从GRPO到DAPO以及GSPO
一、简介
在大语言模型的强化学习阶段,PPO 曾是一主流方法。然而,其依赖值模型在处理长文本输出和复杂任务时暴露出局限性。GRPO 消除了对值模型的依赖,显著提升了可扩展性,但在效率和稳定性方面仍有优化空间。这促使了 DAPO 的出现,它对采样、裁剪和梯度计算等细节进行了改进。然而,在动态激活专家的 MoE 架构中,基于 GRPO 框架的 token 级优化仍难以稳定收敛。GSPO 在此基础上更进一步,将优化粒度提升到序列级别,从根本上减少了高方差和结构噪声。本文将沿着这一演进路径:从 GRPO 开始,逐步解析 DAPO 和 GSPO 背后的设计动机和实现细节。
在接下来的文章中,你将发现:
- 为什么 GRPO 摆脱了 PPO 对价值模型的依赖,但在某些情况下仍然会“坍缩”。
- Clip-Higher 如何解决好 token 过早被限制的问题。
- 动态采样如何防止因无效样本导致的巨大计算浪费。
- Token 级别的梯度损失如何确保长响应不再稀释宝贵的梯度信号。
- 为什么 GRPO 的每个 token 重要性采样在 MoE 架构中产生巨大的方差。
- GSPO 如何用序列级优化代替 token 级优化,从根本上提高稳定性和效率。
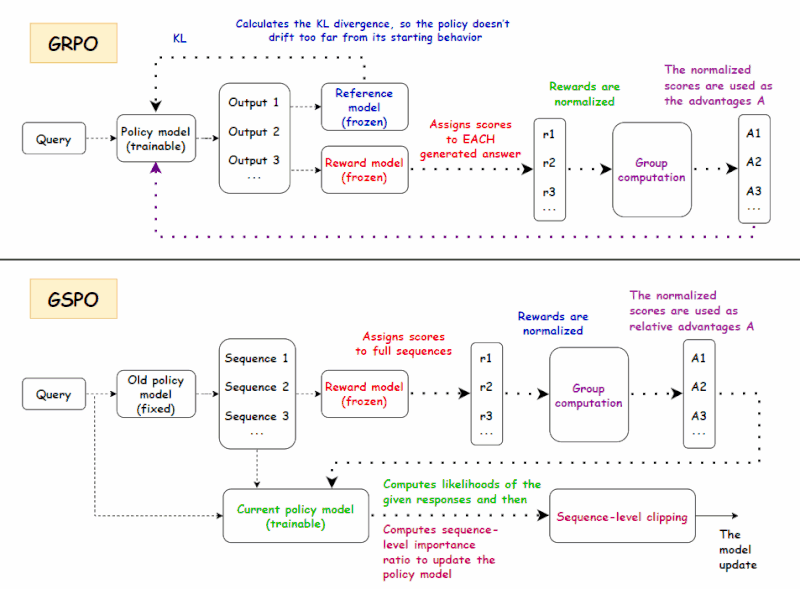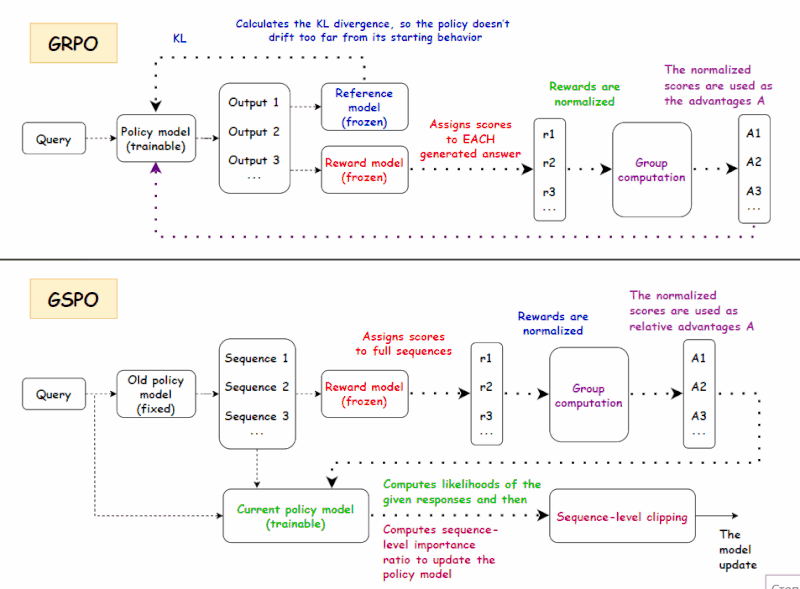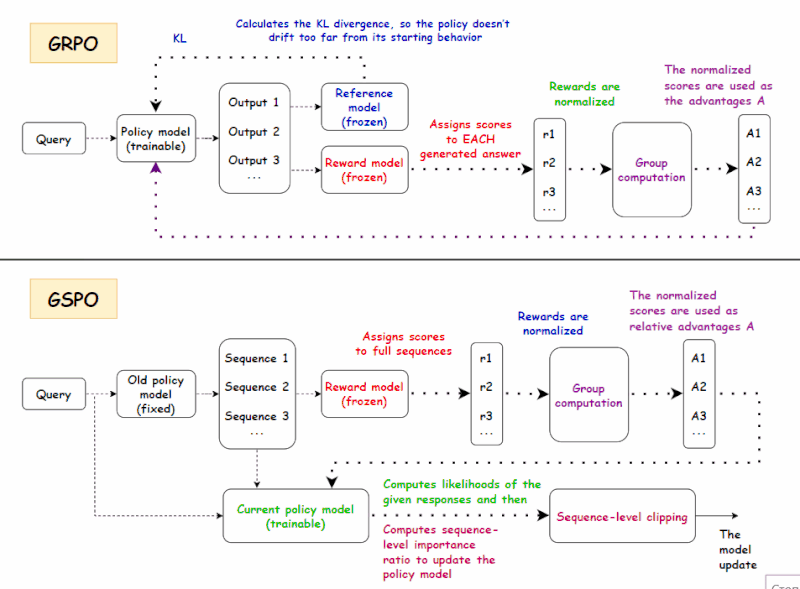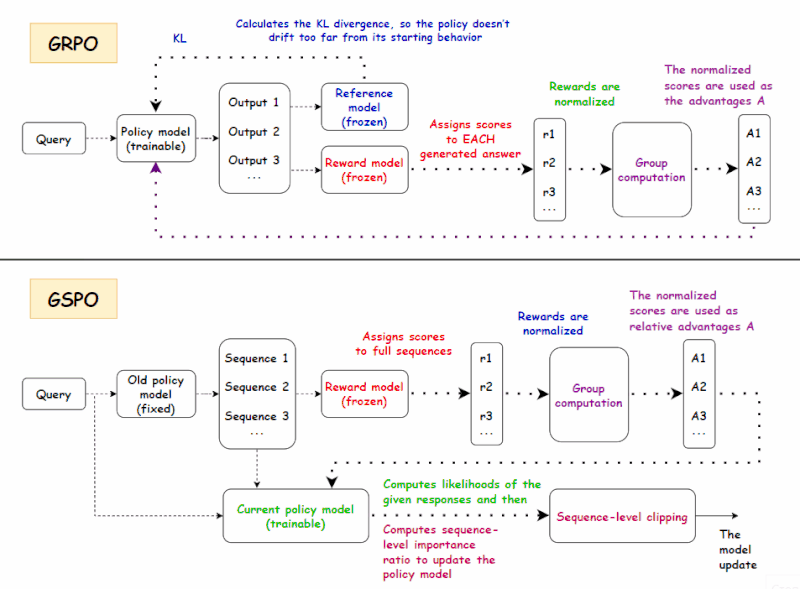
二、GRPO 回顾
GRPO 的训练目标是:
其中
在理解 GRPO 目标后,我们首先需要明确重要性采样的作用和局限性,这对于理解 GRPO 至关重要,也是 DAPO 和 GSPO 中引入改进的切入点。
2.1 重要性比率扮演什么角色?
