LLM(八)——MoE
一、混合专家模型(Mixtral of Experts)
在 Transformer 模型的背景下,MoE 主要由两个部分组成:
稀疏 MoE 层 代替了传统的密集前馈网络 (FFN) 层。MoE 层包含若干“专家”(如 8 个),每个专家都是一个独立的神经网络。实际上,这些专家通常是 FFN,但它们也可以是更复杂的网络,甚至可以是 MoE 本身,形成一个层级结构的 MoE。
一个门控网络或路由器,用于决定哪些 Token 分配给哪个专家。例如,在下图中,“More”这个 Token 被分配给第二个专家,而“Parameters”这个 Token 被分配给第一个网络。值得注意的是,一个 Token 可以被分配给多个专家。如何高效地将 Token 分配给合适的专家,是使用 MoE 技术时需要考虑的关键问题之一。这个路由器由一系列可学习的参数构成,它与模型的其他部分一起进行预训练。
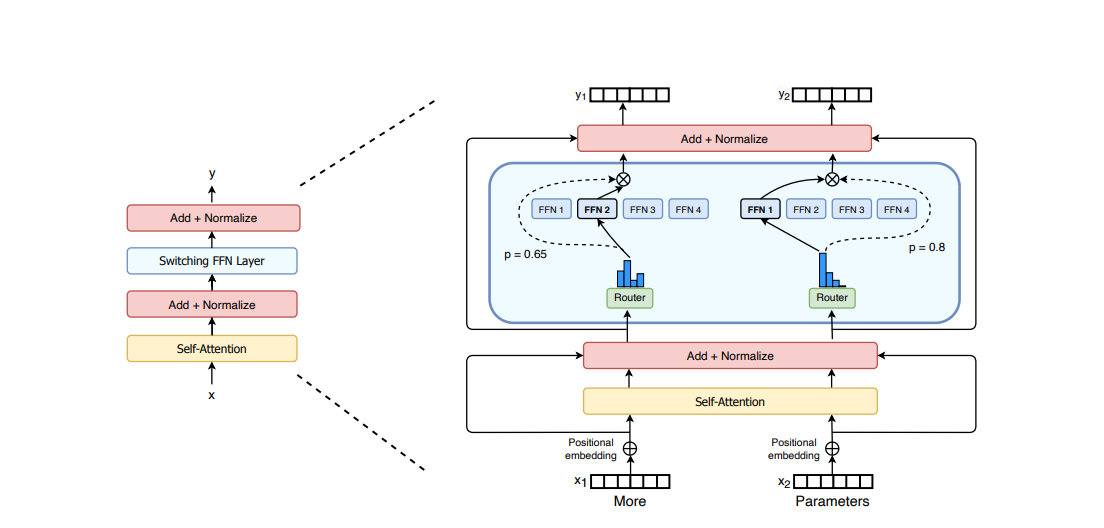
1.1 稀疏性
稀疏性基于条件计算的概念。不同于密集模型中所有参数对所有输入都有效,稀疏性让模型能够只激活系统的部分区域。虽然大批量处理通常能提高性能,但在 MoE 中,当数据通过活跃的专家时,实际的批量大小会减小。例如,如果我们的批量输入包含 10 个 Token,可能有五个 Token 由一个专家处理,另外五个 Token 分别由五个不同的专家处理,这导致批量大小不均匀,资源利用率低下。
通过一个学习型的门控网络 (G),决定将输入的哪些部分分配给哪些专家 (E):
在这种设置中,所有专家都参与处理所有输入——这是一种加权乘法过程。但如果 G 的值为 0,就无需计算相应专家的操作,从而节约了计算资源。在传统设置中,通常使用一个简单的网络配合 softmax 函数。这个网络会学习如何选择最合适的专家处理输入。
