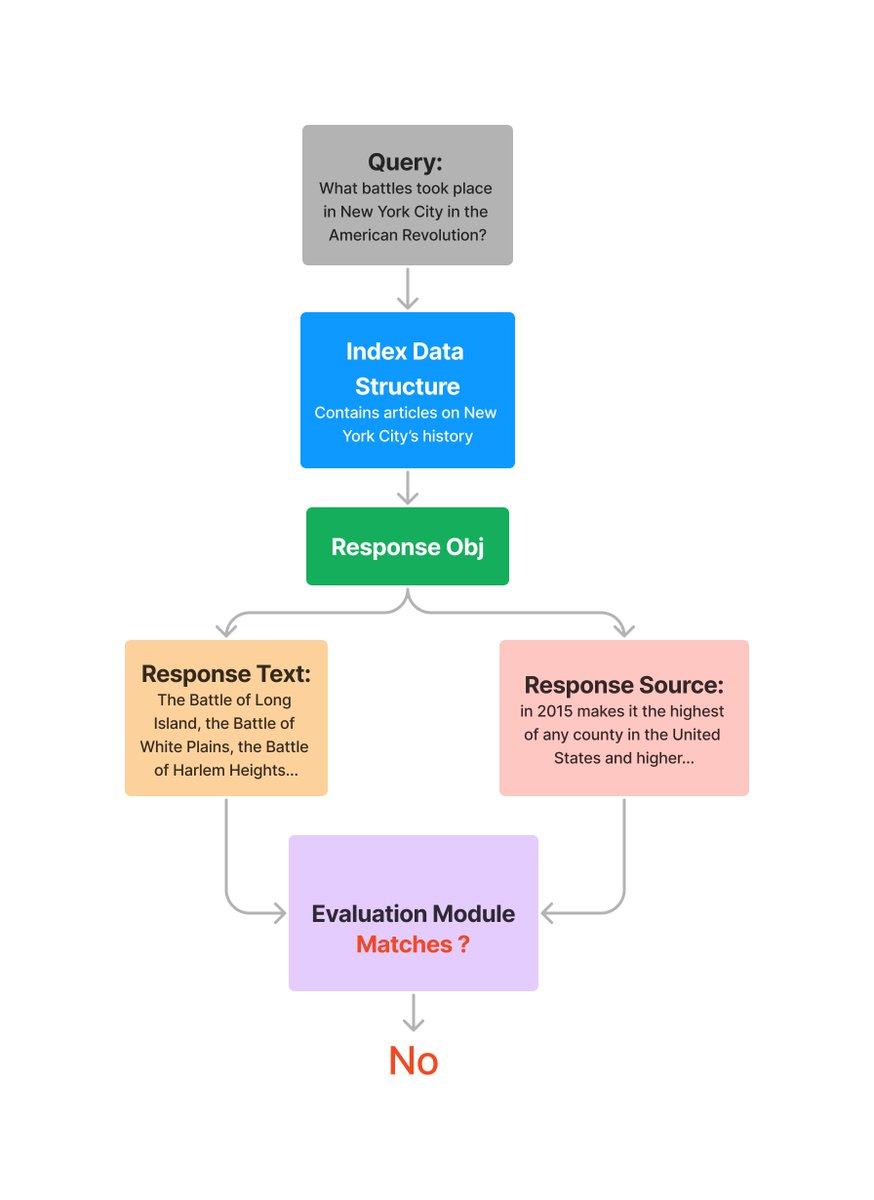
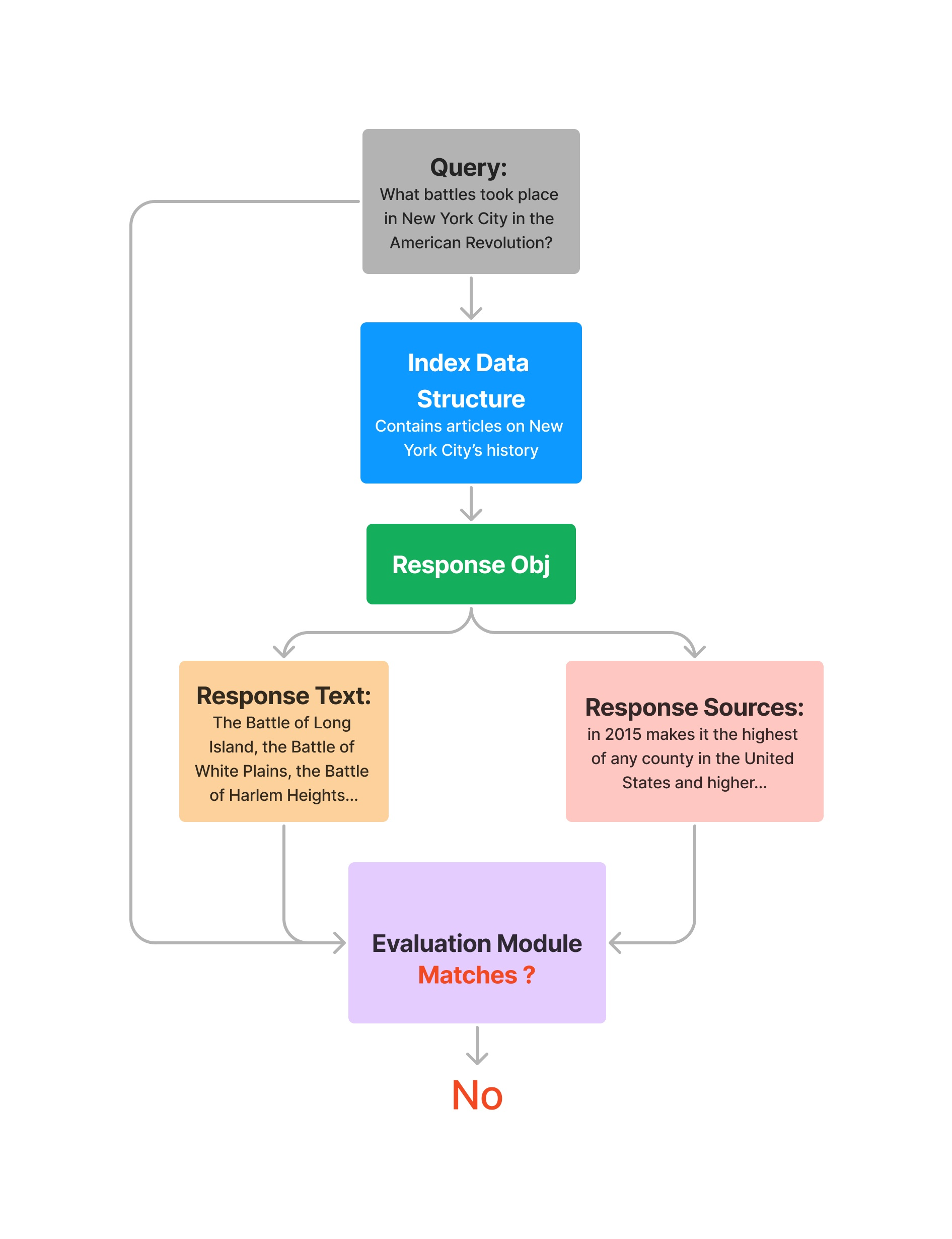
# query index query_engine = vector_index.as_query_engine() response = query_engine.query( "What battles took place in New York City in the American Revolution?" ) eval_result = evaluator.evaluate_response(response=response) print(str(eval_result.passing))
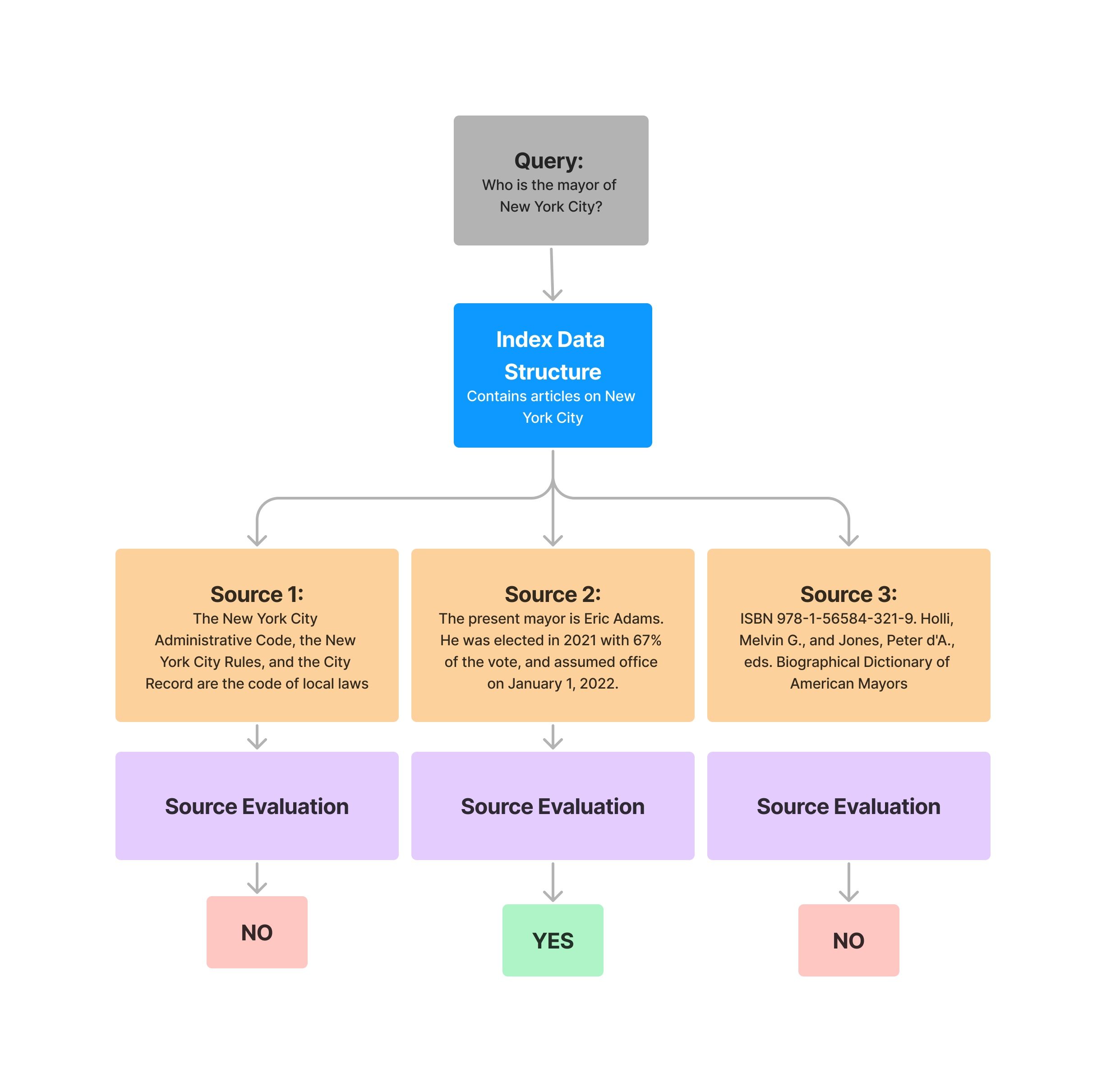
# query index query_engine = vector_index.as_query_engine() response = query_engine.query( "What battles took place in New York City in the American Revolution?" ) response_str = response.response for source_node in response.source_nodes: eval_result = evaluator.evaluate( response=response_str, contexts=[source_node.get_content()] ) print(str(eval_result.passing))
# query index query_engine = vector_index.as_query_engine() query = "What battles took place in New York City in the American Revolution?" response = query_engine.query(query) eval_result = evaluator.evaluate_response(query=query, response=response) print(str(eval_result))
# query index query_engine = vector_index.as_query_engine() query = "What battles took place in New York City in the American