DeepSeek mHC:Manifold-Constrained Hyper-Connections
一、简介
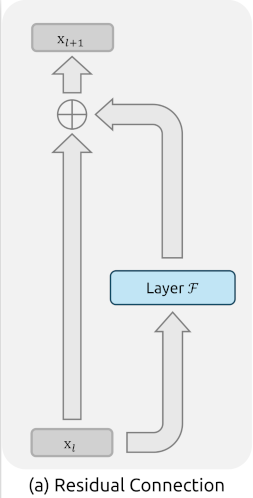
传统的Residual结构计算表达式为:
其中
残差连接的恒等映射特性在大规模训练过程中保持了稳定性和效率。通过递归地将残差连接扩展到多个层:
其中
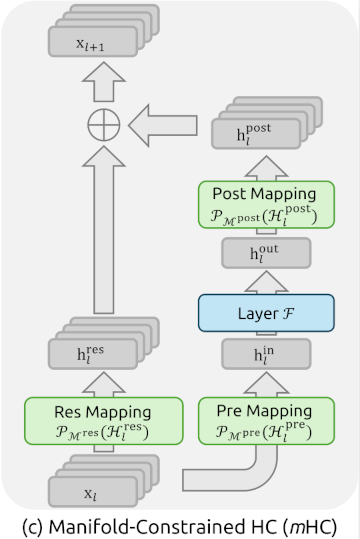
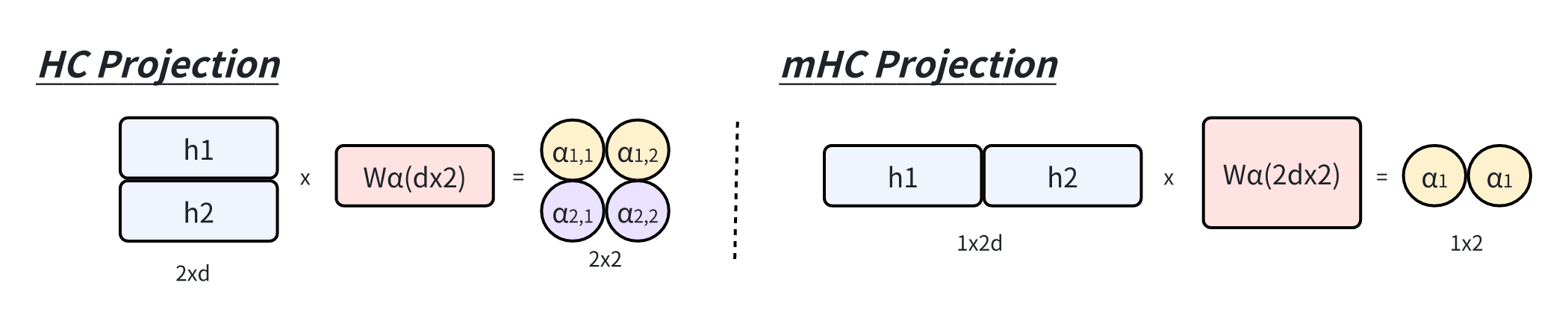
而Hyper-Connections认为直接把
: 表示一个可学习的映射,负责在 个残差流之间混合信息。 :将 的残差流聚合为 维维向量输入到层函数 。 :将层函数 的输出映射回 的残差流。
基于公式(3)可以推导出模型第
这就导致
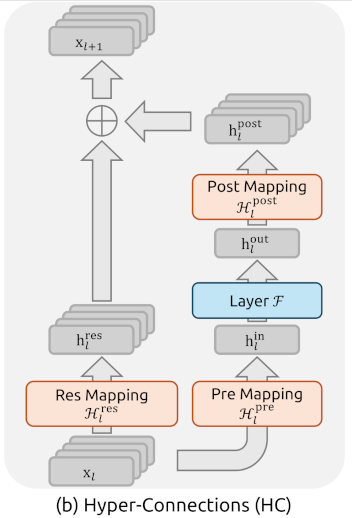
为此,DeepSeek流形约束超连接(Manifold-Constrained Hyper-Connections (mHC)),如上图所示,这是一个通用框架,将 HC 的残差连接空间投影到特定流形上以恢复恒等映射特性,同时结合严格的架构优化以确保效率。具体而言,
残差映射矩阵
投影到双随机矩阵(Doubly Stochastic Matrices)构成的流形(Birkhoff 多面体)。通过 Sinkhorn-Knopp 算法实现这一约束,在数学上保证了信号传播的范数有界性( )和凸组合特性,从而恢复了恒等映射的稳定性。 针对引入的学习参数和宽流带来的计算与存储压力,设计了基于 TileLang 的算子融合、分块重计算(Block-wise Recomputing)策略以及扩展的 DualPipe 通信重叠机制,将
扩展率下的训练时间开销控制在 6.7%。
二、Manifold-Constrian hyper connection
mHC核心思想是:与其让
2.1 数学原理:投影到 Birkhoff 多面体
mHC 将残差映射矩阵
- 非负性:所有元素
。 - 行和为 1:
- 列和为 1:
由所有
Sinkhorn-Knopp算法是一种通过交替行列归一化将非负矩阵转换为双随机矩阵(doubly stochastic matrix)的迭代方法。它是矩阵平衡(matrix balancing)问题的经典解法。
为什么选择双随机矩阵?
