Megatron-LM
一、 通讯原语操作
NCCL 英伟达集合通信库,是一个专用于多个 GPU 乃至多个节点间通信的实现。它专为英伟达的计算卡和网络优化,能带来更低的延迟和更高的带宽。
Broadcast
Broadcast代表广播行为,执行Broadcast时,数据从主节点0广播至其他各个指定的节点(0~3)
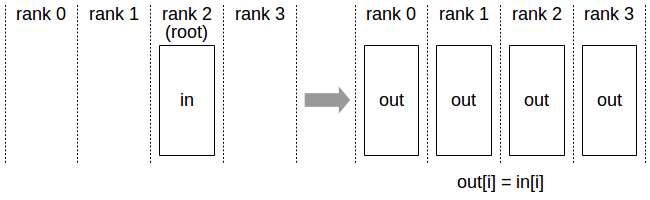
Scatter
Scatter与Broadcast非常相似,都是一对多的通信方式,不同的是Broadcast的0号节点将相同的信息发送给所有的节点,而Scatter则是将数据的不同部分,按需发送给所有的节点。
Reduce
Reduce称为规约运算,是一系列简单运算操作的统称,细分可以包括:SUM、MIN、MAX、PROD、LOR等类型的规约操作。Reduce意为减少/精简,因为其操作在每个节点上获取一个输入元素数组,通过执行操作后,将得到精简的更少的元素。
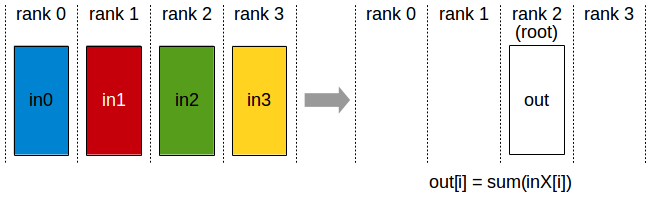
AllReduce
Reduce是一系列简单运算操作的统称,All Reduce则是在所有的节点上都应用同样的Reduce操作
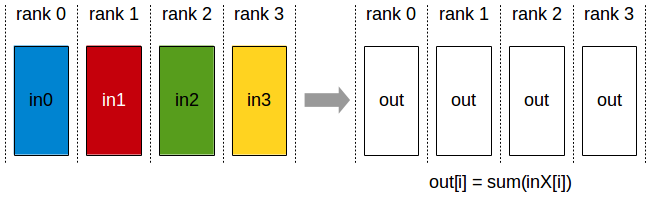
Gather
Gather操作将多个sender上的数据收集到单个节点上,Gather可以理解为反向的Scatter。
AllGather
收集所有数据到所有节点上。从最基础的角度来看,All Gather相当于一个Gather操作之后跟着一个Broadcast操作。
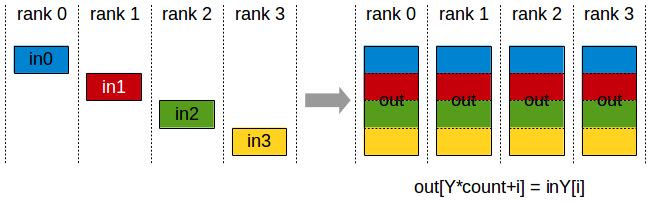
ReduceScatter
Reduce Scatter操作会将个节点的输入先进行求和,然后在第0维度按卡数切分,将数据分发到对应的卡上。
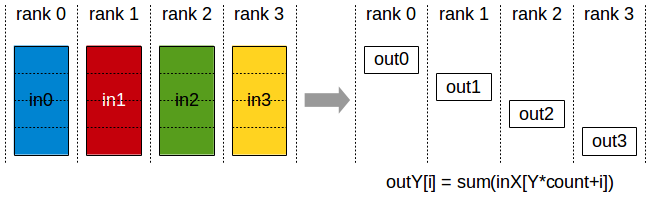
AllReduce操作,目标是高效得将不同机器中的数据整合(reduce)之后再把结果分发给各个机器。在深度学习应用中,数据往往是一个向量或者矩阵,通常用的整合则有Sum、Max、Min等。AllReduce具体实现的方法有很多种,最单纯的实现方式就是每个worker将自己的数据发给其他的所有worker,然而这种方式存在大量的浪费。一个略优的实现是利用主从式架构,将一个worker设为master,其余所有worker把数据发送给master之后,由master进行整合元算,完成之后再分发给其余worker。不过这种实现master往往会成为整个网络的瓶颈。AllReduce还有很多种不同的实现,多数实现都是基于某一些对数据或者运算环境的假设,来优化网络带宽的占用或者延迟。如Ring AllReduce:
