LangGraph(三)—— Multi-Agent Workflows
一、什么是Multi-Agent
Multi-Agent 指的是由语言模型驱动的多个独立参与者,这些参与者以特定的方式相互连接。其中每个Agent可以拥有自己的prompt, LLM, tools和其他自定义代码,以便能更好的与其他Agent协作。
因此在 Multi-Agent Workflows中有两个主要问题:
- 多个独立的Agent分别是什么
- 这些Agent如何连接
在LangGraph中每个Agent都是一个Node,它们之间的连接被称为Edge,控制流程由条件Edge来管理,它们之间通过添加到图的状态来进行通信。LangGraph中有一个状态机的概念,每个独立的Agent节点都有状态,而Agent之间的连接则相当于转移矩阵。由于状态机本质上也是一个有向图,LangGraph的graph表示方法与状态机的概念相辅相成,使得开发者能够以graph的方式设计和实现复杂的多代理系统。
1.1 Multi-Agent 的好处
对工具/职责进行分组:可以提供更好的结果。与必须从数十种工具中进行选择,相比一个Agent在专注于一个任务时更有可能成功。
单独的Prompt:可以提供更好的结果。每个prompt可以有自己的指令和少量示例。每个Agent甚至可以由单独经过微调的大型语言模型(LLM)驱动
有助于开发概念模型:你可以单独评估和改进每个Agent,而不会破坏更大的应用。
Multi-agent设计允许你将复杂的问题划分为可由专门的Agent和大型语言模型(LLM)程序解决的可行工作单元。
二、Multi-Agent 例子
2.1 Agent Supervisor
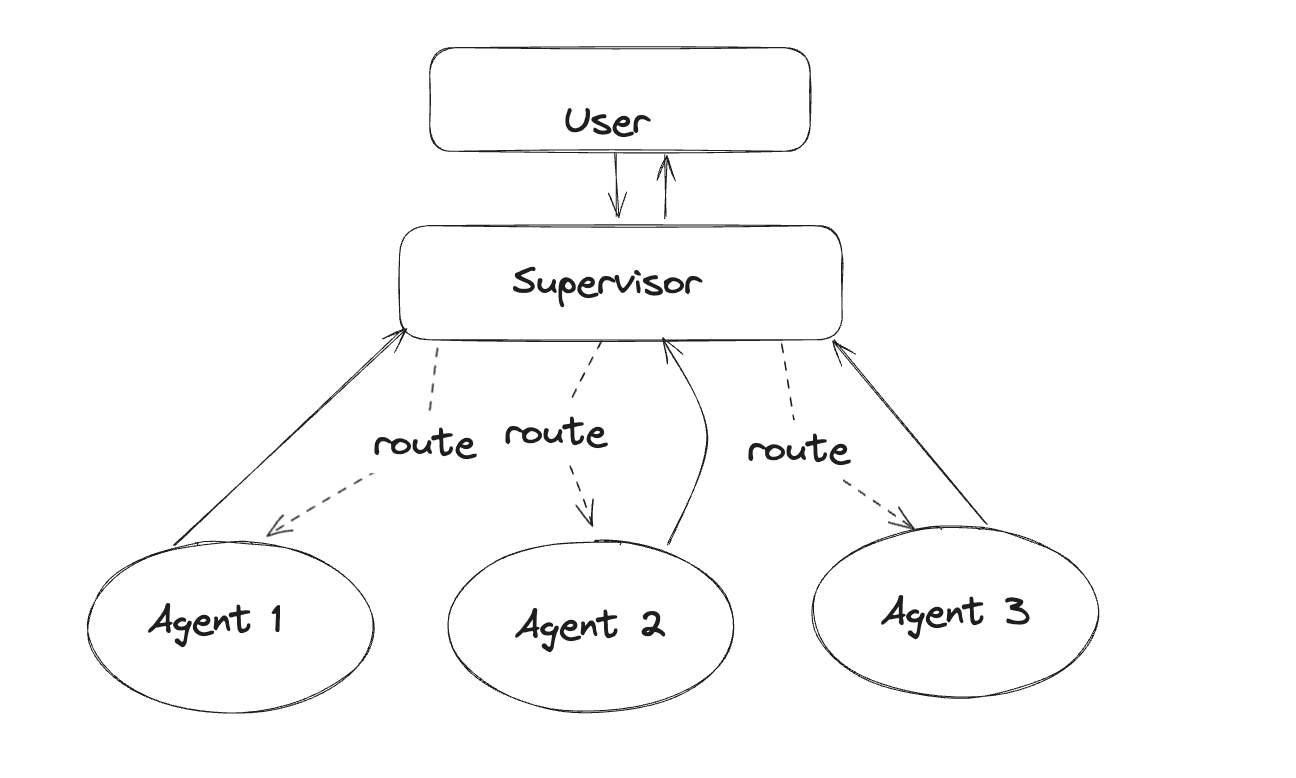
如图Agent Supervisor负责将任务路由到各个独立Agent。而每个独立Agent都是一个LangChain Agent,它们有自己的prompt、LLM和Tools,调用每个独立Agent时不仅仅是一次LLM调用,而是一次AgentExecutor 的运行。
Supervisor也可以被认为是一个Agent,它的Tools是其他Agent.