其他类型的门控机制,如带噪声的 Top-K 门控。这种方法加入了一定的(可调节的)噪声,然后只保留最高的 k 个值。具体来说:
- 添加噪声
- 保留前k个值
- 使用softmax函数
加入噪声是为了实现负载均衡。路由到
1.2 Switch Transformer
Switch Transformer中采用了一种简化的稀疏路由,只路由到单个专家。这种简化保持了模型质量,减少了路由计算,并表现得更好。Switch层的好处是三方面的:(1) 由于只将token路由到单个专家,路由器计算得以减少。(2) 每个专家的批量大小(专家容量)至少可以减半,因为每个token只被路由到单个专家。(3) 路由实现得以简化,通信成本得以降低。
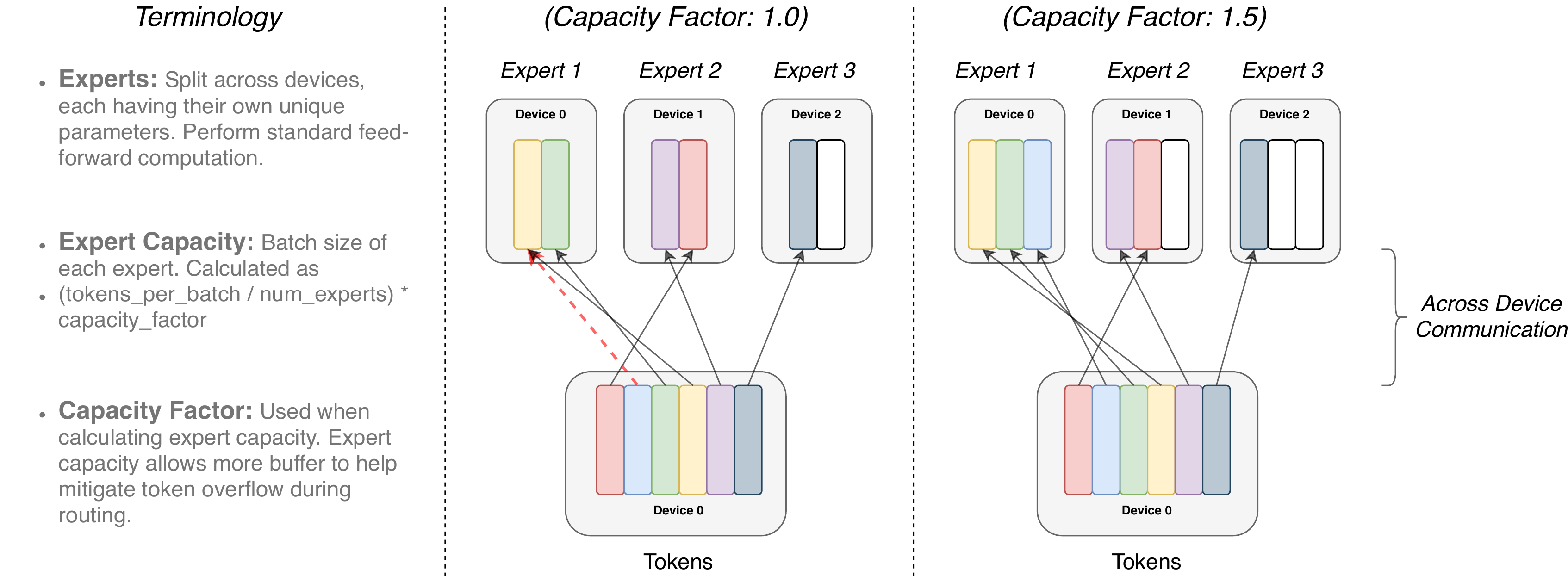
上图中每个专家处理由容量因子(capacity factor)调制的固定批量大小的Tokens。每个Token被路由到具有最高路由器概率的专家,但每个专家的批量大小固定为(total_tokens / num_experts) × capacity_factor。如果Tokens分配不均,则某些专家将溢出(用红色虚线表示),导致这些Tokens不被该层处理。更大的容量因子可以缓解此溢出问题,但也会增加计算和通信成本(用填充的白色/空槽表示)。
分布式 Switch
专家容量——每个专家计算的token数量——是通过将批次中的token数量平均分配给专家数量,然后通过容量因子进一步扩展来设置的:
每批 token 数量除以专家数量,再乘以容量因子。按此计算方式,可以均匀分配批次中的 token 给每个专家。如果容量因子大于 1,可以为 token 分配不均的情况提供缓冲。但容量增加会带来更高的设备间通信成本,这是一个需要权衡的问题。特别地,Switch Transformers 在较低的容量因子(1-1.25)下表现优异。
可微分的负载均衡损失
为了鼓励专家之间的负载均衡,增加了一个辅助损失。对于每个 Switch
层,这个辅助损失在训练期间被加到总模型损失中。给定由
由于寻求在
1.3 改进的训练和微调技术
改进训练
尝试了一种选择性的精确度方法,例如在训练专家系统时使用
bfloat16
格式,而在其他计算过程中则采用全精度。降低精度能够显著减少处理器间的通信成本、计算成本以及存储数据的内存需求。但初期实验中,无论是专家系统还是门控网络都采用
bfloat16
进行训练,结果训练过程变得更加不稳定。特别是路由器计算部分,由于其涉及到指数函数,因此更高的精度显得尤为重要。为了缓解这种不稳定性,路由过程最终也采用了全精度处理。
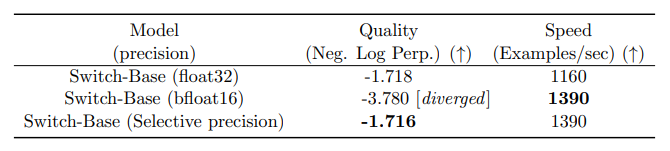
采用选择性精度处理不仅能保持质量,还能提高模型的处理速度。
微调 MoE 技术
密集型模型和稀疏型模型在过拟合上表现出明显不同的特点。稀疏型模型更易于过拟合,因此可以尝试在专家系统内部应用更强的正则化手段,例如不同层次的 dropout 率——对密集层和稀疏层分别设置不同的 dropout 率。
Switch Transformers 的研究发现,在预训练阶段达到固定的困惑度时,稀疏模型在下游任务中的表现通常不及密集型模型,特别是在逻辑推理较多的任务,如 SuperGLUE 上。然而,在知识密集型的任务,比如 TriviaQA 上,稀疏模型的表现却出奇地好。研究还发现,在微调阶段使用较少数量的专家有助于模型表现。此外,模型在小型任务中表现不佳,但在大型任务中则表现良好,这也证明了其泛化能力的问题。