第一阶段,将N个worker分布在一个环上,并且把每个worker的数据分成N份。
第二阶段,第k个worker会把第k份数据发给下一个worker,同时从前一个worker收到第k-1份数据。
第三阶段,worker会把收到的第k-1份数据和自己的第k-1份数据整合,再将整合的数据发送给下一个worker
此循环N次之后,每一个worker都会包含最终整合结果的一份。
假设每个worker的数据是一个长度为S的向量,那么个Ring AllReduce里,每个worker发送的数据量是O(S),和worker的数量N无关。这样就避免了主从架构中master需要处理O(S*N)的数据量而成为网络瓶颈的问题。
二、Megatron-LM介绍
Megatron-LM 能够大规模训练大型 Transformer 语言模型。它为基于预训练 Transformer 的语言模型提供高效的张量、流水线和基于序列的模型并行性。
2. 1 数据并行
数据并行模式会在每个worker之上复制一份模型,这样每个worker都有一个完整模型的副本。输入数据集是分片的,一个训练的小批量数据将在多个worker之间分割;worker定期汇总它们的梯度,以确保所有worker看到一个一致的权重版本。对于无法放进单个worker的大型模型,人们可以在模型之中较小的分片上使用数据并行。
数据并行扩展通常效果很好,但有两个限制:
- 超过某一个点之后,每个GPU的batch size变得太小,这降低了GPU的利用率,增加了通信成本;
- 可使用的最大设备数就是batch size,限制了可用于训练的加速器数量。
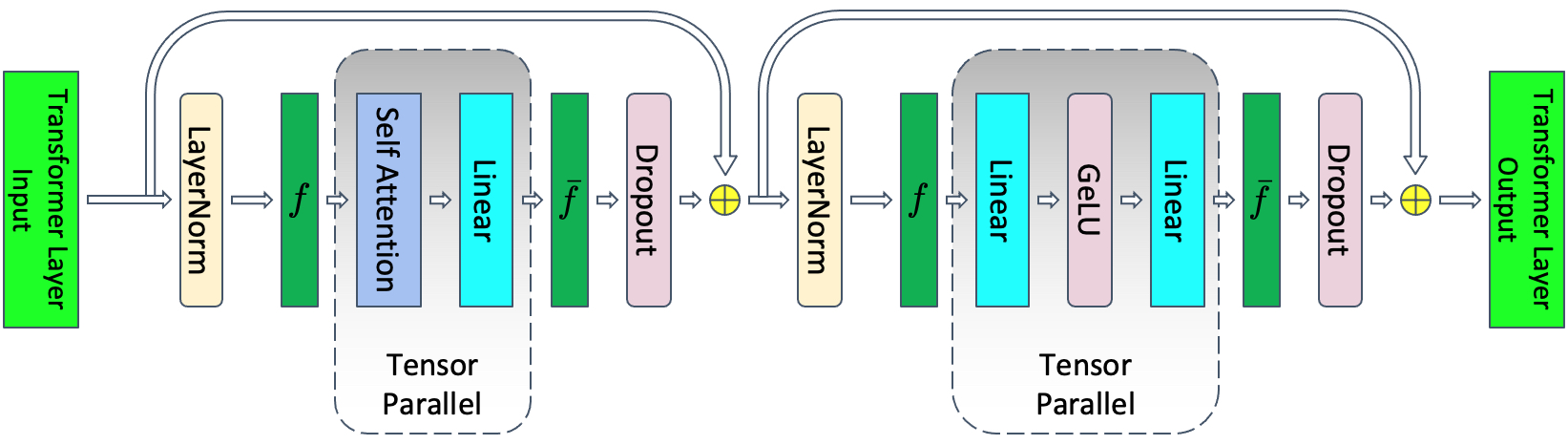
2.2 张量并行(Tensor Parallelism,TP)
在张量并行 (TP) 中,每个 GPU 仅处理张量的一部分,并且仅当某些算子需要完整的张量时才触发聚合操作。( Megatron-LM 论文:Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism)
Transformer 类模型的主要模块为: 一个全连接层
nn.Linear,后面跟一个非线性激活层 GeLU。可以将其点积部分写为
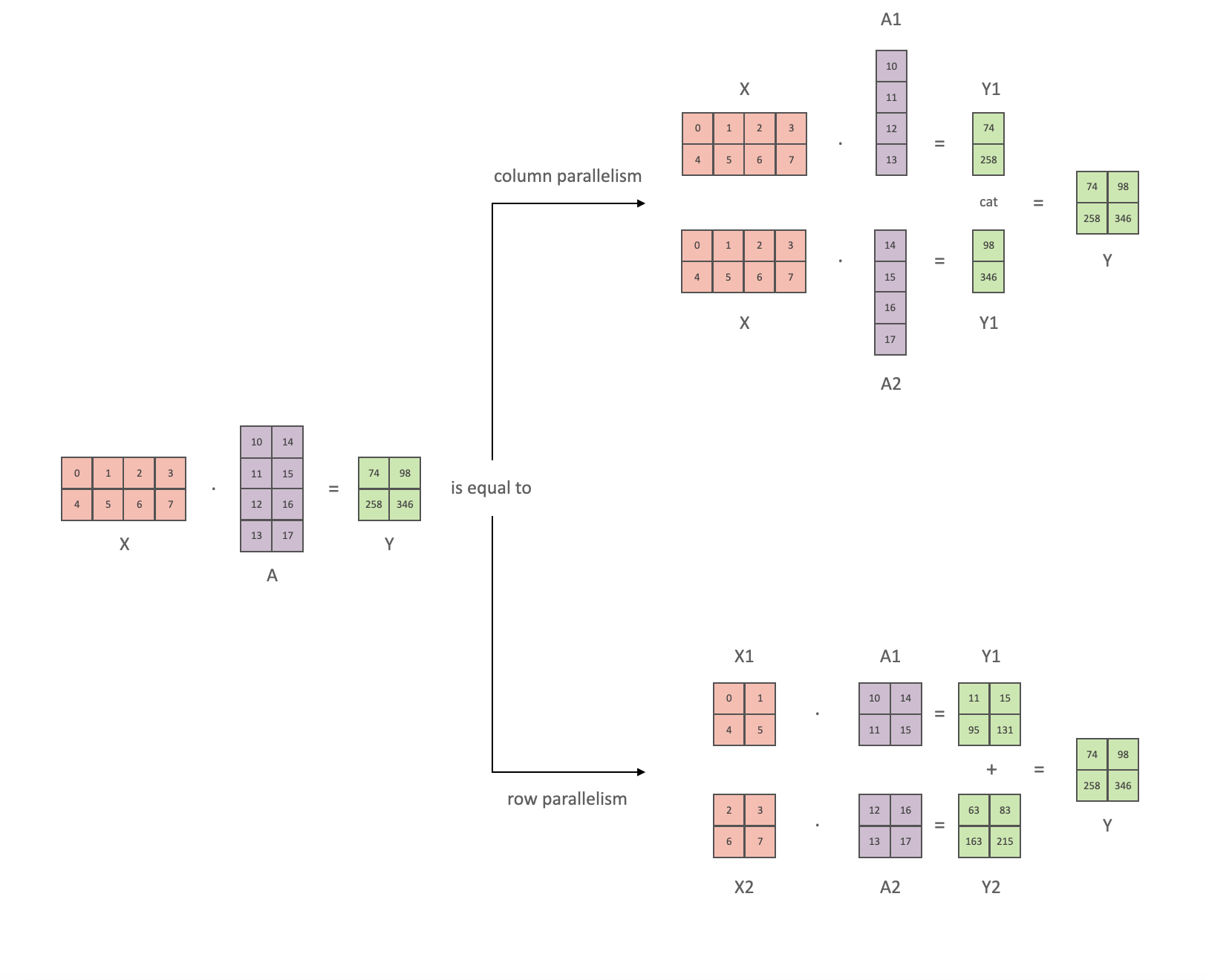
如果将权重矩阵
因为 拆列 - 拆行 序列之后同步 GPU。Megatron-LM
论文作者为此提供了一个不错的图示:
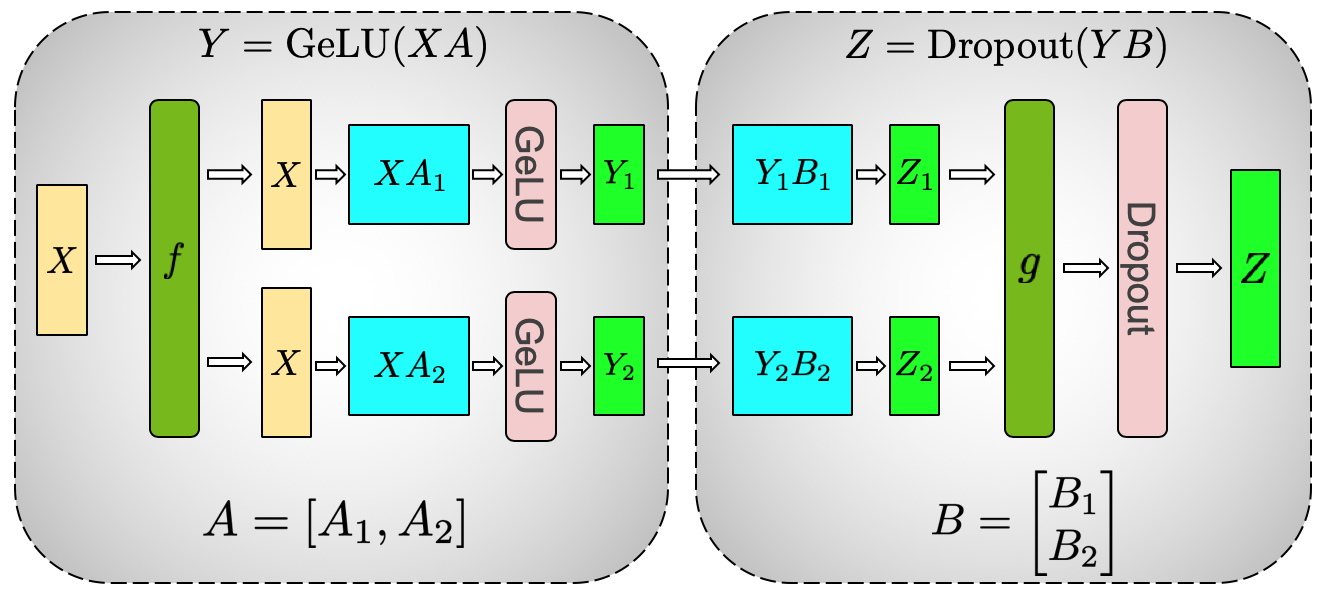
all-reduce,后向传递中的恒等运算符。
并行化多头注意力层甚至更简单,因为它们本来就是并行的,因为有多个独立的头!