Tools
1 | |
Utilites
1 | |
Agent Supervisor
1 | |
Graph
1 | |
展示Graph
1 | |
执行
1 | |
输出
1 | |
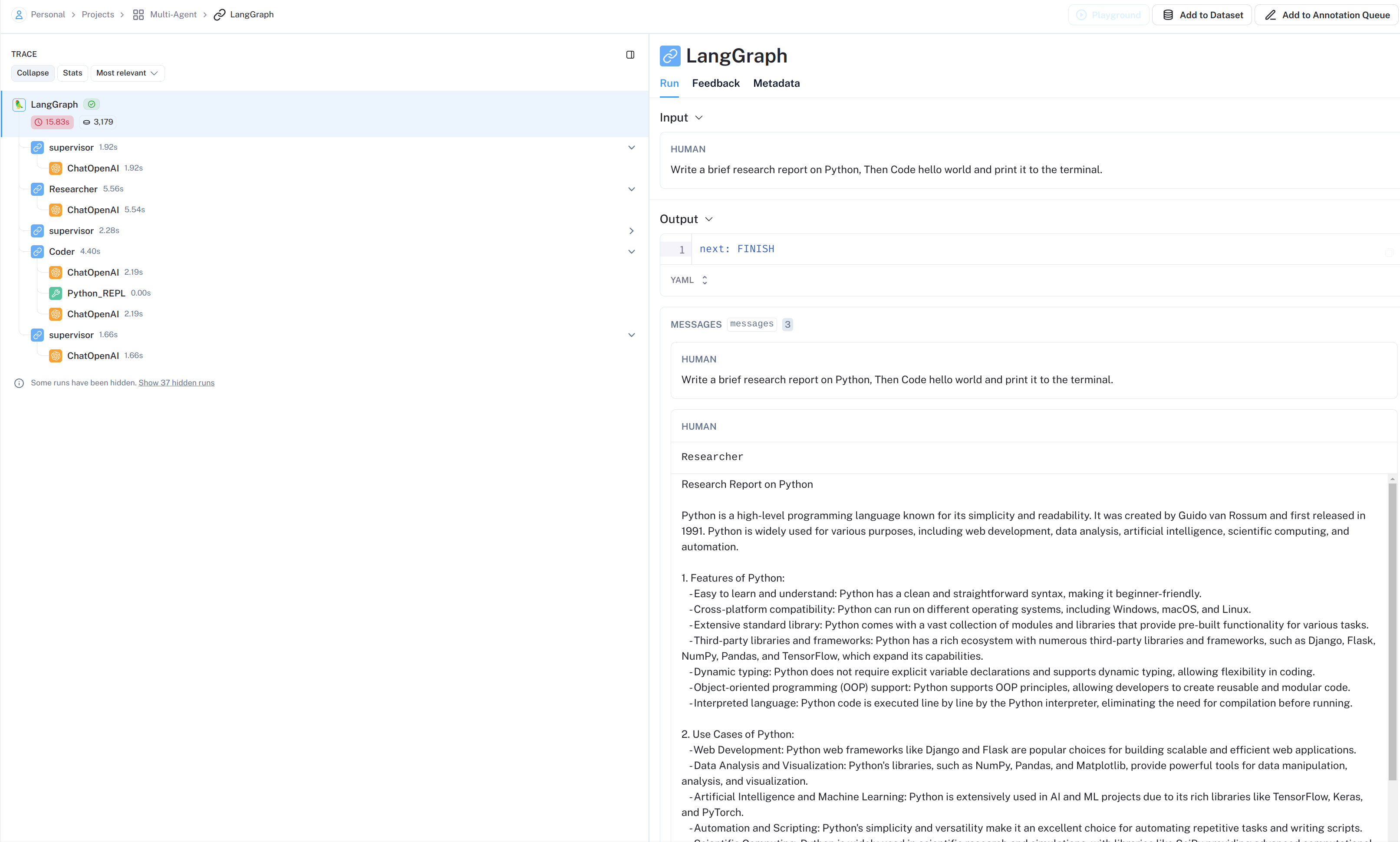
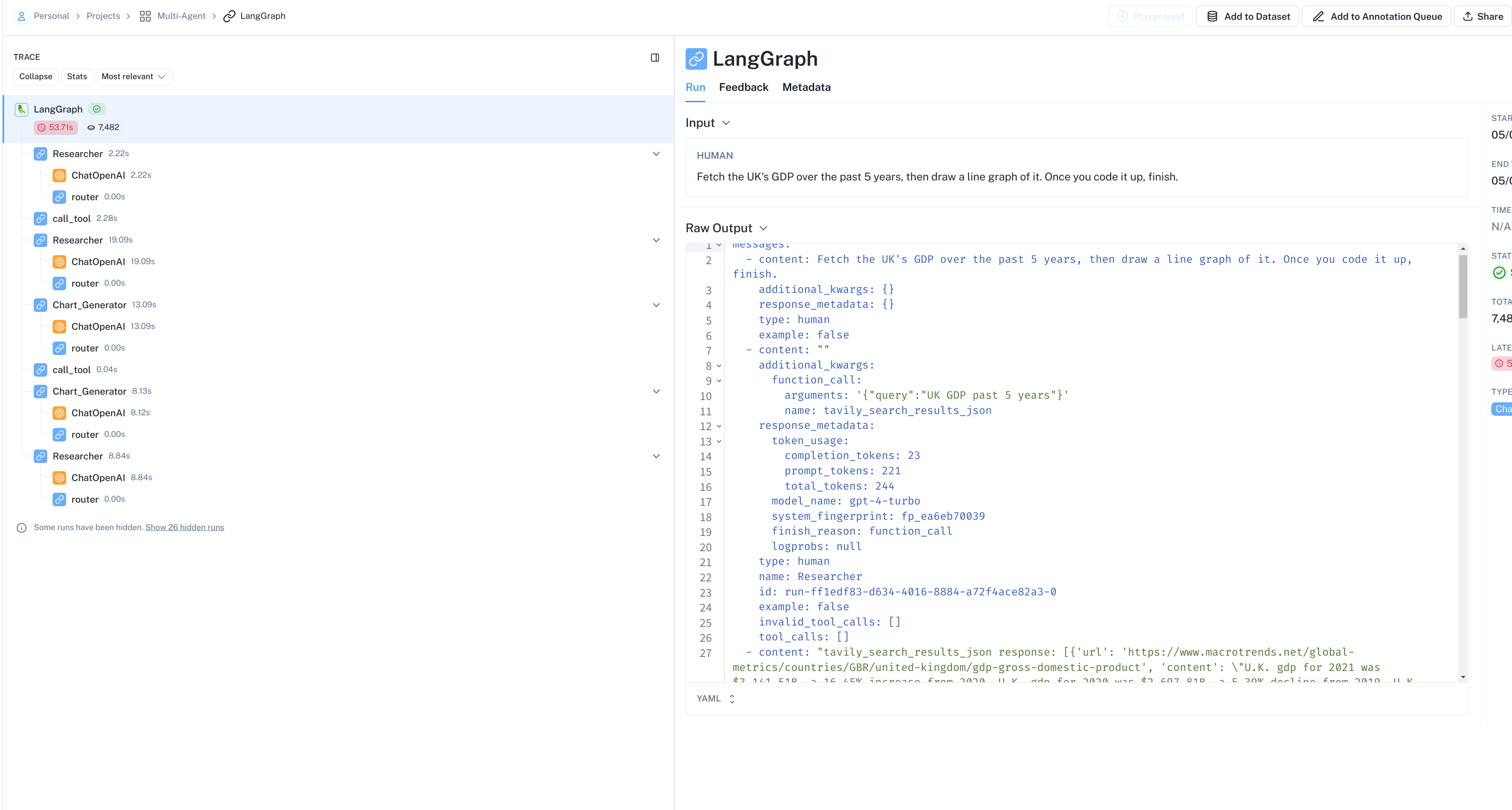
LangSmith流程展示:
2.2 Multi Agent 协作
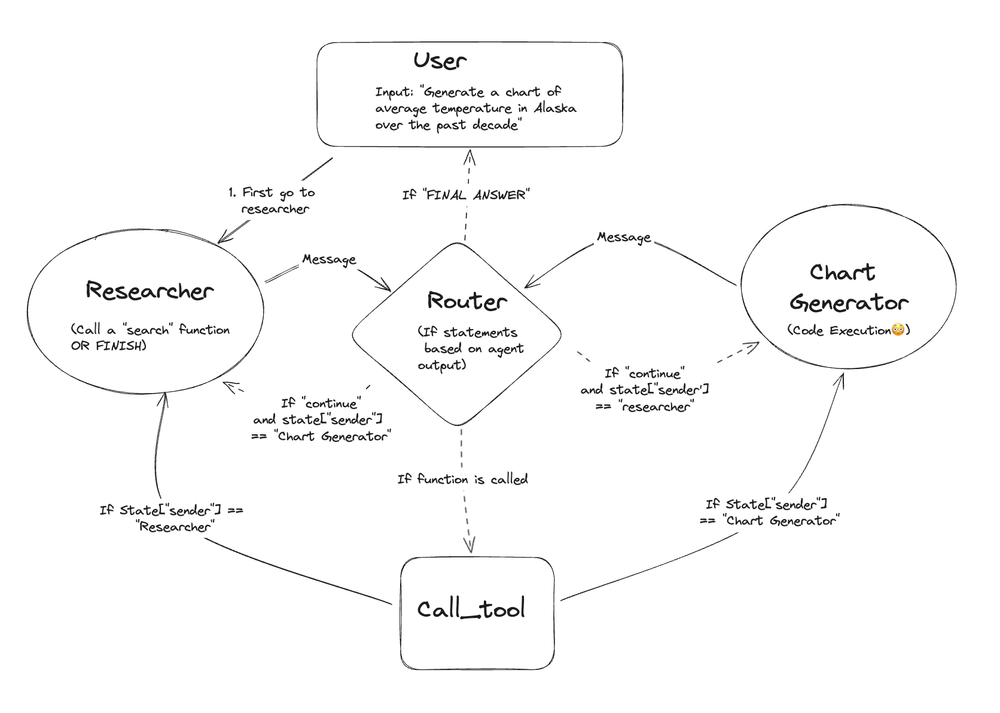
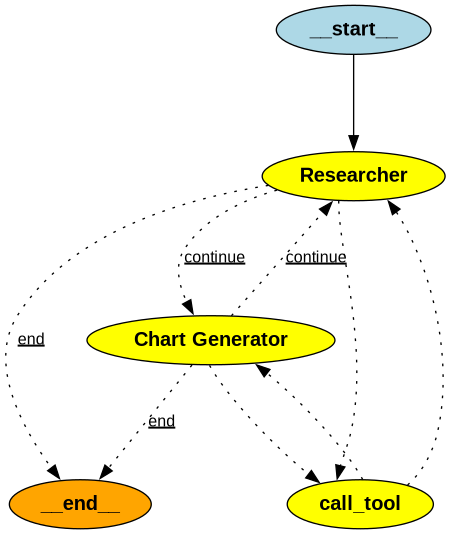
与Agent Supervisor不同,Multi Agent 协作中不同的Agent在一个共享的消息草稿上进行协作。它们所做的所有工作对彼此都是可见的。这样做的好处是其他Agent可以看到完成的所有单独步骤。但是,有时传递所有这些信息可能会过于冗长且不必要,有时候只需要一个代理提供的最终答案。之所以称其为协作,是因为消息草稿的共享特性。
在这种情况下,独立Agent实际上只是一个 LLM 调用。 具体来说,它们是一个特定的提示模板(使用特定的系统消息以特定的方式格式化输入)加上 LLM 调用。
控制状态转换的主要是Router,但它是一个基于规则的Router。 基本上,在每次大型语言模型(LLM)调用之后,它会查看输出,如果调用了一个工具,那么它就会调用那个工具;如果没有调用任何工具,而LLM响应“最终答案”,则它会返回给用户。否则(如果没有调用任何工具,且LLM没有响应“最终答案”),它就会转向另一个LLM。
Agents
1 | |
