LLM(九)——Mixture-of-Depths Transformers
一、Mixture-of-Depths Transformers
MoD(Mixture-of-Depths)采用的技术类似于混合专家(Mixture of Experts,MoE) transformer,其中动态token级路由决策是在整个网络深度上做出的。然而,与 MoE 的想法不同,MoD要么将计算应用于像标准transformer那样的token,要么通过残差连接(Residual Connection)传递它,保持不变并节省计算资源。与MoE相反,这种路由策略应用于前向多层感知机(Multi-Layer Perceptron, MLP)和多头注意力(Multi-head Attention)。由于这也影响了处理的key和query,路由不仅决定了更新哪些token,还决定了哪些token可以被关注。
MoD技术还允许在性能和速度之间进行权衡。一方面,可以训练一个MoD transformer在最终的对数概率训练目标上比标准transformer提高1.5%,并且训练所需的时间相当。另一方面,可以将一个MoD transformer训练达到与isoFLOP最佳的传统transformer相同的训练损失,但每次前向传递使用的FLOPs少得多(高达50%)。这些结果表明,MoD transformer学会了智能路由策略(即跳过不必要的计算),因为它们可以在每次前向传递的FLOPs足迹较小的情况下,实现相同或更好的序列对数概率。 /posts/
1.1 MoD实现
1.1.1 定义计算预算
- 通过限制序列中可以参与块计算(例如自注意力和 MLP)的token数量来定义计算预算,该预算将小于等效的标准transformer。
- 为了定义计算预算,还必须理解容量的概念,它定义了构成给定计算输入的token总数,并且还确定使用条件计算的转换器的总 FLOP 数,而不是任何结果路由决策。
- 并不是所有token都同样重要,某些token可能不需要进行自注意力和 MLP的计算,可以通过学习来识别这些token,因此与标准transformer相比,可以通过降低计算容量来定义每个前向传递更小的计算预算。
例如,在每个标准transformer模块中,自注意力和MLP的处理容量为
1.1.2 对transformer模块进行路由
- token的路由可以通过自注意力和 MLP 块或残差连接这两条路径之一来完成,后者的计算成本较低,从而导致块输出完全由其输入值决定。
- 路由存在两个极端,一个极端是将每个token路由到每个块,就像在标准transformer中一样,而另一个极端是将所有token路由到每个块周围,这提供了一个更快的模型,但下游性能较差。更理想的方法假设为介于这两个极端之间,以获得与标准transformer相比具有更好性能和更快速度的最佳模型。
