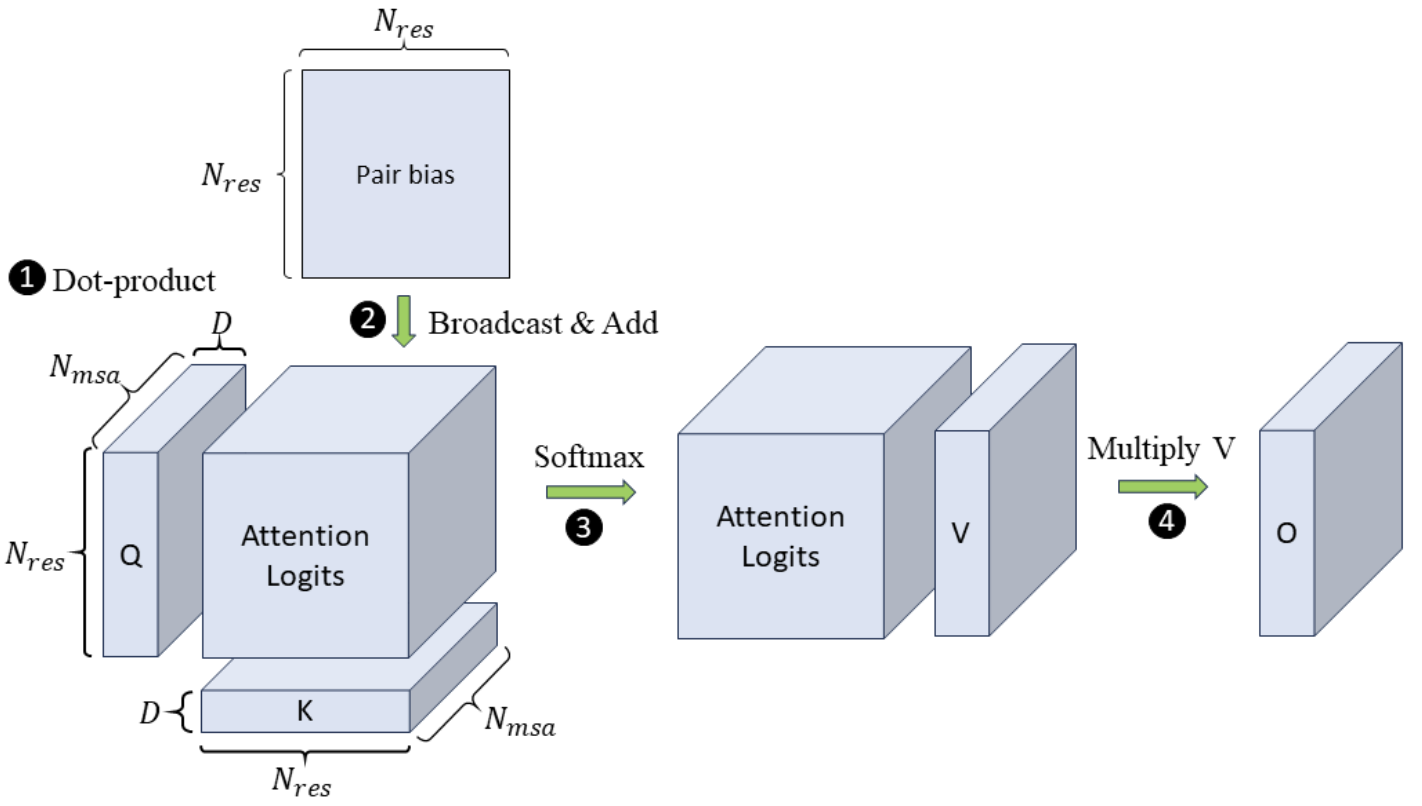
OpenFold 中 MSA 逐行注意力计算的示例,分四步。该示例显示了一个注意力头的计算,其中输入 Q、K 和 V 是 3D 张量,配对偏差是一个矩阵。每个注意力头都与导致内存爆炸的 3D 中间注意力 logit 相关联。DeepSpeed4Science在一个内核中融合了四个步骤,以减少峰值内存使用量。
DeepSpeed4Science 正在通过为注意力变体(即 EvoformerAttention)设计定制的精确注意力内核来解决这种记忆效率低下的问题,这种注意力变体广泛出现在本文中。科学模型的类别。具体来说,为更广泛的社区创建了一组高内存效率的DS4Sci_EvoformerAttention内核,这些内核由复杂的融合/平铺策略和动态内存减少方法启用,作为高质量的机器学习原语。它们合并到 OpenFold 中,在训练过程中提供了显着的加速,并显着降低了模型训练和推理的峰值内存需求。这使得 OpenFold 能够尝试更大、更复杂的模型和更长的序列,并在更广泛的硬件上进行训练。

5.5 Megatron-DeepSpeed
基于新的变基,通过注意掩模和位置嵌入的内存优化技术进一步增强了Megatron-style的序列并行。
5.5.1 注意力掩码的内存高效生成
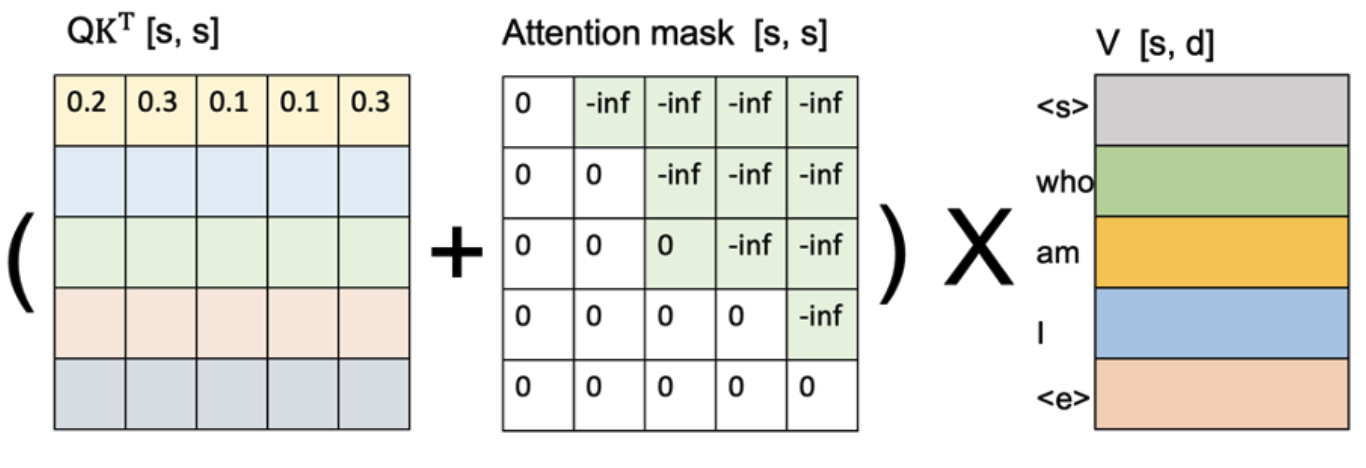 注意力掩码允许模型仅关注前一个token(上图)。首先,注意力掩码之所以是主要内存瓶颈之一,是因为它的大小:[s,
s],其中是序列长度,使其内存复杂度为
注意力掩码允许模型仅关注前一个token(上图)。首先,注意力掩码之所以是主要内存瓶颈之一,是因为它的大小:[s,
s],其中是序列长度,使其内存复杂度为
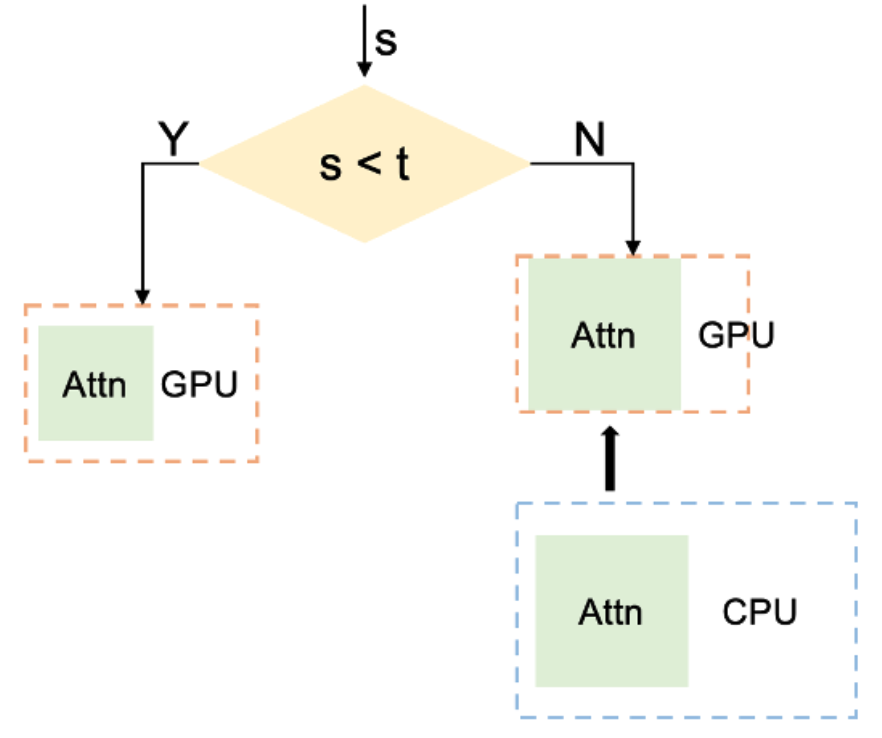
如上图所示,Megatron-DeepSpeed的方法涉及通过大量实验首先确定序列长度阈值。该阈值是根据实现最佳系统性能同时保持合理内存使用率来确定的。如果序列长度低于此阈值,将直接在 GPU 上生成注意掩码。但是,如果序列长度超过此阈值,将遵循以下流程:首先在 CPU 内存中生成它,执行必要的操作,然后将其传输到 GPU 内存。为了防止内存不足错误并确保始终如一的高性能,根据底层 GPU 硬件(例如,对于 A100 40G GPU,阈值为 16K)设定此阈值。
5.5.2 位置嵌入的权重并行化
如上图所示,位置嵌入用于识别每个标记在标记列表中的位置。位置嵌入的权重大小为 [s, d],其中 s 是序列长度,d 是隐藏维度;它与序列长度线性缩放。在原始 Megatron-LM 的设计中,每个 GPU 都保存这些权重的副本。训练这些权重将产生相同大小的梯度和 m 倍的优化器状态(即 m 由 PyTorch 确定)。例如,当 DNA 序列长度超过 100K 时,每个 GPU 的总内存消耗约为 10 GB。
