import random from http import HTTPStatus from dashscope import Generation from pdfminer.high_level import extract_pages from pdfminer.layout import LTTextContainer
defextract_text_from_pdf(filename, page_numbers=None, min_line_length=1): '''从 PDF 文件中(按指定页码)提取文字''' paragraphs = [] buffer = '' full_text = '' # 提取全部文本 for i, page_layout inenumerate(extract_pages(filename)): # 如果指定了页码范围,跳过范围外的页 if page_numbers isnotNoneand i notin page_numbers: continue for element in page_layout: ifisinstance(element, LTTextContainer): full_text += element.get_text() + '\n' # 按空行分隔,将文本重新组织成段落 lines = full_text.split('\n') for text in lines: iflen(text) >= min_line_length: buffer += (' '+text) ifnot text.endswith('-') else text.strip('-') elif buffer: paragraphs.append(buffer) buffer = '' if buffer: paragraphs.append(buffer) return paragraphs
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron∗ Louis Martin† Kevin Stone† Peter Albert Amjad Almahairi Yasmine Babaei Nikolay Bashlykov Soumya Batra Prajjwal Bhargava Shruti Bhosale Dan Bikel Lukas Blecher Cristian Canton Ferrer Moya Chen Guillem Cucurull David Esiobu Jude Fernandes Jeremy Fu Wenyin Fu Brian Fuller Cynthia Gao Vedanuj Goswami Naman Goyal Anthony Hartshorn Saghar Hosseini Rui Hou Hakan Inan Marcin Kardas Viktor Kerkez Madian Khabsa Isabel Kloumann Artem Korenev Punit Singh Koura Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich Yinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra Igor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi Alan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang Ross Taylor Adina Williams Jian Xiang Kuan Puxin Xu Zheng Yan Iliyan Zarov Yuchen Zhang Angela Fan Melanie Kambadur Sharan Narang Aurelien Rodriguez Robert Stojnic Sergey Edunov Thomas Scialom∗
from elasticsearch7 import Elasticsearch, helpers from nltk.stem import PorterStemmer from nltk.tokenize import word_tokenize from nltk.corpus import stopwords import nltk import re
import warnings warnings.simplefilter("ignore") # 屏蔽 ES 的一些Warnings
# 3. 如果索引已存在,删除它(仅供演示,实际应用时不需要这步) if es.indices.exists(index=index_name): es.indices.delete(index=index_name)
# 4. 创建索引 es.indices.create(index=index_name)
# 5. 灌库指令 actions = [ { "_index": index_name, "_source": { "keywords": to_keywords(para), "text": para } } for para in paragraphs ]
# 6. 文本灌库 helpers.bulk(es, actions)
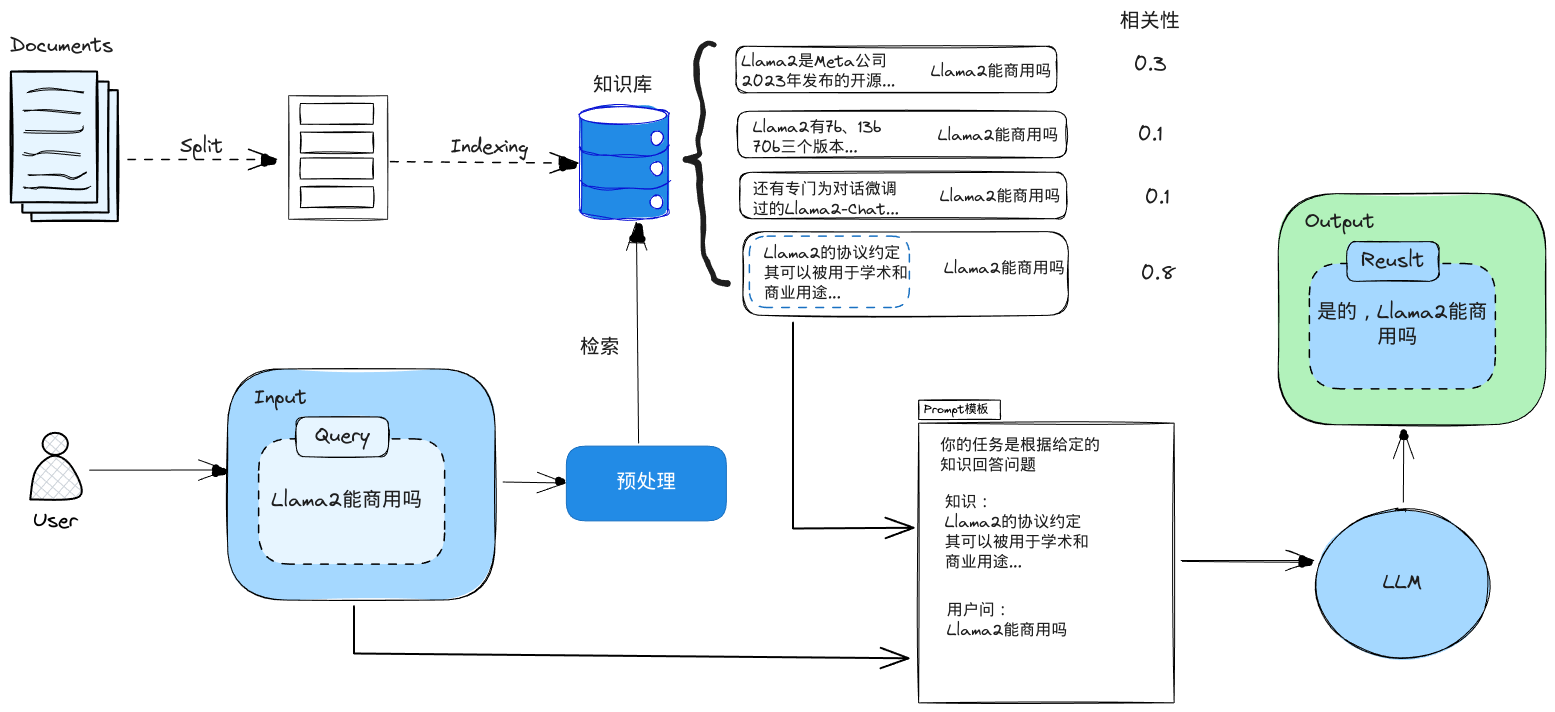
实现关键字检索
1 2 3 4 5 6 7 8 9 10 11 12 13
defsearch(query_string, top_n=3): # ES 的查询语言 search_query = { "match": { "keywords": to_keywords(query_string) } } res = es.search(index=index_name, query=search_query, size=top_n) return [hit["_source"]["text"] for hit in res["hits"]["hits"]]
results = search("how many parameters does llama 2 have?", 2) for r in results: print(r+"\n")
▶
输出
1 2 3
1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper but are not releasing.§
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7billion to 70billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based onour human evaluations for helpfulness and safety, may be a suitable substitute for closed source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
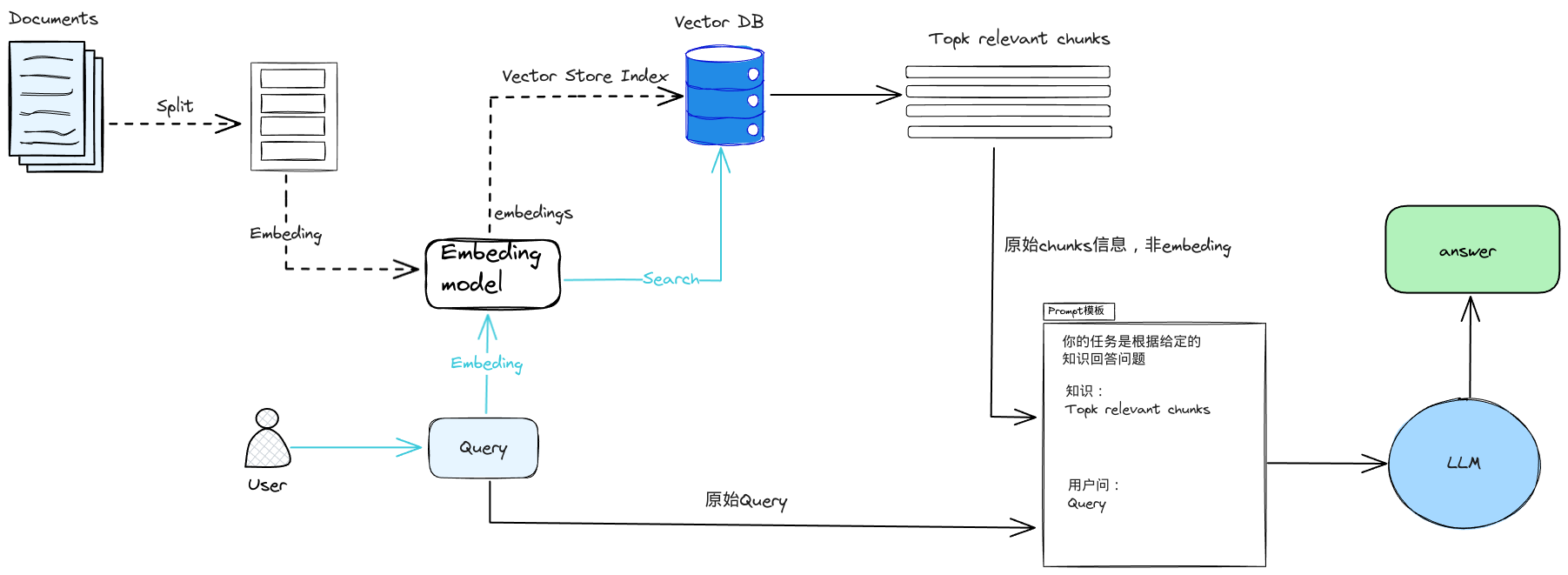
defbuild_prompt(prompt_template, **kwargs): '''将 Prompt 模板赋值''' prompt = prompt_template for k, v in kwargs.items(): ifisinstance(v, str): val = v elifisinstance(v, list) andall(isinstance(elem, str) for elem in v): val = '\n'.join(v) else: val = str(v) prompt = prompt.replace(f"__{k.upper()}__", val) return prompt
已知信息: 1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper but are not releasing.§ In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7billion to 70billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based onour human evaluations for helpfulness and safety, may be a suitable substitute for closed source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
# user_query="Does llama 2 have a chat version?" user_query = "Does llama 2 have a conversational variant?"
search_results = search(user_query, 2)
for res in search_results: print(res+"\n")# user_query="Does llama 2 have a chat version?" user_query = "Does llama 2 have a conversational variant?"
search_results = search(user_query, 2)
for res in search_results: print(res+"\n")
输出
1 2 3
1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper but are not releasing.§
variants of this model with 7B, 13B, and 70B parameters as well.
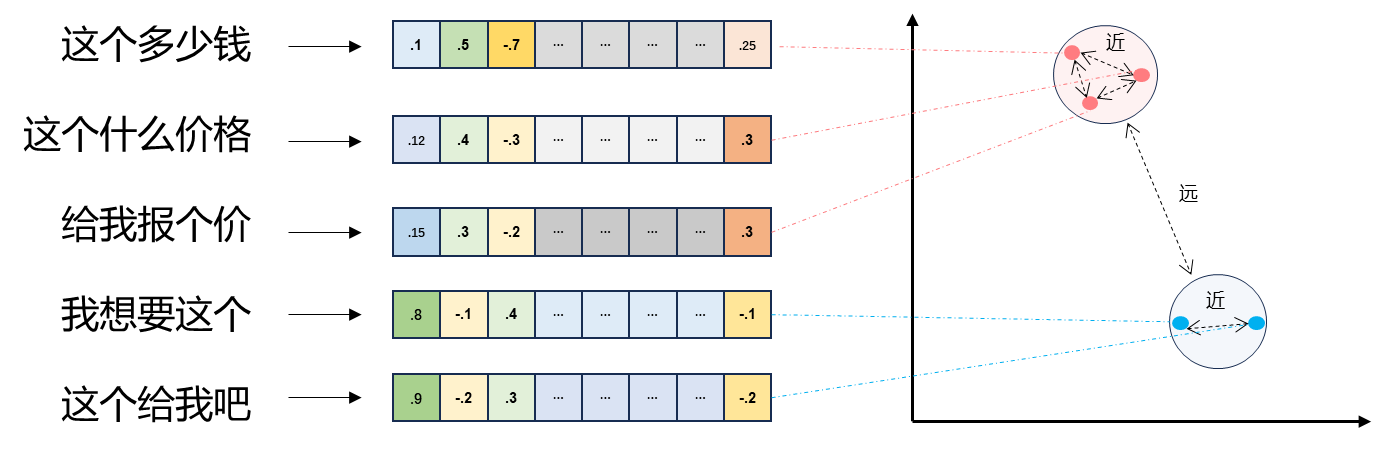
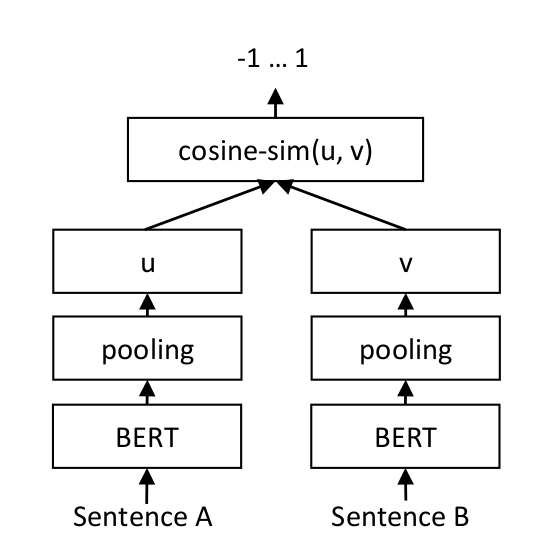
defl2(a, b): '''欧式距离 -- 越小越相似''' x = np.asarray(a)-np.asarray(b) return norm(x)
#通义前文embeding模型 defget_embedings(texts): resp = dashscope.TextEmbedding.call( model=dashscope.TextEmbedding.Models.text_embedding_v2, input=texts) return [x.embedding for x in resp]
for para in results['documents'][0]: print(para+"\n")
▶
输出
1 2 3
1. Llama 2, an updated versionof Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2with7B, 13B, and70B parameters. We have also trained 34B variants, which we report onin this paper but are not releasing.§
In this work, we develop andrelease Llama 2, a familyof pretrained and fine-tuned LLMs, Llama 2and Llama 2-Chat, at scales up to70B parameters. On the series of helpfulness and safety benchmarks we tested, Llama 2-Chat models generally perform better than existing open-source models. They also appear to be on par withsomeof the closed-source models, at least on the human evaluations we performed (see Figures 1and3). We have taken measures to increase the safety of these models, using safety-specific data annotation and tuning, as well as conducting red-teaming and employing iterative evaluations. Additionally, this paper contributes a thorough description of our fine-tuning methodology and approach to improving LLM safety. We hope that this openness will enable the community to reproduce fine-tuned LLMs andcontinueto improve the safety of those models, paving the way for more responsible development of LLMs. We alsoshare novel observations we made during the development of Llama 2and Llama 2-Chat, such as the emergence of tool usageand temporal organization of knowledge.
from openai import OpenAI # 加载环境变量 from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEY
client = OpenAI()
defget_embeddings(texts, model="text-embedding-ada-002", dimensions=None): '''封装 OpenAI 的 Embedding 模型接口''' if model == "text-embedding-ada-002": dimensions = None if dimensions: data = client.embeddings.create( input=texts, model=model, dimensions=dimensions).data else: data = client.embeddings.create(input=texts, model=model).data return [x.embedding for x in data]
for doc in search_results['documents'][0]: print(doc+"\n")
print("====回复====") bot.chat(user_query)
▶
输出
1 2 3 4 5 6
We believe that the openreleaseof LLMs, when done safely, will be a net benefit to society. Likeall LLMs, Llama 2is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021; Solaiman et al., 2023). Testing conducted todate has been in English and has not — and could not — cover all scenarios. Therefore, before deploying any applications of Llama 2-Chat, developers should perform safety testing and tuning tailored to their specific applications of the model. We provide a responsible use guide¶ and code examples‖ to facilitate the safe deployment of Llama 2and Llama 2-Chat. More details of our responsible release strategy can be foundin Section 5.3.
In this work, we develop andrelease Llama 2, a familyof pretrained and fine-tuned LLMs, Llama 2and Llama 2-Chat, at scales up to70B parameters. On the series of helpfulness and safety benchmarks we tested, Llama 2-Chat models generally perform better than existing open-source models. They also appear to be on par withsomeof the closed-source models, at least on the human evaluations we performed (see Figures 1and3). We have taken measures to increase the safety of these models, using safety-specific data annotation and tuning, as well as conducting red-teaming and employing iterative evaluations. Additionally, this paper contributes a thorough description of our fine-tuning methodology and approach to improving LLM safety. We hope that this openness will enable the community to reproduce fine-tuned LLMs andcontinueto improve the safety of those models, paving the way for more responsible development of LLMs. We alsoshare novel observations we made during the development of Llama 2and Llama 2-Chat, such as the emergence of tool usageand temporal organization of knowledge.
2. Llama 2-Chat, a fine-tuned versionof Llama 2 that is optimized for dialogue use cases. We release variants of this model with7B, 13B, and70B parameters as well. We believe that the openreleaseof LLMs, when done safely, will be a net benefit to society.
We are releasing the following models to the general publicfor research and commercial use‡: 1. Llama 2, an updated versionof Llama 1, trained on a new mix of publicly available data.
We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs, Llama 2 is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021; Solaiman et al., 2023).
We also share novel observations we made during the development of Llama 2and Llama 2-Chat, such as the emergence of tool usage and temporal organization of knowledge. Figure 3: Safety human evaluation results for Llama 2-Chat compared to other open-source and closed source models.
In this work, we develop and release Llama 2, a family of pretrained and fine-tuned LLMs, Llama 2and Llama 2-Chat, atscales up to 70B parameters. On the series of helpfulness and safety benchmarks we tested, Llama 2-Chat models generally perform better than existing open-source models.
Additionally, these safety evaluations are performed using content standards that are likely to be biased towards the Llama 2-Chat models. We are releasing the following models to the general public for research and commercial use‡: 1.
We provide a responsible use guide¶ and code examples‖ to facilitate the safe deployment of Llama 2and Llama 2-Chat. More details of our responsible release strategy can be found in Section 5.3.
====回复==== Llama 2的安全性在人类评估中有所体现,但所有LLMs,包括Llama 2,都存在潜在风险(Bender et al., 2021b; Weidinger et al., 2021; Solaiman et al., 2023)。具体到Llama 2-Chat,图3展示了与开源和闭源模型相比的安全性结果。然而,没有提供详细的比较或分数,所以我无法直接告诉你Llama 2的整体安全等级。建议参考相关研究或最新的人类评估报告来了解其安全性情况。
方案:
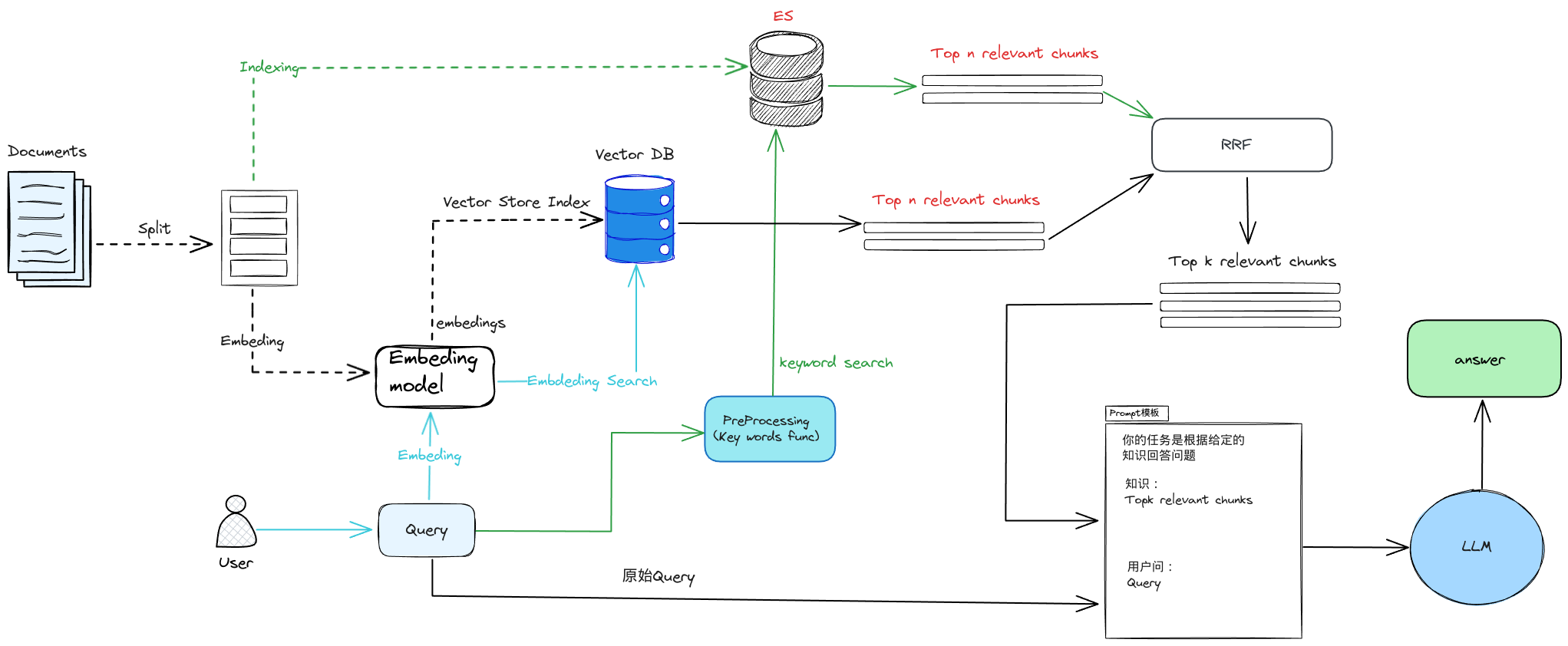
检索时多召回一部分文本
通过一个排序模型对 query 和 document 重新打分排序
机制如下
RAG ReRanker实现
1 2 3 4 5 6 7 8 9 10 11 12 13
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2', max_length=512) #huggingface下载对应模型
user_query = "how safe is llama 2"
scores = model.predict([(user_query, doc) for doc in search_results['documents'][0]]) # 按得分排序 sorted_list = sorted( zip(scores, search_results['documents'][0]), key=lambda x: x[0], reverse=True) for score, doc in sorted_list: print(f"{score}\t{doc}\n")
▶
输出
1 2 3 4 5 6 7 8 9
6.613733291625977 We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs, Llama 2 is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021; Solaiman et al., 2023).
5.310719013214111 In this work, we develop and release Llama 2, a family of pretrained and fine-tuned LLMs, Llama 2and Llama 2-Chat, atscales up to 70B parameters. On the series of helpfulness and safety benchmarks we tested, Llama 2-Chat models generally perform better than existing open-source models.
4.709953308105469 We provide a responsible use guide¶ and code examples‖ to facilitate the safe deployment of Llama 2and Llama 2-Chat. More details of our responsible release strategy can be found in Section 5.3.
4.5439653396606445 We also share novel observations we made during the development of Llama 2and Llama 2-Chat, such as the emergence of tool usage and temporal organization of knowledge. Figure 3: Safety human evaluation results for Llama 2-Chat compared to other open-source and closed source models.
4.03388786315918Additionally, these safety evaluations are performed using content standards that are likely to be biased towards the Llama 2-Chat models. We are releasing the following models to the general public for research and commercial use‡: 1.