Index是一种数据结构,它允许我们快速检索与用户查询相关的上下文。对于
LlamaIndex 来说,它是RAG的核心基础。Indexes是由Documents 构建的。它们用于构建Query Engines 和Chat
Engines ,这使得可以在数据上进行问题和答案以及聊天。Indexes将数据存储在Node对象中(这些对象代表原始文档的块),并暴露了一个Retriever接口,该接口支持额外的配置和自动化。最常见的索引是VectorStoreIndex。
一、索引的工作原理
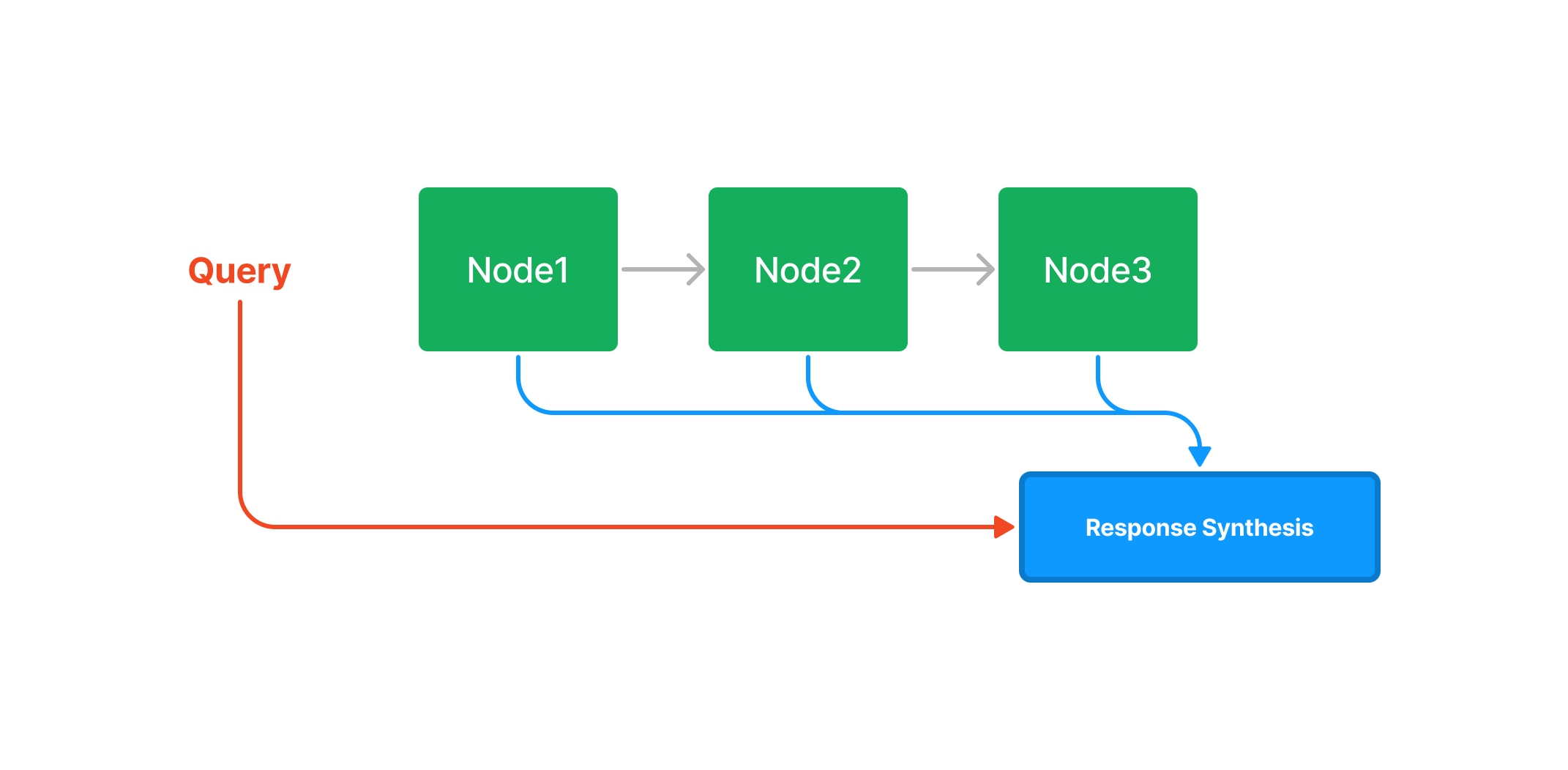
1.1 摘要索引(Summary Index)
摘要索引简单地将节点存储为一个顺序链。
查询
在查询时,如果没有指定其他查询参数,LlamaIndex
简单地将列表中的所有节点加载到响应合成模块中。
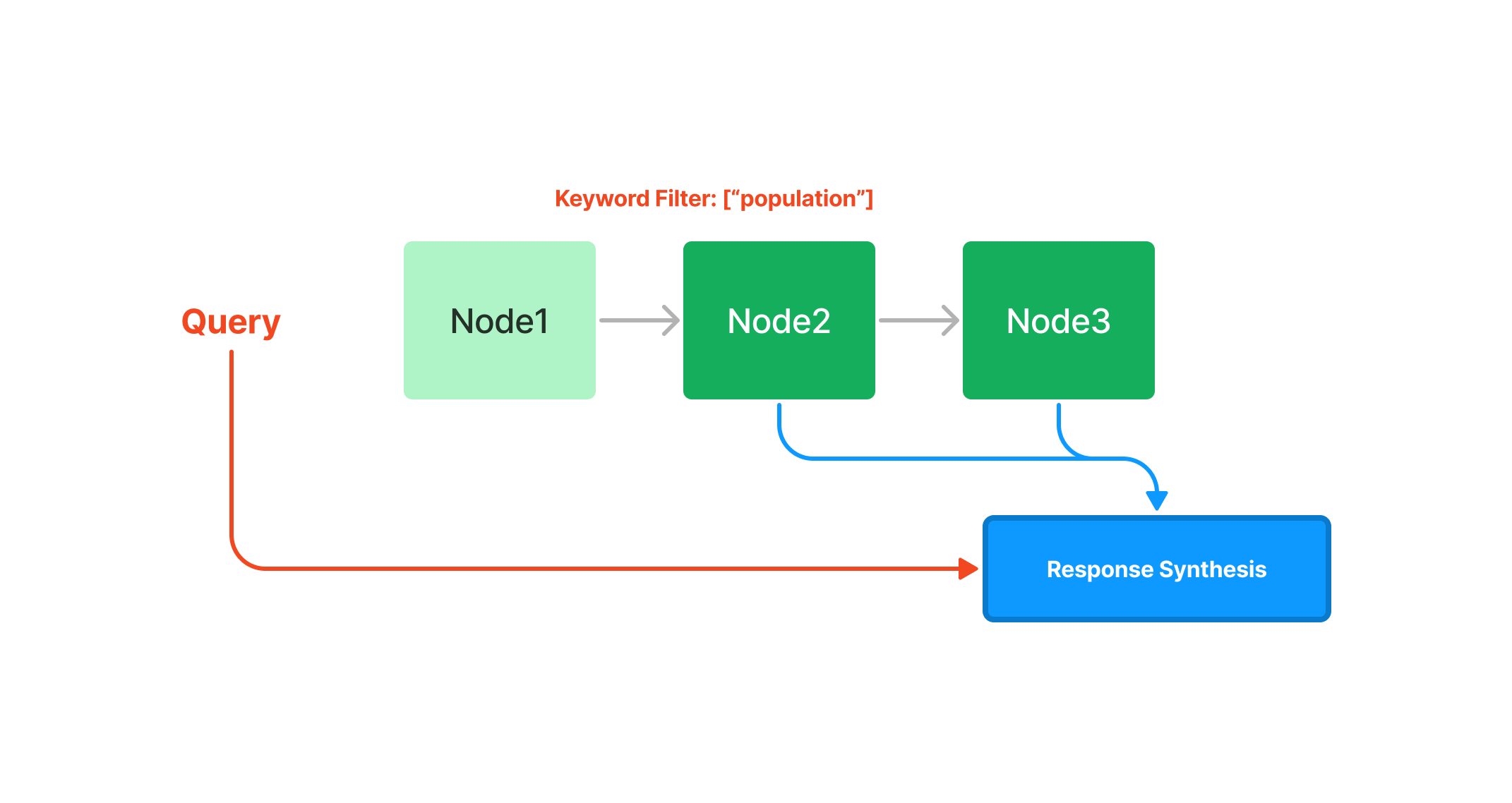
摘要索引提供了多种查询摘要索引的方法,从基于Embedding的查询(将获取前k个邻居),或添加关键词过滤器,如下所示:
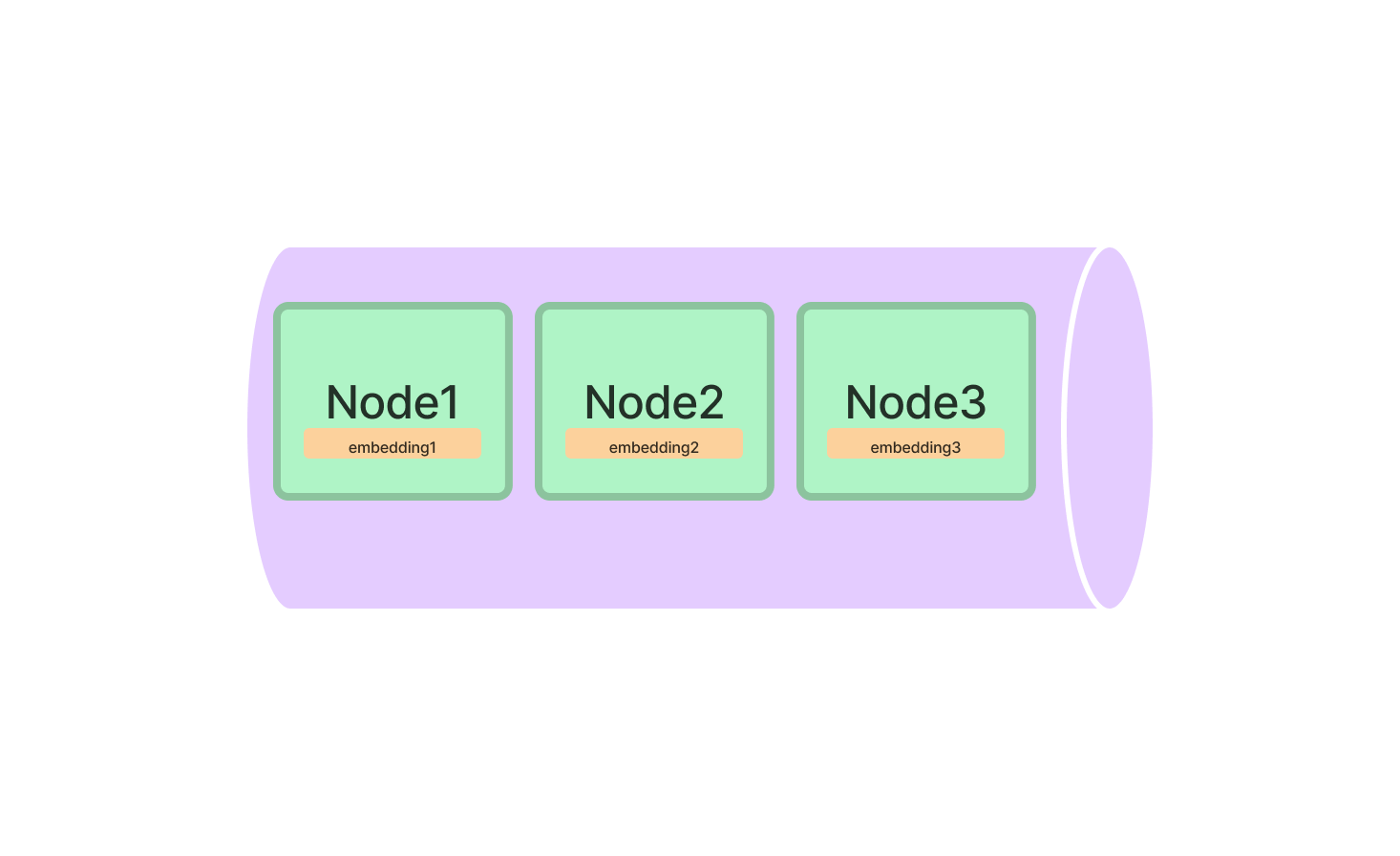
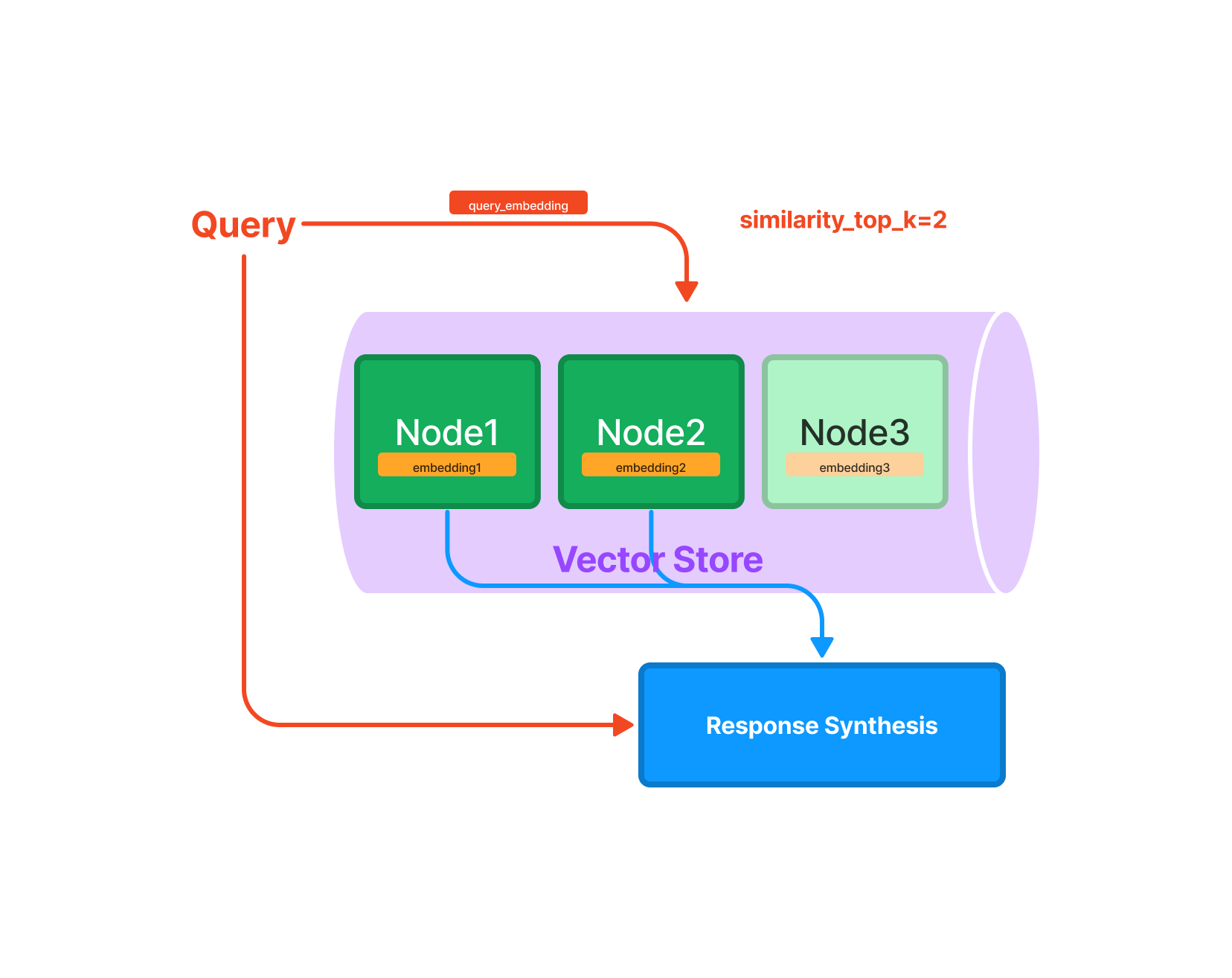
1.2 向量存储索引(Vector Store
Index)
向量存储索引在向量存储 中存储每个节点及其相应的Embedding。
查询
查询向量存储索引涉及获取与查询最相似的前k个节点,并将这些节点传递给响应合成模块。
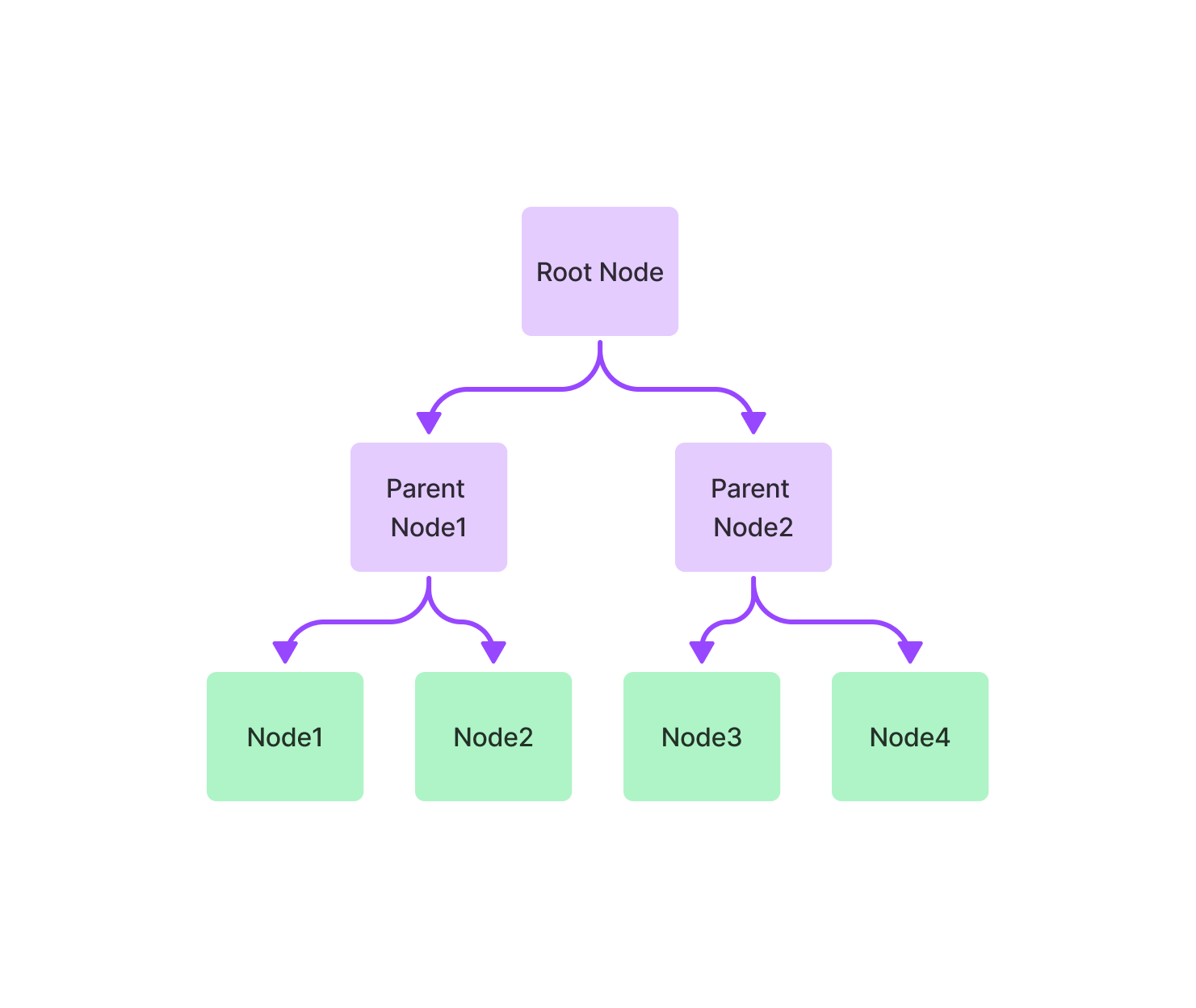
1.3 树索引(Tree Index)
树索引从一组节点(这些节点成为这棵树的叶节点)构建一个层次结构树。
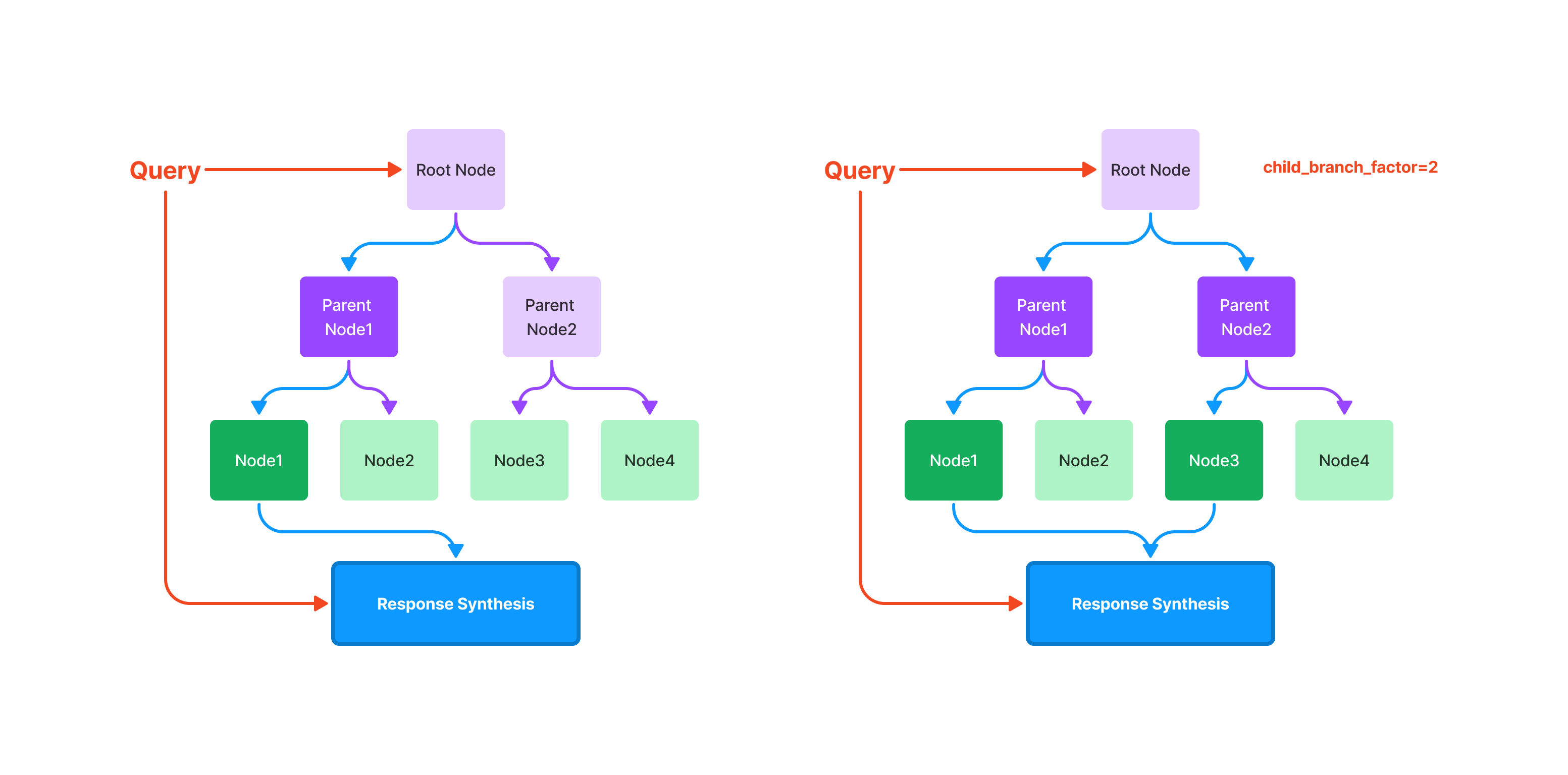
查询
查询树索引涉及从根节点遍历到叶节点。默认情况下,(child_branch_factor=1),一个查询给定一个父节点选择一个子节点。如果
