聚类
1.有监督学习与无监督学习
首先,看一下有监督学习(Supervised Learning)和无监督学(Unsupervised
Learning)习的区别,给定一组数据(input,target)为
有监督学习: 最常见的是回归(regression)和分类(classification)。
- Regression:
是实数向量。回归问题,就是拟合 的一条曲线,使得下式损失函数 最小。
- Classification:
是一个finite number,可以看做类标号。分类问题需要首先给定有label的数据训练分类器,故属于有监督学习过程。分类问题中,cost function 是 属于类 的概率的负对数。
无监督学习:无监督学习的目的是学习一个function
density estimation就是密度估计,估计该数据在任意位置的分布密度
clustering就是聚类,将
聚集几类(如K-Means),或者给出一个样本属于每一类的概率。由于不需要事先根据训练数据去训练聚类器,故属于无监督学习。 PCA和很多deep learning算法都属于无监督学习。
聚类
聚类试图将数据集中的样本划分为若干个通常不相交的子集,每个子集称为一个“簇”(cluster).形式化地说,假定样本集
包含
相应地,用
表示样本
基于不同的学习策略有很多种类型的聚类学习算法,这里先讨论两个基本问题,性能度量和距离计算。
2.性能度量
聚类性能度量亦称聚类“有效性指标”(validity index).对于聚类结果,需要通过某种性能度量来评估其好坏。聚类结果应“簇内相似度”(intra-cluster similarity)高且“簇间相似度”(inter-cluster similarity)低。
聚类性能度量大致分为两类.一类是将聚类结果与某个参考模型(reference model)进行比较,称为外部指标(external index);另一类是直接考察聚类结果而不利用任何参考模型,称为内部指标(internal index).
对数据集
参考模型给出的簇划分为
相应地,令
其中集合
基于上述式子可导出以下常用的聚类性能度量外部指标:
- Jaccard系数(Jaccard Coefficient,简称JC)
- FM指数(Fowlkes and Makkows Index,简称FMI)
- Rand指数(Rand Index,简称RI)
上述性能度量的结果值均在
定义
其中,
显然,
由上述各种距离的定义可以导出以下常用的聚类性能度量内部指标:
- DB指数(Davies_Bouldin Index,简称DBI)
- Dunn指数(Dunn Index,简称DI)
3.距离计算
非负性:
; 同一性:
当且仅当 ; 对称性:
; 直递性:
.
给定样本
对于
对于1,2,3这类数字型之间的距离,可以直接算出1与2的距离比较近、与3的距离比较远,这样的属性称为有序属性(ordinal attribute);而对于与飞机,火车,轮船这样的离散属性则不能直接在属性值上计算距离,称为无序属性(non-ordinal attribute)。无属性距离不可用闵可夫斯基距离计算。
对无序属性可采用VDM(Value Difference Metric).令
将闵可夫斯基距离和VDM结合即可处理混合属性。假定有
当样本空间中不同属性的重要性不同时,可使用加权距离(weihted distance),以加权闵可夫斯基距离为例
其中权重
通常相似度度量是基于某种形式的距离来定义的,距离越大,相似度越小。用于相似度度量的距离未必一定要满足距离度量的所有基本性质,尤其是直递性。不满足直递性的距离称为非度量距离(non-metric-distance).