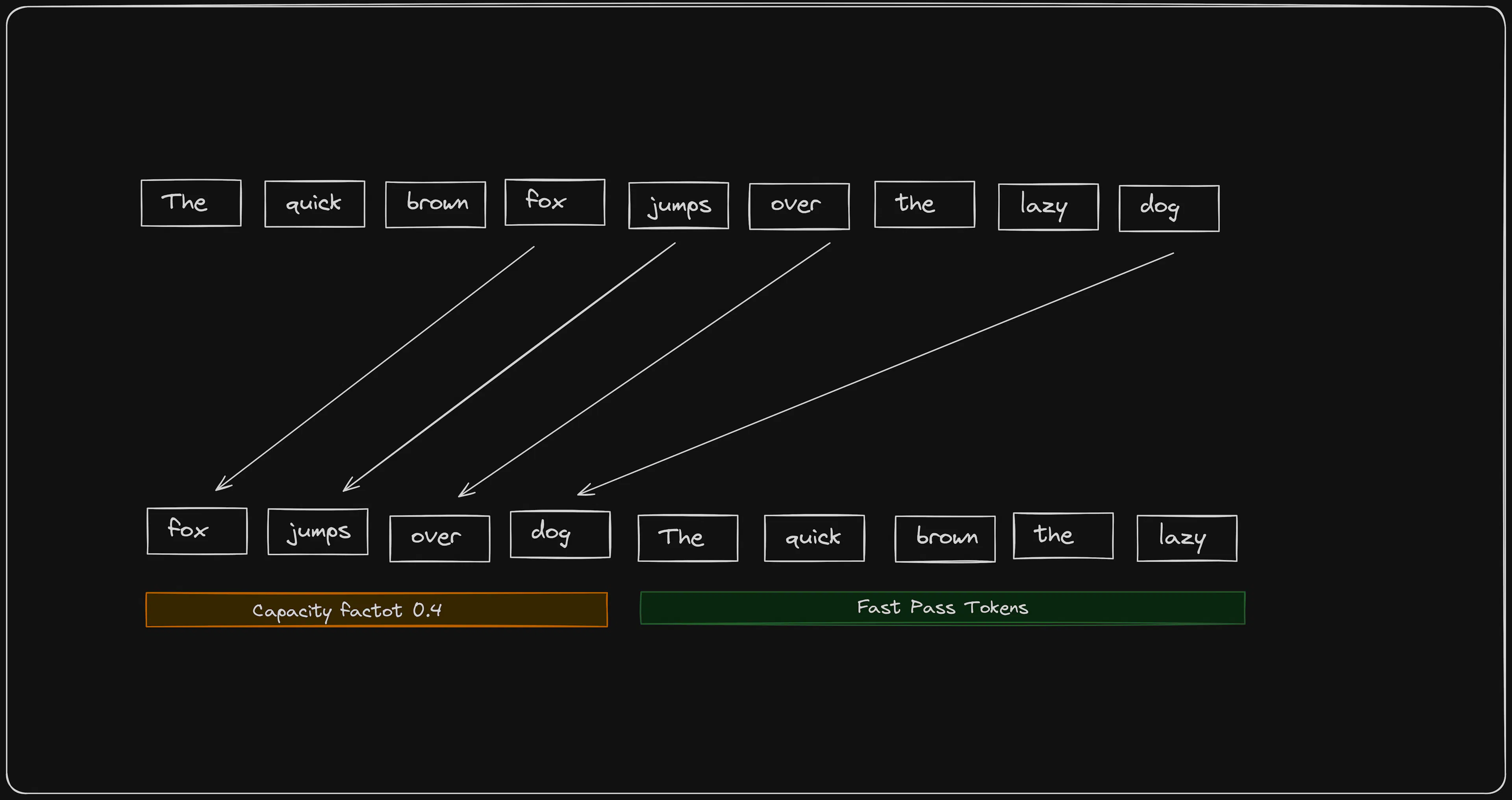
1.1.3 路由机制
与dropout相比,学习路由更可取,而dropout相对于路由token来说表现明显较差。作为学习路由的一部分,网络可以了解哪些token比其他token需要更多或更少的处理。模型使用
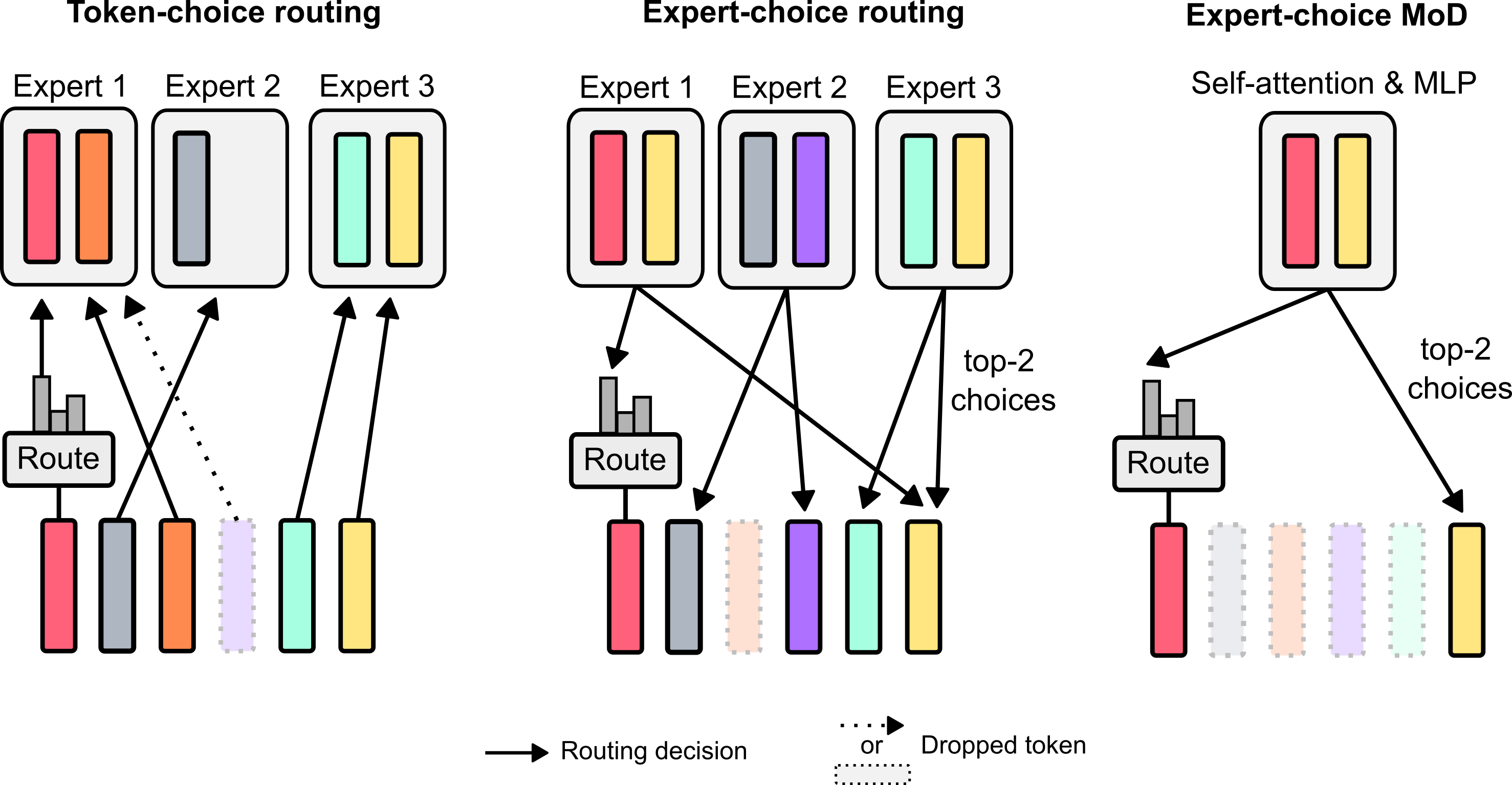
基于token的选择:路由器在计算路径上生成每个token的概率分布,然后将token汇集到其选择的计算路径(可以是概率最高的路径)。该方案可能存在负载平衡问题,因为无法保证token在可能的路径之间适当划分。
基于专家的选择:每个路径不是根据token的偏好选择
个token,而不是选择其首选路径。它确保了完美的负载平衡,因为 个token保证被传送到每条路径。此外,由于 操作取决于路由器权重的大小,因此该路由方案允许相对路由权重来帮助确定哪些token最需要块的计算。路由器还可以通过适当设置权重来确保最关键的token位于 中。因此,对于 MoD 方法来说,由于上述相对于token选择路由的优点,该方案是更优选的方法。
1.1.4 路由实现
每个 token 都由路由器处理以产生标量权重,然后使用前
假设在给定层