这种约束赋予了 mHC 三个对大规模训练至关重要的性质:
- 范数保持(Norm Preservation):
双随机矩阵的谱范数(Spectral Norm)以 1 为界,即
。这意味着映射是非扩张的(non-expansive),从根本上消除了梯度爆炸的数学基础。 - 组合封闭性(Compositional Closure):
双随机矩阵的乘积仍然是双随机矩阵。这意味着无论网络堆叠多少层,复合映射
然保持在 Birkhoff 多面体内,稳定性不会随深度衰减。 - 几何解释: Birkhoff 多面体是置换矩阵(Permutation
Matrices)的凸包。这意味着
实际上是对输入特征进行了一种“凸组合(Convex Combination)”式的混合。这保证了特征的均值守恒,且信号混合过程是良态的。
2.2 参数化与 Sinkhorn-Knopp 算法
在具体实现中,网络并不直接学习双随机矩阵,而是学习其参数化形式,并通过投影算法将其映射到流形上。
动态与静态参数
在 HC 公式中,
在 HC 公式中,可学习的映射由两部分系数组成:依赖于输入的系数和全局系数,分别称为动态映射和静态映射。形式上,HC 计算系数如下:
其中
- HC 在计算过程没有进行约束,训练不稳定
- 多条变换分支,显著增加显存量
mHC 沿用了 HC 的动态选通机制,系数由输入依赖部分(Dynamic)和全局部分(Static)组成:
其中,reshape 操作将
下图示例
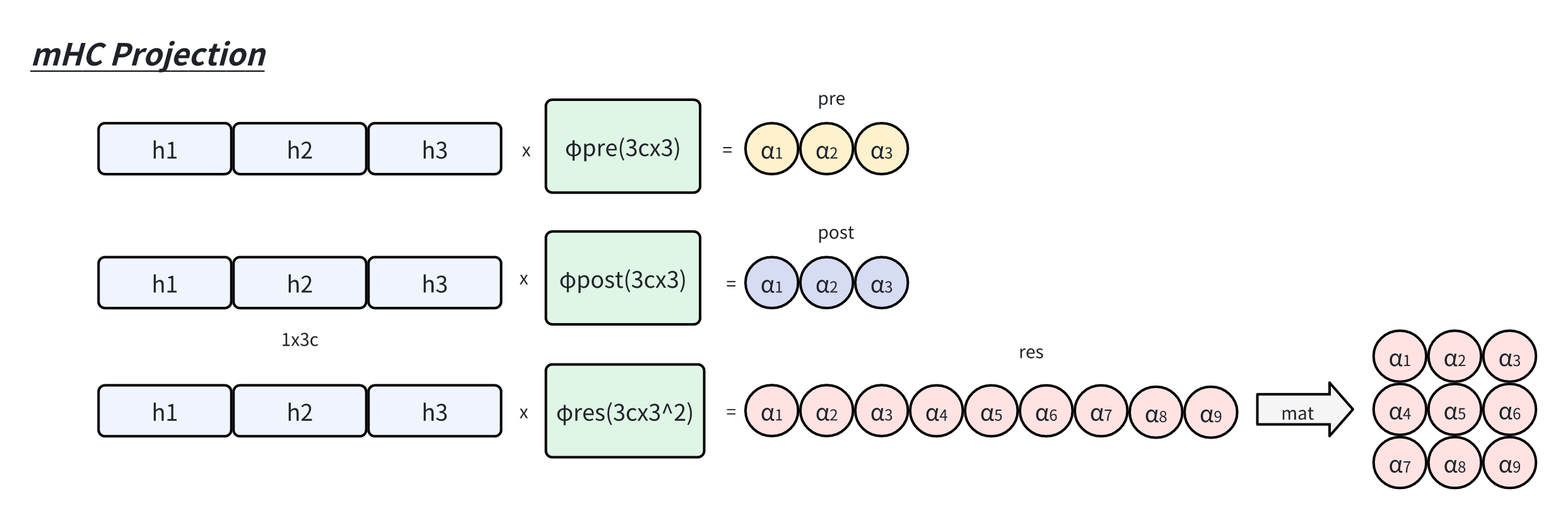
向量化目的:对多个分支的输入拼接 flat 化后学习,某种程度上,扩展了特征向量维度,大大增加了存储容量。
流形投影
对上述缩放因子增加最后的约束:
得到原始系数
- 对于
和 :使用Sigmoid函数( )确保非负性,防止正负系数抵消导致的信号消除。
对于
- 对于
:使用 Sinkhorn-Knopp 算法。 该算法通过迭代的方式,交替对矩阵的行和列进行归一化,最终收敛到双随机矩阵。
迭代过程( 从
其中
2.2.1 特征投影(width connection)
当有了缩放量
其中,
2.2.2 深度链接(depth connection)
将
- 残差输出进行缩放
- 残差分支与变换分支相加,公式如下。
2.3 Sinkhorn-Knopp 算法公式推导
2.3.1 SK 算法目标
给定一个非负矩阵
满足:
的每一行和= 1(行随机) 的每一列和 = 1(列随机) 即 是一个双随机矩阵。
2.3.2 算法步骤
假设
初始化:
设
交替归一化:
- 行归一化:
使得每行和为 1。
- 列归一化:
使得每列和为 1。
重复以上两步直到收敛(行和与列和都接近 1)。
2.3.3 数学表达
设对角矩阵
满足:
其中
这等价于:
其中
迭代形式(Sinkhorn迭代):
代码实现
1 | |
查看打印, 明显迭代 1000 次后结果更优。
1 | |
mHC sinkhorn_knopp 实现
mHC 对输入矩阵进行指数变换,使得矩阵元素都 0,代码实现批量处理数据
1 | |
mHC 代码开源 :https://github.com/dhcode-cpp/mHC-pytorch
三、基础设施优化
虽然 mHC 解决了理论上的不稳定性,但引入的 Sinkhorn 迭代和
3.1 内核融合 (Kernel Fusion)
- RMSNorm 重排序与融合(10)-(13): 观察到 RMSNorm