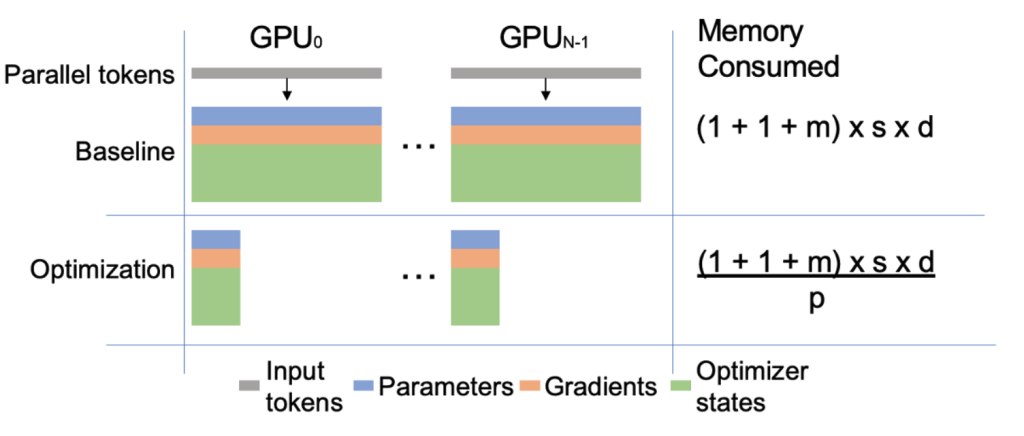
如上图所示。Megatron-DeepSpeed的方法是在启用序列并行时将权重拆分到所有 GPU 上。每个 GPU 只需保存 [s/p, d] 部分权重。因此,将 GPU 内存消耗减少了 p 倍,其中 p 是 GPU 的数量。
5.5.3 新的Megatron-DeepSpeed框架的性能改进
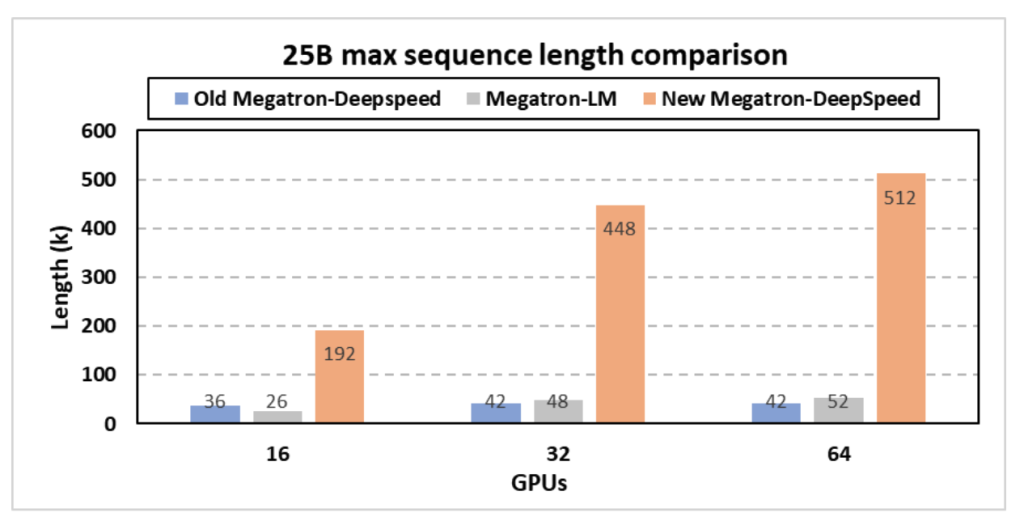
新的 Megatron-DeepSpeed 能够支持更长的序列长度,而不会触发内存不足错误,因为 (1) 当序列长度很大时,Megatron 式序列并行性会分区激活内存,(2) 我们通过内存增强了内存优化-高效的注意力掩码生成和位置嵌入并行化,以及(3)FlashAttention V1和V2支持,这将注意力图计算的内存消耗从相对于序列长度的二次复杂度降低到线性复杂度。新的 Megatron-DeepSpeed 可以实现更高的 TFLPOS,因为它包含 NVIDIA 的新融合内核,并使用我们的内存优化支持更大的批量大小,而不会触发内存不足错误。
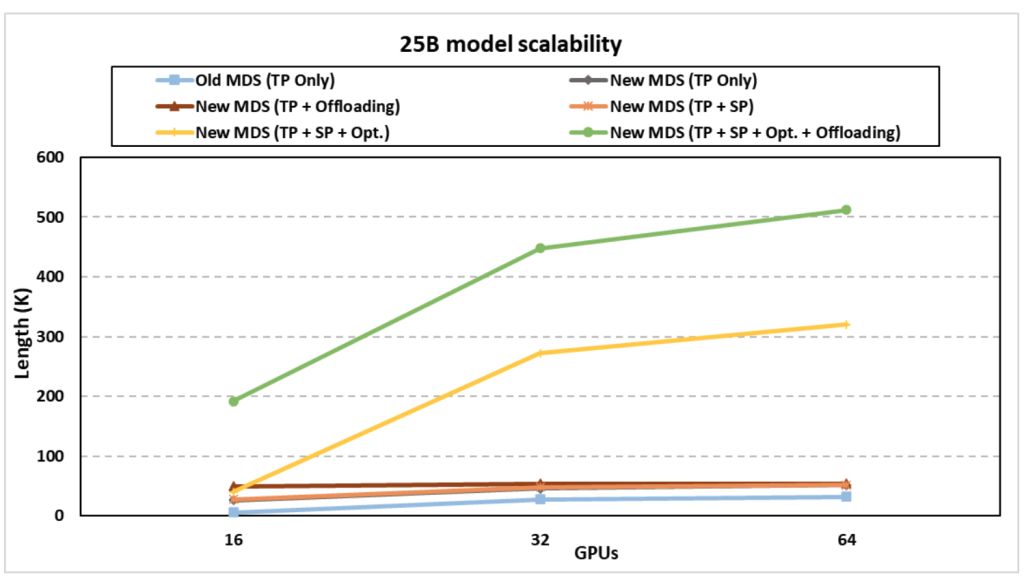
通过新的 Megatron-DeepSpeed 框架,科学家现在可以通过新添加的注意力掩模和位置嵌入、张量并行、流水线并行、序列并行、ZeRO 方面的内存优化技术的协同组合来训练具有更长序列的大型科学模型,例如具有更长序列的 GenSLM -风格的数据并行性和模型状态卸载。新框架使 GenSLM 的25B 模型的最长序列长度分别比之前的 Megatron-DeepSpeed 提高了12 倍。在支持的序列长度方面,该新框架的25B型号的性能也显着优于 NVIDIA 的 Megatron-LM,高达9.8 倍。例如,GenSLM 的 25B 模型现在可以使用 512K 核苷酸序列进行训练,而 Argonne 团队最初在 64 个 GPU 上使用 42K 序列长度。这极大地提高了模型质量和科学发现范围,而没有额外的准确性损失。
六、资源
DeepSpeed:https://github.com/microsoft/DeepSpeed Megatron-DeepSpeed:https://github.com/microsoft/Megatron-DeepSpeed BigScience Megatron-DeepSpeed:https://github.com/bigscience-workshop/Megatron-DeepSpeed DeepSpeed Blog:https://www.deepspeed.ai/posts/ DeepSpeed tutorials:https://www.deepspeed.ai/tutorials/ DeepSpeed4Science:https://deepspeed4science.ai/
参考
- DeepSpeed’s Bag of Tricks for Speed & Scale