4.原型聚类
原型聚类亦称基于原型的聚类(protorype-based clustering),此类算法假设聚类结构能通过一组原型刻画,算法先对原型进行初始化,然后对原型进行迭代更新。
4.1 k-means算法
给定样本集
k-means算法针对聚类所得簇划分
最小化平方误差
其中
最小化上述平方误差并不简单,找到最优解需要考察样本集
k-means算法流程:
输入:聚类簇数
过程:
从
中随机选择 个样本作为初始均值向量 令
对于
计算样本 与各均值向量 的距离:
根据距离最近的均值向量确定
对于
计算新均值向量 ;如果 则将当前均值向量 更新为 ;否则保持当前均值向量不变 重复步骤3,4,直到当前均值向量均未更新
输出:簇划分
K-Means 优缺点:
当结果簇是密集的,而且簇和簇之间的区别比较明显时,K-Means
的效果较好。对于大数据集,K-Means 是相对可伸缩的和高效的,它的复杂度是
K-Means 的最大问题是要求先给出 k 的个数。k 的选择一般基于经验值和多次实验结果,对于不同的数据集,k 的取值没有可借鉴性。另外,K-Means 对孤立点数据是敏感的,少量噪声数据就能对平均值造成极大的影响。
The Lloyd’s Method
Input: n个数据点的集合
Initialize: 初始化簇中心
Repeat: 直到满足停止条件
For each j:
,保持 不变,找出最优的簇 For each j:
保持簇不变 算出最优中心点
每次迭代损失函数均在下降,并有下界,因此收敛。每次迭代
Lloyd方法初始化有多种方式,最常用的有以下几种:
- 从数据集中随机选取k个中心点
- Furthest Traversal
- k-means++
随机初始化
随机初始化过程如下图:
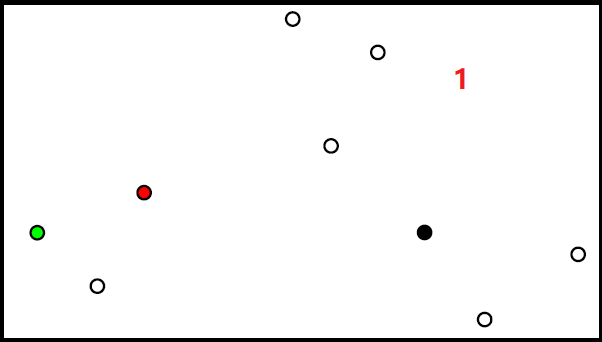
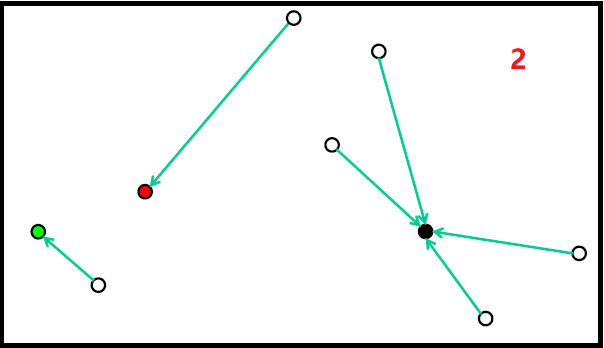
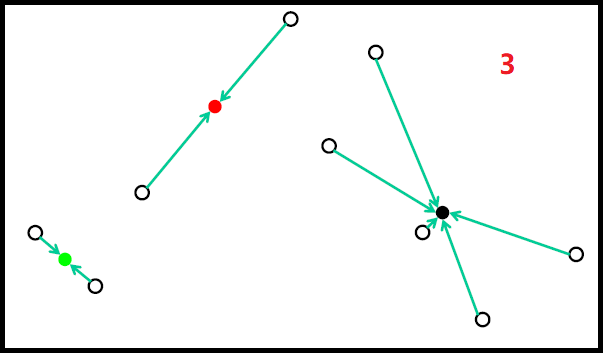
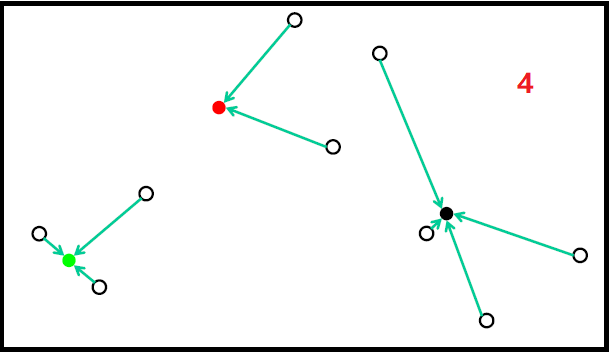
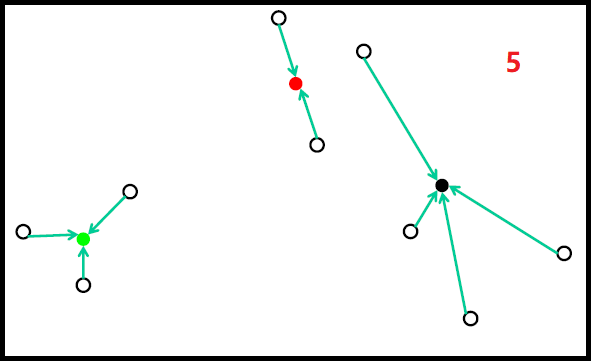
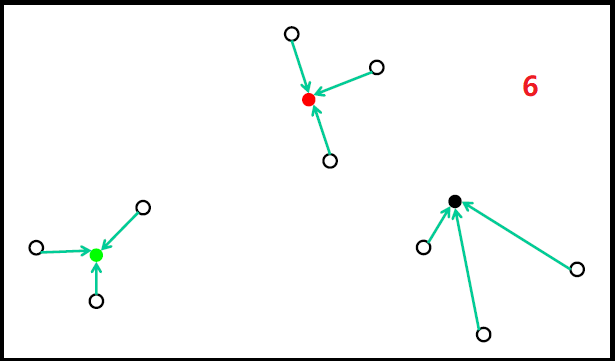
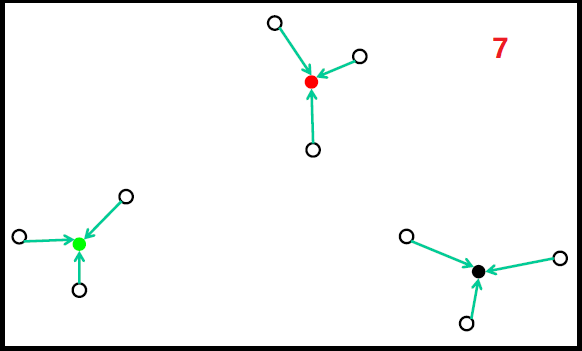
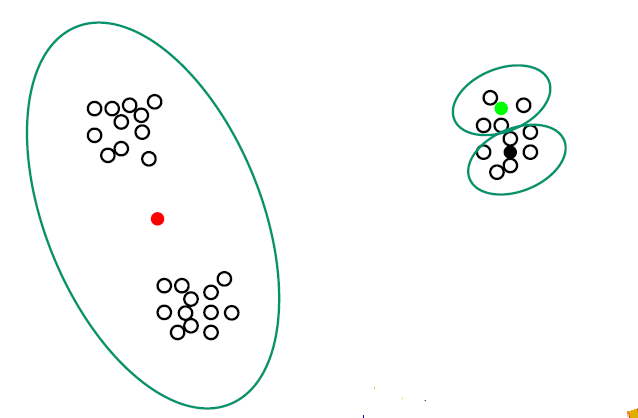
但随机初始化,会存在如下问题:
Furthest Traversal
首先任意选择一个簇的中心
For j = 1,2,
- 选择一个离已选择的中心点
都远的点 作为新的中心点
过程如下:
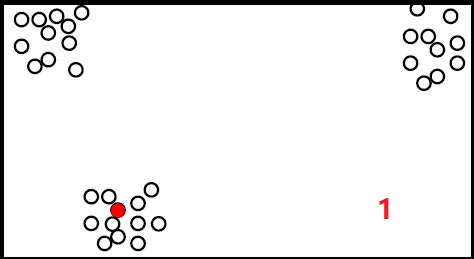
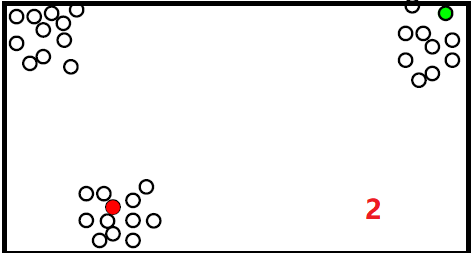
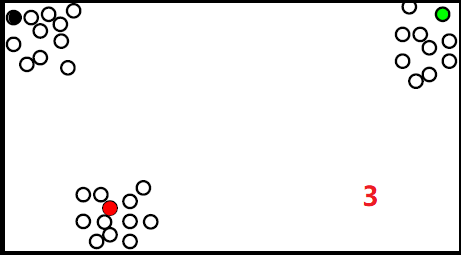
但是这种方法容易受到噪点的影响,如下:
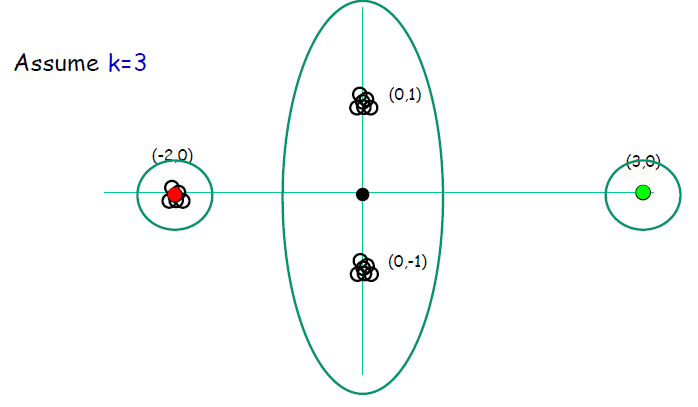
k-means++
假设
首先,随机选择
For j=2,…,k
- 在数据集中选择
,根据以下分布
将上述距离平方算出后进行归一化,便是
上述方法虽然噪点被选的概率很高,但是噪点的个数较少;而和现有中心点是不同簇的点同样离中心点较远,并且这样点的个数较多,因此这些点其中之一被选的概率应该比噪点被选中的概率高;这样可降低噪点对聚类结果的影响。
k-means++步骤
1.先从我们的数据库随机挑个随机点当“种子点”。
2.对于每个点,我们都计算其和最近的一个“种子点”的距离
并保存在一个数组里,然后把这些距离加起来得到 。 3.然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在
中的随机值 ,然后用 ,直到 ,此时的点就是下一个“种子点”。 4.重复第(2)和第(3)步直到所有的K个种子点都被选出来。
5.进行K-Means算法。
k-means++ 每次需要计算点到中心的距离,复杂度为
可以看到算法的第三步选取新中心的方法,这样就能保证距离

假设A、B、C、D的
可以将上述方法进行推广
当
当
当
当
4.2 学习向量化
与
给定样本集
每个样本
每个原型向量代表一个聚类簇,簇标记
算法主要步骤包括:初始化原型向量;迭代优化,更新原型向量。
具体来说,主要是:
- 1.对原型向量初始化,对第
个簇可从类别标记为 的样本中随机选取一个作为原型向量,这样初始化一组原型向量
2.从样本中随机选择样本
,计算样本 与 的距离: ;找出与 距离最近的原型向量 $ 3.如果
则令 ,否则令 4.更新原型向量,
5.判断是否达到最大迭代次数或者原型向量更新幅度小于某个阈值。如果是,则停止迭代,输出原型向量;否则,转至步骤2。
LVQ的关键是第3-4步,即如何更新原型向量。对样本
则原型向量
类似的,若
在学得一组原型向量
由此形成了对样本空间
4.3 高斯混合聚类
与
对
其中
定义高斯混合分布
该分布共由
