最大熵模型
1.熵
决策树中已经说明。
2.最大熵模型
2.1熵的定义
假设随机变量
用
由Jensen不等式:
其中
联合熵
对于服从
条件熵
在随机变量
若
联合熵等于其中一个随机变量的熵加上另一个随机变量的条件熵,即:
相对熵
又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度等。
并约定
在一定程度上,相对熵可以度量两个随机变量的“距离”,且有
互信息
两个随机变量
互信息是一个随机变量包含另一个随机变量信息量的度量。互信息也是在给定另一个随机变量知识的条件下,原随机变量不确定度的缩减量。通过查看表达式,即可知道互信息具有对称性,同样可以简单证明得互信息的非负性。
互信息与熵的关系
由此可见,互信息
由于互信息的对称性,可得:
将
一些重要表达式:
韦恩图可以很好地表示以上各变量之间的关系,对着上面的公式,应该可以很好理解下面的图表达的含义。
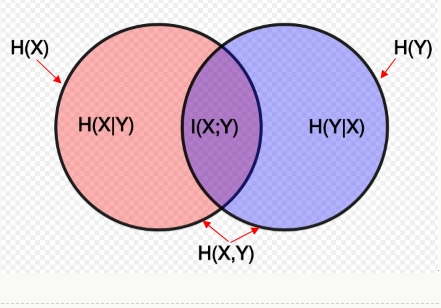
2.2最大熵模型
最大熵原理认为要选择的概率模型首先必须满足已有的事实,即约束条件。在没有更多信息的情况下,那些不确定的部分都是“等可能的”(无偏性)。“最大熵模型”的核心两点:1.承认已知事物(或知识);2.对未知事物不做任何假设,没有任何偏见。
### 2.2.1无偏原则
例如,一篇文章中出现了“学习”这个词,那这个词可以作主语、谓语、宾语。换言之,已知“学习”可能是动词,也可能是名词,故“学习”可以被标为主语、谓语、宾语、定语等等。令
如果没有其他的知识,根据信息熵的理论,概率趋向于均匀。所以有:
若我们已知“学习”被标为定语的可能性很小,只有0.05。引入这个新的知识:在满足了这个约束的情况下,其他的事件我们尽可能的让他们符合均匀分布(无偏原则):
再加入另一个约束条件:当“学习”被标作名词的时候,它被标作谓语的概率为0.95。即:
此时我们仍然坚持无偏见原则,但随着已知的知识点越来越多,其实也就是约束越来越多,求解的过程会变得越来越复杂。我们可以通过使得熵尽可能的大来保持无偏性。将上述优化及约束转化为数学公式:
且满足以下4个约束条件:
以上表达中,一般用
2.2.2最大熵模型表示
最大熵模型的一般表达式:
其中,
假设分类模型是一个条件概率分布
特征:
对于一个特征
则特征函数关于经验分布
其中
特征函数关于模型
其中
换言之,如果能够获取训练数据中的信息,那么上述这两个期望值相等,即:
上面这个等式就是最大熵模型中的限制条件,那么最大熵模型的完整提法是:
2.2.3求解最大熵模型
针对原问题,首先引入拉格朗日乘子
其中参数
按照Lagrange乘子法的思路,对参数
求得:
由于
这里
现将求得的最优解
从
2.2.4极大似然估计
极大似然估计的MLE一般形式表示为:
其中
则对于
上述式子最后结果的第二项是常数项,所以最终结果等价于:
将之前得到的最大熵的解带入MLE:
上述结果跟之前得到的对偶问题的极大化解
只差一个“-”号,所以只要把原对偶问题的极大化解也加个负号,等价转换为对偶问题的极小化解,则与极大似然估计的结果具有完全相同的目标函数。因此,最大熵模型的对偶问题的极小化等价于最大熵模型的极大似然估计。
熵是表示不确定性的度量,似然表示的是与知识的吻合程度,进一步,最大熵模型是对不确定度的无偏分配,最大似然估计则是对知识的无偏理解。 且根据MLE的正确性,可以断定:最大熵的解(无偏的对待不确定性)同时是最符合样本数据分布的解,进一步证明了最大熵模型的合理性。
2.3改进的迭代尺度法(IIS)
最大熵模型为:
对数似然函数为:
通过极大似然函数求解最大熵模型的参数,即求上述对数似然函数参数
改进的迭代尺度法IIS的核心思想是:假设最大熵模型当前的参数向量是
下面,计算参数
将上述求得的下界结果记为
把上述式子求得的
则
令偏导为0,若
若
转为
计算
将上述求解过程中得到的参数