目标是使用这些路由器权重来确定块对每个 token 的计算的输出。假设
这里,
将函数
1 | |
1.1.5 成果
虽然专家选择路由具有许多优点,但它有一个明显的问题:top-k 操作是非因果的。这意味着给定 token 的路由权重是否属于序列的 top-k 取决于其后面的 token 的路由权重值,而在自回归采样时无法访问这些值。为了解决推理期间 top-k 路由的非因果性质,训练辅助预测器网络来预测token是否会出现在 top-k 中,从而实现高效的自回归采样。MoD 模型使用标准语言建模目标进行训练,并添加了用于自回归采样的辅助预测器损失。
MoD hyperparameter tuning
最佳的MoD transformer在达到更低的损失值的同时,其参数数量也更多。存在一些参数规模较小的MoD模型,在其超参数设定下虽然不是isoFLOP最优的,但它们的性能与最优基准模型相当或更好,同时训练速度更快。每隔一个块进行路由对于实现强性能至关重要,将容量减少到总序列的12.5%,即有87.5%的token绕过块时,可以带来渐进的性能提升,但减少到12.5%这个比例以下性能开始下降。
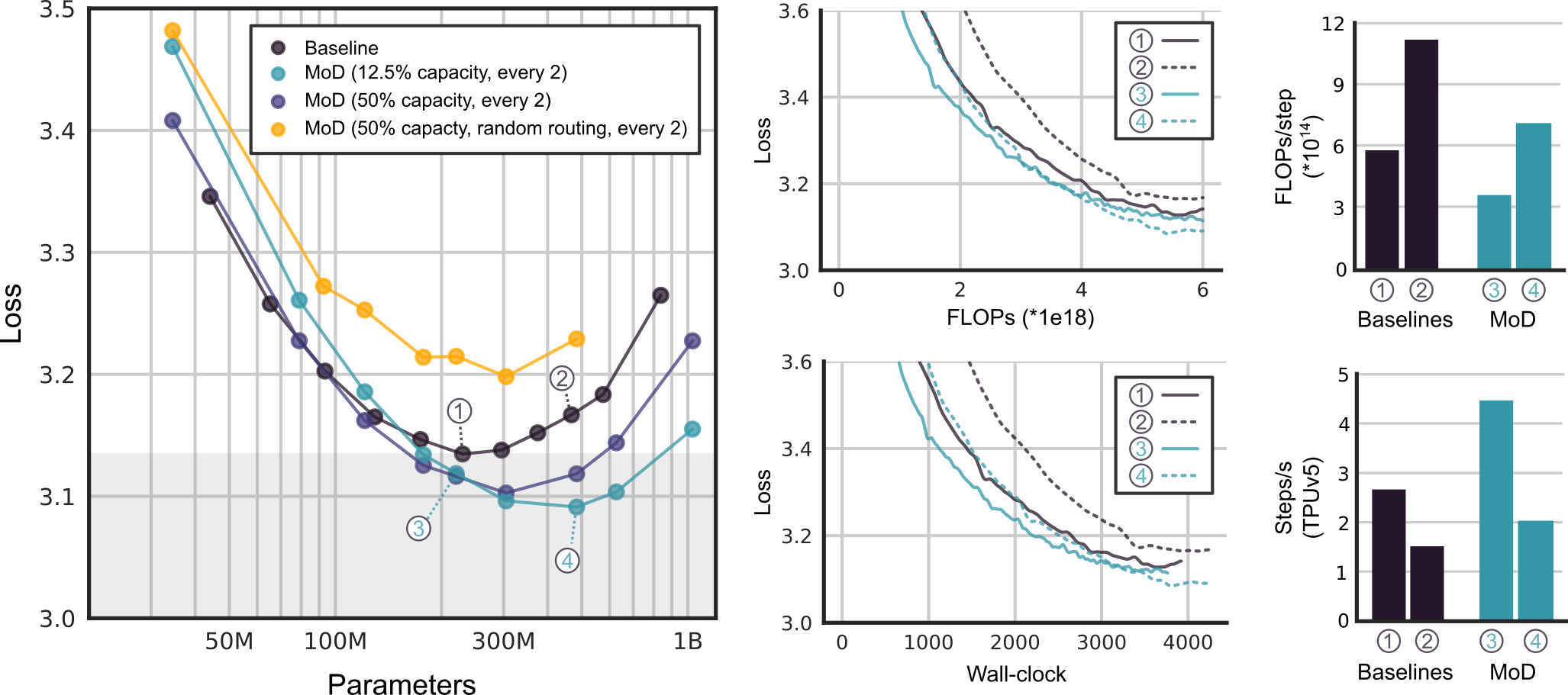
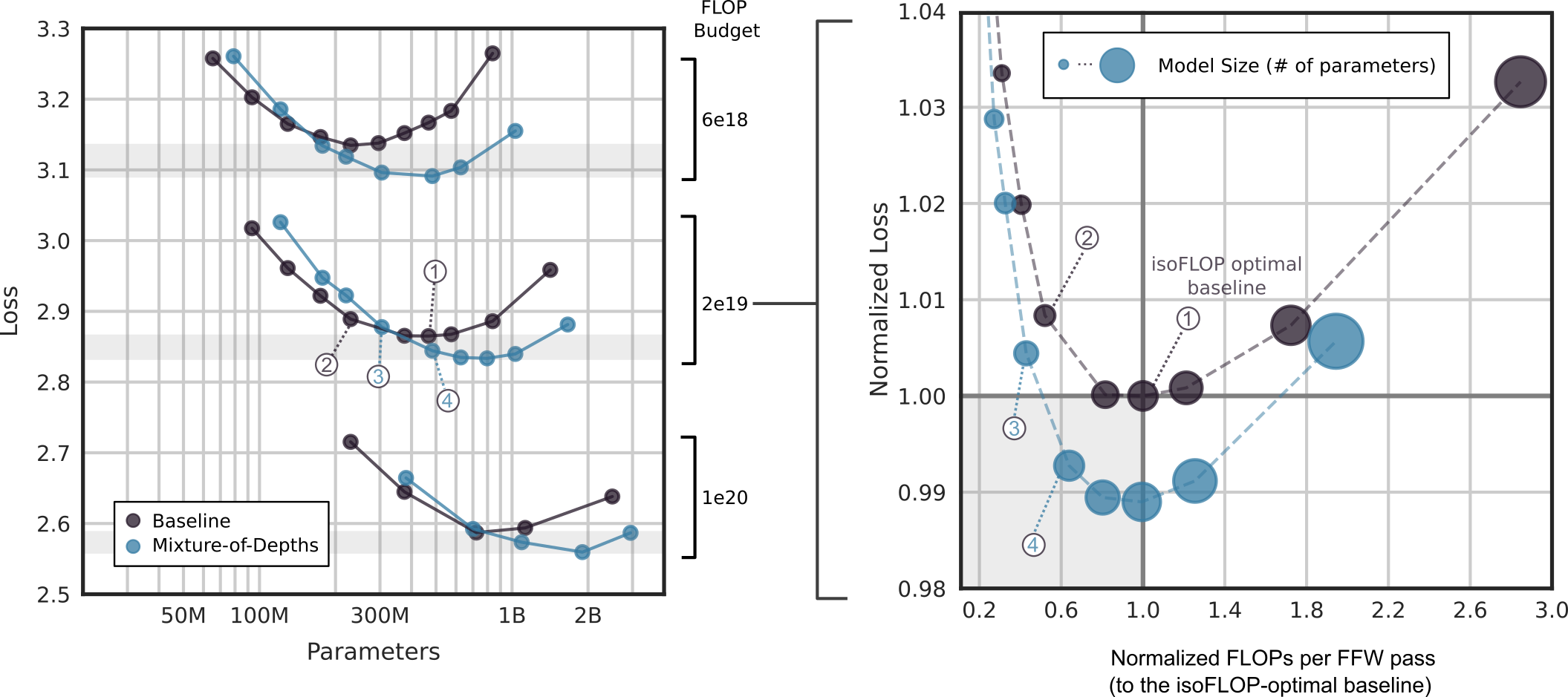
isoFLOP分析