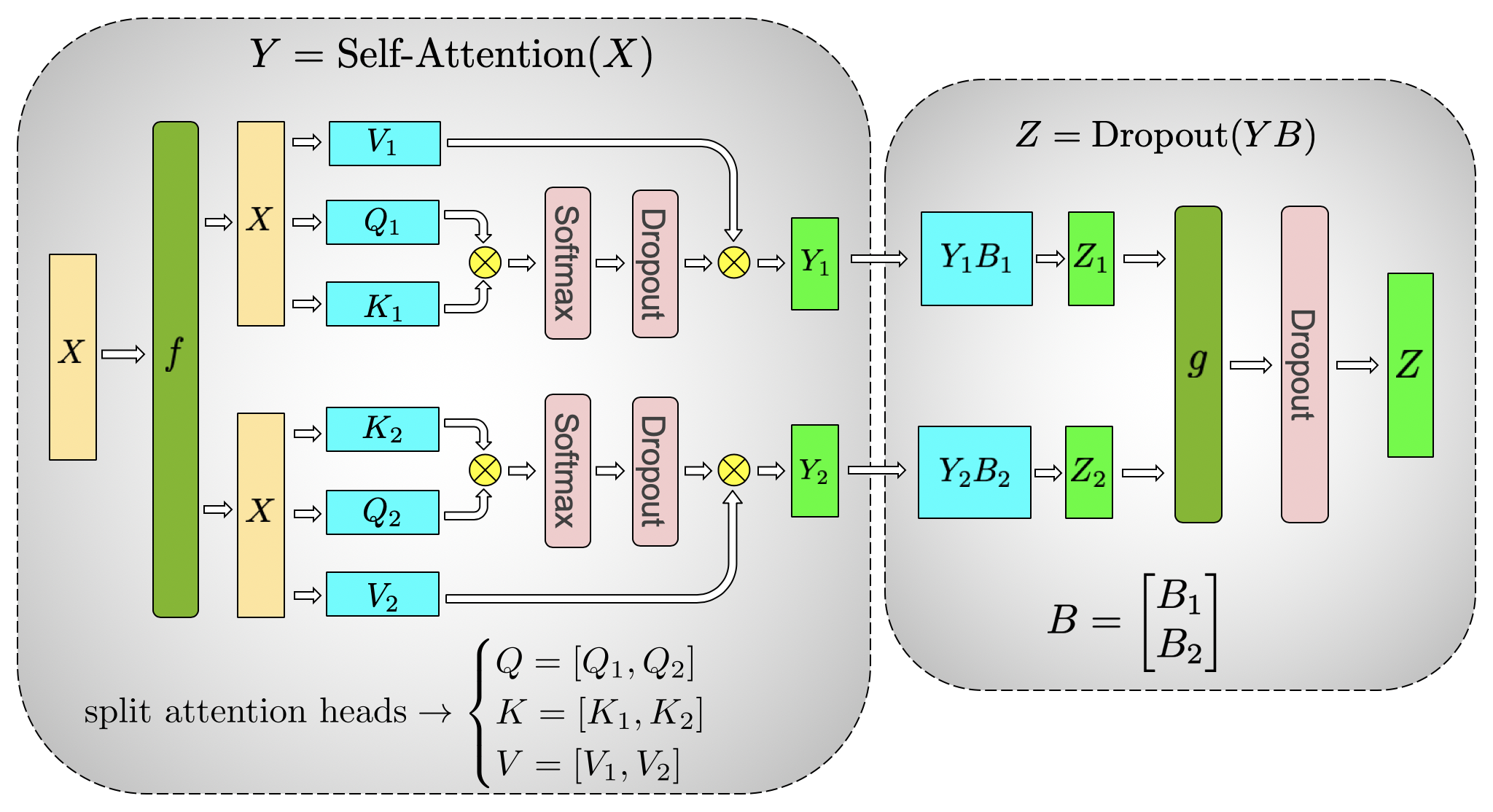
对于自注意力块,我们利用多头注意力操作中固有的并行性,对与
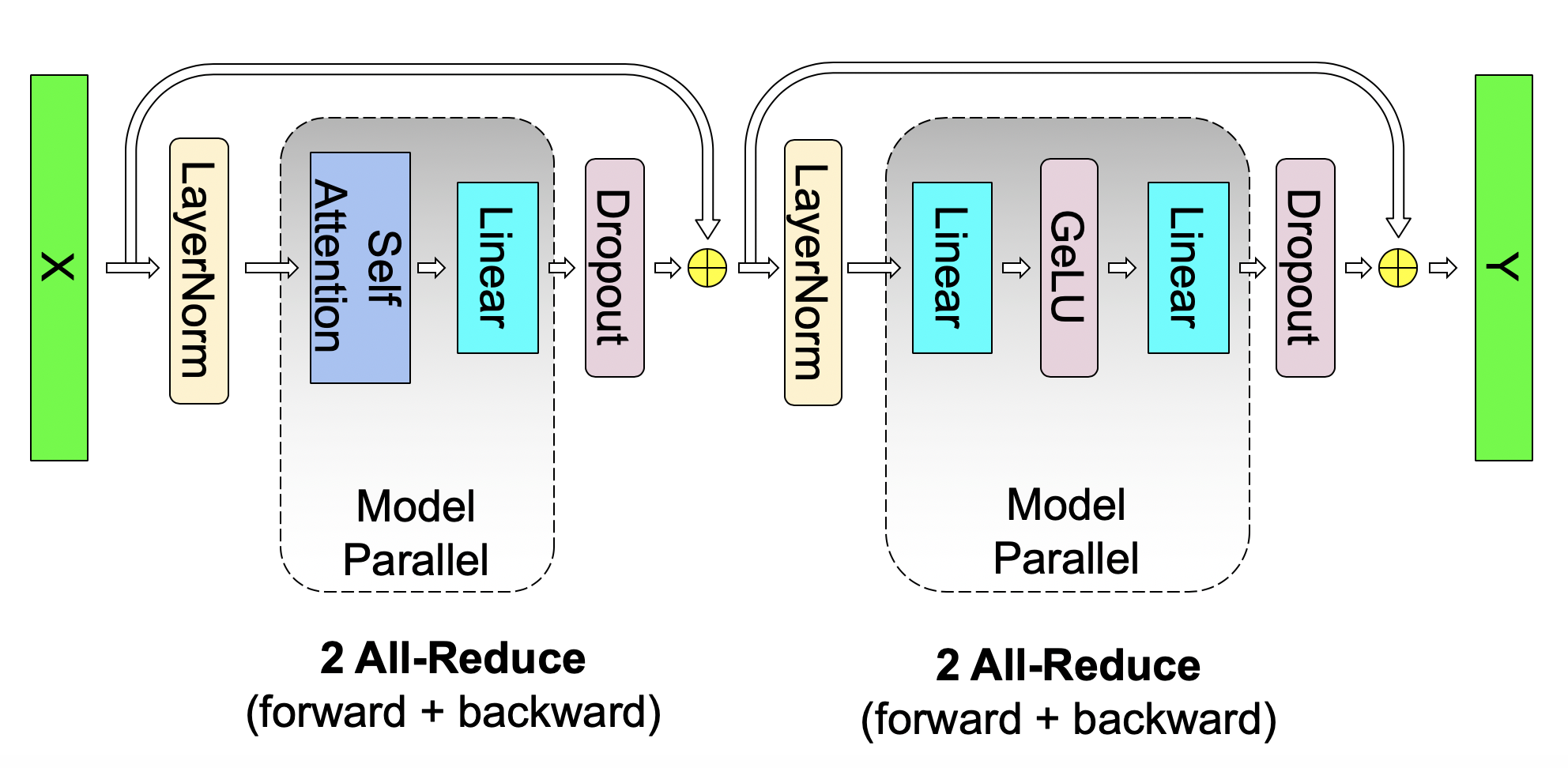
需要特别考虑的是: 由于前向和后向传播中每层都有两个
all reduce,因此 TP
需要设备间有非常快速的互联。因此,除非你有一个非常快的网络,否则不建议跨多个节点进行
TP。实际上,如果节点有 4 个 GPU,则最高 TP 度设为 4 比较好。如果需要 TP
度为 8,则需要使用至少有 8 个 GPU 的节点。
2.3 流水线并行(Pipeline Parallelism,PP)
Naive PP是将模型各层分组分布在多个 GPU 上,并简单地将数据从 GPU
移动到 GPU,就好像它是一个大型复合 GPU 一样。该机制相对简单 -
将所需层用.to()
方法绑到相应设备,现在只要数据进出这些层,这些层就会将数据切换到与该层相同的设备,其余部分保持不变。
这其实就是垂直模型并行,因为在画大多数模型的拓扑图时,其实是垂直切分模型各层的。例如,如果下图显示一个 8 层模型:
1 | |
将它垂直切成 2 部分,将层 0-3 放置在 GPU0 上,将层 4-7 放置在 GPU1 上。现在,当数据从第 0 层传到第 1 层、第 1 层传到第 2 层以及第 2 层传到第 3 层时,这就跟单 GPU 上的普通前向传播一样。但是当数据需要从第 3 层传到第 4 层时,它需要从 GPU0 传输到 GPU1,这会引入通信开销。如果参与的 GPU 位于同一计算节点 (例如同一台物理机器) 上,则传输非常快,但如果 GPU 位于不同的计算节点 (例如多台机器) 上,通信开销可能会大得多。然后第 4 到 5 到 6 到 7 层又像普通模型一样,当第 7 层完成时,通常需要将数据发送回标签所在的第 0 层 (或者将标签发送到最后一层)。现在可以计算损失,然后使用优化器来进行更新参数了。
问题:
- 该方案在任意给定时刻除了一个 GPU 之外的其他所有 GPU 都是空闲的。因此,如果使用 4 个 GPU,则几乎等同于将单个 GPU 的内存量翻两番,而其他资源 (如计算) 相当于没用上。另外还需要加上在设备之间复制数据的开销。所以 4 张 使用Naive PP的 6GB 卡将能够容纳与 1 张 24GB 卡相同大小的模型,而后者训练得更快,因为它没有数据传输开销。但是,比如说,如果你有 40GB 卡,但需要跑 45GB 模型,你可以使用 4x 40GB 卡 (也就刚刚够用,因为还有梯度和优化器状态需要显存)。
- 共享嵌入可能需要在 GPU 之间来回复制。使用的流水线并行 (PP) 与上述Naive PP 几乎相同,但它解决了 GPU 闲置问题,方法是将传入的 batch 分块为 micros batch 并人工创建流水线,从而允许不同的 GPU 同时参与计算过程。
下图来自于GPipe
论文,图上把网络分成4块,每一块放在一个GPU上,不同的颜色表示不同的GPU,于是就有了
