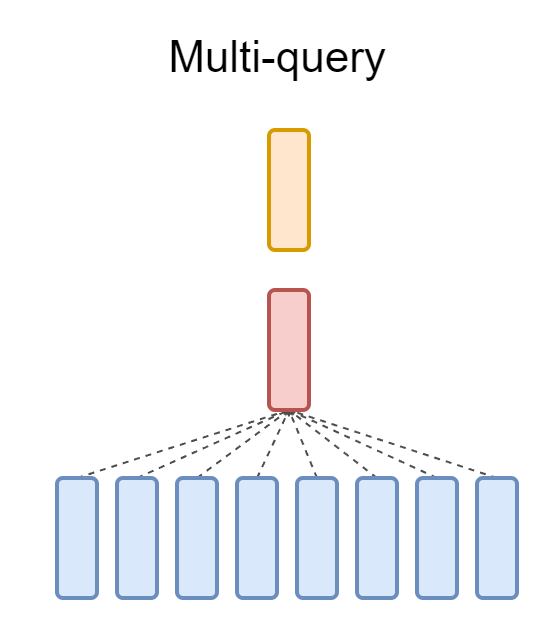
一、Multi-Query
Attention(MQA)
多查询注意力(MQA)是多头注意力(MHA)算法的改进版本,它可以在不牺牲模型精度的情况下提高计算效率。在标准
MHA 中,单独的线性变换应用于每个注意力头的查询 (Q)、键 (K) 和值 (V)。
MQA 与此不同,它在所有头中使用一组共享的键 (K) 和值
(V),同时允许对每个查询 (Q) 进行单独的转换。
Multi-Query Attention代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| class MultiQueryAttention(Attention):
r"""
https://arxiv.org/pdf/1911.02150.pdf
"""
def __init__(self, word_size: int = 512, embed_dim: int = 64, n_query:int=8) -> None:
super().__init__(word_size, embed_dim)
self.n_query = n_query
self.proj = nn.Parameter(torch.empty(embed_dim * n_query, embed_dim))
nn.init.xavier_normal_(self.proj)
delattr(self, 'query')
self.querys = nn.ModuleList([
nn.Linear(in_features=word_size, out_features=embed_dim, bias=True)
for _ in range(n_query)
])
self.key = nn.Linear(in_features=word_size, out_features=embed_dim, bias=True)
self.value = nn.Linear(in_features=word_size, out_features=embed_dim, bias=True)
def forward(self, x: Tensor) -> Tensor:
K = self.key(x)
V = self.value(x)
Z_s = torch.cat([
self.self_attention(query(x), K, V) for query in self.querys
], dim=1)
Z = torch.matmul(Z_s, self.proj)
return Z
|
二、Grouped-Query Attention
(GQA)