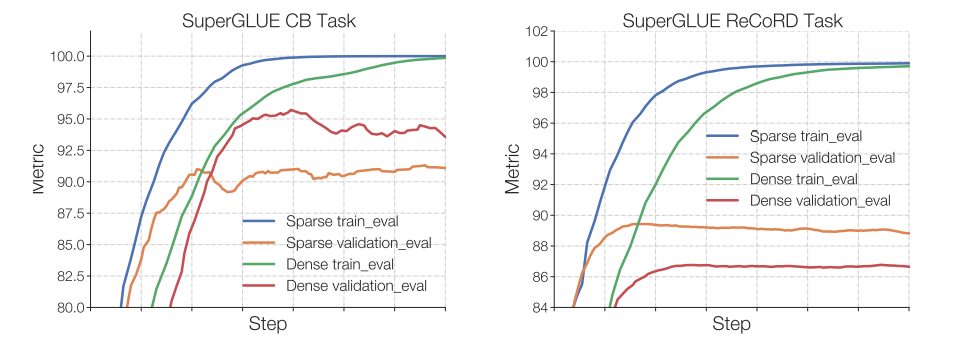
从图中可以看出,在小型任务(左图)中,稀疏模型在验证集上明显过拟合。而在大型任务(右图)中,MoE 的表现却相当不错。
另一个尝试是冻结所有非专家层的权重,结果如预期那样导致了性能大幅下降,因为 MoE 层占据了网络的大部分。相反,仅冻结 MoE 层的参数几乎能达到更新所有参数的效果。这种方法可以加速微调过程,同时减少内存使用。
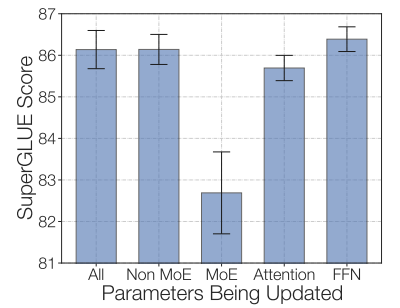
通过仅冻结 MoE 层,不仅能加快训练速度,还能保持模型的质量。
在调整稀疏型多专家系统(MoEs)时,需要特别关注它们独特的微调超参数配置。比如,这类稀疏模型通常更适合较小的批量大小和较高的学习率。
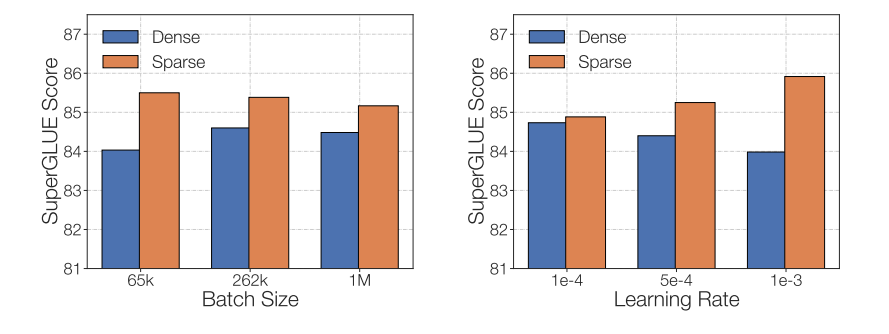
微调后的稀疏模型在采用较低的学习率和较大的批量大小时,其性能会有所提升。此图片来源于 ST-MoE 论文。
新论文MoEs Meets Instruction Tuning展示了一些有趣的实验:
- 单任务微调
- 多任务指令微调
- 在多任务指令微调后进行单任务微调
对比了微调后的 MoE 和 T5 等效模型,发现后者性能更优。但当微调 Flan T5(T5 指令等效模型)MoE 时,MoE 的表现显著提高。不仅如此,Flan-MoE 相比 MoE 的提升幅度,甚至超过了 Flan T5 相比 T5 的提升,这表明 MoEs 可能从指令微调中获益更大,尤其是在任务数量更多的情况下。这与先前建议关闭辅助损失功能的讨论相反,实际上,这种损失可以帮助防止过拟合。
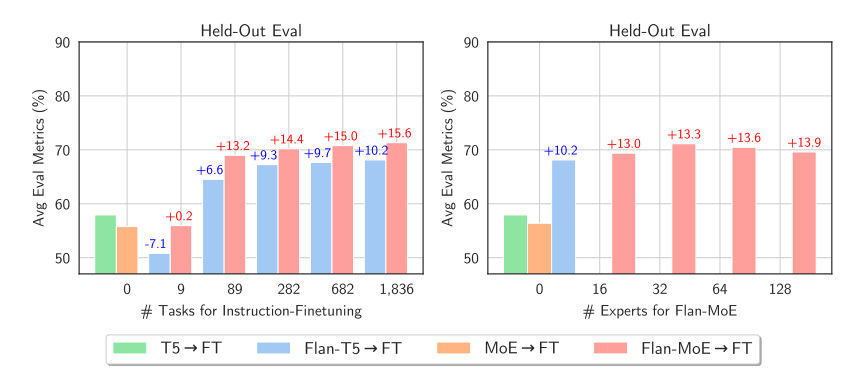