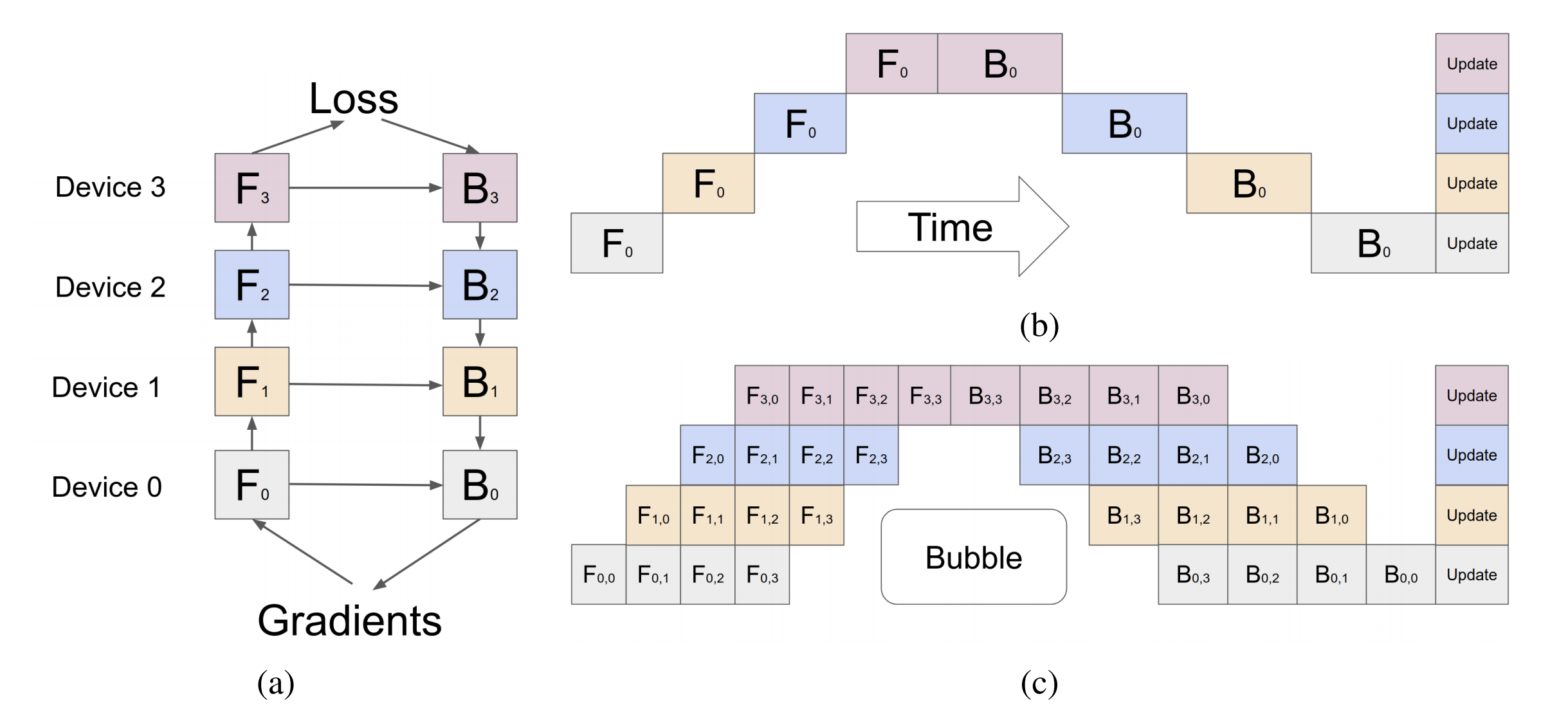
- 其b部分表示朴素 PP 方案:为一般的模型并行的运算模式,在每个时间点只有一台设备在处理计算逻辑,完成计算后将结果发送给下一台设备
- c部分是 PP 方法 PP
引入了一个新的超参数来调整,称为
块(chunks)。它定义了通过同一管级按顺序发送多少数据块。例如,在图(c)的部分,可以看到 chunks = 4。GPU 0 在 chunk 0、1、2 和 3 (F0,0、F0,1、F0,2、F0,3) 上执行相同的前向路径,然后等待,等其他 GPU 完成工作后,GPU 0 会再次开始工作,为块 3、2、1 和 0 (B0,3、B0,2、B0,1、B0,0) 执行后向路径 请注意,从概念上讲,这与梯度累积 (gradient accumulation steps,GAS) 的意思相同。PyTorch 叫它 块,而 DeepSpeed 叫它 GAS。
因为块,PP 引入了 micro-batches (MBS) 的概念。DP 将全局 batch size
拆分为小 batch size,因此如果 DP 度为 4,则全局 batch size 1024 将拆分为
4 个小 batch size,每个小 batch size 为 256 (1024/4)。而如果 块 (或 GAS)
的数量为 32,最终得到的 micro batch size 为 8
(256/32)。每个管级一次处理一个 micro batch 计算 DP + PP
设置的全局批量大小的公式为:
这种调度机制被称为 全前全后。
GPipe实验发现,通过将mini-batch进一步划分成更小的micro-batch,同时利用pipipline方案,每次处理一个micro-batch的数据,得到结果后,将该micro-batch的结果发送给下游设备,同时开始处理后一个 micro-batch的数据,通过这套方案减小设备中的Bubble(设备空闲的时间称为 Bubble)
使用 chunks=1 你最终得到的是Navie
PP,这是非常低效的。而使用非常大的块数,你最终会得到很小的微批量大小,这很可能也不是很有效。因此,必须通过实验来找到能最有效地利用
GPU 的块数。
该图显示存在无法并行化的 “死” 时间气泡,因为最后一个 forward
阶段必须等待 backward
完成流水。那么,找到最佳的块数,从而使所有参与的 GPU
达到高的并发利用率,这一问题其实就转化为最小化气泡数了。
Megatron-LM 和 DeepSpeed 都有自己的 PP 协议实现。
其他一些可选方案:
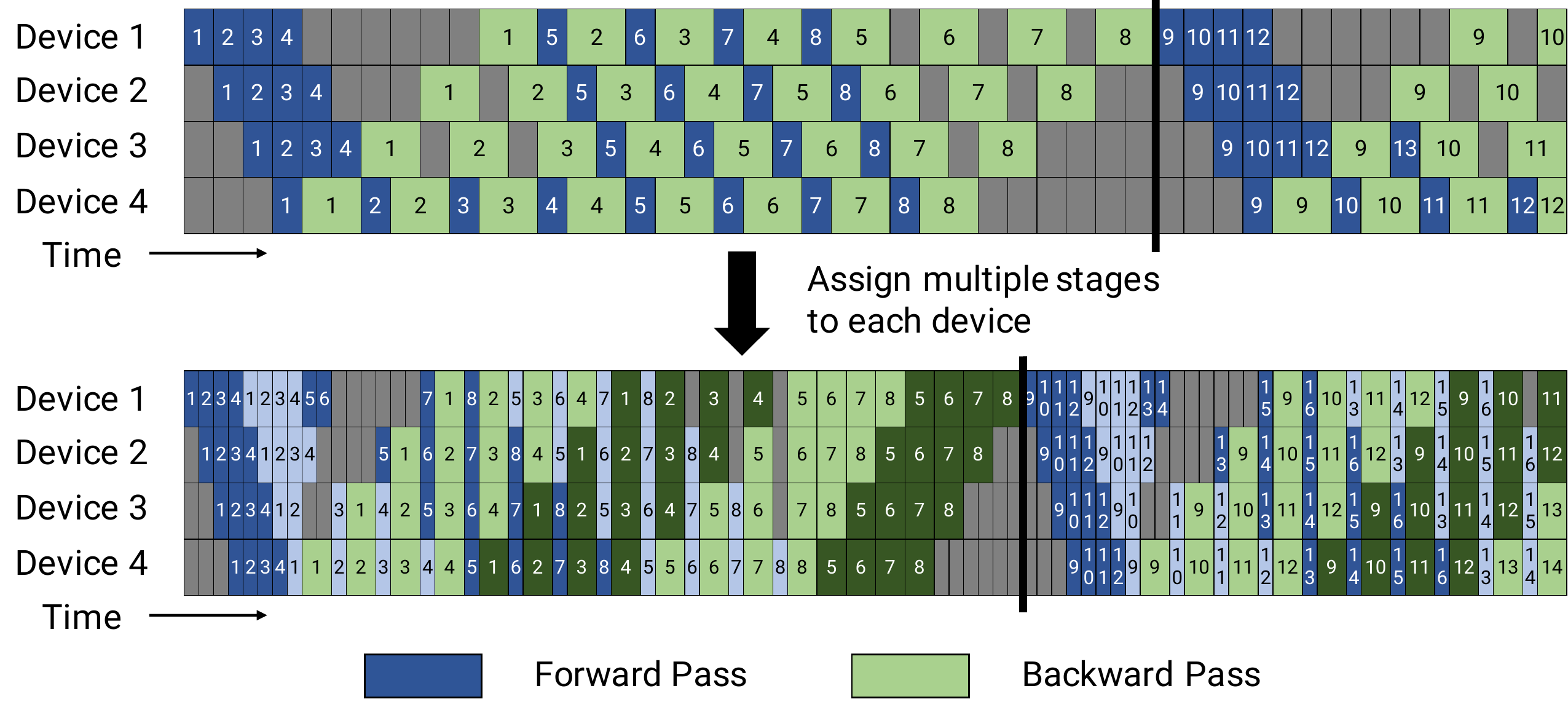
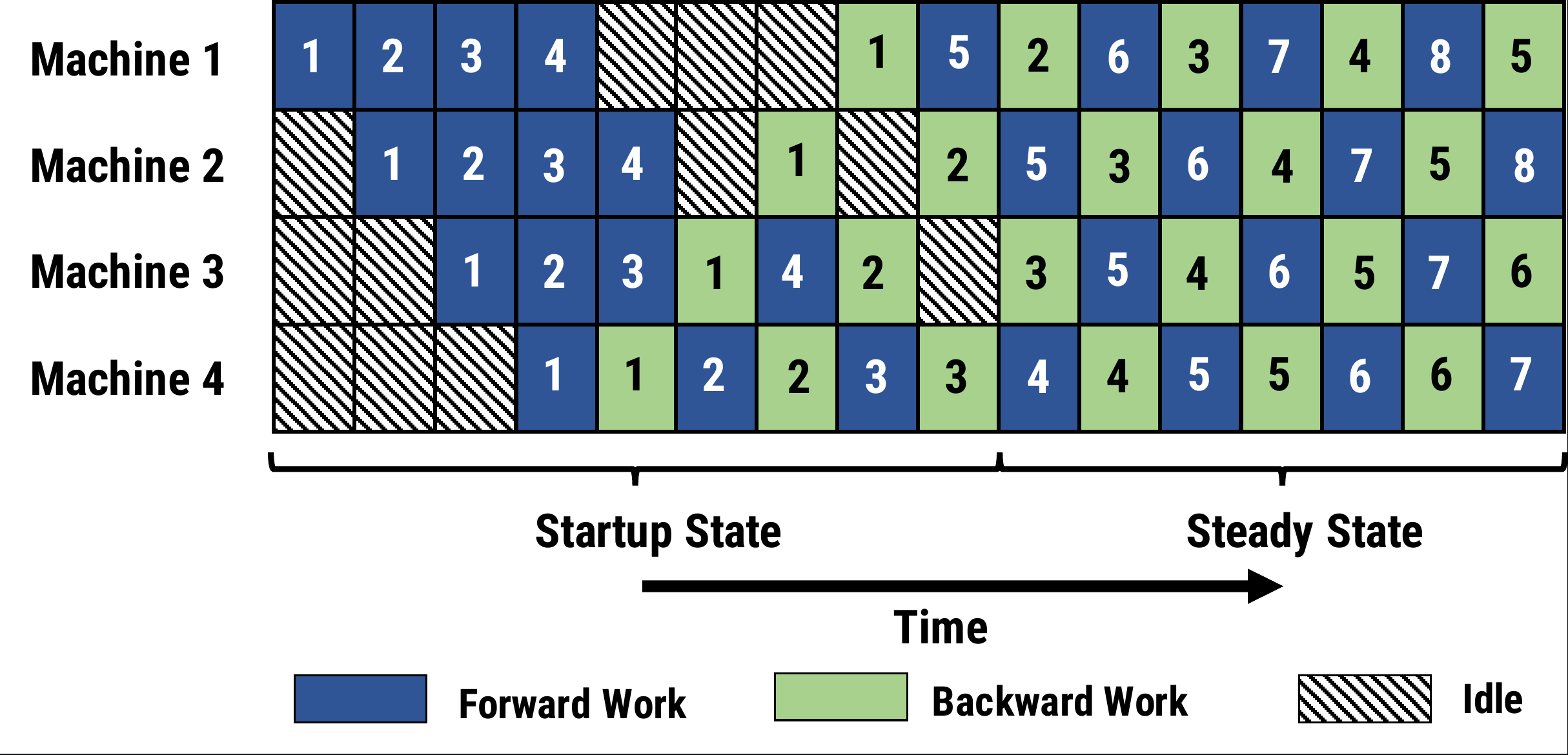
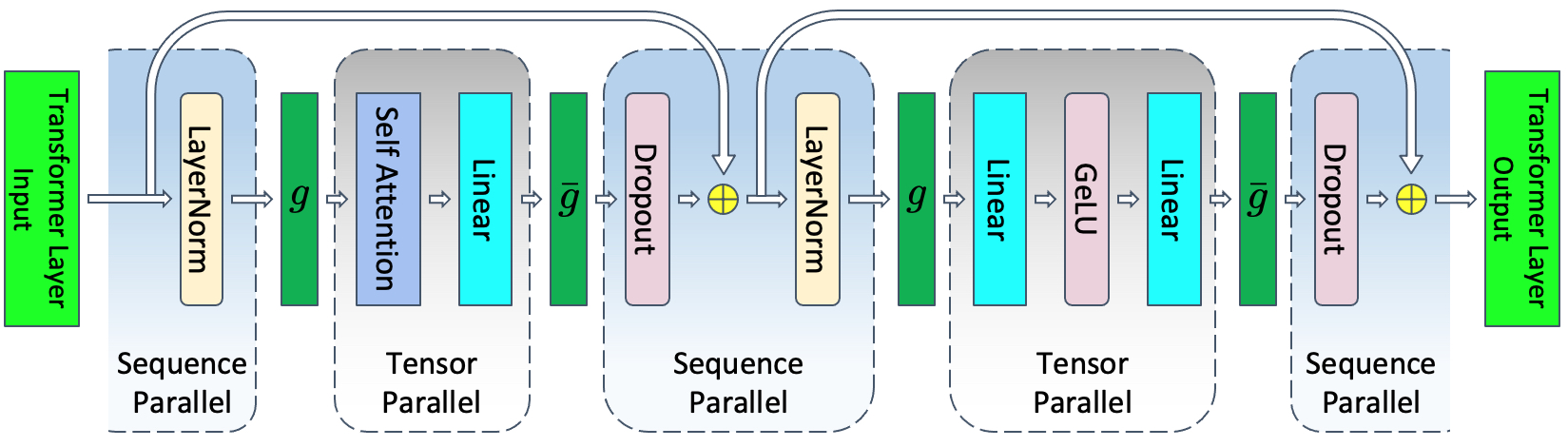
2.4 序列并行 (Sequence Parallelism,SP)