从多头模型生成多查询模型分为两个步骤:首先,转换检查点,其次,进行额外的预训练以使模型适应其新结构。下图展示了将多头检查点转换为多查询检查点的过程。K和V头的投影矩阵均值合并为单个投影矩阵,比选择单个键和值头或从头开始随机初始化新的键和值头效果更好。
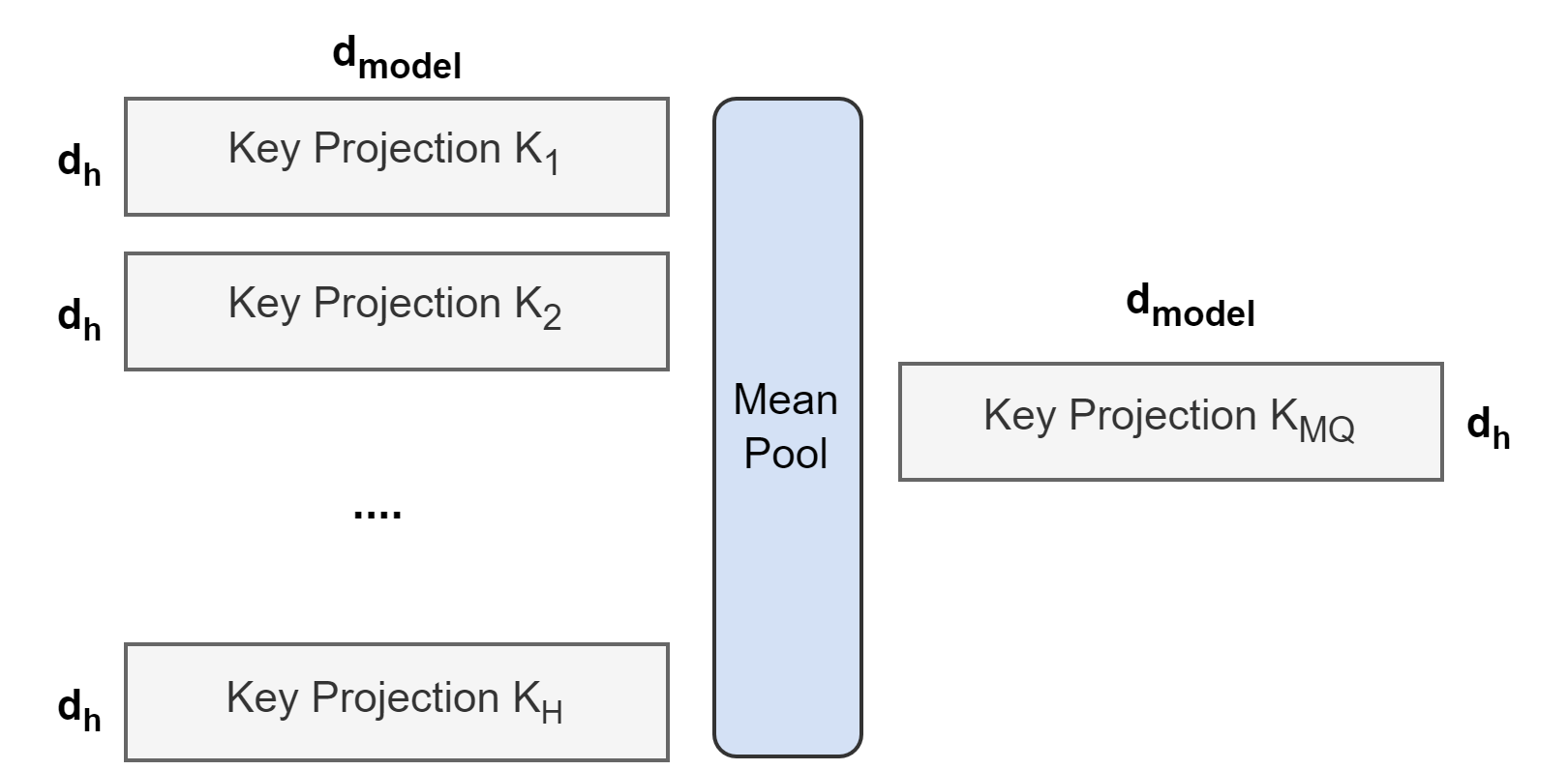
然后,转换后的检查点将在相同的预训练配方上对其原始训练步骤的一小部分进行预训练。
Grouped-query attention
多头注意力有 H
个Q头、K头和V头。GQA在所有Q头中共享单个K和V头。相反,分组查询注意力为每组查询头共享单个K和V头,在多头和多查询注意力之间进行插值。
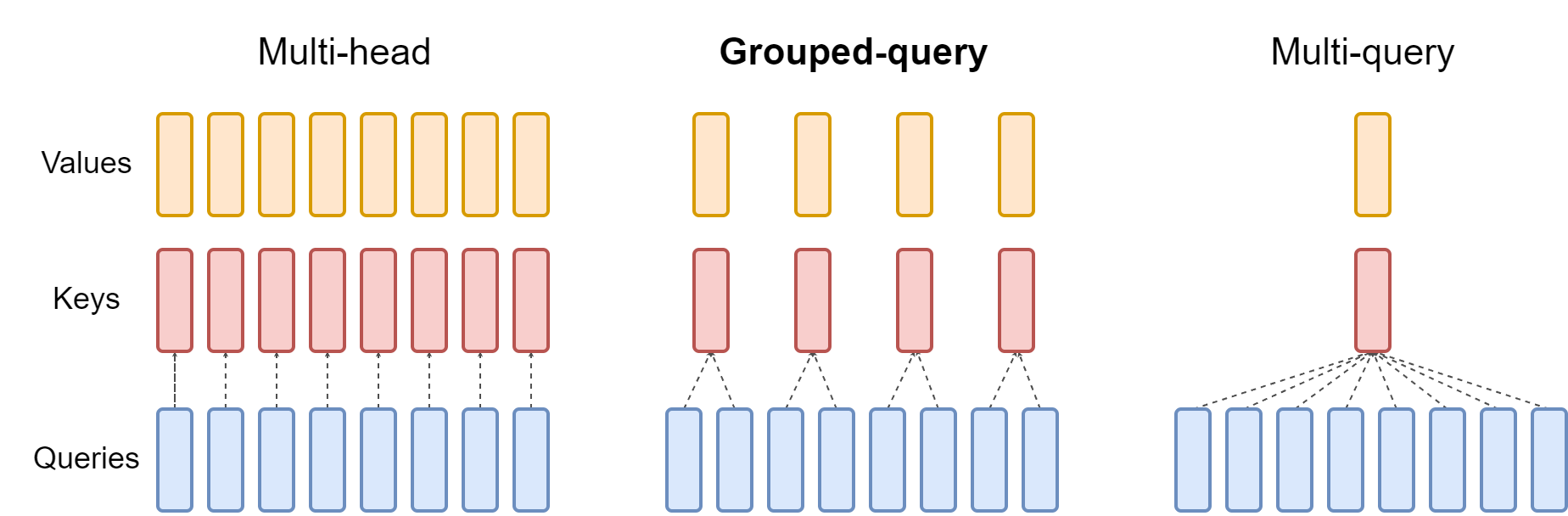
分组查询注意力将查询头分为组,每个组共享一个K头和V头。 GQA-g
指的是带有组的分组查询。
GQA-具有单个组,因此具有单个K和V头,相当于
MQA,而 GQA-h 具有等于头数的组,相当于
MHA。上图显示了分组查询注意力和多头/多查询注意力的比较。当将多头检查点转换为
GQA
检查点时,通过对该组内的所有原始头进行均值池化来构造每个组K和V头。
Grouped-Query Attention代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| class GroupedQueryAttention(Attention):
r"""
https://arxiv.org/pdf/2305.13245.pdf
"""
def __init__(self, word_size: int = 512, embed_dim: int = 64,
n_grouped: int = 4, n_query_each_group:int=2) -> None:
super().__init__(word_size, embed_dim)
delattr(self, 'query')
delattr(self, 'key')
delattr(self, 'value')
self.grouped = nn.ModuleList([
MultiQueryAttention(word_size, embed_dim, n_query=n_query_each_group)
for _ in range(n_grouped)
])
self.proj = nn.Parameter(torch.empty(embed_dim * n_grouped, embed_dim))
nn.init.xavier_uniform_(self.proj)
def forward(self, x: Tensor) -> Tensor:
Z_s = torch.cat([head(x) for head in self.grouped], dim=1)
Z = torch.matmul(Z_s, self.proj)
