from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import Chroma from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field
# Data model classGradeDocuments(BaseModel): """Binary score for relevance check on retrieved documents."""
binary_score: str = Field(description="Documents are relevant to the question, 'yes' or 'no'")
# LLM with function call llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0) structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt system = """You are a grader assessing relevance of a retrieved document to a user question. \n If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \n Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.""" grade_prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "Retrieved document: \n\n {document} \n\n User question: {question}"), ] )
# Prompt system = """You a question re-writer that converts an input question to a better version that is optimized \n for web search. Look at the input and try to reason about the underlying sematic intent / meaning.""" re_write_prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "Here is the initial question: \n\n {question} \n Formulate an improved question."), ] )
# Web search docs = web_search_tool.invoke({"query": question}) web_results = "\n".join([d["content"] for d in docs]) web_results = Document(page_content=web_results) documents.append(web_results)
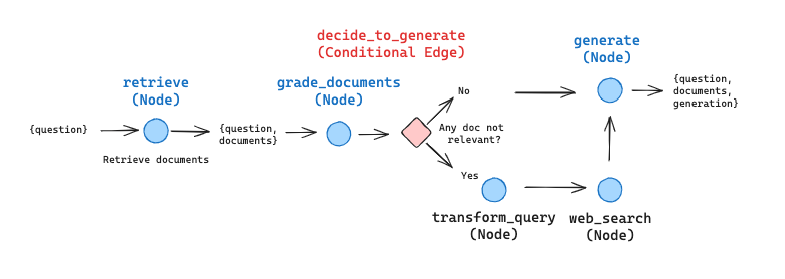
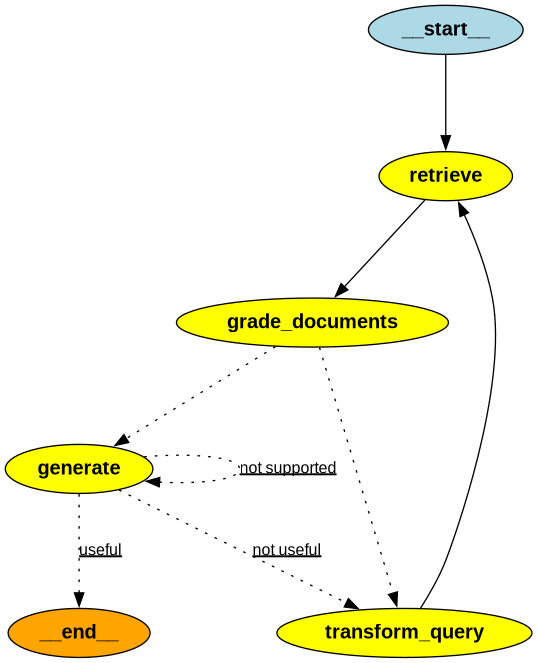
if web_search == "Yes": # All documents have been filtered check_relevance # We will re-generate a new query print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---") return"transform_query" else: # We have relevant documents, so generate answer print("---DECISION: GENERATE---") return"generate"
# Run inputs = {"question": "What are the types of agent memory?"} for output in app.stream(inputs): for key, value in output.items(): # Node pprint(f"Node '{key}':") # Optional: print full state at each node # pprint.pprint(value["keys"], indent=2, width=80, depth=None) pprint("\n---\n")
---RETRIEVE--- "Node 'retrieve':" '\n---\n' ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY--- "Node 'grade_documents':" '\n---\n' ---TRANSFORM QUERY--- "Node 'transform_query':" '\n---\n' ---WEB SEARCH--- "Node 'web_search_node':" '\n---\n' ---GENERATE--- "Node 'generate':" '\n---\n' ('The different categories of memory in agents are short-term memory and ' 'long-term memory. Short-term memory is used for in-context learning, while ' 'long-term memory allows agents to retain and recall information over ' 'extended periods by leveraging external storage. Agents can also utilize ' 'tool use, such as calling external APIs for additional information.')