假设样本的生成过程由高斯混合分布给出:首先,根据
常用EM算法对上述分布进行迭代优化求解,之前已详细讨论过EM算法,此处不再进行讨论。
5.密度聚类
密度聚类亦称基于密度的聚类(density-based clustering),此类算法假设聚类结构能通过样本分布的紧密程度确定。通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果。
DBSCAN是一种著名的密度聚类算法,它基于一组邻域(neighborhood)参数
邻域:对 ,其 邻域包含样本集 中与 的距离不大于 的样本,即 | 。 核心对象(core object): 若
的 邻域至少包含 个样本,即 ,则 是一个核心对象; 密度直达(directly density-reachable):若
位于 的 邻域中,且 是核心对象,则称 由 密度直达; 密度可达(density-reachable):对
与 ,若存在样本序列 ,其中 且 由 密度直达,则称 由 密度可达; 密度相连(density-connected):对
与 ,若存在 使得 与 均由 密度可达,则称 与 密度相连。
下图给出上述概念的直观概念
上图中
基于这些概念,DBSCAN将簇定义为:由密度可达关https://zhuanlan.zhihu.com/p/577060385系导出的最大的密度相连样本集合。形式化地说,给定邻域参数
连接性(connectivity):
与 密度相连 最大性(maximality):
由 密度可达
若
于是,DBSCAN算法先任选数据集中的一个核心对象为种子(seed),再由此出发确定相应的聚类簇,算法描述如下。算法先根据给定的邻域参数
输入:样本集
输出:簇划分
初始化核心对象集合
,初始化聚类簇数 ,初始化未访问样本集合 ,簇划分 对于
按下面的步骤找出所有的核心对象:
- 通过距离度量方式,找到样本
的 邻域子样本集
- 通过距离度量方式,找到样本
- 如果子样本集样本个数满足|
| ,将样本 加入核心对象样本集合:
- 如果子样本集样本个数满足|
如果核心对象集合
,则算法结束,否则转入步骤4 在核心对象集合
中,随机选择一个核心对象 ,初始化当前簇核心对象队列 ,初始化类别序号 ,当初始化当前簇样本集合 ,更新未访问样本集合 如果当前簇核心对象队列
,则当前聚类簇 生成完毕。更新簇划分 ,更新核心对象集合 ,转入步骤3. 在当前簇核心对象队列
中取出一个核心对象 ,通过邻域距离阈值 找出所有的 邻域子集样本 ,令 ,更新当前簇样本集合 ,更新未访问样本集合 ,更新 ,转入步骤5.