张量并行对训练期间花费最多时间的 Transformer 层部分进行并行化,因此计算效率很高。然而,它保留了层范数以及注意力和 MLP 块之后的dropout,因此,它们在张量并行组中复制。这些元素不需要大量计算,但需要大量激活内存。
在transformer层的非张量并行区域中,操作沿序列维度是独立的。这一特性使得能够沿着序列维度
为了避免这些额外的通信,将这些操作与
在非并行形式中,transformer中的MLP 块所遵循的层范数可以表述为:
其中
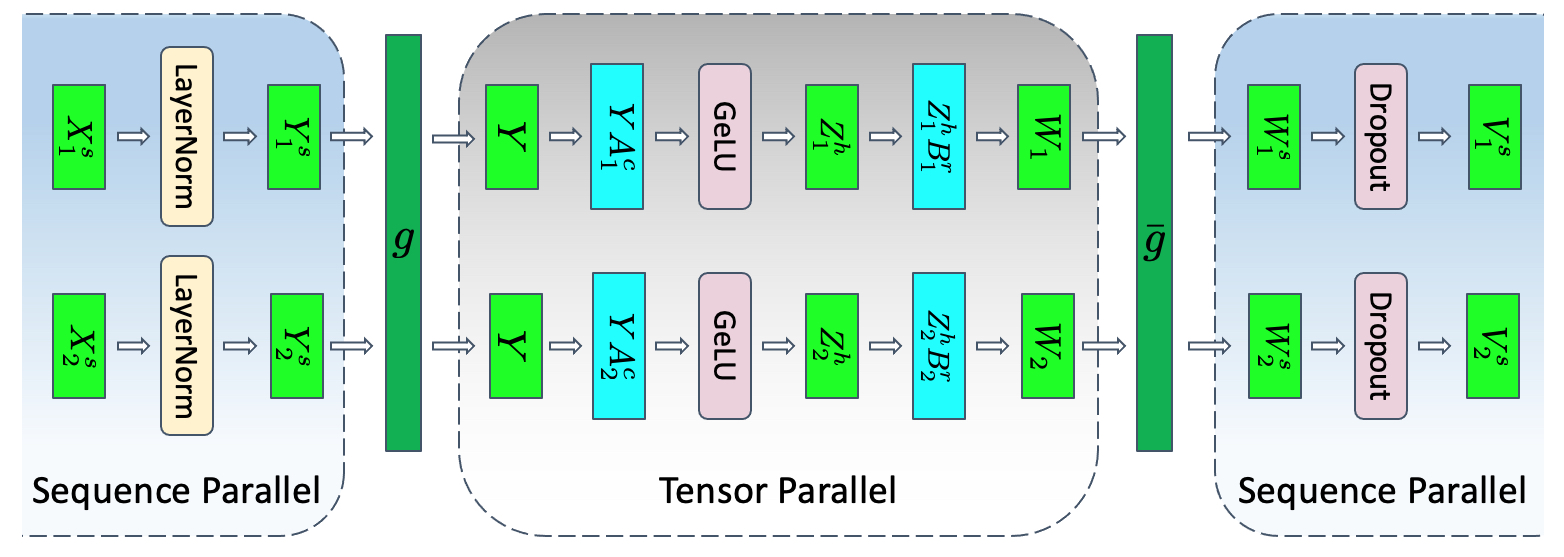
层范数的输入沿着序列维度
如果对反向传递进行类似的分解,会发现
张量并行需要在一次正向和反向传递中进行四次all-reduces,而张量与序列并行需要在一次正向和反向传递中进行四次all-gather和四次reduce-scatter。乍一看,与张量并行相比,具有序列并行的张量似乎需要更多的通信。但是,Ringall-reduces由两个步骤组成:reduce-scatter,然后是all-gather。因此,张量并行和张量与序列并行使用的通信带宽相同。因此,序列并行不会引入任何通信开销。
从公式
2.5 Context Parallelism (CP)
megatron中的context并行(简称CP)与sequence并行(简称SP)不同点在于,SP只针对Layernorm和Dropout输出的activation在sequence维度上进行切分,CP则是对所有的input输入和所有的输出activation在sequence维度上进行切分,可以看成是增强版的SP。除了Attention模块以外,其他的模块(Layernorm、Dropout)由于没有多token的处理,在CP并行时都不用任何修改。
为什么Attention模块是个例外? 因为Attention计算过程中每个token的Q(query)要跟同一个sequence中其他token的K(key)和V(value)一起进行计算,存在计算上的依赖,所以通过CP并行后,在计算Attention前要通过allgather通信拿到所有token的KV向量,在反向计算时对应需要通过reduce_scatter分发gradient梯度。
为了减少显存占用,在前向时每个gpu只用保存一部分KV块,反向时通过allgather通信拿到所有的KV数据。KV的通信发生在相邻TP通信组相同位置的rank之间。allgather和reduce_scatter在ring拓扑架构实现时,底层会通过send和recv来进行实现。
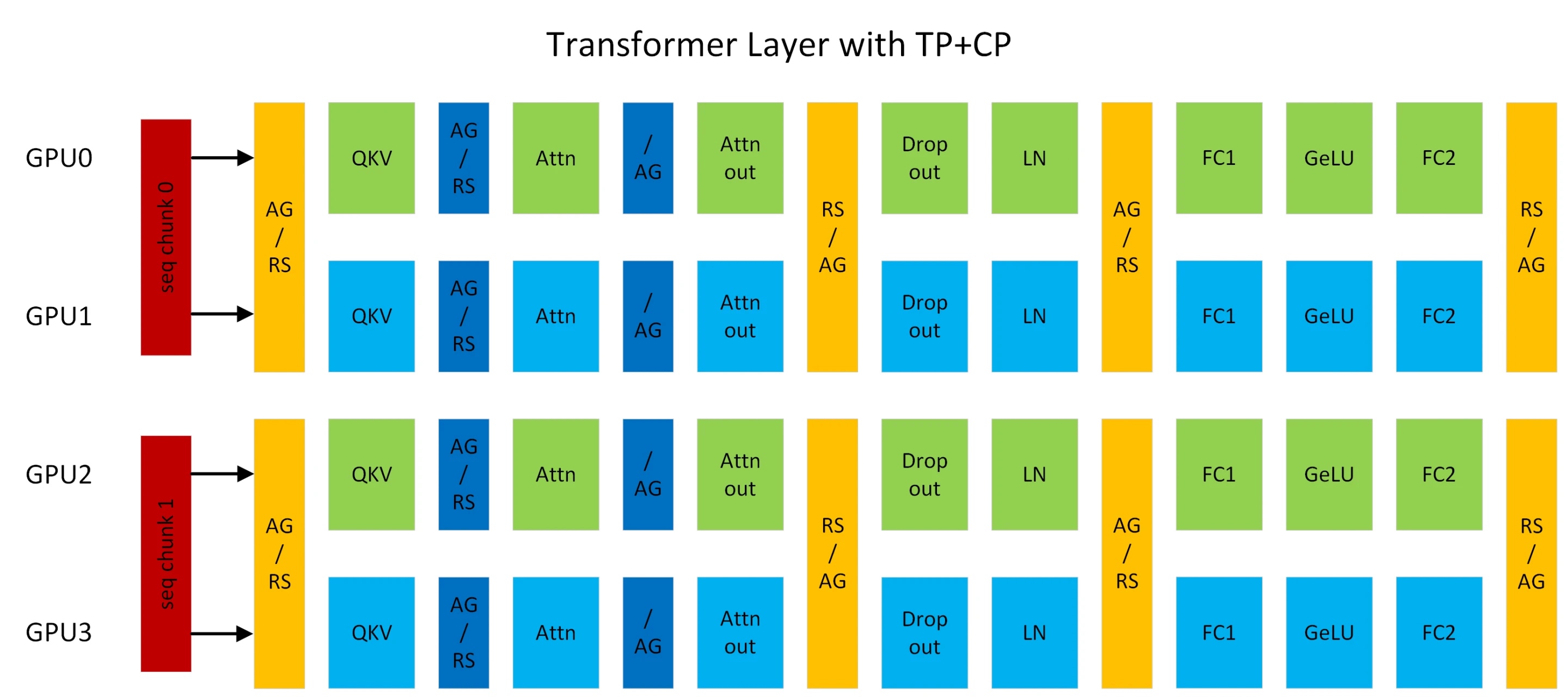
以上图TP2-CP2的transformer网络为例,在Attention前的是CP的通信算子,其他都是TP的通信算子。AG表示allgather, RS表示reduce_scatter, AG/RS表示前向allgather反向reduce_scatter, RS/AG表示前向reduce_scatter反向allgather。
