review = "Je trouve le goût médiocre. La mousse ne tient pas, c'est bizarre. J'achète les mêmes dans le commerce et le goût est bien meilleur...\nVieux lot ou contrefaçon !?" overall_chain.invoke(review)
▶
输出
1 2 3 4 5
{'Review': "Je trouve le goût médiocre. La mousse ne tient pas, c'est bizarre. J'achète les mêmes dans le commerce et le goût est bien meilleur...\nVieux lot ou contrefaçon !?", 'English_Review': "I find the taste mediocre. The foam doesn't last, it's strange. I buy the same ones in stores and the taste is much better... Old batch or counterfeit!?", 'summary': 'The reviewer is disappointed with the taste and quality of the product, suspecting it may be an old batch or counterfeit.', 'language': "C'est en français.", 'followup_message': "Merci pour vos commentaires. Nous sommes désolés d'apprendre que vous n'avez pas été satisfait de notre produit. Nous vous assurons que nous prenons la qualité de nos produits très au sérieux et nous allons enquêter sur cette question pour comprendre ce qui s'est passé. Nous vous remercions de nous en avoir informé et nous ferons tout notre possible pour rectifier la situation."}
from langchain.chains.router import MultiPromptChain #导入多提示链 from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser from langchain.prompts import PromptTemplate