重要性采样的本质是我们希望计算在新分布下的期望,但我们的数据是从旧分布中抽取的。因此,我们使用新策略和旧策略下相同动作的概率比率作为校正权重:
这使得我们能够使用旧策略的离线数据来评估新策略下的期望值,避免了每次更新后需要重采样的需求(从而降低成本)。然而,如果新旧策略之间的差距过大,权重的方差可能会变得非常高,导致训练不稳定。
重要性采样的目的是在只有行为分布样本的情况下,估计目标分布下的期望值。在 PPO/GRPO 中,我们不直接从新策略中采样数据;相反,我们首先使用旧策略生成数据(因为采样成本很高),这个过程称为 rollout。在更新时,我们必须修正分布不匹配的问题,而重要性采样正是用于此处的。在采样后定义每个标记的重要性比率为:
PPO/GRPO 目标函数可以写为:
这里,
带着这种重要性采样的直观理解,我们可以进一步考虑它在 PPO/GRPO
中的实际效果:优势函数
2.2
让我们分析这些情况。假设min 和
clip 操作会将其限制在 1.2。当min
操作,不会发生剪裁,因此正面的优势向上变化受到限制。
相反地,当min
操作会进一步限制它,最高限制在min
操作不施加任何限制(它可以达到
然而,仅匹配
2.3 裁剪对梯度和 token 效率的影响
对于
此时,我们对 GRPO 的机制、优势及局限性已有相对完整的理解。接下来,我们将看到 DAPO 如何在保留 GRPO 基本框架的同时,引入更细粒度的改进来应对效率和稳定性方面的挑战。
三、从 GRPO 到 DAPO
DAPO 的出发点是一个简单而直接的动力:在实际训练中,由于不合理的裁剪范围、冗余采样和长序列中的梯度稀释等问题,GRPO 常常浪费大量的学习信号。DAPO 通过四个针对性的改进来解决这些问题。
3.1
为什么 DAPO 会提高上限
作者们观察到,将 clip upper bound 设置为较小的
例如,如果旧策略的概率是 0.9,上限是
这就是我们所说的”马太效应”的实质:富者愈富,贫者愈困。如果旧政策几乎无法以极低的概率采样到一个关键
token,比如 “Wait”
,但当前模型显著提高了这个概率,它仍然可能被剪裁掉,从而剥夺了模型”扭转局势”的机会。
Clip-Higher 解决了“优质 token 过早被限制”的问题,但它并未解决另一个常见的浪费来源:采样多样性不足。为应对这一问题,DAPO 引入了动态采样。
3.2 DAPO - 动态采样
DAPO 中的第二个创新是动态采样。其动机如下:假设对于一个给定的查询,我们采样 10 个响应,而这 10 个响应要么非常好,要么非常差,始终获得最大奖励或零奖励。由于 GRPO 的计算方法,这 10 个样本都将具有零优势,因此贡献零梯度。
这意味着有效梯度贡献样本的数量远低于标称样本数,这会导致高方差、训练不稳定以及样本浪费。这种效应在训练开始时(模型较差时)尤为明显,以及后期(模型太好以至于经常产生完美响应时)再次出现。
为应对这一问题,DAPO 实施了一项额外的采样规则:对于每个查询,采样的响应集合中不能所有奖励值都为 0 或 1。如果所有采样值都是 0 或都是 1,则继续抽取额外的样本,直到违反此条件。这可以用约束条件表示为:
这确保了对于相同的输入,采样集合中既包含正确答案也包含错误答案。
除了采样多样性之外,GRPO 在长响应方面还有一个隐藏的缺陷:随着响应长度的增加,token 梯度会被稀释。DAPO 的第三个改进通过 Token-Level Gradient Loss 解决了这个问题。
3.3 DAPO - Token 级别的梯度损失
DAPO 中的第三个创新解决了 GRPO 中存在的问题:每个 token 的梯度权重随着采样响应长度的增加而减少。
为什么会这样呢?假设我们进行两次采样:一次响应有 200 个
token,另一次有 10 个 token。在 GRPO
的公式中,我们首先对每个样本内的梯度进行平均,然后再对整个批次进行平均。这使得第一个响应中的每个
token 的权重为
