MachineLearning-Lecture01 Instructor (Andrew Ng): Okay. Good morning. Welcome to CS229, the machine learning class. So what I wanna do today is ju st spend a little time going over the logistics of the class, andthen we'll start to talk a bit about machine learning. By way of introduction, my name's Andrew Ng and I'll be instru ctor for this class. And so I personally work in machine learning, and I' ve worked on it for about 15 years now, and I actually think that machine learning i
paragraphs = text_splitter.create_documents([pages[0].page_content]) for para in paragraphs[0:5]: print(para.page_content) print('-------')
▶
输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
MachineLearning-Lecture01 Instructor (Andrew Ng): Okay. Good morning. Welcome to CS229, the machine learning class. So what I wanna do today is ju st spend a little time going over the logistics ------- learning class. So what I wanna do today is ju st spend a little time going over the logistics of the class, and then we'll start to talk a bit about machine learning. ------- of the class, and then we'll start to talk a bit about machine learning. By way of introduction, my name's Andrew Ng and I'll be instru ctor for this class. And so ------- By way of introduction, my name's Andrew Ng and I'll be instru ctor for this class. And so I personally work in machine learning, and I' ve worked on it for about 15 years now, and ------- I personally work in machine learning, and I' ve worked on it for about 15 years now, and I actually think that machine learning is th e most exciting field of all the computer -------
from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.vectorstores import Chroma from langchain_community.document_loaders import PyPDFLoader from langchain_openai import OpenAIEmbeddings from langchain_community.embeddings.dashscope import DashScopeEmbeddings
# 加载 PDF loaders = [ # 故意添加重复文档,使数据混乱 PyPDFLoader("MachineLearning-Lecture01.pdf"), PyPDFLoader("MachineLearning-Lecture01.pdf"), PyPDFLoader("MachineLearning-Lecture02.pdf"), PyPDFLoader("MachineLearning-Lecture03.pdf") ] docs = [] for loader in loaders: docs.extend(loader.load())
627 cs229-qa@cs.stanford.edu. This goes to an acc ount that's read by all the TAs and me. So rather than sending us email individually, if you send email to this account, it will actually let us get back to you maximally quickly with answers to your questions. If you're asking questions about homework probl ems, please say in the subject line which assignment and which question the email refers to, since that will also help us to route your question to the appropriate TA or to me appropriately and get the response back to you quickly. Let's see. Skipping ahead — let's see — for homework, one midterm, one open and term project. Notice on the honor code. So one thi ng that I think will help you to succeed and do well in this class and even help you to enjoy this cla ss more is if you form a study group. So start looking around where you' re sitting now or at the end of class today, mingle a little bit and get to know your classmates. I strongly encourage you to form study groups and sort of have a group of people to study with and have a group of your fellow students to talk over these concepts with. You can also post on the class news group if you want to use that to try to form a study group. But some of the problems sets in this cla ss are reasonably difficult. People that have taken the class before may tell you they were very difficult. And just I bet it would be more fun for you, and you'd probably have a be tter learning experience if you form a
those homeworks will be done in either MATLA B or in Octave, which is sort of — I know some people ========== those homeworks will be done in either MATLA B or in Octave, which is sort of — I know some people
我们可以看到一种新的失败的情况。
下面的问题询问了关于第三讲的问题,但也包括了来自其他讲的结果。
1 2 3 4 5
question = "what did they say about regression in the third lecture?" docs = retriever.get_relevant_documents(question)