在高维状态
操作延迟较高,作者将其除以范数的操作重新排序到矩阵乘法之后。这允许将 RMSNorm 的权重吸收到后续的线性投影系数中。 - 统一扫描内核(Unified Scan Kernel)(13)-(14):
将计算
所需的两次对 的扫描操作融合为一个 Kernel,充分利用矩阵乘法单元(Tensor Cores)并最大化内存带宽利用率。 - Sinkhorn 融合(18): 将 Sinkhorn-Knopp 的 20 次迭代完全在一个 Kernel 内完成,中间结果保留在片上缓存(On-chip memory),避免了极其昂贵的全局显存读写。
- 应用内核融合(13)-(14):引入两个额外的核函数来应用这些映射,一个用于
,另一个用于 通过将 的应用与残差合并相结合,它将读数据量从 降低到了 ,写数据量从 降低到了 。
代码实现
1 | |
RMSNorm 存在融合 trick,原本计算流程为:
可以进行如下变换, 而 RMSNorm 层参数
缩放因子计算: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36def mapping(self, h, res_norm):
B, L, N, D = h.shape
# 1.vectorize
h_vec_flat = h.reshape(B, L, N*D)
# RMSNorm Fused Trick: gamma-scaling
h_vec = self.norm.gamma * h_vec_flat
# 2.projection
H = h_vec @ self.w
# RMSNorm Fused: compute r
r = h_vec_flat.norm(dim=-1, keepdim=True) / math.sqrt(self.nc)
r_ = 1.0 / r
# 3. mapping
n = N
H_pre = r_ * H[:,:, :n] * self.alpha[0] + self.beta[:n]
H_post = r_ * H[:,:, n:2*n] * self.alpha[1] + self.beta[n:2*n]
H_res = r_ * H[:,:, 2*n:] * self.alpha[2] + self.beta[2*n:]
# 4. final constrained mapping
H_pre = F.sigmoid(H_pre)
H_post = 2 * F.sigmoid(H_post)
# 6. sinkhorn_knopp iteration
H_res = H_res.reshape(B, L, N, N)
H_res_exp = H_res.exp()
with torch.no_grad():
_, U, V = res_norm(H_res_exp.reshape(B*L, N, N), self.max_sk_it)
# recover
P = torch.bmm(torch.bmm(U.detach(), H_res_exp.reshape(B*L, N, N)), V.detach())
H_res = P.reshape(B, L, N, N)
return H_pre, H_post, H_res
另外
1 | |
mHC Forward
1 | |
打印, h_pre 为残差分支输入,不会增加功能层的计算量。