from langchain_openai import OpenAIEmbeddings from langchain_openai import ChatOpenAI from langchain.chains import RetrievalQA from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.vectorstores import Chroma from langchain_community.document_loaders import PyPDFLoader from langchain_community.embeddings.dashscope import DashScopeEmbeddings
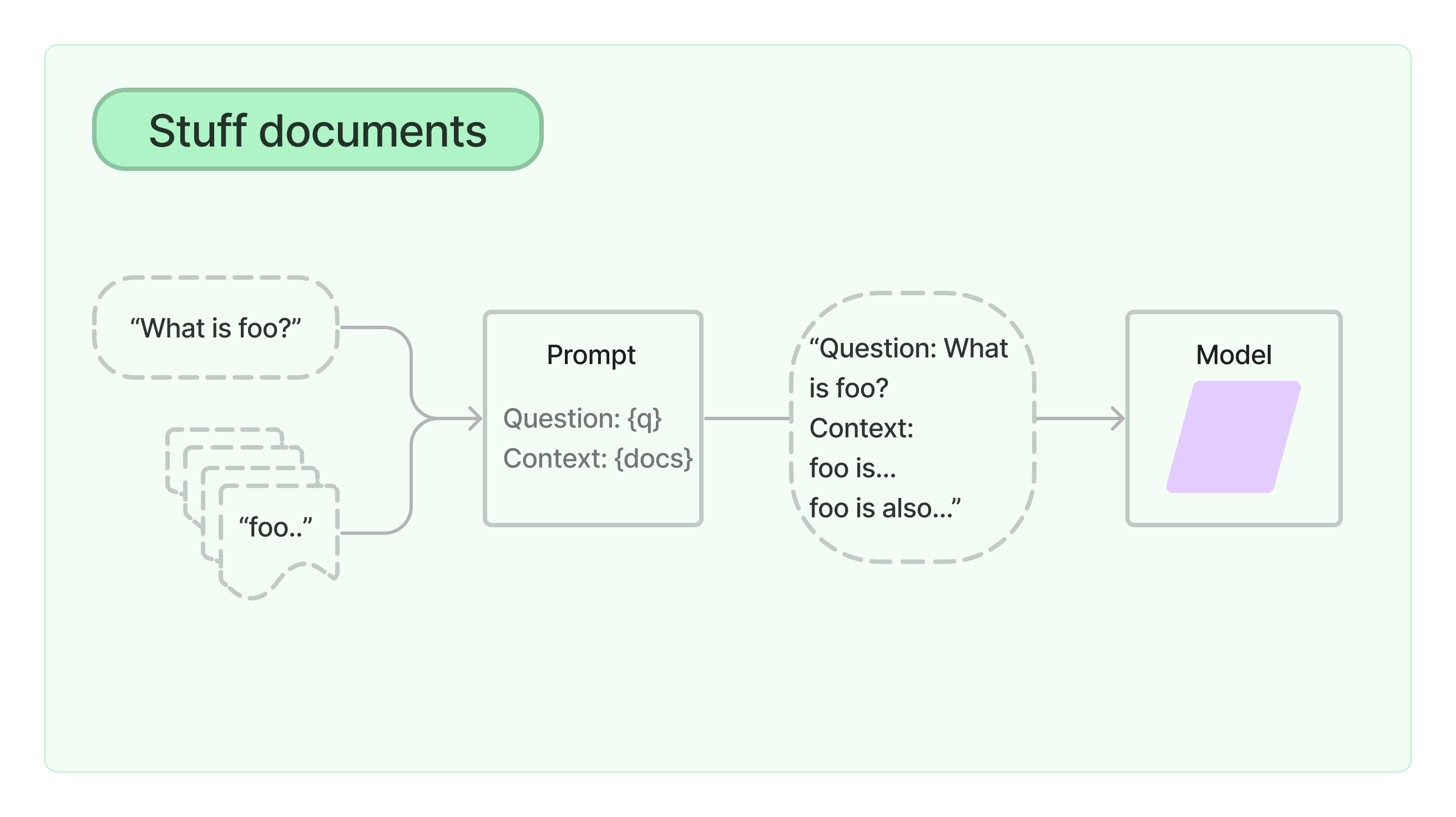
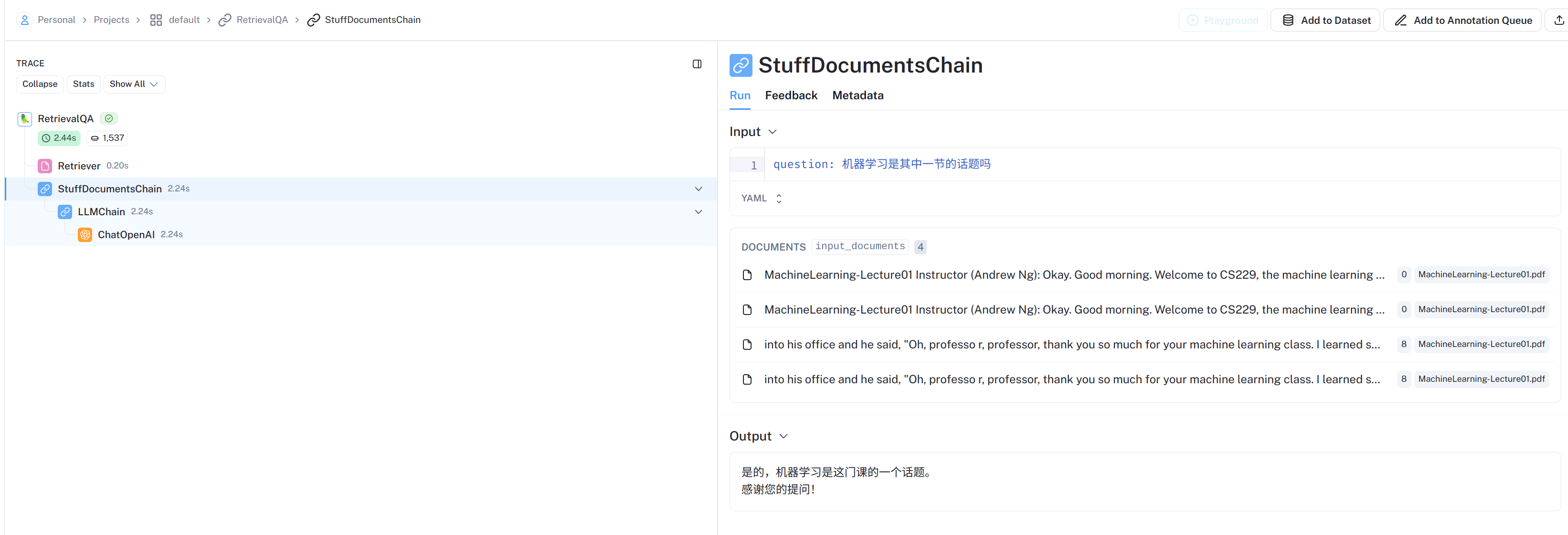
# 加载 PDF loader = PyPDFLoader("MachineLearning-Lecture01.pdf") docs = [] docs.extend(loader.load())
# # 可以以该方式进行检索问答 question = "What are major topics for this class?" result = qa_chain({"query": question}) print(result["result"])
▶
输出
1 2 3 4 5 6
The major topics for this class, as outlined bythe instructor, include:
1. Machine learning fundamentals covered inthe main lectures. 2. Optional discussion sections covering extensions tothe main lecture materials, such as convex optimization and hidden Markov models. 3. The use of MATLAB for assignments, withthe instructor strongly advising against using R due to potential compatibility issues. 4. Flexibility in group sizes forthe term project, with options for groups ofthree, two, or individual work, with grading being the same regardless of group size.
