CTM——Continuous Thought Machine
一、CTM 是什么
Continuous Thought Machine(连续思维机) 是由 Sakana AI 提出的一种全新神经网络架构。它的核心理念是:思考需要时间,推理是一个过程。
与当代神经网络将神经元活动抽象为单一静态值(如 ReLU 激活函数)不同,CTM 将神经动力学(Neural Dynamics)——即神经元活动随时间演化的复杂模式——作为其核心计算机制。CTM 通过神经元之间的同步化(Synchronization)来与世界交互,产生观察和做出预测。
论文:Continuous Thought Machines (arXiv:2505.05522) 项目主页:pub.sakana.ai/ctm GitHub:SakanaAI/continuous-thought-machines ⭐ 1.9k | Fork 289 许可证:Apache-2.0
1.1 为什么要做这项研究?
神经网络最初是受生物大脑启发的,但它们与生物大脑之间仍存在显著差异。生物大脑展现出复杂的神经动力学,这些动力学随时间演化,但现代神经网络为了方便大规模深度学习,有意地抽象掉了这种时间动态。
经过数亿年的进化,生物大脑拥有了丰富的神经动力学机制,包括:
- STDP(脉冲时间依赖可塑性)
- 神经振荡(Neuronal Oscillations)
现代 AI 在许多领域表现优异,但人类认知的灵活性和通用性与当前 AI 之间仍存在差距。CTM 的作者认为,时间应该成为人工智能的核心组成部分,才能最终达到与人类大脑匹敌甚至超越的能力水平。
1.2 三大核心贡献
CTM 提出了三项关键创新:
| 创新 | 描述 |
|---|---|
| 解耦的内部时间维度 | 引入一个与输入数据完全解耦的内部”思维”维度,使神经元活动能够在其上展开 |
| 神经元级别模型(NLM) | 每个神经元拥有独立的私有权重参数,处理传入信号的历史记录来产生激活 |
| 同步化作为表征 | 直接使用神经元活动的同步化矩阵作为潜在表征,用于观察数据和产生输出 |
1.3 与推理模型和递归的关系
当前 AI 前沿面临一个关键转折:从简单的输入-输出映射转向真正的推理能力。递归(Recurrence)正重新成为扩展模型复杂性的自然途径——现代文本生成模型(有时称为”推理模型”)使用中间生成作为递归的一种形式,在测试时启用额外的计算。
CTM 与现有方法的三个关键区别:
- 解耦的内部维度——使得对任何数据模态都可以进行顺序思考
- 私有的神经元级别模型——使得可以考虑精确的神经时序
- 神经同步化作为表征——直接用于解决任务
二、Method 方法论
CTM 是一种神经网络架构,它通过显式地将神经动力学作为核心功能组件,从根本上偏离了传统的前馈模型。
视频展示连续思维机器:其内部循环过程中的一个步骤。连续思维机器 (CTM) 是一种神经网络架构,它提供了一种全新的数据思维方式。与传统的前馈模型不同,CTM 将神经动力学的概念明确地融入其功能的核心。上面的视频以图示的方式概述了 CTM 的内部工作原理。
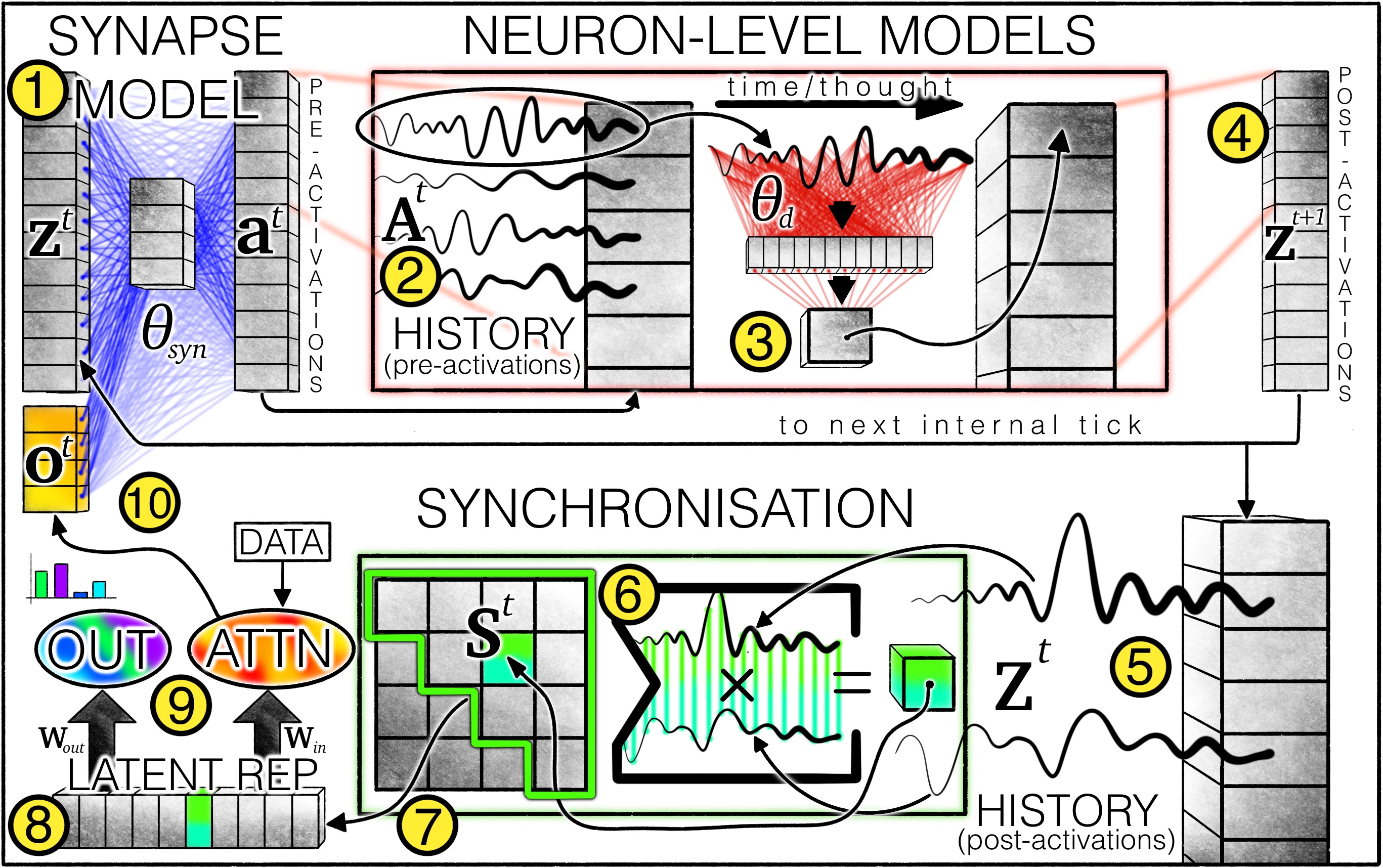
CTM 架构:①突触模型(权重以蓝线表示)模拟神经元间的交互作用,从而产生预激活。对于每个神经元,②都会保留一段预激活历史记录,其中最新的预激活被③神经元级模型(权重以红线表示)用于产生④后激活。⑤后激活历史记录也会被保留,并用于⑥计算同步矩阵。神经元对⑦从同步矩阵中选择,从而产生⑧潜在表征,CTM⑨利用这些潜在表征生成输出,并通过交叉注意力机制调节数据。调节后的数据(例如,注意力输出)⑩与后激活连接起来,用于下一个内部时钟周期。
| Variable | Description |
|---|---|
| 在内部时钟 |
|
| 循环(突触)模型权重;类似 U-NET 的架构,在给定的内部滴答时间 |
|
| 内部滴答时间 |
|
| 最近的预激活历史记录,设计为 FIFO 列表,使其长度始终为 |
|
| 单个神经元级模型的权重, |
|
| 截至当前内部时钟周期的所有激活后历史记录,长度可变;用作同步点积的输入。 | |
| 内部时钟周期 |
|
| 分别从 |
|
| 交叉注意力输出。 |
CTM 由三个核心思想组成:
- 利用内部循环,可以构建一个类似于思维的概念发生的维度。上方视频中展示的整个过程仅需一次迭代;页面顶部的交互式迷宫演示则使用了 75 次迭代。这种循环与任何数据维度完全无关。
- 神经元级模型,通过将私有(即,基于每个神经元)MLP 模型应用于传入的预激活历史来计算后激活。
- 同步性作为一种表征方式,通过追踪神经元活动随时间的变化,计算神经元对之间随时间推移的同步程度。这种同步性度量是 CTM 执行操作和进行预测所依据的表征。
虽然数据对于任何建模来说无疑都至关重要,但 CTM 的设计理念是内部重复和同步,其中数据的作用在某种程度上是次要的,而内部过程本身的作用才是最重要的。输入数据会根据当前的同步情况在每个内部滴答中被处理和摄取,预测也是如此。
思考 ImageNet 时的神经动力学:每个子图代表单个神经元随时间变化的活动。正是这些神经元之间的同步性构成了 CTM 使用的表征。
2.1 Internal Ticks(内部时钟)——“思维”维度
CTM 引入了一个连续的内部维度:
与传统的序列模型(如 RNN 或 Transformer)按数据固有序列(如句子中的词、视频中的帧)逐步处理输入不同,CTM 沿着一条自生成的内部思维步骤时间线运作。这种内部展开允许模型迭代地构建和精炼其表征,即使在处理静态或非序列数据(如图像或迷宫)时也是如此。
CTM 的内部维度是神经活动动力学可以展开的维度。我们相信这种动力学可能是智能思维的基石。
关键特点:
- 内部时间步称为 “internal ticks”
- 该维度完全与数据维度解耦
- 允许模型对任何类型的数据进行迭代思考
2.2 Synapse Model(突触模型)——递归权重
一个递归的 MLP(以 U-NET 方式构建)充当 CTM
的突触模型。在任意内部时刻
其中
2.3 Neuron-Level Models(神经元级别模型)
其中:
是神经元 的独有参数 是包含所有后激活的向量中的一个单元 是一个 维向量(时间序列)
所有神经元的后激活与注意力输出连接起来,并循环输入到
这是一个非常关键的设计——每个神经元都有自己的私有模型,而不是所有神经元共享同一个激活函数(如 ReLU)。这使得 CTM 能够模拟生物大脑中每个神经元独特的放电模式。
2.4 Synchronization(同步化表征)
CTM 如何与外部世界交互?答案是神经同步化。
首先,后激活被收集到后激活”历史”中:
神经同步化定义为后激活历史的内积矩阵:
由于该矩阵以
— 用于输出预测 — 用于与数据交互(如注意力查询)
将
随着模型宽度
增长时,同步化表征以 的速度增长,这为提高表达能力提供了机会,而无需更多参数即可将潜在空间投影到这种大小。
调制输入数据
其中
在大多数实验中,CTM 使用标准的交叉注意力(Cross Attention)来从输入数据中提取信息:
其中 FeatureExtractor(如
ResNet)首先用于构建有用的局部特征作为键和值。
2.5 损失函数
CTM 在每个内部时刻
以及相应的确定性度量
一个自然而然的问题随之而来:我们应该如何将
— 最小损失点 — 最大确定性点
这种方法的优势在于,CTM 可以在多个内部时钟周期内执行有意义的计算,自然而然地促进课程效应,并使 CTM 能够根据问题难度调整计算。最终损失计算如下:
这种设计的优势: 1. CTM 可以在多个内部时刻执行有意义的计算 2. 自然形成课程效应(Curriculum Effect) 3. 使 CTM 能够根据问题难度调整计算量
三、实验结果
CTM 在多个极具挑战性的任务上展示了其强大的性能和多功能性。
3.1 ImageNet 图像分类
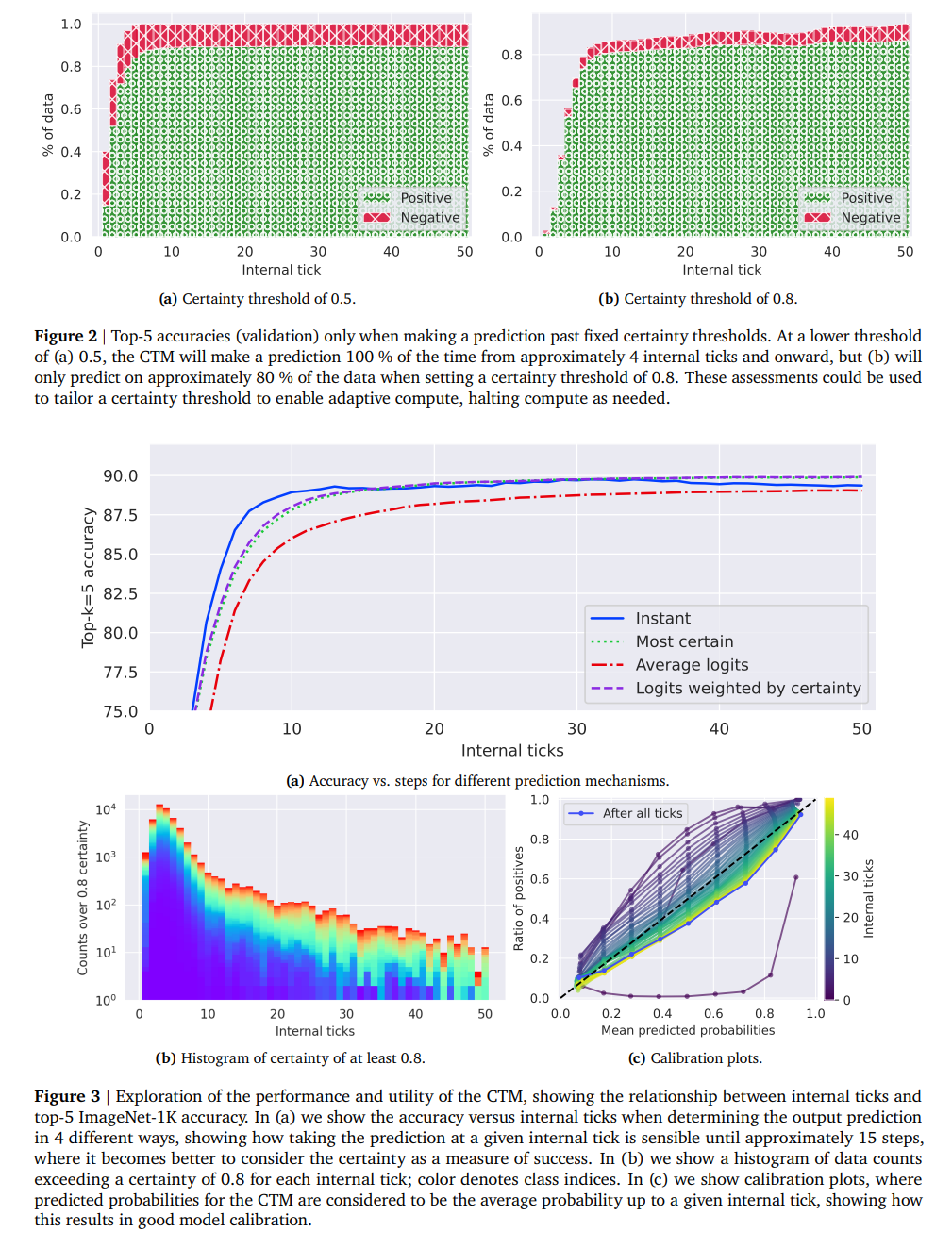
CTM 启用了自适应计算(Adaptive Compute),内部步骤(即 CTM 投入到问题中的”思考量”)可以提前截断。实验表明,超过某个阈值后仅有边际增益,但增益仍然存在。
关键发现:
- CTM 在推理过程中会环顾图像,逐步建立预测
- 注意力权重展示了 CTM 在 16 个头上关注图像不同区域的过程
- 所有这些都使用神经活动的同步化直接作为表征
CTM 从未设定要在 ImageNet 上取得某个新的 SOTA 性能。相反,研究者想展示 CTM 与数据交互的方式有多么不同和有趣。
3.2 迷宫求解
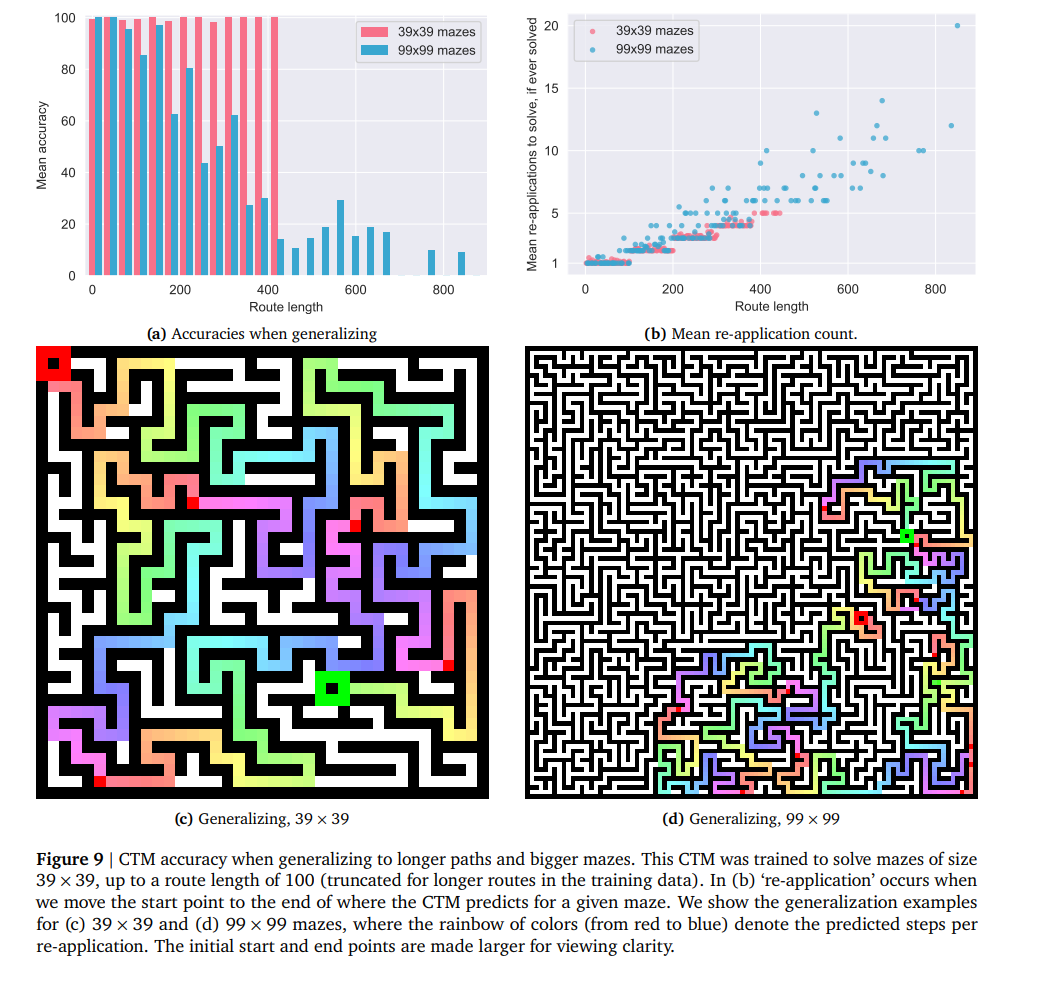
解决迷宫对机器来说是一项极具挑战性的任务——只有当前最前沿的模型才能在相当简单的迷宫上表现良好,而且通常需要精心设计数据/目标或大量工具使用。
CTM 的迷宫实验设置:
- 直接预测从起点到终点的路径(截断形式),步骤为:左、右、上、下、等待
- 不使用位置编码——CTM 必须构建内部世界模型来查询数据和导航迷宫
- 注意力模式直观地跟随解决方案路径
- 甚至能泛化到超出截断路径的长度!
泛化能力: 使用在 39×39 迷宫上训练的 CTM(路径长度上限 100),在 99×99 迷宫上仍保持推理能力,完整路径约长 6 倍。
世界模型(World Model):通过不使用位置编码,CTM 必须”临场”构建内部世界模型。它能如此令人信服地做到这一点,这一事实本身就非常了不起。
3.3 奇偶校验任务(Parity Task)
二进制序列的奇偶性可以通过 RNN 在数据顺序输入时合理地预测——模型只需维护一个内部状态,每遇到一个负数就翻转一个”开关”。但当整个序列一次性提供时,任务变得极具挑战性。
CTM 的实验:
- 输入 64 位二进制向量,预测每个位置的累积奇偶性
- 超过 75 个内部时钟步的 CTM 能可靠地解决此任务,部分运行达到 100% 准确率
- LSTM 基线在超过 10 个内部时钟步后就难以学习
学习到的算法可视化:
- 一个模型以逆序关注数据,然后一次性预测累积奇偶性
- 另一个模型正向关注,增量式预测奇偶性
- 两者都达到了完美准确率
CTM 能够以逆序搜索数据,表明它在进行某种形式的规划(Planning)——在做出最终决定之前先建立对数据的理解。
3.4 记忆与同步化(Q&A MNIST 任务)
为评估 CTM 记忆和回忆信息的能力,研究者设计了一个 Q&A MNIST 任务:
- 模型首先观察一系列 MNIST 数字
- 然后接收交替出现的索引和运算符嵌入,指定应回忆哪些数字及应用哪种模运算
- 所有数字和索引/运算符嵌入呈现完毕后,零张量标志信号模型产生最终答案
关键设计:MNIST 数字始终位于神经元级别模型所使用的激活历史窗口之外——CTM 必须组织其激活,使其能在后续时间步回忆数字。
结果:
- LSTM 在只使用单个内部时钟步时优于 CTM,但在更多时钟步下变得不稳定
- CTM 随内部时钟步增加而表现更强,在最具挑战性的分布内任务中达到 95%+ 准确率
- CTM 还展示了泛化到比训练时更多的数字或索引-运算符嵌入的能力
3.5 CTM vs 人类(CIFAR-10)
在 CIFAR-10 上与人类性能对比:
- 使用 CIFAR-10D(难度校准)和 CIFAR-10H(人类不确定性量化)数据集
- CTM 展示了最佳的校准性(Calibration),甚至优于人类
- CTM 产生了丰富、多样和复杂的神经动力学,包括周期行为(没有周期驱动函数!)
3.6 排序实数
CTM 被训练从
- 使用 CTC 损失训练
- 约 80% 的时间能正确排序长度为 30 的列表
- 展示了 CTM 在可控环境中如何根据难度应用更多或更少的计算
3.7 强化学习环境
CTM 扩展到与外部环境交互的任务,使用 PPO 训练:
- 导航任务
- 部分可观察的 CartPole 和 Acrobot
CTM 接收观察,使用固定数量的内部思维步骤处理,然后输出下一个动作。激活历史在环境步骤之间连续传递,使得过去环境步骤的激活可以影响当前的决策过程。
四、Neural Dynamics(神经动力学)
神经活动:使用 UMAP 投影进行二维可视化。每个神经元都显示为一个单独的点,点的大小随绝对值变化,颜色随值变化(蓝色代表负值,红色代表正值)。我们将在后续演示中展示类似的图像。
CTM 最引人注目的特性之一是其丰富的神经动力学——神经元活动随时间演化的复杂模式。
与 LSTM 基线相比:
- CTM 产生丰富、多样、复杂的动力学,具有多种有趣特征
- 包括周期行为(没有周期驱动函数)
- LSTM 的神经活动则相对单调
CTM 和 LSTM 之间神经活动的显著差异证明了 CTM 的两个新元素(神经元级别模型和同步化作为表征)使得神经动力学成为一种基本的计算机制。
4.1 宽度消融实验(CIFAR-100)
在保持其他条件恒定的情况下改变神经元数量(模型宽度):
- 更宽的网络展示了更多的多样性而非更少
- 直觉上人们可能认为更多神经元意味着更少的”多样性空间”,但实验观察到相反的结果
4.2 自适应计算
内部时钟步数与预测之间的关系:
- CTM 使用广泛的步骤范围来达到对数据的最高确定性
- 每种设置(25、50、100 个内部时钟步)中都有两个集中区域,表明 CTM 根据数据类型遵循不同的内部处理过程
五、CTM 架构总览
1 | |
六、代码与复现
6.1 仓库结构
1 | |
6.2 环境搭建
1 | |
如果 PyTorch 版本有问题:
1 | |
6.3 模型训练
1 | |
6.4 检查点与数据
- 检查点下载:Google Drive - checkpoints
- 迷宫数据下载:Google Drive - maze data
生成分析视频需要 ffmpeg:
1 | |
七、CTM 的意义与展望
7.1 核心价值
CTM 代表了朝着弥合计算效率与生物合理性之间差距的新颖一步:
- 超越逐点激活函数 — 通过私有的神经元级别模型,培养了更丰富的神经元动力学
- 全新的表征类型 — 利用神经同步化作为一种根本性的新表征形式,与自神经网络早期以来流行的激活向量截然不同
- 自适应计算 — 自然地展现出根据问题难度调整计算量的能力
- 可解释性 — 内部处理过程天然地提供了更大的可解释性,如在迷宫求解和奇偶校验任务中的方法论性解题过程
- 架构统一性 — 核心架构在多种任务间保持基本一致,仅需调整输入/输出模块
7.2 缺失的成分:时间
生物智能在许多情况下仍然优于 AI。生物大脑解决任务的方式与传统神经网络截然不同,这可能解释了为什么会如此。可能生物智能以现代 AI 根本不会的方式关注时间。
CTM 的开发旨在以更贴近生物大脑的方式解决问题,强调精确时序和神经动力学相互作用的核心角色。CTM 的可视化演示中直观的、可解释的结果令人兴奋,因为它表明 CTM 确实在利用时间来推理数据。
7.3 未来方向
- 探索 CTM 如何在更复杂环境(如游戏或视频)中无需显式位置编码就能导航
- 进一步借鉴生物学概念,发现新的、令人兴奋的涌现行为
- 扩展到更大规模的模型和更复杂的任务
作者团队(注意:Llion Jones 是 Transformer 论文 “Attention Is All You Need” 的联合作者之一): - Luke Darlow — Sakana AI - Ciaran Regan — Sakana AI, University of Tsukuba - Sebastian Risi — Sakana AI, IT University of Copenhagen - Jeffrey Seely — Sakana AI - Llion Jones — Sakana AI