child_branch_factor=2,则查询每层选择两个子节点。
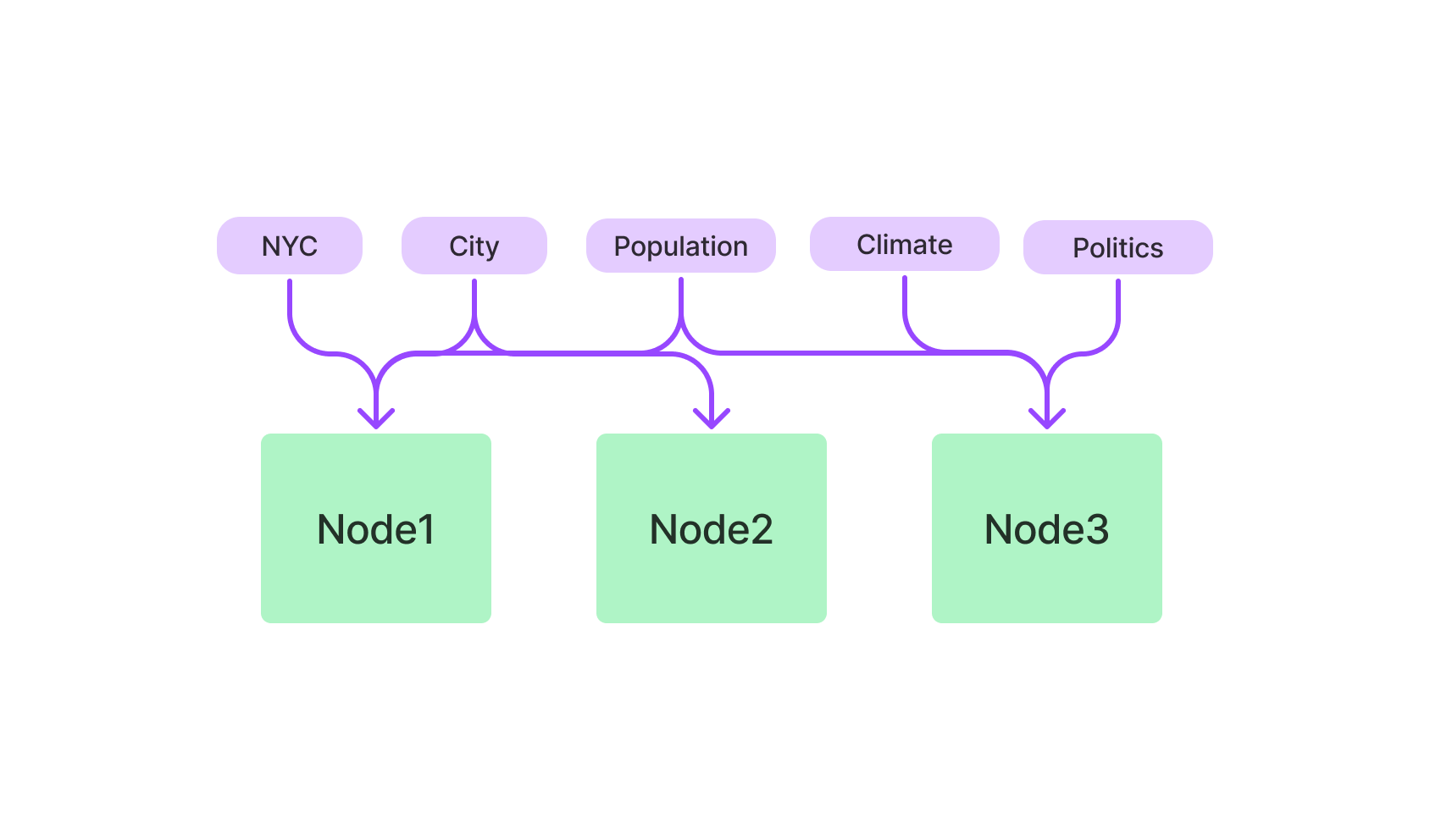
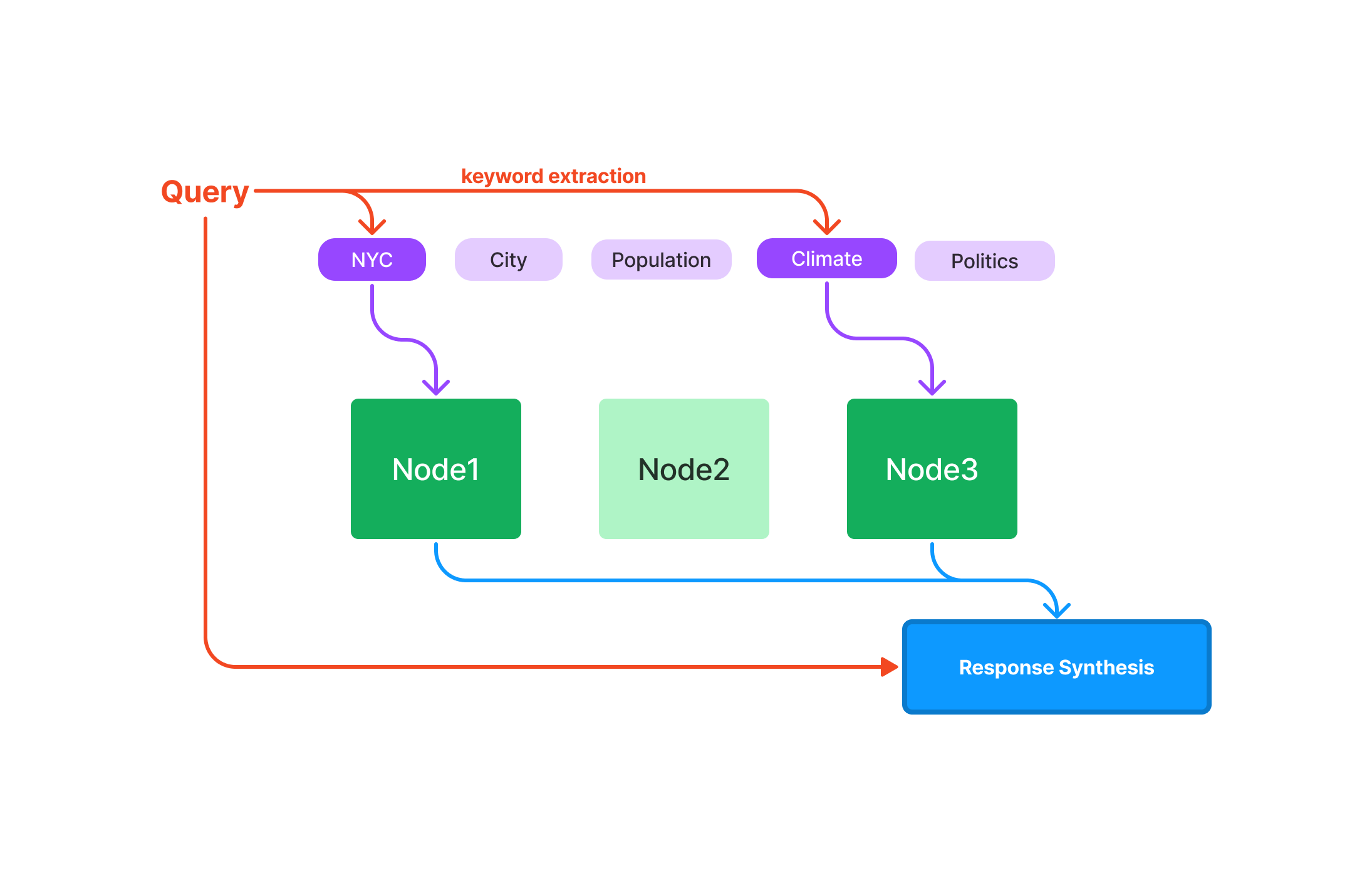
1.4 关键词表索引(Keyword Table
Index)
关键词表索引从每个节点中提取关键词,并构建一个从每个关键词到相应节点的映射。
查询
在查询时,从查询中提取相关关键词,并将其与预先提取的节点关键词匹配,以获取相应的节点。提取的节点被传递到响应合成模块。
二、VectorStoreIndex
向量存储是RAG的关键组成部分,因此在使用 LlamaIndex
构建的几乎所有应用中,都会直接或间接地使用到它们。向量存储接受一系列 Node
对象,并从它们构建索引。
2.1 加载数据到索引中
2.1.1 基本用法
使用 Vector Store 的最简单方法是加载一组文档,并使用
from_documents 从它们构建索引:
1 2 3 4 5 6 7 from llama_index.core import VectorStoreIndex, SimpleDirectoryReader"../../examples/data/paul_graham"
如果在命令行上使用 from_documents,可以使用
show_progress=True 以在索引构建期间显示进度条。使用
from_documents 时,文档会被分割成块,并解析成 Node
对象,这些是轻量级的文本字符串抽象,用于跟踪元数据和关系。
默认情况下,VectorStoreIndex
将所有内容存储在内存中,VectorStoreIndex会以每批 2048
个节点的批次生成并插入向量。如果内存受限(或者有大量的内存),可以通过传递
insert_batch_size=2048
并指定想要的批次大小来修改这个设置。
2.1.2
使用IngestionPipeline创建节点
如果想要更多地控制文档是如何被索引的,推荐使用IngestionPipeline 。这允许自定义分块、元数据和节点的Embedding。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from llama_index.core import Documentfrom llama_index.embeddings.openai import OpenAIEmbeddingfrom llama_index.core.node_parser import SentenceSplitterfrom llama_index.core.extractors import TitleExtractorfrom llama_index.core.ingestion import IngestionPipeline, IngestionCache25 , chunk_overlap=0 ),
2.1.3 直接创建和管理节点
如果想要完全控制你的索引,可以手动创建和定义节点 ,并将它们直接传递给索引构造器:
1 2 3 4 5 6 from llama_index.core.schema import TextNode"<text_chunk>" , id_="<node_id>" )"<text_chunk>" , id_="<node_id>" )
处理文档更新
直接管理索引时,处理随时间变化的数据源。索引类有插入、删除、更新和刷新操作,可以在下面了解更多关于它们的内容:
2.2 存储向量索引
LlamaIndex 支持数十种向量存储 。可以通过传递
StorageContext 并在上面指定 vector_store
参数来指定使用哪一个,如下例中使用 Pinecone:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import pineconefrom llama_index.core import (from llama_index.vector_stores.pinecone import PineconeVectorStore"<api_key>" , environment="<environment>" )"quickstart" , dimension=1536 , metric="euclidean" , pod_type="p1" "quickstart" ))"../../examples/data/paul_graham"
VectorStoreIndex 的更多示例 ,还有向量存储
2.3 可组合检索
VectorStoreIndex(以及任何其他索引/检索器)能够检索通用对象,包括
对节点的引用(references to nodes)
查询引擎(query engines)
检索器(retrievers)
查询管道(query pipelines)
如果检索到这些对象,它们将使用提供的查询自动运行。
1 2 3 4 5 6 7 8 9 10 11 from llama_index.core.schema import IndexNode"A query engine describing X, Y, and Z." ,"my_query_engine" ,True )
如果检索到包含查询引擎的索引节点,将运行查询引擎,并将结果响应作为节点返回。更多细节请查看:https://docs.llamaindex.ai/en/stable/examples/retrievers/composable_retrievers/
三、文档管理(Document
Management)
大多数 LlamaIndex 索引结构都允许插入、删除、更新和刷新操作。
3.1 插入
在构建索引后,插入一个新的文档到任何索引数据结构中。这个文档将被分解成节点,并被吸收到索引中。插入背后的机制取决于索引结构。例如,对于摘要索引,新文档被插入为列表中的附加节点。对于向量存储索引,新文档(和Embedding)被插入到底层的文档/Embedding存储中。