from langchain_openai import ChatOpenAI from langchain.prompts import ChatPromptTemplate from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
prompt = ChatPromptTemplate.from_template("tell me a joke about {foo}") model = ChatOpenAI()
functions = [ { "name": "joke", "description": "A joke", "parameters": { "type": "object", "properties": { "setup": {"type": "string", "description": "The setup for the joke"}, "punchline": { "type": "string", "description": "The punchline for the joke", }, }, "required": ["setup", "punchline"], }, } ]
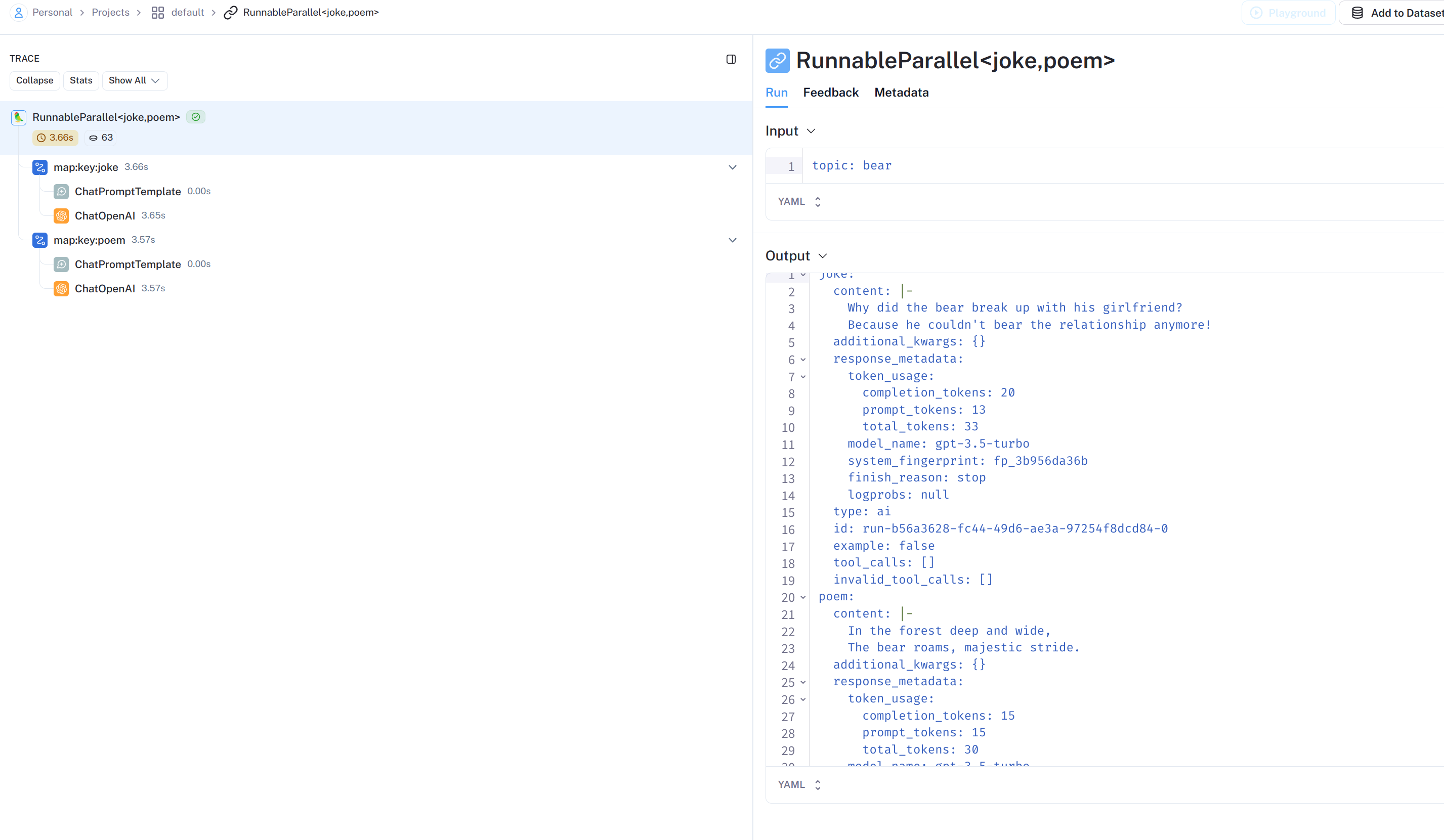
from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnableParallel from langchain_openai import ChatOpenAI