1 | |
3.2 sinkhorn_knopp 梯度流分析
由于 SK 算子是迭代计算的,梯度流会产生循环依赖
1 | |
可以改写成无计算图求 u, v, 将迭代结果直接作用于原矩阵
1 | |
3.3 mHC 重计算
由于残差流宽度是
- 策略:不保存 mHC 算子的中间输出。在反向传播时,通过重执行前向计算来恢复这些数据。
- 优化: 由于 mHC 算子不包含繁重的层函数(如 Attention/FFN),重计算成本较低。
- 分块管理:
为了平衡重计算带来的计算开销和存储开销,作者将
层网络划分为若干块(Block),每块包含 层。只持久化存储每个块的输入 。 最优块大小 的理论推导公式为:
在实际中,为了配合流水线并行(Pipeline
Parallelism),块的边界与流水线阶段(Stage)边界对齐。层中重新计算的瞬时激活值。层

存储和重新计算的中间激活值
我们列出了每个标记保留用于反向传播的激活值和在每个连续的
1 | |
3.4 DualPipe 中的通信重叠优化
在大规模训练中,DualPipe 调度策略被用于重叠计算和通信。然而,mHC
引入了跨流水线阶段的

将 DualPipe 调度扩展以处理 mHC
引入的开销。每个块的长度的表示仅为说明,不代表实际持续时间。(F), (B),
(W)分别指前向传递、后向传递、权重梯度计算。
作者对 DualPipe 进行了扩展
- 高优先级流(High-Priority Stream): 将 MLP(FFN)层的_{}$内核放在专用高优先级流上执行,以防止阻塞通信流。
- 非持久化 Attention: 避免在 Attention 层使用长期占用的持久化内核,允许在需要时抢占计算资源,从而更灵活地调度重叠操作。
- 解耦重计算: 重计算过程不依赖于流水线通信(因为输入已本地缓存),因此可以更自由地填充到流水线气泡中。
通过这些优化,在
3.5 mHC 分析
- sinkhorn_knopp 迭代看成是归一化手段, 在 Muon 优化中用
msign算子约束,msign的计算通过Newton-schulz迭代求得 - HC、mHC 可以看成是残差分支
与多个 进行加权组合, 为第 个分支的缩放 - 完整的计算过程残差分支保留激活者, 其他变换分支都用重计算技巧减少显存, 其他分支都是比较小的计算过程
用加权组合视角,看待 HC
- MoE :单个门控权重单元(gate)小计算量, 多个专家(experts)大计算量
- HC:多个变换分支小计算量,单个残差分支大计算量
四、总结
DeepSeek-AI 的这项工作为大模型的宏观架构设计提供了一个极具价值的案例:如何通过严格的数学约束将“不羁”的复杂拓扑结构驯化为可扩展的架构。
mHC 的贡献在于:
- 明确指出了 HC 失效的根源是恒等映射属性的破坏和 I/O 瓶颈。
- 利用 Birkhoff 多面体投影(双随机矩阵)从理论上重构了信号传播的稳定性。
- 通过内核融合和通信重叠,将理论复杂度极高的 Sinkhorn 投影和宽残差流在实际算力集群上高效跑通。
这项技术不仅是对 HC 的修复,也为未来探索更复杂的神经网络拓扑结构(如各种 Differentiable Neural Computer 或复杂路由网络)指明了方向:几何约束(Geometric Constraints)可能是平衡模型可塑性(Plasticity)与稳定性(Stability)的关键。