those homeworks will be done in either MATLA B or in Octave, which is sort of — I know some people ========== into his office and he said, "Oh, professo r, professor, thank you so much for your machine learnin
可以看到输出已经不同了
4.3 解决特殊性
关于第三讲的问题,输出包括了来自其他讲的结果
使用元数据
为了解决这一问题,很多向量数据库都支持对metadata的操作。
metadata为每个嵌入的块(embedded chunk)提供上下文。
1 2 3 4 5 6
question = "what did they say about regression in the third lecture?" retriever = db.as_retriever(search_kwargs={"k":3,'filter': {'source':'MachineLearning-Lecture03.pdf'}}) #默认为similarity相似性搜索
docs = retriever.get_relevant_documents(question) for doc in docs: print(doc.metadata)
from langchain.retrievers.self_query.base import SelfQueryRetriever from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info = [ AttributeInfo( name="source", description="The lecture the chunk is from, should be one of `MachineLearning-Lecture01.pdf`, `MachineLearning-Lecture02.pdf`, or `MachineLearning-Lecture03.pdf`", type="string", ), AttributeInfo( name="page", description="The page from the lecture", type="integer", ), ]
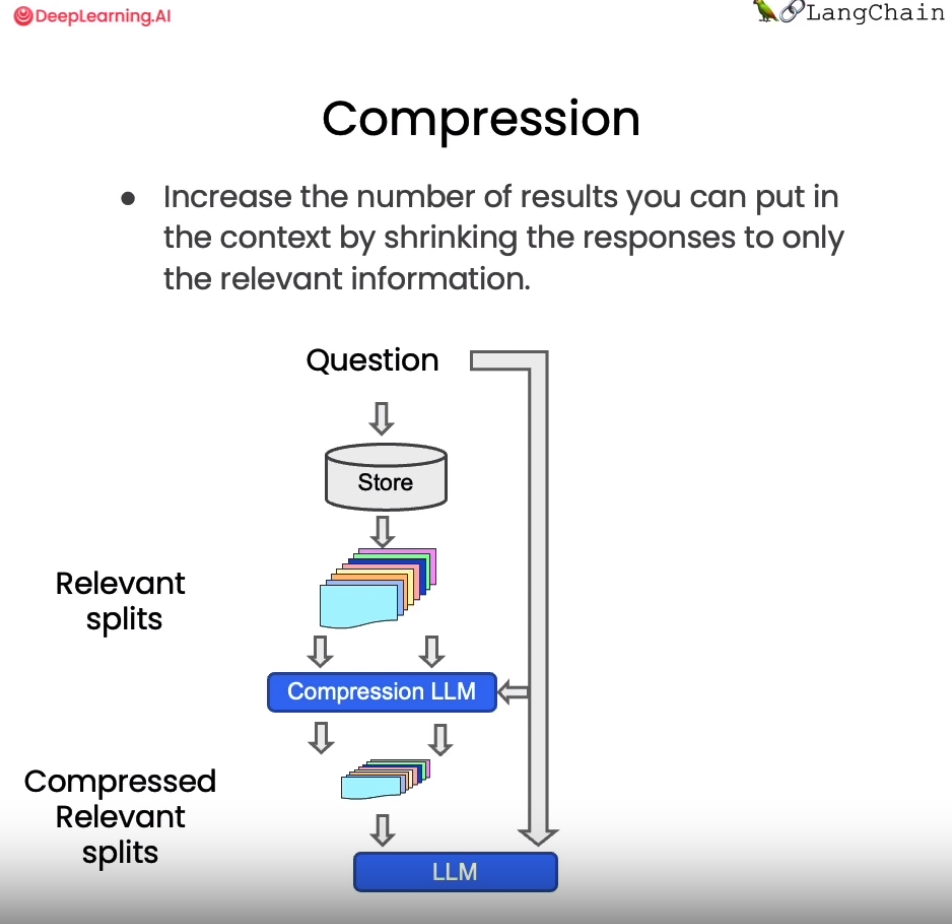
question = "what did they say about matlab?" compressed_docs = compression_retriever.get_relevant_documents(question) pretty_print_docs(compressed_docs)
▶
输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Document 1:
MATLAB is I guess part ofthe programming language that makes it very easy towrite codes using matrices, towrite code for numerical routines, to move data around, to plot data. And it's sort of an extremely easy to learn tool to use for implementing a lot of learning algorithms. ---------------------------------------------------------------------------------------------------- Document 2:
MATLAB is I guess part ofthe programming language that makes it very easy towrite codes using matrices, towrite code for numerical routines, to move data around, to plot data. And it's sort of an extremely easy to learn tool to use for implementing a lot of learning algorithms. ---------------------------------------------------------------------------------------------------- Document 3:
MATLAB is I guess part ofthe programming language that makes it very easy towrite codes using matrices, towrite code for numerical routines, to move data around, to plot data. And it's sort of an extremely easy to learn tool to use for implementing a lot of learning algorithms. ---------------------------------------------------------------------------------------------------- Document 4:
MATLAB is I guess part ofthe programming language that makes it very easy towrite codes using matrices, towrite code for numerical routines, to move data around, to plot data. And it's sort of an extremely easy to learn tool to use for implementing a lot of learning algorithms. there's also a software package called Octave that you can download for free off the Internet. And it has somewhat fewer features than MATLAB, butit's free, andforthe purposes of this class, it will work for just about everything.
question = "what did they say about matlab?" compressed_docs = compression_retriever.get_relevant_documents(question) pretty_print_docs(compressed_docs)
▶
输出
1 2 3 4 5 6 7 8 9 10 11
Document 1:
MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to plot data. And it's sort of an extremely easy to learn tool to use for implementing a lot of learning algorithms. ---------------------------------------------------------------------------------------------------- Document 2:
"Oh, it was the MATLAB." ---------------------------------------------------------------------------------------------------- Document 3:
All the homeworks can be done in MATLAB or Octave.
from langchain.indexes import SQLRecordManager, index from langchain_core.documents import Document from langchain_elasticsearch import ElasticsearchStore from langchain_openai import OpenAIEmbeddings
# 索引到一个空的向量存储: def_clear(): """Hacky helper method to clear content. See the `full` mode section to to understand why it works.""" index([], record_manager, vectorstore, cleanup="full", source_id_key="source")