model = ChatOpenAI() joke_chain = ChatPromptTemplate.from_template("tell me a joke about {topic}") | model poem_chain = ( ChatPromptTemplate.from_template("write a 2-line poem about {topic}") | model )
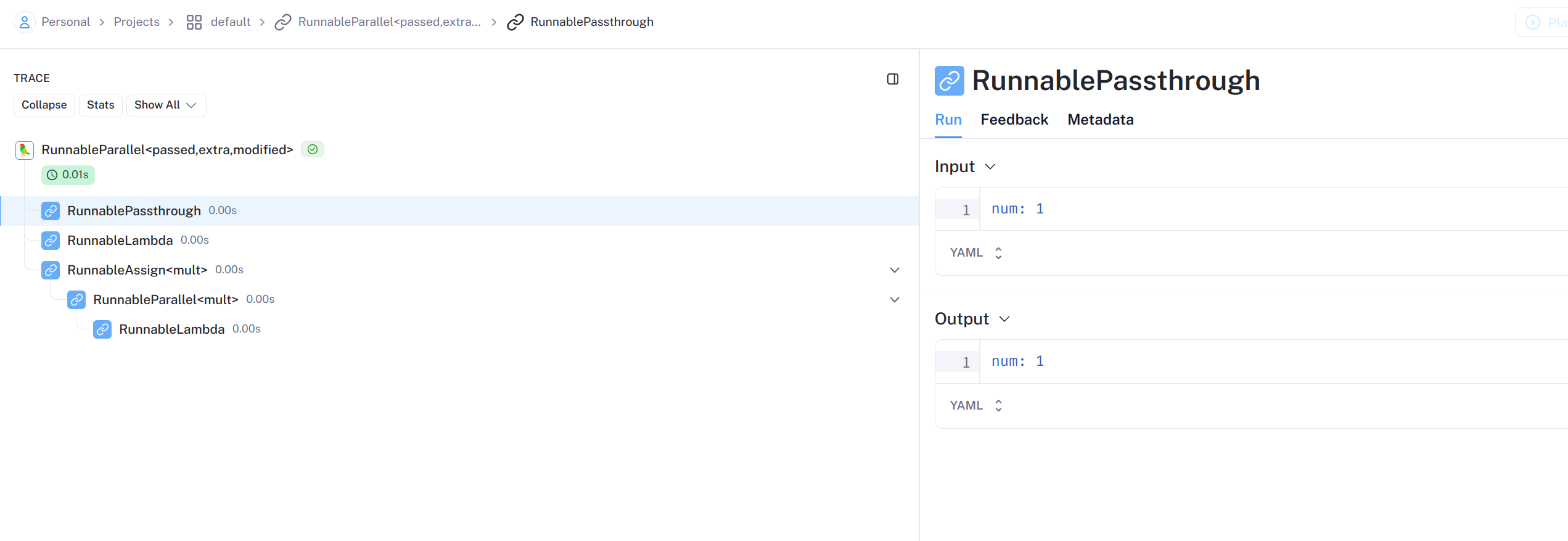
from langchain.schema.output_parser import StrOutputParser from langchain_core.runnables import RunnableParallel from langchain_core.runnables import RunnablePassthrough from operator import itemgetter
llm = ChatOpenAI() prompt1 = ChatPromptTemplate.from_template(""" What is the city {person} is from? Only respond with city name. """)
prompt2 = ChatPromptTemplate.from_template(""" What country is the city {city} in? Respond in {language}. """)
chain1 = prompt1|llm|StrOutputParser()
rp =RunnableParallel( city=chain1, language=itemgetter("language") )
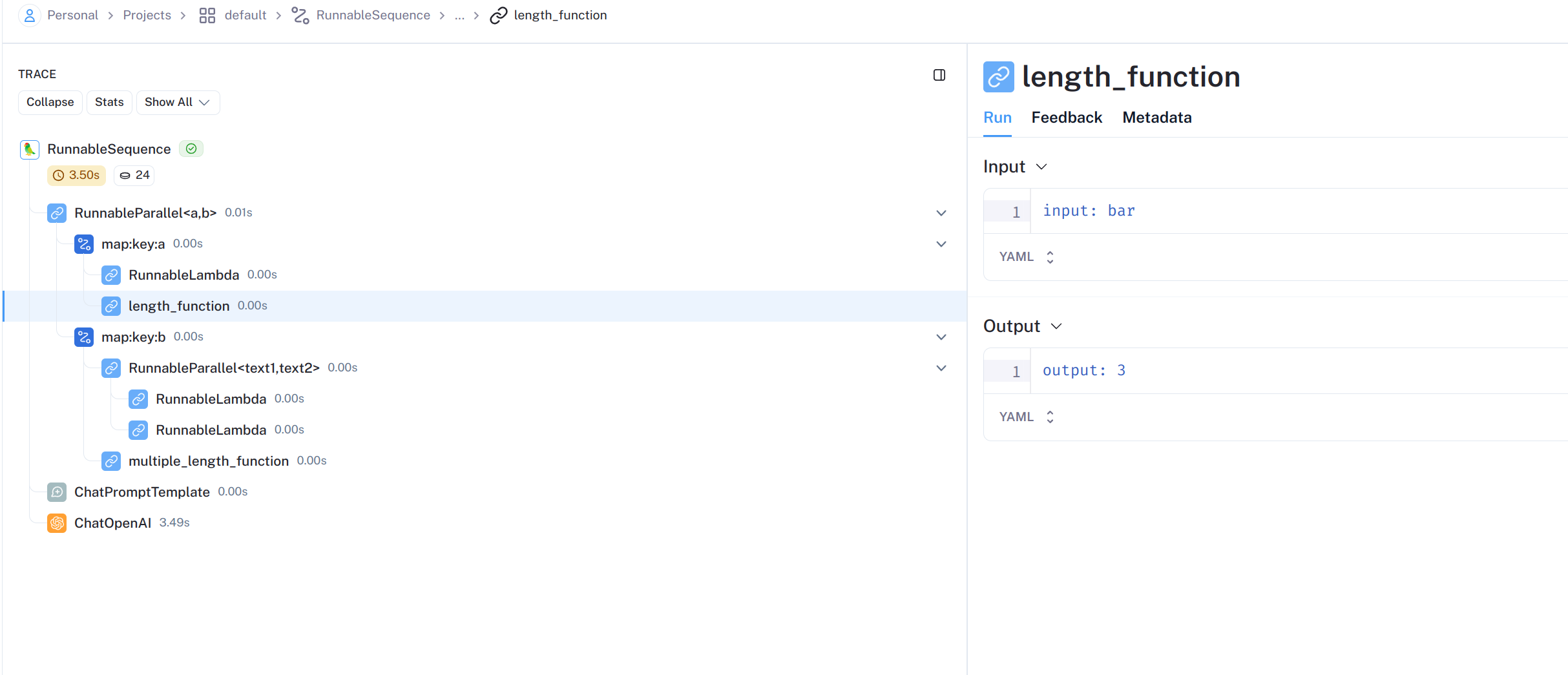
from langchain_community.vectorstores import Chroma from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_openai import ChatOpenAI from langchain_community.embeddings.dashscope import DashScopeEmbeddings
vectorstore = Chroma.from_texts( ["harrison worked at kensho"], embedding=embeddings ) retriever = vectorstore.as_retriever() template = """Answer the question based only on the following context: {context}
Question: {question} """ prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI()
from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_openai import ChatOpenAI from langchain_core.runnables import RunnableBranch
chain = ( PromptTemplate.from_template( """Given the user question below, classify it as either being about `LangChain`, `Anthropic`, or `Other`.