Tools
1 | |
Graph State
1 | |
Agent Node
1 | |
Tool Node
1 | |
条件Edge
1 | |
Graph
1 | |
Graph 预览
1 | |
执行
1 | |
输出
1 | |
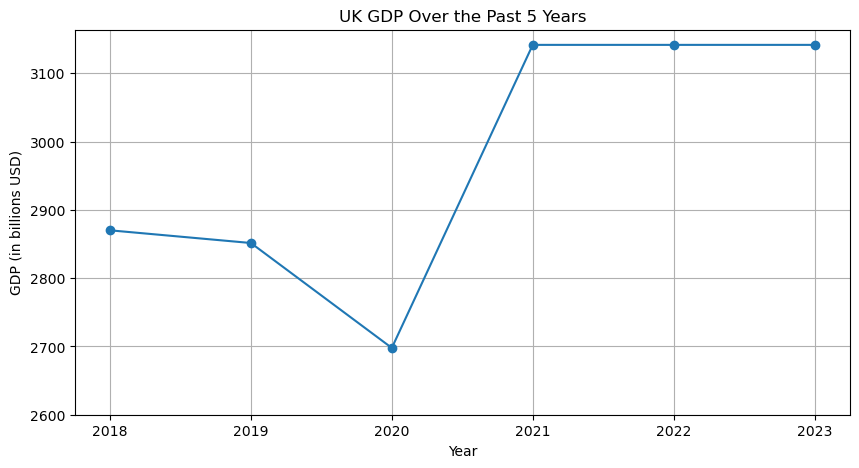
LangSmith流程展示:
2.3 层级Agent Teams
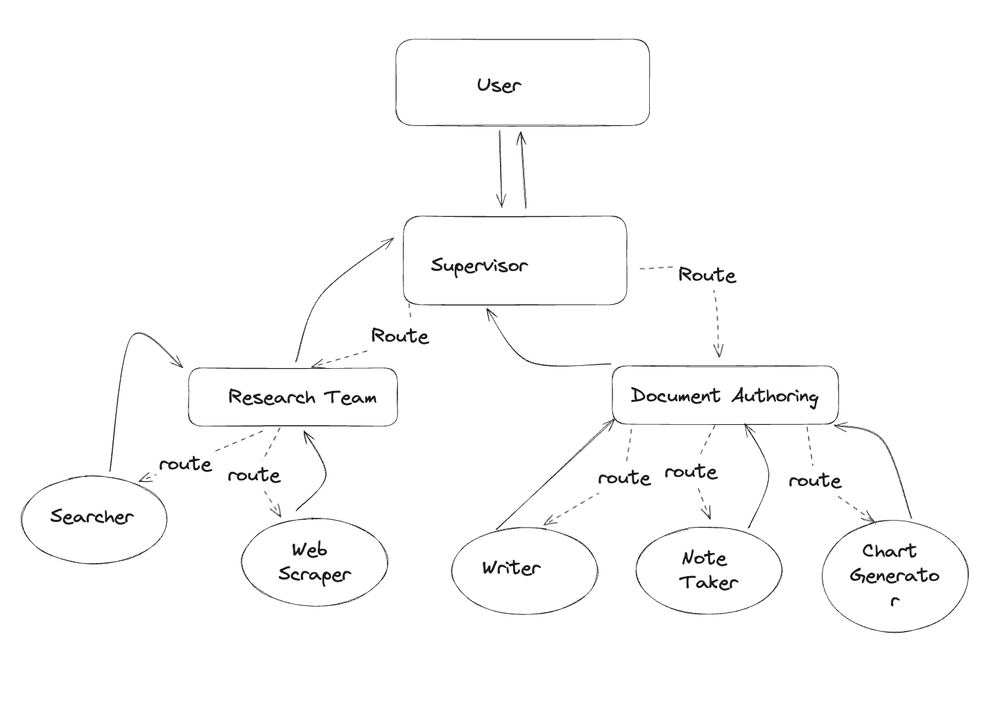
层级Agent Teams与Agent Supervisor类似,但节点中的Agent实际上是其他 LangGraph 对象。这比使用 LangChain AgentExecutor 作为Agent Runtime更灵活。称其为分层团队,因为子Agent在某种程度上可以被视为团队。这里每个LangGraph Agent是一个独立的Agent了。
Tools
1 | |
Document writing team tools
1 | |
Helper Utilities 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78from typing import Any, Callable, List, Optional, TypedDict, Union
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import Runnable
from langchain_core.tools import BaseTool
from langchain_openai import ChatOpenAI
from langgraph.graph import END, StateGraph
def create_agent(
llm: ChatOpenAI,
tools: list,
system_prompt: str,
) -> str:
"""Create a function-calling agent and add it to the graph."""
system_prompt += "\nWork autonomously according to your specialty, using the tools available to you."
" Do not ask for clarification."
" Your other team members (and other teams) will collaborate with you with their own specialties."
" You are chosen for a reason! You are one of the following team members: {team_members}."
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
system_prompt,
),
MessagesPlaceholder(variable_name="messages"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
agent = create_openai_functions_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools)
return executor
def agent_node(state, agent, name):
result = agent.invoke(state)
return {"messages": [HumanMessage(content=result["output"], name=name)]}
def create_team_supervisor(llm: ChatOpenAI, system_prompt, members) -> str:
"""An LLM-based router."""
options = ["FINISH"] + members
function_def = {
"name": "route",
"description": "Select the next role.",
"parameters": {
"title": "routeSchema",
"type": "object",
"properties": {
"next": {
"title": "Next",
"anyOf": [
{"enum": options},
],
},
},
"required": ["next"],
},
}
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
(
"system",
"Given the conversation above, who should act next?"