缺点很明显:对于较难的问题,长回答很常见。如果这些回答质量高,它们宝贵的梯度信号会被稀释。如果质量差,并且长仅仅是因为重复或冗长,那么纠正信号也会减弱。
DAPO 的解决方案:在计算梯度时,对所有样本生成的总 token
数进行平均。在我们的例子中,长回答和短回答都使每个 token 的权重为
这对应于将损失聚合从 GRPO 更改为:
到 DAPO 的:
从经验上看,词元级别的损失能够带来更稳定的训练,防止熵值过高(这会导致策略随机行动),并在熵值过低时避免探索崩溃(Clip-Higher 也有助于解决这个问题)。通过从样本级别损失转向词元级别损失,DAPO 确保长响应能够按比例贡献于最终梯度:每个词元都直接影响整体梯度,与其样本长度无关。
最后的改进也涉及响应长度,但从一个不同的角度来处理:过长响应对整体奖励的负面影响。
3.4 DAPO - 过长奖励塑形
DAPO 的第四次改进通过软惩罚机制调整过长响应的奖励。具体来说,当生成的序列超过预设的第一长度阈值时,会对 token 进行惩罚,并且随着长度的增加,惩罚线性增长。如果长度超过第二阈值,惩罚将足够大以至于抵消正确答案的原始奖励,从而有效地模拟了过长响应被视为无效的情况。
结合 Clip-Higher、动态采样、Token 级梯度损失和过长奖励塑形,DAPO 对 GRPO 进行了细粒度的改进,显著提高了训练效率和稳定性。然而,在某些架构中,特别是 MoE,GRPO 仍然存在结构性问题,这些问题 DAPO 无法完全解决,这促使我们转向 GSPO。
四、GSPO:解决 MoE 训练中的 GRPO 不稳定性问题
如果 DAPO 可以被视为 GRPO 框架内的“微调和优化”,那么 GSPO 则迈出了更根本的一步:它将优化粒度从 token 级别转变为序列级别。这一转变背后的动机源于 MoE 架构训练过程中,GRPO 的重要性采样引入了较大的方差和不稳定性。GSPO 的核心思想是在奖励处理过程中减少对每个 token 优化的依赖,同时更加重视整体序列结果。下面,我们将介绍 GSPO 背后的主要概念。
简而言之:传统的 PPO 和 GRPO 等算法通常单独优化模型输出的每个 token,给某些 token 更高的权重,而给其他 token 较低的权重。虽然这旨在实现细粒度优化,但在长文本、大模型场景下,反而可能引入噪声和奖励偏差,导致模型失去方向,甚至突然崩溃。问题的根源在于我们基于完整响应评估模型,却逐 token 进行训练,导致奖励粒度与优化目标之间存在不匹配。GSPO 通过从逐 token 评分转变为序列级优化,使奖励与优化目标保持一致。这种转变提供了两大主要优势:
- 稳定性——GSPO 优化整个序列,减少了从 token 级别的波动产生的训练噪声。
- 效率——GSPO 筛选并保留高质量样本进行优化,加速收敛并提升结果。
在 MoE 架构中,优势更加显著:由于每次推理仅激活一小部分专家模块,路由路径是动态且难以控制的。传统方法通常依赖路由重放,记录推理过程中的专家激活并强制在训练中执行相同路由,以确保一致性。虽然有效,但这大大增加了工程成本并限制了性能。GSPO 的序列级逻辑自然避免了路由重放的需求,使 MoE 训练更轻量且更稳定。对于日益增多的 MoE 模型,这是一个宝贵的突破。例如,QWen3 系列已采用 GSPO。从 PPO→GRPO→GSPO,我们看到 LLMs 的 RL 优化目标应与任务的性质紧密对齐,同时保持训练逻辑简单、可扩展和可部署。进步往往不是由复杂的技巧驱动,而是由对核心问题的深刻洞察驱动。
PPO 在长文本和复杂任务中表现不佳,主要原因是其依赖值模型:当策略模型输出长序列时,值估计会变得不准确,导致难以从简单任务泛化到复杂任务。GRPO 消除了这种依赖,摆脱了值模型的瓶颈。然而,GRPO 在 MoE 训练或长时间训练过程中仍面临稳定性问题:在某个时刻,模型可能会突然崩溃,即使恢复训练或调整参数也往往无法恢复。接下来,让我们分析可能的原因和解决方案。
4.1 重要性比率扮演什么角色,为什么它在 GRPO 中存在问题?