return Z
|
三、Sliding Window Attention
(SWA)
3.1 SWA
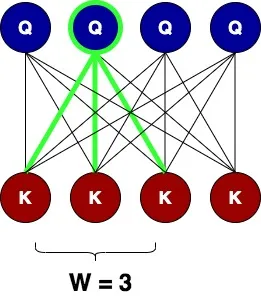
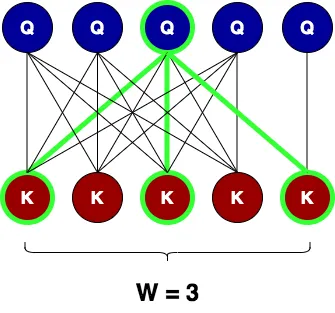
SWA作用是定义一个宽度为 W
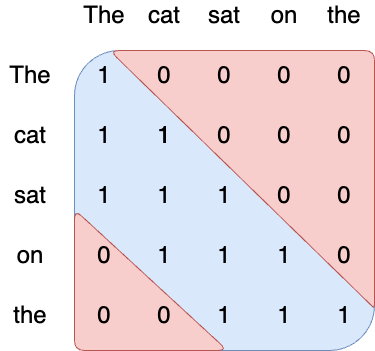
的窗口,这样查询节点就可以只关注关键节点中的对等节点,以及窗口内关键节点的直接邻居。下图显示了大小为
3 的注意力窗口,其中以绿色突出显示的节点 Q
可以关注对等键(中间的那个)及其左侧和右侧的直接邻居(两侧的窗口大小/2)
。他们选择窗口来包含对等键的直接邻居,基于这样的假设:单词最重要的信息是其本地邻居。
内存减少到 ,当 时,这比 好一个数量级。
这个关注窗口会让查询节点丢失来自该窗口之外的关键节点的信息?将多个层堆叠在一起时,最终会发生的情况是,在较高层上,查询节点从远邻居那里获得注意力信息,但以不同的表示方式。就像卷积层对图像的作用一样!下图提供了窗口大小为
3 的两个连续层所发生情况的视觉动画。
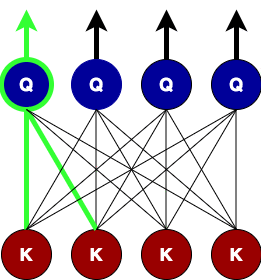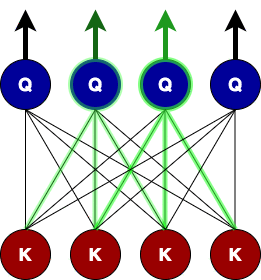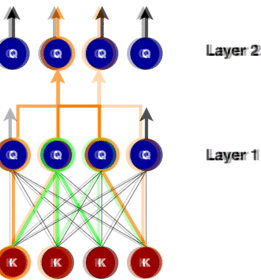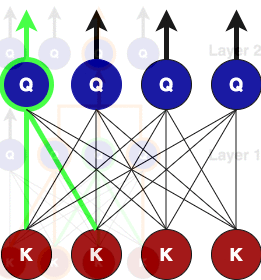
在单个关注层的级别上,查询节点(以绿色突出显示)仅关注其对等节点及其直接邻居。但在第二层,查询关注节点通过关注第一层的查询节点(由橙色路径token)从第二个直接邻居获取信息。因此,最终得到每个token注意力的圆锥形结构,最底层是近邻的局部注意力节点,但在更高层,注意力从远离它的token获取信息(全局注意力)。
3.2 扩大的滑动窗口注意力
对于很长的文档,将需要大量的注意力层来覆盖token之间的长距离全局注意力关系。这将整个注意力块的内存需求提高到
,其中
n:是输入序列长度,w:窗口大小,L:块中注意力层的数量。为了保持滑动窗口的记忆改善,同时保持长距离注意力关系,希望
。这可以通过减少L来改善。
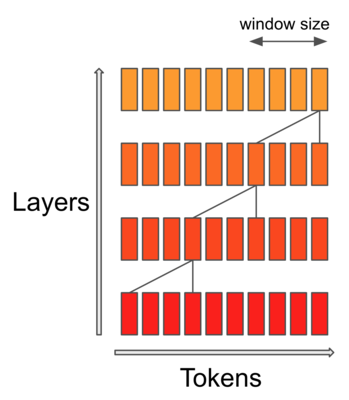
层数与窗口覆盖的邻居相关:每层覆盖的邻居越多,所需的层数就越少。作者提出了使用扩张窗口的想法:不采用
W 个连续邻居,而是采用 W
个交替邻居,如下图。请注意,每层的内存需求仍然是 ,因为节省了注意力仅 W
元素的权重,因此每层不会增加内存。然而,需要更少的层来覆盖更大的序列跨度。
3.3 KV Cache
逐个生成token是一种常见做法,但计算成本可能很高,因为它在每一步都会重复某些计算。为了解决这个问题,KV