这里TP2对应为[GPU0, GPU1], [GPU2, GPU3], CP2对应为TP组相同位置的rank号,也就是[GPU0, GPU2], [GPU1, GPU3]。CP并行与Ring Attention类似,但是提供了新的OSS与FlashAttention版本,也去除了low-triangle causal masking的冗余计算。
LLM经常由于sequence长度过长导致显存OOM,这时之前的一种方式是通过重计算的方式保存中间的activation产出,全量重计算的劣势会带来30%的计算代价;另外一种方式是扩大TP(tensor parallel)的大小,扩大TP的劣势在于会对tensor切的更小,从而导致linear fc的计算时间变少,从而与通信很难进行计算的掩盖。
通过CP可以更好解决OOM的问题,每个GPU只用处理一部分的sequence,
同时减少CP倍的通信和计算,但保持TP不变,同时activation也会减少CP倍。
2.6 可选Activation重计算(Selective Activation Recomputation)
| 注意力头数量 | PP大小 | ||
| 微批量大小 | 序列长度 | ||
| 隐层维度 | TP大小 | ||
| transformer层数 | 词汇量 |
Attention
block:包括自注意力,随后是线性投影和注意力dropout。线性投影以大小
、 和 矩阵相乘:只需要存储大小为 的共享输入。 矩阵相乘:它需要存储 和 ,总大小为 。 - Softmax:反向传播需要大小为
的 Softmax 输出。 - Softmax dropout:只需要大小为
的掩码。 :需要存储 dropout 输出 ( ) 和 ( ),因此需要 的存储空间。
注意力块需要
MLP: 两个线性层以大小
Layer norm: 每个层范数以大小
将注意力、MLP 和层规范所需的内存相加,存储 Transformer 网络单层激活所需的内存为:
TP
张量并行不仅并行化了注意力和 MLP
块内的模型参数和优化器状态,而且还并行化了这些块内的激活。请注意,这些块的输入激活(例如,
SP+TP
使用序列并行和张量并行,存储每个 Transformer 层激活所需的内存从公式
PP
流水线并行性只是将 Transformer 的
1F1B
流水线调度。流水线气泡最小化的调度将最大的内存压力放在流水线的第一阶段(流水线的第一阶段是指第一组
对于其他流水线调度,所需的总内存会略有不同。例如,交错调度需要存储
Selective Activation Recomputation
与存储所有激活(公式
建议不checkpoint并重新计算整个 Transformer
层,而是仅checkpoint并重新计算每个 Transformer
层中占用大量内存但重新计算计算成本不高的部分,或选择性激活重新计算。为此,方程
