# Sort the list based on the URLs and get the text d_sorted = sorted(docs, key=lambda x: x.metadata["source"]) d_reversed = list(reversed(d_sorted)) concatenated_content = "\n\n\n --- \n\n\n".join( [doc.page_content for doc in d_reversed] )
from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field
### OpenAI
# Grader prompt code_gen_prompt = ChatPromptTemplate.from_messages( [("system","""You are a coding assistant with expertise in LCEL, LangChain expression language. \n Here is a full set of LCEL documentation: \n ------- \n {context} \n ------- \n Answer the user question based on the above provided documentation. Ensure any code you provide can be executed \n with all required imports and variables defined. Structure your answer with a description of the code solution. \n Then list the imports. And finally list the functioning code block. Here is the user question:"""), ("placeholder", "{messages}")] )
# Data model classcode(BaseModel): """Code output"""
prefix: str = Field(description="Description of the problem and approach") imports: str = Field(description="Code block import statements") code: str = Field(description="Code block not including import statements") description = "Schema for code solutions to questions about LCEL."
expt_llm = "gpt-4-turbo" llm = ChatOpenAI(temperature=0, model=expt_llm) code_gen_chain = code_gen_prompt | llm.with_structured_output(code) question = "How do I build a RAG chain in LCEL?" # solution = code_gen_chain_oai.invoke({"context":concatenated_content,"messages":[("user",question)]})
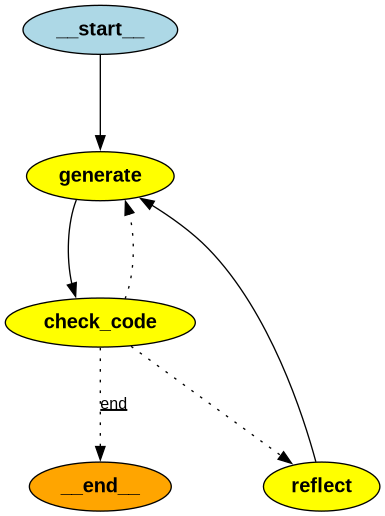
Graph State
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
from typing importDict, TypedDict, List
classGraphState(TypedDict): """ Represents the state of our graph.
Attributes: error : Binary flag for control flow to indicate whether test error was tripped messages : With user question, error messages, reasoning generation : Code solution iterations : Number of tries """
error : str messages : List generation : str iterations : int
from operator import itemgetter from langchain.prompts import PromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field from langchain_core.runnables import RunnablePassthrough
### Parameter
# Max tries max_iterations = 3 # Reflect # flag = 'reflect' flag = 'do not reflect'
### Nodes
defgenerate(state: GraphState): """ Generate a code solution
Args: state (dict): The current graph state
Returns: state (dict): New key added to state, generation """
# We have been routed back to generation with an error if error == "yes": messages += [("user","Now, try again. Invoke the code tool to structure the output with a prefix, imports, and code block:")]
# Prompt reflection reflection_message = [("user", """You tried to solve this problem and failed a unit test. Reflect on this failure given the provided documentation. Write a few key suggestions based on the documentation to avoid making this mistake again.""")]
# Add reflection reflections = code_gen_chain.invoke({"context" : concatenated_content, "messages" : messages}) messages += [("assistant" , f"Here are reflections on the error: {reflections}")] return {"generation": code_solution, "messages": messages, "iterations": iterations}
### Edges
defdecide_to_finish(state: GraphState): """ Determines whether to finish.