与稠密模型相比,稀疏模型在指令微调方面有更显著的收益。在多机器、高吞吐量的场景中,专家系统是非常有效的。如果预训练的计算预算有限,那么稀疏模型将是更佳的选择。对于 VRAM 较少、吞吐量低的情况,稠密模型则更为合适。
对 Switch Transformers 进行微调以进行内容总结的在线笔记本。
1.4 加速 MoEs 的运行
在最初的多专家系统(MoE)研究中,MoE 层被设计成分支结构,这导致计算速度较慢,因为 GPU 本身并不适合这种设计。同时,由于设备间需要传输信息,网络带宽成为了性能瓶颈。下面将探讨一些方法,以提高这些模型在预训练和推理阶段的实用性,使 MoEs 运行更加高效。
并行处理技术
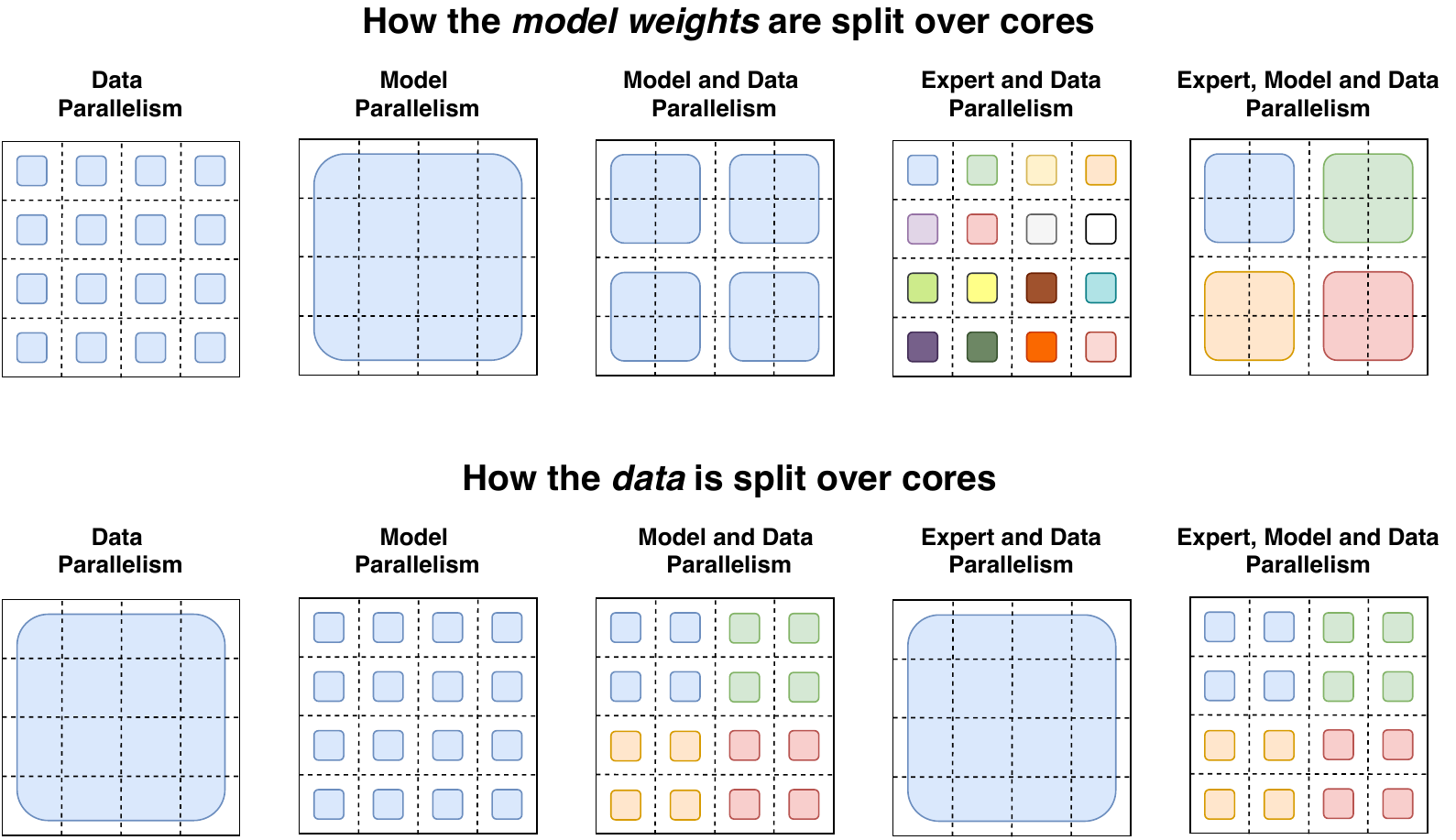
简要介绍一下并行处理技术:
- 数据并行: 相同的权重在所有核心上复制,数据则在核心之间分配。
- 模型并行: 模型在各核心之间分配,数据在所有核心上复制。
- 模型和数据并行: 我们可以在核心间分配模型和数据。需要注意的是,不同核心处理的是不同批次的数据。
- 专家并行: 将不同的专家部署在不同的处理单元上。如果与数据并行结合,每个核心将配备一个不同的专家,数据则在所有核心间分配。
在专家并行模式下,不同的处理单元部署了不同的专家,每个处理单元处理不同批次的训练样本。对于非 MoE 层,专家并行的行为类似于数据并行。对于 MoE 层,序列中的 tokens 被发送到拥有相应专家的处理单元。
容量因子和通信成本
提高容量因子(CF)可以增加模型质量,但同时也会增加通信成本和激活内存的需求。如果全到全的通信速度较慢,那么使用较小的容量因子将是更好的选择。一个较好的初始设置是使用 top-2 路由,1.25 的容量因子,并且每个核心配置一个专家。在评估阶段,可以调整容量因子以减少计算量。