| Configuration | Activations Memory Per Transformer Layer |
|---|---|
| no parallelism | |
| tensor parallel (baseline) | |
| tensor + sequence parallel | |
| tensor parallel + selective activation recomputation | |
| tensor parallel + sequence parallel + selective activation recomputation | |
| full activation recomputation |
表:针对不同技术的每个transformer层的激活内存(以字节为单位)
2.7 DataSets
Megatron-LM 的另一个重要特性是高效的数据加载器。在首次训练启动前,每个数据集中的每个样本都被分成固定序列长度 (BLOOM 为 2048) 的样本,并创建索引以对每个样本进行编号。基于训练超参,我们会确定每个数据集所需要参与的 epoch 数,并基于此创建一个有序的样本索引列表,然后打乱它。举个例子,如果一个数据集中有 10 个样本并应参与 2 个 epoch 的训练,则系统首先按 [0, …, 9, 0, …, 9] 顺序排好样本索引,然后打乱该顺序为数据集创建最终的全局顺序。请注意,这意味着训练不会简单地遍历整个数据集然后重复,你有可能在看到另一个样本之前看到同一个样本两次,但在训练结束时模型将只看到每个样本两次。这有助于确保整个训练过程中的训练曲线平滑。这些索引,包括每个样本在原始数据集中的偏移量,被保存到一个文件中,以避免每次开始训练时都重新计算它们。最后,可以将其中几个数据集以不同的权重混合到训练最终使用的数据中。
2.8 Checkpoint重塑和互操作性
用于将可变张量和流水线并行大小的 Megatron-LM Checkpoint重塑为Transformers 分片Checkpoint的实用程序,因为它对大量工具具有强大的支持,例如Accelerate Big Model Inference、Megatron-DeepSpeed Inference 等。还支持将Transformers 分片Checkpoint转换为可变张量和流水线并行大小的 Megatron-LM Checkpoint,以进行大规模训练。
2.9 CUDA 融合核函数
GPU 主要做两件事。它可以将数据写到显存或从显存读数据,并对这些数据执行计算。当 GPU 忙于读写数据时, GPU 的计算单元就会空闲。如果想有效地利用 GPU,我们希望将空闲时间降至最低。
核函数是一组实现特定 PyTorch 操作的指令。例如,当你调用 torch.add 时,它会通过一个 PyTorch 调度器,它会根据输入张量及其他变量的取值来决定它应该运行哪些代码,最后运行它。CUDA 核函数使用 CUDA 来实现这些代码,因此只能在 NVIDIA GPU 上运行。