5.1 DBSCAN小结
对于那些异常样本点或者说少量游离于簇外的样本点,这些点不在任何一个核心对象在周围,在DBSCAN中一般将这些样本点标记为噪音点。
在DBSCAN中,一般采用最近邻思想,采用某一种距离度量来衡量样本距离,比如欧式距离。对应少量的样本,寻找最近邻可以直接去计算所有样本的距离,如果样本量较大,则一般采用KD树或者球树来快速的搜索最近邻。
某些样本可能到两个核心对象的距离都小于
DBSCAN的主要优点有:
可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
DBSCAN的主要缺点有:
如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值
,邻域样本数阈值 联合调参,不同的参数组合对最后的聚类效果有较大影响。
6.层次聚类
层次聚类(hierarchical clustering)试图在不同层次对数据集进行划分,从而形成树形的聚类结构。数据集的划分可采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略。
AGNES是一种采用自底向上聚合策略的层次聚类算法。它将数据集中的每个样本看做一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并,该过程不断重复,直到达到预设的聚类个数。这里的关键是如何计算聚类簇之间的距离。实际上,每一个簇是一个样本集合,因此,值需要采用关于集合的某种距离即可。例如,给定聚类簇
最小距离:
最大距离:
平均距离:
显然,最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定,而平均距离则由两个簇的所有样本共同决定。当聚类簇聚类由
单链接步骤如下图(1-5)
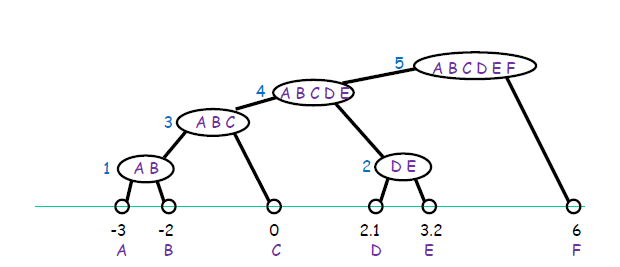
全链接步骤如下图(1-5)
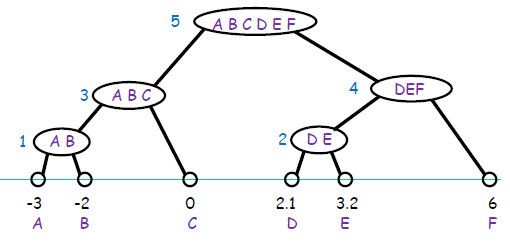
AGNES算法描述如下:
输入样本集
将每个对象当做一个簇进行初始化,
设置当前聚类簇数
计算每两个簇的距离,得到距离矩阵
当
时,找出距离最近的两个聚类簇 ,合并 : ;对于 的聚类簇 重编号为 ;然后删除距离矩阵 的第 行和列;对于 ,计算 ; 更新 ,直到达到预设的聚类簇数。
输出:划分
AGNES算法简单,但遇到合并点选择困难的情况.一旦一组对象被合并,不能撤销,算法的复杂度为
DIANA算法
DIANA(Divisive Analysis)算法属于分裂的层次聚类,首先将所有的对象初始化到一个簇中,然后根据一些原则(比如最邻近的最大欧式距离),将该簇分类。直到到达用户指定的簇数目或者两个簇之间的距离超过了某个阈值。
DIANA用到如下两个定义:
簇的直径:在一个簇中的任意两个数据点都有一个欧氏距离,这些距离中的最大值是簇的直径
平均相异度(平均距离)
算法描述:
输入:包含
输出:
将所有对象整个当成一个初始簇
在所有簇中挑选出具有最大直径的簇;找出所挑出簇里与其他点平均相异度最大的一个点放入splinter group,剩余的放入old party中。
在old party里找出到splinter group中点的最近距离不大于old party中点的最近距离的点,并将该点加入splinter group
重复 3 直到没有新的old party的点被分配给splinter group;
Splinter group 和old party为被选中的簇分裂成的两个簇,与其他簇一起组成新的簇集合
算法性能:
缺点是已做的分裂操作不能撤销,类之间不能交换对象。如果在某步没有选择好分裂点,可能会导致低质量的聚类结果。大数据集不太适用。
参考
- 周志华 《机器学习》