缓存就发挥了作用。它涉及缓存以前的键和值,因此不需要为每个新token重新计算它们。这显着减少了计算中使用的矩阵的大小,使矩阵乘法更快。唯一的代价是
KV 缓存需要更多的 GPU 内存(如果不使用 GPU,则需要 CPU
内存)来存储这些状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
| class KVCache:
def __init__(self, max_batch_size, max_seq_len, n_kv_heads, head_dim, device):
self.cache_k = torch.zeros((max_batch_size, max_seq_len, n_kv_heads, head_dim)).to(device)
self.cache_v = torch.zeros((max_batch_size, max_seq_len, n_kv_heads, head_dim)).to(device)
def update(self, batch_size, start_pos, xk, xv):
self.cache_k[:batch_size, start_pos :start_pos + xk.size(1)] = xk
self.cache_v[:batch_size, start_pos :start_pos + xv.size(1)] = xv
def get(self, batch_size, start_pos, seq_len):
keys = self.cache_k[:batch_size, :start_pos + seq_len]
values = self.cache_v[:batch_size, :start_pos + seq_len]
return keys, values
|
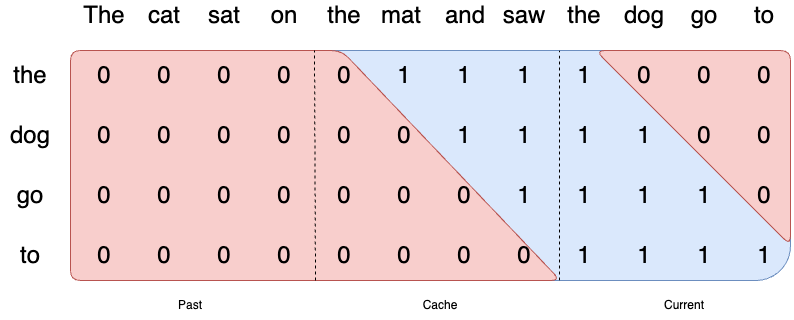
3.4 Rolling buffer cache
由于使用的是滑动窗口注意力(大小为
W),因此不需要将所有先前的token保留在 KV-Cache 中,可以将其限制为最新的
W token。将位置i的(key,
value)存储在缓存位置i%W中。当位置i大于W时,缓存中过去的值将被覆盖。

3.5 Pre-fill and chunking
生成序列时,需要逐一预测token,因为每个token都以前一个token为条件。然而,prompt是预先知道的,可以用prompt预先填充(k,v)缓存。
使用语言模型生成文本时,使用prompt,然后使用之前的token一一生成token。在处理
KV-Cache 时,首先需要将所有prompt令牌添加到 KV-Cache
中,以便可以利用它来生成下一个token。由于prompt是预先知道的,因此可以使用prompt的token来预填充
KV
缓存。如果prompt非常大,可以将其分成更小的块,并用每个块预先填充缓存。为此,可以选择窗口大小作为块大小。因此,对于每个块,需要计算对缓存和块的注意力。
longformer代码
Mistral
AI 7B代码
四、Multi-Head Latent
Attention(MLA)
4.1 Multi-Head Attention
令 为 embedding 维度, 为注意力头数量, 为每个注意力头的维度,
为注意力层中第 个 token
的注意力输入。 标准 MHA 首先通过三个矩阵 分别生成 :
然后, 将被切成 个头,以进行多头注意力计算:
其中 分别表示第 个注意力头的 query、key 和 value;
表示输出投影矩阵。在推理过程中,需要缓存所有 key 和 value
以加速推理,因此 MHA 需要为每个 token 缓存 个元素。
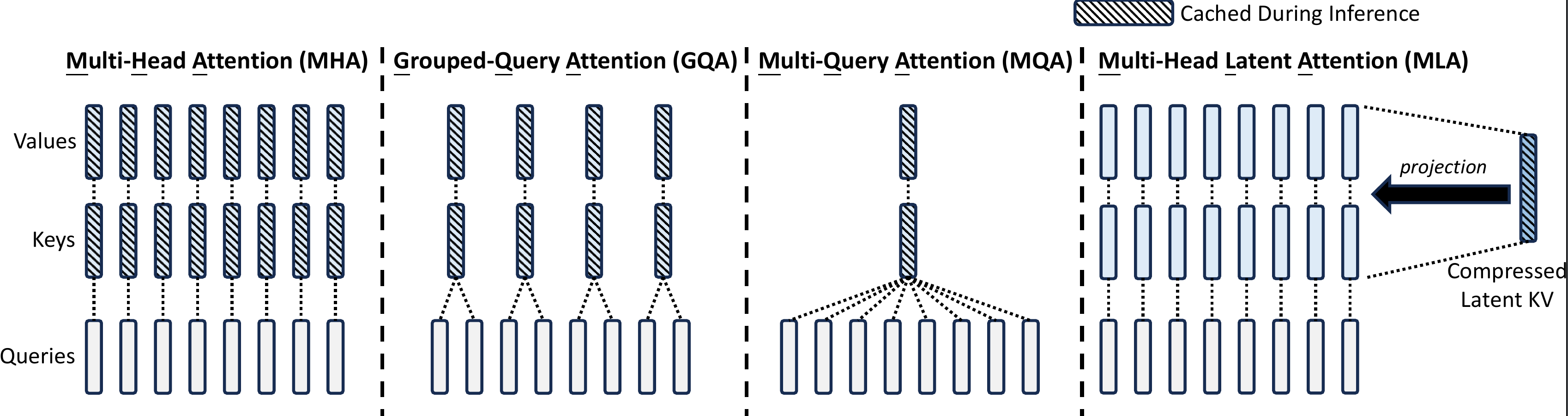 Multi-Head Attention (MHA), Grouped-Query
Attention (GQA), Multi-Query Attention (MQA), and Multi-head Latent
Attention (MLA)对比
Multi-Head Attention (MHA), Grouped-Query
Attention (GQA), Multi-Query Attention (MQA), and Multi-head Latent
Attention (MLA)对比
4.2 MLA 低秩KV联合压缩
MLA从LoRA的成功借鉴经验,实现了比GQA这种通过复制参数压缩矩阵尺度的方法更为节省的低秩推理,同时对模型的效果损耗不大。
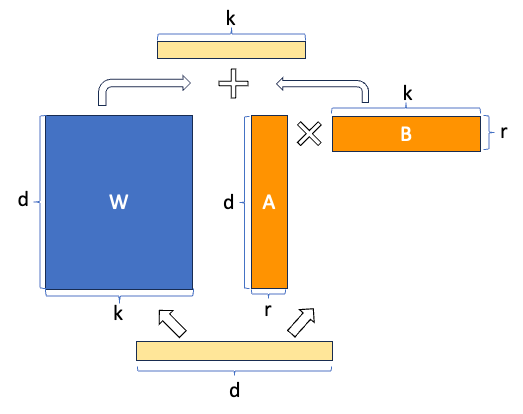 LoRA低秩分解
LoRA低秩分解
MLA的核心是对key和value进行低秩联合压缩,以减少KV缓存:
其中 是压缩后的K和V的latent在向量; 表示 KV 压缩维度;
是向下投影矩阵;而
分别是K和V的向上投影矩阵。在推理过程中,MLA只需要缓存 ,因此其 KV 缓存只有
个元素,其中 表示层数。此外,在推理过程中,由于
可以被吸收到 中,而 可以被吸收到
中,甚至不需要计算出用于注意的K和V。
为了减少训练期间的激活内存,还对查询进行低秩压缩,即使它不能减少 KV
缓存:
其中 是查询的压缩latent向量;
表示查询压缩维度;并且 分别是查询的向下投影和向上投影矩阵。
令,则
这一计算公式和 Multi-Query Attention
其实是一样的,都是使用的单独的和共享的。向量点积的维度是而不是。在论文中实际设置的是 。也就是说 Multi-Head Latent
Attention 其实是 head dimension 提高到4倍的 Multi-Query Attention。
对做了一个低秩分解。
吸收到 中,因此在推理过程中,MLA只需要缓存
,其 KV 缓存只有
个元素,其中 表示层数。
4.3 解耦RoPE(Rotary Position
Embedding)
但是,RoPE 与低秩 KV 压缩不兼容。具体来说,RoPE
对K和Q都是位置敏感的。如果将 RoPE 应用于K ,则公式(2)中的 将与位置敏感的 RoPE
矩阵耦合。这样,在推理过程中, 就不能再被吸收到 中,因为与当前生成的 token 相关的
RoPE 矩阵将位于 和
之间,并且矩阵乘法不遵循交换律。因此,必须在推理过程中重新计算所有前缀
token 的K,这将严重阻碍推理效率。
作为一种解决方案,论文提出了解耦的 RoPE
策略,该策略使用额外的多头查询 和共享密钥 来承载 RoPE,其中
表示解耦查询和密钥的每个头维度。配备解耦的 RoPE 策略后,MLA
执行以下计算:
其中 和
分别是生成解耦查询和密钥的矩阵; 表示应用 RoPE
矩阵的操作;
表示连接操作。在推理过程中,解耦密钥也应被缓存。因此,模型需要一个包含
个元素的总 KV
缓存。
4.4 完整架构
Deepseek-V2 Multi-Head Latent Attention完整公式计算流程:
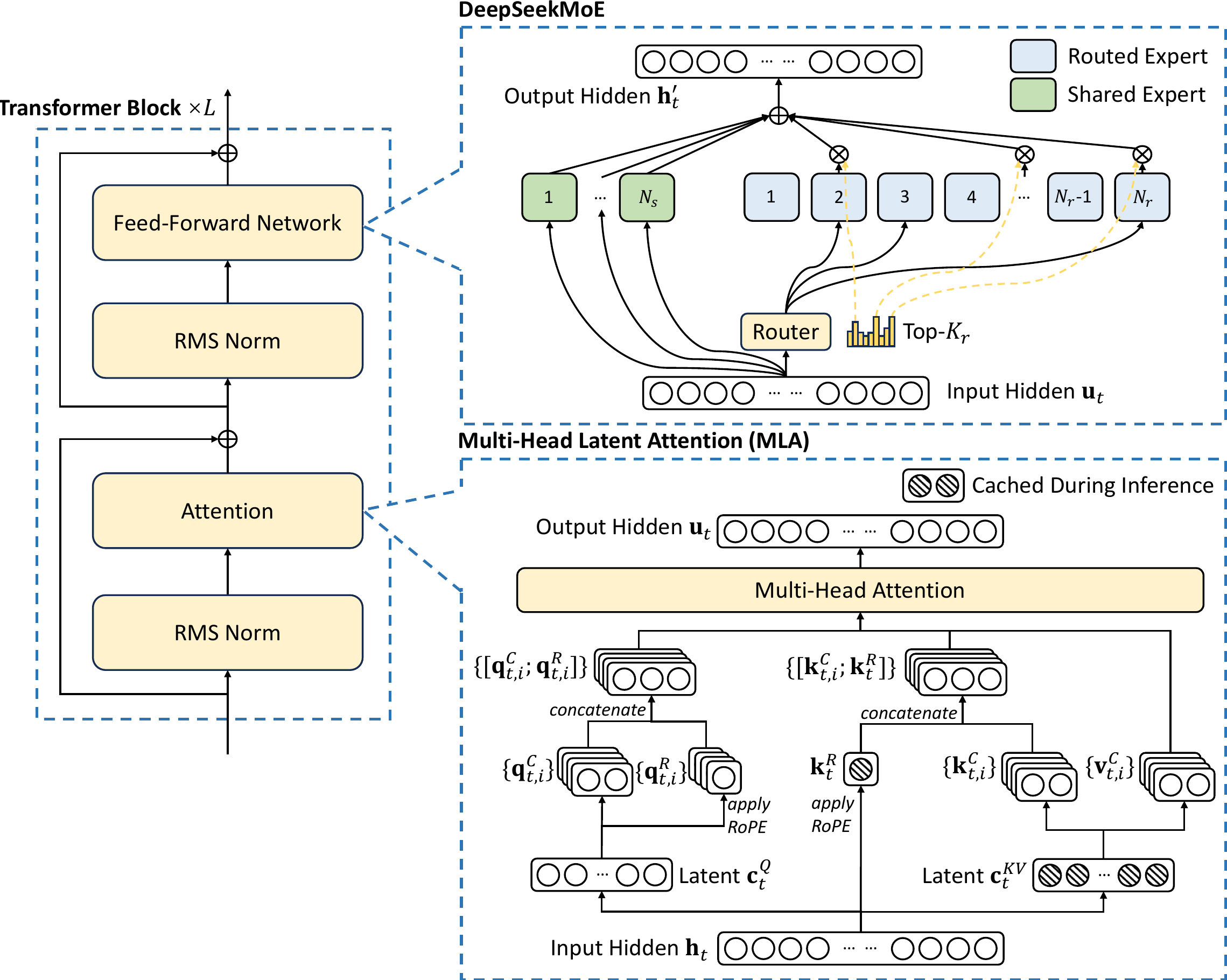 Deepseek-V2架构
Deepseek-V2架构
4.5 代码示例
完整代码
首先结合配置文件中的这几行了解下每个部分的作用:
1
2
3
4
5
6
| "hidden_size": 5120,
"kv_lora_rank": 512,
"moe_intermediate_size": 1536,
"q_lora_rank": 1536,
"qk_nope_head_dim": 128,
"qk_rope_head_dim": 64
|
模型处理上一层计算出的隐藏状态(hidden_size=5120)时,首先会将模型的q压缩到
q_lora_rank这一维度(设定为1536),再扩展到 q_b_proj
的输出维度(num_heads * q_head_dim),最后切分成 q_pe 和 q_nope
两个部分,在训练部分中我们将看到这样设计的作用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
self.q_a_proj = nn.Linear(
self.hidden_size, config.q_lora_rank, bias=config.attention_bias
)
self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)
self.q_b_proj = nn.Linear(