1 2 3 4 5 6 7 8 9 10 11 12 13 from llama_index.core import SummaryIndex, Document"text_chunk_1" , "text_chunk_2" , "text_chunk_3" ]for i, text in enumerate (text_chunks):f"doc_id_{i} " )for doc_chunk in doc_chunks:
3.2 删除
可以删除大多数索引数据结构中的文档,只需指定
document_id。(树索引当前不支持删除)。与文档对应的所有节点都将被删除。
1 index.delete_ref_doc("doc_id_0" , delete_from_docstore=True )
在使用相同文档存储的索引之间共享节点,delete_from_docstore
将默认为 False。但是,当设置为 False
时,这些节点在查询时不会被使用,因为它们将从索引的
index_struct 中删除,该索引会跟踪哪些节点可用于查询。
3.3 更新
如果文档已经在索引中存在,可以更新具有相同 doc_id
的文档(例如,如果文档中的信息已更改)。
1 2 3 4 5 6 0 ].text = "Brand new document text" 0 ],"delete_kwargs" : {"delete_from_docstore" : True }},
可以传递了一些额外的 kwargs 以确保文档从 docstore 中删除。
3.4 刷新
如果在加载数据时设置了每个文档的
doc_id,可以自动刷新索引。refresh()
函数将只更新具有相同
doc_id但文本内容不同的文档。任何在索引中完全不存在文档将被插入。refresh()
还返回一个布尔列表,指示输入中的哪些文档已在索引中刷新。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 0 ] = Document(text="Super new document text" , id_="doc_id_0" )"This isn't in the index yet, but it will be soon!" ,"doc_id_3" ,"delete_kwargs" : {"delete_from_docstore" : True }}print (refreshed_docs)
使用 SimpleDirectoryReader 时设置
filename_as_id 标志就可以自动设置 doc_id。
3.5 文档跟踪
任何使用 docstore
的索引(即除大多数向量存储集成之外的所有索引),还可以查看已插入到
docstore 中的文档。
1 2 3 4 5 6 7 print (index.ref_doc_info)""" > {'doc_id_1': RefDocInfo(node_ids=['071a66a8-3c47-49ad-84fa-7010c6277479'], metadata={}), 'doc_id_2': RefDocInfo(node_ids=['9563e84b-f934-41c3-acfd-22e88492c869'], metadata={}), 'doc_id_0': RefDocInfo(node_ids=['b53e6c2f-16f7-4024-af4c-42890e945f36'], metadata={}), 'doc_id_3': RefDocInfo(node_ids=['6bedb29f-15db-4c7c-9885-7490e10aa33f'], metadata={})} """
输出中的每个条目都以 doc_id
作为键,以及它们被拆分成的节点的关联
node_ids。最后,还跟踪了每个输入文档的原始元数据字典。
四、LlamaCloudIndex +
LlamaCloudRetriever
LlamaCloud 是新一代的托管解析、提取和检索服务,旨在为 LLM和
RAG应用带来生产级别的上下文增强。
目前,LlamaCloud 支持:
托管Ingestion API,处理解析和文档管理
托管Retrieval API,为RAG 系统配置最佳检索
4.1 使用
LlamaCloud 登录并获取 API
密钥。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import os"LLAMA_CLOUD_API_KEY" "llx-..." from llama_index.core import SimpleDirectoryReaderfrom llama_index.indices.managed.llama_cloud import LlamaCloudIndex"my_first_index" ,"default" ,"llx-..." ,True ,"my_first_index" , project_name="default" )
托管检索配置检索器
1 2 3 4 5 6 7 from llama_index.indices.managed.llama_cloud import LlamaCloudRetriever"my_first_index" , project_name="default" )
可以使用其他索引快捷方式来利用新托管索引:
1 2 3 query_engine = index.as_query_engine(llm=llm)
4.2 检索器设置
以下是检索器 settings/kwargs 的完整列表:
dense_similarity_top_k: Optional[int] – 如果大于
0,使用密集检索检索 k 个节点sparse_similarity_top_k: Optional[int] – 如果大于
0,使用稀疏检索检索 k 个节点enable_reranking: Optional[bool] –
是否启用重新排名。为了准确性牺牲一些速度rerank_top_n: Optional[int] –
重新排名初始检索结果后返回的节点数量alpha Optional[float] – 密集和稀疏检索之间的权重。1 =
完全密集检索,0 = 完全稀疏检索
在许多情况下,特别是对于长篇文档,文本片段可能缺乏必要的上下文信息,以区分该片段与其他相似文本片段。为了解决这个问题,使用LLM提取与文档相关的某些上下文信息,以更好地帮助检索和语言模型区分看起来相似的段落。
完整例子
5.1 使用
首先,定义一个元数据提取器,它接受一个特征提取器的列表,这些特征提取器将按顺序处理。
然后,将这些信息输入到节点解析器中,节点解析器会为每个节点添加额外的元数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from llama_index.core.node_parser import SentenceSplitterfrom llama_index.core.extractors import (from llama_index.extractors.entity import EntityExtractor5 ),3 ),"prev" , "self" ]),10 ),0.5 ),
然后,可以在输入文档或节点上运行转换
1 2 3 4 5 from llama_index.core.ingestion import IngestionPipeline
5.2 自定义提取器
如果提供的提取器不符合需求,也可以像这样定义一个自定义提取器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from llama_index.core.extractors import BaseExtractorclass CustomExtractor (BaseExtractor ):async def aextract (self, nodes ) -> List [Dict ]:"custom" : node.metadata["document_title" ]"\n" "excerpt_keywords" ]for node in nodesreturn metadata_list
extractor.extract() 将自动调用
aextract(),以提供同步和异步入口。
在更高级的例子中,可以利用 LLM 从节点内容和现有元数据中提取特征。
官方资源