重要性采样使我们能够在仅拥有来自行为分布的样本时,估计目标分布下的期望值。我们通过根据目标策略与行为策略之间的概率比来对样本进行加权来实现这一点。然而,这种校正假设有多个样本,如果只有一个样本,它将无法有效地调整分布偏移。
大型模型训练中的问题是,重要性采样是按每个 token 进行的,单个 token 的比率无法有意义地执行分布校正。相反,它引入了高方差噪声,尤其是在不稳定的 MoE 设置中。这表明 GRPO 的 token 级计算可能本质上是不理想的。
另一个不匹配:我们的奖励是针对整个响应(序列级别)给出的,但在标记级别的重要性采样中,我们将这个奖励平均分配到各个标记(奖励塑形),并试图单独调整它们。这造成了奖励信号和优化目标之间的粒度不匹配。既然我们已经有了序列级别的奖励,为什么不让 GRPO 的优化也采用序列级别呢?
4.2 为什么 GRPO 在 MoE 架构中难以收敛?
专家激活波动性:新政策与旧政策可能会激活不同的专家,从而引入结构性偏差和噪声。当
理论上,重要性比率应当反映相同结构下参数更新所引起的概率变化。但专家变化会导致与优化方向无关的、不可预测的高方差波动。这种方差会扭曲策略梯度估计,导致训练不稳定,甚至引发崩溃。
4.3 在 GSPO 之前的路由重放
路由重放记录了在从
虽然传统方法使用路由重放来缓解专家激活不匹配的问题,但 GSPO 完全绕过了这种依赖,从根源上减少了结构差异。
4.4 GSPO 损失设计
如果奖励是序列级别的,重要性比也应该是序列级别的。
从上文可以看出,GSPO 用序列级比率
序列级别的比率经过长度归一化以减少方差并保持值在一致的尺度上。如果不进行归一化,不同长度的答案会使比率对长度非常敏感。由于同一序列的所有标记共享相同的重要性比率,如果触发裁剪,将裁剪整个序列,而不仅仅是某些标记。归一化因子
4.4.1 为什么需要指数化而不是直接使用对数似然差异?
指数化是必要的,因为重要性采样的核心公式是:
这里权重必须是一个概率比
这不再是无偏的重要性采样校正。
GSPO 通过
这确保了重要性比率在序列长度上的一致性缩放,避免了长序列中少数 token 概率变化导致的极端值。在日志空间中不进行指数运算会使比率对长度敏感,需要调整裁剪范围,并破坏与 PPO/GRPO 中使用的 KL 正则化兼容性。
4.5 理论梯度分析:GSPO 与 GRPO
从客观定义来看,关键区别在于重要性比率在梯度计算中的定义和使用方式。
如果不进行裁剪,区别在于是否要在同一响应中对不同的 token
进行不同的加权。GRPO 根据
GSPO 的梯度:
这里,响应中的所有 token 共享相同的权重
GRPO 的梯度:
在这里,权重
另一个区别在于裁剪如何与这些比率相互作用。对于正优势样本,GRPO
的比率范围大致为
奖励指标在检测模型漂移方面也存在滞后,等到问题出现时,模型可能已经偏离了一段时间。实验表明,GSPO 由于裁剪更为激进,使用有效 token 数量更少,却实现了更高的训练效率。
总之,GSPO 实现了序列内一致的梯度权重,减少了 token 之间的方差,特别适用于长序列和 MoE 场景下的稳定训练。它的引入标志着从 PPO → GRPO → GSPO 的转变,从依赖价值模型的 token 级优化转向与任务本质相一致的序列级优化。
Reference
- From GRPO to DAPO and GSPO: What, Why, and How
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- Why GRPO is Important and How it Works
- Group Relative Policy Optimization (GRPO)
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale
- DAPO: Enhancing GRPO For LLM Reinforcement Learning
- DAPO:字节完整开源全部复现RL细节
- Group Sequence Policy Optimization
- What is GSPO ? The RL algorithm used to train Qwen3
- GSPO:迈向持续拓展的语言模型强化学习
- The Evolution of Policy Optimization: Understanding GRPO, DAPO, and Dr. GRPO’s Theoretical Foundations
- Beyond PPO - The New Wave of Policy Optimization Techniques for LLM Post-Training