服务技巧
MoE 的一个主要问题是它的参数特别多。如果是在本地环境中使用,可能会更倾向于使用一个体积更小的模型。下面,我们来看看几种有助于优化服务的技巧:
- Switch Transformers 的研究者们早期就做了一些模型蒸馏的实验。通过将 MoE 模型蒸馏成更密集的形式,他们能够保留大约 30-40% 的稀疏性优势。因此,蒸馏不仅加快了模型的预训练速度,还能在实际应用中使用更小的模型。
- 最新的一些方法对路由机制进行了改进,能将整个句子或特定任务直接指派给某个专家,从而提取出适合服务的子网络。
- 专家聚合(MoE)技术:这种方法通过合并不同专家的权重,在推理阶段有效减少了模型的参数数量。
FasterMoE(2022 年 3 月)深入分析了 MoE(专家混合体)在高效分布式系统中的表现。研究不仅探讨了不同并行处理策略的理论极限,还包括了如何倾斜专家的受欢迎程度、减少延迟的精细通信调度,以及一种新型的拓扑感知门控机制。这种机制通过选择延迟最低的专家来进行决策,从而实现了高达 17 倍的速度提升。
Megablocks(2022 年 11 月)致力于探索高效的稀疏预训练技术。他们提出了一种新的 GPU 核心,能够处理 MoE 中的动态性。这一创新方法不会丢失任何 Token,并且能够高效地适应现代硬件,带来了显著的速度提升。那么,它的独特之处在哪里呢?与传统的 MoE 使用批量矩阵乘法不同(这种方法假设所有专家的形状和 Token 数量都一样),Megablocks 则通过块稀疏运算来表达 MoE 层,这使得它能够适应不均匀的任务分配。
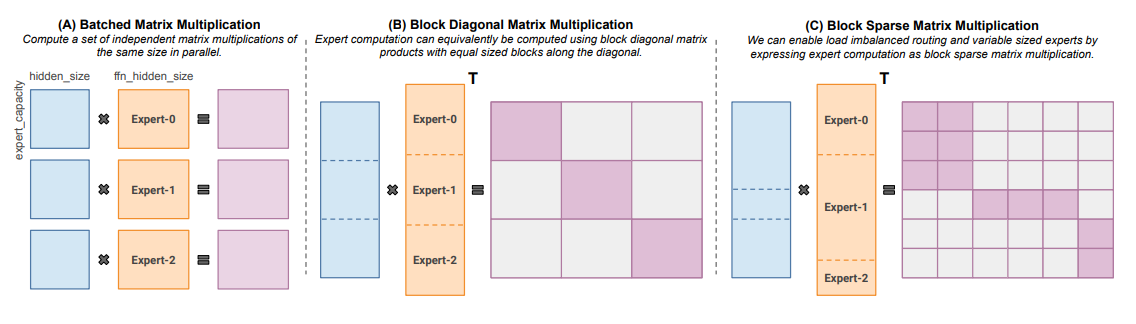
适用于不同大小专家和不同数量 Token 的块稀疏矩阵乘法。