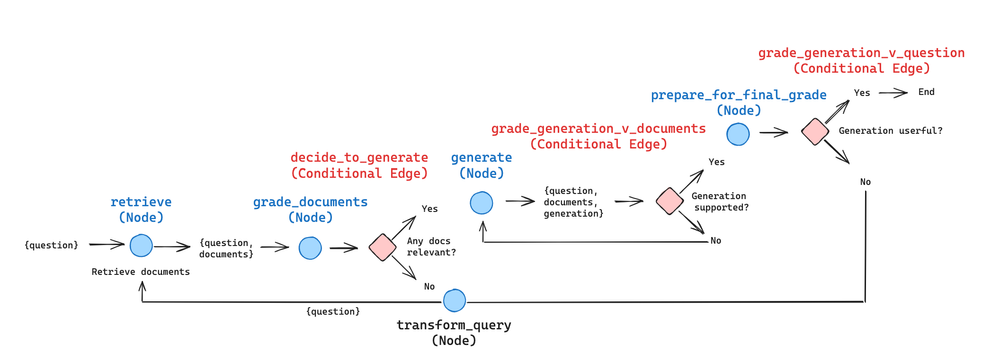
LangSmith流程展示:
提问无关问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from pprint import pprint
# Run inputs = {"question": "How does the AlphaCodium paper work?"} for output in app.stream(inputs): for key, value in output.items(): # Node pprint(f"Node '{key}':") # Optional: print full state at each node # pprint.pprint(value["keys"], indent=2, width=80, depth=None) pprint("\n---\n")
---RETRIEVE--- "Node 'retrieve':" '\n---\n' ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY--- "Node 'grade_documents':" '\n---\n' ---TRANSFORM QUERY--- "Node 'transform_query':" '\n---\n' ---WEB SEARCH--- "Node 'web_search_node':" '\n---\n' ---GENERATE--- "Node 'generate':" '\n---\n' ('The AlphaCodium paper functions by reasoning about problems in natural ' 'language during a pre-processing phase and generating, running, and fixing ' 'code solutions in an iterative phase. It improves the performance of Large ' 'Language Models on code generation tasks by using a test-based, multi-stage, ' 'code-oriented iterative flow. The key mechanisms involve reasoning about ' 'problems in natural language, generating code solutions, and running and ' 'fixing the solutions against public and AI-generated tests.')
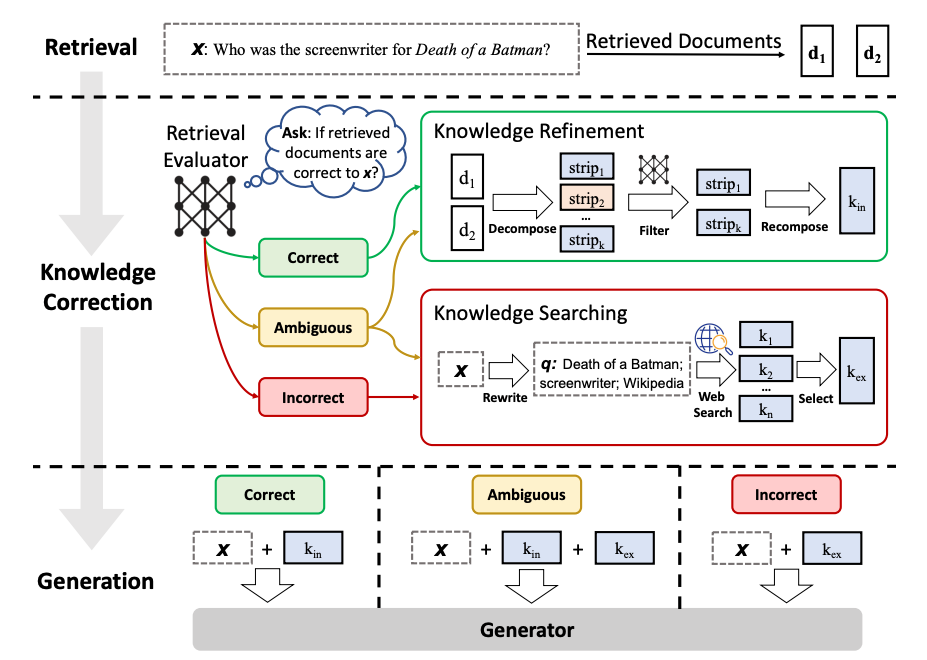
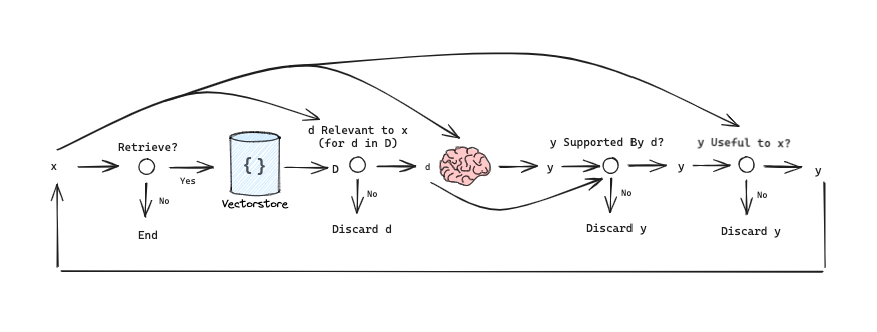
由Retrieve
token来决定使用x (question)或者x (question),y (generation)来检索
D chunks,输出是yes, no,
continue。
ISRAEL token 通过循环 input (x (question),
d (chunk)) for d in D 来判断
D 是否与 x 相关,
。输出是relevant, irrelevant。
ISSUP token 决定 D 中每个 chunk
的LLM生成是否与该 chunk 相关。输入是
x,d,y for d in
D。并确认y (generation)中所有值得验证的陈述都得到了d (chunk)的支持。输出是fully supported,
partially supported, no support。
ISUSE token 决定D
中每个chunk的生成内容对x是否是有用的响应。输入是
x,y for d in
D。输出是{5, 4, 3, 2, 1}。
from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import Chroma from langchain_openai import OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate from langchain_core.pydantic_v1 import BaseModel, Field from langchain_openai import ChatOpenAI