12.5% 容量的 MoD 变体用于对 6e18、2e19 和 1e20 FLOP 执行 isoFLOP 分析,训练模型大小从 60M 到 3B 参数不等。下图表示每次前向传递的相对 FLOP(标准化为 isoFLOP 最佳基线)。存在着既能与等效浮点操作最优基线保持一致的性能又能提高训练速度的MoD transformer,这既因为它们每参数使用的浮点操作数更少,也因为它们使用的参数总数更少。只需调整MoD配置(即容量和路由频率)下的模型规模,使其每次前向传递的浮点运算数与等效浮点操作最优基准相等,就可以获得该配置下表现最佳的MoD变体。
路由分析
下图将表示路由决策,并观察序列末尾的深蓝色垂直带。在下面的直方图中,可以观察到路由器权重的分布如辅助损失所示:大约 12.5% 的权重高于 0.5% 和 87.5%。采取了大胆绕过部分块的路由策略,transformer模型相对于基准模型仍能取得性能上的提升。

自回归性能评估
在自回归采样期间从训练中的非因果 top-

1.1.6 Mixture-of-Depths-and-Experts (MoDE)
Mixture of Depths(MoD)技术与Mixture of Experts(MoE)技术的融合。
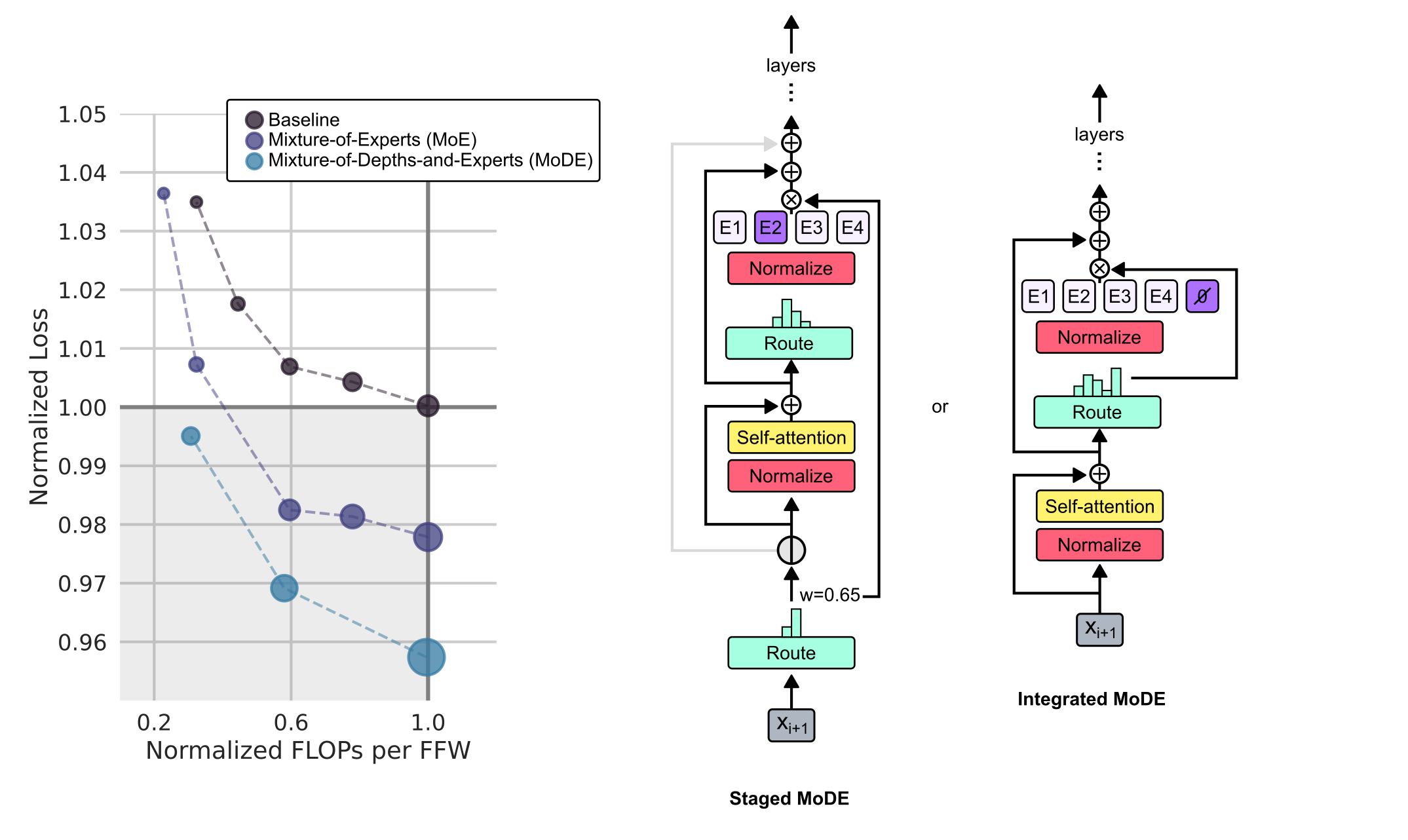
Staged MoDE:在自注意力步骤之前将token绕向区块或向区块路由。 Integrated MoDE:通过在传统MLP专家中集成“无操作”专家来实现MoD路由
在这两种变体中,Staged MoDE允许token跳过自注意力步骤,而Integrated MoDE简化了路由机制。Integrated MoDE 是更可取的,因为token明确地学习选择围绕专家的剩余路径,而不是首选专家但在实现容量减少时被丢弃。
参考
- Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
- 《Mixture-of-Depths: Dynamically allocating compute in transformer-based language models》精华摘译
- Mixture of Depth is Vibe
- Mixture-of-Depths: A new approach to efficiently allocate compute in Transformer Language Models
- Mixture of Depths: Dynamic Compute Allocation for Language Models
- Mixture-of-Depths: Dynamically allocating compute in transformer-based language models