" Or should we FINISH? Select one of: {options}",
),
]
).partial(options=str(options), team_members=", ".join(members))
return (
prompt
| llm.bind_functions(functions=[function_def], function_call="route")
| JsonOutputFunctionsParser()
)
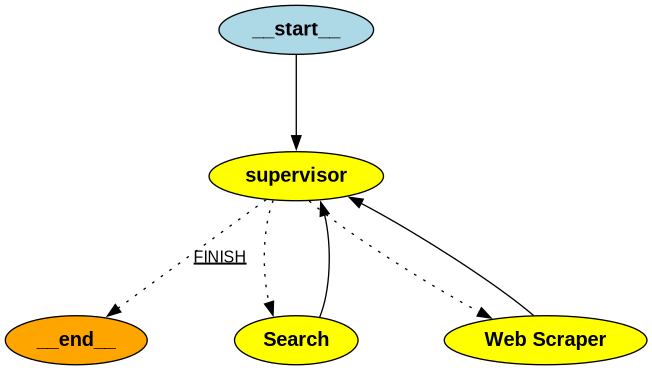
Research Team
supervisor agent
1 | |
Research Graph 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30research_graph = StateGraph(ResearchTeamState)
research_graph.add_node("Search", search_node)
research_graph.add_node("Web Scraper", research_node)
research_graph.add_node("supervisor", supervisor_agent)
# Define the control flow
research_graph.add_edge("Search", "supervisor")
research_graph.add_edge("Web Scraper", "supervisor")
research_graph.add_conditional_edges(
"supervisor",
lambda x: x["next"],
{"Search": "Search", "Web Scraper": "Web Scraper", "FINISH": END},
)
research_graph.set_entry_point("supervisor")