Revolution?" response = query_engine.query(query) response_str = response.response for source_node in response.source_nodes: eval_result = evaluator.evaluate( query=query, response=response_str, contexts=[source_node.get_content()], ) print(str(eval_result.passing))
from llama_index.core import SimpleDirectoryReader from llama_index.llms.openai import OpenAI from llama_index.core.llama_dataset.generator import RagDatasetGenerator
# define generator, generate questions dataset_generator = RagDatasetGenerator.from_documents( documents=documents, llm=llm, num_questions_per_chunk=10, # set the number of questions per nodes )
rag_dataset = dataset_generator.generate_questions_from_nodes() questions = [e.query for e in rag_dataset.examples]
2.6 Batch Evaluation
LlamaIndex还提供了一个批量评估运行器,用于在多个问题上运行一组评估器。
1 2 3 4 5 6 7 8 9 10
from llama_index.core.evaluation import BatchEvalRunner
from llama_index.core.llama_dataset import ( LabelledRagDataset, CreatedBy, CreatedByType, LabelledRagDataExample, )
example1 = LabelledRagDataExample( query="This is some user query.", query_by=CreatedBy(type=CreatedByType.HUMAN), reference_answer="This is a reference answer. Otherwise known as ground-truth answer.", reference_contexts=[ "This is a list", "of contexts used to", "generate the reference_answer", ], reference_by=CreatedBy(type=CreatedByType.HUMAN), )
# a sad dataset consisting of one measely example rag_dataset = LabelledRagDataset(examples=[example1])
from llama_index.core.llama_dataset.generator import RagDatasetGenerator from llama_index.llms.openai import OpenAI import nest_asyncio
nest_asyncio.apply()
documents = ... # a set of documents loaded by using for example a Reader
llm = OpenAI(model="gpt-4")
dataset_generator = RagDatasetGenerator.from_documents( documents=documents, llm=llm, num_questions_per_chunk=10, # set the number of questions per nodes )
rag_evaluator = RagEvaluatorPack( query_engine=query_engine, # built with the same source Documents as the rag_dataset rag_dataset=rag_dataset, ) benchmark_df = await rag_evaluator.run()
from llama_index.core.llama_dataset import download_llama_dataset from llama_index.core.llama_pack import download_llama_pack from llama_index.core.evaluation import CorrectnessEvaluator from llama_index.llms.gemini import Gemini