# Data model classGradeDocuments(BaseModel): """Binary score for relevance check on retrieved documents."""
binary_score: str = Field(description="Documents are relevant to the question, 'yes' or 'no'")
# LLM with function call llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0) structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt system = """You are a grader assessing relevance of a retrieved document to a user question. \n It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.""" grade_prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "Retrieved document: \n\n {document} \n\n User question: {question}"), ] )
# Data model classGradeHallucinations(BaseModel): """Binary score for hallucination present in generation answer."""
binary_score: str = Field(description="Answer is grounded in the facts, 'yes' or 'no'")
# LLM with function call llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0) structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# Prompt system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts.""" hallucination_prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"), ] )
# Data model classGradeAnswer(BaseModel): """Binary score to assess answer addresses question."""
binary_score: str = Field(description="Answer addresses the question, 'yes' or 'no'")
# LLM with function call llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0) structured_llm_grader = llm.with_structured_output(GradeAnswer)
# Prompt system = """You are a grader assessing whether an answer addresses / resolves a question \n Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question.""" answer_prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "User question: \n\n {question} \n\n LLM generation: {generation}"), ] )
# Prompt system = """You a question re-writer that converts an input question to a better version that is optimized \n for vectorstore retrieval. Look at the input and try to reason about the underlying sematic intent / meaning.""" re_write_prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "Here is the initial question: \n\n {question} \n Formulate an improved question."), ] )
ifnot filtered_documents: # All documents have been filtered check_relevance # We will re-generate a new query print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---") return"transform_query" else: # We have relevant documents, so generate answer print("---DECISION: GENERATE---") return"generate"
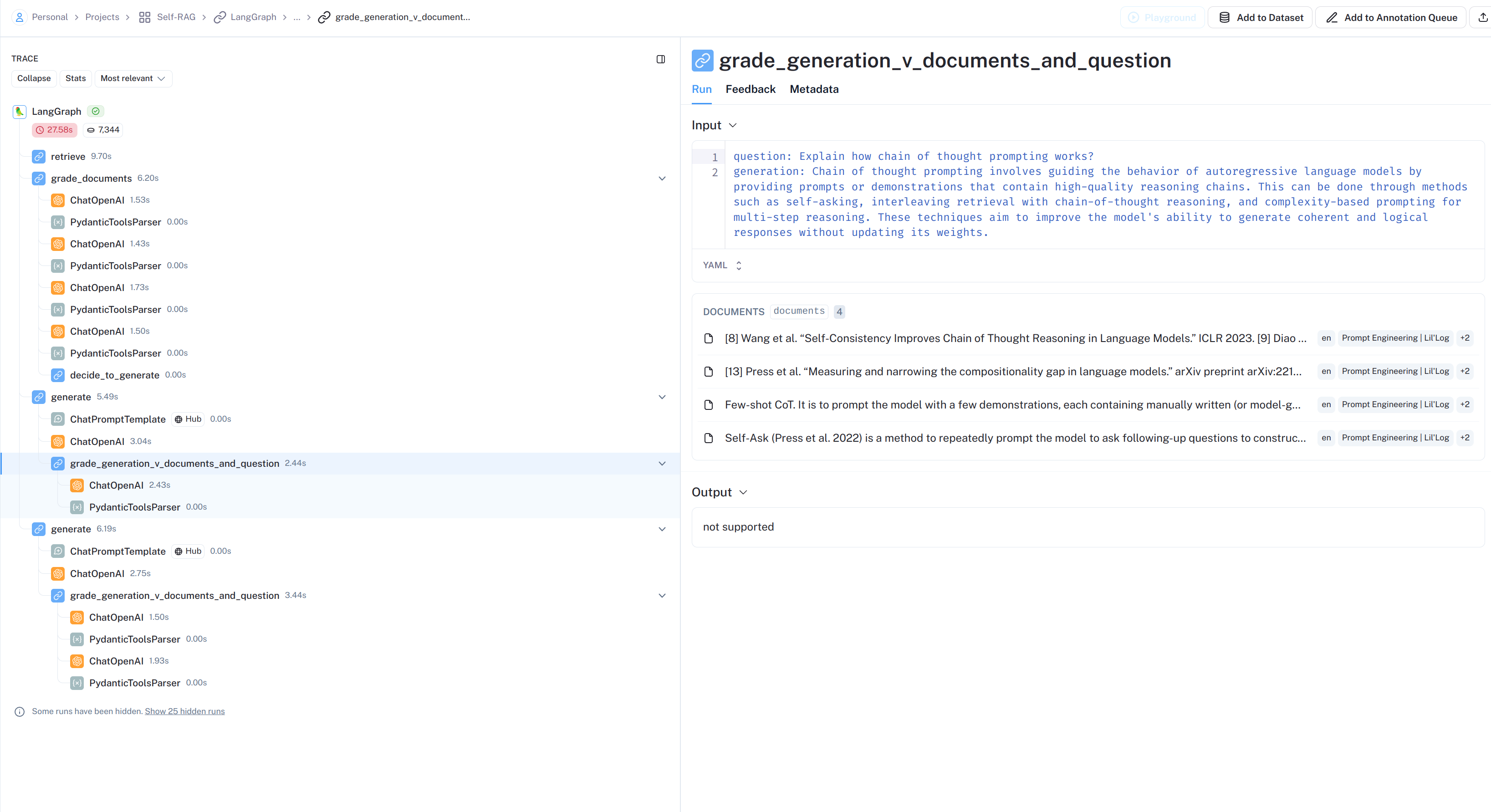
defgrade_generation_v_documents_and_question(state): """ Determines whether the generation is grounded in the document and answers question.
# Run inputs = {"question": "Explain how the different types of agent memory work?"} for output in app.stream(inputs): for key, value in output.items(): # Node pprint(f"Node '{key}':") # Optional: print full state at each node # pprint.pprint(value["keys"], indent=2, width=80, depth=None) pprint("\n---\n")
---RETRIEVE--- "Node 'retrieve':" '\n---\n' ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT NOT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: GENERATE--- "Node 'grade_documents':" '\n---\n' ---GENERATE--- ---CHECK HALLUCINATIONS--- ---DECISION: GENERATION IS GROUNDED IN DOCUMENTS--- ---GRADE GENERATION vs QUESTION--- ---DECISION: GENERATION ADDRESSES QUESTION--- "Node 'generate':" '\n---\n' ('Short-term memory is used for in-context learning and allows the model to ' 'learn new information. It has a limited capacity and lasts for a short ' 'duration. Long-term memory, on the other hand, can store information for a ' 'long time and has unlimited storage capacity. It includes ' 'explicit/declarative memory for facts and events, and implicit/procedural ' 'memory for skills and routines.')