- DeepSpeed介绍
- DeepSpeed框架:1-大纲和资料梳理
- Zero系列三部曲:Zero、Zero-Offload、Zero-Infinity
- ZeRO: Zero Redundancy Optimizer,一篇就够了。
- DeepSpeed-GitHub
- ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters
- ZeRO-Infinity and DeepSpeed: Unlocking unprecedented model scale for deep learning training
- DeepSpeed ZeRO++: A leap in speed for LLM and chat model training with 4X less communication
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- ZeRO-Offload: Democratizing Billion-Scale Model Training
- ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
- ZeRO++: Extremely Efficient Collective Communication for Giant Model Training
- DeepSpeed ZeRO++:降低4倍网络通信,显著提高大模型及类ChatGPT模型训练效率
- 从啥也不会到DeepSpeed————一篇大模型分布式训练的学习过程总结
- 论文阅读: ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
- DeepSpeed之ZeRO系列:将显存优化进行到底
- huggingface DeepSpeed
- 大模型并行训练指南:通俗理解Megatron-DeepSpeed之模型并行与数据并行
- 训练一个130亿参数的模型要用几个GPU?微软:一个就够
- Zero Redundancy Optimizer
- DeepSpeed Sparse Attention
- DeepSpeed Under the Hood: Revolutionising AI with Large-Scale Model Training
- Demystifying Sparse Attention: A Comprehensive Guide from Scratch
- 为节约而生:从标准Attention到稀疏Attention
- Generating Long Sequences with Sparse Transformers
- 神经网络稀疏综述
- 机器学习梯度量化方法简介