config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False
)
bsz, q_len, _ = hidden_states.size()
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
q_nope, q_pe = torch.split(
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
|
对于kv矩阵的设计,模型使用了kv压缩矩阵设计(只有576维),在训练时进行先降维再升维。在模型推理的时候,需要缓存的量变成
compressed_kv,经过 kv_b_proj 升高维度得到 k,v 的计算结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
self.kv_a_proj_with_mqa = nn.Linear(
self.hidden_size,
config.kv_lora_rank + config.qk_rope_head_dim,
bias=config.attention_bias,
)
self.kv_a_layernorm = DeepseekV2RMSNorm(config.kv_lora_rank)
self.kv_b_proj = nn.Linear(
config.kv_lora_rank,
self.num_heads
* (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),
bias=False,
)
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
compressed_kv, k_pe = torch.split(
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
)
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
kv = (
self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
.transpose(1, 2)
)
|
Deepseek-V2要把整个计算流程拆成 q_nope, k_nope, k_pe, k_nope
这四个部分。Deepseek-V2设计了两个pe结尾的变量用于储存旋转位置编码的信息,将信息存储和旋转编码解耦合开。之后,将q,k中负责储存信息的部分,负责旋转编码的部分拼接起来,进行标准的attention计算:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| k_nope, value_states = torch.split(
kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1
)
kv_seq_len = value_states.shape[-2]
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
if past_key_value is not None:
cache_kwargs = {"sin": sin, "cos": cos}
key_states, value_states = past_key_value.update(
key_states, value_states, self.layer_idx, cache_kwargs
)
attn_weights = (
torch.matmul(query_states, key_states.transpose(2, 3)) * self.softmax_scale
)
attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.num_heads * self.v_head_dim)
attn_output = self.o_proj(attn_output)
|
参考
- GQA: Training Generalized
Multi-Query Transformer Models from Multi-Head Checkpoints
- Grouped
Query Attention (GQA) explained with code
- Group
Query Attention (GQA) 机制详解以及手动实现计算
- The
Large Language Model Playbook
- Mistral
AI 7B v0.1模型的参考实现
- Longformer: The
Long-Document Transformer
- Sliding
Window Attention
- Understanding
LongFormer’s Sliding Window Attention Mechanism
- Mistral SWA(Sliding
window attention)的一些理解
- Generating Long Sequences
with Sparse Transformers
- DeepSeek-V2: A Strong,
Economical, and Efficient Mixture-of-Experts Language Model
- 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA
- Deepseek-V2技术报告解读!全网最细!
- 关于 MHLA(Multi-Head Latent
Attention)的一些分析