EM算法
1.基础知识
1.1.高斯混合模型
高斯混合模型是有如下形式的概率分布模型:
其中
假设观测数据
高斯混合分布的对数最大化似然函数为:
对数里面有加和,无法直接通过求偏导解方程的方法求取最大值。 可以用EM算法解决这种难以计算的问题,EM算法是一种近似逼 近的迭代计算方法。
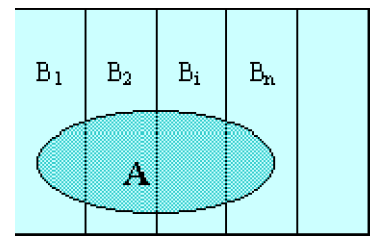
1.2.全概率公式
对于任一事件
上式称为全概率公式。
1.3.Jensen不等式
如果

2.EM算法原理及推导
实际问题中可能有一些数据是我们无法观测到的,假设观测数据
EM算法
对于观测数据
根据Jensen不等式,想要等式成立,有如下条件:
可以推出:
则:
即
上式中第二项与
可得最大化似然函数等同于:
EM算法流程
由以上推导可知EM算法通过迭代求
(1)选择参数的初始值
(2)E步(求期望):
(3)M步:最大化第二步的期望值,然后对参数求偏导等于0后求得下一步迭代的参数:
(4)重复E步和M步直至:
停止迭代,返回
EM算法是利用下边界逼近真实值,如下图:

3.EM算法收敛性
观测数据的似然函数:
令
则对数似然函数可以写成:
由于
第二项:
因此
4.EM算法在高斯混合模型中的应用
高斯混合模型在第一节中已经提过,下面以单变量为例。
明确隐变量,写出完整的对数似然函数
完整数据可表示为
完整数据的似然函数可表示为:
E-步
M-步
多元高斯混合模型
与单元求解类似(注意向量和矩阵求导的细节即可)