- 1-Bit Stochastic Gradient Descent and its Application to Data-Parallel Distributed Training of Speech DNNs
- 論文筆記 1-bit Adam: Communication Efficient Large-Scale Training with Adam’s Convergence Speed
- 1-bit Adam: Communication Efficient Large-Scale Training with Adam’s Convergence Speed
- DeepSpeed with 1-bit Adam: 5x less communication and 3.4x faster training
- Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam
- Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam
- 一种使用1-bit通信的Adam优化器
- 1-bit LAMB: Communication Efficient Large-Scale Large-Batch Training with LAMB’s Convergence Speed
- DeepSpeed-FastGen:通过 MII 和 DeepSpeed-Inference 实现 LLM 高吞吐量文本生成
- DeepSpeed: Accelerating large-scale model inference and training via system optimizations and compression
- BinaryConnect: Training Deep Neural Networks with binary weights during propagations
- TernaryBERT: Distillation-aware Ultra-low Bit BERT
- TERNARY WEIGHT NETWORKS
- BinaryBERT: Pushing the Limit of BERT Quantization
- Extreme Compression for Pre-trained Transformers Made Simple and Efficient
- TinyBERT: Distilling BERT for Natural Language Understanding
- Greedy-layer Pruning: Speeding up Transformer Models for Natural Language Processing
- DeepSpeed Model Compression Library
- Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
- Compression of Generative Pre-trained Language Models via Quantization
- ACL 2022 杰出论文:华为&港大提出SOTA预训练语言模型量化压缩方法
- ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
- Using Tensor Cores in CUDA Fortran
- Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
- Efficient Kernel Fusion Techniques for Massive Video Data Analysis on GPGPUs
- CUTLASS: Fast Linear Algebra in CUDA C++
- DeepSpeed Compression: A composable library for extreme compression and zero-cost quantization
- ONNX runtime
- DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
- DS4Sci_EvoformerAttention: eliminating memory explosion problems for scaling Evoformer-centric structural biology models
- DeepSpeed4Science Overview and Tutorial
- DeepSpeed4Science:利用先进的AI系统优化技术实现科学发现
- DeepSpeed4Science Enables Very-Long Sequence Support via both Systematic and Algorithmic Approaches for Genome-scale Foundation Models
- DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
- Distributional Graphormer: Toward equilibrium distribution prediction for molecular systems
- Introducing ClimaX: The first foundation model for weather and climate
- Announcing the DeepSpeed4Science Initiative: Enabling large-scale scientific discovery through sophisticated AI system technologies
- 详解PyTorch FSDP数据并行(Fully Sharded Data Parallel)