chain = research_graph.compile()
# The following functions interoperate between the top level graph state
# and the state of the research sub-graph
# this makes it so that the states of each graph don't get intermixed
def enter_chain(message: str):
results = {
"messages": [HumanMessage(content=message)],
}
return results
research_chain = enter_chain | chain
Research Graph预览
1 | |
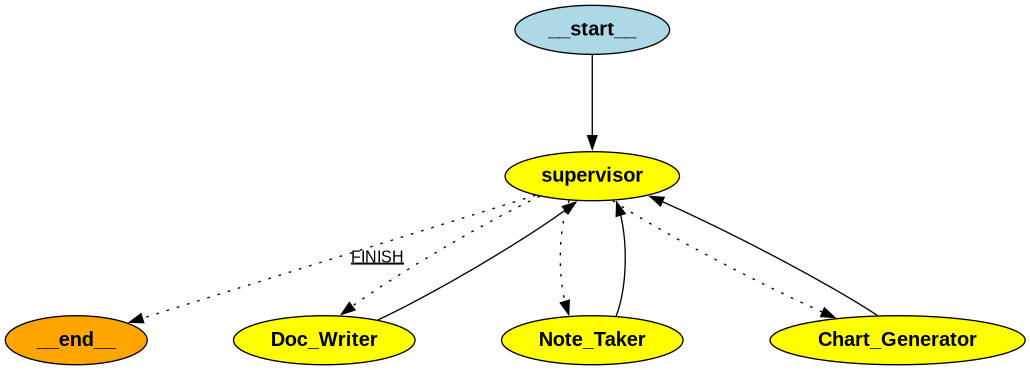
Document Writing Team
doc writing supervisor
1 | |
Document Writing Graph
1 | |
Document Writing Graph 预览
1 | |
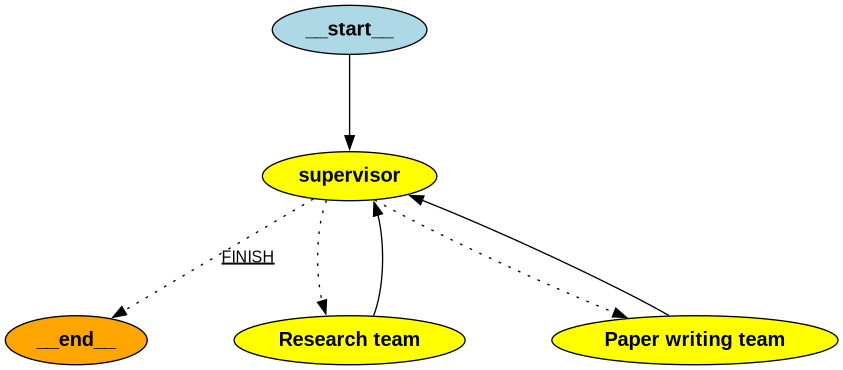
Add Layers
Supervisor Node
1 | |
Graph
1 | |
Graph预览
1 | |
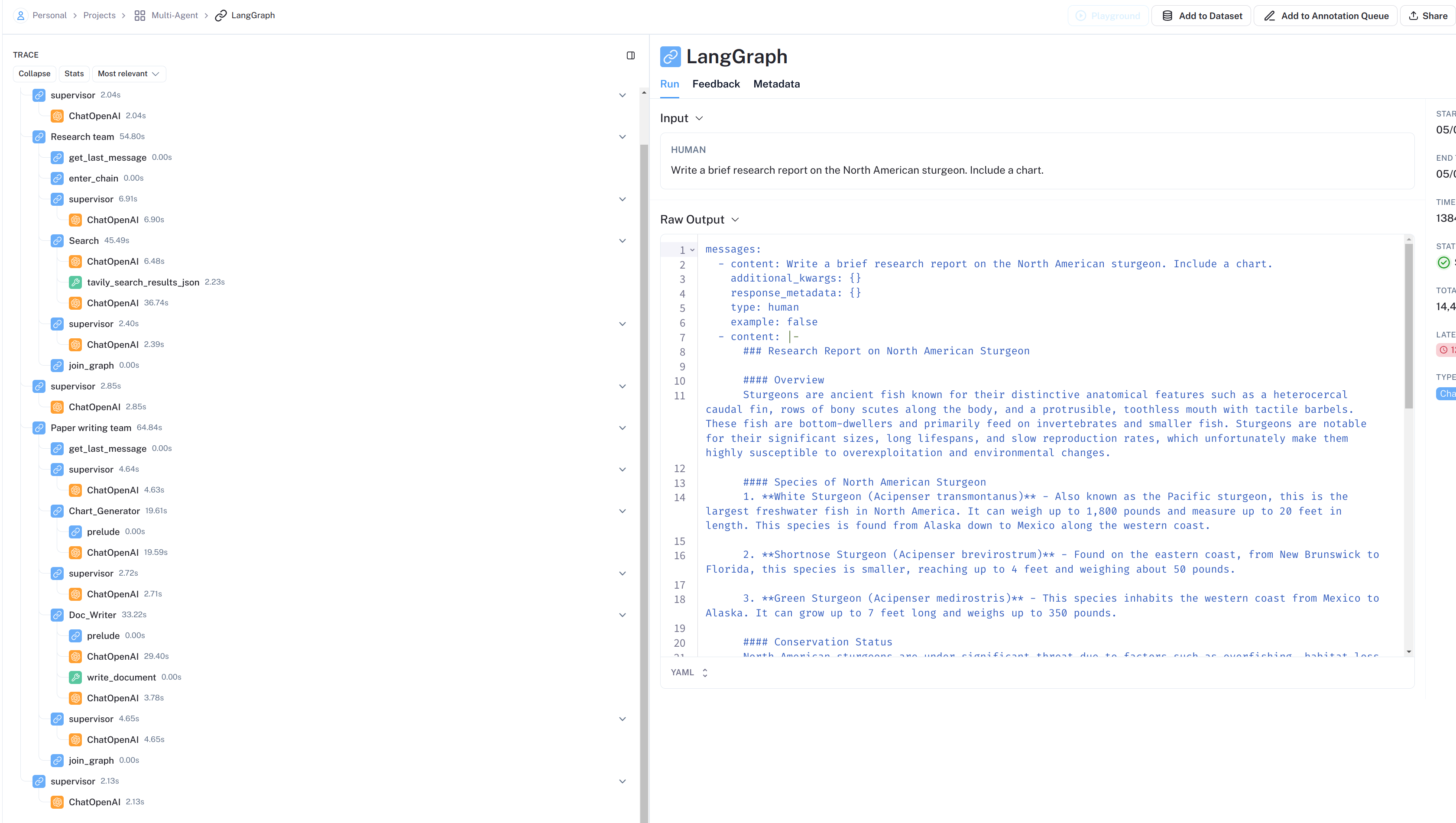
执行
1 | |
输出
1 | |
LangSmith流程展示:
三、第三方应用
基于LangGraph构建的 Multi-Agent 架构
3.1 GPT-Newspaper
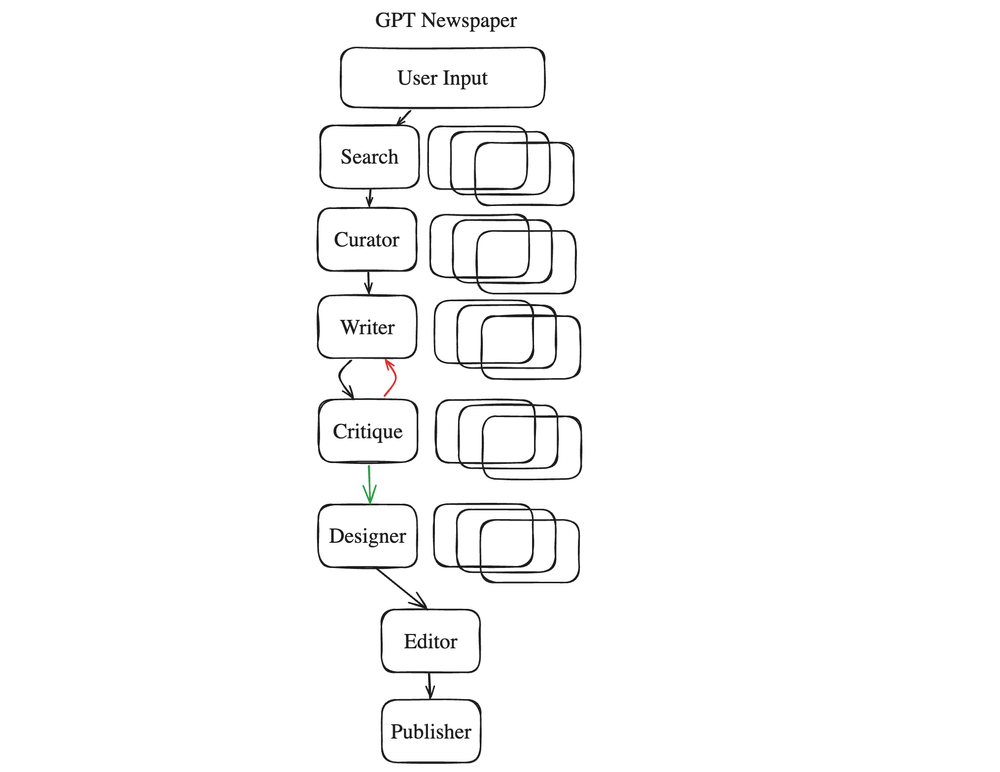