Args: state (dict): The current graph state
Returns: str: Next node to call """ error = state["error"] iterations = state["iterations"]
if error == "no"or iterations == max_iterations: print("---DECISION: FINISH---") return"end" else: print("---DECISION: RE-TRY SOLUTION---") if flag == 'reflect': return"reflect" else: return"generate"
question = "How can I directly pass a string to a runnable and use it to construct the input needed for my prompt?" app.invoke({"messages":[("user",question)],"iterations":0})
输出
1 2 3 4 5 6 7 8 9 10 11 12
---GENERATING CODE SOLUTION--- ---CHECKING CODE--- messages=[HumanMessage(content='Process this input: Hello, this is a direct string input!')] ---NO CODE TEST FAILURES--- ---DECISION: FINISH--- {'error': 'no', 'messages': [('user', 'How can I directly pass a string to a runnable and use it to construct the input needed for my prompt?'), ('assistant', 'Directly passing a string to a runnable for constructing input for a prompt in LCEL \n Imports: from langchain_core.runnables import RunnableLambda\nfrom langchain_core.prompts import ChatPromptTemplate \n Code: # Define the prompt template\nprompt = ChatPromptTemplate.from_template("Process this input: {input}")\n\n# Define a runnable that constructs the input for the prompt\nconstruct_input = RunnableLambda(lambda x: {\'input\': x})\n\n# Chain the input constructor with the prompt\nchain = construct_input | prompt\n\n# Example usage\nresult = chain.invoke(\'Hello, this is a direct string input!\')\nprint(result)')], 'generation': code(prefix='Directly passing a string to a runnable for constructing input for a prompt in LCEL', imports='from langchain_core.runnables import RunnableLambda\nfrom langchain_core.prompts import ChatPromptTemplate', code='# Define the prompt template\nprompt = ChatPromptTemplate.from_template("Process this input: {input}")\n\n# Define a runnable that constructs the input for the prompt\nconstruct_input = RunnableLambda(lambda x: {\'input\': x})\n\n# Chain the input constructor with the prompt\nchain = construct_input | prompt\n\n# Example usage\nresult = chain.invoke(\'Hello, this is a direct string input!\')\nprint(result)', description='Schema for code solutions to questions about LCEL.'), 'iterations': 1}
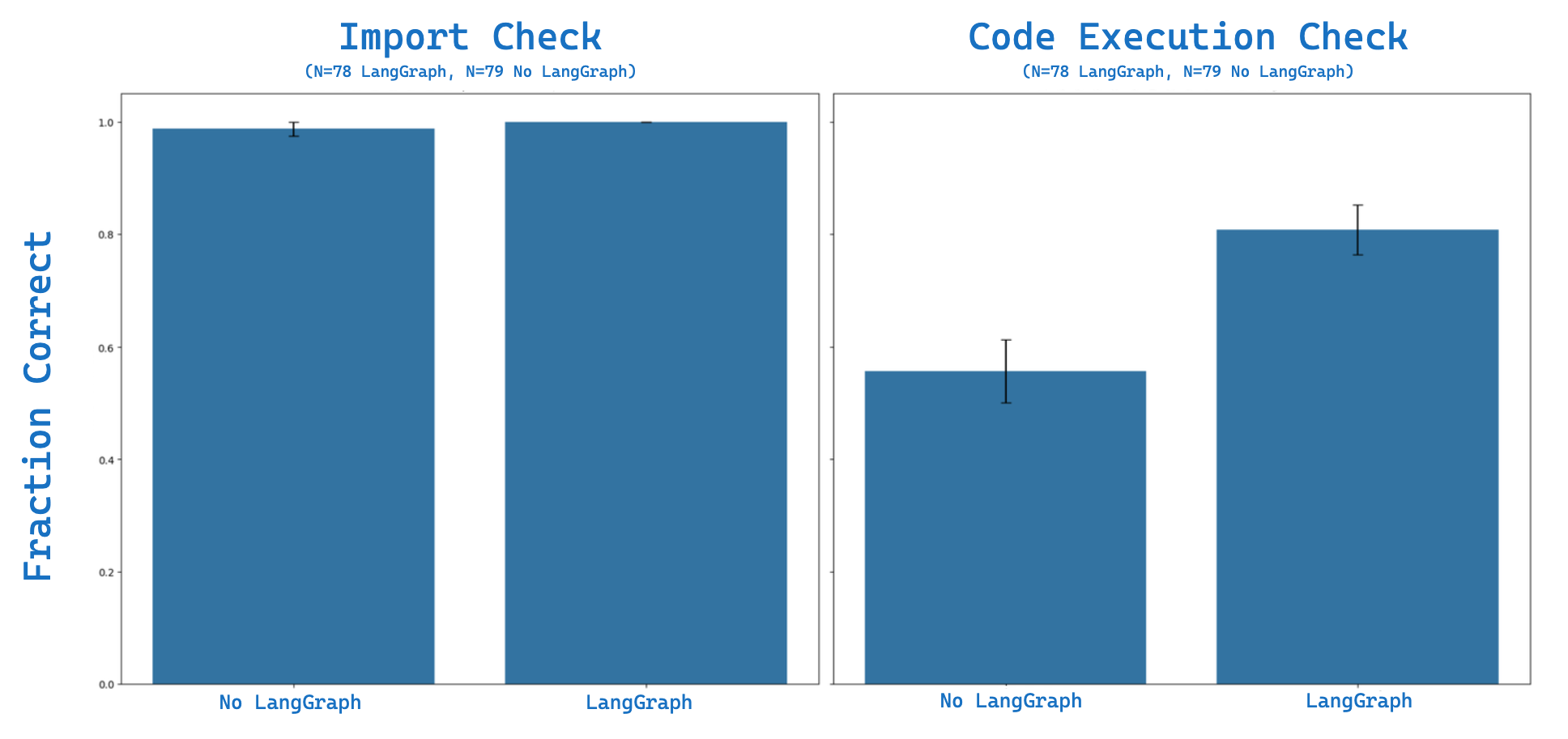
使用20个问题的评估集对上下文填充进行了四次评估,评估结果。在上下文填充中,大约98%的导入测试是正确的,而大约55%的代码执行测试是正确的(N=79次成功的试验)。使用LangSmith来查看失败案例:这里有一个例子,它没有意识到RunnableLambda函数的输入将是一个字典,并错误地认为它是一个字符串:AttributeError: 'dict' object has no attribute 'upper'。
You previously tried to solve this problem. ... --- Most recent run error --- Execution error: 'dict' object has no attribute 'upper' ... Please re-try to answer this. ...
# Clone the dataset to your tenant to use it public_dataset = ("https://smith.langchain.com/public/326674a6-62bd-462d-88ae-eea49d503f9d/d") client.clone_public_dataset(public_dataset)