现在,当使用 GPU 计算 c = torch.add (a, b); e = torch.max ([c,d]) 时,一般情况下,PyTorch 将执行的操作是启动两个单独的核函数,一个执行 a 和 b 的加法,另一个执行取 c 和 d 两者的最大值。在这种情况下,GPU 从其显存中获取 a 和 b,执行加法运算,然后将结果写回显存。然后它获取 c 和 d 并执行 max 操作,然后再次将结果写回显存。
如果要融合这两个操作,即将它们放入一个 “融合核函数” 中,然后启动那个内核,不会将中间结果 c 写到显存中,而是将其保留在 GPU 寄存器中,并且仅需要获取 d 来完成最后的计算。这节省了大量开销并防止 GPU 空闲,因此整个操作会更加高效。
融合核函数就是这样。它们主要将多个离散的计算和进出显存的数据移动替换为有很少数据移动的融合计算。此外,一些融合核函数会对操作进行数学变换,以便可以更快地执行某些计算组合。
为了快速高效地训练,有必要使用 Megatron-LM 提供的几个自定义 CUDA 融合核函数。特别地,有一个 LayerNorm 的融合核函数以及用于融合缩放、掩码和 softmax 这些操作的各种组合的核函数。Bias Add 也通过 PyTorch 的 JIT 功能与 GeLU 融合。这些操作都是瓶颈在内存的,因此将它们融合在一起以达到最大化每次显存读取后的计算量非常重要。因此,例如,在执行瓶颈在内存的 GeLU 操作时同时执行 Bias Add,运行时间并不会增加。这些核函数都可以在 Megatron-LM repository 代码库中找到。
参考
- 千亿参数开源大模型 BLOOM 背后的技术
- Megatron-LM
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
- PipeDream: Fast and Efficient Pipeline Parallel DNN Training
- GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
- Reducing Activation Recomputation in Large Transformer Models
- Docs » Using NCCL » Operations
- 大模型-LLM分布式训练框架总结
- Ring Attention with Blockwise Transformers for Near-Infinite Context
- Megatron-LM源码系列(八): Context Parallel并行
- Context parallelism overview
- [源码解析] 模型并行分布式训练Megatron (1) — 论文 & 基础
- Megatron-LM 的分布式执行调研:原理和最佳实践
- Ring Attention with Blockwise Transformers for Near-Infinite Context