GPT-Newspaper 是一个创新的自治Agent,旨在创建根据用户偏好量身定制的个性化报纸。GPT-Newspaper 通过利用人工智能的力量,根据个人的品味和兴趣来策划、撰写、设计和编辑内容,从而彻底改变了我们消费新闻的方式。该架构由六个专门的子Agent组成。其中有一个关键步骤——一个作者与评论者之间的循环,这个循环增加了一个有益的循环过程。
3.2 Crew AI example
CrewAI 结合 LangChain 和 LangGraph 自动化检查电子邮件和创建草稿的过程。CrewAI 对自主 AI 代理进行编排,使它们能够高效地协作并执行复杂任务。
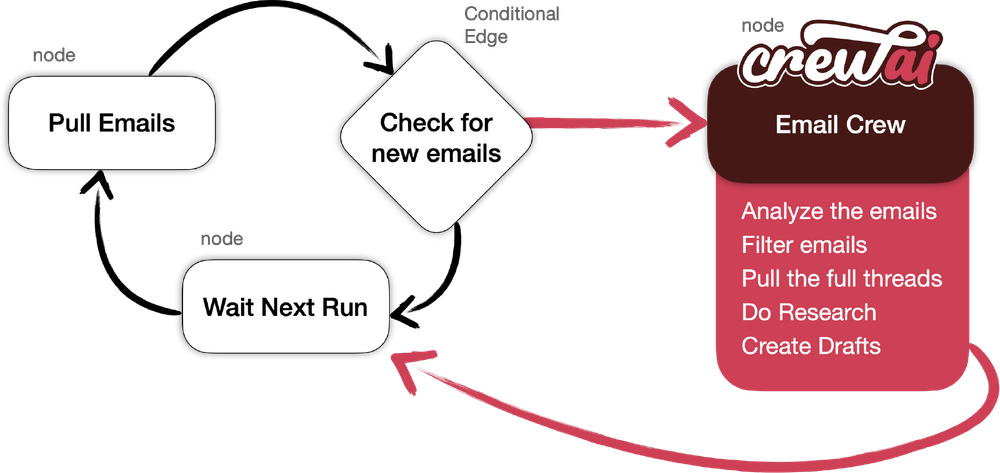
YouTube视频:https://youtu.be/OzYdPqzlcPo
四、其他框架
LangGraph 并不是第一个支持Multi-Agent工作流的框架。这些框架之间的大部分差异主要在于它们引入的mental model和概念。
4.1 Autogen
Autogen 可能是第一个Multi-Agent框架。LangGraph 和 Autogen 在mental model上的最大区别在于Agent的构建方式。LangGraph 倾向于明确定义不同的Agent和转换概率,并将其表示为图。Autogen 则更多地将其框架用于“对话”。LangGraph官方认为这种“图”框架更直观,并为构建更复杂和有特定意见的工作流(真正想要控制节点之间的转换概率)提供了更好的开发者体验。它还支持那些没有被“对话”明确捕获的工作流。
Autogen 和 LangGraph 之间的另一个关键区别是,LangGraph 完全集成到了 LangChain 生态系统中,这意味着你可以充分利用所有 LangChain 集成和 LangSmith 的可观测性。
4.2 CrewAI
CrewAI 最近成为创建 Multi-Agent Teams 的流行方式。与LangGraph相比,CrewAI是一个更高级别的框架。LangGraph官方正在积极与CrewAI团队合作,将LangGraph集成到CrewAI中。CrewAI已经实现了一个非常棒的更高级别的开发者体验(DevEx)。
官方资源
代码示例更详细说明: