一、简介
LLM Memory 在 Agent
领域常被视为一种对历史时序状态进行压缩的手段,能够有效减少上下文长度。而
DeepSeek 最新提出的 Conditional-Memory Engram
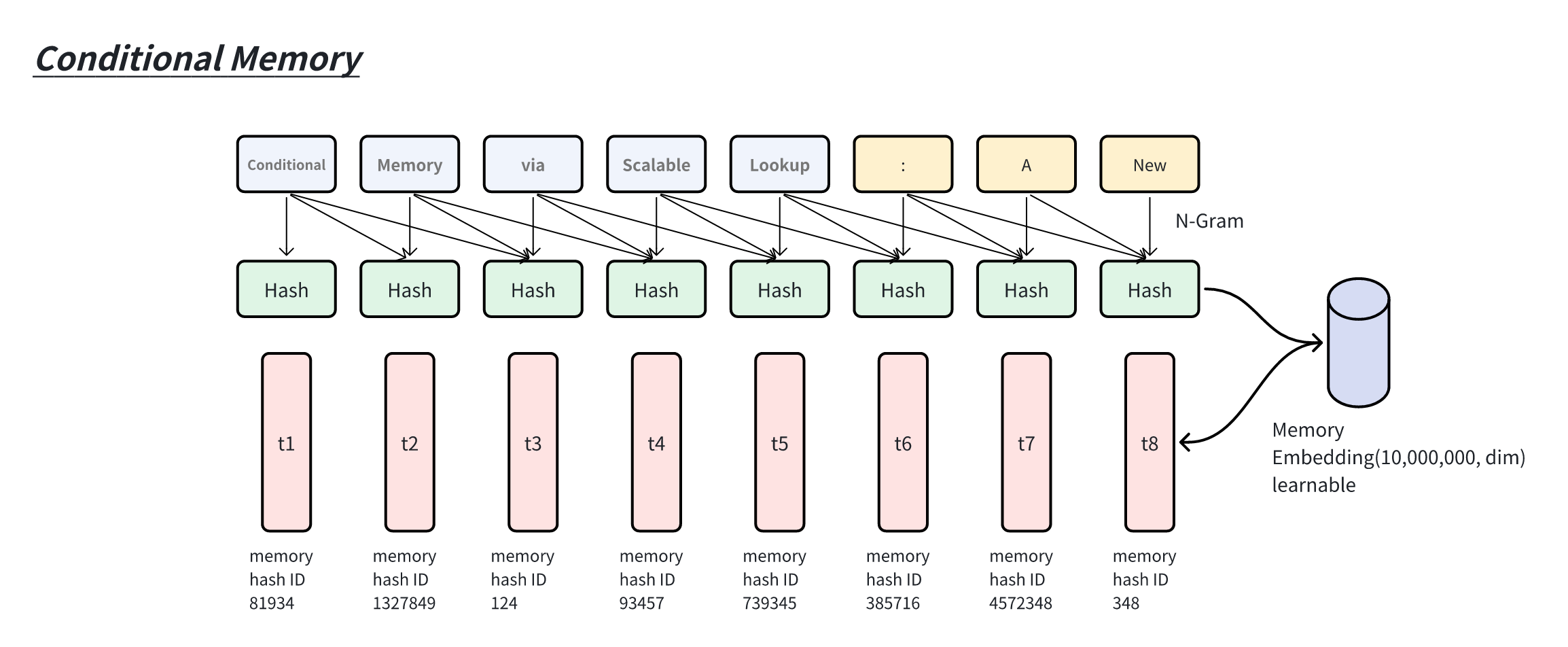
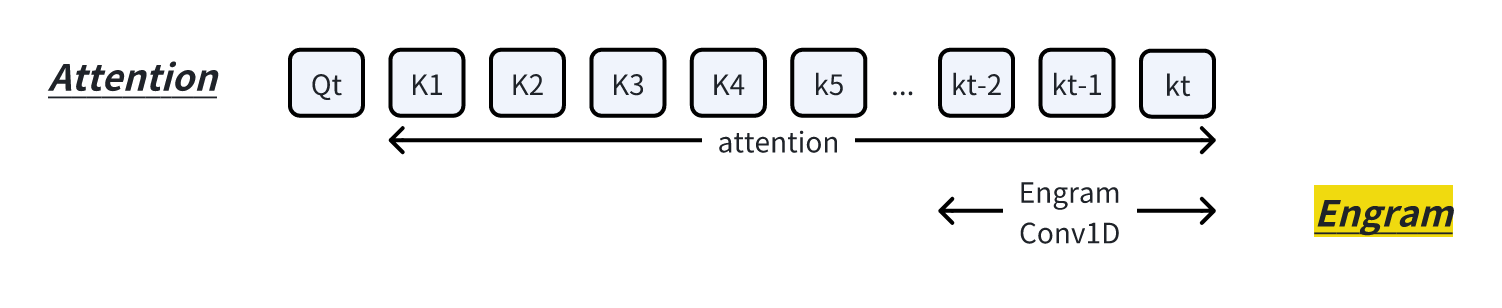
建模,并非旨在压缩长上下文,而是一种短距离时序特征学习方法。下图中, 相邻
3 个 token 被映射成一个记忆 embedding。
Engram 的目标实则是增强模型的长上下文处理能力。Attention
机制与Engram 算法直观的对比:
Attention : query 会与历史上所有 key
计算注意力分数。例如在股票交易中,当前时刻的交易决策可能会参考过去所有时刻(如上市十年间的全部数据)的股价信息。Engram :可看作一种长短时特征学习机制。仍以股票交易为例,短期内的标志性事件(如当日曝出企业财务造假新闻)所产生的影响是可预测的——在新闻发布前后,存在一段可被观测的隐藏短期时序模式。Engram
正是对这种短时序特征进行建模的方法。
因此,Engram 所捕捉的短时序特征,即 Conditional
Memory,并非通常直观理解中的长程记忆处理方式。Attention
本身可通过注意力权重的分布自然体现长短时偏好,而 Engram
则在此基础上,显式地引入了一种短时序建模机制。
Engram 并非用于取代 Attention。Engram 对标的模块应当是类似 MoE(FFN)
一类的特征学习,引入记忆学习 则可以看成是一种参数 Scaling
或增加模型容量的手段。
二、Engram 框架
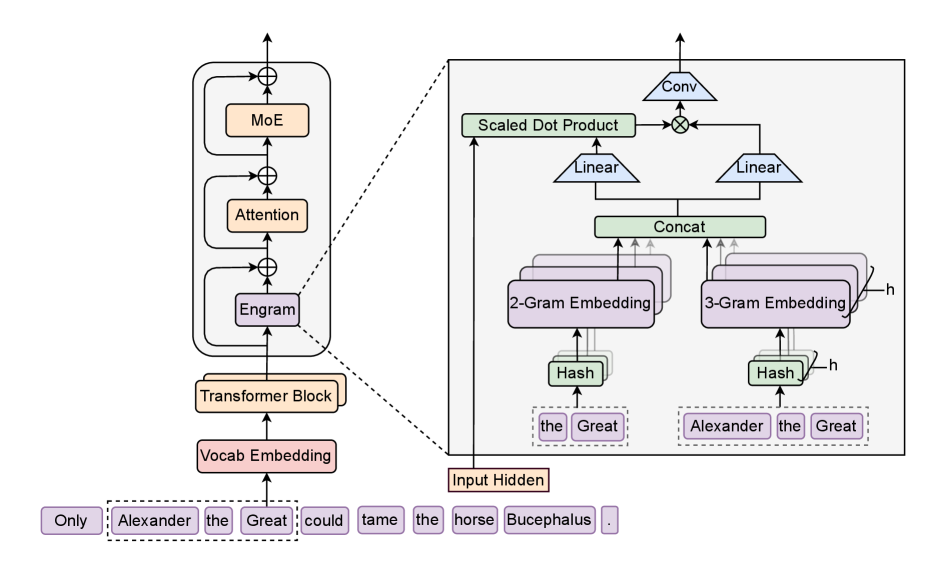
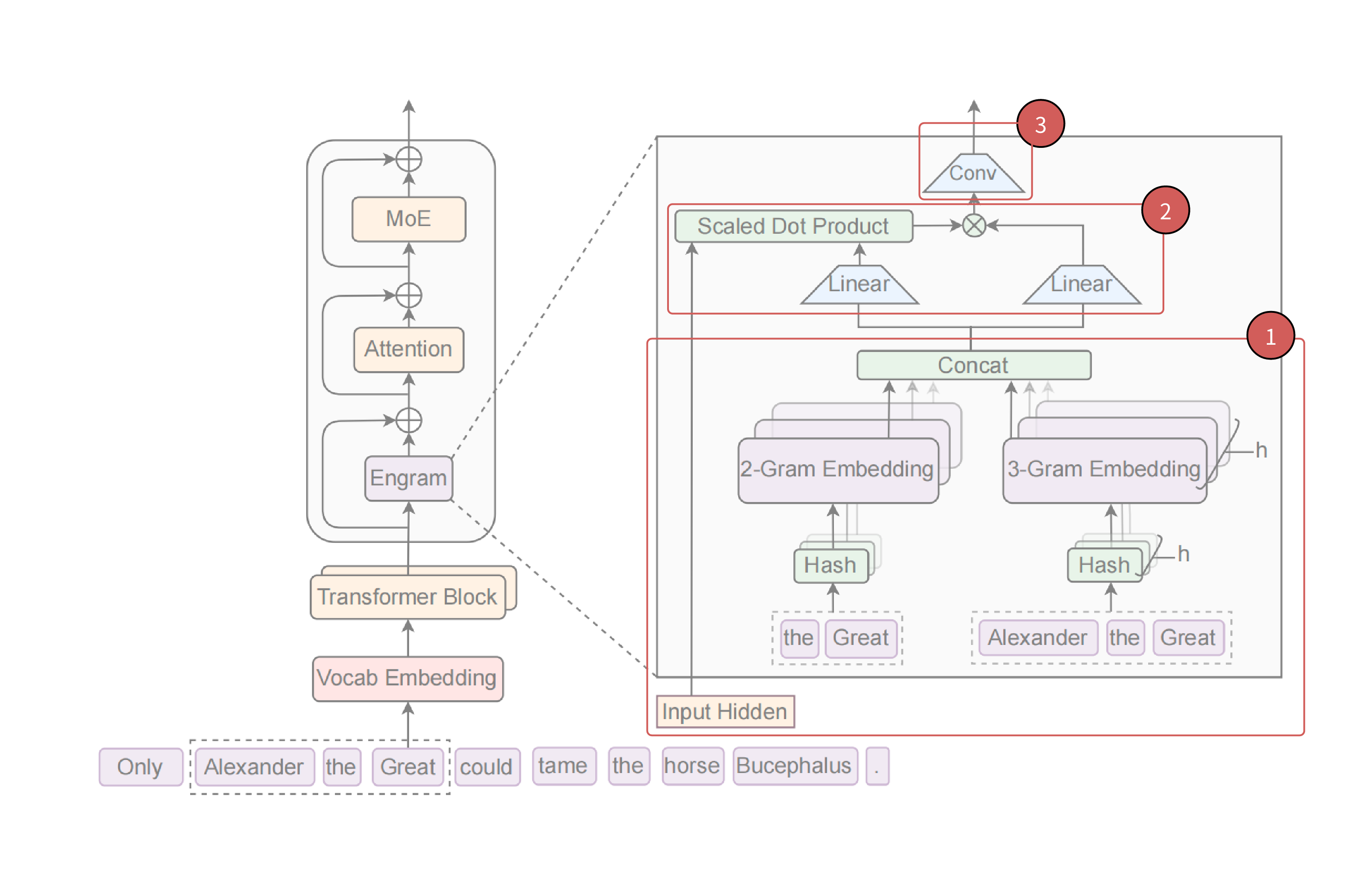
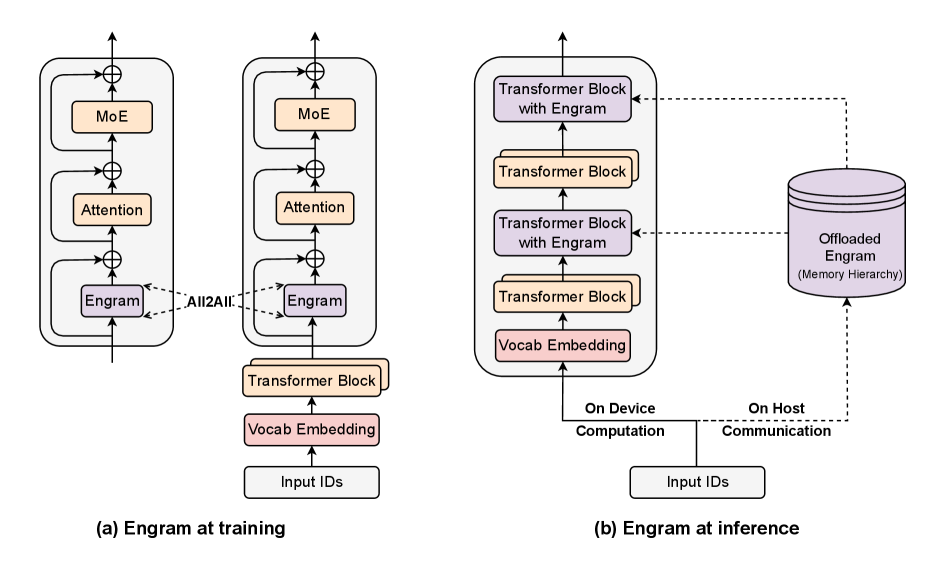
Engram 架构
在基础的attention和moe前,额外添加了一个Engram模块,该模块通过检索静态
2.1 Engram架构拆解
Engram 是一种条件记忆模块。我们用一种简化的架构来描述这一特性。对
N-gram 进行压缩:
N-gram :指的是 token-id
序列里的一个窗口连续子序列, word2vec
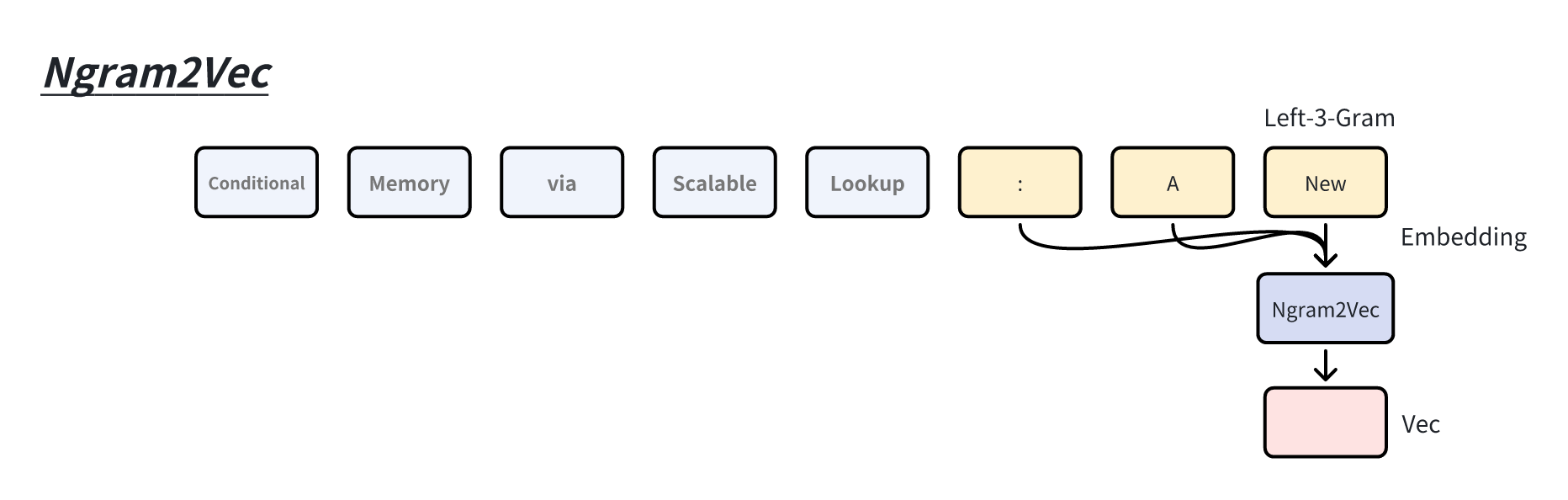
使用中心词表示来预测周围的词来学习特征表示。我们定义一种 “left-N-gram”
来达到描述窗口历史子序列。Encoding :对 N-gram
的序列编码成一串向量,如我们基于最简单的N-gram的 Token Embeeding
进行求和,本文简称这种编码方法为 Ngram2vec
Engram 的取名即是: E ncoding
N-gram
1 2 3 4 5 6 7 8 9 10 11 def get_ngram_vec (h, N ):"""get left-N-gram sum""" for i in range (1 , N):return ngram_vec0 ,1 ,2 ,3 ,4 ]])3 )print (h) print (ngram_vec)
对于原有 token-level 的特征则可以与 Ngram2Vec
进行融合,达到引入外部信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 tokenizer = AutoTokenizer.from_pretrained(name, trust_remote_code=True )'Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models' ]'pt' ).input_ids 3 )
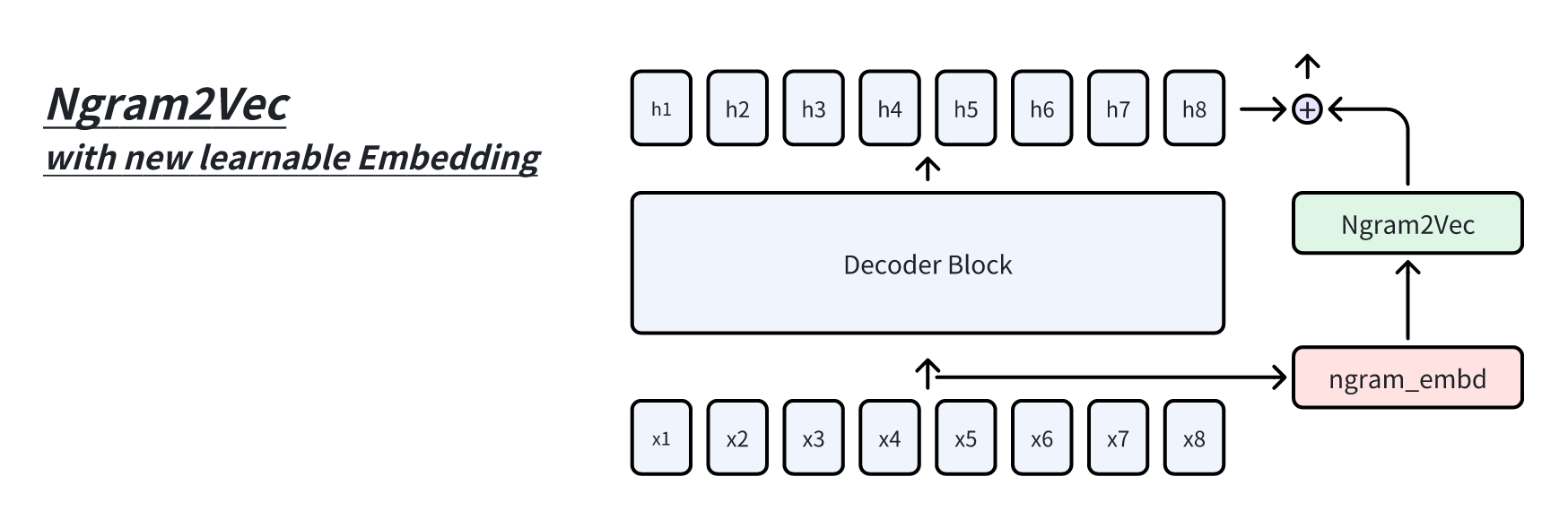
将 Engram 模块串接到 Decoder-Block 前,将特征与 Engram
的特征进行相加,输出的结果传输到注意力层前。根据原 paper 的描述隔 block
引入 Engram
1 2 3 4 5 6 attn = nn.Linear(backbone_config.hidden_size, backbone_config.hidden_size)
2.2 Engram 框架所解决的问题
Engram 用 N-Gram 规则统一定义短序列,实际上原模型
Ngram2Vec
Conditional Mmeory:如何利用条件记忆序列建模?
2.2.1 如何做 Ngram2Vec?
在上述提出了一种朴素的
Ngram2Vec,当有新知识引入时,会影响原本的知识,那么
如何引入独立的记忆层来学习新的内容? 如以下代码中的
self.ngram_embd
如何高效的学习的 Ngram2Vec ?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class LanguageModelWithNgram2Vec (nn.Module):def __init__ (self, config, N = 3 ):super ().__init__()self .N = Nself .embd = nn.Embedding(config.vocab_size, config.hidden_size)self .proj = nn.Linear(config.hidden_size, config.hidden_size)self .ngram_embd = nn.Embedding(config.vocab_size, config.hidden_size)def forward (self, x ):self .embd(x)self .proj(h)self .ngram_embd(x)self .N)return h_engramprint (h_engram.shape)
2.2.2 如何做条件记忆序列建模?
我们定义 Ngram2Vec 是
short-memory(短距离记忆)。在因果注意力计算形式中,查询历史 KV
来完成序列交互,计算各时刻的特征,本质上是
History2Vec。可以归纳两种方式来描述外部记忆如何增强原有的特征表示
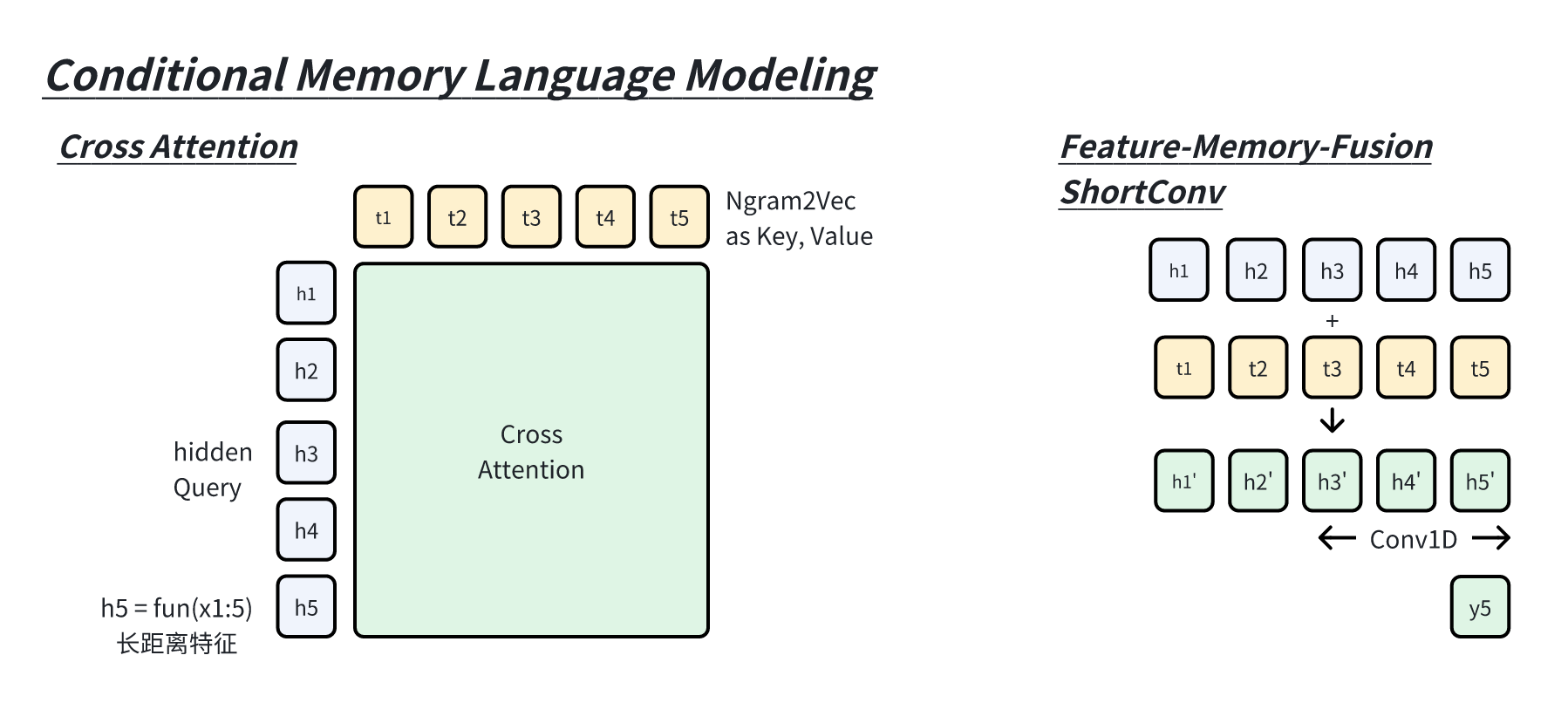
交叉注意力 :将 memory 作为 KV 进行序列交互,完成
token-feature 与 memory
交互,实现上可以采用交叉注意力完成。但这种方式显著增加了计算量。序列依赖式 :将 memory 与特征相加融合,并引入类似
Conv1D 的方式进行短距离序列建模。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class EngramCrossAttn (LanguageModelWithNgram2Vec ):def __init__ (self, config, N = 3 ):super ().__init__(config, N)self .dim = config.hidden_sizeself .Wq = nn.Linear(config.hidden_size, config.hidden_size)self .Wk = nn.Linear(config.hidden_size, config.hidden_size)self .Wv = nn.Linear(config.hidden_size, config.hidden_size)def forward_ (self, x ):self .embd(x)self .proj(h)self .ngram_embd(x)self .N)self .Wq(h_proj)self .Wk(ngram_vec), self .Wv(ngram_vec)1 ,2 ) /math.sqrt(self .dim)1 )return h_engramprint (h_engram.shape)
至此,可以得到一个核心的概念:Conditional Memory。 对于一个
next-token 预测来说,增加了一部分条件。
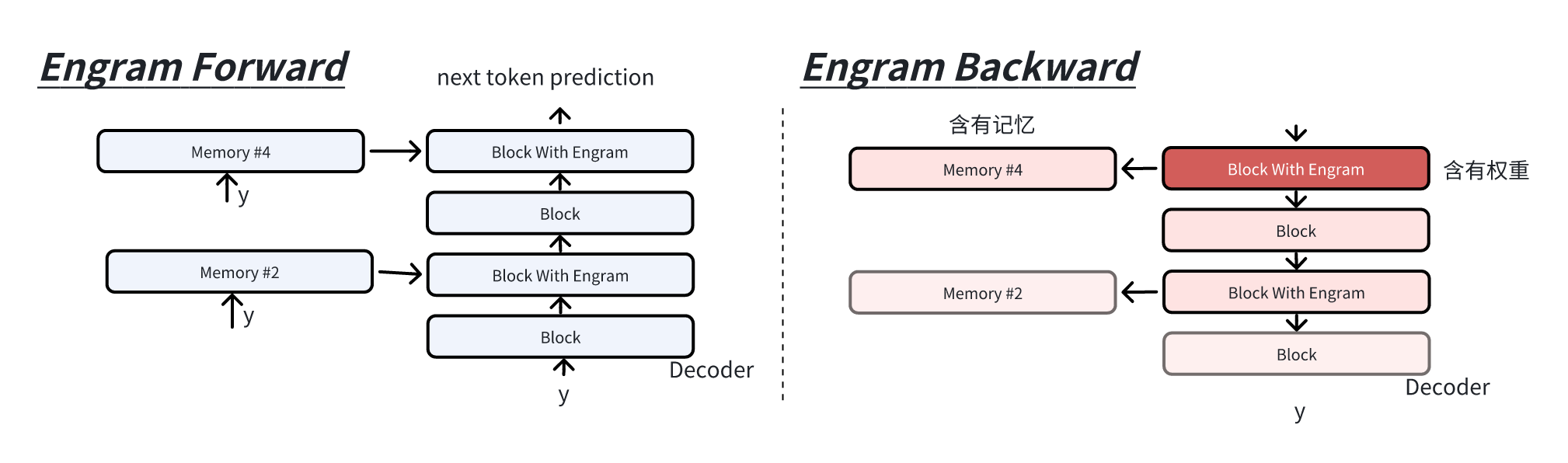
engram 模块是伴随解码块的, ngram_embd 独立串接在 block
内,不是输入嵌入层只放置于解码器前。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class EngramBlock (nn.Module):""" Decoder Block with Engram """ def __init__ (self, config, N = 3 )super ().__init__()self .dim = config.hidden_sizeself .engram = EngramCrossAttn(config, N = 3 )self .attn = nn.Linear(self .dim, self .dim)self .ffn = nn.Linear(self .dim, self .dim)def forward (self, h ):self .engram(h) self .attn(h)self .ffn(h)return h
三、Engram: Ngram2Vec
为了实现 Ngram2Vec, 有两种简单的学习方式:
将 N-gram 对应多个Embedding 进行统计,如求和或平均;
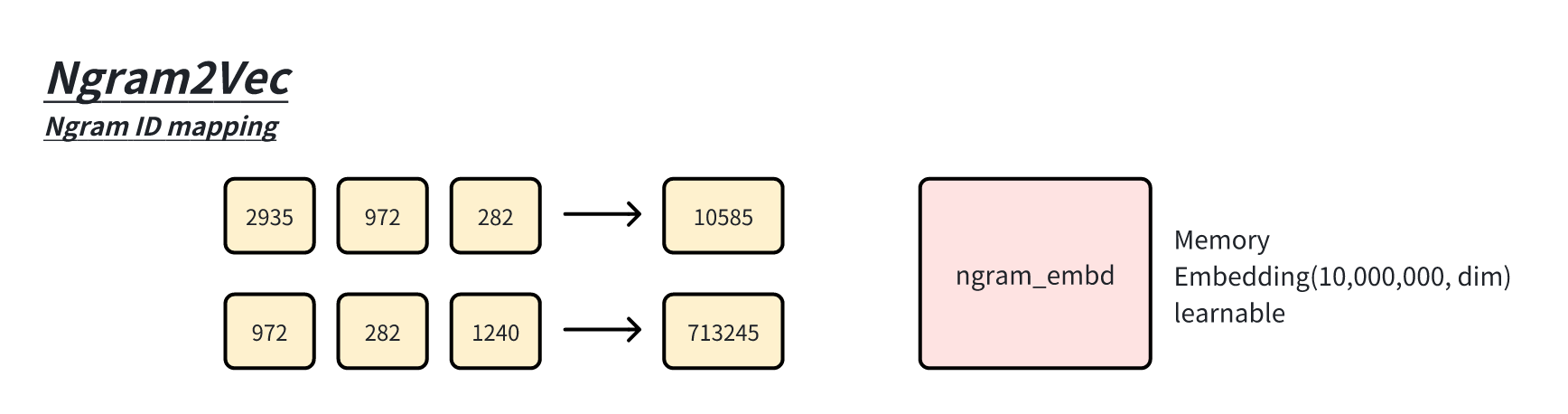
Engram 的做法是将 N-Gram token-ID 进行映射成 1 个 ID,并在一个额外的
Embedding 来放置 Ngram 的特征向量,这个额外的 Embedding 则为 Memory
Embedding。
以下代码中只要实现好 mapping 函数,即可确定性的达到 ID
值映射的目的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class NgramMapping (nn.Module):def __init__ (self, vocab_size=5 , dim = 128 , N = 3 , max_ngram_vocab_size = 1000 ):super ().__init__()self .N = Nself .dim = dimself .embd = nn.Embedding(vocab_size, dim)self .proj = nn.Linear(dim, dim)self .ngram_embd = nn.Embedding(max_ngram_vocab_size, dim)def mapping (self, x, N ):"""恒等映射, 不处理 gram""" return xdef forward (self, x ):self .embd(x)self .proj(h)self .mapping(x, self .N) self .ngram_embd(x_)return h_engram
3.1 N-gram 直接映射
一种直接的映射是将 N-Gram Token-ID
进行相加或相乘,在新词表中创建出一个新词。这种方法映射后的词量是巨大的,以一个
128k 的词表来说,其词表需要新创建
例如,一个很小的词表 vocab_size=5, 当 N=3
时, 有组合 5^3=125。
以下代码中将 N-gram 进行乘积映射, 输入token序列取值范围为
当 3-gram 中, 有数据为 0 时, 都可能冲突的映射到 new_id = 0
当 3-gram 中, token 序列
另外需要申请一个大的 ngram_embd, 当原始
vocab_size = 100 时, max_ngram_vocab_size 应为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class NgramMappingMul (nn.Module):def __init__ (self, vocab_size=5 , dim = 128 , N = 3 , max_ngram_vocab_size = 1000 ):super ().__init__()self .N = Nself .dim = dimself .embd = nn.Embedding(vocab_size, dim)self .proj = nn.Linear(dim, dim)self .ngram_embd = nn.Embedding(max_ngram_vocab_size, dim)def mul_mapping (self, x, N ):"""乘积映射""" for i in range (N):1 ) return x_def forward (self, x ):self .embd(x)self .proj(h)self .mul_mapping(x, self .N) self .ngram_embd(x_)return h_engram
3.2 N-gram 哈希映射
我们可以设计一种哈希映射,具体的新创建一个大小为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class NgramMappingHash (nn.Module):def __init__ (self, vocab_size=5 , dim = 128 , N = 3 , max_ngram_vocab_size = 1000 ):super ().__init__()self .N = Nself .dim = dimself .embd = nn.Embedding(vocab_size, dim)self .proj = nn.Linear(dim, dim)self .ngram_embd = nn.Embedding(max_ngram_vocab_size, dim)self .mod = max_ngram_vocab_sizedef hash_mapping (self, x, N ):"""哈希映射""" for i in range (1 , N):1 )print ('mul id:' , x_.tolist())self .modreturn x_def forward (self, x ):self .embd(x)self .proj(h)self .hash_mapping(x, self .N) self .ngram_embd(x_)return h_engram, x_100 1 , 5 ), dtype=torch.long)print ('original id:' , x.tolist())100 , 128 , 3 , 10007 ) print ('hash id' , x_.tolist())
哈希映射相较之前的映射方法,存储量可控。 哈希映射存在冲突问题不同的
N-Gram 可能映射到统同一个 Embedding。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def hash_mapping (x, N, mod=37 ):"""哈希映射""" for i in range (1 , N):1 )for i in range (L):0 , i]] += 1 if hash_table[x_[0 , i]] > 1 :continue return x_, hash_table
打印结果如下,哈希表数字大于1,说明有两个 ID 哈希到同一个位置了
1 2 3 4 5 6 7 8 9 10 x = torch.arange(37 ).unsqueeze(dim=0 )3 , mod=37 )print (new_id)print (hash_table)0 , 1 , 4 , 18 , 6 , 28 , 20 , 16 , 0 , 17 , 25 , 6 , 3 , 9 , 4 , 29 , 1 , 9 ,18 , 17 , 19 , 24 , 19 , 15 , 10 , 26 , 35 , 33 , 3 , 26 , 22 , 9 ]])2. , 2. , 0. , 2. , 2. , 0. , 2. , 0. , 0. , 3. , 1. , 0. , 0. , 0. , 0. , 1. , 1. , 2. ,2. , 2. , 1. , 0. , 1. , 0. , 1. , 1. , 2. , 0. , 1. , 1. , 0. , 0. , 0. , 1. , 0. , 1. ,0. ])
对于冲突有两种处理方式:
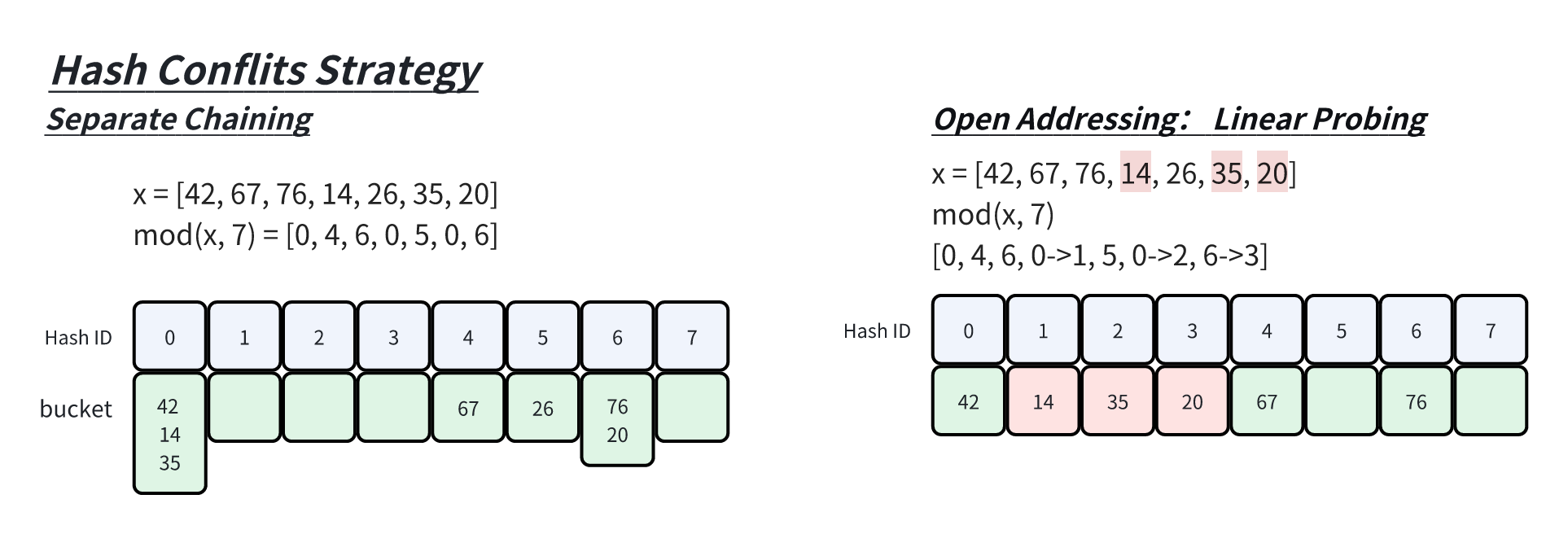
不解决冲突:多个数据将可能映射到同一个Hash
ID。可以想象成哈希表中每个 ID
对应一个桶,桶里是可以容纳多个原数据的。常见的有:链地址法
解决冲突:如果映射的 Hash ID 已有数据, 那么通过新的策略重新
hash。可以想象成哈希表中每个 ID
至多被一个数据映射到。例如常见的有:开放寻址法
如下面代码,遇到冲突后进行线性试探,直到找到一个未映射过的空位。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def hash_mapping (x, N, mod=37 ):"""哈希映射""" for i in range (1 , N):1 )for i in range (L):0 , i]if hash_table[idx] == 0 :1 else :while hash_table[idx] == 1 :1 ) if idx >= max_vocab_size:0 1 return x_, hash_table37 ).unsqueeze(dim=0 ) 3 , mod=37 )print (new_id)print (hash_table)18 , 17 , 19 , 24 , 19 , 15 , 10 , 26 , 35 , 33 , 3 , 26 , 22 , 9 , 29 , 0 , 12 , 31 ,10 ]])1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. , 1. ,1. ])
至此,我们期望的 N-gram 压缩的哈希映射为:
新 Embedding 最大存储可控
冲突少
查询次数少(频繁的处理冲突,影响查找效率)
如果哈希表是不用解决冲突的,那么哈希表中的每个桶里被映射的数据量是均衡的。
3.3 Multiplicative-XOR
Hash(乘异或哈希)
官方实现代码中, 类 class::NgramHashMapping 进行实现 XOR
哈希, 建议按照以下内容逐步理解源码。
3.3.1 XOR 哈希
定义哈希函数
hash(key) = (key ^ (key >> 4)) % table_size
,观察其二进制数值。
给定数值 42, 二进制为 00101010
操作key >> 4 :2, 二进制为 00000010,
将key的二进制右移4位,左边补0
进行key ^ (key >> 4) , 其中 ^ 为异或(XOR)操作
00101010 ^ 00000010 得到 00101000
最终哈希值: 40 % 100 = 40,其中 100 是哈希表大小。
代码实现如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class XORHash :def __init__ (self, size=100 ):self .size = sizeself .table = [[] for _ in range (size)] def hash (self, key ):return (key ^ (key >> 4 )) % self .sizedef insert (self, key ):self .hash (key)for i, k in enumerate (self .table[idx]):if k == key:self .table[idx][i] = keyreturn self .table[idx].append(key)def get (self, key ):self .hash (key)for k in self .table[idx]:if k == key:return kreturn None
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 h = XORHash(50 )1 , 128 ) for _ in range (128 )]for i, num in enumerate (data):print (h.table)print (f"插入 {len (data)} 个元素" )print (f"查找示例:" )for key in [data[0 ], data[10 ], data[20 ], 999 ]:if k == None :print (f"{key} 未找到" )else :print (f"{key} " )
结果如下,哈希表中的元素是个列表。哈希方法可以不解决冲突。
其哈希表中理想情况下,各个列表长度均等。
1 2 3 4 5 6 7
3.3.2 Multiplicative-XOR Hash
算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import randomclass MultiplicativeXORHashNgram3 :def __init__ (self, size=200 ):self .size = size self .table = [[] for _ in range (size)]self .multipliers = [11400714819323198485 % (2 **32 ), 2654435761 , 179424673 ]def hash (self, x ):0 for i in range (3 ):self .multipliers[i]16 return hash_val % self .sizedef insert (self, x ):self .hash (x)for i, k in enumerate (self .table[idx]):if k == x:self .table[idx][i] = xreturn False self .table[idx].append(x)return len (self .table[idx]) > 1 def get (self, x ):self .hash (x)for k in self .table[idx]:if k == x:return idxreturn None
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 h = MultiplicativeXORHashNgram3(50 )1 , 128 ) for _ in range (3 )] for _ in range (128 )]0 for point in data:if h.insert(point):1 print (f"Conflicts Ratio: {conflicts/len (data)*100 :.1 f} %" )0 ], data[10 ], [999 , 999 , 999 ]]for point in test_points:"find" if result else "not exist" print (f"3-gram {point} : {status} , hash_id: {result} " )
输出
1 2 3 4 Conflicts Ratio : 64.1% 3-gram [93, 128, 33] : find, hash_id: 10 3-gram [94, 93, 107] : find, hash_id: 16 3-gram [999, 999, 999] : not exist, hash_id: None
3.3.3 DeepSeek
Multiplicative-XOR Hash 实现
用 Multiplicative-XOR Hash 的处理方法优势在于
可以处理 N-gram 数据输入
映射后的哈希表中的列表大小均衡
根据前置内容,容易理解官方的哈希实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class NgramHashMapping :def _get_ngram_hashes ( self, input_ids: np.ndarray, layer_id: int , ) -> np.ndarray:self .layer_multipliers[layer_id]def shift_k (k: int ) -> np.ndarray:if k == 0 : return x0 , 0 ), (k, 0 )),'constant' , constant_values=self .pad_id)[:, :T]return shiftedfor k in range (self .max_ngram_size)]for n in range (2 , self .max_ngram_size + 1 ):2 0 ] * multipliers[0 ])for k in range (1 , n):self .n_head_per_ngramself .vocab_size_across_layers[layer_id][n_gram_index]for j in range (num_heads_for_this_ngram):int (head_vocab_sizes[j])False ))return np.stack(all_hashes, axis=2 )
3.4 N-gram: 多哈希映射
为了丰富外部获取的
embedding,可以进行多哈希映射,示例一个简单的映射规则,不同的哈希函数取不同的模,可以达到多哈希映射,丰富特征。
1 2 3 4 5 x = torch.arange(20 ).unsqueeze(dim=0 ) 3 , mod=37 , max_vocab_size=40 )print (new_id)3 , mod=33 , max_vocab_size=40 )print (new_id)
同一份序列有不同的数据映射
1 2 3 4 tensor([[ 0 , 1 , 4 , 18 , 6 , 28 , 20 , 16 , 0 , 17 , 25 , 6 , 3 , 9 , 4 , 29 , 1 , 9 ,18 , 17 ]])0 , 1 , 4 , 18 , 14 , 19 , 18 , 20 , 25 , 24 , 32 , 22 , 24 , 26 , 7 , 3 , 8 , 7 ,9 , 14 ]])
创建多分支对应的 embd。在单哈希映射中我们可以设定嵌入维度为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 100 , 256 )100 , 128 )100 , 128 )20 ).unsqueeze(dim=0 ) 3 , mod=37 , max_vocab_size=40 )print (new_id_1)3 , mod=33 , max_vocab_size=40 )print (new_id_2)print (h_branch_1[0 , 2 , :5 ]) print (h_branch_2[0 , 2 , :5 ])
输出如下,统一个映射 ID 对应的 embedding 向量不同。
1 2 3 4 5 6 tensor([[ 0 , 1 , 4 , 18 , 6 , 28 , 20 , 16 , 0 , 17 , 25 , 6 , 3 , 9 , 4 , 29 , 1 , 9 ,18 , 17 ]])0 , 1 , 4 , 18 , 14 , 19 , 18 , 20 , 25 , 24 , 32 , 22 , 24 , 26 , 7 , 3 , 8 , 7 ,9 , 14 ]])0.7217 , -1.0902 , 0.7087 , 1.0136 , 0.6399 ], grad_fn=<SliceBackward0>)1.0131 , 0.0814 , 0.0663 , -0.8880 , 0.0722 ], grad_fn=<SliceBackward0>)
对于多头哈希得到的 embedding 也可以进一步拼接。 如
3.5 Tokenizer 词表压缩
上述 N-gram 的映射复杂度与原本词表大小正相关。
压缩词表大小能够减轻映射目标词嵌入矩阵的大小。具体的 Tokenizer
词表可以进行压缩,对于每个
token,采用一定的规范化函数,如将单词统一改成小写或取消标点,示例如下
Apple vs. ␣apple,
新的词表能减少同义重复词,此过程也可能产生新词。 代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 class CompressedTokenizer :def __init__ ( self, tokenizer_name_or_path, ):self .tokenizer = AutoTokenizer.from_pretrained(tokenizer_name_or_path, trust_remote_code=True )"\uE000" self .normalizer = normalizers.Sequence ([r"[ \t\r\n]+" ), " " ),r"^ $" ), SENTINEL)," " ),self .lookup_table, self .num_new_token, self .overlap_num = self ._build_lookup_table()def __len__ (self ):return self .num_new_tokendef _build_lookup_table (self ):len (self .tokenizer)0 for tid in range (vocab_size):self .tokenizer.decode([tid], skip_special_tokens=False )if "�" in text:self .tokenizer.convert_ids_to_tokens(tid)else :self .normalizer.normalize_str(text)if norm else textif nid is None :len (new_tokens)else :1 for tid in range (vocab_size):return lookup, len (new_tokens), countdef _compress (self, input_ids ):0 self .lookup_table[valid_ids]return out def __call__ (self, input_ids ):return self ._compress(input_ids)
代入 DeepSeek-V3 的 tokenizer, 得到如下词表:
1 2 3 tokenizer = AutoTokenizer.from_pretrained("./v3" , trust_remote_code=True )"./v3" )print (self .overlap_num)
即是原词表有 30188 个规范化前后一致的 token。 新 tokenizer
词表量不一定比原来 tokenizer 词表量小。
测试得到两个分词器有不同的 token_id 输出
1 2 3 4 5 6 7 prompt = 'i Love llm, I love xiaodonggua' 'input_ids' ]print (len (prompt_ids)) print (len (c_prompt_ids)) print (prompt_ids[:10 ]) print (c_prompt_ids[:10 ])
3.6 小结
Ngram2Vec 可以用多种方法获取,本文采用 N-gram 哈希映射成新 ID 来取新
embedding 作为 N-gram-wise 的 token-level memory
Ngram 输入是 N-维长度序列,DeepSeek 官方精心设计了
Multiplicative-XOR Hash ,在工程上要保证哈希后冲突率尽可能小
四、Engram: Conditional Memory
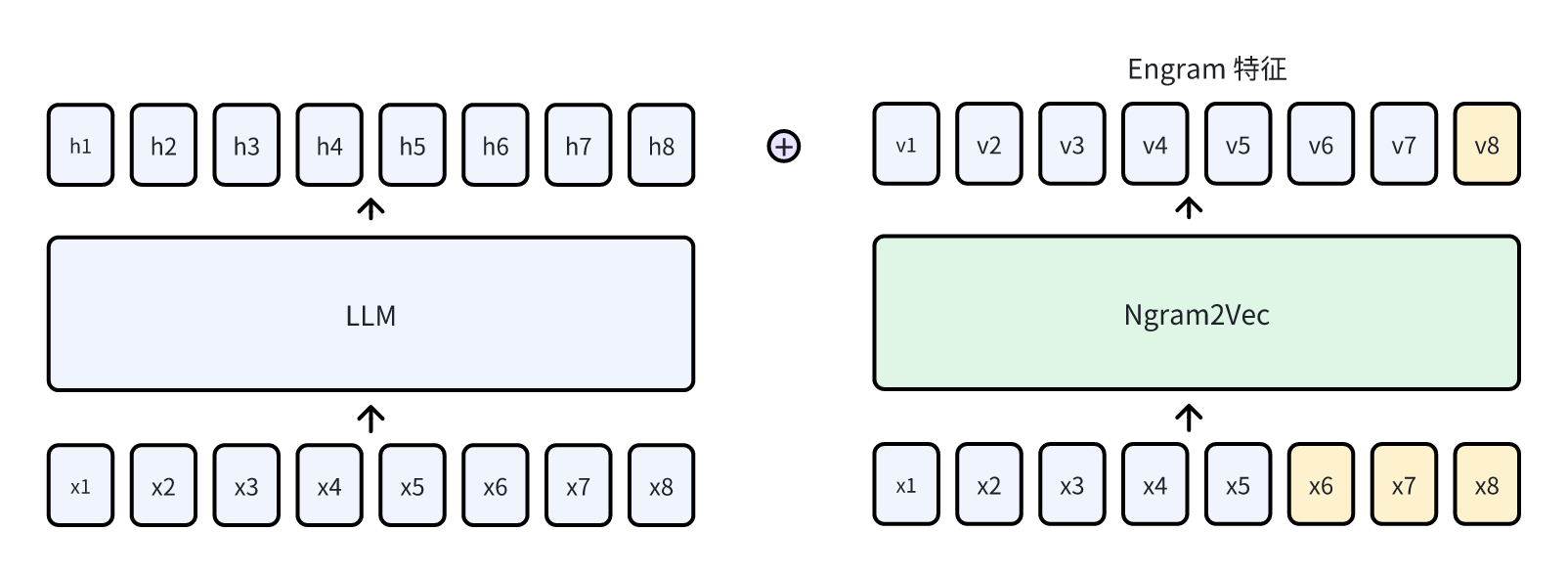
网络的数据流中有两类数据源,其 tensor 维度一致
Hidden State :token-level 级别的特征。如 attention
层输出为注意力特征,ffn
层输出为任务特征。自回归语言模型,每个token最终的 hidden state 都称之为
“next-token-prediction” 特征。一个网络数据流中,特征都是在输入 token-id
的 context 序列维度或特征维度进行交互而得。Memory Embedding :N-gram 映射到外部取得的
embedding。
要实现两组不同数据之间的交互,一种自然的方式是 Cross
Attention。Engram 实际上并未采用 Cross Attention
方案 。而是在 token-level 级别上的 Hidden State 和 Memory
Embedding 进行融合。
标准的Next-token-prediction 任务为:
Engram 引入了外部的 Memory Embedding,预测概率为:
其中,
Memory :N-Gram 映射成记忆嵌入向量Conditional : 预测概率引入外部条件信息
4.1 Engram 架构图
Engram 模块中具体分为三个部分:
输入 :input-hidden 和 memory embedding。
较为复杂的是 multi-heads hash memory 获取Scaled Dot Product :通常会将该算子与 Attention
等同。但事实上,Engram 只是用这个算子计算, 例如,将时刻conv :每个时刻都有 conditional memory
加持的特征为
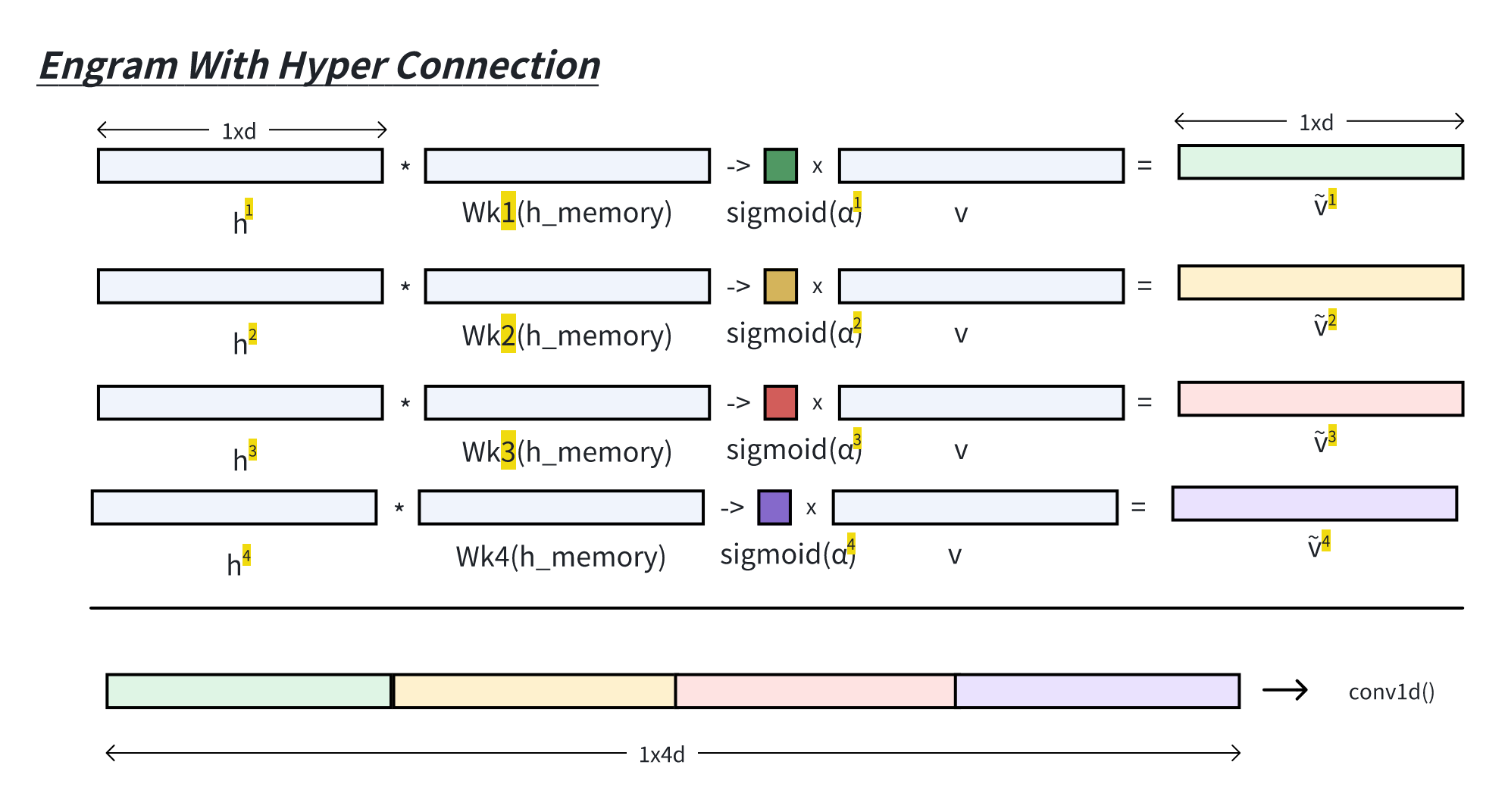
实现一个简易模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class EngramSimple (nn.Module):def __init__ (self, memory_vocab_size, dim, kernel_size=2 ):super ().__init__()self .memory_vocab_size = memory_vocab_sizeself .memory_embd = nn.Embedding(memory_vocab_size, dim)self .Wk = nn.Linear(dim, dim)self .Wv = nn.Linear(dim, dim)self .kernel_size = kernel_sizeself .w_conv1d = nn.Parameter(torch.randn(kernel_size))def forward (self, x, h ):""" h: bsz, seq_len, dim x: bsz, seq_len """ self .multi_head_hash(x)self .get_memory(hash_id) self .Wk(h_memory), self .Wv(h_memory)sum (dim=2 , keepdim=True )self .short_conv1d(v_)return out
相应的操作实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class EngramSimple (nn.Modules):def multi_head_hash (self, x ):self .memory_vocab_size, (B,T)) return hash_iddef get_memory (self, hash_id ):self .memory_embd(hash_id)return h_memorydef short_conv1d (self, v ):"""简化conv1d, 相邻时刻相加""" self .w_conv1d[0 ]self .w_conv1d[1 ]1 :] += v1[:,:,:-1 ]return v0
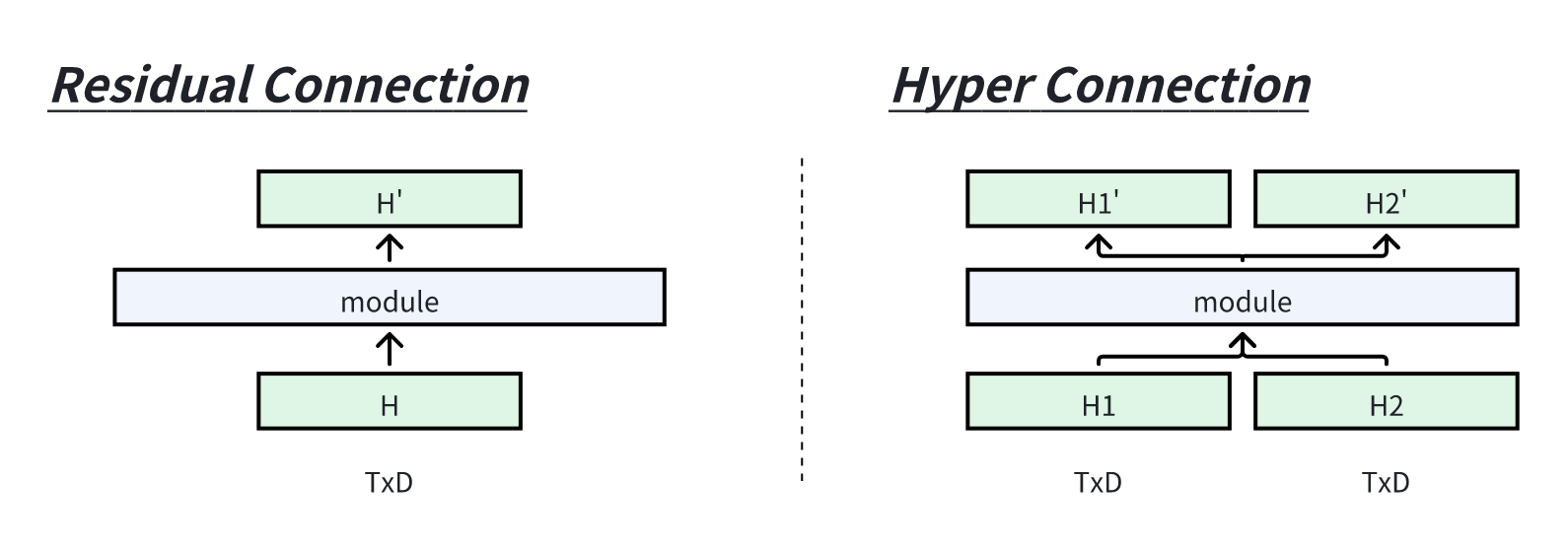
官方论文公式和代码不容易理解,原因是 Engram 集成了
Hyper-Connection(HC)非 HC 版本可以称之为是单流
Engram,集成了HC得版本称之为多流Engram。
为了使得更易理解,将从单流版本 Engram 进行讲解。然后再进一步讨论
Hyper Connection 与 Engram 的集成。
1 2 3 4 5 6 7 8 9 10 11 12 13 def forward (self, x, h ):""" h: bsz, seq_len, dim x: bsz, seq_len """ def forward_hc (self, x, h ):""" h: bsz, seq_len, n_hc, dim x: bsz, seq_len """
4.2 Engram Without
Hyper-Connection
Engram 详细讲解为:
Multi-heads-hash memory Scale-Dot-Product Fusion Short Conv1D
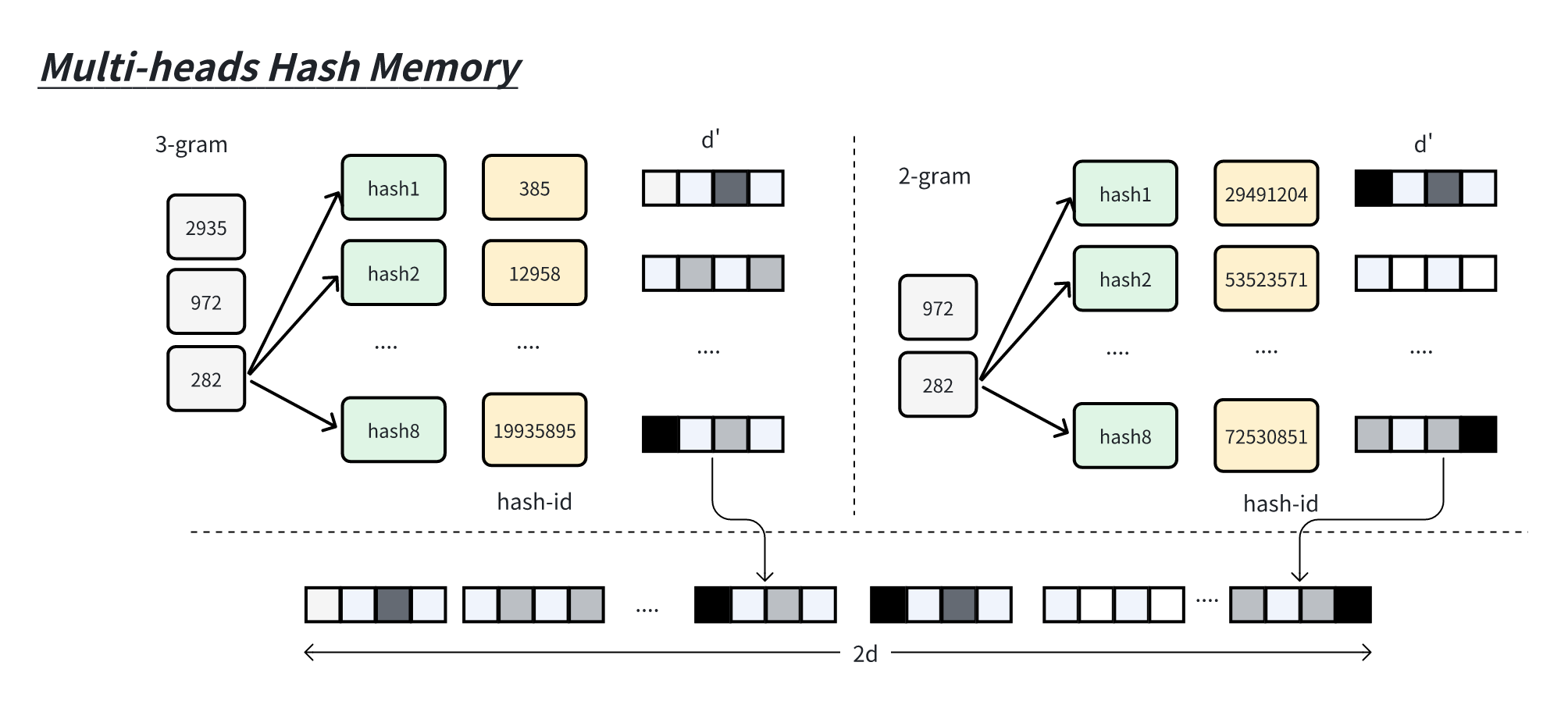
4.2.1 Multi-heads-hash memory
N-Gram 数据根据
Engram 取 3-Gram 和 2-Gram 的记忆,记为
将
此时一个 token 得到的多头哈希记忆变为为向量
多哈希类实现为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class MultiHeadsHash :def __init__ (self, max_memory_vocab_size, layer_id ):self .mods = torch.tensor([12582917 , 25165843 , 50331653 , 100663319 , 201326611 , 402653189 , 805306457 , 1610612741 ]) self .mods *= (layer_id+1 ) self .max_memory_vocab_size = max_memory_vocab_sizeself .layer_id = layer_iddef hash (self, x, mod, n_gram ):for i in range (1 , n_gram):self .max_memory_vocab_sizereturn hash_iddef multi_head_hash (self, x, mods, n_gram ):for mod in mods:self .hash (x, mod, n_gram)1 ) return hash_idsdef get_all_hash_ids (self, x, max_n_gram ):for N in range (1 , max_n_gram): self .multi_head_hash(x, self .mods, N)return ngram_hash_ids
memory 类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class ConditionalMemory (nn.Module):""" 每层Memory不同, Engram memory 伴随 DecoderBlock """ def __init__ (self, config ):super ().__init__()self .head_dim = config.head_dimself .head_hash = config.head_hashself .memory_embds = nn.Embedding(max_memory_vocab_size * self .head_hash,self .head_dim)self .offset = torch.arange(self .head_hash) * max_memory_vocab_size self .offset = self .offset[None , None , 1 ]def forward (self, x, ngram_hash_ids ):len (ngram_hash_ids)self .offsetfor hash_ids in ngram_hash_ids:self .memory_embds(hash_ids)1 )self .head_hash*self .head_dim) return h_memory
4.2.2 Scale-Dot-Product Fusion
此时每个时刻有
其中 ,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class EngramWithoutHC (nn.Module):def __init__ (self, config, layer_id=1 , ):super ().__init__()self .max_n_gram = config.max_n_gram1 )self .Wk = nn.Linear(memory_dim, D) self .Wv = nn.Linear(memory_dim, D)self .norm1 = nn.RMSNorm(D)self .norm2 = nn.RMSNorm(D)self .hash = MultiHeadsHash(max_memory_vocab_size=config.max_memory_vocab_size,self .memory = ConditionalMemory(config)
将
其中,
然后对标量分数
完整 context 变为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class EngramWithoutHC (nn.Module):def forward (self, h, x ):""" h: bsz, seq_len, dim hidden states x: bsz, seq_len input ids """ self .hash .get_all_hash_ids(x, self .max_n_gram)self .memory(x, ngram_hash_id)self .norm1(h)self .norm2(self .Wk(h_memory))sum (dim=-1 , keepdim=True ) / math.sqrt(D) self .Wv(h_memory)return out
值得注意的是,单个 query 与单个 key、value
的交互可以视作是注意力计算的一个特例。如果是 所有的记忆嵌入成为多个
key、value,那么就回到标准的注意力计算模式:单 query 和 多 key,
Value。
论文标题的 Sparsity
即是在一个巨量存储的记忆里通过哈希方式,稀疏的选出特定的 memory
。给定
Memory Embedding 矩阵共有 600,000 条
2-gram/3-gram记为 2 组数据, 设多头哈希为 8, 所选记忆条目为 16
条。
稀疏度:
4.2.3 Short Conv-1D
上述混合hidden与memory 产生了完整 context 变为
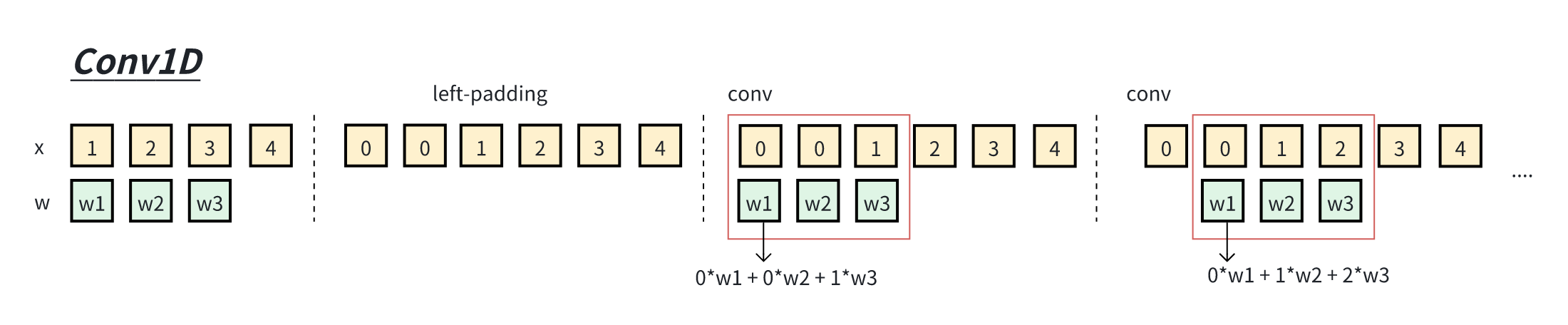
4.2.3.1 Conv1D 时序数据处理
Conv1D 是一种时序维度的卷积方式,对于一维时序数据 kernel_size = 3 记为
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def fun_conv1d (x, w ):len (w)len (x)0 ] * (kernel_size-1 ) + xfor i in range (x_len):0 for j in range (kernel_size):print (x_padding[i: i+kernel_size], '*' ,w, '->' , x_tmp)return x_conv1d1 , 2 , 3 , 4 ]1 , 10 , 100 ]print ('x:' , x, 'w:' , w)print (y)
输出为
1 2 3 4 5 6 x: [1 , 2 , 3 , 4 ] w: [1 , 10 , 100 ]0 , 0 , 1 ] * [1 , 10 , 100 ] -> 100 0 , 1 , 2 ] * [1 , 10 , 100 ] -> 210 1 , 2 , 3 ] * [1 , 10 , 100 ] -> 321 2 , 3 , 4 ] * [1 , 10 , 100 ] -> 432 100 , 210 , 321 , 432 ]
上述代码的特点在于,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 kernel_size = 3 1 ,1 ,1 ,False ,1 ) * 1 , 1 ,len (x)1 )print (x_tensor.shape) 1 ,10 ,100 ]]],dtype=torch.float32)print (y[0 ,0 ,:x_len])
打印结果与手动运算一致
1 2 torch.Size([1 , 1 , 4 ])100. , 210. , 321. , 432. ], grad_fn=<SliceBackward0>)
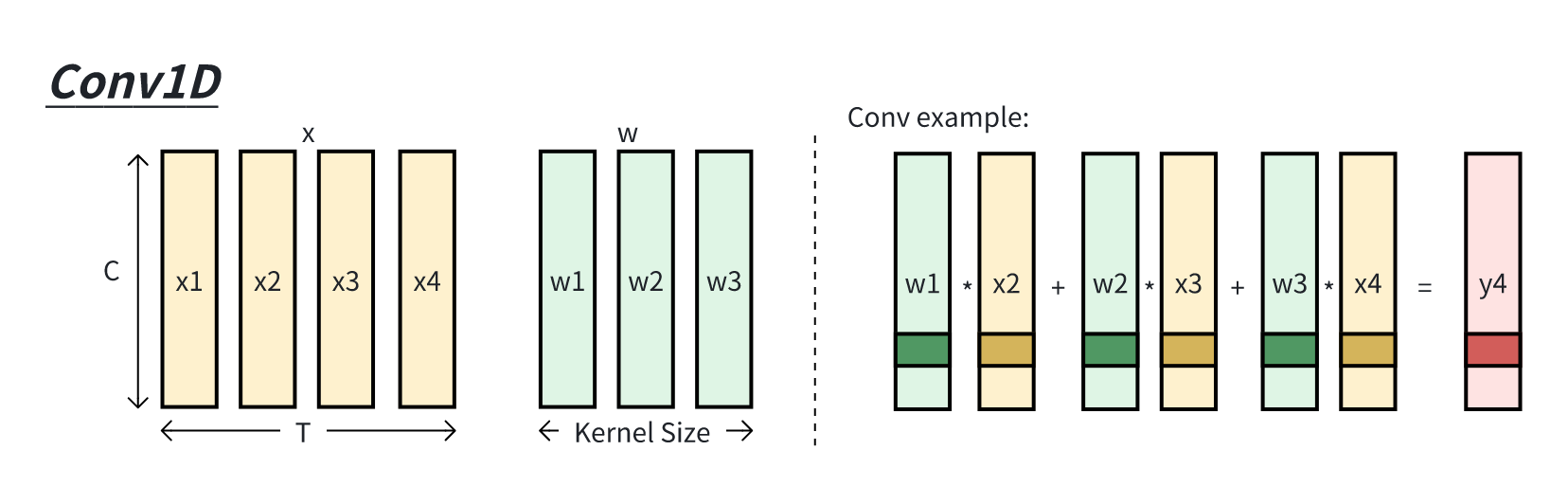
4.2.3.2 Conv1D 时序特征处理
给定序列长度为group 参数可以设定。
实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 B = 1 10 128 print (X.shape)1 ,2 ) 1 ) * 1 , dilation=1 , bias=False ,)print ('shape_groupC:' , conv_3C.weight.data.shape)1 ,2 )[:, :T]print (Y.shape)
打印
1 2 3 torch.Size([1 , 10 , 128 ])128 , 1 , 3 ])1 , 10 , 128 ])
4.2.3.3 Engram Short Conv-1D
回到 Engram,对融合的
其中,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class ShortConv1DWithoutHC (nn.Module):def __init__ (self, dim, n_hc, kernel_size, ):super ().__init__()1 self .total_dim = dim self .conv = nn.Conv1d(self .total_dim,self .total_dim,self .total_dim,False ,1 ) * dilation, self .norm = nn.RMSNorm( dim )self .act_fn = nn.SiLU()def forward (self, x ):self .norm(x)1 , 2 ) self .conv(x_norm)self .act_fn(y) 1 ,2 )return y
ShortConv1D
通过卷积核范围内学习短距离特征表示,类似的滑窗注意力也是一种可控学习“短”距离特征表示的方法。
在距离上 ShortConv1D 是短的,思考 Engram 前一个 DecoderBlock
有注意力层,那么 DecoderBlock 输出的 hidden state
中每个时刻都有对前序数据进行加工。ShortConv1D
对多个包含历史的特征进行更复杂的加工处理。
至此,Engram 所有模块都得到了实现。
4.3 Engram With
Hyper-Connection
Hyper Connection 是一种新的残差链接范式,DeepSeek 提出 mHC 采用流形约束提升 HC
训练的稳定性。
在 HC 类的网络流中,hidden state 由原本的
对比单流和多流 Scale-Dot-Product 对比:
HC 版本有多个
HC 版本中的
HC 版本中的 RMSNorm 有 N*2 个
得到门控
带 HC 版本的 ShortConv1D 实现细节:
在每个输入分支上
将
标准的做 Conv1D
将 Conv1D 的结果再切分成 HC 分支。
4.4 小结
Engram 的输出结果混合 Hidden State 与 Ngram 映射的记忆
Scale-Dot-Product 并非实现类似注意力特征的序列建模, ShortConv1D
才是增加短距离建模能力的直接操作
Conditional Memory 为模型的规模扩展增加新维度。
五、Engram pytorch实现
代码参考
去除了 tokenizer 压缩和 XOR 哈希,更深入代码本质。 摘选带 HC 的
Engram
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class Engram (nn.Module):def __init__ (self, config, layer_id=1 , ):super ().__init__()self .n_hc = config.n_hc1 )self .Wks = nn.ModuleList([ nn.Linear(memory_dim, D) for i in range (self .n_hc) ])self .Wv = nn.Linear(memory_dim, D)self .norm1 = [ nn.RMSNorm(D) for i in range (self .n_hc) ]self .norm2 = [ nn.RMSNorm(D) for i in range (self .n_hc) ]self .max_n_gram = config.max_n_gramself .memory = ConditionalMemory(config)self .hash = MultiHeadsHash(max_memory_vocab_size=config.max_memory_vocab_size,self .conv = ShortConv1D(config.dim, class Engram (nn.Module):def forward (self, h, x ):""" h: bsz, seq_len, n_hc, dim hidden states x: bsz, seq_len input ids """ self .hash .get_all_hash_ids(x, self .max_n_gram)self .memory(x, ngram_hash_id)for hc_idx in range (self .n_hc):self .norm1[hc_idx](h[:,:, hc_idx, :])self .norm2[hc_idx](self .Wks[hc_idx](h_memory))sum (q*k, dim=1 , keepdim=True ) / math.sqrt(D) 2 ) self .Wv(h_memory).unsqueeze(2 ) self .conv(v_) + v_return out
实现易理解的multi-head hash
实现Memory
实现short-Conv1D
实现 Engram 前向、模型前向
六、Engram与Attention
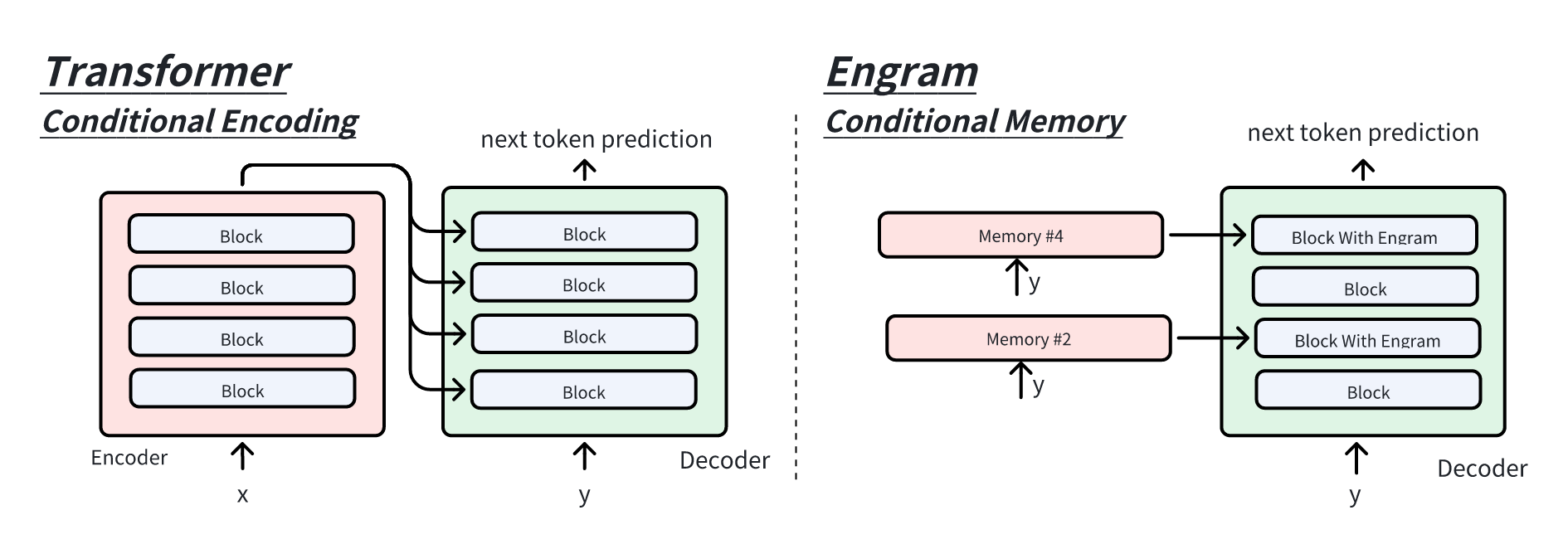
Engram 负责将学习的内容存在记忆中,从反向视角,梯度流向两部分权重
与 Conditonal Memory 相应的模型如 Transformer,可以称之为是
Conditional Encoding
Engram 负责短距离建模,Attention 负责长距离建模。 Attention
在语言模型中仍是核心序列表征学习机制。
七、Engram Infra
训练 :额外创建的 Embedding
可以采用词表并行训练,可以类似 MoE 实现 Dispatch-Combine All-to-All
模式。由于训练时,memory 参数分布在多层网络中,
需要频繁的做前向和梯度反向计算。
推理 :可以分层静态管理 Engram, paper
中提到推理时可以做预取,推理服务需要配套开发 Memory 管理
硬件 :上述infra分析建立在 计算-通信
维度,假如每个计算设备,都可以通过低廉的存储组成,那么可以直接从磁盘中预取操作,掩盖掉
memory-IO开销,消除 all-to-all 通信开销。
八、讨论
短序列一定要 N-gram 吗?为什么是哈希映射?
不一定。有研究实现字符级别分词并自适应从 Embedding
空间上合并。也可以通过一些规则来映射,如字节近期工作将序列 token 转化为
concept。
N-Gram 哈希特点是内容无感的,正如 BPE
算法,其通用性是建立在统计规则的。
Engram 学到了什么?
Engram 学到了短序列建模,类似的在
Yarn中提到,长文本的扩展一个重要处理是对特征信号高频绝对外推。
对于一个基模,可以将额外习得的知识填入到 Embeeding 上,那么与 LoRA
区别在于,LoRA 是参数扩展, Engram 是输入扩展。
Engram 学会了记忆吗?准确来说他学会了检索
Engram 如何扩展模型容量?
LLM 模型的核心容量通常是在 FFN 中体现的,MoE
是一种高效的容量扩展方式。
Engram 扩展模型的容量范式则为,增加更多的 memory-embedding
对计算没影响,对 IO
有影响,相较廉价的闪存和磁盘存储突破模型容量限制。
另外可以扩展 n-gram 数量,引入新的 scaling 维度
Engram 的记忆可扩展性讨论
考虑 agent 类场景,则可以引入额外的类似的。任务/模态等
Conditional-memory
而 rag 知识库也可以作为 一种 Conditional-memory,其所查询的 embedding
则不是rag类 chunk2embeeding,它的 memory
是跟随查询上下文长度的,数据量更大。
外置 Embeeding 学习范式
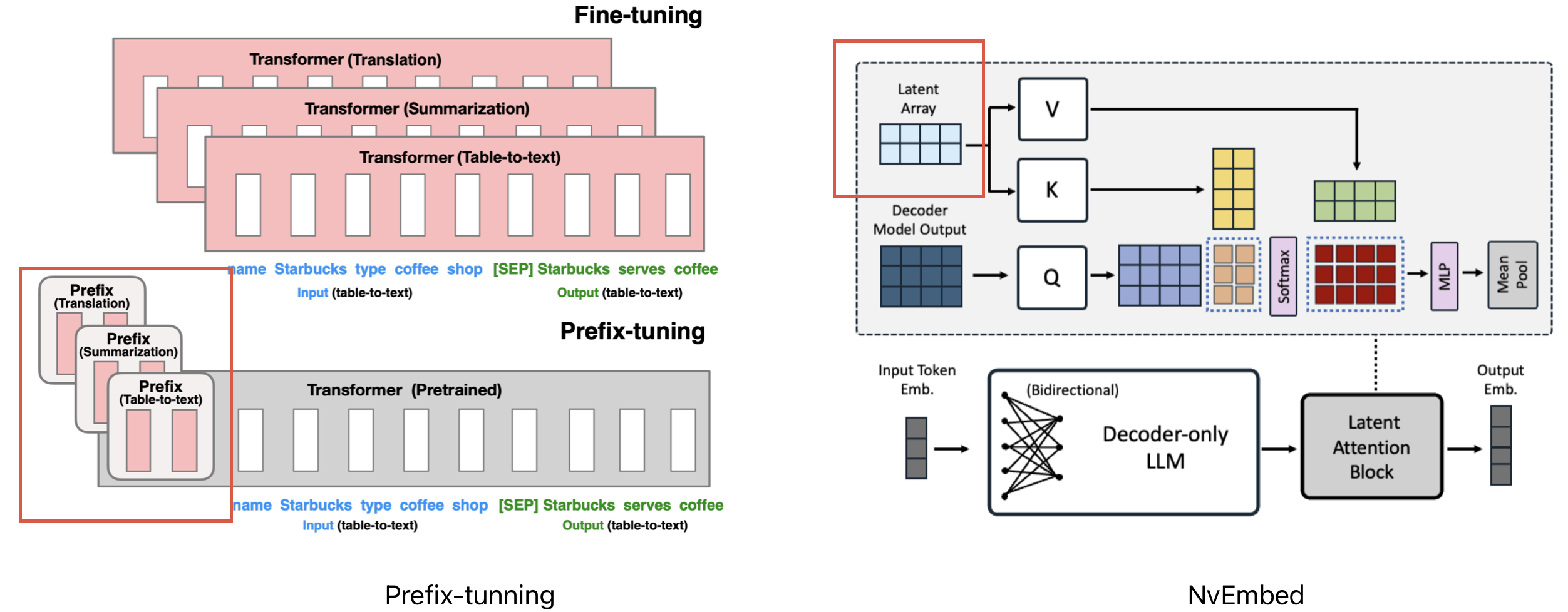
围绕着 LLM 结构
Prefix-Finetuning , 将任务前缀用 embedding
描述,并投影到 key 特征空间, 进行 conditional 推理NvEmbd :将 Decoder LLM 训练为 Encoder
模型用于做文本的向量化,其引入 latent embedding
学习向量相似度学习任务的对
九、总结
Engram
提供了一种新的外置检索记忆的学习模式。提高模型的适用性和扩展性;
Engram 建模就近的 N-gram
记忆,拓展长文本之路,反直觉的是要去增强短距离建模;
Engram 并未颠覆传统的 Attention 架构,从预测任务角度引入了
conditional memroy。
Reference
Conditional Memory via
Scalable Lookup: A New Axis of Sparsity for Large Language
Models deepseek-ai/Engram 【手撕Engram】DeepSeek
的 Conditional Memory 能取代 Attention 吗?(超长文、附代码) Deepseek
Conditional Memory浅读 Conditional
Memory:DeepSeek 如何为大模型引入“第二条稀疏轴”——从 MoE 走向“计算 ×
记忆”双稀疏的大模型新范式 流形约束超连接(mHC):Manifold-Constrained
Hyper-Connections