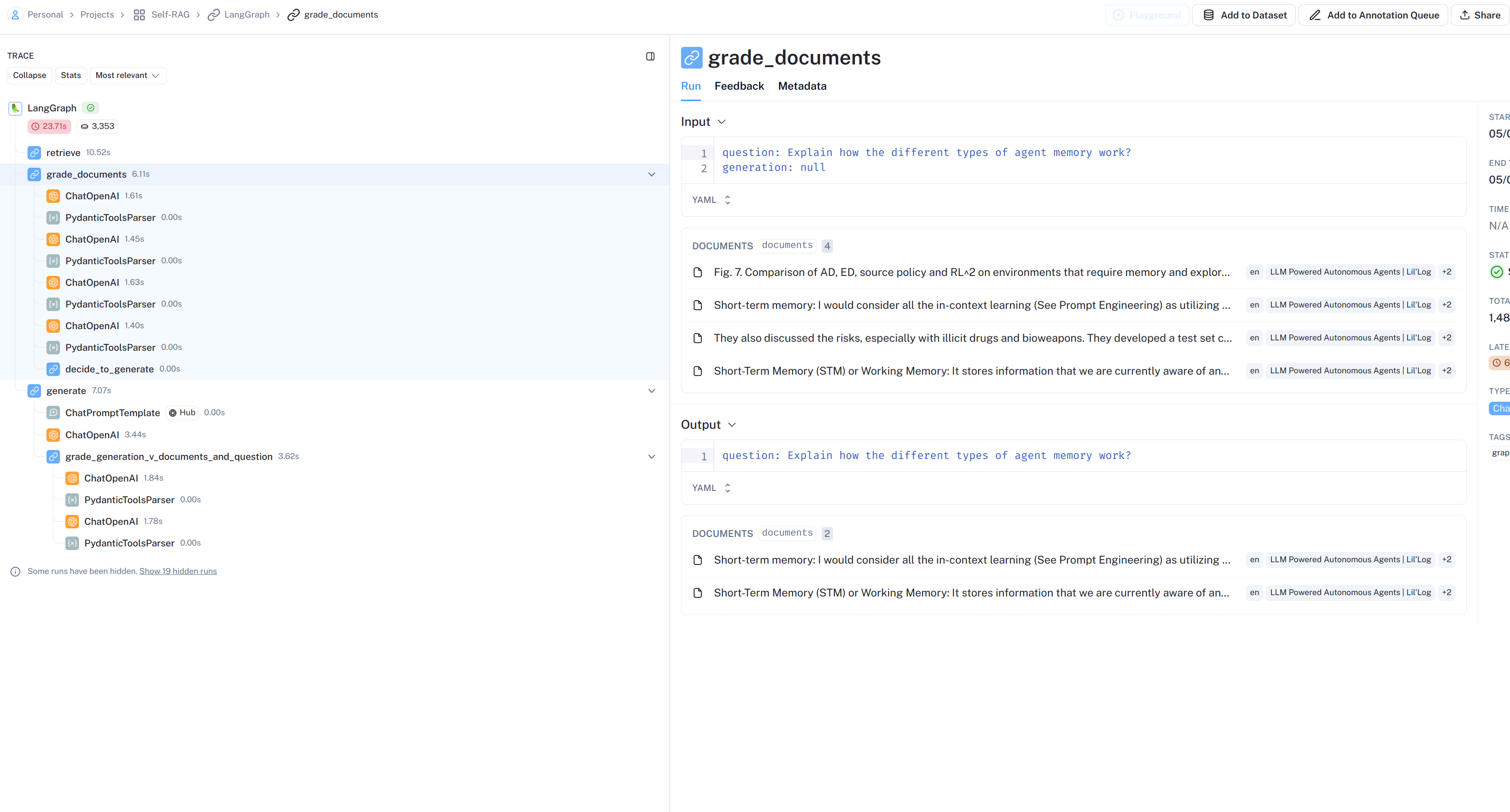
LangSmith流程展示:
上图中有文档过滤
例子2:
1 2 3 4 5 6 7 8 9 10 11
inputs = {"question": "Explain how chain of thought prompting works?"} for output in app.stream(inputs): for key, value in output.items(): # Node pprint(f"Node '{key}':") # Optional: print full state at each node # pprint.pprint(value["keys"], indent=2, width=80, depth=None) pprint("\n---\n")
---RETRIEVE--- "Node 'retrieve':" '\n---\n' ---CHECK DOCUMENT RELEVANCE TO QUESTION--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---GRADE: DOCUMENT RELEVANT--- ---ASSESS GRADED DOCUMENTS--- ---DECISION: GENERATE--- "Node 'grade_documents':" '\n---\n' ---GENERATE--- ---CHECK HALLUCINATIONS--- '---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---' "Node 'generate':" '\n---\n' ---GENERATE--- ---CHECK HALLUCINATIONS--- ---DECISION: GENERATION IS GROUNDED IN DOCUMENTS--- ---GRADE GENERATION vs QUESTION--- ---DECISION: GENERATION ADDRESSES QUESTION--- "Node 'generate':" '\n---\n' ('Chain of thought prompting involves guiding the behavior of autoregressive ' 'language models by providing prompts or demonstrations that contain ' 'high-quality reasoning chains. This can be done through methods such as ' 'self-asking, interleaving retrieval with chain-of-thought reasoning, and ' 'complexity-based prompting for multi-step reasoning. These techniques aim to ' "improve the model's ability to generate coherent and logical responses " 'without updating its weights.')