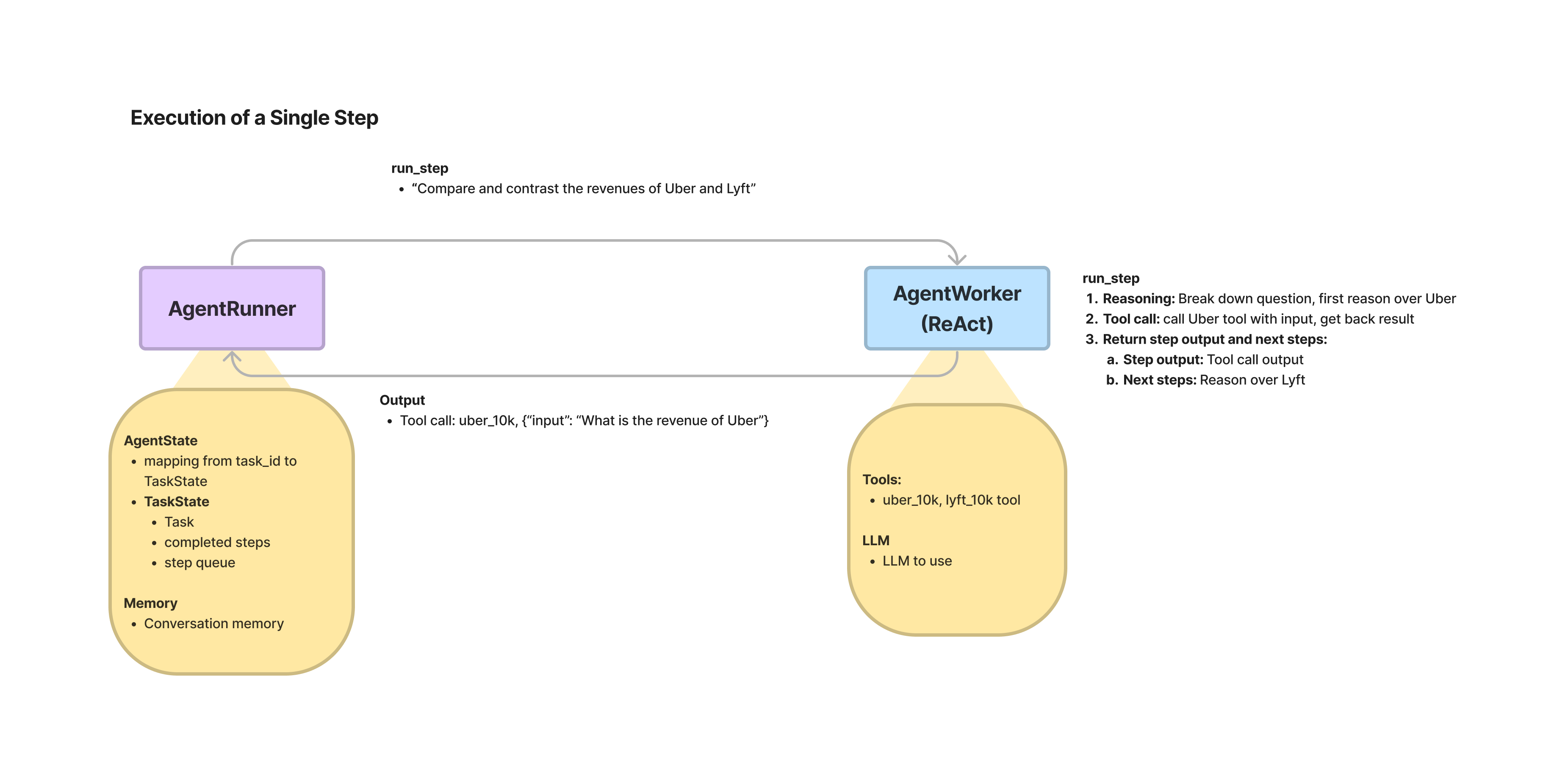
推理循环取决于Agent的类型。Function Calling Agents 在 while
循环中调用
function call API,因为工具决策逻辑已经内置在function call API
中。给定一个输入prompt和之前的聊天历史(包括之前的函数调用),function call API
将决定是否进行另一个函数调用(选择一个工具),或者返回一个assistant消息。如果
API
返回一个函数调用,那么我们就负责执行该函数并传递一个函数消息到聊天历史中。如果
API 返回一个assistant消息,那么循环就完成了。
ReAct Agent使用general text completion,因此它可以与任何
LLM 一起使用。general text completion有一个简单的
input str → output str格式,这意味着推理逻辑必须编码在提示中。ReAct
Agent使用一个受到 ReAct
论文启发的输入提示(并适应到其他版本),以决定选择哪个工具。它看起来像这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
... You have access to the following tools: {tool_desc}
To answer the question, please use the following format.