langchain_chain = PromptTemplate.from_template( """You are an expert in langchain. \ Always answer questions starting with "As Harrison Chase told me". \ Respond to the following question:
anthropic_chain = PromptTemplate.from_template( """You are an expert in anthropic. \ Always answer questions starting with "As Dario Amodei told me". \ Respond to the following question:
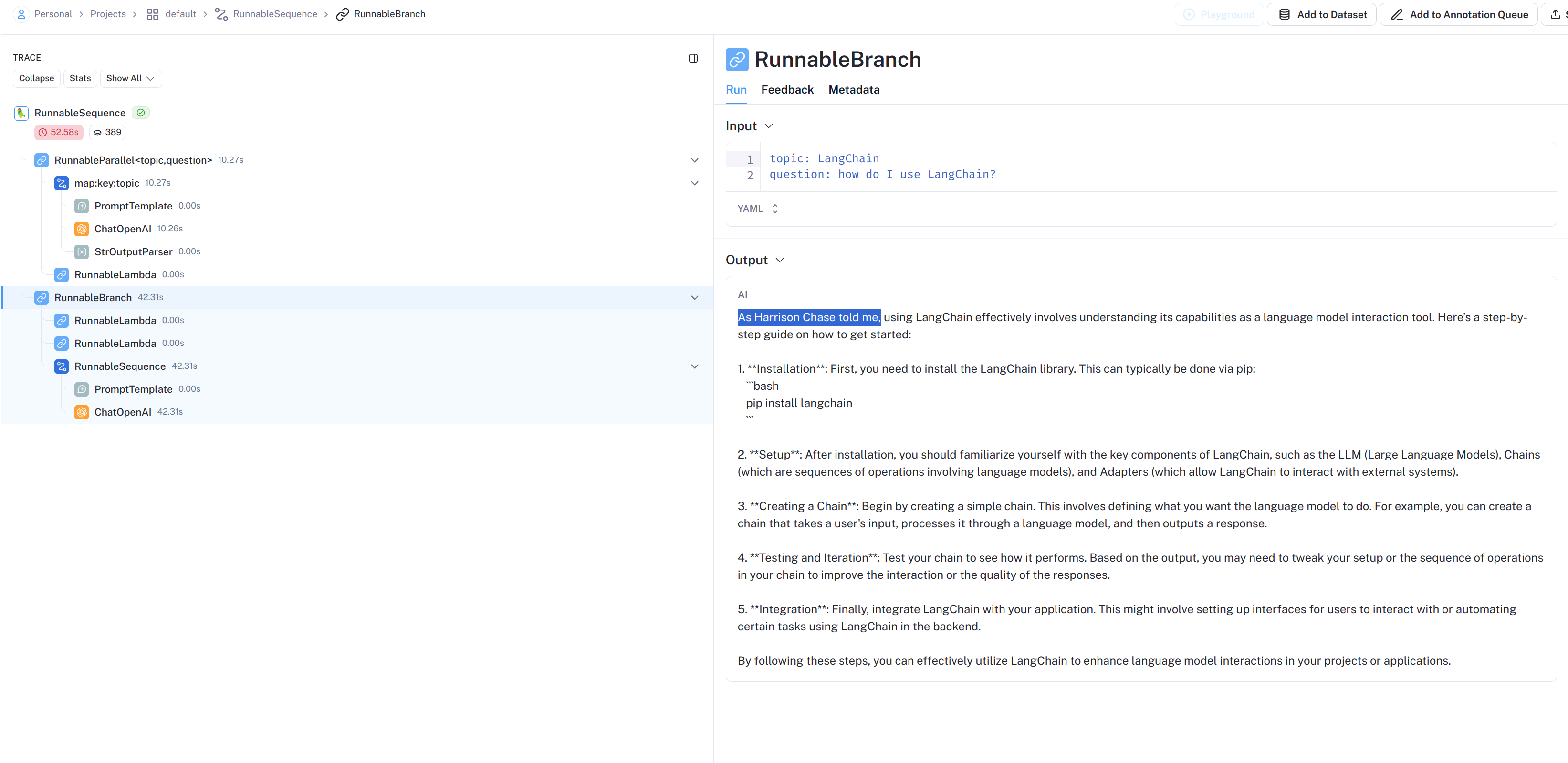
full_chain = {"topic": chain, "question": lambda x: x["question"]} | branch full_chain.invoke({"question": "how do I use LangChain?"})
▶
输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
As Harrison Chase told me, using LangChain effectively involves understanding its capabilities as a language model interaction tool. Here’s a step-by-step guide on how to get started:
1.**Installation**: First, you need to install the LangChain library. This can typically be done via pip: ```bash pip install langchain ```
2.**Setup**: After installation, you should familiarize yourself with the key components of LangChain, such as the LLM (Large Language Models), Chains (which are sequences of operations involving language models), and Adapters (which allow LangChain to interact with external systems).
3.**Creating a Chain**: Begin by creating a simple chain. This involves defining what you want the language model to do. For example, you can create a chain that takes a user's input, processes it through a language model, and then outputs a response.
4.**Testing and Iteration**: Test your chain to see how it performs. Based on the output, you may need to tweak your setup or the sequence of operations in your chain to improve the interaction or the quality of the responses.
5.**Integration**: Finally, integrate LangChain with your application. This might involve setting up interfaces for users to interact with or automating certain tasks using LangChain in the backend.
By following these steps, you can effectively utilize LangChain to enhance language model interactions in your projects or applications.
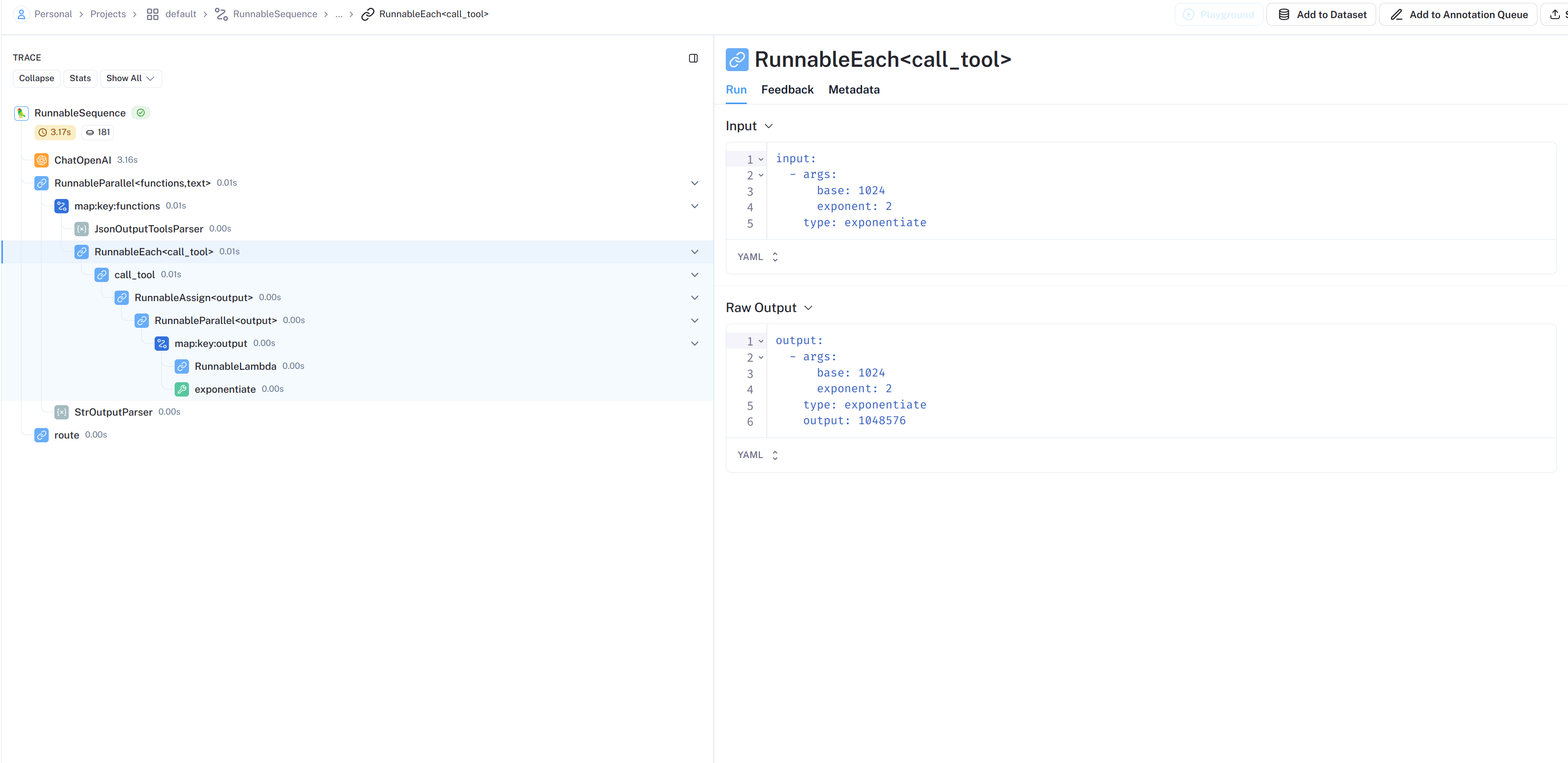
@tool defexponentiate(base: int, exponent: int) -> int: "Exponentiate the base to the exponent power." return base**exponent
tools = [multiply, add, exponentiate]
# 名称到函数的映射 tool_map = {tool.name: tool for tool in tools}
llm = ChatOpenAI()
defcall_tool(tool_invocation: dict) -> Union[str, Runnable]: """Function for dynamically constructing the end of the chain based on the model-selected tool.""" tool = tool_map[tool_invocation["type"]] return RunnablePassthrough.assign( output=itemgetter("args") | tool )
# .map() allows us to apply a function to a list of inputs. call_tool_list = RunnableLambda(call_tool).map()
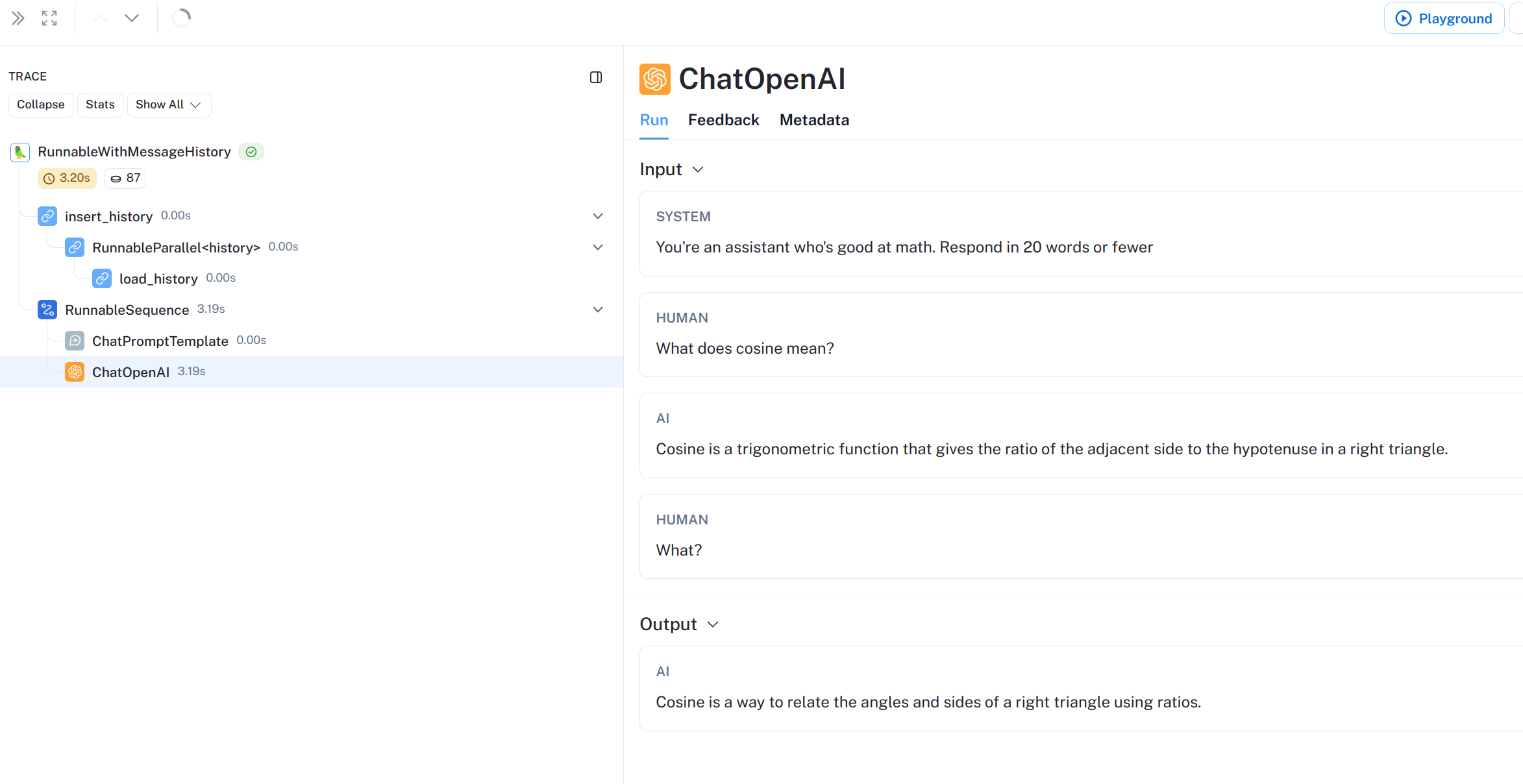
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_openai.chat_models import ChatOpenAI from langchain_community.chat_message_histories import ChatMessageHistory from langchain_core.chat_history import BaseChatMessageHistory from langchain_core.runnables.history import RunnableWithMessageHistory
model = ChatOpenAI() prompt = ChatPromptTemplate.from_messages( [ ( "system", "You're an assistant who's good at {ability}. Respond in 20 words or fewer", ), MessagesPlaceholder(variable_name="history"), ("human", "{input}"), ] ) runnable = prompt | model
Human: What does cosine mean? AI: Cosine is a trigonometric function that gives the ratio of the adjacent side to the hypotenuse in a right triangle. Human: What? AI: Cosine is a way to relate the angles and sides of a right triangle using ratios.