``` Thought: I need to use a tool to help me answer the question. Action: tool name (one of {tool_names}) Action Input: the input to the tool, in a JSON format representing the kwargs (e.g. {{"text": "hello world", "num_beams": 5}}) ``` Please use a valid JSON format for the action input. Do NOT do this {{'text': 'hello world', 'num_beams': 5}}.
If this format is used, you will receive a response in the following format:
``` Observation: tool response ``` ...
LlamaIndex在chat prompts上原生实现
ReAct;推理循环被实现为assistant消息和user消息交替的系列。Thought/Action/Action Input
部分被表示为assistant消息,而 Observation 部分被表示为user消息。ReAct
prompt不仅期望选择工具的名称,还期望以 JSON
格式填写工具的参数。这使得输出与 OpenAI function call API
的输出类似——主要区别在于,在function call
API的情况下,工具选择逻辑是内置在 API
本身中的(通过微调模型),而在这里则是通过明确的提示引出的。
defget_weather( location: str = Field( description="A city name and state, formatted like '<name>, <state>'" ), ) -> str: """Usfeful for getting the weather for a given location.""" ...
from llama_index.core.agent import ReActAgent from llama_index.core.tools import QueryEngineTool
# NOTE: lyft_index and uber_index are both SimpleVectorIndex instances lyft_engine = lyft_index.as_query_engine(similarity_top_k=3) uber_engine = uber_index.as_query_engine(similarity_top_k=3)
query_engine_tools = [ QueryEngineTool( query_engine=lyft_engine, metadata=ToolMetadata( name="lyft_10k", description="Provides information about Lyft financials for year 2021. " "Use a detailed plain text question as input to the tool.", ), return_direct=False, ), QueryEngineTool( query_engine=uber_engine, metadata=ToolMetadata( name="uber_10k", description="Provides information about Uber financials for year 2021. " "Use a detailed plain text question as input to the tool.", ), return_direct=False, ), ]
from llama_index.core import Document from llama_index.agent.openai_legacy import ContextRetrieverOpenAIAgent
# toy index - stores a list of Abbreviations texts = [ "Abbreviation: X = Revenue", "Abbreviation: YZ = Risk Factors", "Abbreviation: Z = Costs", ] docs = [Document(text=t) for t in texts] context_index = VectorStoreIndex.from_documents(docs)
# add context agent context_agent = ContextRetrieverOpenAIAgent.from_tools_and_retriever( query_engine_tools, context_index.as_retriever(similarity_top_k=1), verbose=True, ) response = context_agent.chat("What is the YZ of March 2022?")
4.5.3 Query Planning
OpenAI Function
Agents能够进行高级查询规划。诀窍是为Agent提供一个QueryPlanTool
-
如果Agent调用QueryPlanTool,它将被迫推断一个完整的Pydantic模式,代表对一组子工具的查询计划。
# should output a query plan to call march, june, and september tools response = agent.query( "Analyze Uber revenue growth in March, June, and September" )